Share
電子情報通信学会システム数理と応用研究会(2025年11月13日)で発表したスライドです.
https://ken.ieice.org/ken/paper/20251113vcon/
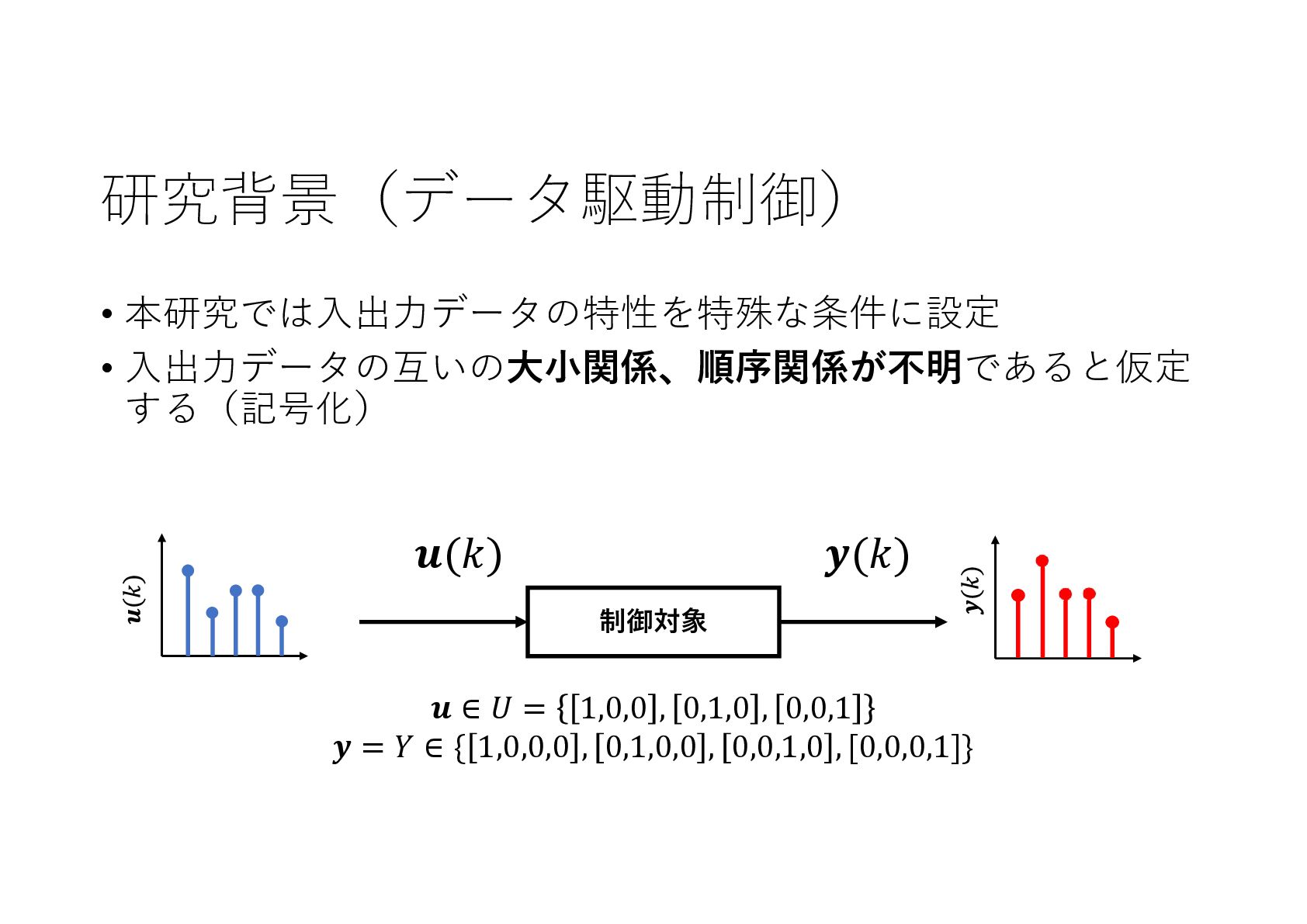
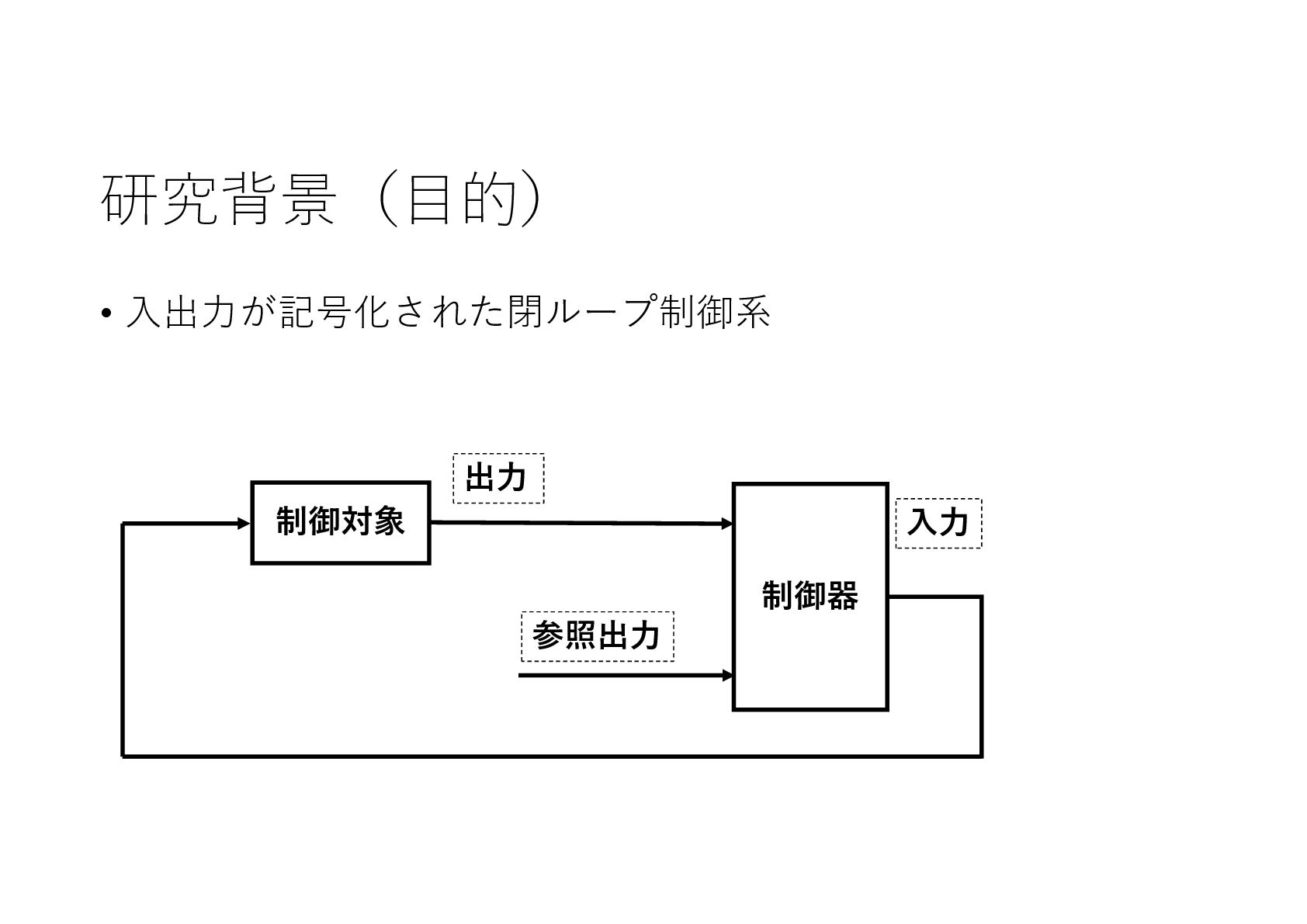
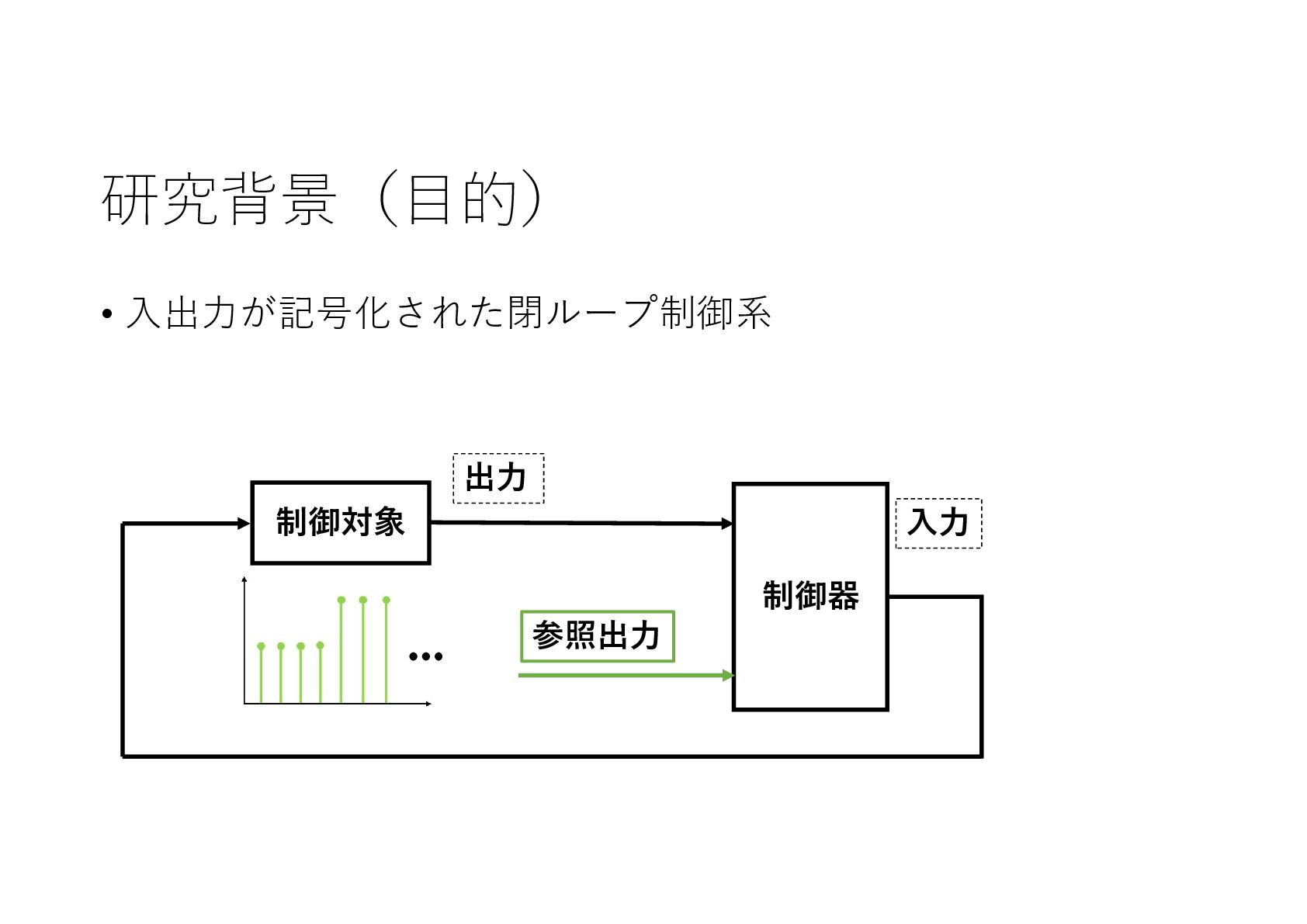
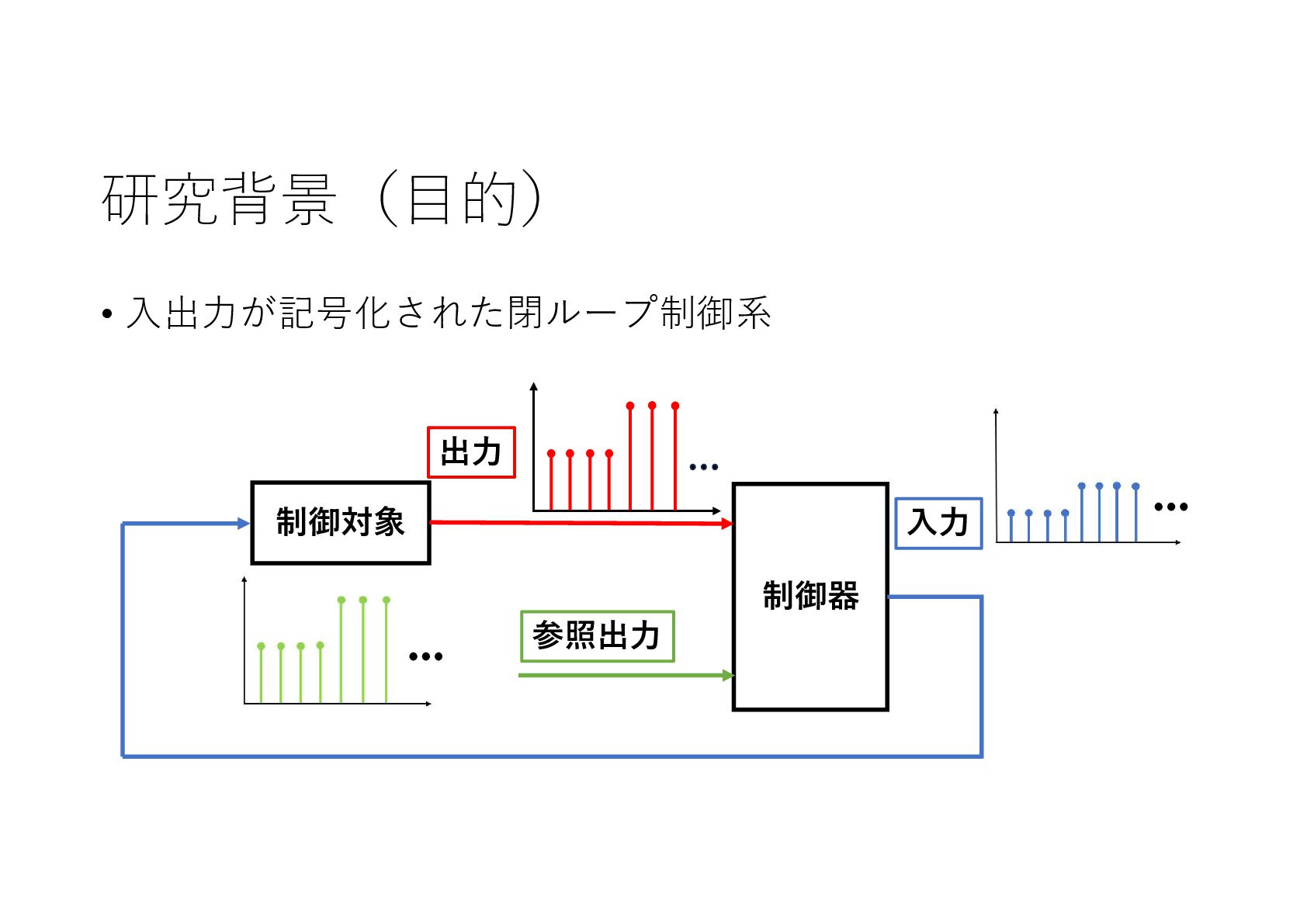
