BERT ◦ that can model human judgements with a few thousand possibly biased training examples • A key aspect of BLEURT is a novel pre-training scheme ◦ that uses millions of synthetic example to help model generalize • State-of-the-art results ◦ on the last three years of the WMT Metrics shared task ◦ and WebNLG Competition dataset • BLEURT is superior to vanilla BERT-based approach ◦ even when training data is scarce and out-of-distribution
measure the surface similarity b/w the reference and candidate. ◦ correlate poorly with human judgment • Metrics based on learned components ◦ High correlation with human judgment ◦ Fully learned metrics (BEER, RUSE, ESIM) ▪ are trained ent-to-end, and rely on handcrafted features and/or learned embeddings ▪ offers gread expressivity ◦ Hybrid metrics (YiSi, BERTscore) ▪ combine trained elements, e.g., contextual embeddings, with handwritten logic, e.g., as token alignment rules ▪ offers robustness
to take full advantage of available ratings data for training ◦ and be robust to distribution drifts • Insight is ◦ possible to combine expressivity and robustness ◦ by pre-training a metric on large amounts of synthetic data, before fine-tuning • To this end, Wepropose BLEURT ◦ Bilingual Evaluation Understudy with Representations from Transformers • A key ingredient of BLEURT is pre-training scheme ◦ , which uses random perturbations of Wikipedia sentences augmented with a diverse set of lexical and sentence-level signals
fine-tuning. ◦ Generate a large number of synthetic ref-cand pairs. ◦ Train BERT on several lexical- and semantic-level supervision signals with a multi-task loss. • Optimize pre-training scheme for generality with 1. The set of reference sentences should be large and diverse. a. to cope with a wide range of NLG domains and tasks. 2. The sentence pairs should contain wide variety of lexical, syntactic, and semantic dissimilarities. a. to anticipate all variations that an NLG system may produce. 3. The pre-training objectives should effectively capture those phenomena a. so that BLEURT can lean to identify them.
