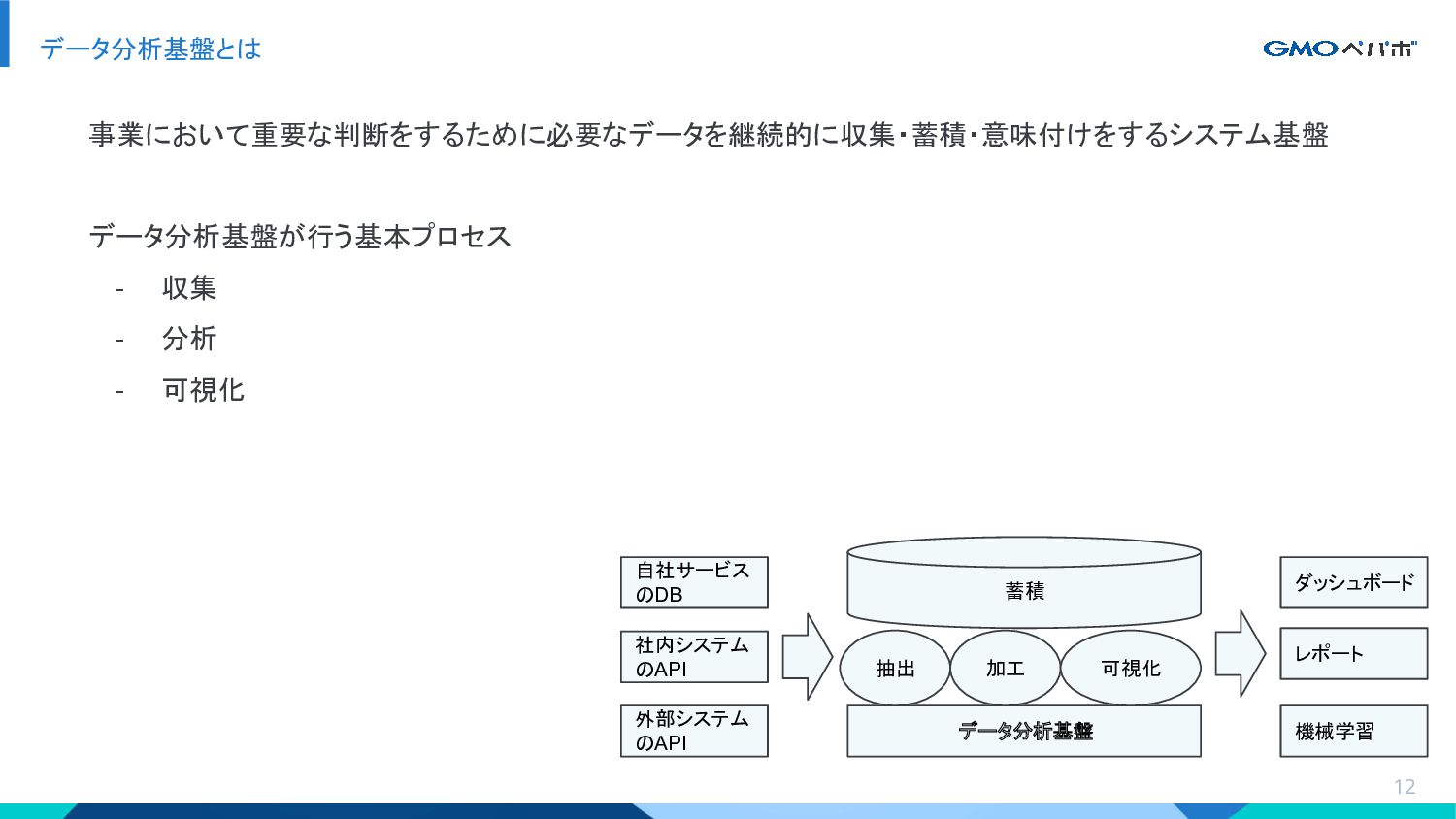
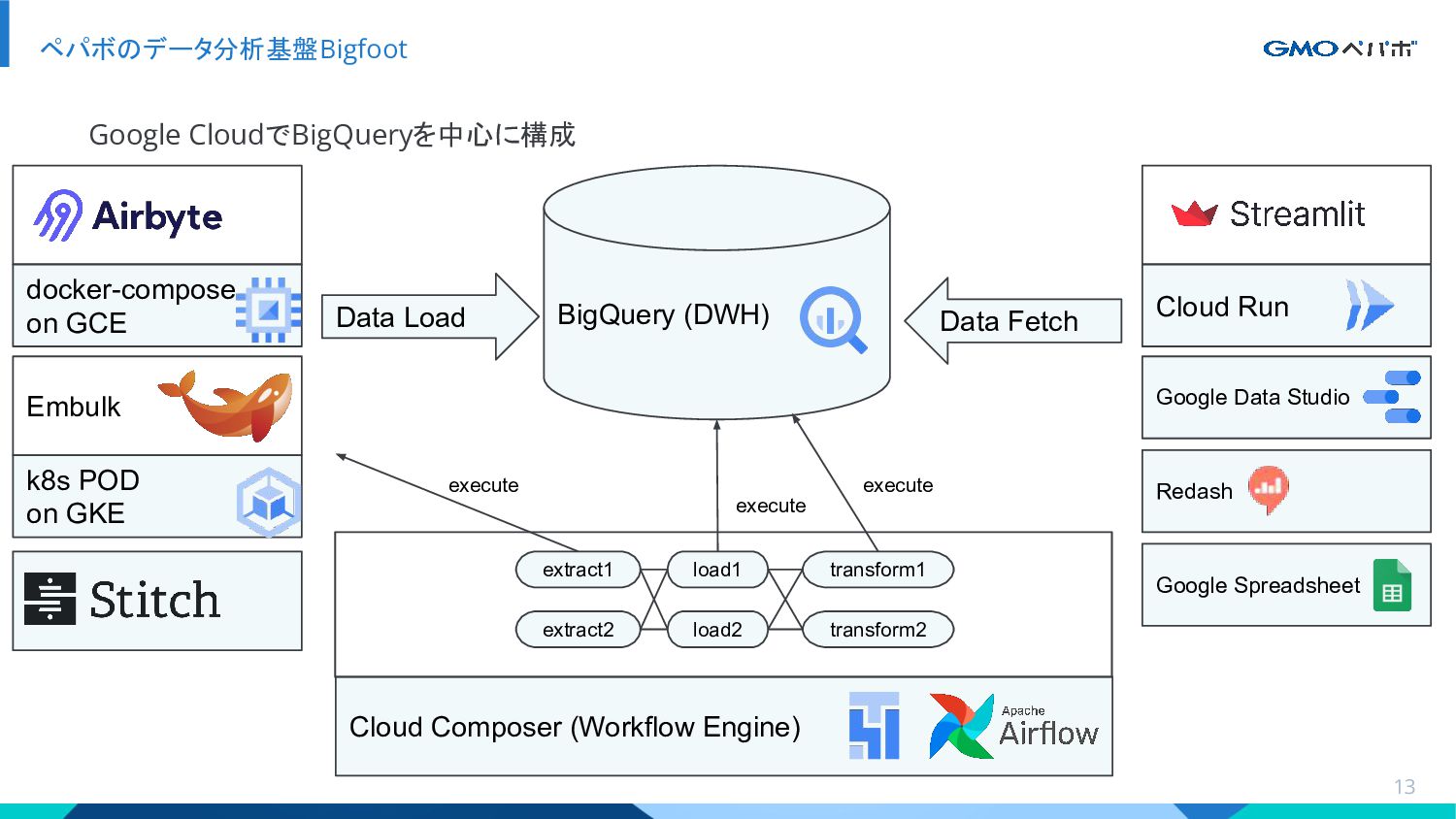
GMOペパボ株式会社では主にGoogle Cloud Platformのサービスを利用してデータ分析基盤を構築し運用しています。