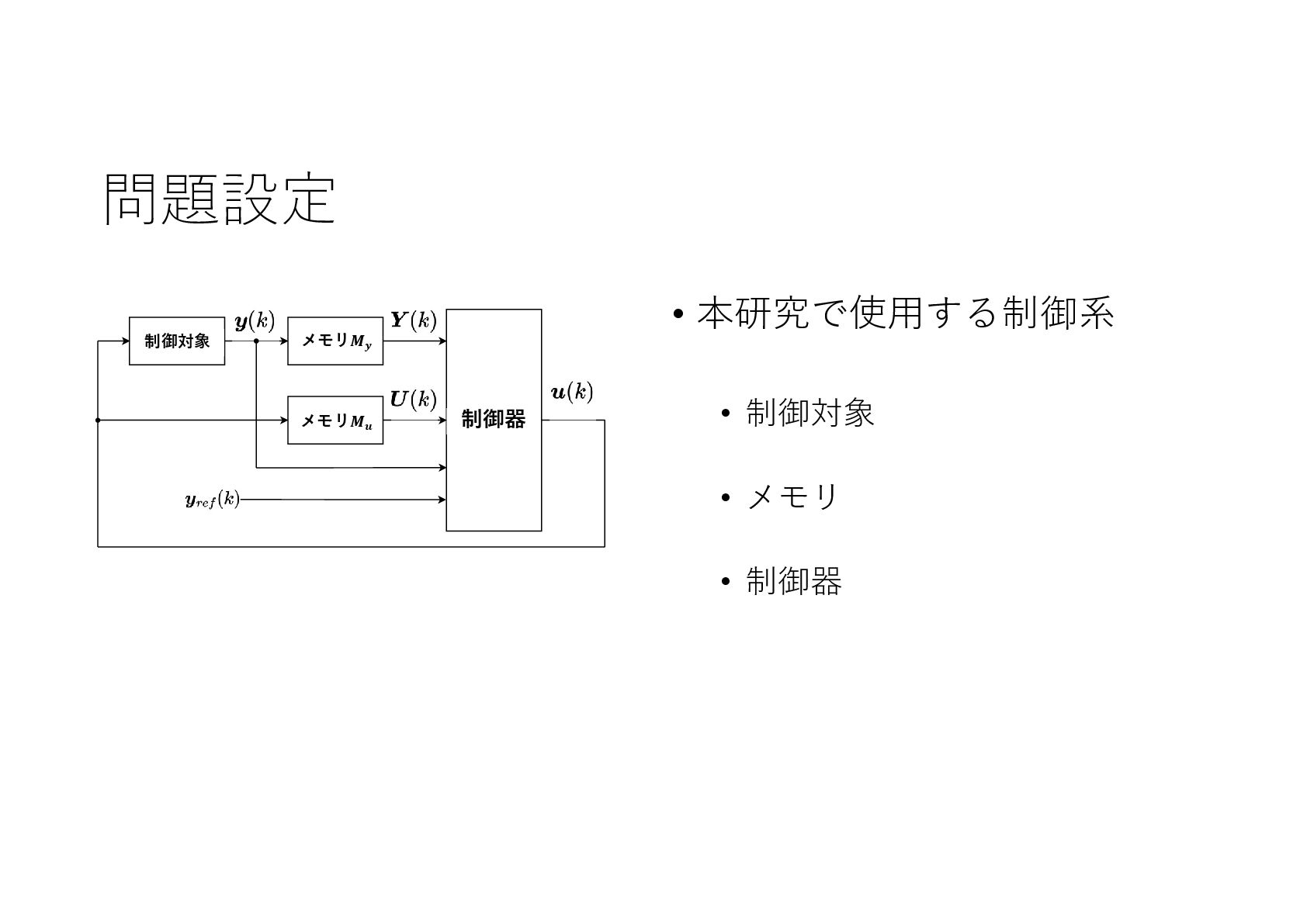
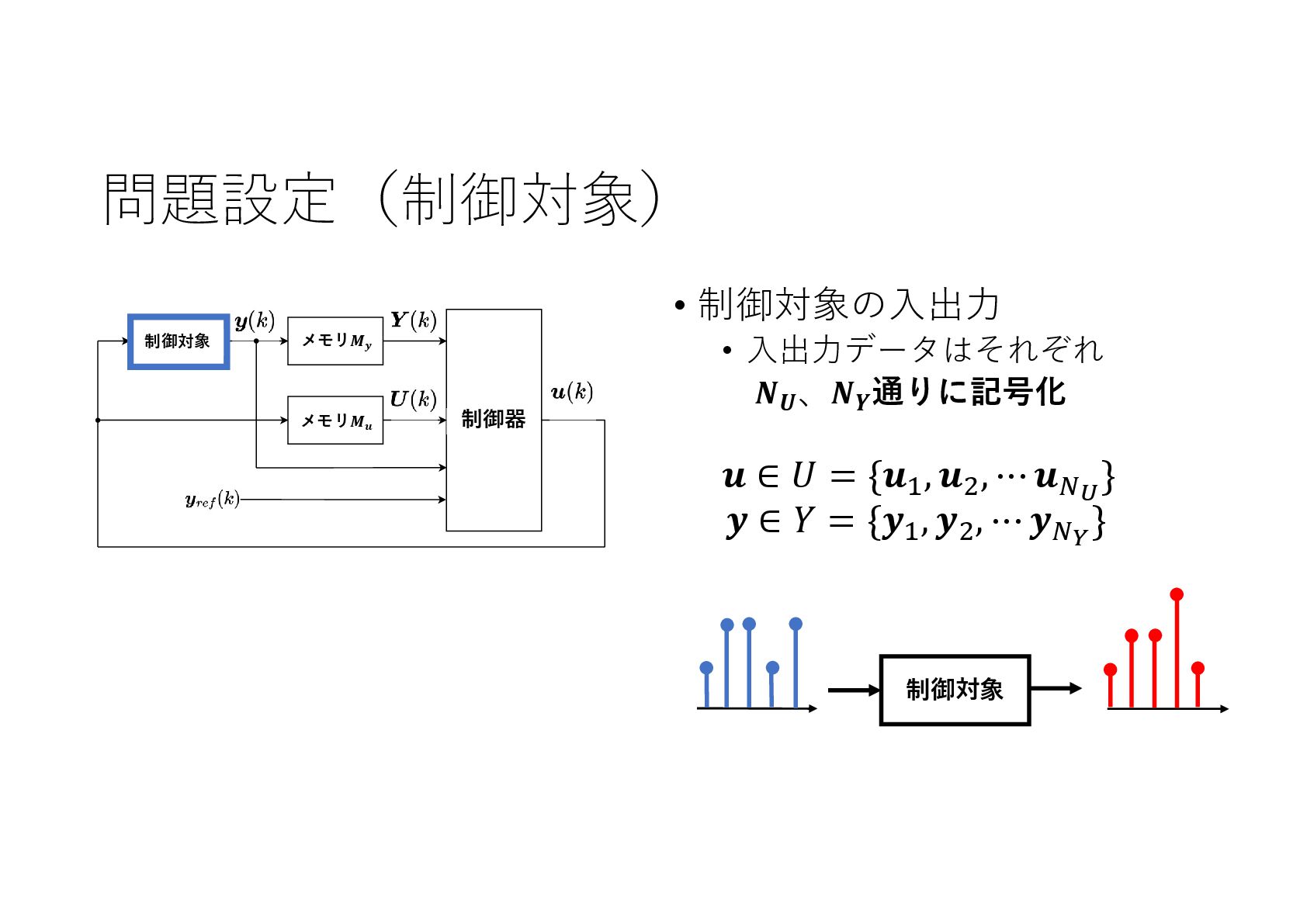
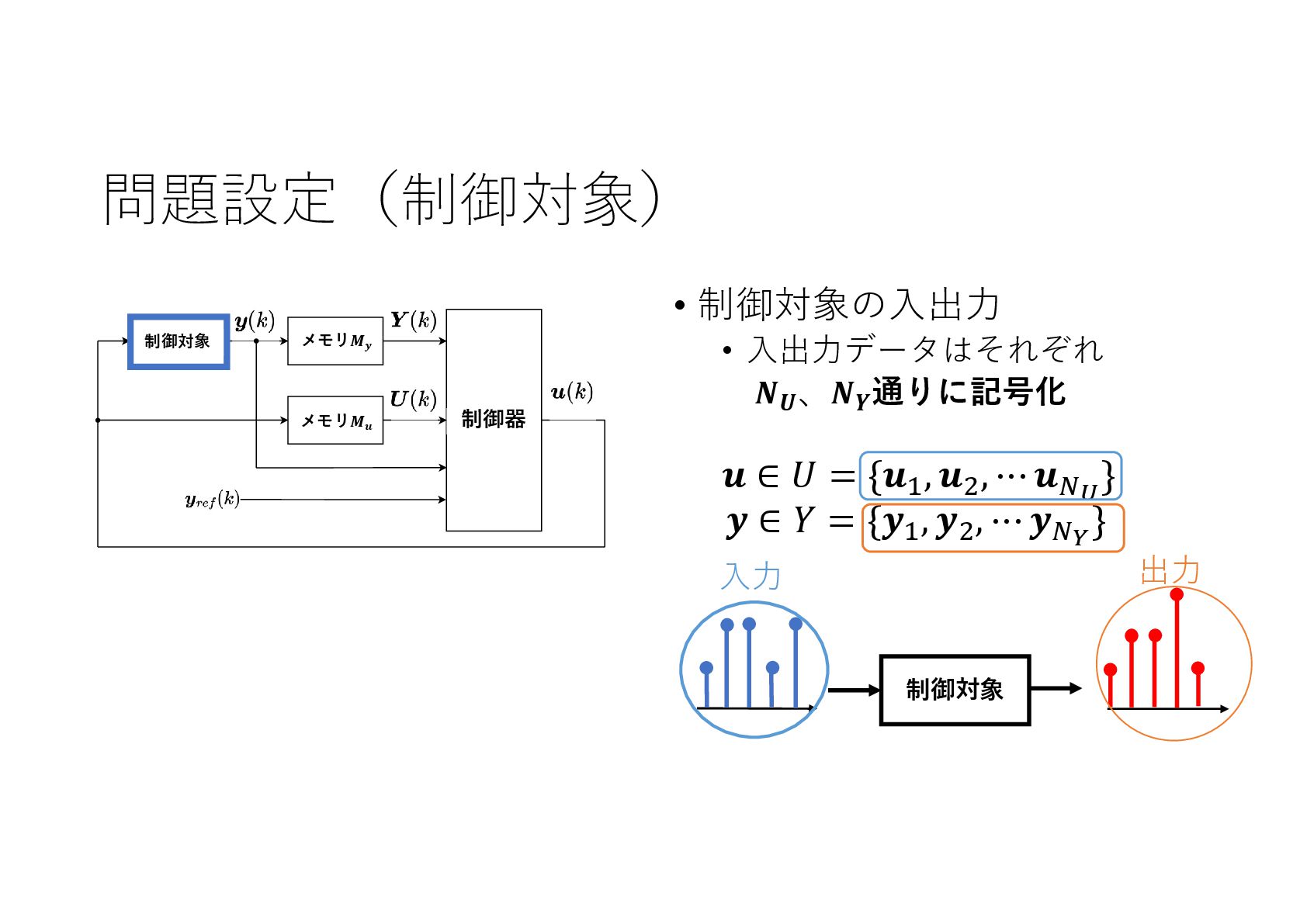
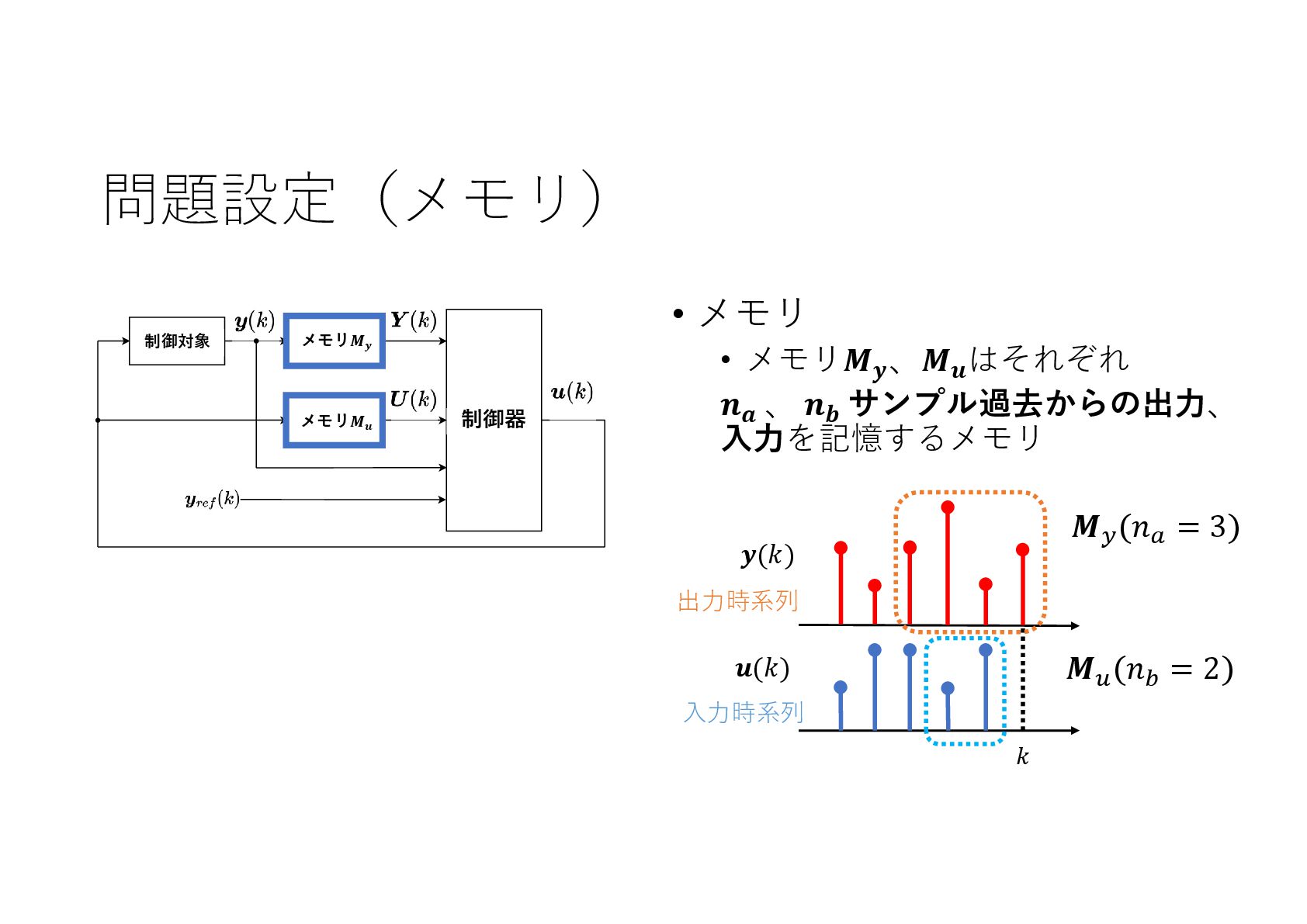
記号的な入出力を持つ動的なシステムに対し,機械学習による制御系設計をニューラルネットワークを利用して実現しました.
{kind=link}
