Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
Reliability and Learnability of Human Bandit F...
Search
ryoma yoshimura
June 20, 2019
Research
85
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement Learning
研究室の論文読み会の発表資料です。
ryoma yoshimura
June 20, 2019
More Decks by ryoma yoshimura
See All by ryoma yoshimura
TransQuest: Translation Quality Estimation with Cross-lingual Transformers
kokeman
0
290
Automatic Machine Translation Evaluation in Many Languages via Zero-Shot Paraphrasing
kokeman
0
65
BLEURT: Learning Robust Metrics for Text Generation
kokeman
0
270
Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks
kokeman
1
860
Courteously Yours: Inducing courteous behavior in Customer Care responses using Reinforced Pointer Generator Network
kokeman
0
170
Beyond BLEU: Training Neural Machine Translation with Semantic Similarity
kokeman
0
180
Reinforcement Learning Based Text Style Transfer without Parallel Training Corpus
kokeman
0
130
タスクとデータセット紹介 GLUE, SuperGLUE
kokeman
0
1.1k
Multi-Reference Training with Pseudo-References for Neural Translation and Text Generation
kokeman
0
250
Other Decks in Research
See All in Research
シングルチャネルマルチトーカー音声認識の進展
ryomasumura
0
200
データサイエンティストの就労意識~2015 → 2026 一般(個人)会員アンケートより
datascientistsociety
PRO
0
300
YOLO26_ Key Architectural Enhancements and Performance Benchmarking for Real-Time Object Detection
satai
3
890
論文紹介 "ReSim: Reliable World Simulation for Autonomous Driving"
kogo
0
700
Fukui Shibiten 39 - AI Art
butchi
0
150
オーストリア流 都市の公共交通サービス水準評価@公共交通オープンデータ最前線2026
trafficbrain
0
210
研究室単位での自律的 IPv6接続性確立に向けたAS共同運用モデルの提案と実証
reokashiwa
PRO
0
160
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
120
Ghost in the 7‑Zip: The Shadow of Residential Proxies Creeping into Your Life
nttcom
0
1.6k
論文紹介:HalluCitation Matters
wasyro
0
130
某助成金プロジェクト採択に向けて企業研究所のアウトリーチ専任者がやったこと