その中心となるのがデータウェアハウスのBigQueryとワークフローエンジンのCloud Composerです。また、社内向けのデータ可視化(ダッシュボード)システムではCloud Runを利用しています。
データ分析基盤から得られる情報を重要な意思決定に用いるためには、ユーザーに提供しているインフラと同様に、可用性を明らかにし、継続的に可用性を高める Realiability エンジニアリングが必要となります。本講演ではGCPで構築されているデータ分析基盤を題材として、データ分析基盤に求められる可用性や、小規模なチームにおけるオブザーバビリティへの取り組みについてご紹介します。
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
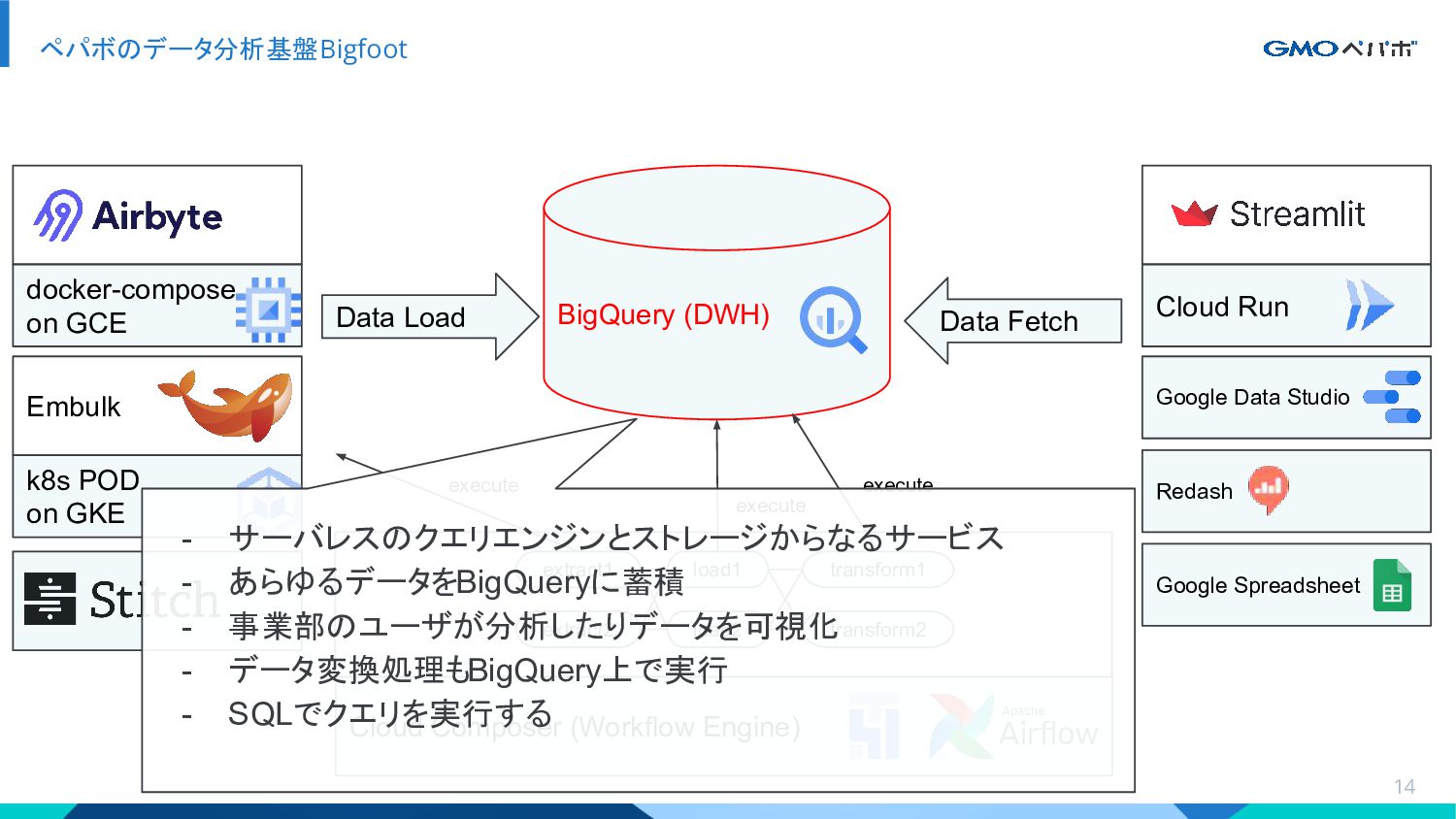{kind=link}
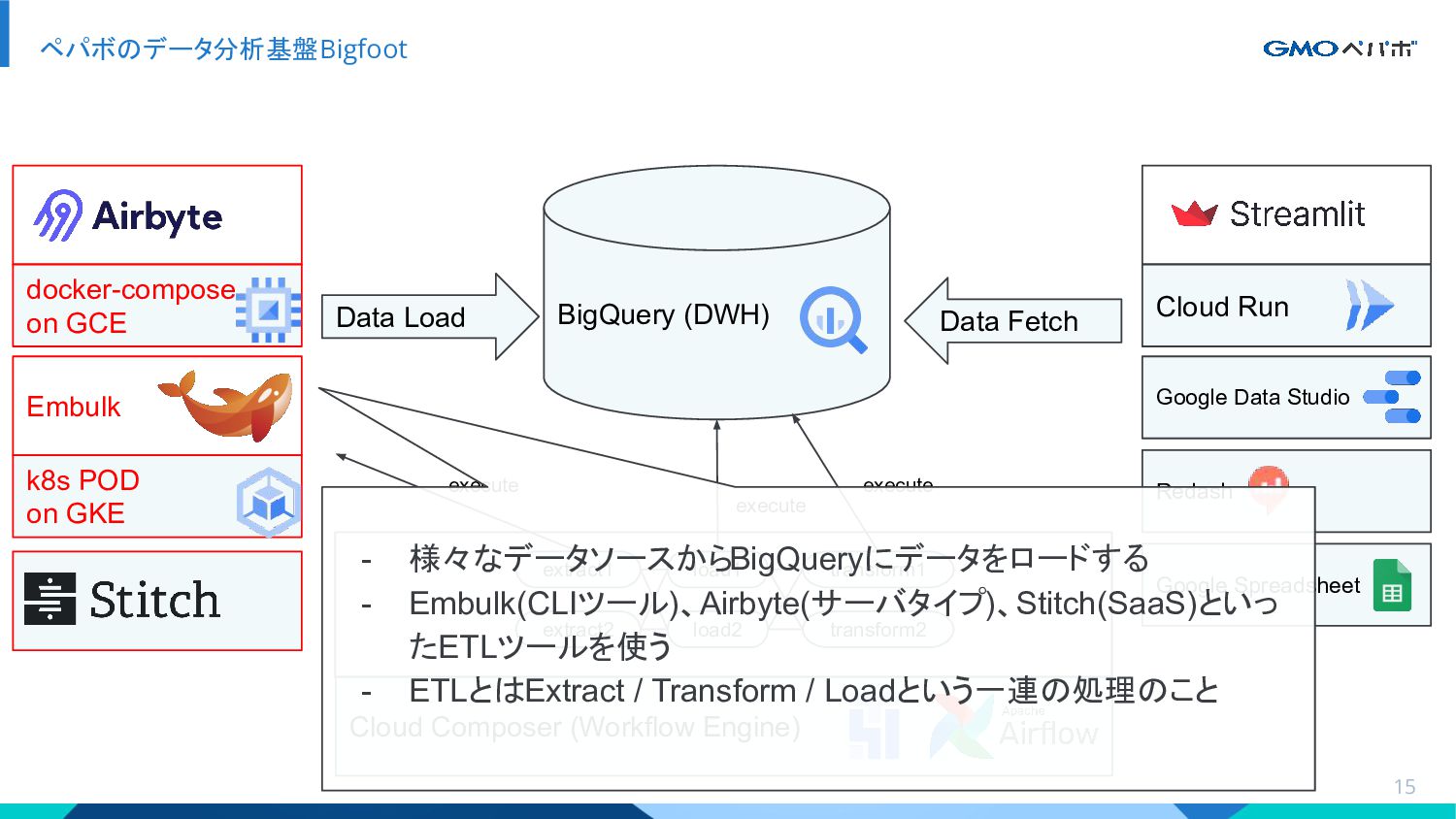{kind=link}
