Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
TransQuest: Translation Quality Estimation with...
Search
Sponsored
·
Your Podcast. Everywhere. Effortlessly.
Share. Educate. Inspire. Entertain. You do you. We'll handle the rest.
→
ryoma yoshimura
January 19, 2021
Research
290
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
TransQuest: Translation Quality Estimation with Cross-lingual Transformers
研究室のEMNLP読み会での資料です。
paper:
https://www.aclweb.org/anthology/2020.coling-main.445.pdf
ryoma yoshimura
January 19, 2021
More Decks by ryoma yoshimura
See All by ryoma yoshimura
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing
kokeman
0
65
BLEURT: Learning Robust Metrics for Text Generation
kokeman
0
270
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
kokeman
1
860
Courteously Yours: Inducing courteous behavior in Customer Care responses using Reinforced Pointer Generator Network
kokeman
0
170
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
kokeman
0
180
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
kokeman
0
130
タスクとデータセット紹介 GLUE, SuperGLUE
kokeman
0
1.1k
Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement Learning
kokeman
0
85
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation
kokeman
0
250
Other Decks in Research
See All in Research
Data Visualization Tools in the Age of AI
flekschas
0
170
SoftMatcha 2: 1兆語規模コーパスの超高速かつ柔らかい検索
e869120_sub
7
3.6k
2026 東京科学大 情報通信系 研究室紹介 (大岡山)
icttitech
0
4.1k
Research Engineerという仕事 / Research Engineering: Bridging Research and Business
chck
1
240
明日から使える!研究効率化ツール入門
matsui_528
13
7.5k
計算情報学研究室 (数理情報学第7研究室)2026
tomohirokoana
0
650
さくらインターネット研究所テックトーク2026春、研究開発Gr.25年度成果26年度方針
kikuzo
0
160
GLIM とMegaParticles:正規分布近似の限界とタイトカップリング&パーティクルフィルタの進展 / GLIM and MegaParticles : Progress of the distribution representation in SLAM
koide3
0
600
National high-resolution cropland classification of Japan with agricultural census information and multi-temporal multi-modality datasets
satai
3
380
全国町字単位空き家率推定データver1.0データ仕様
microbaseinc
0
130
2026年度 生成AI を活用した論文執筆ガイド/ワークショップ / 2026 Academic Year Guide to Writing Papers Using Generative AI - Workshop
ks91
PRO
0
190
[BlackHatAsia2026] Hidden Telemetry: Uncovering TraceLogging ETW Providers You're Not Using (Yet)
asuna_jp
1
590
Featured
See All Featured
Claude Code どこまでも/ Claude Code Everywhere
nwiizo
65
57k
個人開発の失敗を避けるイケてる考え方 / tips for indie hackers
panda_program
123
22k
The Art of Programming - Codeland 2020
erikaheidi
57
14k
