A talk by Komodor's co-founding CTO Itiel Shwartz on DevOpsCon London 2022.
Kubernetes has given us the power to move extremely fast. But without any safeguards in place, we more often than not find ourselves staring at it blankly trying to figure out what the hell went wrong (sounds familiar, right?).
In this session, we are going to do a live demonstration of common Kubernetes failure scenarios, both app and infra related, and may the Gods of the demo be kind to us.
We will laugh a little and cry a little, as we cover Kubernetes monitoring, observability & troubleshooting best practices and talk about metrics, distributed tracing, logging, network visualization, and more. But cheer up! We’ll wrap up by introducing some helpful tools, in order to find and fix issues as fast as possible.
{kind=link}
{kind=link}
{kind=link}
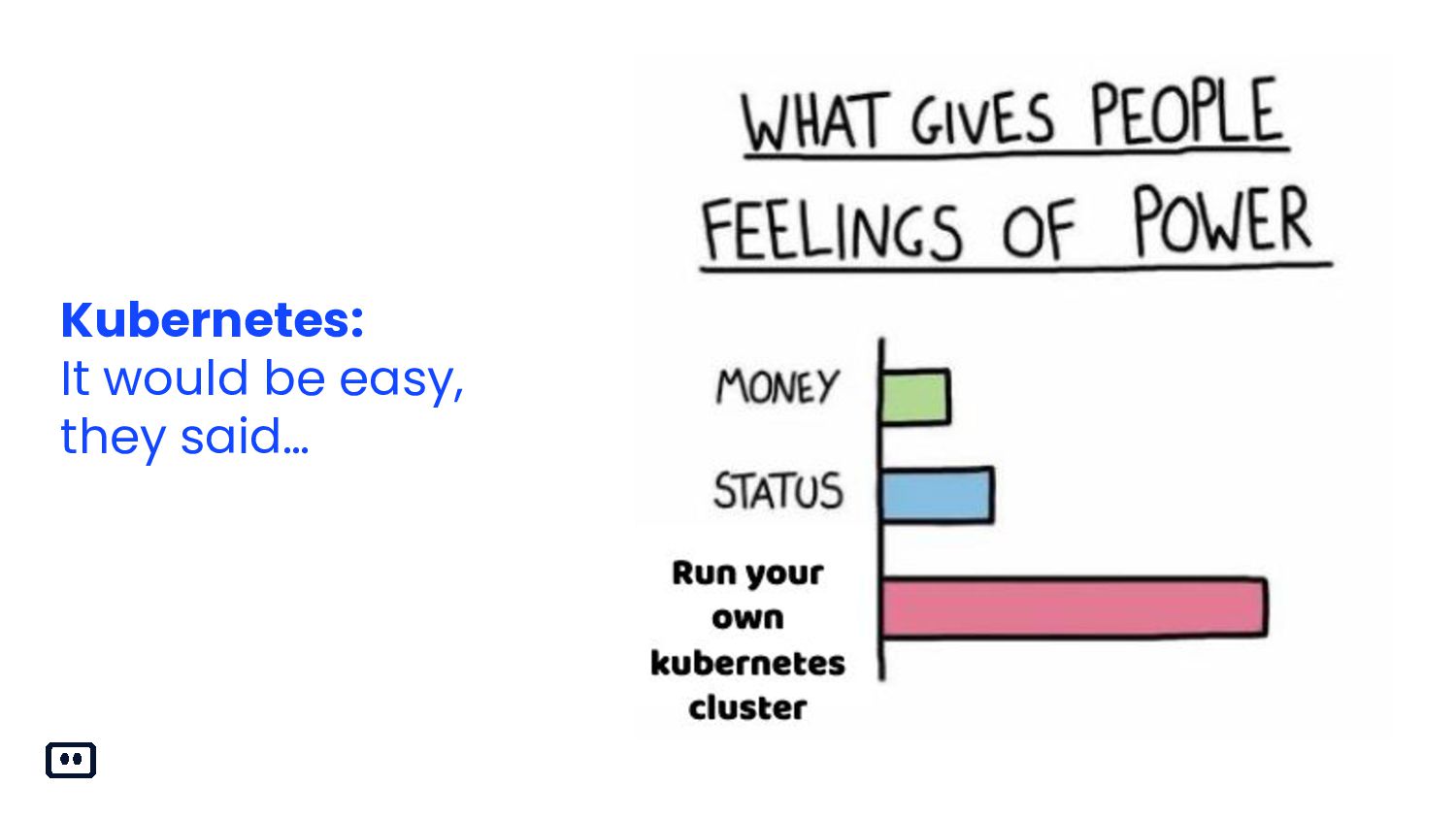{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
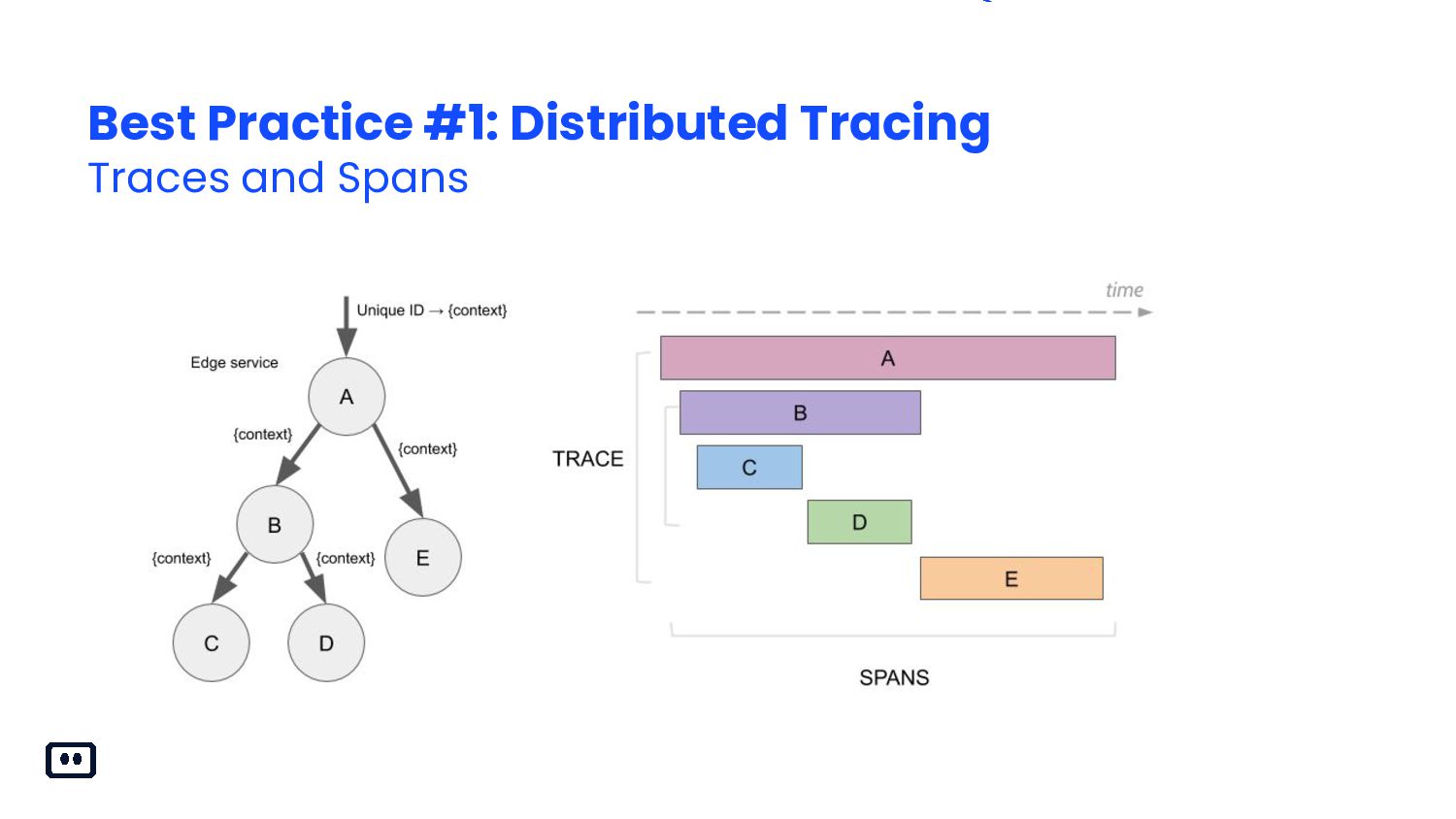{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}