◦ by randomly perturbing 1.8 million segments z from WIkipedia ◦ Obtain about 6.5 million perturbations z~ • Three techniques: ◦ Mask filling with BERT ▪ Inserting masks at random positions and fill them with the language model. ▪ Introduce lexical alterations while maintaining the fluency ◦ Backtranskation ▪ to create variants of the reference sentence that preserves semantics ◦ Dropping words
Backtranslation Likelihood ◦ computing the summation over all possible French sentences is intractable ◦ 4 pre-training signals (en-de, en-fr) in both directions. τ: pre-training signal (z, z~): ref-cand pairs |z~|: number of tokens in z ~
contradicts z~ using a classifier. ◦ using BERT fine-tuned on an entailment dataset, MNLI • Backtranslation flag ◦ Boolean that indicates whether the perturbation was generated ◦ with backtranslation or with mask-filling. Modeling • Task-lebel losses with a weighted sum. M: number of synthetic examples K: number of task γ k : weight
to quality drifts (2017) • WebNLG2017 Challenge Dataset ◦ Test BLEURT’s ability to adapt to different tasks • Ablation ◦ Measure the contribution of each pre-training task • Model ◦ BLEURT are trained in three steps i. regular BERT pre-training ii. pretraining on synthetic data iii. fine-tuning on task-specific rating ◦ Batch size: 32, lr: 1e-5, ◦ pre-training steps: 0.8M, fine-tuning steps: 40k ◦ γ k : set with grid search
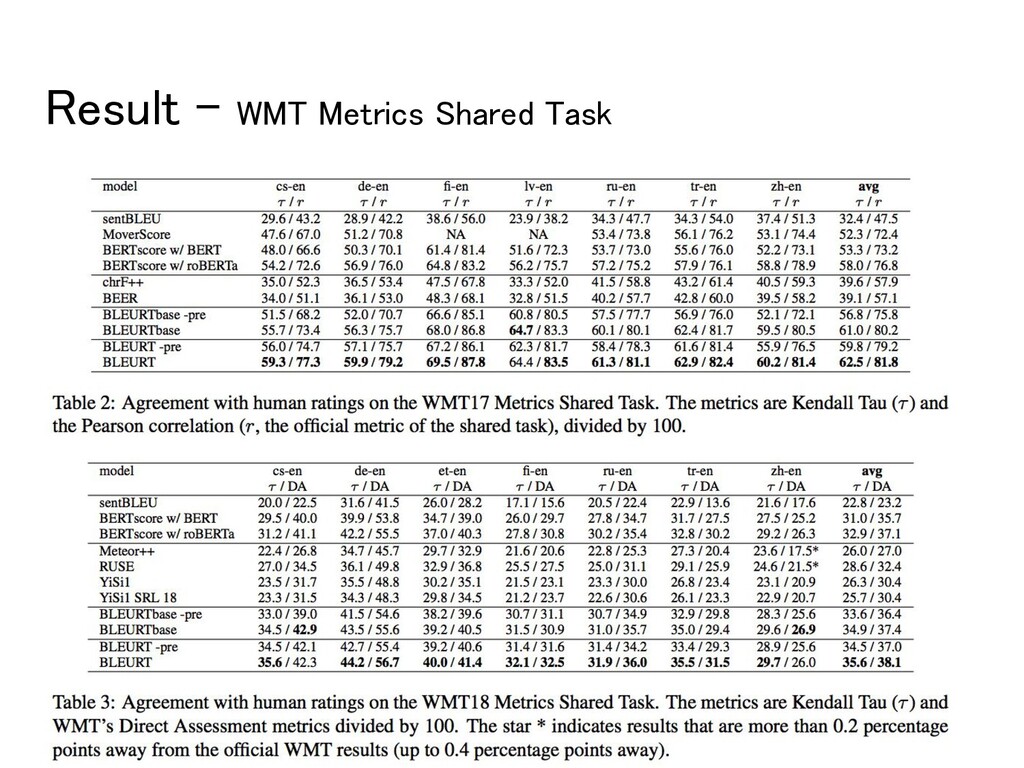
◦ WMT2017-2019 (to-English) • Metrics ◦ Evaluate agreement b/w the metrics and the human ratings. ◦ Kndall’s Tau τ (all year), Pearson’s correlation (2017), DARR (2018, 2019) • Models ◦ BLEURT, BLEURTbase ▪ Based on BERT-large and BERT-base ◦ BLEURT-pre, BLUERTbase-pre ▪ Skip the pre-training phase and fine-tune directly on the WMT ratings.
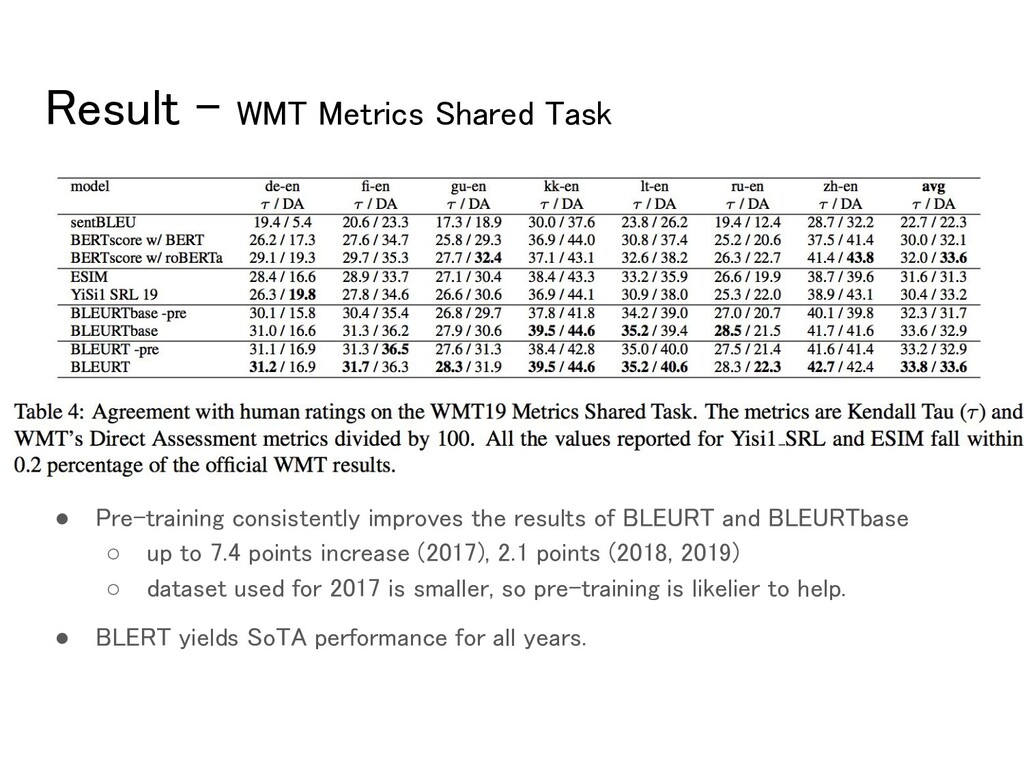
improves the results of BLEURT and BLEURTbase ◦ up to 7.4 points increase (2017), 2.1 points (2018, 2019) ◦ dataset used for 2017 is smaller, so pre-training is likelier to help. • BLERT yields SoTA performance for all years.