Fantastic passwords and where to find them - at NoRuKo
philnash
52
3.8k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
750
The Hidden Cost of Media on the Web [PixelPalooza 2025]
tammyeverts
2
360
Designing Dashboards & Data Visualisations in Web Apps
destraynor
231
55k
Agile Actions for Facilitating Distributed Teams - ADO2019
mkilby
0
220
The Curse of the Amulet
leimatthew05
2
13k
JAMstack: Web Apps at Ludicrous Speed - All Things Open 2022
reverentgeek
1
500
The Art of Delivering Value - GDevCon NA Keynote
reverentgeek
16
2k
BBQ
matthewcrist
89
10k
Transcript
2021/01/19 研究室COLING読み会 紹介者: 吉村
Abstract • 品質推定(QE)はニューラルにより大きな進歩 • 既存の手法の多くは訓練されたペアに対してのみ有効で新し い言語ペアに対しては再学習が必要 • Cross-lingual transformerに基づくシンプルなQEフレームワー クを提案し2つのアーキテクチャの実装と評価
• 実験の結果 WMT2020 で SOTA の結果 • 転移学習の学習設定がリソースの少ない言語を扱う場合にお いて非常に有効であることを証明した 2
Introduction • QEの目的は参照訳を使用せず翻訳の品質を評価すること ◦ 複数の翻訳システムから最適な翻訳を選択する ◦ 翻訳の信頼性をユーザーに提示 ◦ 翻訳がそのまま使えるか,人手の編集が必要か,再翻訳が必要かの判断 •
現在はニューラル手法がSOTA • 既存の手法の問題点 ◦ 多くは訓練された言語ペアに対してのみ有効で新しい言語ペアに対しては再 学習が必要 ◦ 学習のために大量のアノテーションされたデータを必要とするため,リソースの 少ない言語ペアでは品質推定は難しい • これらの問題を解決し,SOTAの結果を得ることができる文レ ベルの機械翻訳品質推定フレームワークTransQuestを提案 3
Contributions • TransQuest を導入し,文レベルの品質推定の2つのタスクで SOTA手法を超えるアーキテクチャを実装 • 複数の言語ペアに対して品質推定できるモデルの開発 ◦ QEで複数言語ペアに対応した最初のモデル ◦
