Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
GunosyでのKinesis Analytics利用について / BigData JAWS ...
Search
koid
April 04, 2017
Technology
1k
1
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
GunosyでのKinesis Analytics利用について / BigData JAWS 6 Kinesis Analytics
koid
April 04, 2017
More Decks by koid
See All by koid
新しい技術の導入時に大切にしていること / IVS CTO Night 2018 LT
koid
2
7.3k
GunosyでのKinesis Analytics利用について / AWS Solution Days 2017 -AWS DB Day-
koid
0
300
re:Inventに行ってきました - 気になった新サービス / AWS re:Invent2016 Participants LT
koid
0
2.1k
AWS Lambda - ピーキーなアクセスに備える / Gunosy Beer Bash #8
koid
0
2.3k
AWS Lambdaで複数アカウント間でアレコレする / Gunosy Beer Bash #7
koid
1
2.3k
サーバにログインしない・させないサービス運用 / AWS Summit 2015 Devcon
koid
6
9.3k
GunosyのMicroServicesとOpsWorks / よくわかる AWS OpsWorks
koid
18
6.1k
Other Decks in Technology
See All in Technology
SRE Next 2026 何でも屋からの脱却
bto
0
700
クラウド上のデータ復旧で見落としがちな制約: 医療系 SaaS の BCP 設計から得た教訓
kakehashi
PRO
0
3.5k
Foxgloveについて 実際にExtensionを開発して公開するまでの話 / About Foxglove: The Story of Developing and Releasing an Extension
ry0_ka
0
240
Devsumi 2026 Summer 人もAIも使える共通基盤を事業の加速装置にする~デザインシステム運用に学ぶ組織レバレッジ~ 渡辺 凌央
legalontechnologies
PRO
0
130
Claude Codeとハーネスについて考えてみる
oikon48
19
9.4k
世界、断片、モデル。そして理解