{kind=link}
![研究背景(データ駆動制御) • 入出力データの特性によって様々な場面で応用が可能 • 入力が離散値で出力が連続値である場合は、電力変換や化学プ ラントの制御器設計に応用可能[2] [2]小中英嗣. 機械学習に基づく離散値制御系に対する制御器設計. 電気学会論文誌C 制御対象](https://files.speakerdeck.com/presentations/2f6362fb4d194edd9ff1d941dac9f0f4/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
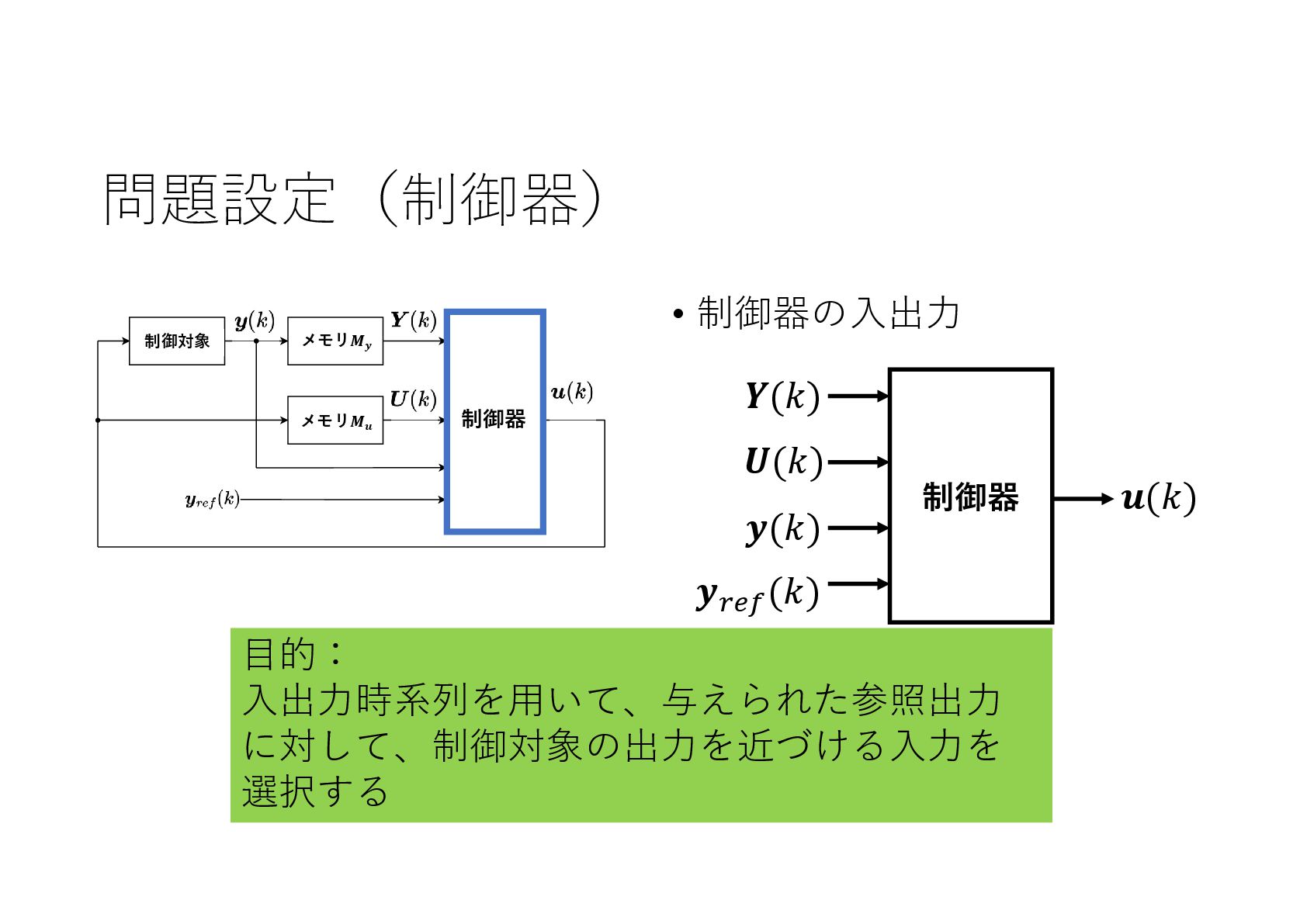{kind=link}
{kind=link}
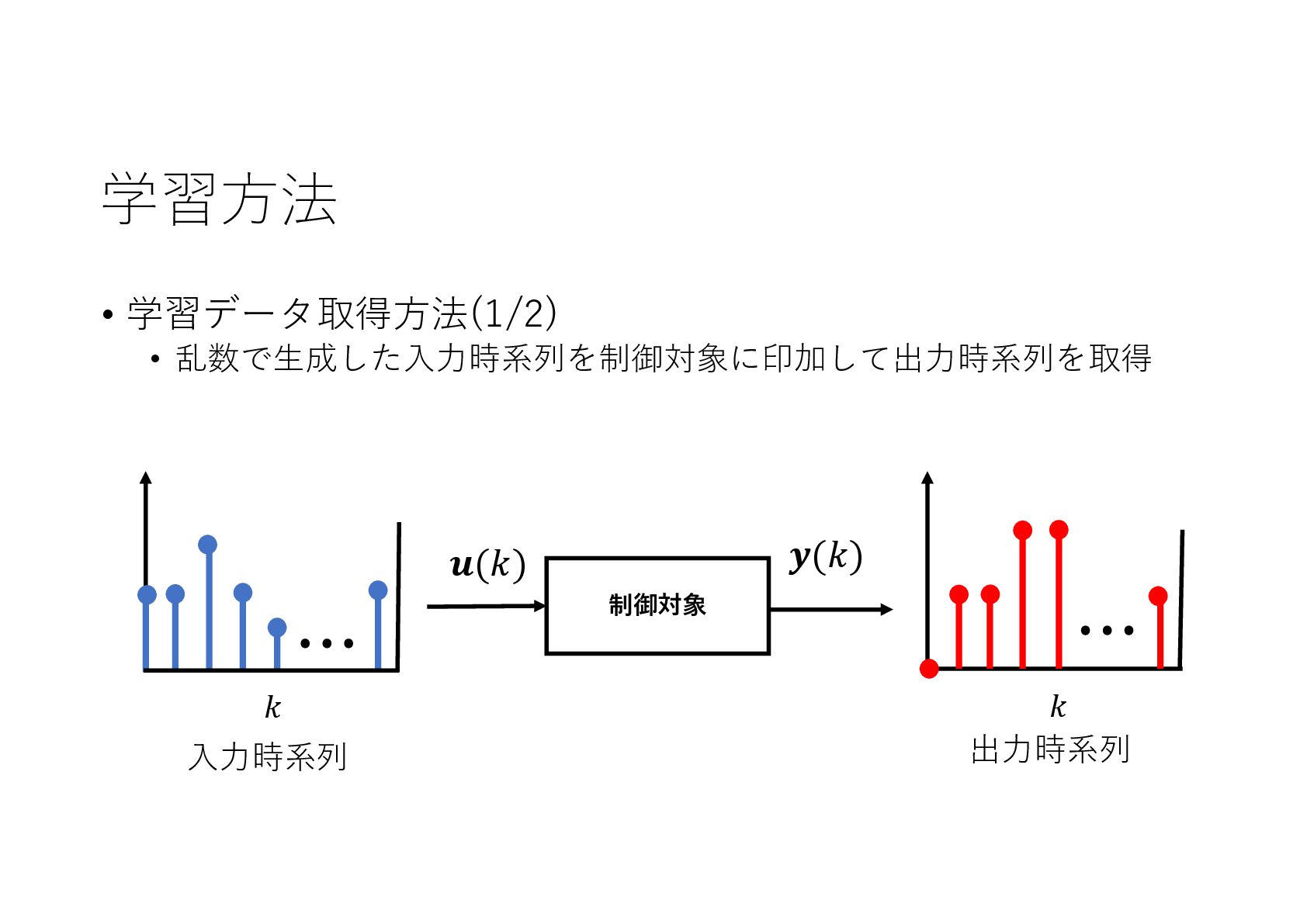{kind=link}
{kind=link}
{kind=link}
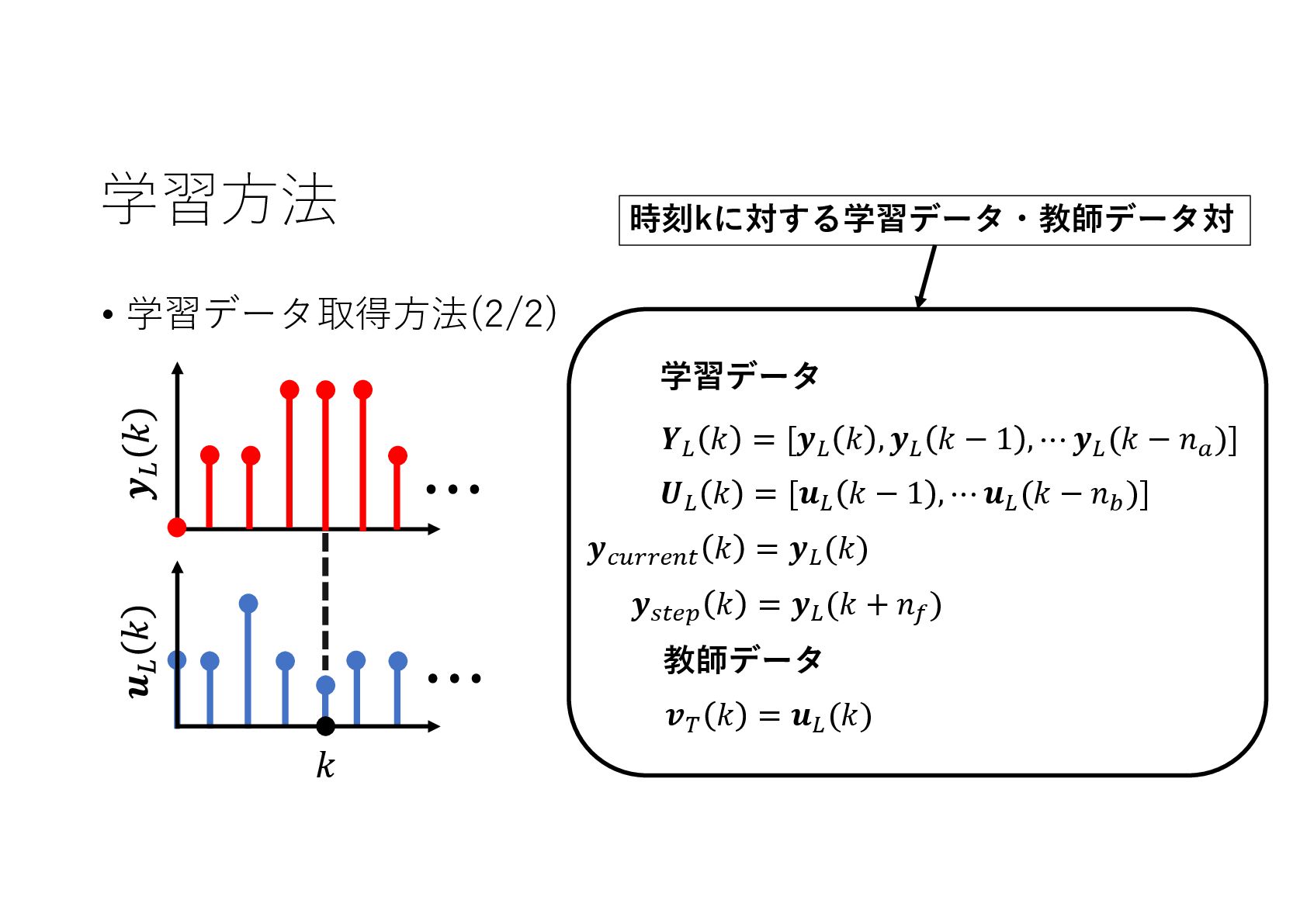{kind=link}
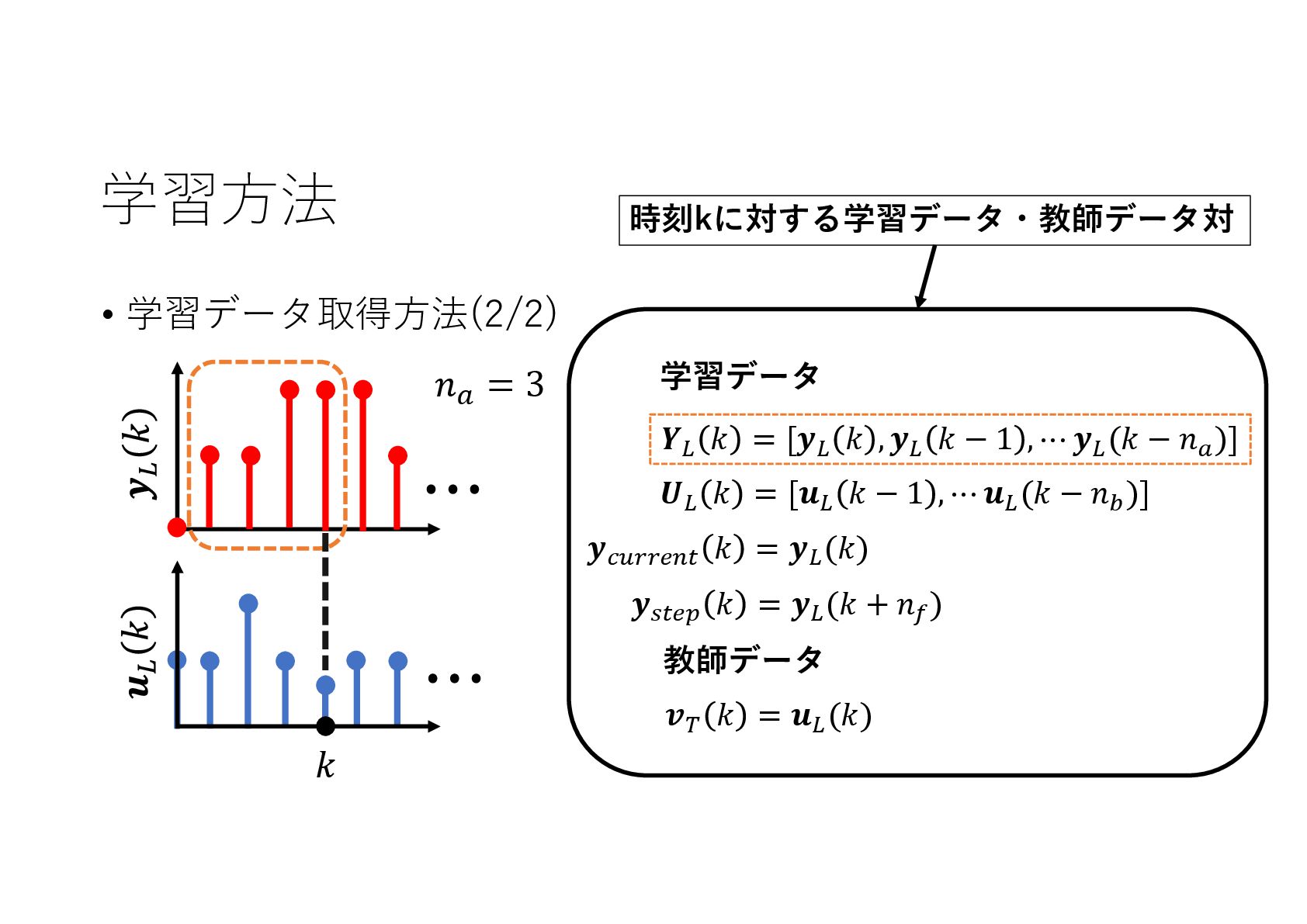{kind=link}