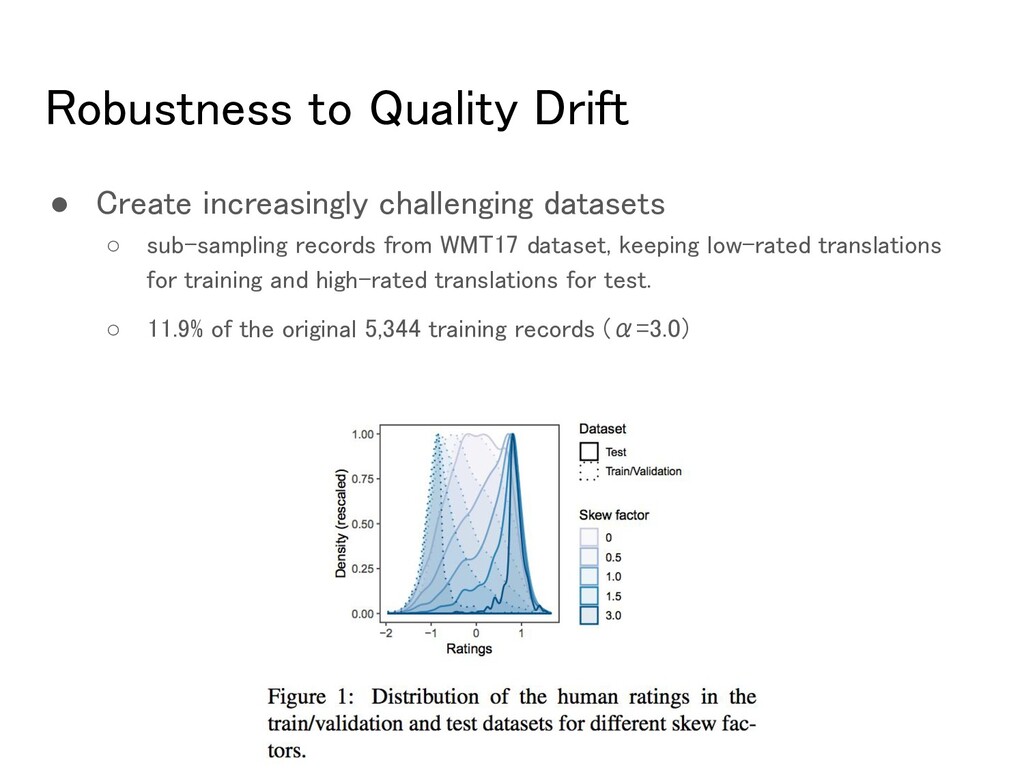
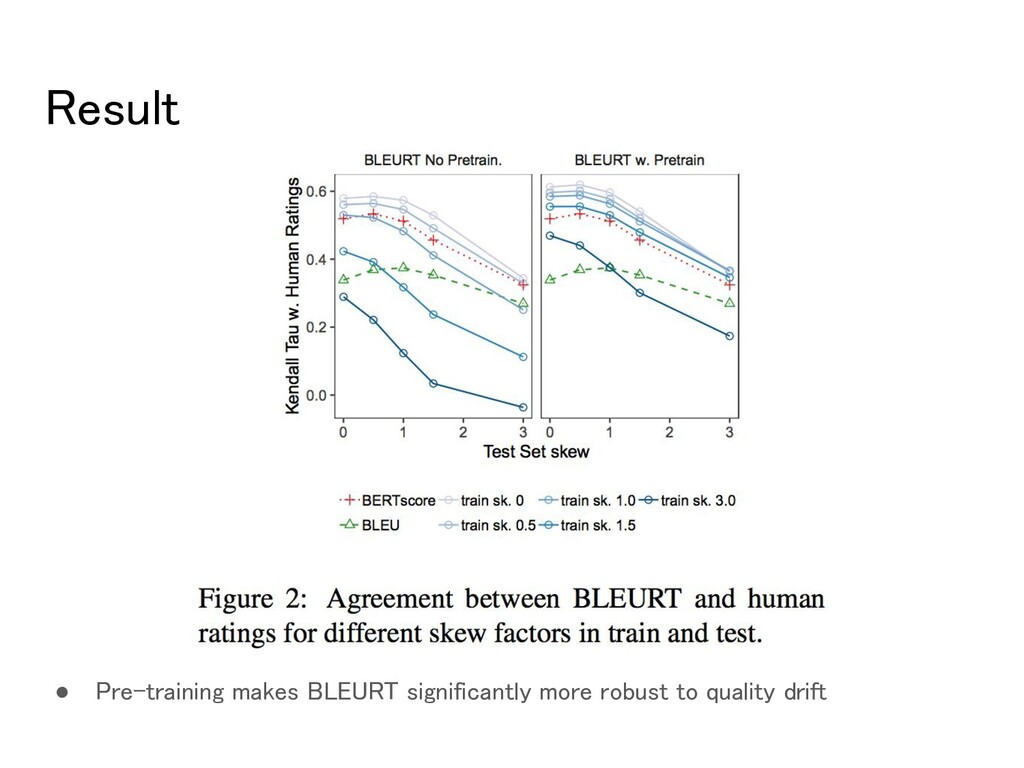
sub-sampling records from WMT17 dataset, keeping low-rated translations for training and high-rated translations for test. ◦ 11.9% of the original 5,344 training records (α=3.0)
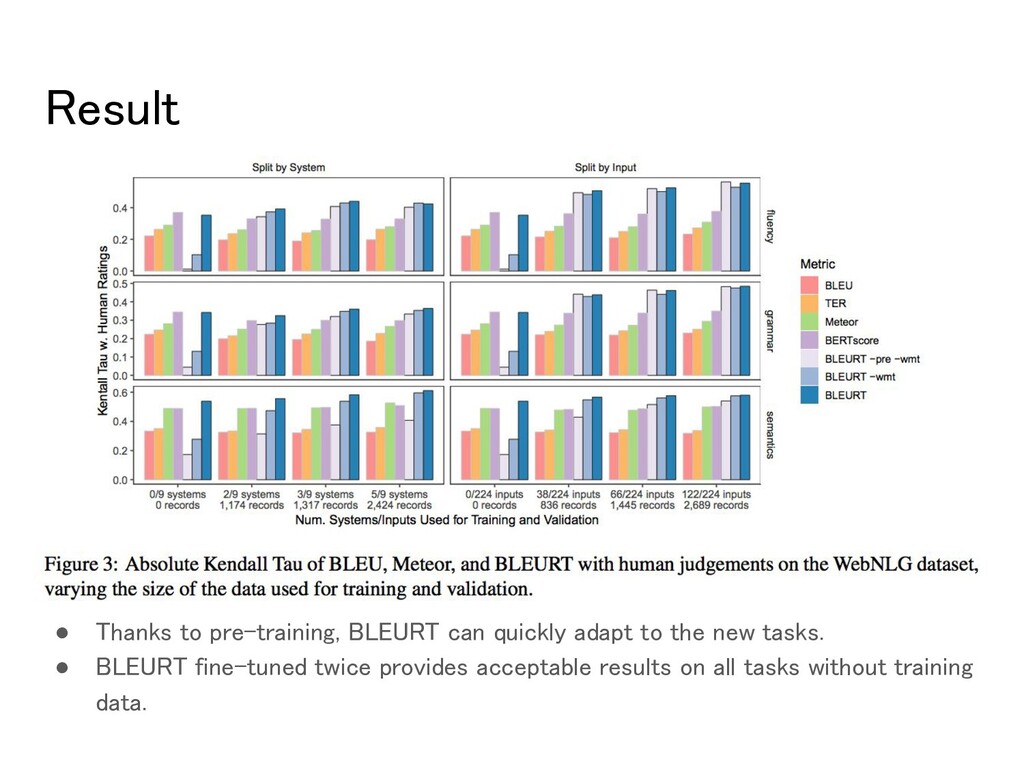
to new tasks with limited training data. • Dataset ◦ The WebNLG challenge benchmarks ◦ 4,677 sentence pairs with 1 to 3 reference ◦ evaluated on 3 aspects: semantics, grammar, and fluency • Systems ◦ BLEURT -pre -wmt: WebNLG ◦ BLEURT -wmt: synthetic data → WebNLG ◦ BLEURT: synthetic data → WMT → WebNLG e.g.