ardbeg1958
1
110
ZOZOTOWNの進化と信頼性を両立する負荷試験
zozotech
PRO
2
160
Empower GenAI with Agile - あなたのアジャイルが生成AIのバフになる仕組み
hageyahhoo
1
180
なぜ私たちのSREプラクティスはなかなか機能しないのか 〜システムより先に組織を見る〜 / Why our SRE practices aren't really working
vtryo
3
3.7k
美しいコードを書くためにF#を学んでみた話
yud0uhu
1
420
あなたの『Site』はどこですか? — xREという考え方
miyamu
0
1.2k
プロダクトだけじゃない、社内プロセスにおける自動化・省力化ノススメ
kakehashi
PRO
1
3.7k
Featured
See All Featured
For a Future-Friendly Web
brad_frost
183
10k
CSS Pre-Processors: Stylus, Less & Sass
bermonpainter
360
30k
Speed Design
sergeychernyshev
33
1.9k
A designer walks into a library…
pauljervisheath
211
24k
Leo the Paperboy
mayatellez
8
1.9k
How to make the Groovebox
asonas
2
2.3k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.7k
Raft: Consensus for Rubyists
vanstee
141
7.6k
Templates, Plugins, & Blocks: Oh My! Creating the theme that thinks of everything
marktimemedia
31
2.8k
Design and Strategy: How to Deal with People Who Don’t "Get" Design
morganepeng
133
19k
How to audit for AI Accessibility on your Front & Back End
davetheseo
0
460
Paper Plane
katiecoart
PRO
2
52k
Transcript
GunosyでのKinesis Analytics利⽤について 株式会社Gunosy ⼩出 幸典
⾃⼰紹介 • 名前 – ⼩出 幸典 (こいで ゆきのり) • 所属
– 株式会社Gunosy • プロビジョニング・デプロイフローの共通化とか • 過剰リソース警察、コスト削減おじさん • 好きなAWSサービス – OpsWorks, Lambda, Kinesisファミリー, 最近ちょこっとECS
