Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reinforcement Learning Based Text Style Transfe...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ryoma yoshimura
July 25, 2019
Research
130
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
研究室のNAACL論文読み会での発表資料です。
ryoma yoshimura
July 25, 2019
More Decks by ryoma yoshimura
See All by ryoma yoshimura
TransQuest: Translation Quality Estimation with Cross-lingual Transformers
kokeman
0
290
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing
kokeman
0
65
BLEURT: Learning Robust Metrics for Text Generation
kokeman
0
270
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
kokeman
1
860
Courteously Yours: Inducing courteous behavior in Customer Care responses using Reinforced Pointer Generator Network
kokeman
0
170
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
kokeman
0
180
タスクとデータセット紹介 GLUE, SuperGLUE
kokeman
0
1.1k
Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement Learning
kokeman
0
85
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation
kokeman
0
250
Other Decks in Research
See All in Research
第64回CV・PRML勉強会 論文紹介:Linguistic Priors for Visual Decoupling: Towards Symmetric Vision-Brain Alignment
sokikatayama
0
140
論文紹介:HalluCitation Matters
wasyro
0
130
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4.1k
NII S. Koyama's Lab Research Overview AY2026
skoyamalab
0
430
はじまりの クエスチョンブック —余暇と豊かさにあふれた社会とは?
culturaltransition
PRO
0
570
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
AY 2026 Guide to Academic Writing Using Generative AI - Workshop
ks91
PRO
0
140
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
160
非試合日の野球場を楽しむためのARホームランボールキャッチ体験システムの開発 / EC79-miyazaki
yumulab
0
310
第12回人と環境にやさしい交通をめざす全国大会/熊本都市圏「車1割削減、渋滞半減、公共交通2倍」をめざして
trafficbrain
0
140
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
170
RS-Agent: Automating Remote Sensing Tasks through Intelligent Agent
satai
3
390
Featured
See All Featured
Skip the Path - Find Your Career Trail
mkilby
1
170