afroscript
0
110
長時間動画QAにおけるマルチエージェント推論 ・SVAgent: Storyline-Guided Long Video Understanding via Cross-Modal Multi-Agent Collaboration
murakawatakuya
1
160
Featured
See All Featured
Ruling the World: When Life Gets Gamed
codingconduct
0
290
Typedesign – Prime Four
hannesfritz
42
3.1k
Digital Projects Gone Horribly Wrong (And the UX Pros Who Still Save the Day) - Dean Schuster
uxyall
1
2.1k
Design in an AI World
tapps
1
260
Heart Work Chapter 1 - Part 1
lfama
PRO
8
36k
The Success of Rails: Ensuring Growth for the Next 100 Years
eileencodes
47
8.2k
Mind Mapping
helmedeiros
PRO
1
290
Helping Users Find Their Own Way: Creating Modern Search Experiences
danielanewman
31
3.3k
Put a Button on it: Removing Barriers to Going Fast.
kastner
60
4.4k
Utilizing Notion as your number one productivity tool
mfonobong
4
440
The SEO Collaboration Effect
kristinabergwall1
1
510
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Transcript
Reliability and Learnability of Human Bandit Feedback for Sequence-to-Sequence Reinforcement
Learning Julia Kreutzer and Joshua Uyheng and Stefan Riezler (NAACL 2018) 紹介者: 吉村
Abstract • Human bandit Feedback を報酬とした強化学習 (RL) で NMTを改善 •
Human bandit Feedback の質が Reward Estimator (RE) に与える影響 とその推定報酬の質が RL に与える影響を調べた • 5-point と ペアワイズ選択の評価がついたデータを作成して分析 ◦ 両タスクの評価者間、評価者内の一致度は同程度 ◦ 標準化された 5-point が最も高い信頼性が高い • 5-point 評価付きの800文で回帰学習した RE で BLEU が1.0上がった • 少量の信頼できる弱い人間のフィードバックがあればよく、大規模スケール で応用の可能性があることを示した。
Introduction • BLEUやROUGEなどを報酬として使う seq2seq の強化学習は 翻訳 (Bahdanau et al., 2017)
や要約(Paulus et al., 2017). などで行われてい る • 先行研究 (Kreutzer et al., 2018) ◦ 商品タイトルの En-Fr 翻訳をユーザーの5つ星評価を報酬として強化 学習で行なったが報酬の品質が悪く失敗、クリックログを利用すると良 くなった。 • 高品質な Human Feedback を手に入れる方法とその信頼性が RL にどう 影響するかを調べる ◦ 5-point と pairwaise で評価者間と評価者内の一致率を測定 ◦ 人間の報酬の学習可能性にも取り組む ◦ MT を 推定報酬を使った RL でどれほど改善できるかを調査
Human MT Rating Task • Data ◦ TED corpus の一部を使用