{kind=link}
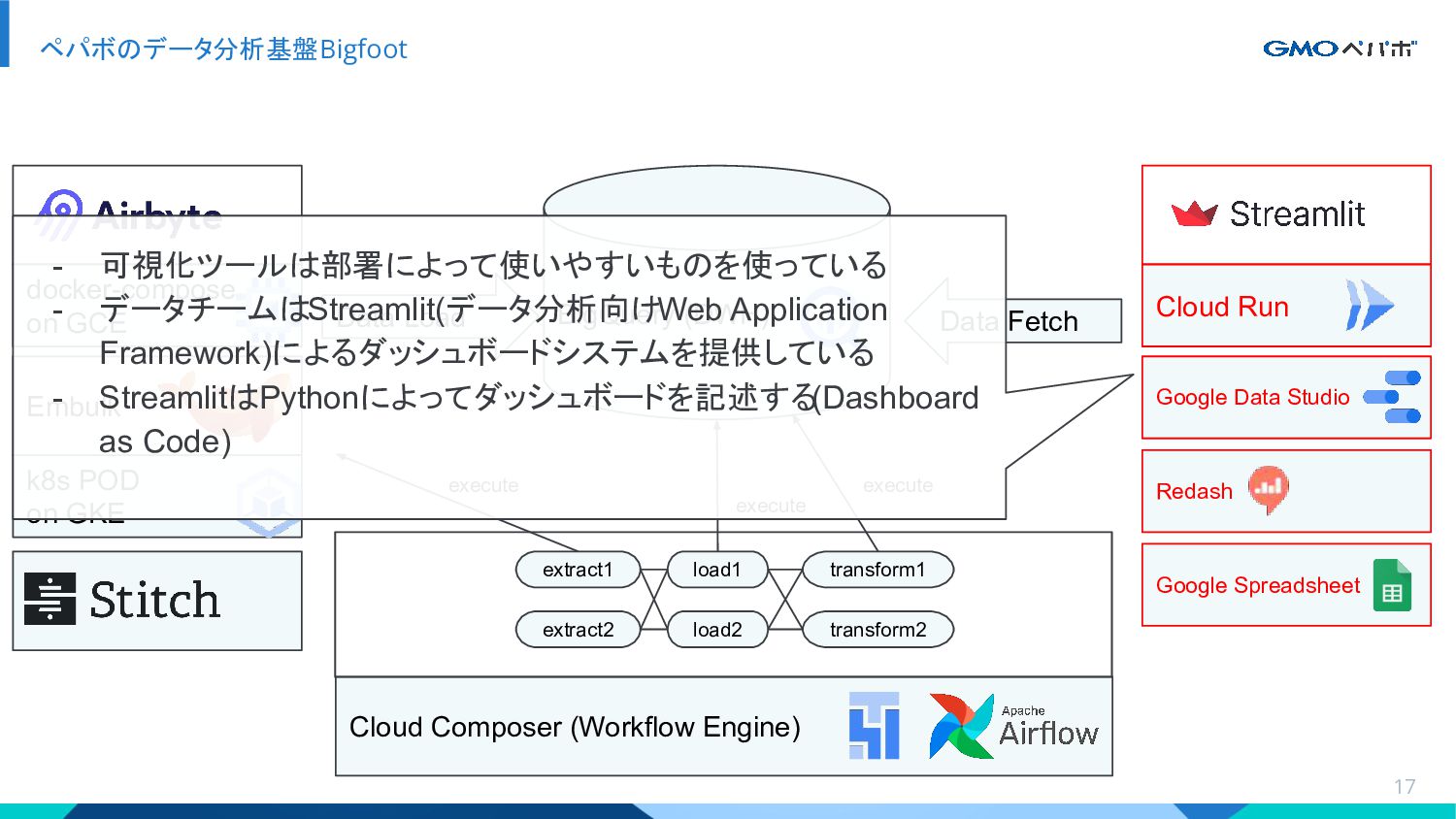{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
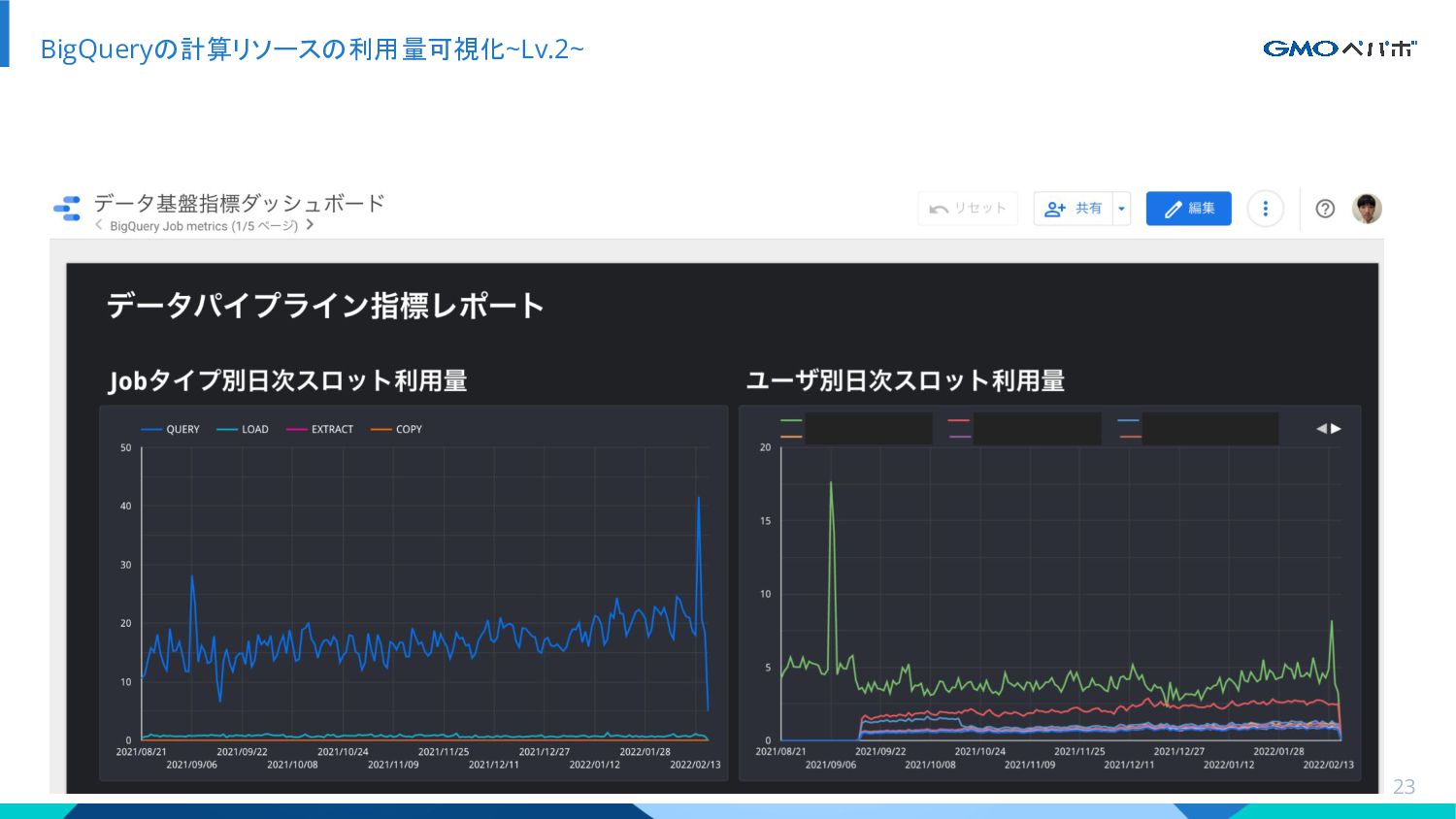{