et al., 2019) has SOTA performance on sentence-pair regression tasks. • Problem: Massive computational overhead ◦ Finding the most similar pair in a collection of 10,000 sentences requires about 65 hours with BERT. ◦ Not applicable to large-scale semantic similarity comparison, clustering, and information retrieval via semantic search. • Proposal: Sentence-BERT (SBERT) ◦ Using siamese and triplet network structures. ◦ Fine-tuning on NLI and MNLI data. • Experiment: STS task and transfer learning task. ◦ Outperforms other SOTA sentence embeddings methods. ◦ 65 hours with BERT but 5 seconds with SBERT. ◦ BERT embeddings is unsuitable to be used with common similarity measures like cos-similarity.
BiLSTM network with max-pooling over the output. ◦ SNLI dataset and the MultiGenre NLI dataset. ◦ Outperforms unsupervised method like SkipThought. • Universal Sentence Encoder (Cer et al., 2018) ◦ transformer network and augments unsupervised learning with training on SNLI. • BERT (Dvlin et al., 2018) ◦ Researchers have started to input individual sentences into BERT and to derive fixedsize sentence embeddings. ◦ Commonly used approach is to average the BERT output layer or by using the output of the first token (the [CLS] token). ◦ There is so far no evaluation if these methods lead to useful sentence embeddings.
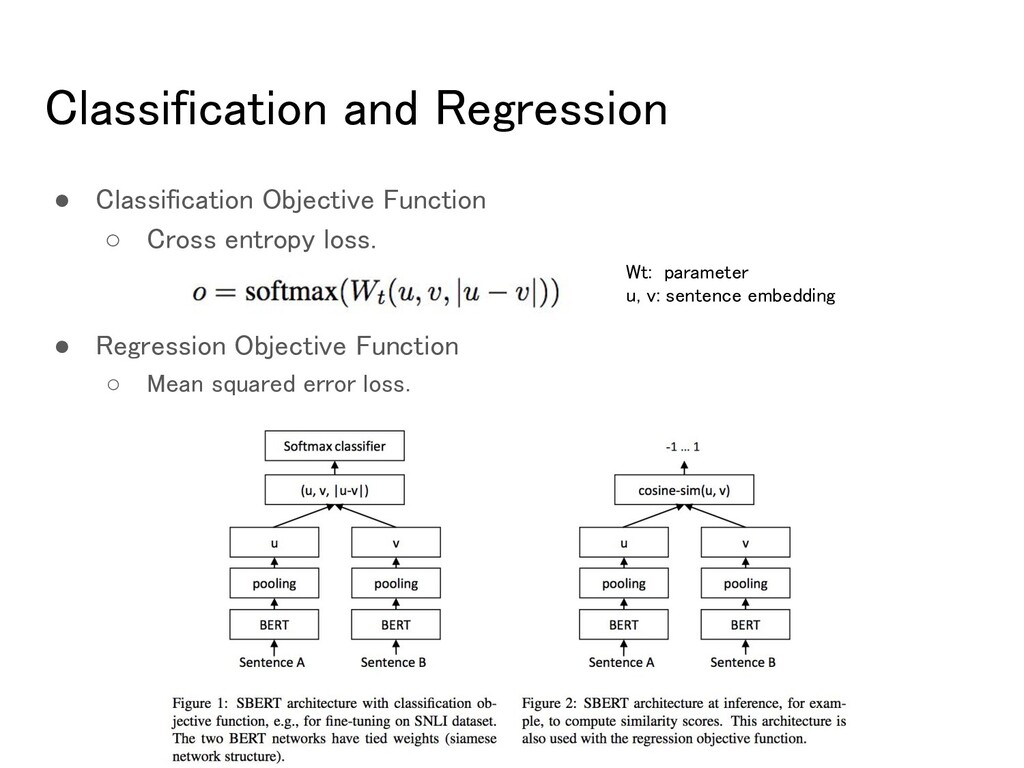