株式会社Gunosy – 「情報を世界中の⼈に最適に届ける」 • Gunosyは 情報キュレーションサービス「グノシー」と • 2016年6⽉1⽇にKDDI株式会社と共同でリリースした 無料ニュース配信アプリ「ニュースパス」を提供する •
会社です。「情報を世界中の⼈に最適に届ける」を ビジョンに活動しています。 ネット上に存在するさまざまな情報を、 独⾃のアルゴリズムで収集、評価付けを⾏い ユーザーに届けます。 情報キュレーションサービス 「グノシー」 600媒体以上のニュースソースをベースに、 新たに開発した情報解析・配信技術を⽤いて⾃動的に 選定したニュースや情報をユーザーに届けます。 無料ニュース配信アプリ 「ニュースパス」
宣伝:データ分析ブログやっています http://data.gunosy.io/
本⽇お話させていただく内容 Gunosyでどういった感じで Kinesis Analyticsを利⽤しているか
なぜストリーム処理/マイクロバッチ処理をしたいのか • 「情報を世界中の⼈に最適に届ける」 – 時間(鮮度)の制約 • 情報には「鮮度」がある – 頻度(量)の制約 •
⾒せられる情報量には限りがある • どういった⼈に、どういった情報が適しているのか – 事前に「誰にどのぐらい読まれるか」等の推定はしているが、⾄近 の実績値も評価に利⽤したい – より短い時間・より少ない試⾏で、実績値を集めたい
例えば • 記事クリックの(ニア)リアルタイム算出 – 「⼤域的な」傾向はわかる
例えば • 「⼤域的な」!= 全てのユーザ – それぞれどういった⼈に適しているのか
Gunosyでの右往左往 • 2013 mongodb+マイクロバッチで頑張っていた • 2014 Redshift+マイクロバッチで頑張っていた – fluentdのflush intervalが短すぎるとcopyが詰まる
– クエリ投げすぎても詰まる余り⾼頻度にできない • 2015 Norikraで頑張っていた – 度々⽌まるが知⾒無さすぎ→監視も復旧⾃動化もままならず – 我々には早かった • 2016 Spark Streamingで頑張っていた – ⾃由度⾼いけど開発コスト⾼し、インフラコスト⾼し – 我々にはオーバースペックだった 本⽇は割愛
本題 Kinesis Analyticsを利⽤してみた
ざっくりした構成(Source Stream) • 以前よりfluentdを利⽤してログ配送をしていた – 同じログをStreams/Firehoseに送る • fluent-plugin-kinesis • Kinesis
