Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Multi-Reference Training with Pseudo-References...
Search
ryoma yoshimura
January 23, 2019
Research
250
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation
研究室のEMNLP読み会の発表資料です。
ryoma yoshimura
January 23, 2019
More Decks by ryoma yoshimura
See All by ryoma yoshimura
TransQuest: Translation Quality Estimation with Cross-lingual Transformers
kokeman
0
290
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing
kokeman
0
65
BLEURT: Learning Robust Metrics for Text Generation
kokeman
0
270
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
kokeman
1
860
Courteously Yours: Inducing courteous behavior in Customer Care responses using Reinforced Pointer Generator Network
kokeman
0
170
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
kokeman
0
180
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
kokeman
0
130
タスクとデータセット紹介 GLUE, SuperGLUE
kokeman
0
1.1k
Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement Learning
kokeman
0
85
Other Decks in Research
See All in Research
Language and AI
ayaniwa
0
170
進学校の生徒にはア行の苗字が多いのか
ozekinote
0
480
データセンター事業者を取り巻く近年の状況とその中での研究開発動向、テストベッドへの貢献の可能性
kikuzo
1
270
業界横断 副業コンプライアンス調査 三者(副業者・本業先・発注者)におけるトラブル認知ギャップの構造分析
fkske
0
1.3k
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
「AIとWhyを深堀る」をAIと深堀る
iflection
0
530
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
300
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
COMETAを用いたデータ民主化運動の歴史
sazimai
0
120
英語教育 “研究” のあり方:学術知とアウトリーチの緊張関係
terasawat
1
1k