of BERT/RoBERTa. ◦ Pooling strategy (CLS-token, MEAN, MAX) • Create siamese and triplet networks (Schroff et al, 2015) ◦ Update weight such that the sentence embeddings are semantically meaningful and can be compared with cosine-similarity. • The network structure depends on the available training data. ◦ Classificartion ◦ Regression ◦ Triplet
tunes the network such that the distance between a and p is smaller than that a and n. • As metric they use Euclidean distance and set ∊ = 1. a: anchor sentence p: positive sentence n: negative sentence s x : sentence embeddings ∊: margin ‖・‖: a distance metric
dataset ◦ SNLI: 570K sent-pairs with labels contradiction, entailment, neutral. ◦ Multi-NLI: 430K covers a range of spoken and written text. • Fine-tuning SBERT with a 3-way softmax-classifier objective function for one epoch. • Hyper parameter ◦ Batch-size: 16 ◦ Optimizer: Adam ◦ Learning rate: 2e-5 ◦ Linear learning rate warmup over 10% ◦ Pooling strategy: MEAN
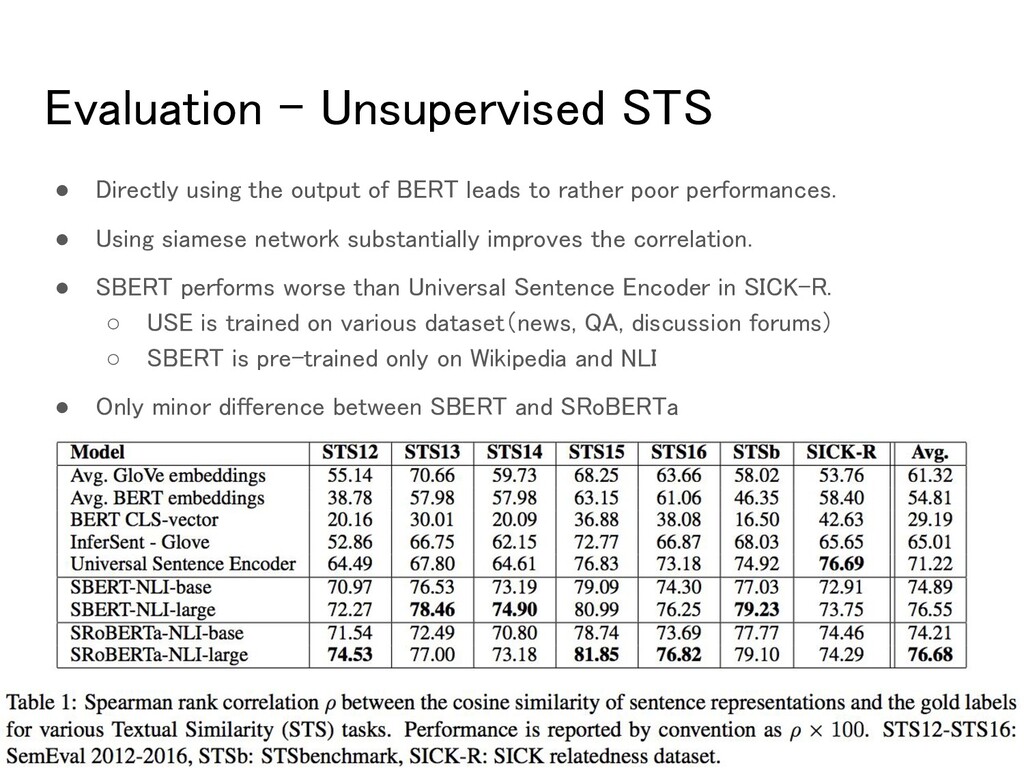
BERT leads to rather poor performances. • Using siamese network substantially improves the correlation. • SBERT performs worse than Universal Sentence Encoder in SICK-R. ◦ USE is trained on various dataset(news, QA, discussion forums) ◦ SBERT is pre-trained only on Wikipedia and NLI • Only minor difference between SBERT and SRoBERTa
training on STSn ◦ First training on NLI, then training on STSb • Later strategy leads to a slight improvement of 1-2 points. • Two-step approach had an especially large impact for the BERT cross-encoder.