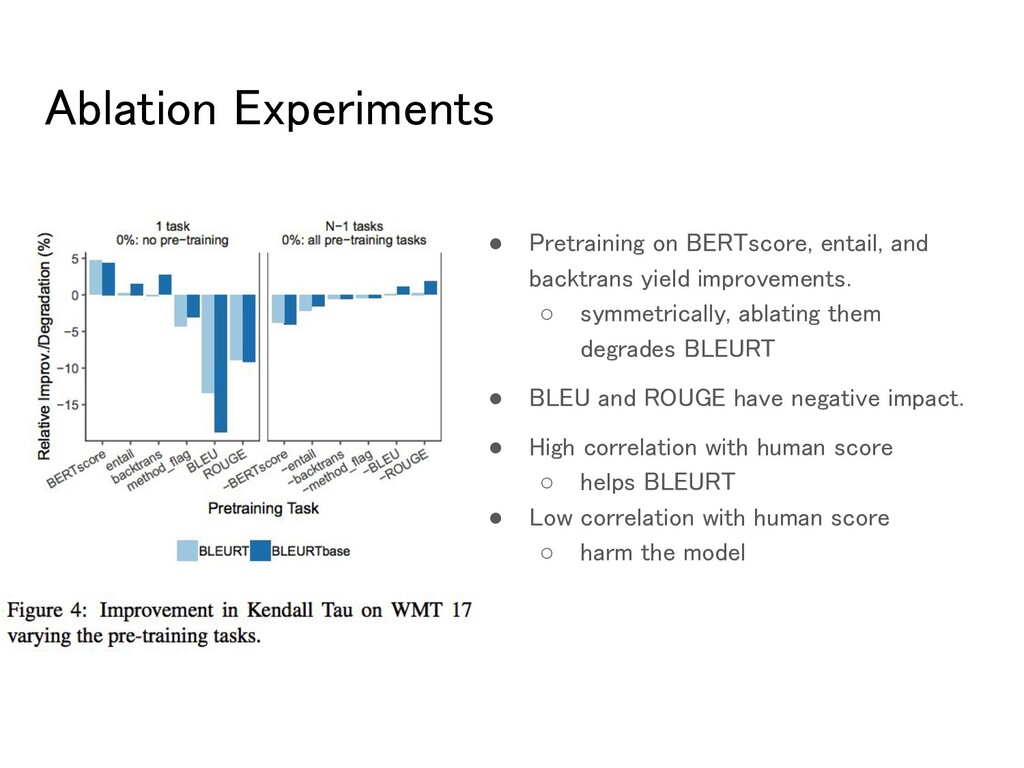
improvements. ◦ symmetrically, ablating them degrades BLEURT • BLEU and ROUGE have negative impact. • High correlation with human score ◦ helps BLEURT • Low correlation with human score ◦ harm the model
English • Novel pre-train scheme ◦ 1. regular BERT pre-training ◦ 2. pre-training on synthetic data ◦ 3. fine-tuning on task-specific rating • Experiments ◦ SoTA results on WMT and WebNLG Challenge dataset ◦ robust both domain and quality drifts
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}