Analyticsはまだ東京に来ていないので、他リージョンへ Web servers (fluentd) Kinesis Firehose S3 (backup) Kinesis Analytics Elasticsearch Service summary log Mobile apps Source Stream log Tokyo Oregon Kinesis Firehose
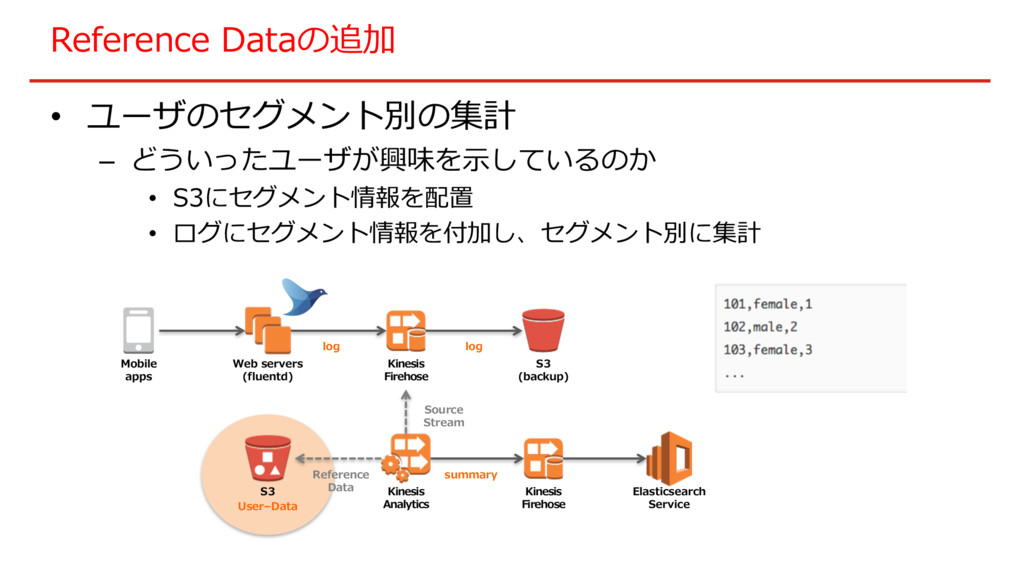
Reference Dataの追加 • ユーザのセグメント別の集計 – どういったユーザが興味を⽰しているのか • S3にセグメント情報を配置 • ログにセグメント情報を付加し、セグメント別に集計
S3 User–Data Reference Data Web servers (fluentd) Kinesis Firehose S3 (backup) Kinesis Analytics Elasticsearch Service summary log Mobile apps Source Stream log Kinesis Firehose
SQL例 • ⼀度中間ストリームを作る – Source StreamとReference DataをJOIN
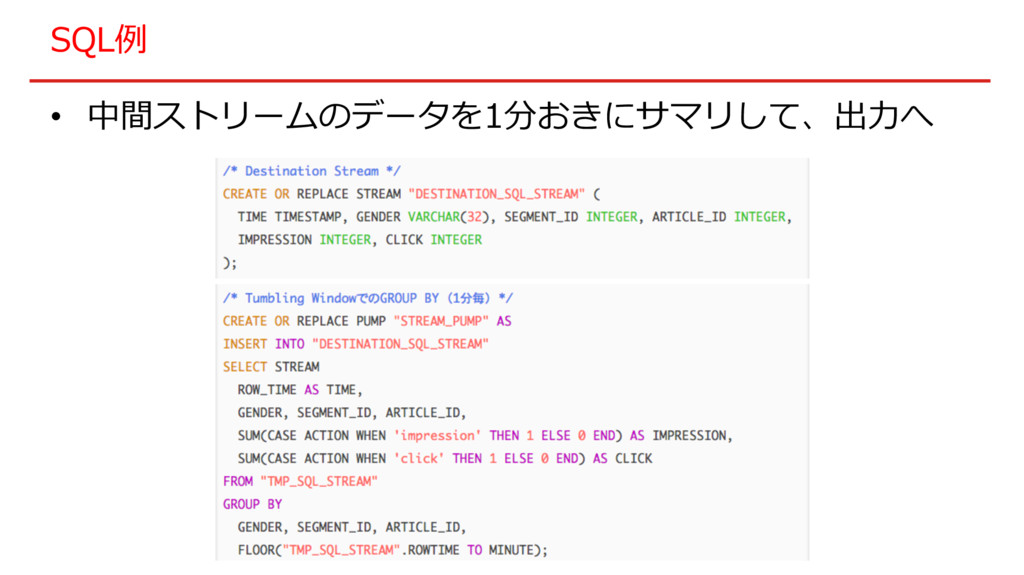
SQL例 • 中間ストリームのデータを1分おきにサマリして、出⼒へ
クエリ結果のイメージ • (再掲)
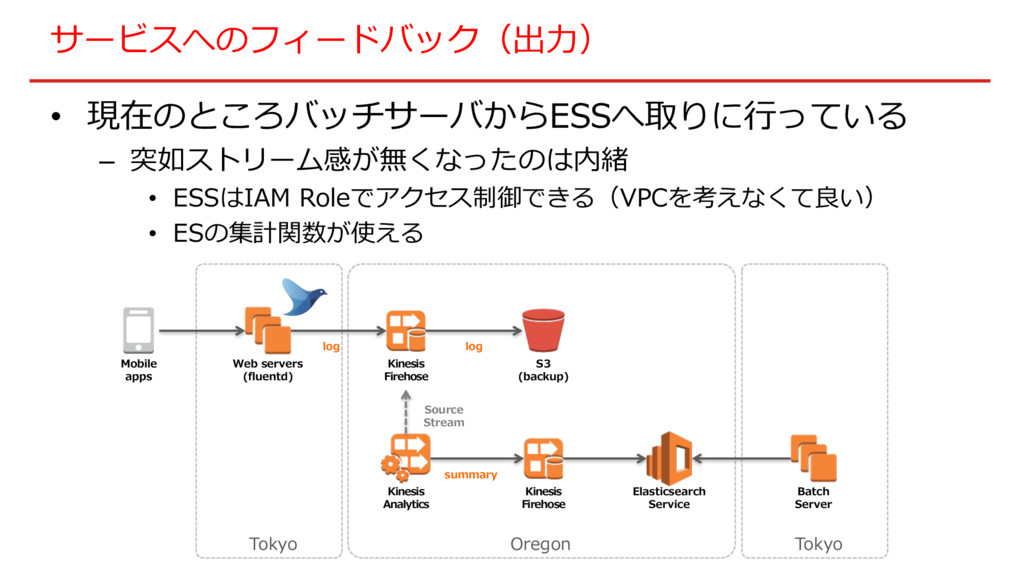
サービスへのフィードバック(出⼒) • 現在のところバッチサーバからESSへ取りに⾏っている – 突如ストリーム感が無くなったのは内緒 • ESSはIAM Roleでアクセス制御できる(VPCを考えなくて良い) • ESの集計関数が使える
Web servers (fluentd) Kinesis Firehose S3 (backup) Kinesis Analytics Elasticsearch Service summary log Mobile apps Source Stream log Tokyo Oregon Kinesis Firehose Batch Server Tokyo
苦労/⼯夫したところなど
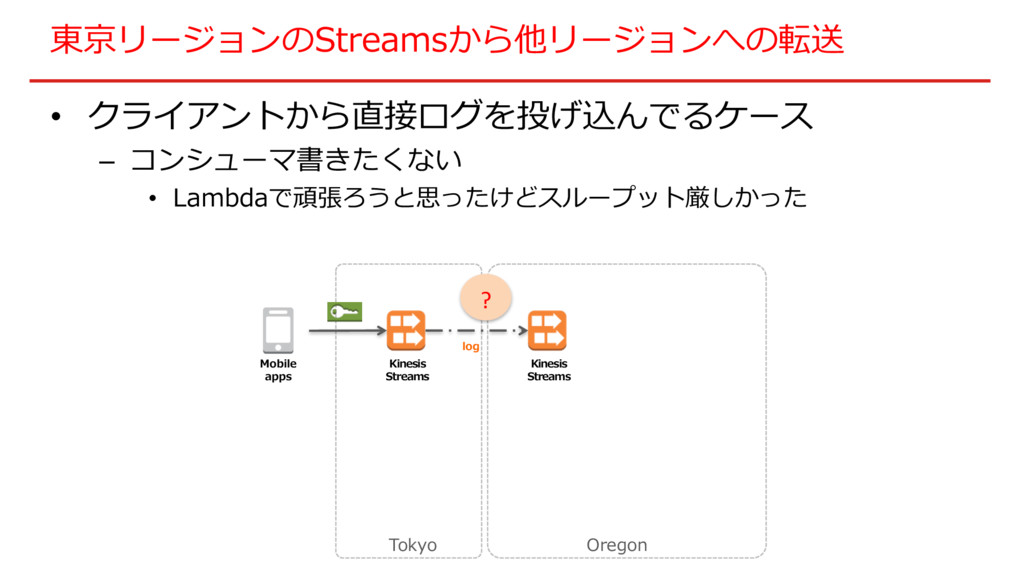
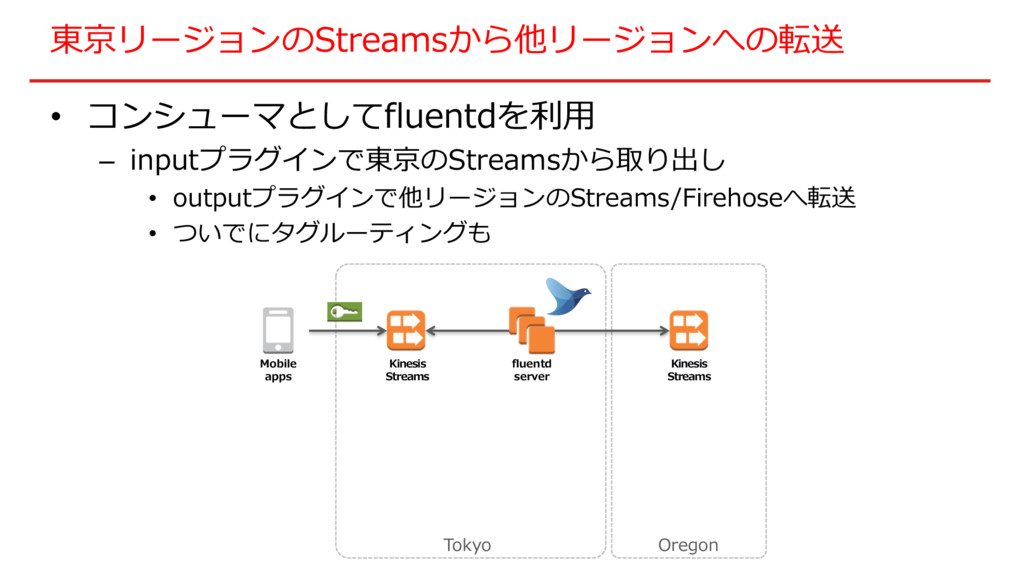
東京リージョンのStreamsから他リージョンへの転送 • クライアントから直接ログを投げ込んでるケース – コンシューマ書きたくない • Lambdaで頑張ろうと思ったけどスループット厳しかった Kinesis Streams log
Mobile apps Tokyo Oregon Kinesis Streams ?