{kind=link}
{kind=link}
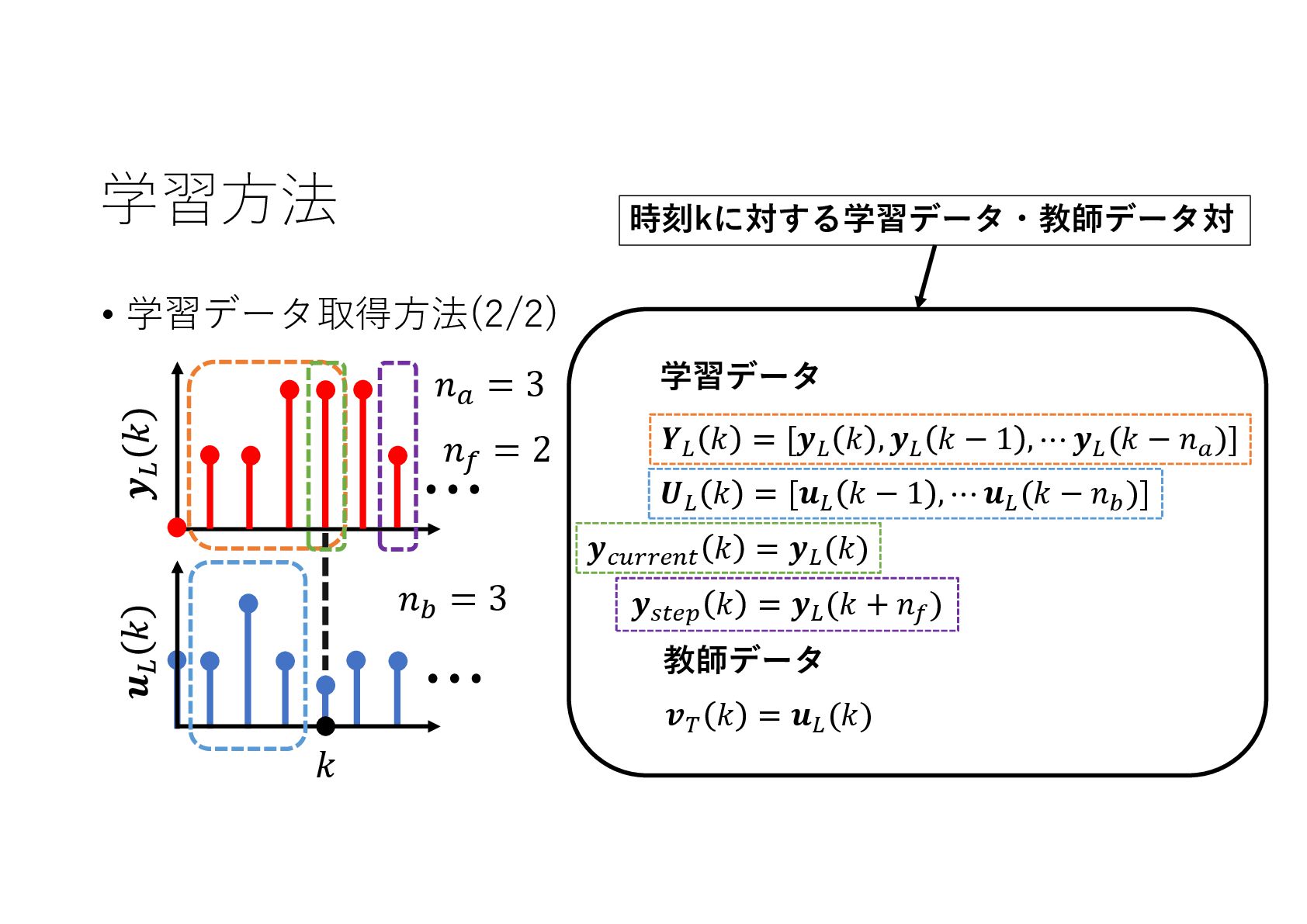{kind=link}
{kind=link}
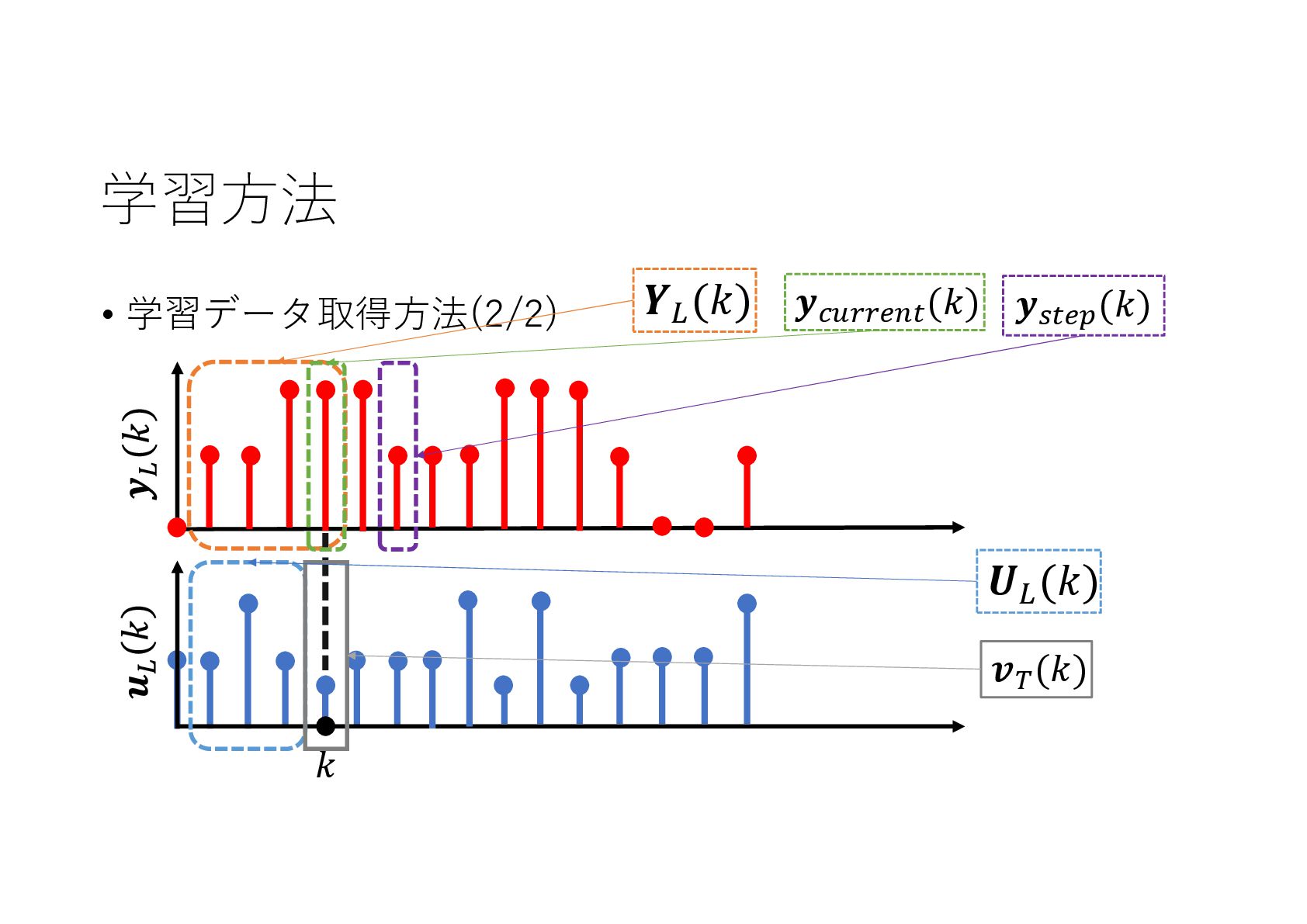{kind=link}
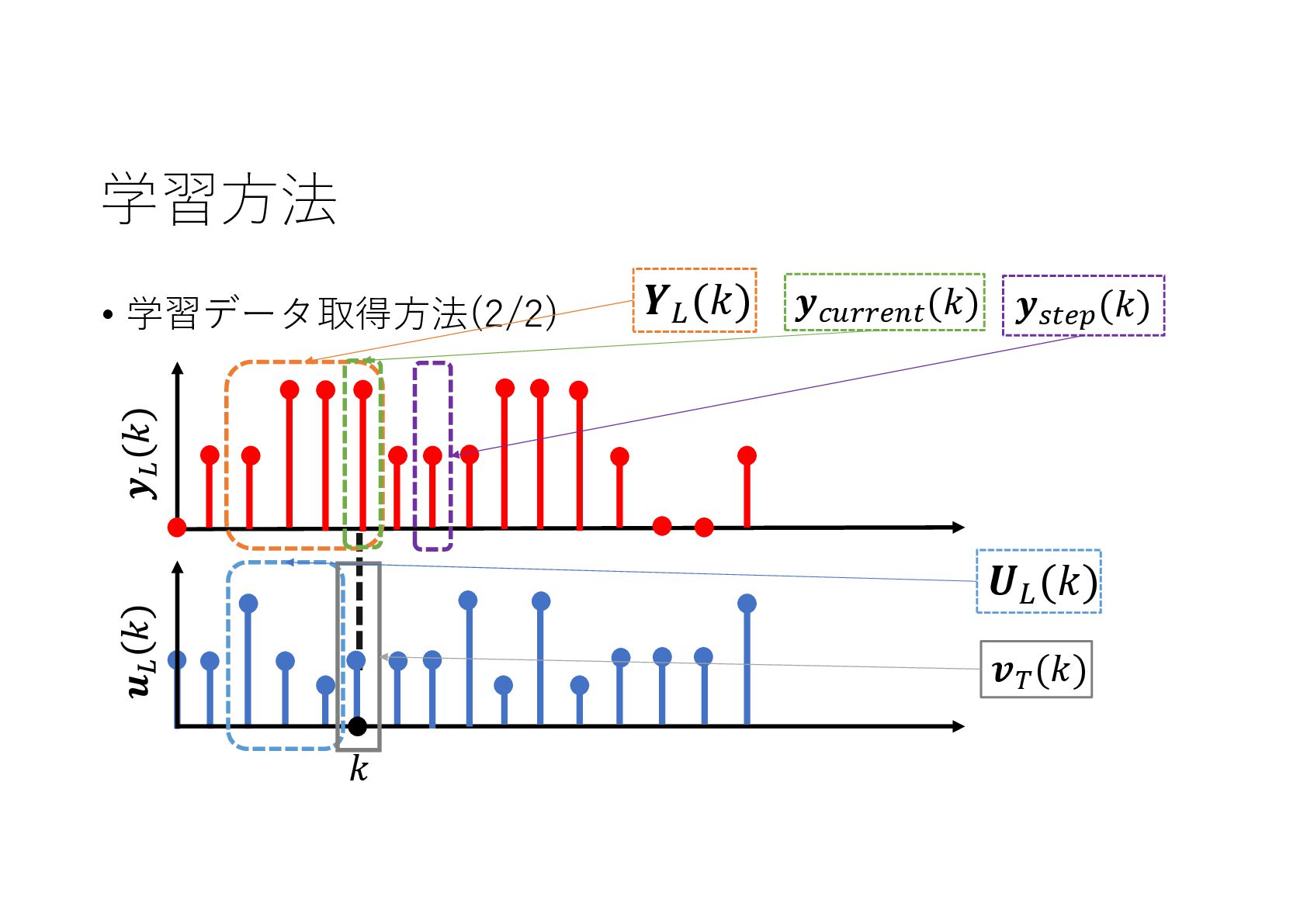{kind=link}
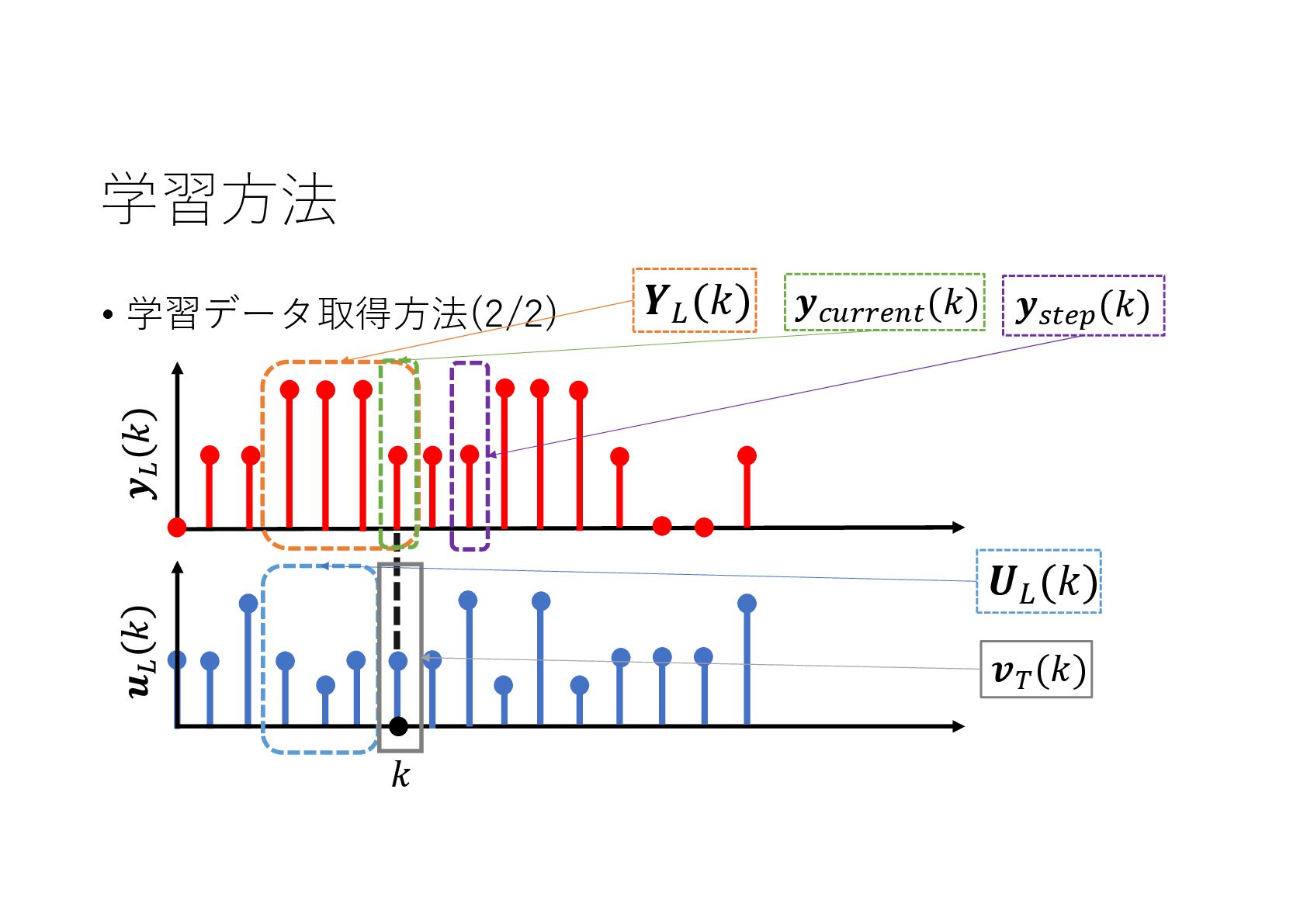{kind=link}