複数言語ペアの品質推定環境を維持するために必要なコストが高い問題に対 処 • 低リソース言語ペアにおける品質推定に取り組み,データ量 が少なくても転移学習の設定でSOTAを凌駕する結果 • コミュニティに重要なリソースを提供 ◦ オープンソースのフレームワークとしてのコードと,事前学習済みの品質推定 モデルを公開 4
Related Work • QEはWMT2012から毎年開催 ◦ 毎年アノテーションされたデータが公開されている • ニューラル以前の手法 ◦ QuEst
[Specia et al., 2013], QuEst++ [Specia et al., 2015] ◦ 言語学的特徴に基づくSVRやランダムフォレスト • ニューラル以降の手法 ◦ deepQuest [lve et al., 2018] ▪ predictor-estimator モデル ◦ OpenKiwi [Kepler et al., 2019] ▪ LSTM based predictor-estimator モデル ◦ 大規模なパラレルデータでの事前学習が必要 5
Related Work • mBERT [Devlin et al., 2019] ◦
多言語データで事前学習した BERT ◦ クロスリンガルベンチマークでは良い結果ではなかった [K et al., 2020] • XLM-RoBERTa (XML-R) [Conneau to al., 2020] ◦ 104言語,2.5TBの大規模な多言語データでRoBERTaを学習 ◦ MLMでのみ訓練 ◦ クロスリンガルベンチマークでmBERTより良い結果 6
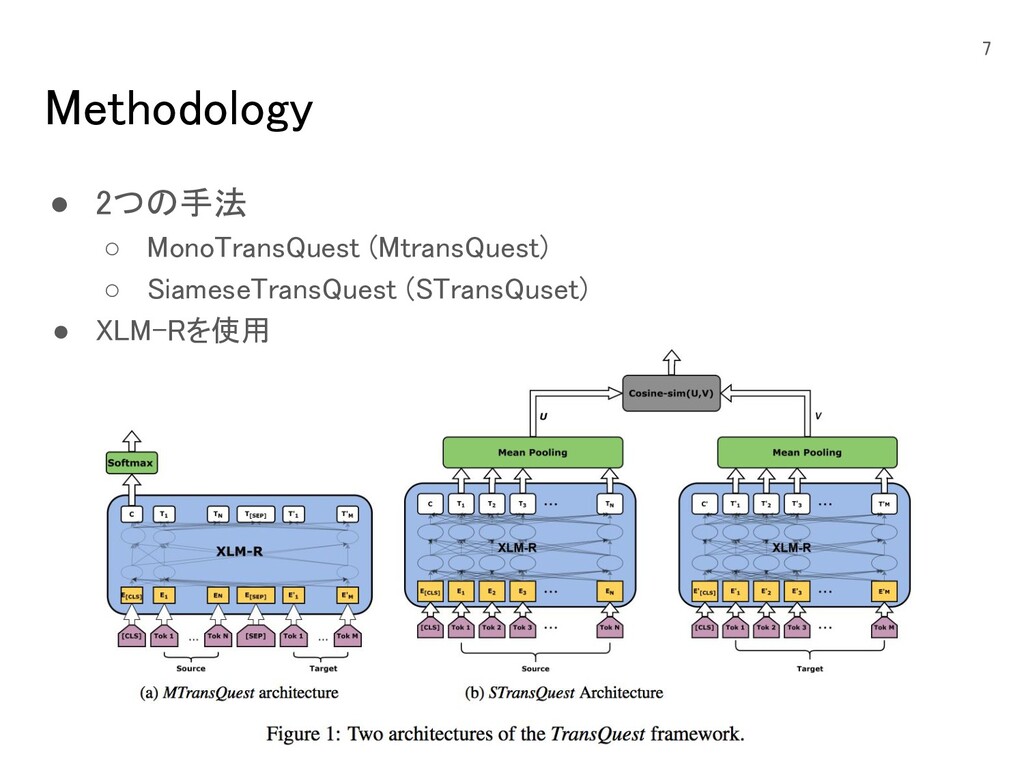
Methodology 7 • 2つの手法 ◦ MonoTransQuest (MtransQuest) ◦ SiameseTransQuest (STransQuset)
• XLM-Rを使用
Methodology 8 • MonoTransQuest (MtransQuest) ◦ [CLS]トークンに対応する最終層を使用 ◦ 事前実験で全単語ベクトルの平均,各単語ベクトルの最大値を使 う手法より良かった
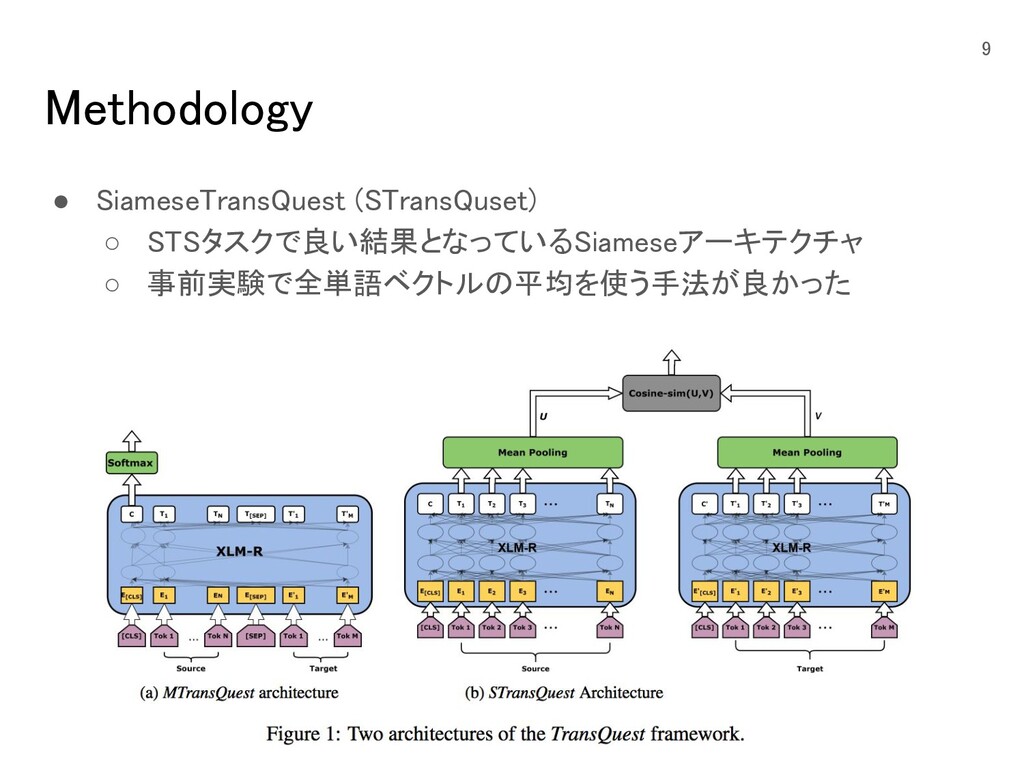
Methodology 9 • SiameseTransQuest (STransQuset) ◦ STSタスクで良い結果となっているSiameseアーキテクチャ ◦ 事前実験で全単語ベクトルの平均を使う手法が良かった
Training Details • Model: Transformers の XLM-R-large • Batch size:
8 • Optimizer: Adam • lr: 2e-5 • linear lr warm-up over 10% of the training data • epoch: 3 • early stopping 10 10