Harness Engineering and Al Agent
kzinmr
3
1.8k
LINEヤフー データサイエンス Meetup「三井物産コモディティ予測チャレンジ」の舞台裏-AlpacaTechパート
gamella
1
610
Featured
See All Featured
Side Projects
sachag
455
43k
Designing Experiences People Love
moore
143
24k
Learning to Love Humans: Emotional Interface Design
aarron
275
41k
StorybookのUI Testing Handbookを読んだ
zakiyama
31
6.8k
No one is an island. Learnings from fostering a developers community.
thoeni
21
3.8k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
For a Future-Friendly Web
brad_frost
183
10k
Building a A Zero-Code AI SEO Workflow
portentint
PRO
0
640
First, design no harm
axbom
PRO
2
1.2k
Navigating Algorithm Shifts & AI Overviews - #SMXNext
aleyda
1
1.5k
XXLCSS - How to scale CSS and keep your sanity
sugarenia
249
1.3M
Rebuilding a faster, lazier Slack
samanthasiow
85
9.6k
Transcript
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation
Renji Zheng, Mingbo Ma, Liang Huang EMNLP2018 研究室EMNLP読み会 紹介者 吉村
概要 • 複数のリファレンスでモデルを学習 ◦ テキスト生成の正解は1つではないので複数あったほうがいい ◦ 複数のリファレンスがあるデータセットを使用 • 複数のリファレンスから lattice
を作ってさらに多くの擬似リファ レンスを作成 ◦ 4~5個のリファレンスでは潜在的なリファレンスをカバーできない
Main Contributions • 機械翻訳と画像キャプションにおいてマルチリファレンスでの 学習法を3つ調査 • 複数の参照訳を lattice にするための新しいネットワークベー スの複数の系列アラインメントモデルを提案
• 擬似リファレンスでを用いた学習でMTでBLEUが+1.5、画像 キャプションでBLEUが+3.1、CIDErで+11.7
複数のリファレンスでの学習法 • 学習データを変えるだけでモデルは変更しなくていい • 複数のリファレンスがあるデータセットをシングルリファレンス のデータセットに変換 • 作り方はSample One、Uniform、Shuffleの3つ
複数のリファレンスでの学習法 • Sample One ◦ 各エポックでランダムに1つリファレンスを決める • Uniform ◦ 複数の各リファレンスに同じ入力をつける