Being A Developer After 40
akosma
91
590k
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
New Earth Scene 8
popppiees
3
2.4k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
The Curious Case for Waylosing
cassininazir
1
440
Exploring the relationship between traditional SERPs and Gen AI search
raygrieselhuber
PRO
2
4.2k
Max Prin - Stacking Signals: How International SEO Comes Together (And Falls Apart)
techseoconnect
PRO
0
320
A better future with KSS
kneath
240
18k
Sam Torres - BigQuery for SEOs
techseoconnect
PRO
0
440
DevOps and Value Stream Thinking: Enabling flow, efficiency and business value
helenjbeal
1
260
WENDY [Excerpt]
tessaabrams
11
38k
Transcript
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
Hongyu Gong, Suma Bhat, Lingfei Wu, JinJun Xiong, Wen-mei Hwu NAACL2019読み会 紹介者: 吉村
Abstract • パラレルコーパスをつかわないテキストスタイル変換 • スタイル、意味、流暢性の評価器を報酬として強化学習 • positive-negative, informal-formal の変換タスクで SOTA
• 人手評価でも効果的であることがわかった
Introduction • パラレルコーパスでのスタイル変換は成功しているがパラレル コーパスはいつでも利用できるわけではない • 従来手法 ◦ 意味をエンコードしてスタイル情報と組み合わせてスタイ ル変換する ◦