◦ WMT で学習した NMT (out-of-domain)と TED で学習したNMT(in-domain)でそれぞれ翻訳 ◦ 結果が同じものはフィルタリング ◦ reference の長さが 20 ~ 40 のものを選択 ◦ reference と chrF の差が大きくて文長の差が最小になる ようにソートして上位 400 pair を使用 → 同じ長さで質が異なるペアがとれる
Human MT Rating Task Rating Data and Annotator • 400
ペア (800の翻訳文) • 400ぺアのうち100ペアを複製して500ペア取得 • シャッフルして5分割 ◦ 各セクションに文の重複ないように ◦ 各セクションのうち20ペアが複製したペア • 評価者 ◦ ドイツ語と英語のネイティブ or 流暢な大学生 ◦ 5-points 16人, pairwise 14人 データはここでDLできる
Human MT Rating Task Interface
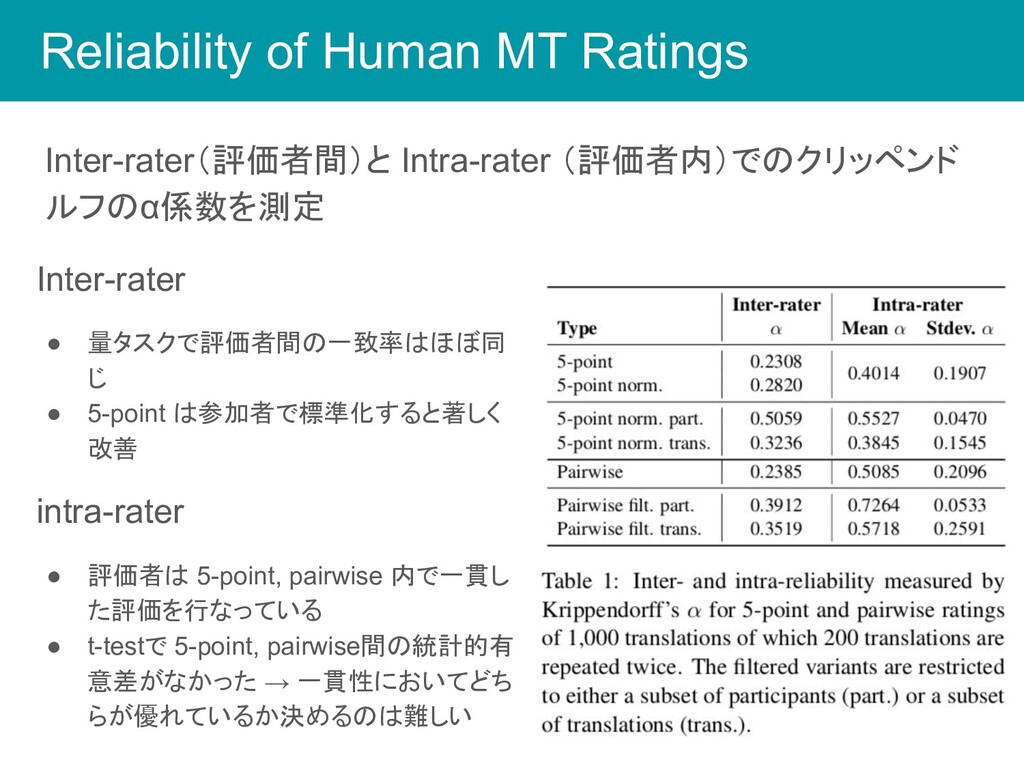
Reliability of Human MT Ratings Inter-rater(評価者間)と Intra-rater (評価者内)でのクリッペンド ルフのα係数を測定 Inter-rater
• 量タスクで評価者間の一致率はほぼ同 じ • 5-point は参加者で標準化すると著しく 改善 intra-rater • 評価者は 5-point, pairwise 内で一貫し た評価を行なっている • t-testで 5-point, pairwise間の統計的有 意差がなかった → 一貫性においてどち らが優れているか決めるのは難しい
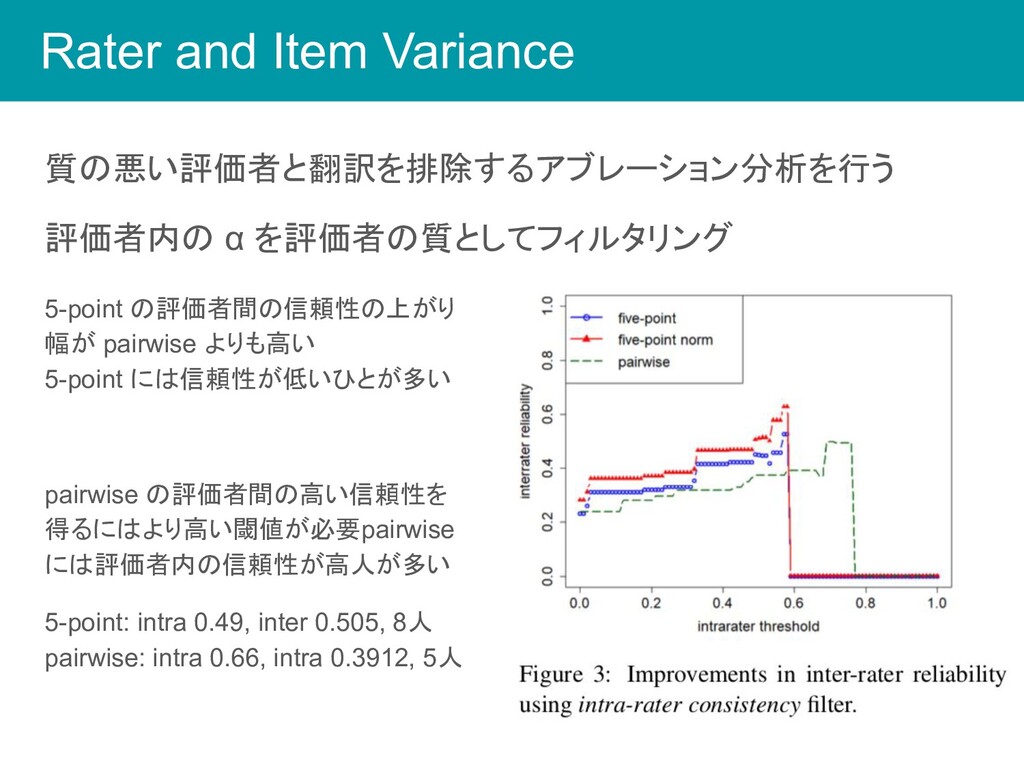
Rater and Item Variance 質の悪い評価者と翻訳を排除するアブレーション分析を行う 評価者内の α を評価者の質としてフィルタリング 5-point の評価者間の信頼性の上がり
幅が pairwise よりも高い 5-point には信頼性が低いひとが多い pairwise の評価者間の高い信頼性を 得るにはより高い閾値が必要pairwise には評価者内の信頼性が高人が多い 5-point: intra 0.49, inter 0.505, 8人 pairwise: intra 0.66, intra 0.3912, 5人
Rater and Item Variance 分散が大きい翻訳をフィルタリング 0~1 で正規化した値を1から引いて閾 値とする pairwise が
5-point をすぐに追い越す 多くの翻訳が評価者間で不一致である ことに起因する pairwise の全体的な評価者間の信頼 性が低い 70% が保持されるように(結果は table1 )
Qualitative Analysis 評価作業後に、1(非常に困難)から10(非常に簡単)までの尺度 で、主観的な難しさを参加者につけてもらう 5-point (平均4.8)、pairwise(平均5.69) 参加者に聞いた各タスクの難しいところ • 5-point さまざまなエラータイプの比較
非常に少ないが本質的なエラーのある長い文の評価 • pairwise 類似した、または類似した不適切な翻訳を区別 どちらも文法的に理解できない文で困難を示した
Learning a Reward Estimator(5-points) 回帰モデル • simulated では gold referenceとの
sBLEU で r を計算 • 評価者間で平均をとり 0 ~ 1 に正規化して使用 y: translation ψ: parameters r^: prediction reward r: judgements
Learning a Reward Estimator(pairwise) Brandley-Terry モデル : REが y1 が
y2 よりも良いと推定する確率 : y1 が y2 よりも良いとされる確率(相対度数) Simulation だと y: translation ψ: parameters
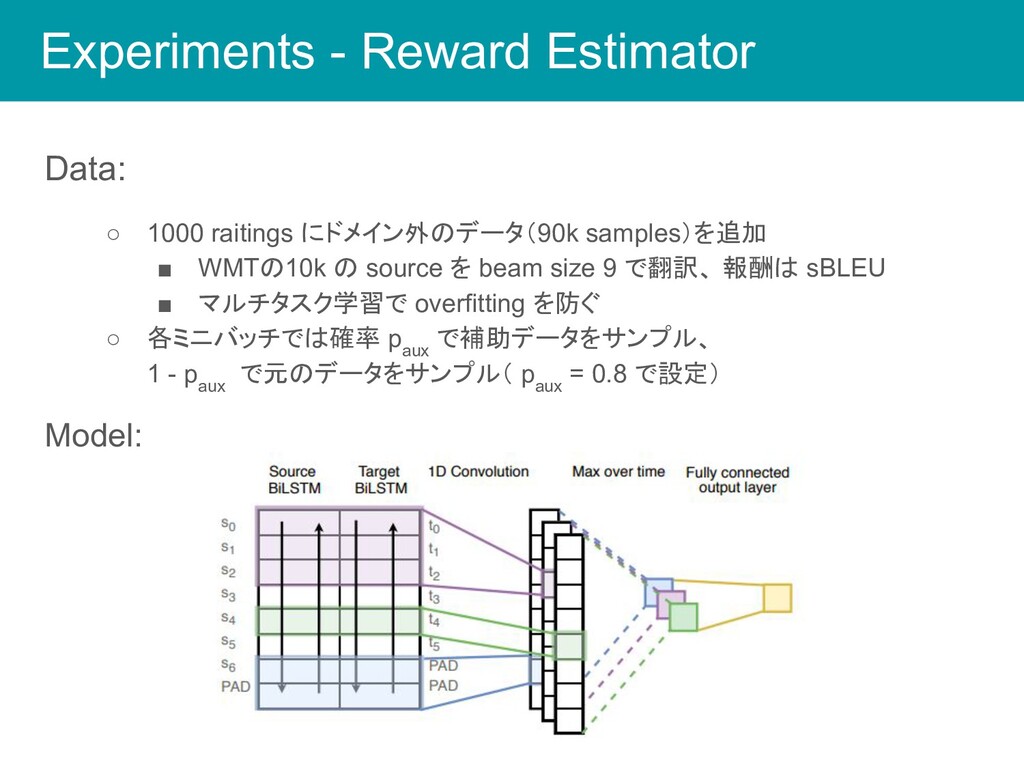