• Shuffle ◦ Uniformで各エポックごとにシャッフルする x i : source y i : reference D : multiple reference dataset D’ : single reference dataset ※ D’ は順序集合
擬似リファレンスの作り方 • 複数のリファレンスから lattice を構築してそれをたどることで 擬似リファレンスを生成 ◦ 似た単語をマージする ◦ 元のリファレンスとBLEUを測って高いものを採用
• Hard alignと Soft align がある
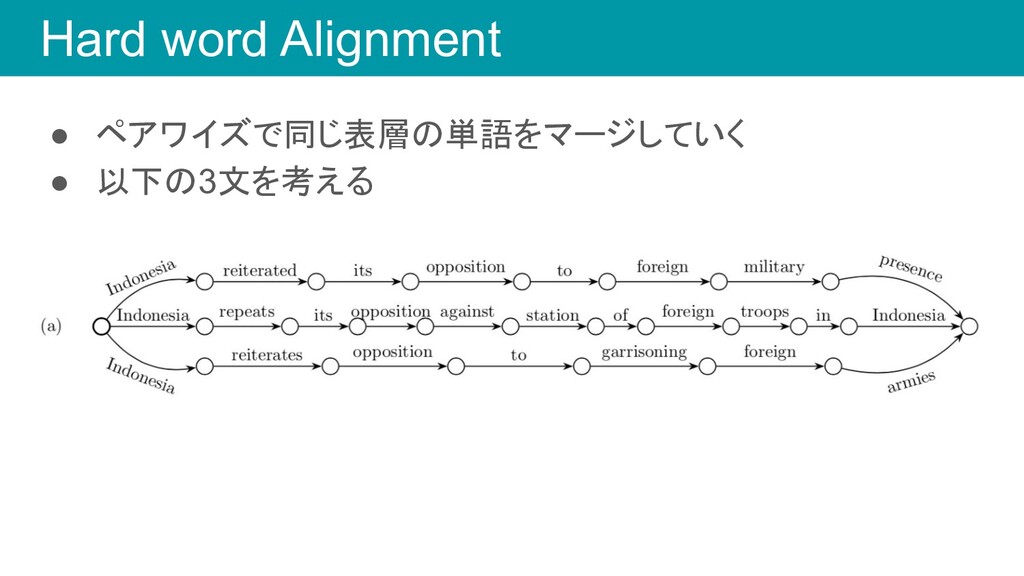
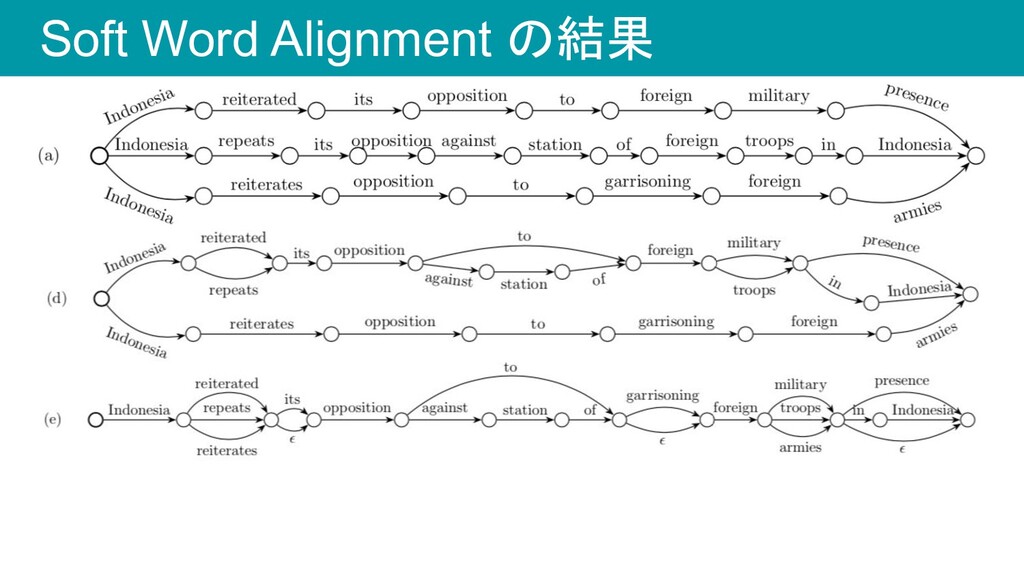
Hard word Alignment • ペアワイズで同じ表層の単語をマージしていく • 以下の3文を考える
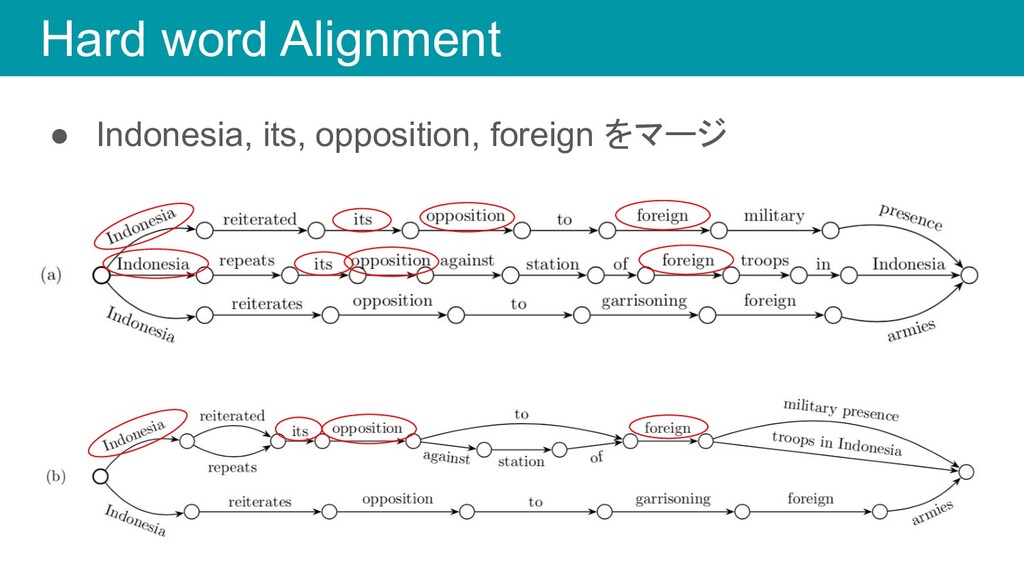
Hard word Alignment • Indonesia, its, opposition, foreign をマージ
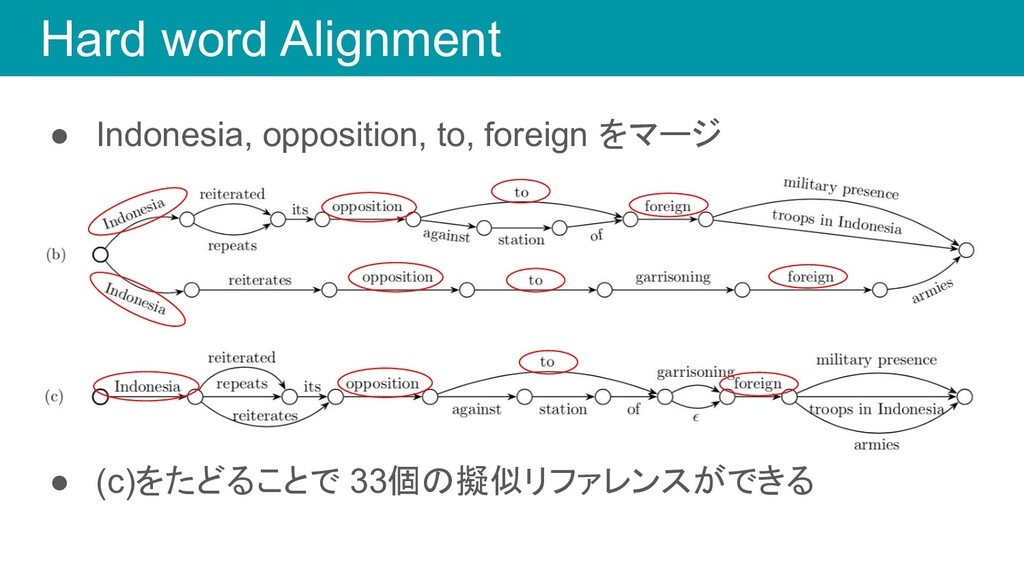
Hard word Alignment • Indonesia, opposition, to, foreign をマージ •
(c)をたどることで 33個の擬似リファレンスができる
Hard Word Alignment の問題点 • 類義語を考慮できない ◦ 例での reiterated, repeats,
reiterates • 同一の単語は他の文では異なる意味をもつ可能性がある ◦ toなど(不定詞、前置詞)
Soft Word Alignment • 文y i と文y j に対して semantic