東京リージョンのStreamsから他リージョンへの転送 • コンシューマとしてfluentdを利⽤ – inputプラグインで東京のStreamsから取り出し • outputプラグインで他リージョンのStreams/Firehoseへ転送 • ついでにタグルーティングも Kinesis
Streams Mobile apps Tokyo Oregon Kinesis Streams fluentd server
利⽤していての所感
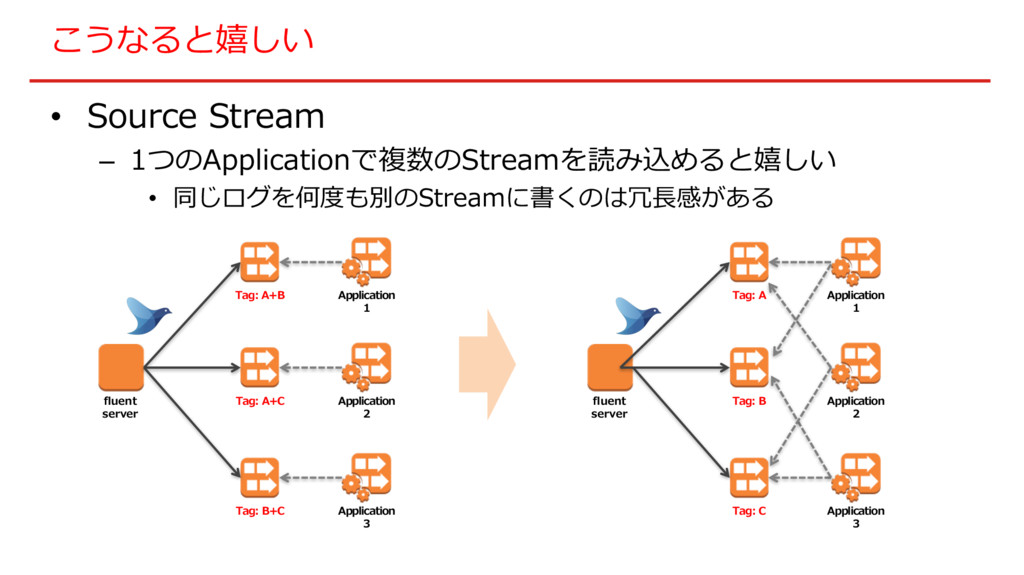
こうなると嬉しい • Source Stream – 1つのApplicationで複数のStreamを読み込めると嬉しい • 同じログを何度も別のStreamに書くのは冗⻑感がある fluent server
Tag: A+B Application 1 Tag: A+C Application 2 Tag: B+C Application 3 fluent server Tag: A Application 1 Tag: B Application 2 Tag: C Application 3
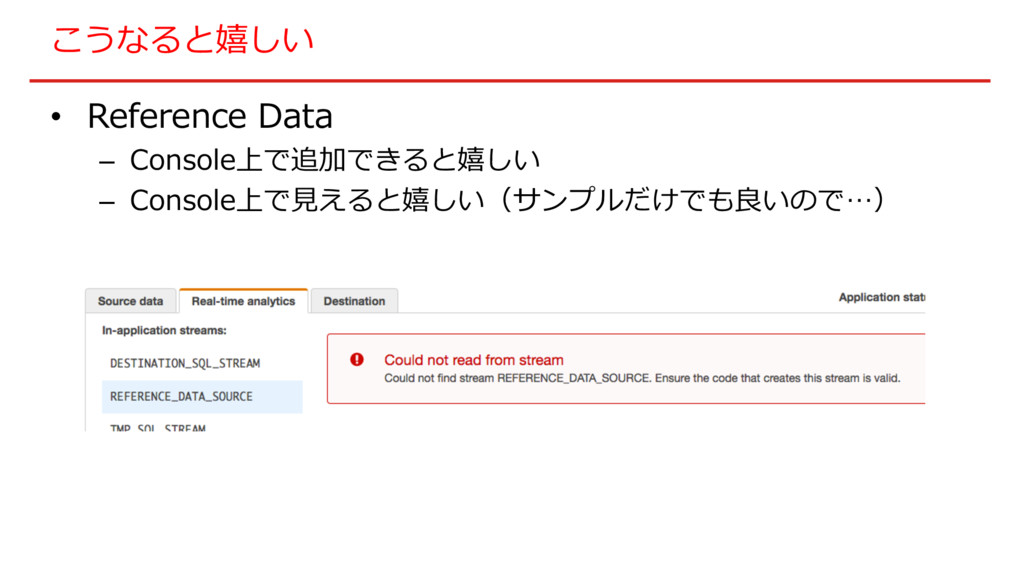
こうなると嬉しい • Reference Data – Console上で追加できると嬉しい – Console上で⾒えると嬉しい(サンプルだけでも良いので…)
まとめ • 開発が楽 – ほとんどConfig芸(IAMは⼤変) – クエリだけ集中して考えられる • 運⽤も楽 –
フルマネージド – 前後(Streams/Firehose)の流量は注意 • コストも安い – (ケース次第ですが)
終わりに • ご清聴ありがとうございました
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}