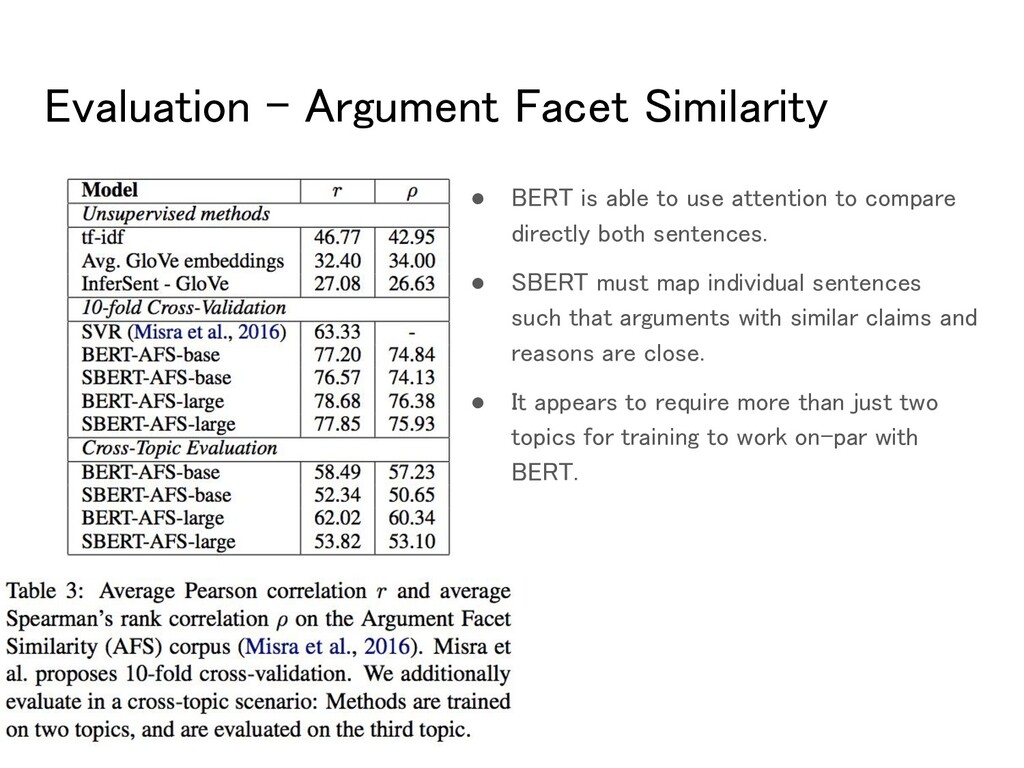
corpus. (Misra et al., 2016) ◦ 6,000 sentential argument pairs. ◦ From social media dialogs on three controversial topics. ▪ gun control, gay marriage, and death penalty. ◦ Annotated on a scale from 0 to 5 ▪ 0: different topic, 5: completely equivalent. ◦ The similarity notion is fairly different to STS datasets. ▪ To be considered similar, arguments must not only make similar claims, but also provide a similar reasoning. ▪ Simple unsupervised methods perform badly on this dataset (Reimers et al., 2019)
able to use attention to compare directly both sentences. • SBERT must map individual sentences such that arguments with similar claims and reasons are close. • It appears to require more than just two topics for training to work on-par with BERT.
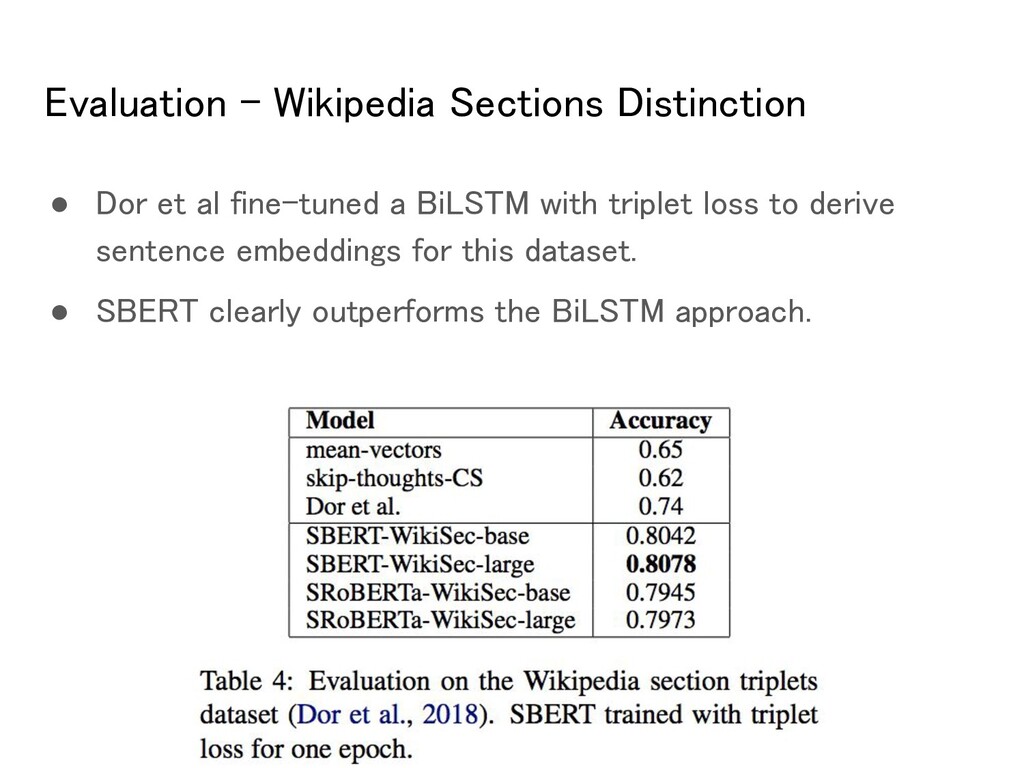