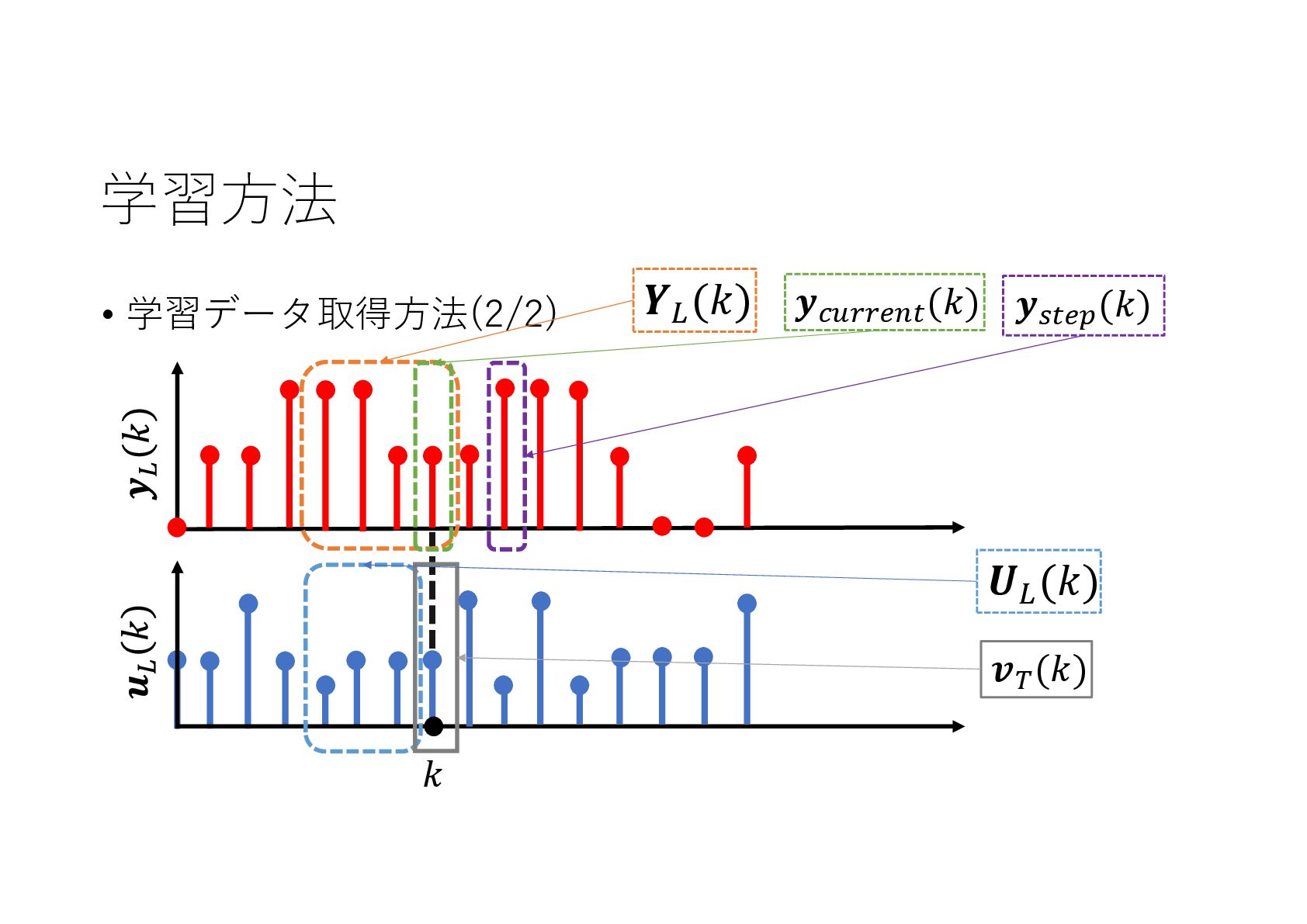{kind=link}
{kind=link}
{kind=link}
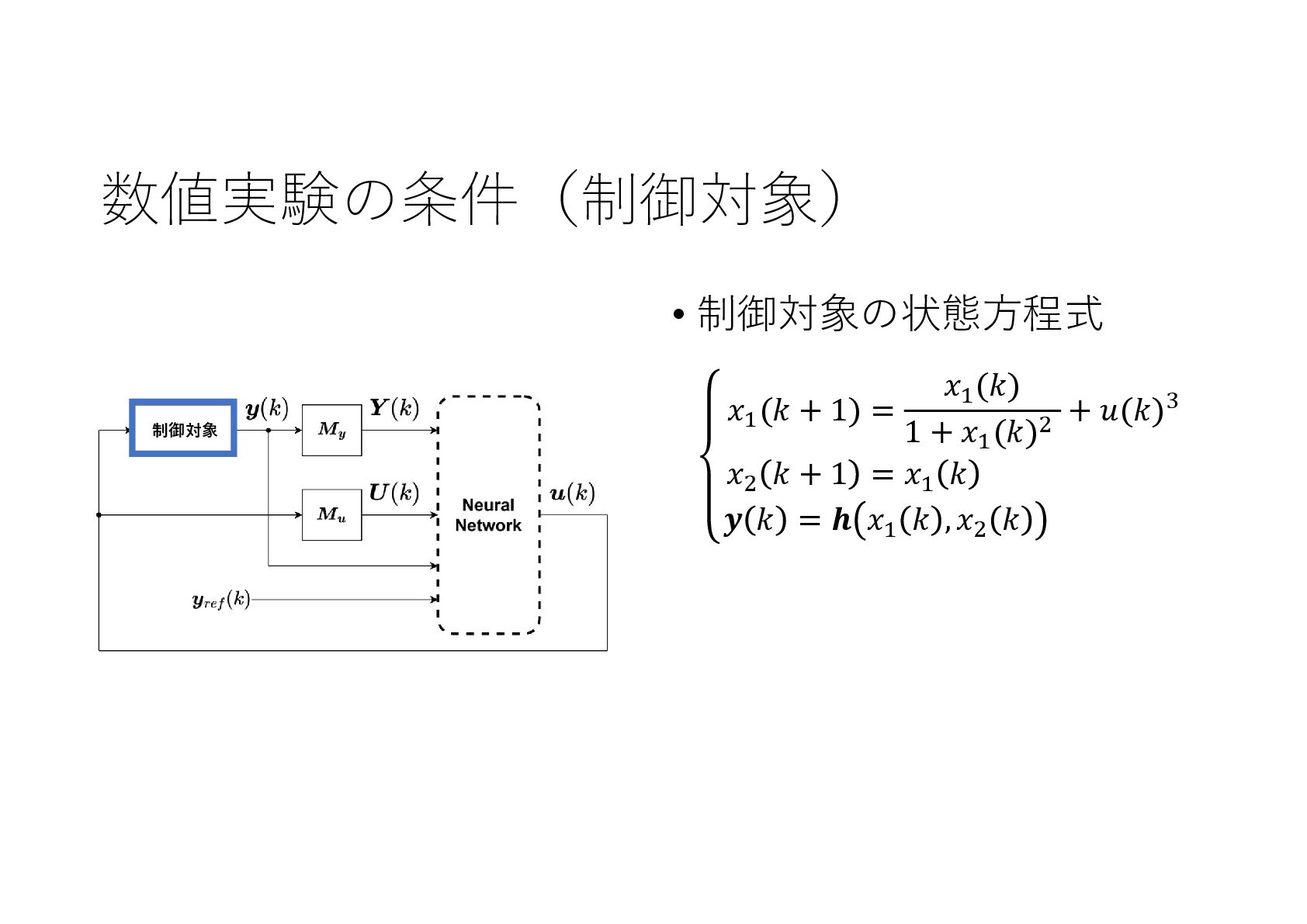{kind=link}
{kind=link}
{kind=link}
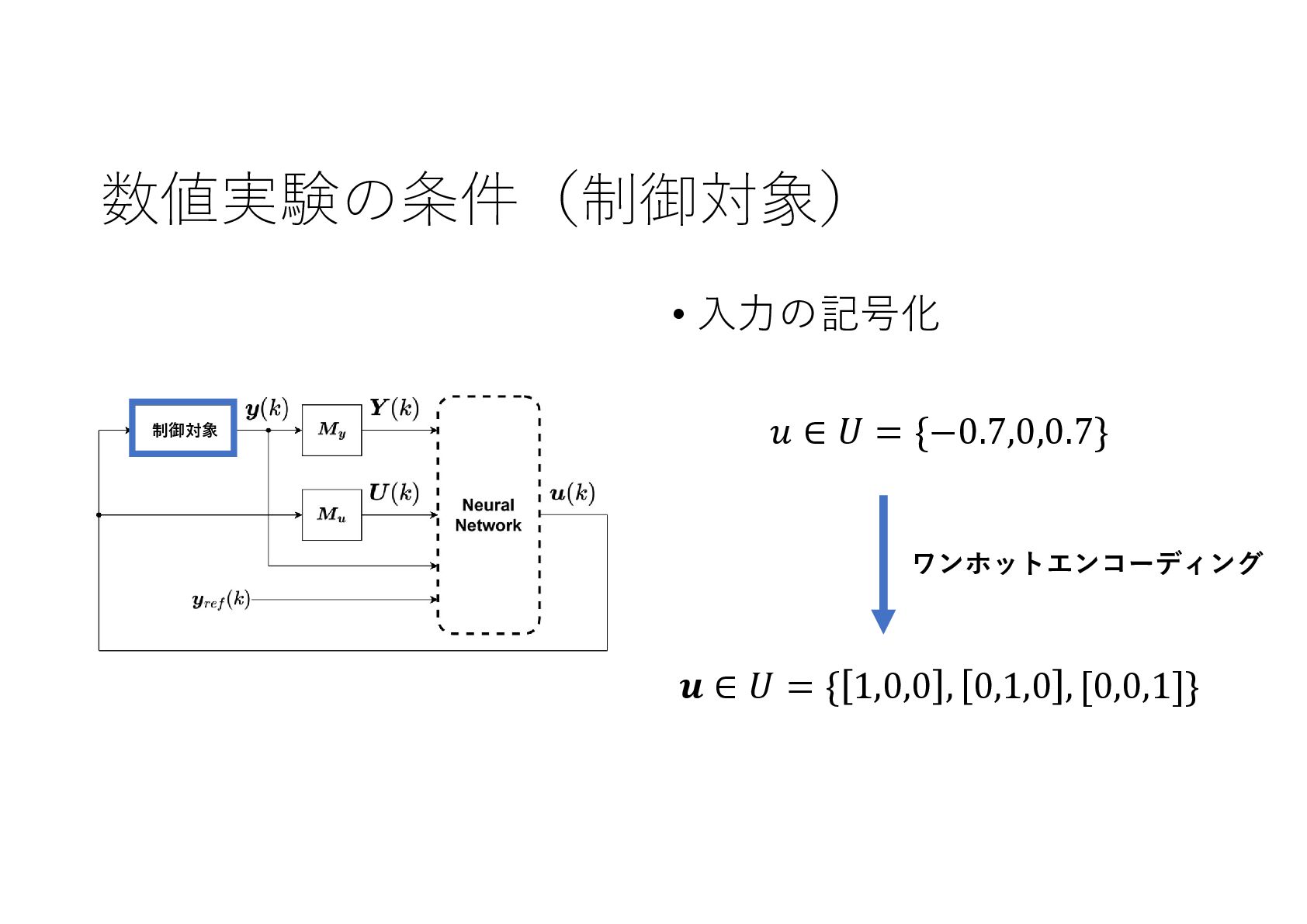{kind=link}
{kind=link}
{kind=link}