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
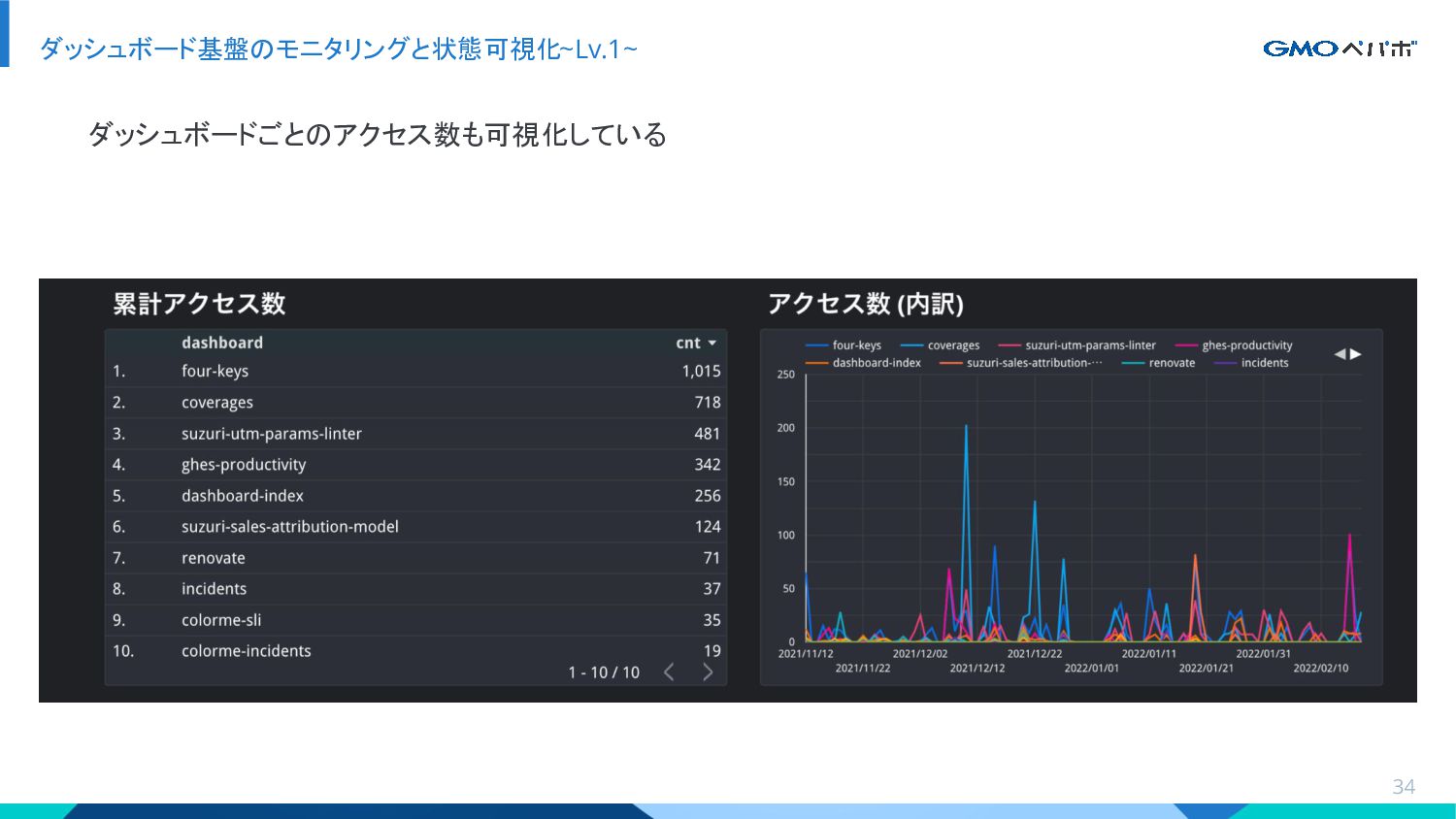
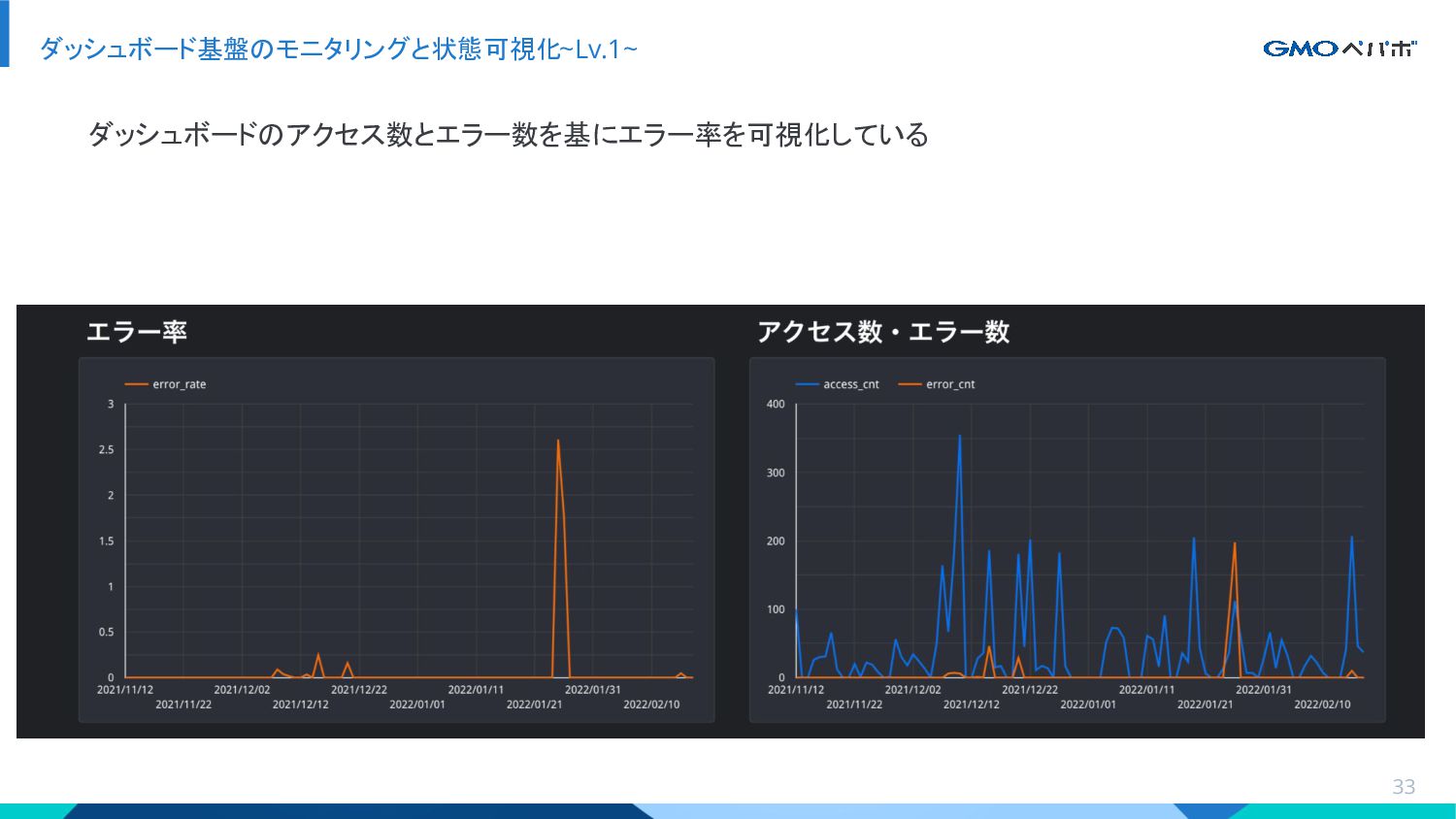{kind=link}
