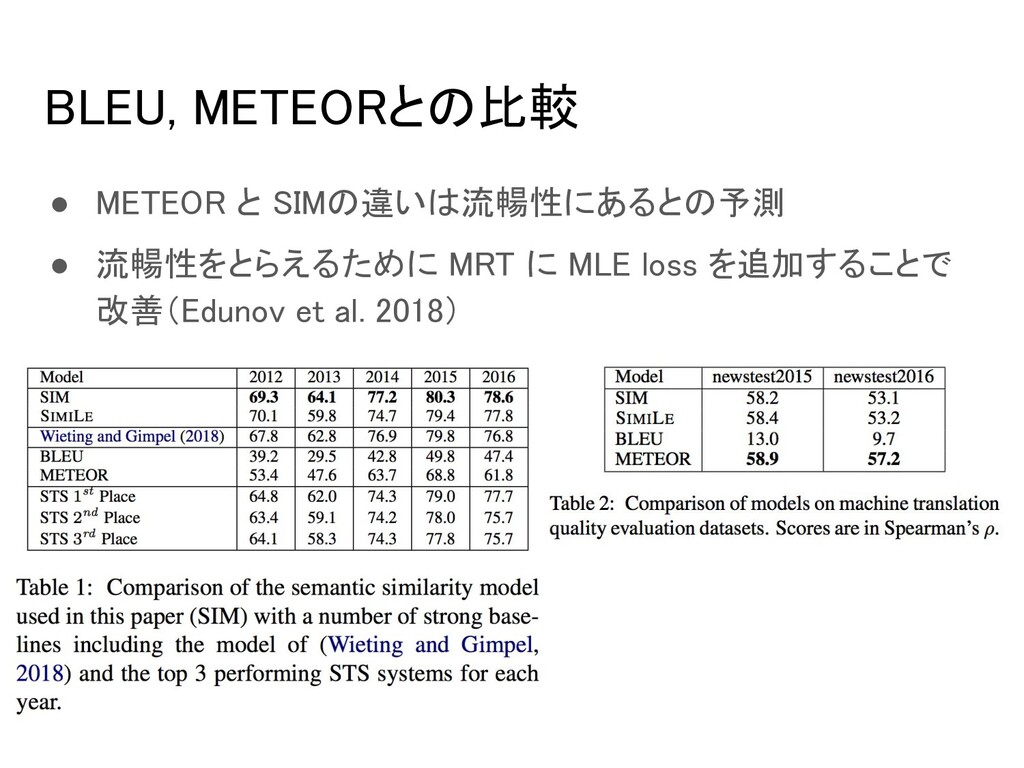
News Commentary v13 (WMT18) ▪ valid: validation set of WMT16, 17 ▪ test: test set of WMT18 ◦ tr-en: ▪ train: SETIMES2 (WMT18) ▪ valid: validation set of WMT16, validation and test set of WMT17 ▪ test: test set of WMT18 • Evaluation ◦ Automatic Evaluation ▪ BLEU, SIM (not SIMILE) 意味を重視 ◦ Human Evaluation ▪ 200文を人手評価(情報をどれだけ伝えたかの観点)
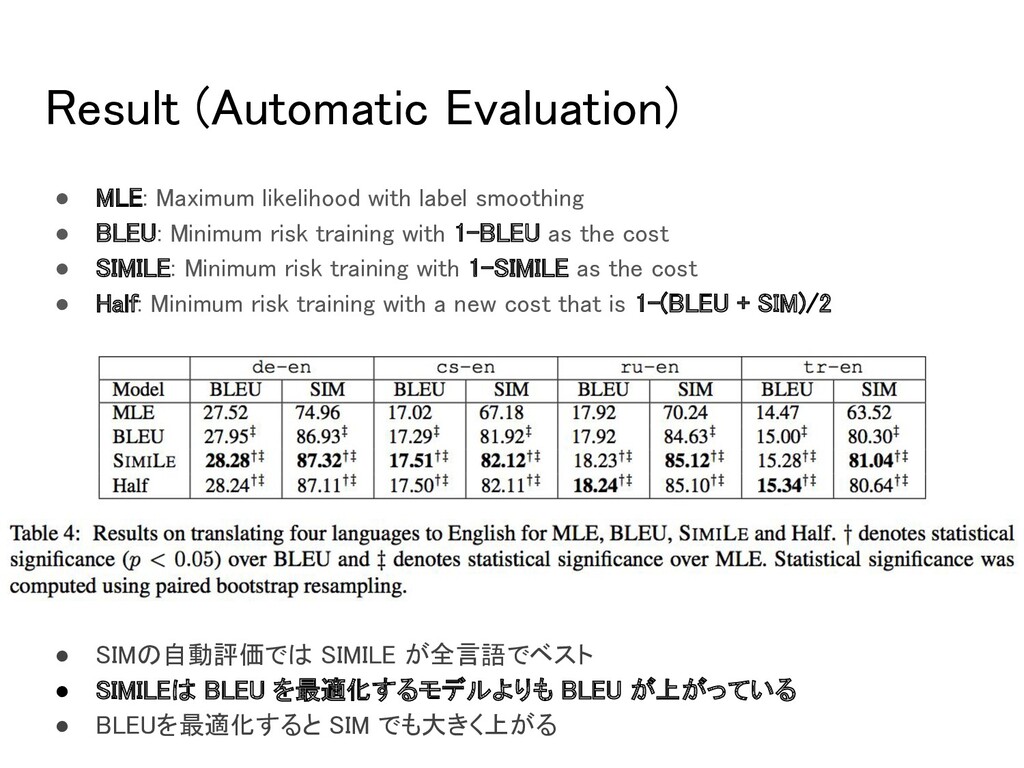
• BLEU: Minimum risk training with 1-BLEU as the cost • SIMILE: Minimum risk training with 1-SIMILE as the cost • Half: Minimum risk training with a new cost that is 1-(BLEU + SIM)/2 • SIMの自動評価では SIMILE が全言語でベスト • SIMILEは BLEU を最適化するモデルよりも BLEU が上がっている • BLEUを最適化すると SIM でも大きく上がる
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}