パラメータで微分可能な損失関数に制限されている ◦ 意味とスタイルのみを学習、評価している ▪ 流暢性などの他の重要な側面は見ていない • 提案手法 ◦ パラレルコーパスを使わないスタイル変換を行う RL を用 いた学習システムを提案する ◦ 報酬にスタイルの強さ、意味の保持、流暢性を使用
Contributions • テキストスタイル変換のための RL フレームワークを提案複数 の評価指標を報酬にして学習を行う • パラレルコーパスがない問題に対処している • 意味の保持と変換の強さで
SOTA
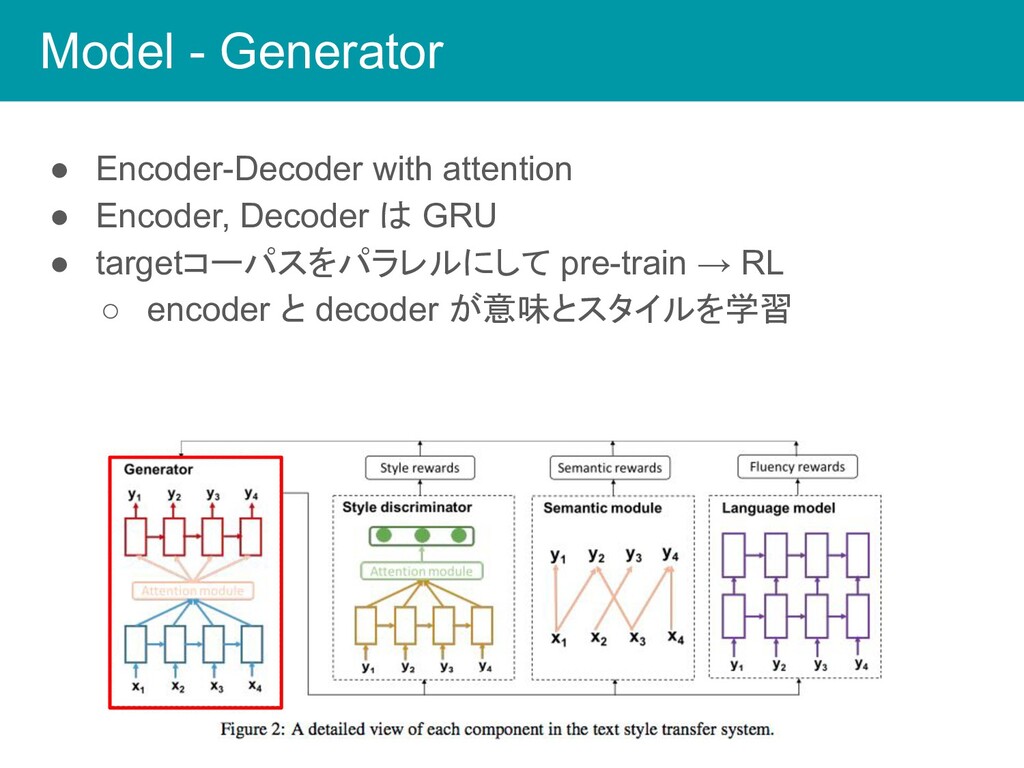
Model - Generator • Encoder-Decoder with attention • Encoder, Decoder
は GRU • targetコーパスをパラレルにして pre-train → RL ◦ encoder と decoder が意味とスタイルを学習
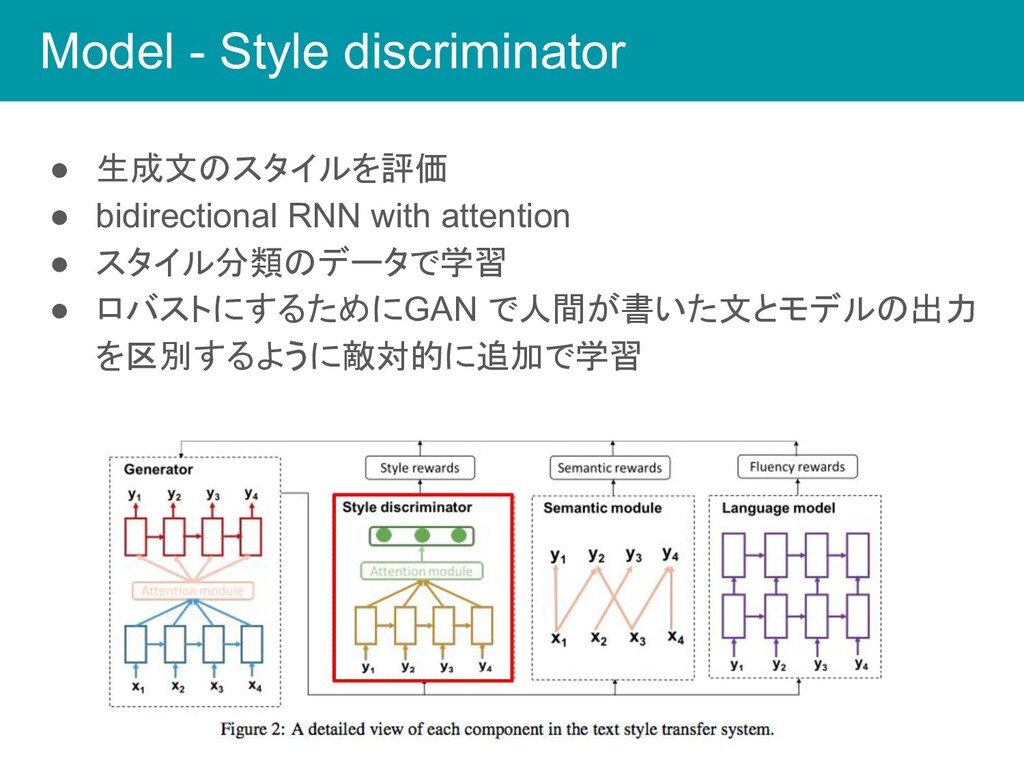
Model - Style discriminator • 生成文のスタイルを評価 • bidirectional RNN with
attention • スタイル分類のデータで学習 • ロバストにするためにGAN で人間が書いた文とモデルの出力 を区別するように敵対的に追加で学習
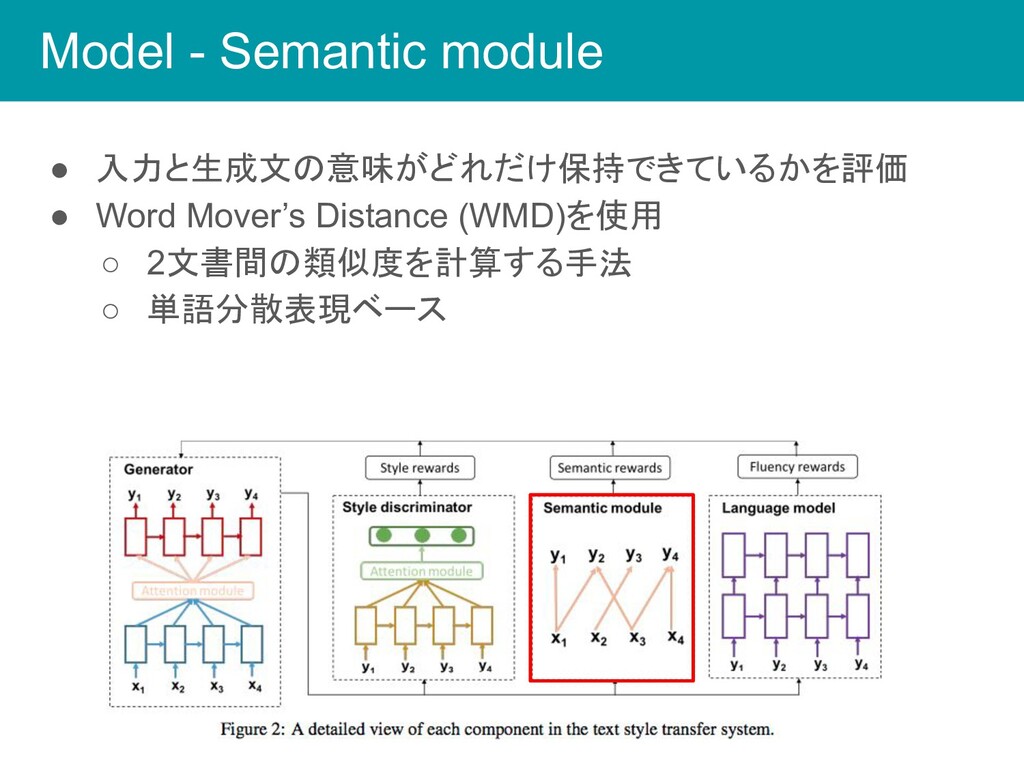
Model - Semantic module • 入力と生成文の意味がどれだけ保持できているかを評価 • Word Mover’s Distance
(WMD)を使用 ◦ 2文書間の類似度を計算する手法 ◦ 単語分散表現ベース
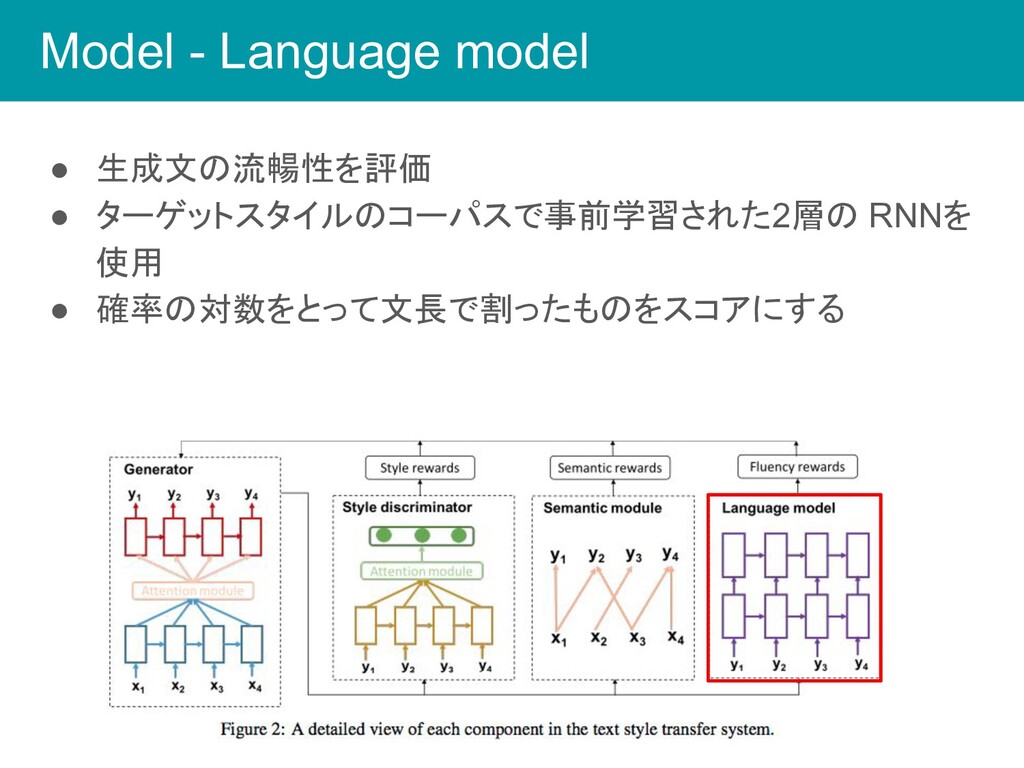
Model - Language model • 生成文の流暢性を評価 • ターゲットスタイルのコーパスで事前学習された2層の RNNを 使用
• 確率の対数をとって文長で割ったものをスコアにする
• 与えられた環境における価値を最大化するようにエージェント を学習 • 方策 π : p(a|s) ◦ 状態