sentence triplets (Dor et al., 2018) ◦ sentences in the same section are thematically closer than sentences in different sections. ◦ The anchor and the positive example come from the same section ◦ The negative example comes from a different section of the same article. • Train: 1.8 Million / Test: 222,957 • Evaluation Metric: accuracy
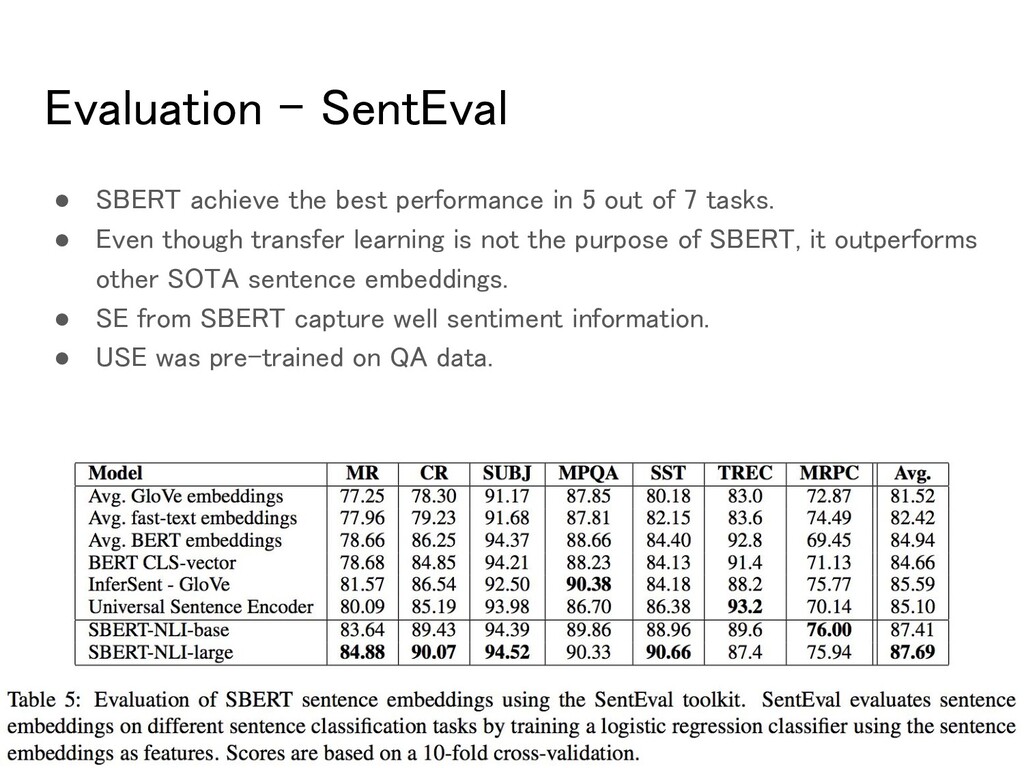
Toolkit to evaluate the quality of sentence embesings. • The purpose of SBERT SE are not to be used for transfer learning for other tasks. ◦ Fine-tuning BERT as described by Devlin is more suitable. ◦ However, SentEval can still give an impression on the quality of our SE for various tasks. • Experiment flollowing seven SentEval transfer tasks ◦ MR: Sentiment prediction for movie reviews snippets. ◦ CR: Sentiment Prediction of customer product reviews. ◦ SUBJ: Subjectivity prediction of sentences from movie reviews. ◦ MPQA: Phase level opinion polarity classification from newswire. ◦ SST: Stanford Sentiment Treebank with binary labels. ◦ TREC: Fine grained question-type classification from TREC. ◦ MRPC: Microsoft Research Paraphrase Corpus.
