separately? Can we train on monolingual data instead of bitext? • 提案手法は,LASERがLMと組み合わさった場合でもほとんどの言語ペア で大幅に上回っている • 妥当性と流暢性を共同で最適化するほうが,個別に最適化して事後に組 み合わせるよりも優れていることを示唆 • 提案手法は単言語コーパスで学習しているmBARTより高い • 計算時間も早い ◦ Prism: 1.3 weeks on 8 V100s ◦ mBART: 2.5 weeks on 256 V100s
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
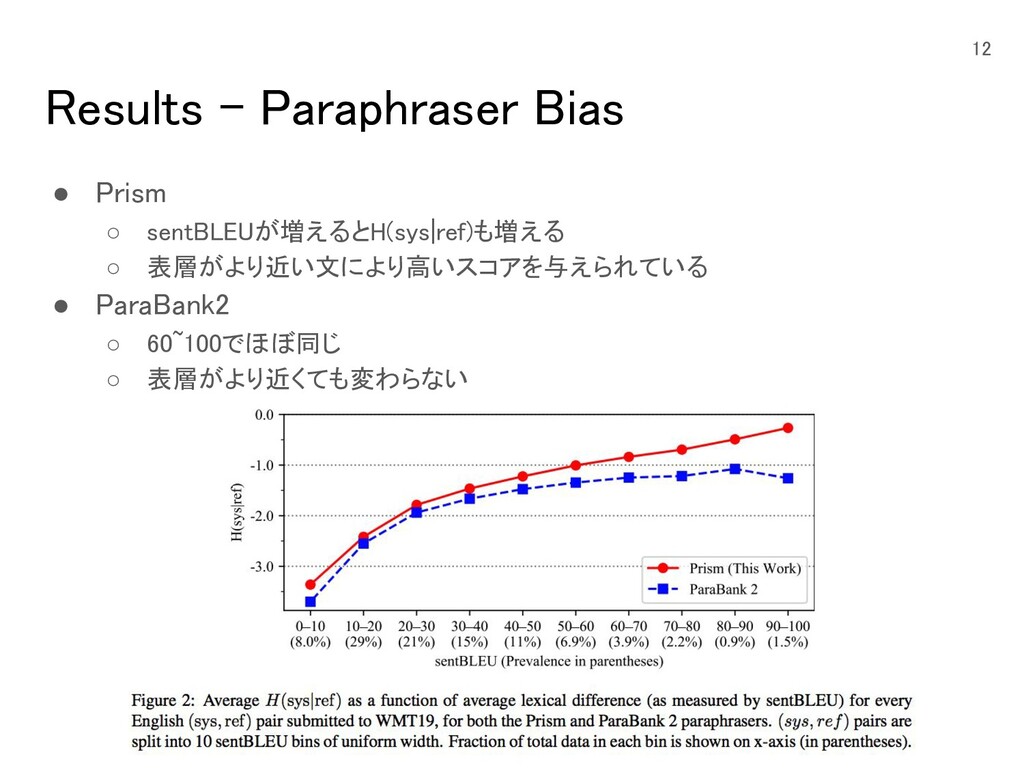{kind=link}
{kind=link}
{kind=link}
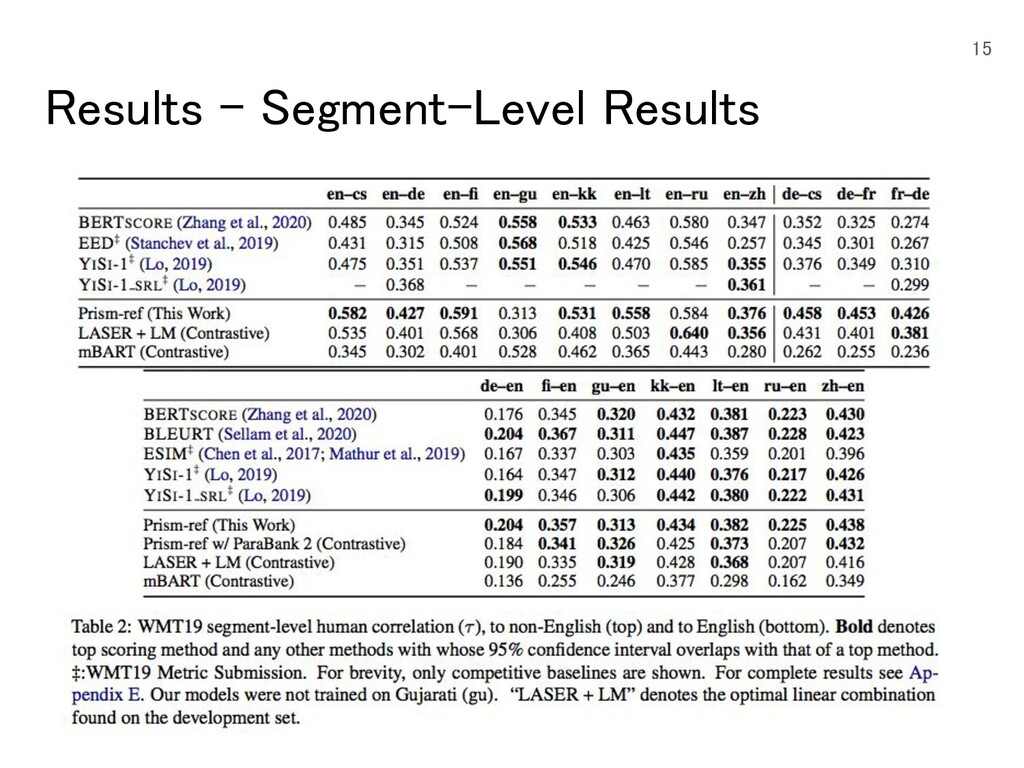{kind=link}
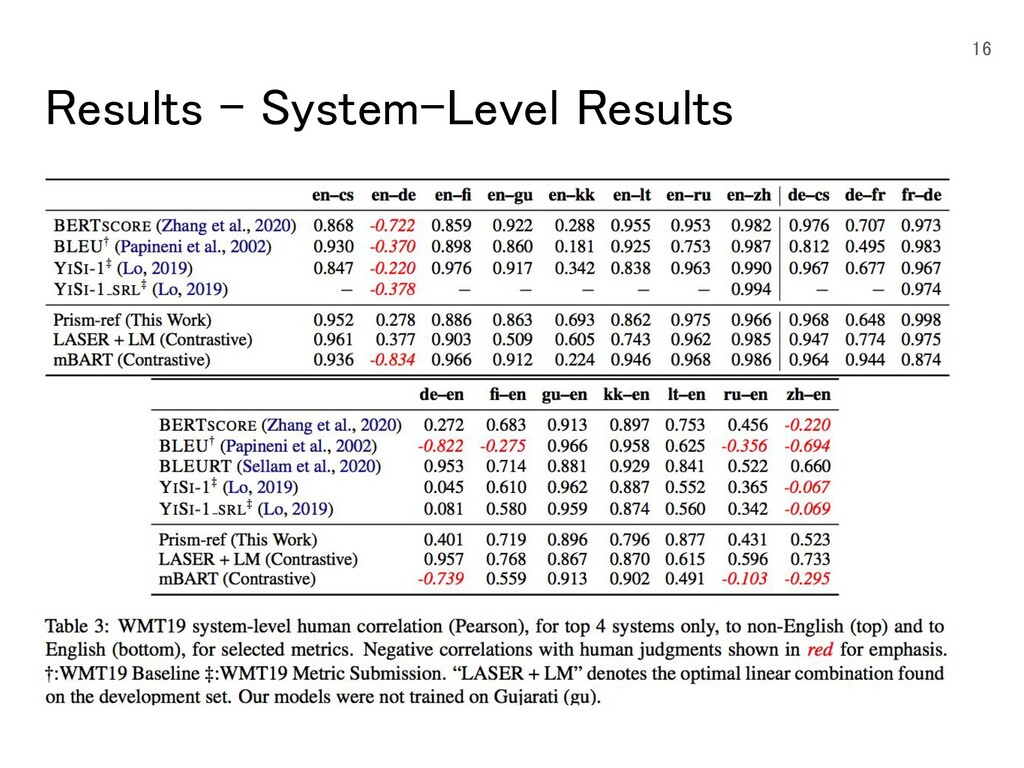{kind=link}
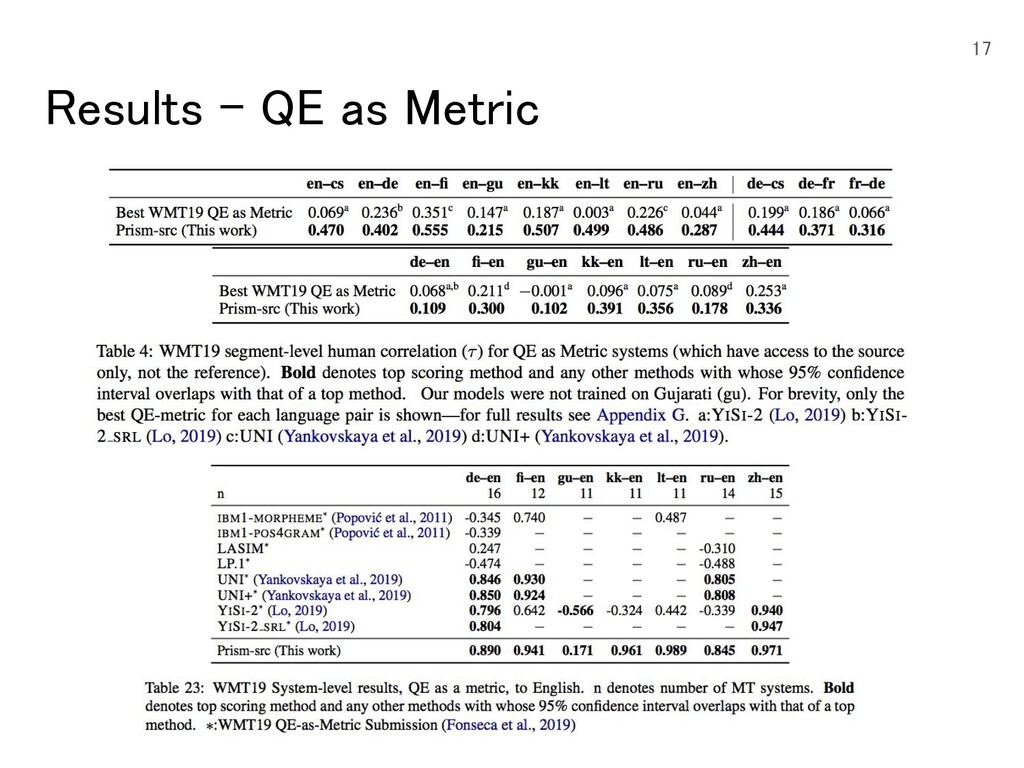{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}