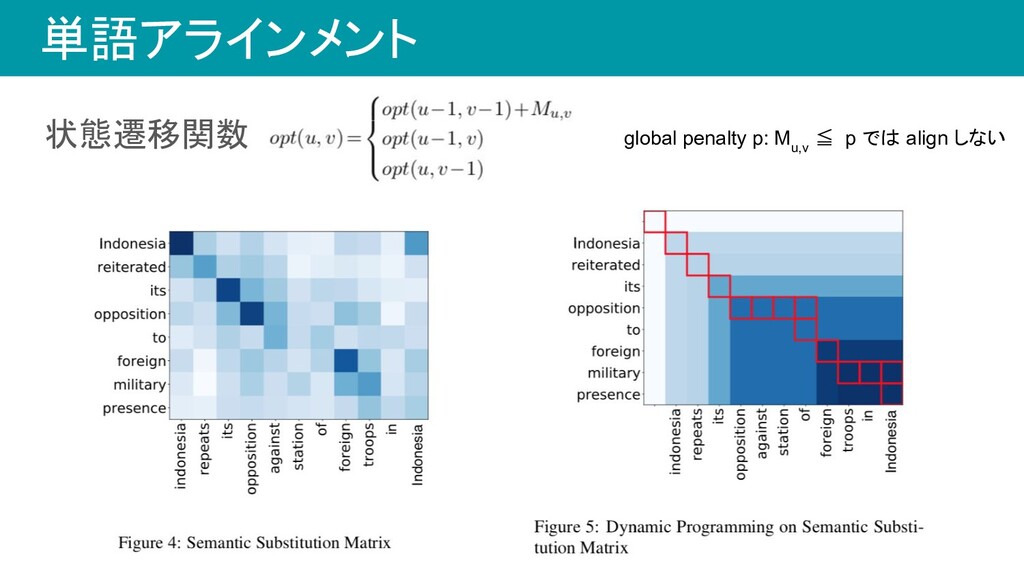
substitution matrix を作る • 各セルM u,v の値は単語y i,u と単語y j,v の類似度スコア • bidirectional LMの隠れベクトルのcos類似度 • Mを使ってアラインメントする ◦ M 0,0 からM |yi|,|yj| までの最適パスを動的計画法で求める
単語アラインメント 状態遷移関数 global penalty p: M u,v ≦ p では
align しない
Soft Word Alignment の結果
実験(MT) • NIST(2002-2005, 2006, 2008) zh-en ◦ single ref 1Mペア
(pre-train) 4 ref 5974ペア (train, valid, test) • global penalty 0.9 ◦ 100文集まるまで global penalty を減らしていく BLEUは上位50件のみ • bi-LMはpre-training dataとtraining dataで学習, word enmmbeding は Glove • encoderとdecoderは2層のbi-LSTMでBPEを使用 • pre-train: batch size 64, beam size 15, dropout 0.3 • multi-reference-train: batch size 100, 200, 400のベスト
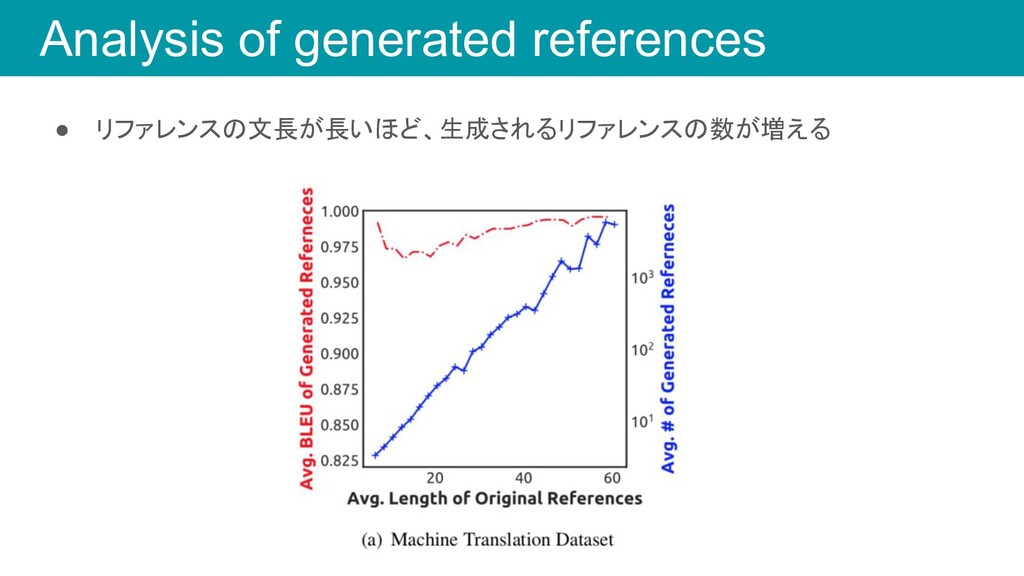
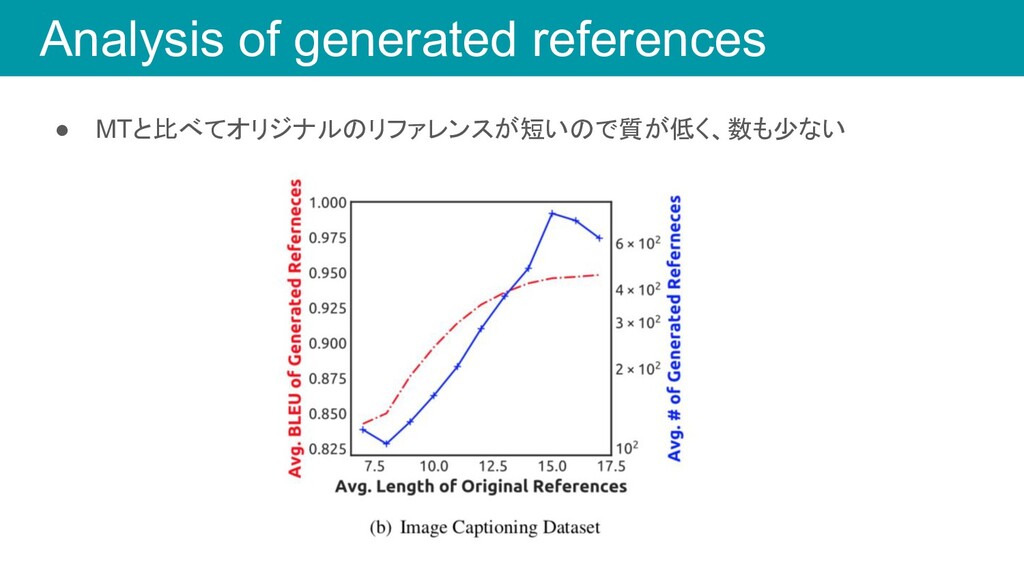