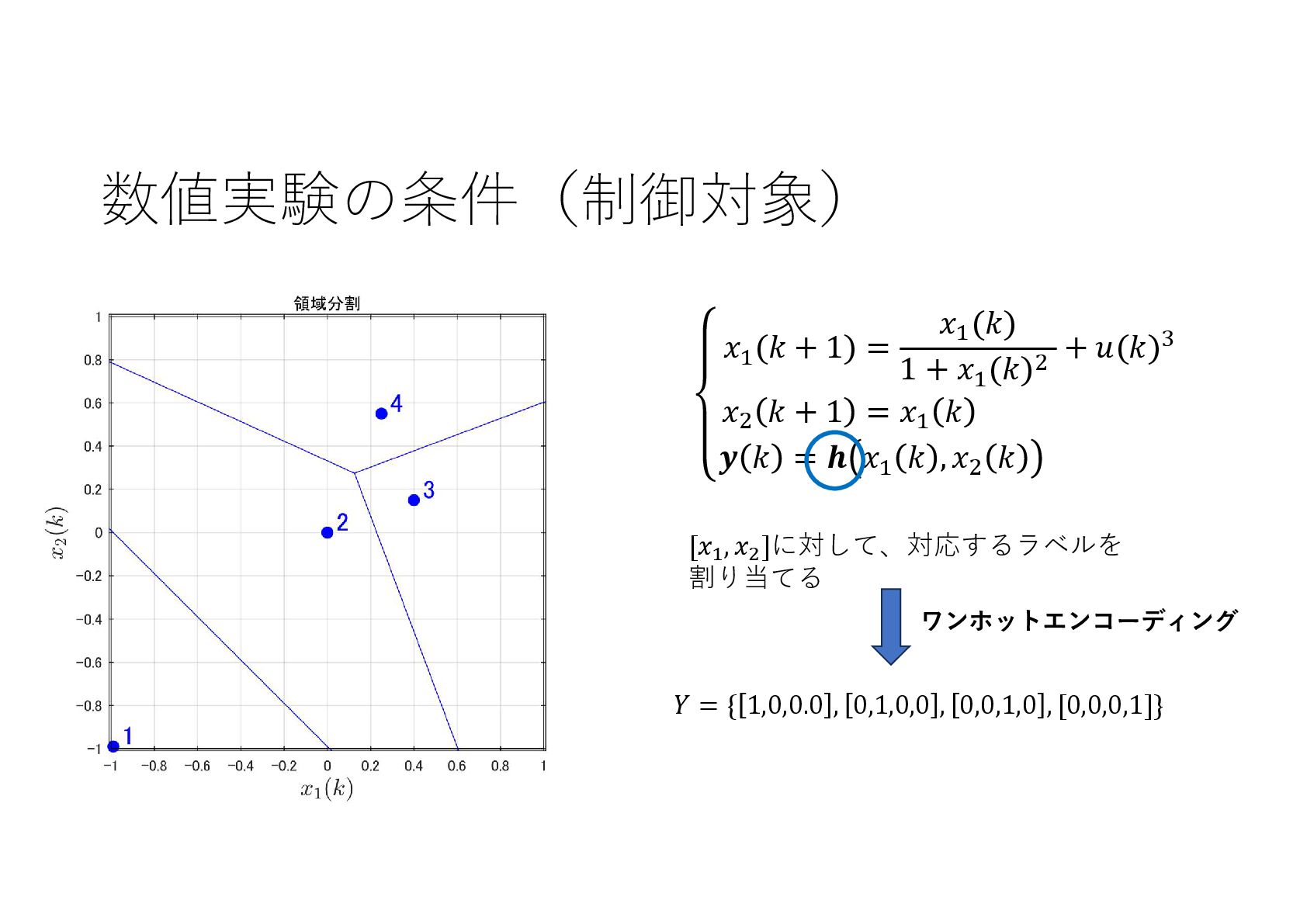{kind=link}
{kind=link}
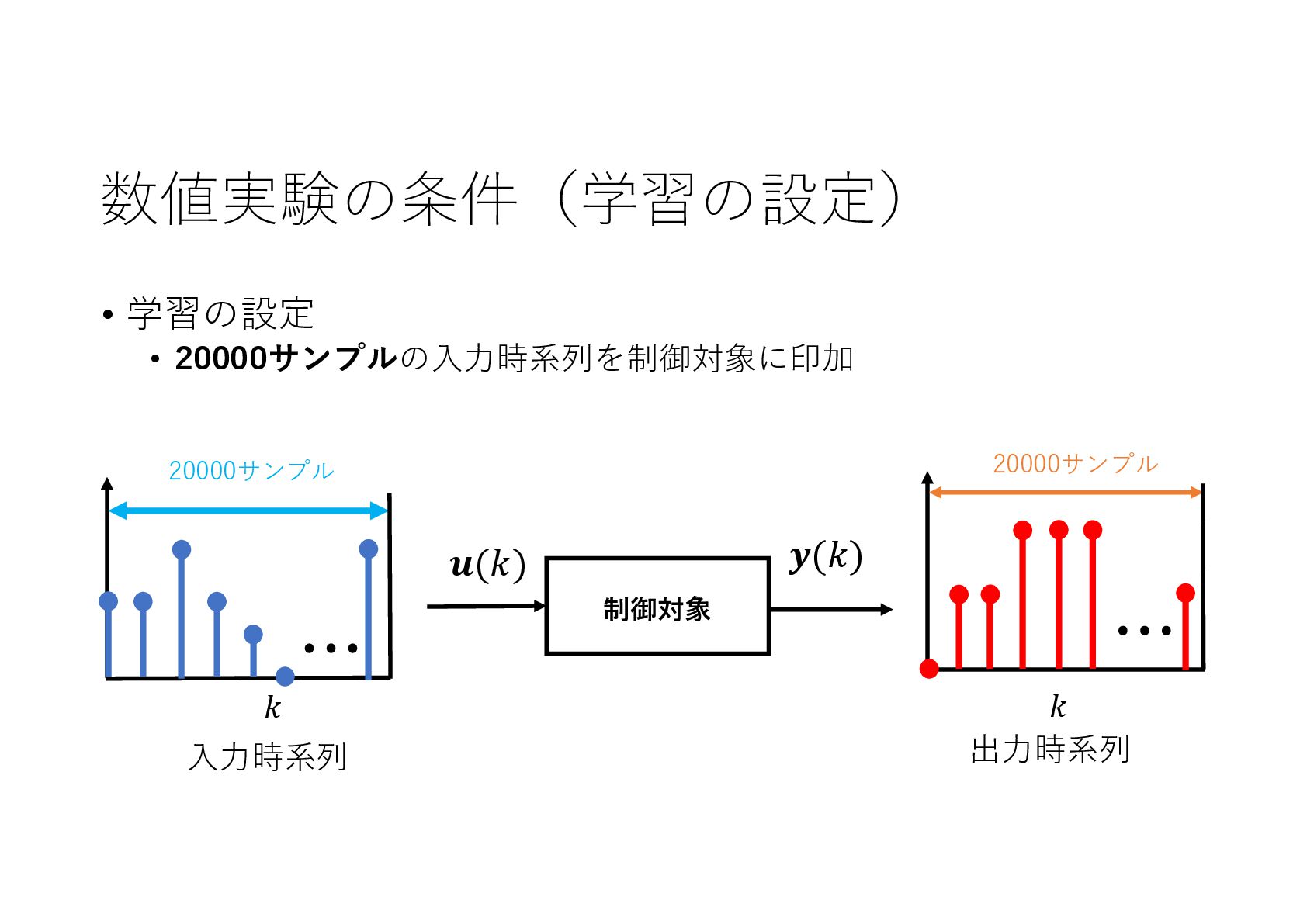{kind=link}
{kind=link}
{kind=link}
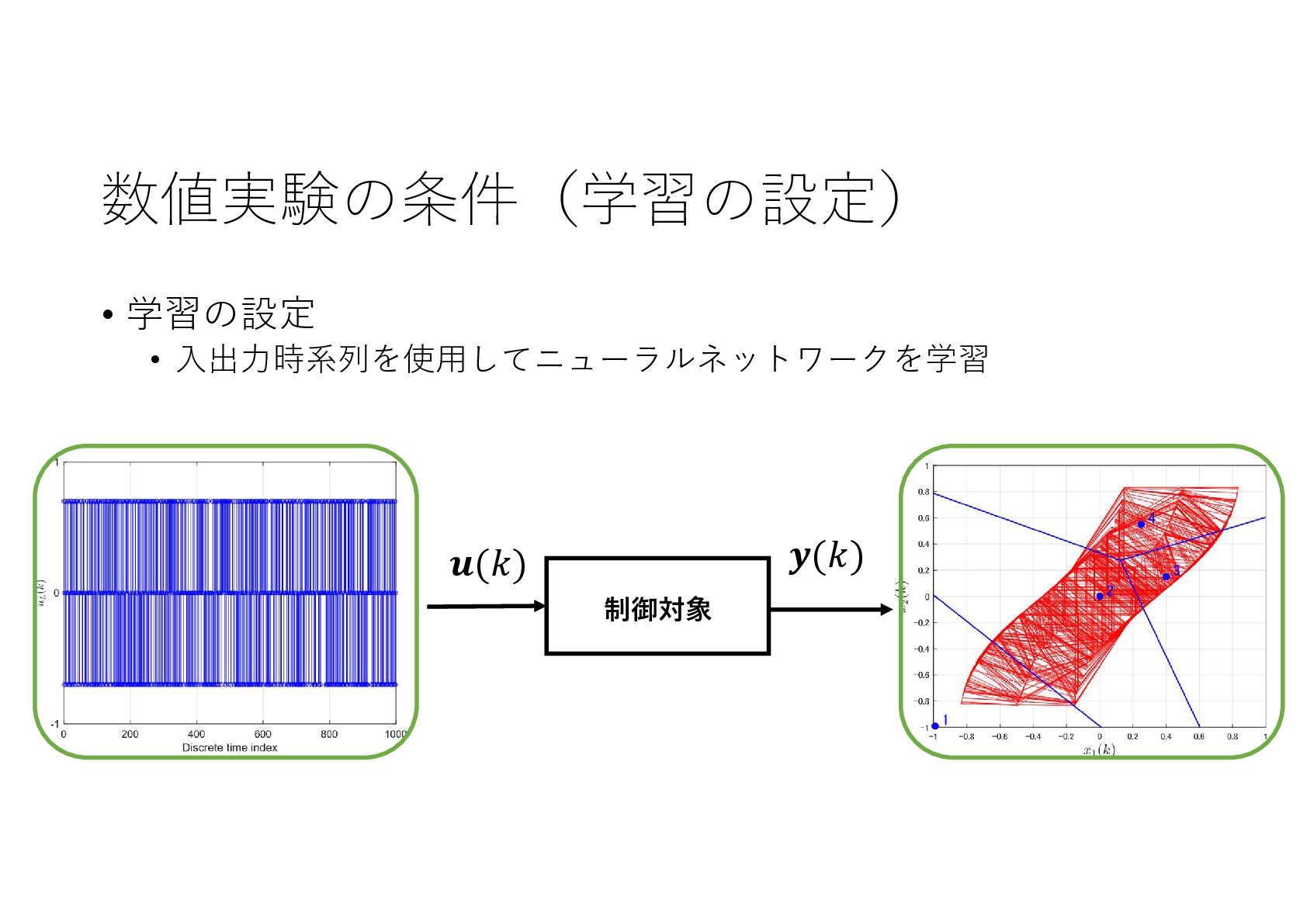{kind=link}
{kind=link}
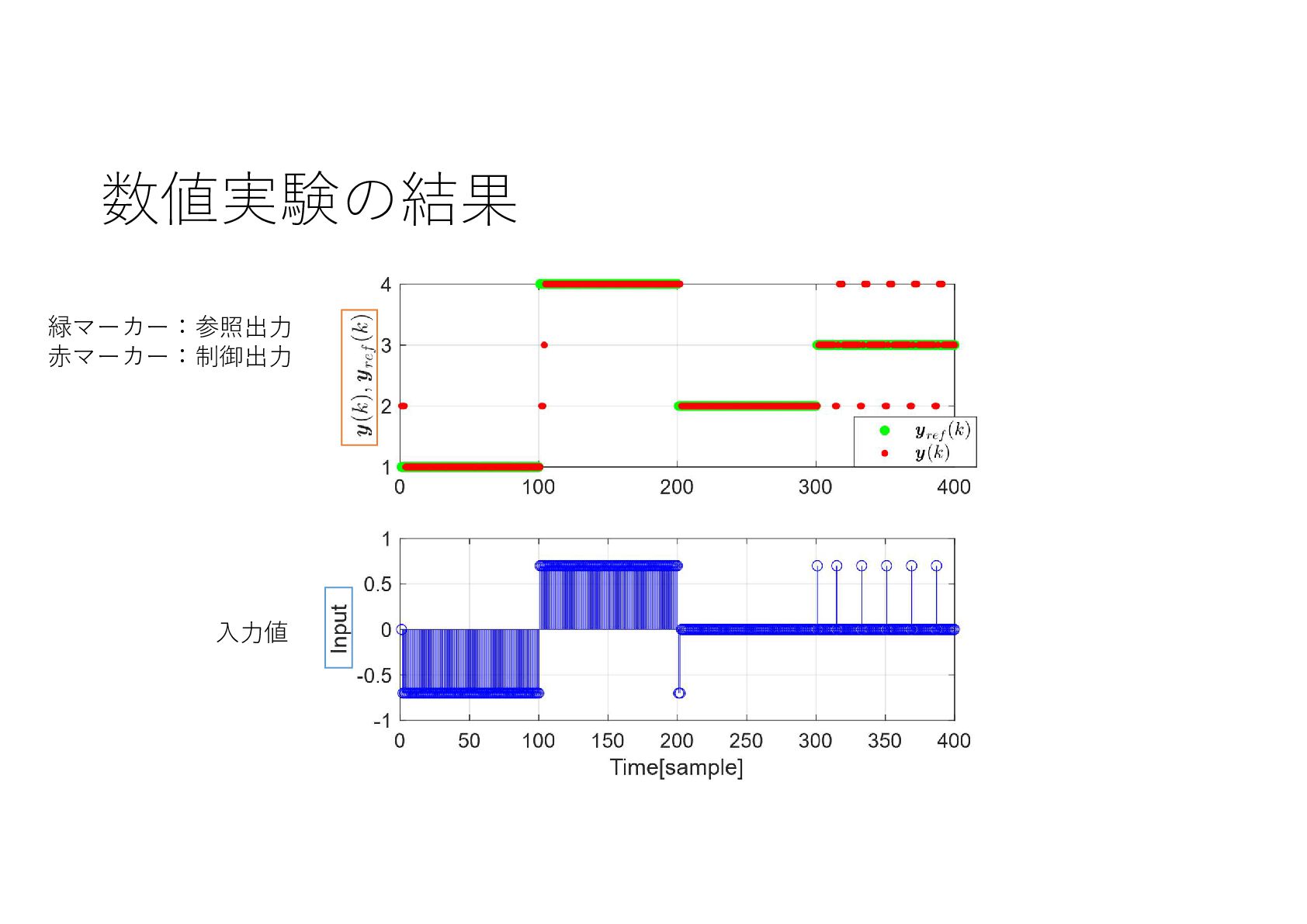{kind=link}