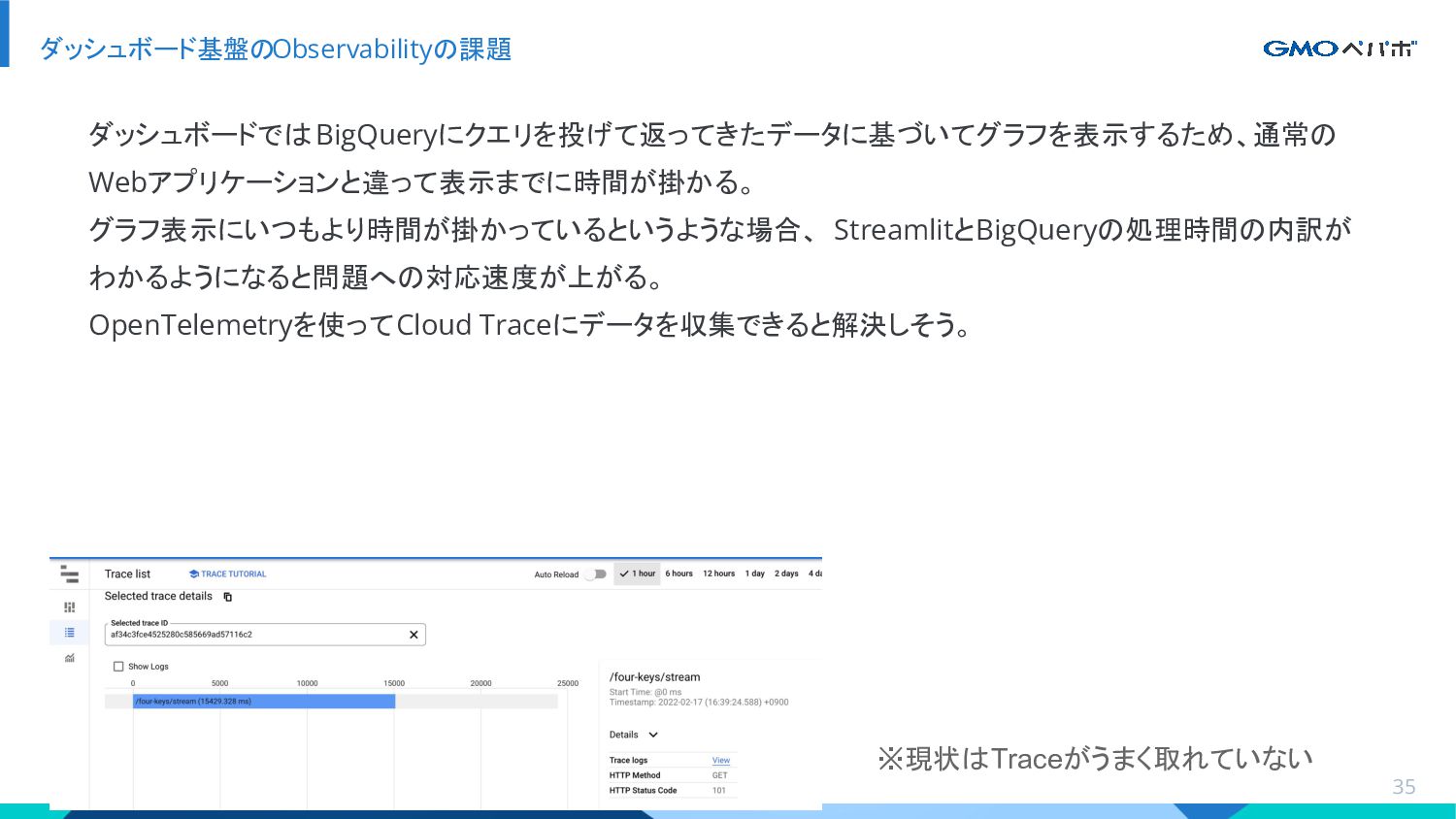
{kind=link}
{kind=link}
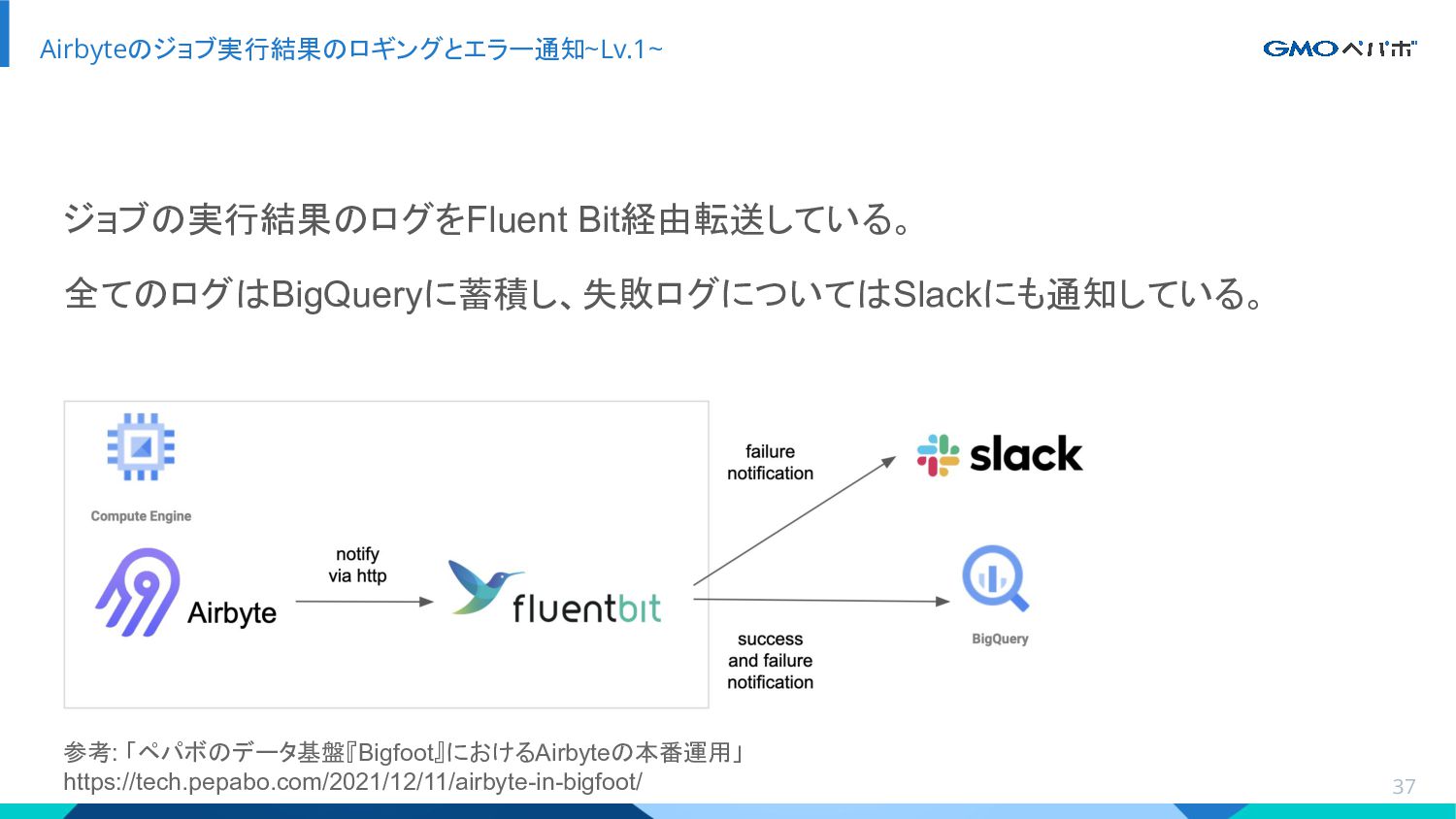
{kind=link}
{kind=link}