s でどう行動するかを定めた確率分布 • 方策ベースと価値ベース ◦ 価値ベース: 価値関数 Q(s, a) を学習 ◦ 方策ベース: 方策を学習し、累積報酬和を最大化 Reinforcement Learning reward Enviroment Agent action state
Reinforcement Learning REINFROCE: 方策ベースのアルゴリズム G: generator T’: maximum length
of the decoder V: target vocabulary γ : (0 < γ < 1) discounting factor 割引報酬和 報酬の期待値 State: Action:
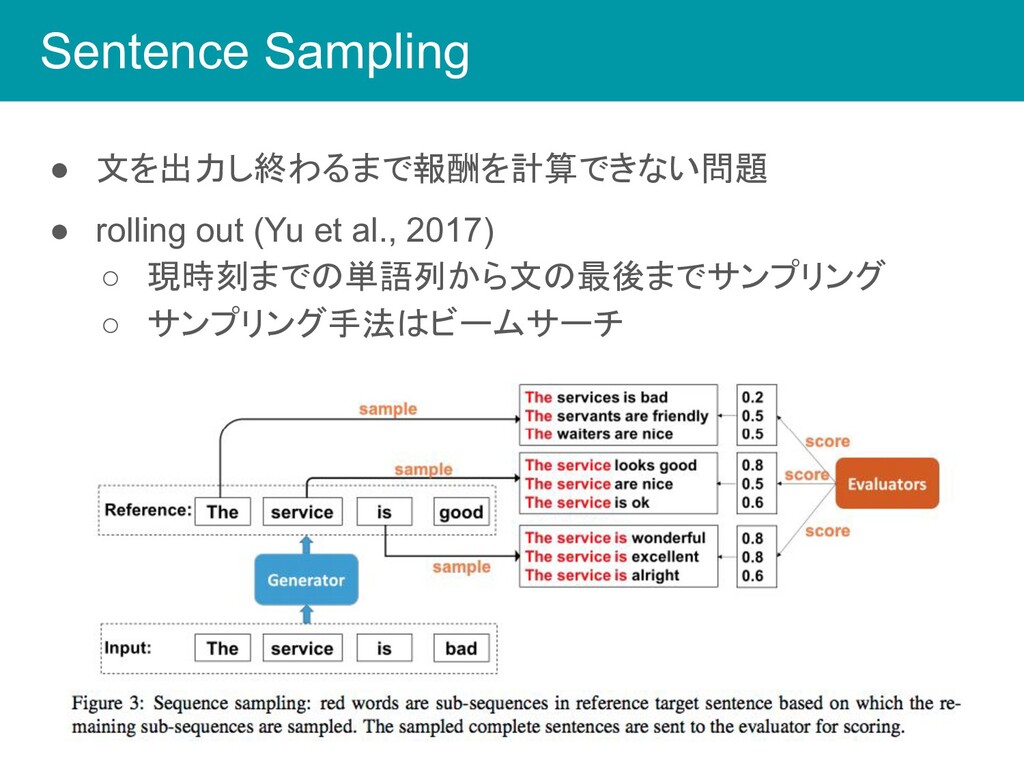
Sentence Sampling • 文を出力し終わるまで報酬を計算できない問題 • rolling out (Yu et al.,
2017) ◦ 現時刻までの単語列から文の最後までサンプリング ◦ サンプリング手法はビームサーチ •
Reward 3つの評価器の加重平均 実験では α = 1.0, β = 0.5, η
= 0.5 に設定
Experiment • タスク ◦ positive - negative sentiment (ST) ◦
formal - informal (FT) • データセット ◦ ST: Yelp website (restaurant reviews) ◦ FT: Grammarly’s Yahoo Answer Fomalyty Corpus ▪ family, relationships のデータを使用
Experiment • Model settings ◦ embeddings size 50 ▪ English
WikiCorpus で学習して train で tune する ◦ beam size 8 in RL and inference. • ベースライン: 2つの unsupervised な SOTA モデル ◦ Cross alignment model (CA) [Shen et al., 2017] ▪ GAN ベースの手法, cross alignment AE を提案 ◦ Multi-decoder seq2deq model (MDS) [Fu et al., 2018] ▪ GAN ベース、encoder で意味を学習してスタイル固有 の decoder で変換させる