Experiments - Reward Estimator Data: ◦ 1000 raitings にドメイン外のデータ(90k samples)を追加
▪ WMTの10k の source を beam size 9 で翻訳、 報酬は sBLEU ▪ マルチタスク学習で overfitting を防ぐ ◦ 各ミニバッチでは確率 p aux で補助データをサンプル、 1 - p aux で元のデータをサンプル( p aux = 0.8 で設定) Model:
Experiments - Reward Estimator TER とのスピアマンの順位相関係数で評価(sQEと同様) MSE では simulated が
humanよりわ ずかに高い PW では 逆で、sentence-bleuに対する softmax が人手による pairwise 選択の 確率ほど表現力がないから フィルタリングすると MSE では相関が 高くなるが PW では下がる 相関が全体的に低いのは small dataset に over-fitting してるから pairwise より標準化 5-point が信頼性 が高かった。 → 報酬の質が RE の質に影響
Reinforcement Learning from Estimated or Simulated Direct Rewards. MLE で
pre-train D: paralell corpus x: source y: target 強化学習で fine-tuning する 温度パラメータ τ で分布を平滑化 報酬の期待値 k-samplingで近似
Off-Policy Learning from Direct Rewards. RE の予測報酬を使わず報酬付きデータで強化学習 • 目的関数 ログにある
翻訳 y が出る確率をそのまま用いる ログ: reweighting over the mini-bach B
Experiments Data • WMT17, de-en (out-of-domain) train: 5.9M , dev:
2,299 (WMT16) . test: 3,004 • IWST (TED), de-en (in-domain) train: 153k, dev:6,969, test:6750 Architecture • subword-based encoder-decoder with attention ◦ bidirectional encoder and single layer decoder • subword embedding size: 500 • sample k: 5, softmax temperature: 0.5
Result • WMTのみの学習での結果がベースライン • 教師ありで fine tuning したものが uper bound
• BLEU が 7 point 上がる
Result Simulated - Direct • RL は GLEUを報酬 • OPL
は sBLEU を報酬 Simulated - Estemated • MSE: +1.2, PW: +0.8 (BLEU) • REが少量の rating を一般化する のに役立っている Human - Direct • simulationと同じくらい Human - Estemated • MSE > PW + 1.1 (BLEU) • Filterしてもあまり変わらない
Conclusion • NMT を human bandit feedback で改善するために NMT に
おける RL の信頼性、学習性、有効性について 5-point と pairwise の報酬でどう異なるかを調べた • 5-point と pairwise の信頼性は同程度で 5-point の方が RE の学習と RL に適していることがわかった • 小さいデータセットで BLEU が 1向上 • post-edit や gold reference と異なり迅速かつ安価に取得で きるので、大規模なデータでの応用の可能性がある
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}