5 out of 7 tasks. • Even though transfer learning is not the purpose of SBERT, it outperforms other SOTA sentence embeddings. • SE from SBERT capture well sentiment information. • USE was pre-trained on QA data.
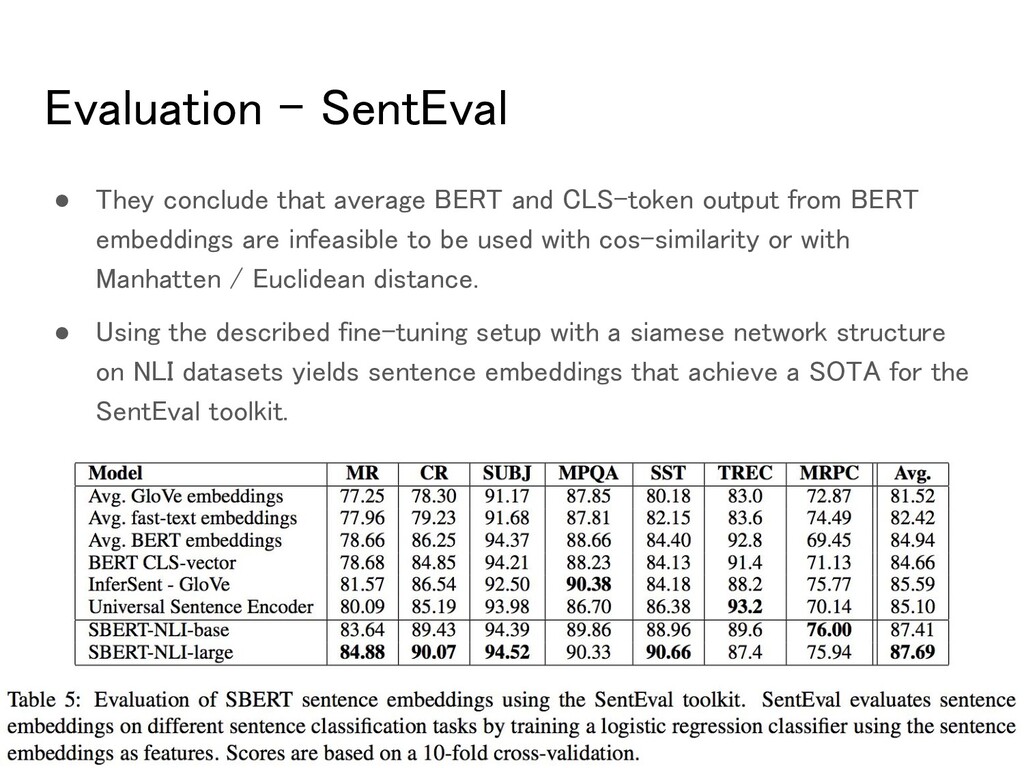
CLS-token output from BERT embeddings are infeasible to be used with cos-similarity or with Manhatten / Euclidean distance. • Using the described fine-tuning setup with a siamese network structure on NLI datasets yields sentence embeddings that achieve a SOTA for the SentEval toolkit.
on regression. ◦ Conneau et al., 2017 found is beneficial for the InferSent to use MAX instead of MEAN. Pooling Strategy Concatenation • InferSent and USE both use (u, v, |u-v|, u∗v). ◦ In this architecture, adding the u∗v decreased the performance. • |u-v| is the most important.
GPU • Smart Batching ◦ Sentences with similar lengths are grouped together and are only padded to the longest element in a mini-batch. • On a GPU, it is about 9% faster than InferSent and about 55% faster than Universal Sentence Encoder.
be used with common similarity measures like cos-similarity. • To overcome this shortcoming, they presented SBERT. ◦ SBERT fine-tunes BERT in a triplet network architecture. • Evaluation on various common benchmarks ◦ Improvement over SOTA sentence embeddings methods. • SBERT is computationally efficient.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}