Analysis of generated references • リファレンスの文長が長いほど、生成されるリファレンスの数が増える
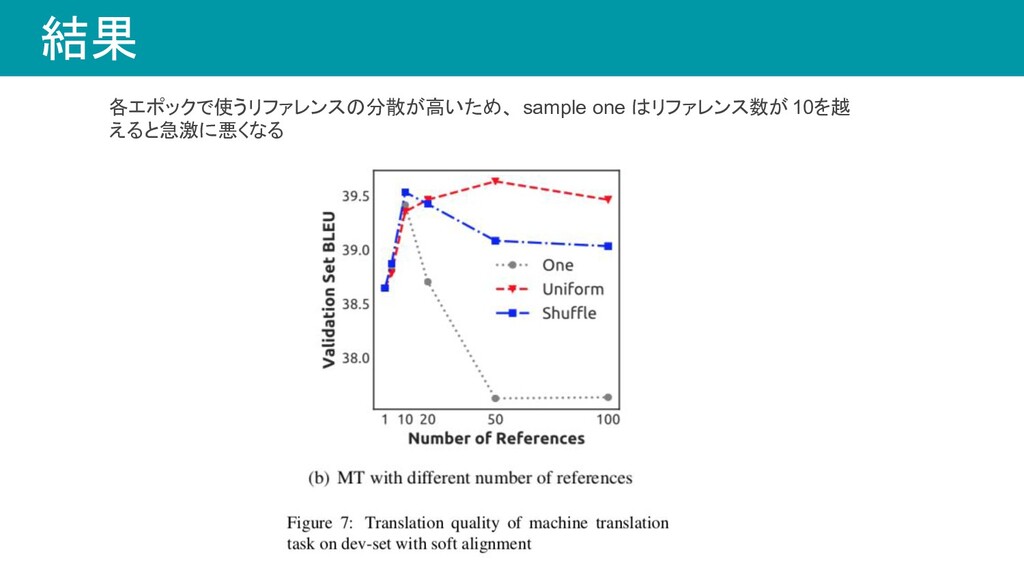
結果
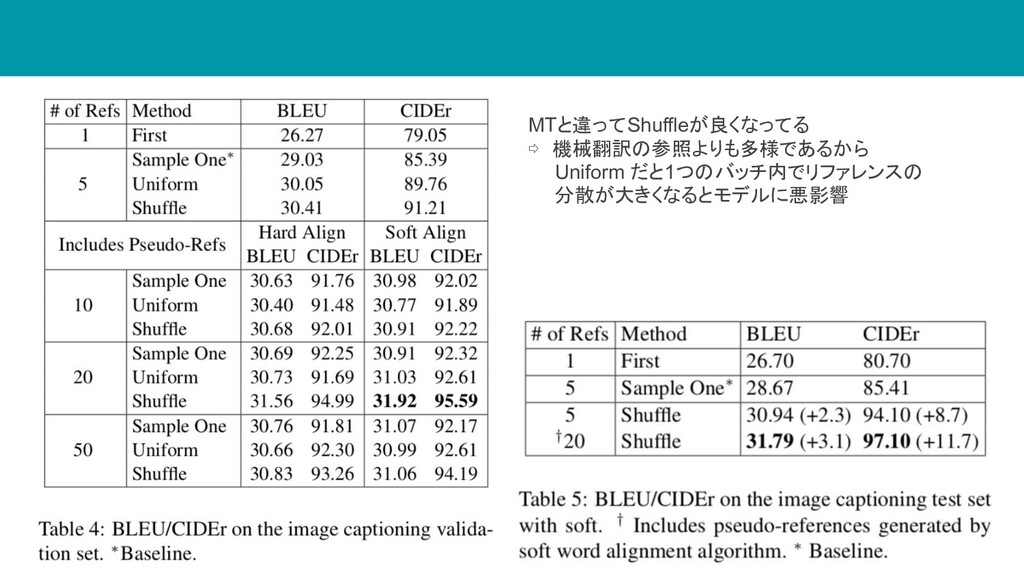
結果 各エポックで使うリファレンスの分散が高いため、 sample one はリファレンス数が10を越 えると急激に悪くなる
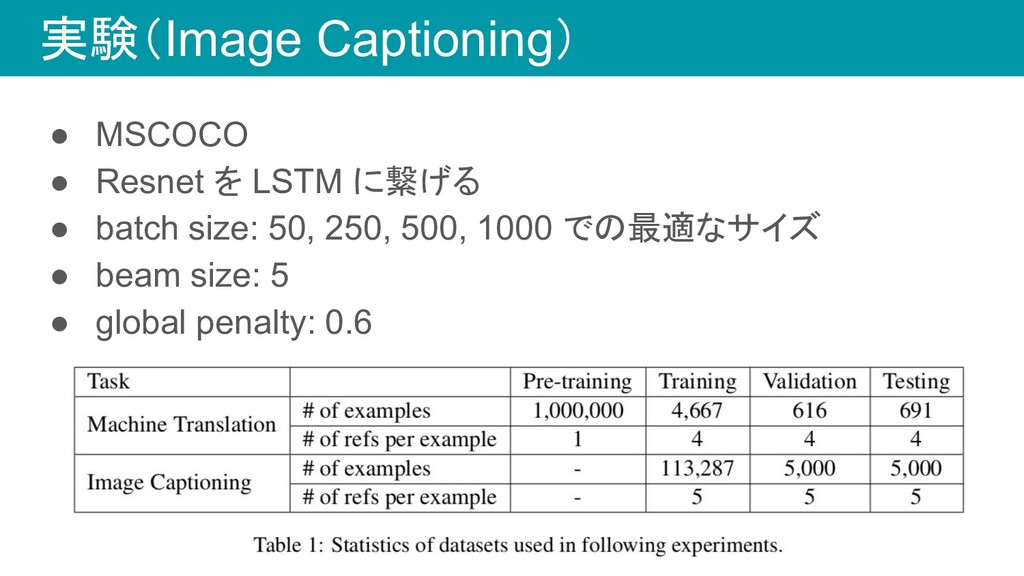
実験(Image Captioning) • MSCOCO • Resnet を LSTM に繋げる •
batch size: 50, 250, 500, 1000 での最適なサイズ • beam size: 5 • global penalty: 0.6
Analysis of generated references • MTと比べてオリジナルのリファレンスが短いので質が低く、数も少ない
MTと違ってShuffleが良くなってる ⇨ 機械翻訳の参照よりも多様であるから Uniform だと1つのバッチ内でリファレンスの 分散が大きくなるとモデルに悪影響
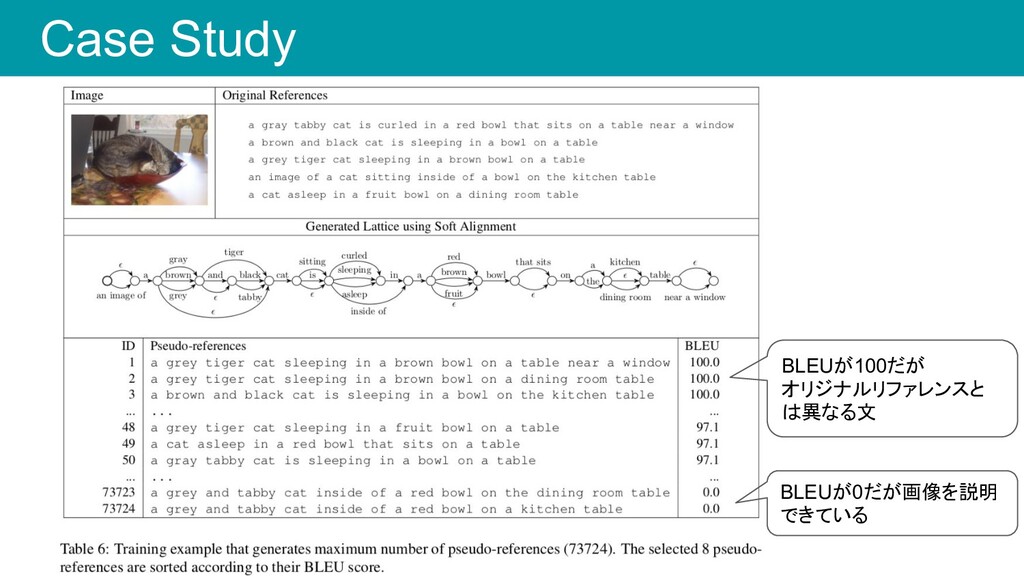
Case Study BLEUが100だが オリジナルリファレンスと は異なる文 BLEUが0だが画像を説明 できている
Conclusion • マルチリファレンスでの学習方法を調査 • 既存のマルチリファレンスから擬似リファレンスを生成する手法を提案 • MTと画像キャプションの両タスクでベースラインを上回る
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}