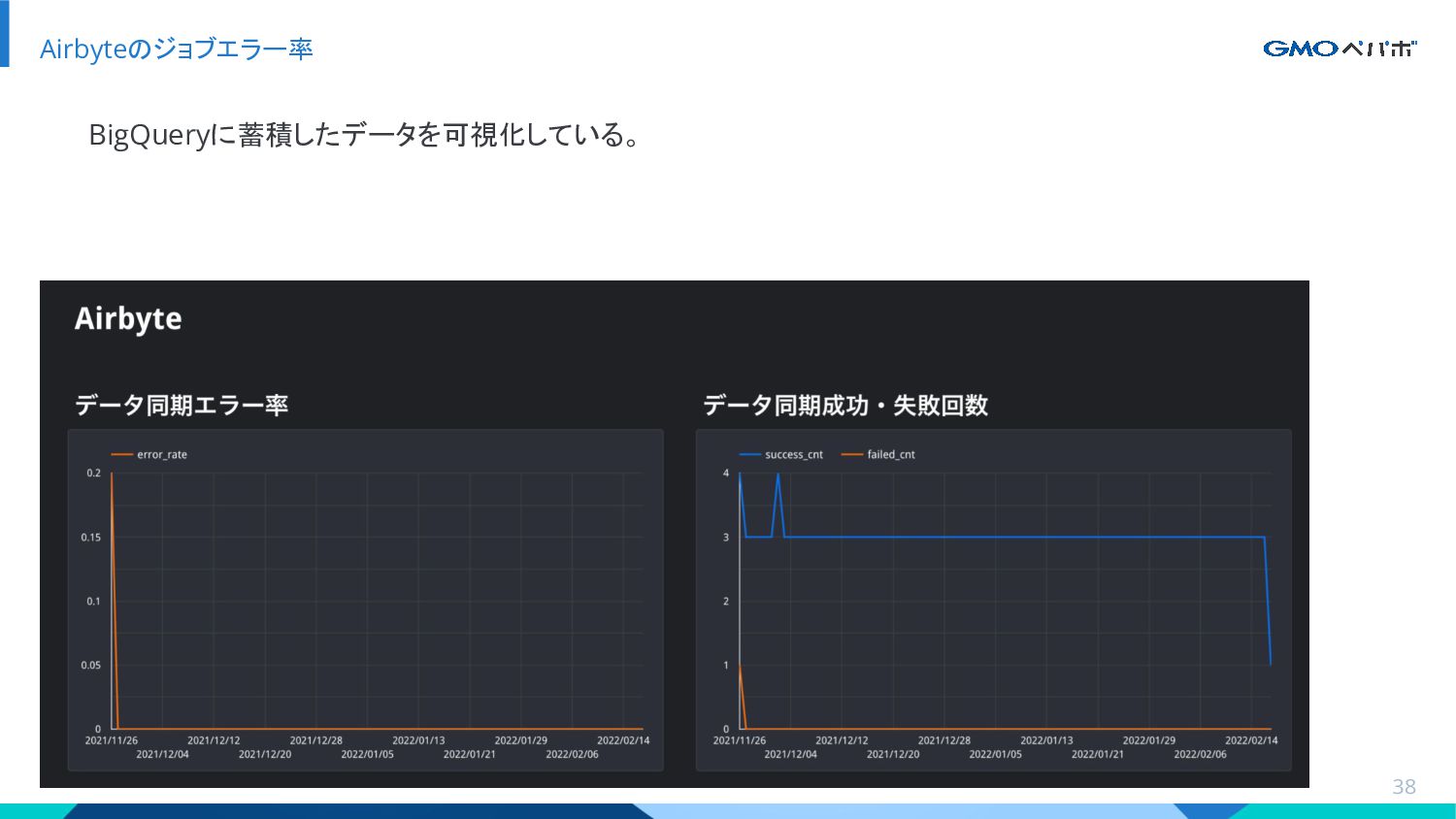{kind=link}
{kind=link}
{kind=link}
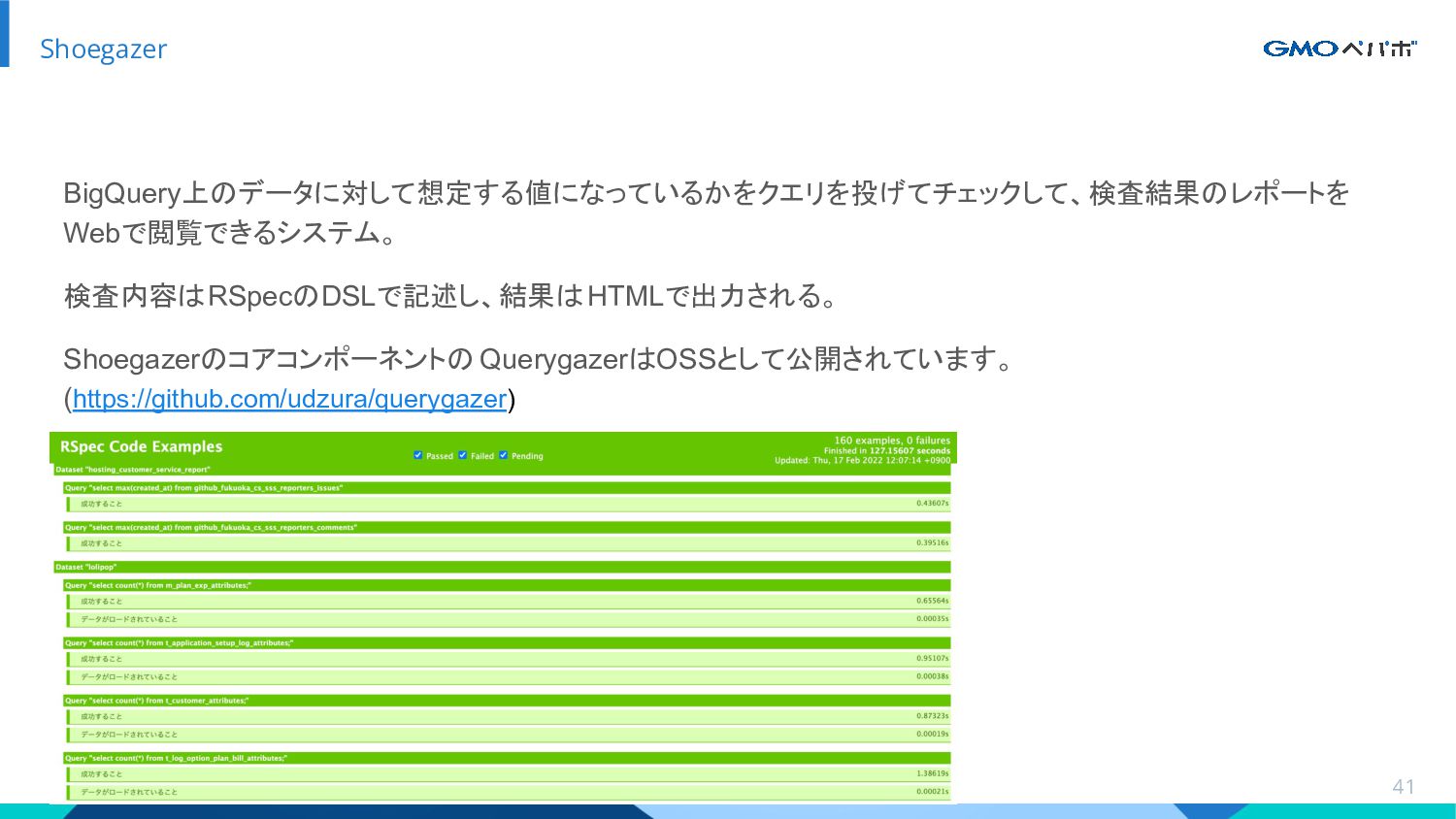{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}