Dataset 11 • Predicting HTER ◦ HTER: 翻訳をリファレンスに変換する修正数ベースの指標 ◦ WMTで公開されているデータ
Dataset • Predicting DA ◦ Direct Assesment (1~100) ▪ 3人のプロの翻訳者が評価
▪ z-score で標準化して平均したものを予測 ◦ WMT 2020 QE taskのデータ ◦ Wikipedia から作られた 6言語ペアのデータ ◦ High-resource ▪ English-German (En-De), English-Chinese (EN-Zh) ◦ Medium-resource ▪ Romainian-English (Ro-En), Estonian-English (Et-En) ◦ Low-resource ▪ Sinhala-English (Si-En), Nepalese-English (Ne-En), Russian-English (En-Ru) ◦ 全言語 train/dev/test がそれぞれ 7,000/1,000/1,000 文 12
Multi language pair QE 複数言語ペアのための2つの学習設定 1. 言語ペアを2つのグループに分ける ◦ ソースが英語の言語ペアグループ(En-*) ◦
ターゲットが英語の言語ペアグループ(*-En) ◦ 特定方向のグループを合わせて学習に使用する 2. 方向を考慮せずに全ての言語ペアの学習データを合わせて, すべての言語ペアについて単一のモデルを構築 (MTransQuest-m, STransQuest-m) 13
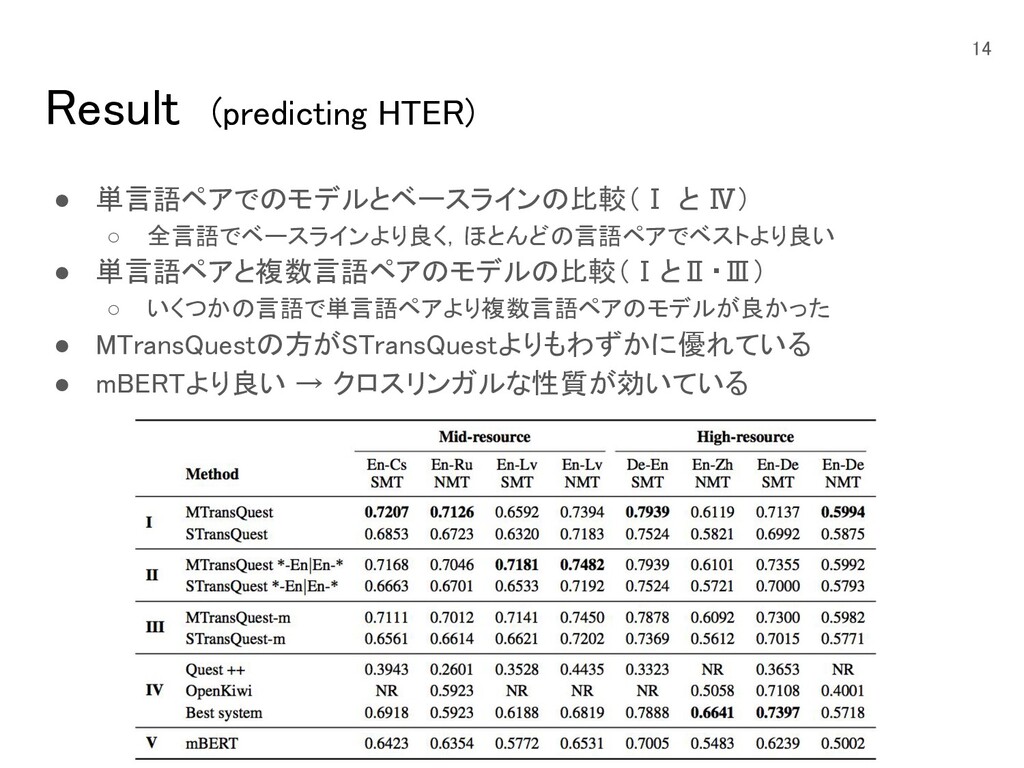
Result (predicting HTER) • 単言語ペアでのモデルとベースラインの比較(Ⅰ と Ⅳ) ◦ 全言語でベースラインより良く,ほとんどの言語ペアでベストより良い •
単言語ペアと複数言語ペアのモデルの比較(ⅠとⅡ・Ⅲ) ◦ いくつかの言語で単言語ペアより複数言語ペアのモデルが良かった • MTransQuestの方がSTransQuestよりもわずかに優れている • mBERTより良い → クロスリンガルな性質が効いている 14
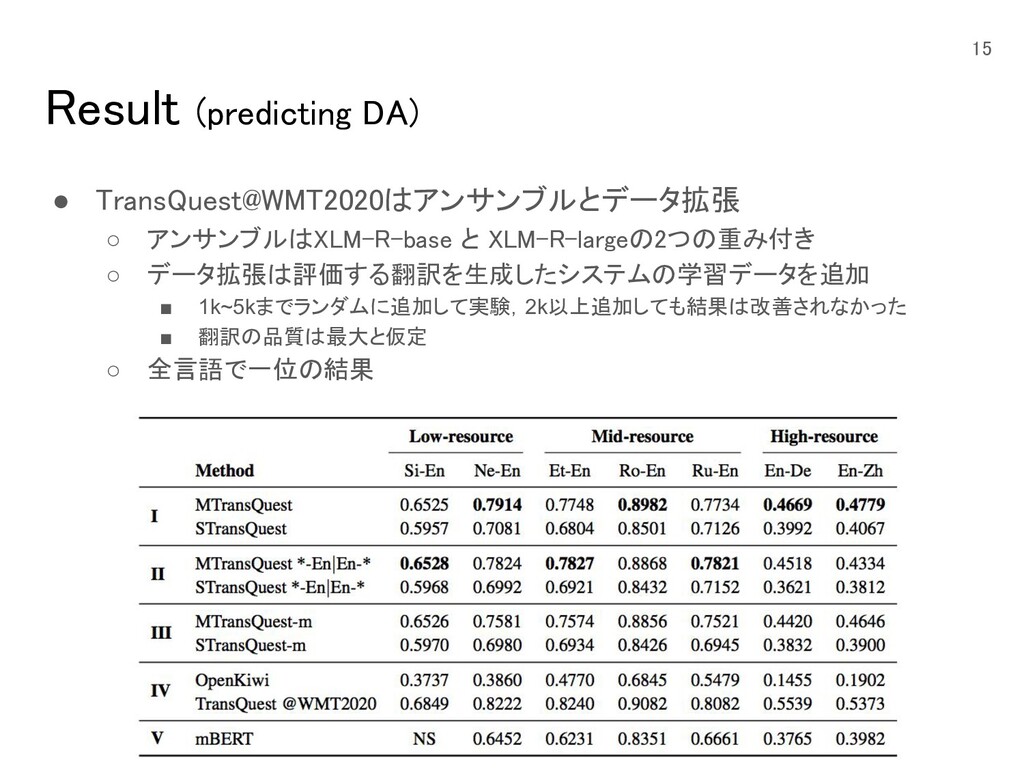
Result (predicting DA) • TransQuest@WMT2020はアンサンブルとデータ拡張 ◦ アンサンブルはXLM-R-base と
XLM-R-largeの2つの重み付き ◦ データ拡張は評価する翻訳を生成したシステムの学習データを追加 ▪ 1k~5kまでランダムに追加して実験,2k以上追加しても結果は改善されなかった ▪ 翻訳の品質は最大と仮定 ◦ 全言語で一位の結果 15