{kind=link}
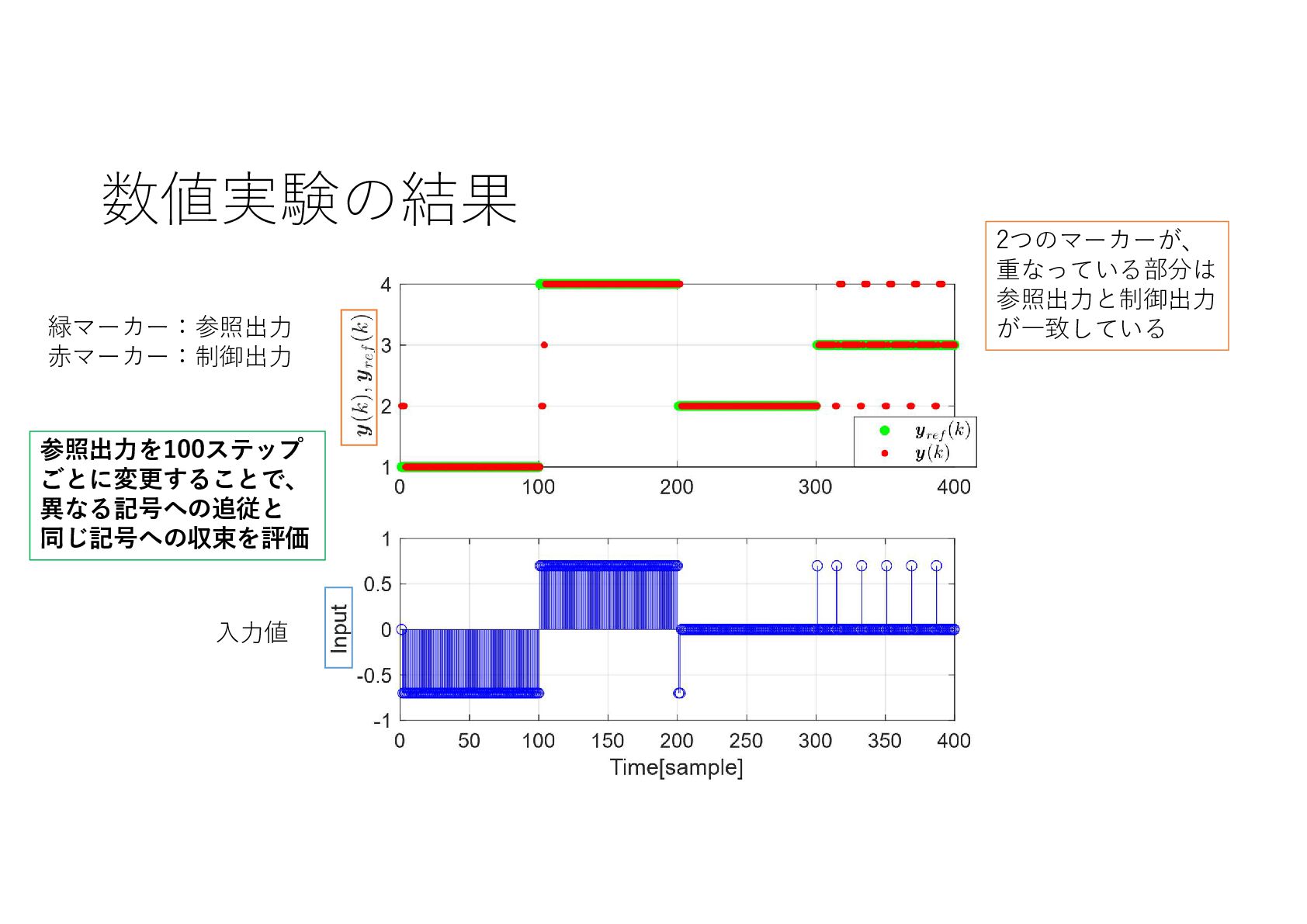{kind=link}
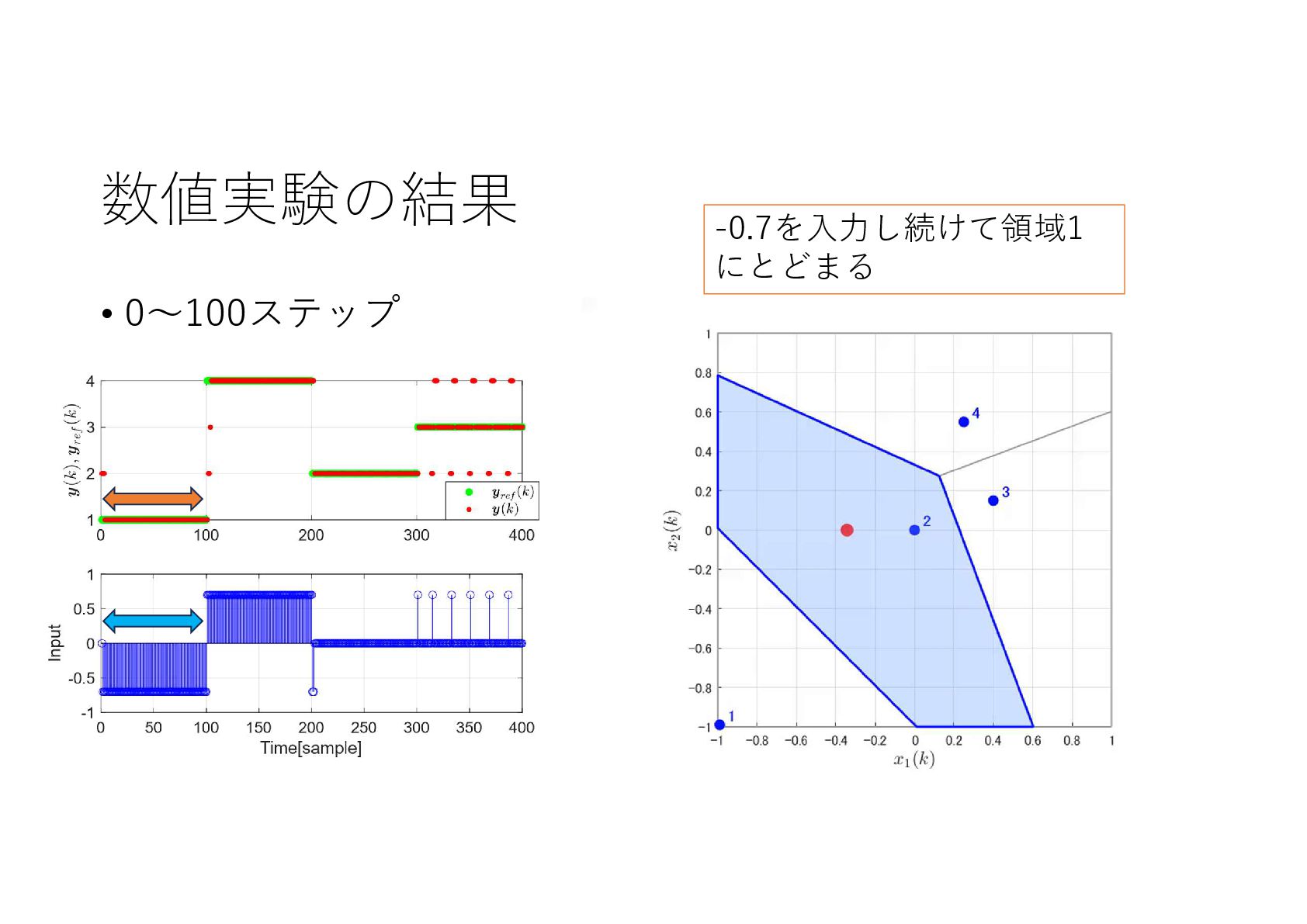{kind=link}
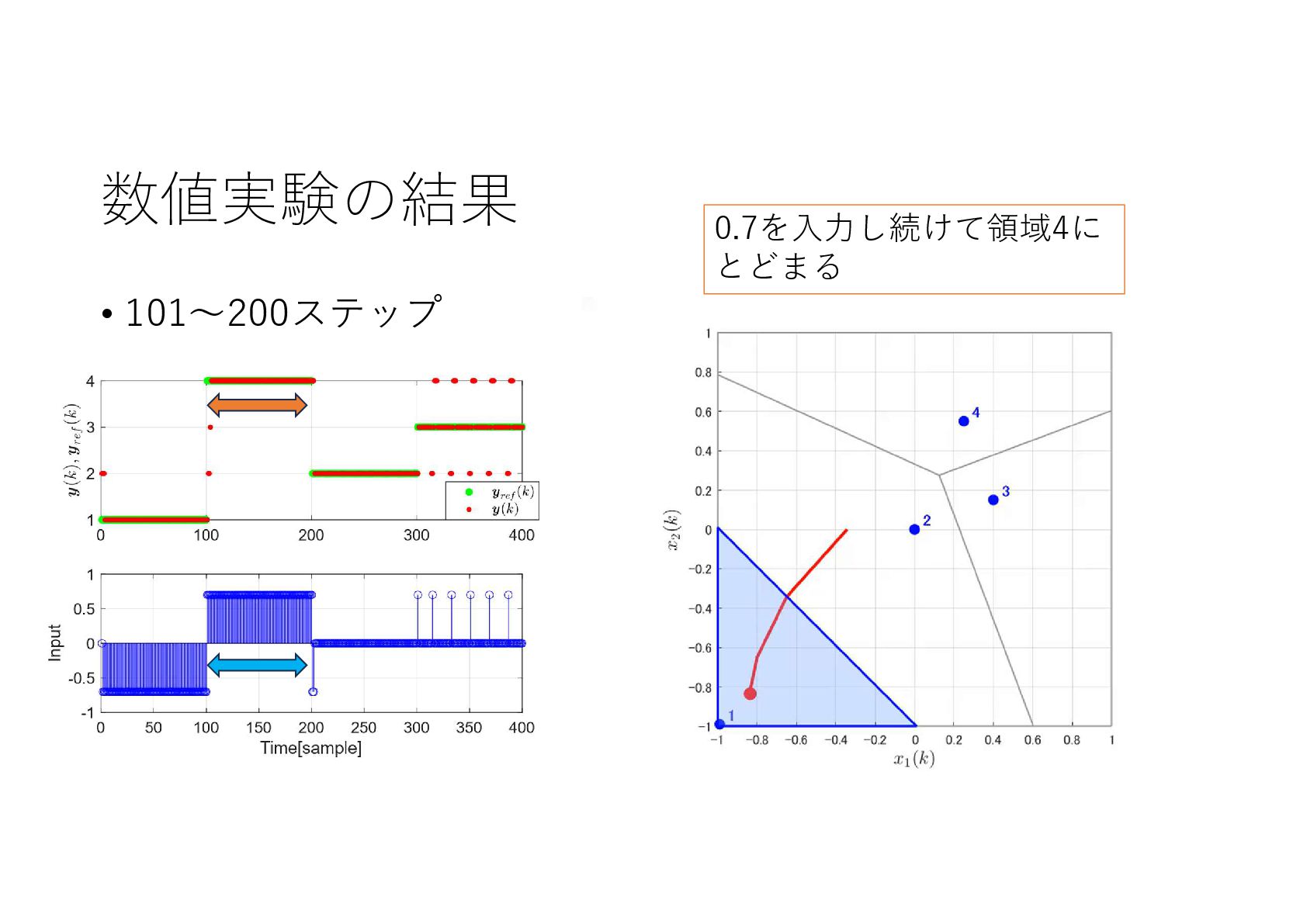{kind=link}
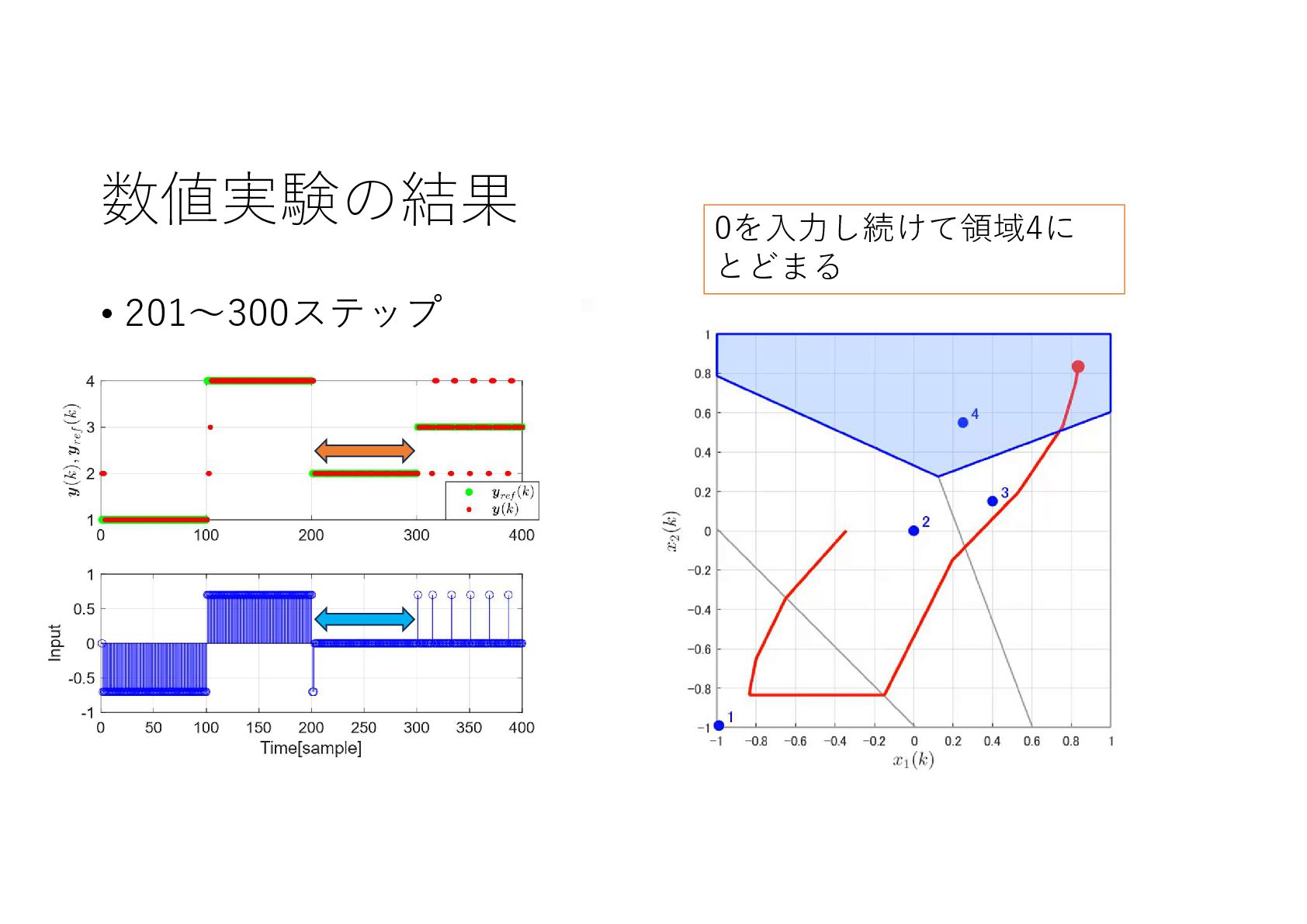{kind=link}
{kind=link}
{kind=link}
{kind=link}