Experiment - Automatic Evaluation • Content preservation ◦ S sem
[Fu et al., 2018] ▪ 単語分散表現ベースの手法 • Transfer strength ◦ スタイル変換のコーパスで学習された LSTM ベースの分 類器 [Fu et al., 2018] • Fluency ◦ perplexity • Overall score ◦
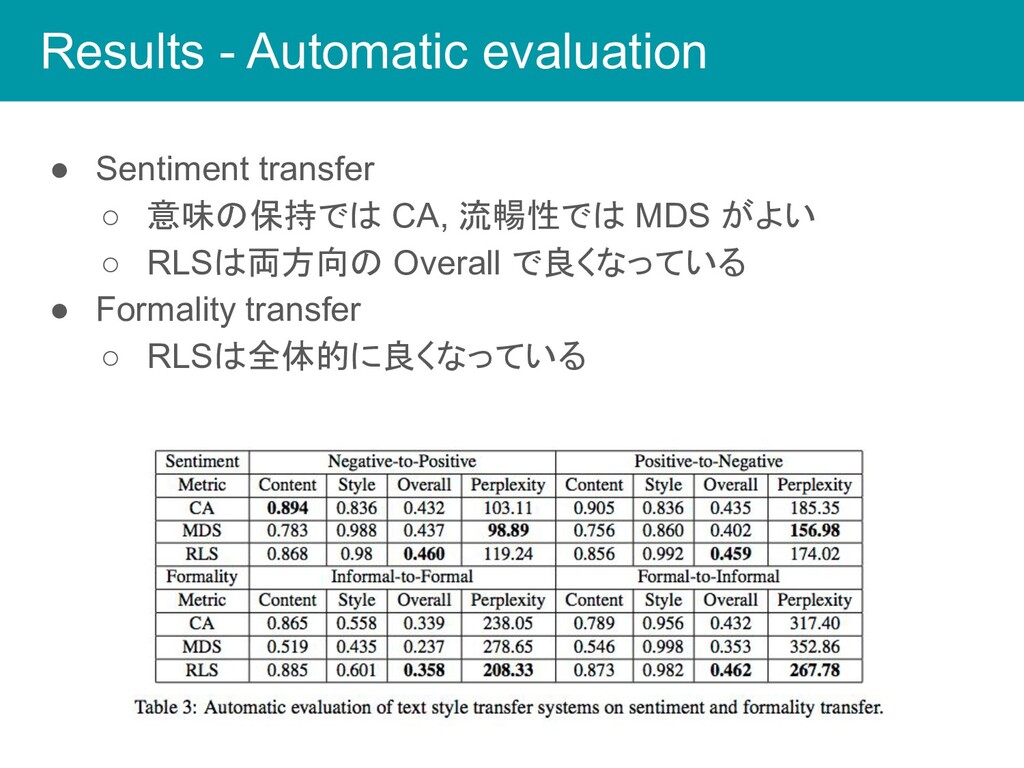
Results - Automatic evaluation • Sentiment transfer ◦ 意味の保持では CA,
流暢性では MDS がよい ◦ RLSは両方向の Overall で良くなっている • Formality transfer ◦ RLSは全体的に良くなっている
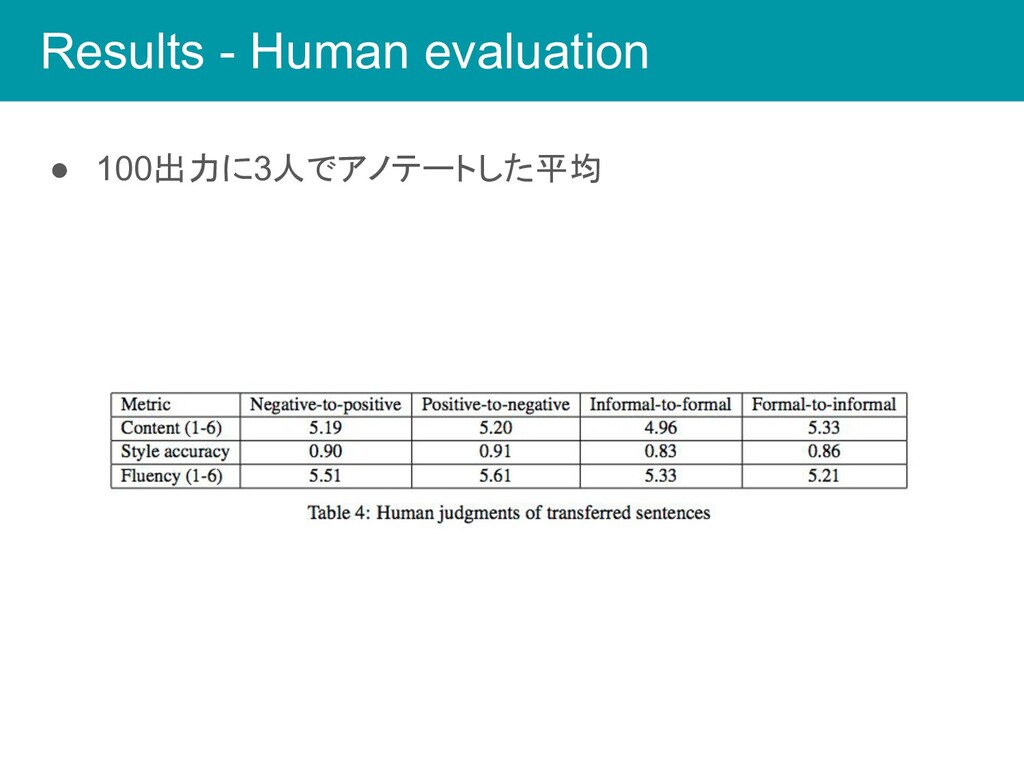
Results - Human evaluation • 100出力に3人でアノテートした平均
Example1 baseline は食品にトピックが変更されているが RLS ではフードサービスのトピックを保 持している。 CAモデルはピザについて、MDSモデルは顧客サービスについて説明してるが RLS で はチキンのトピックを保持している。
Example2 原文は修辞的な質問(質問に見せかけて意見を主張する)であり、「人々は彼らの行動 の背後にある意味をほとんど理解できない」ことを真に意味している 全てのモデルが意味をとらえられていない難しい例
Conclusions • スタイル、意味、流暢性の評価基準を組み込んだ強化学習 ベースのテキストスタイル変換システムを提案 • 2つの異なるスタイル変換タスクで自動評価および人手評価で その有用性を実証した
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}