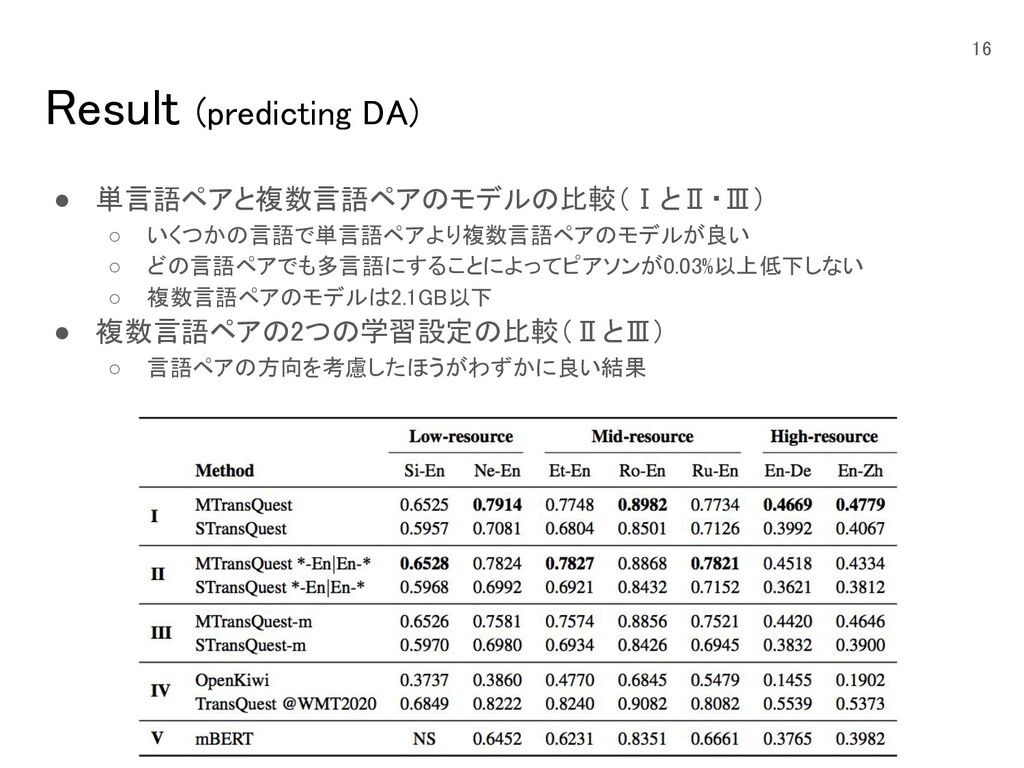
Result (predicting DA) • 単言語ペアと複数言語ペアのモデルの比較(ⅠとⅡ・Ⅲ) ◦ いくつかの言語で単言語ペアより複数言語ペアのモデルが良い
◦ どの言語ペアでも多言語にすることによってピアソンが0.03%以上低下しない ◦ 複数言語ペアのモデルは2.1GB以下 • 複数言語ペアの2つの学習設定の比較(ⅡとⅢ) ◦ 言語ペアの方向を考慮したほうがわずかに良い結果 16
Result transfer learning based QE • High resource 言語で学習した後に Low
resource 言語で学習 • 少ないデータ量でも高いピアソンの相関係数 • アノテーションされたデータが少ない言語ペアにおいて有効 17
MTransQuest vs STransQuest • 7,000文の学習@Nvidia Tesla K80 ◦ MTransQuest:
平均 4,480s ◦ StransQuest: 平均 3,900s • 1,000文の推論 ◦ MTransQuest: 平均 35s ◦ StransQuest: 平均16s • 精度重視ならMTransQuest • 効率重視ならStranQuest 18
Conclusions • 機械翻訳の品質推定のための新しいフレームワークTransQuestを提 案 • 文レベルの品質推定でSOTAの結果 • 複数言語ペアでの学習と低リソース言語の転移学習の実験 • 今後
◦ 文書レベルなどのモデルを増やしてTransQuestを拡張 ◦ 英語を含まない言語ペアに対する転移学習 ◦ 低リソース言語ペアでの教師なし 19
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Related Work • mBERT [Devlin et al., 2019] ◦](https://files.speakerdeck.com/presentations/e966086c37224b6a8851554a5e8c3801/slide_5.jpg){kind=link}
{kind=link}
![Methodology 8 • MonoTransQuest (MtransQuest) ◦ [CLS]トークンに対応する最終層を使用 ◦ 事前実験で全単語ベクトルの平均,各単語ベクトルの最大値を使 う手法より良かった](https://files.speakerdeck.com/presentations/e966086c37224b6a8851554a5e8c3801/slide_7.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}