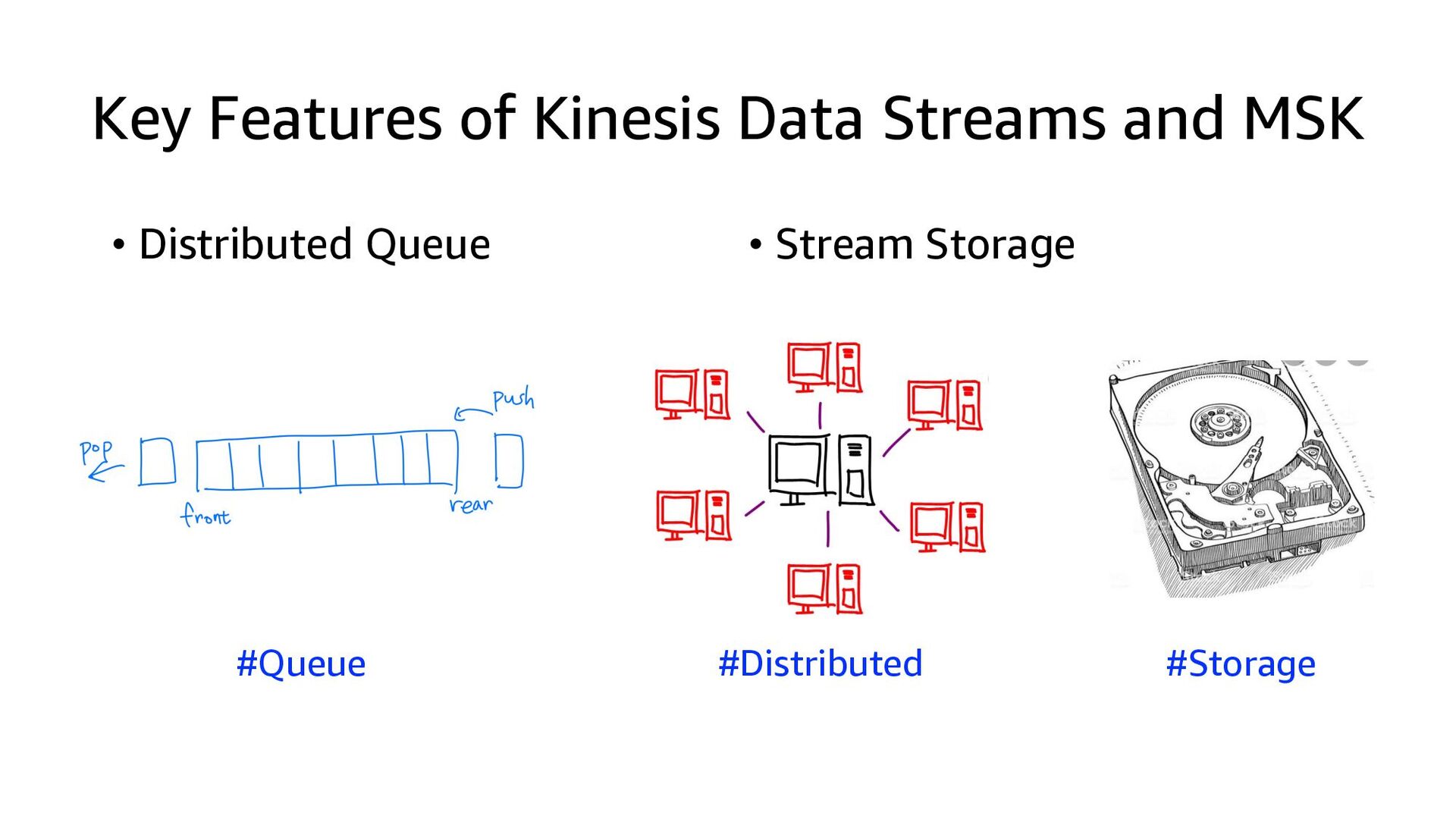
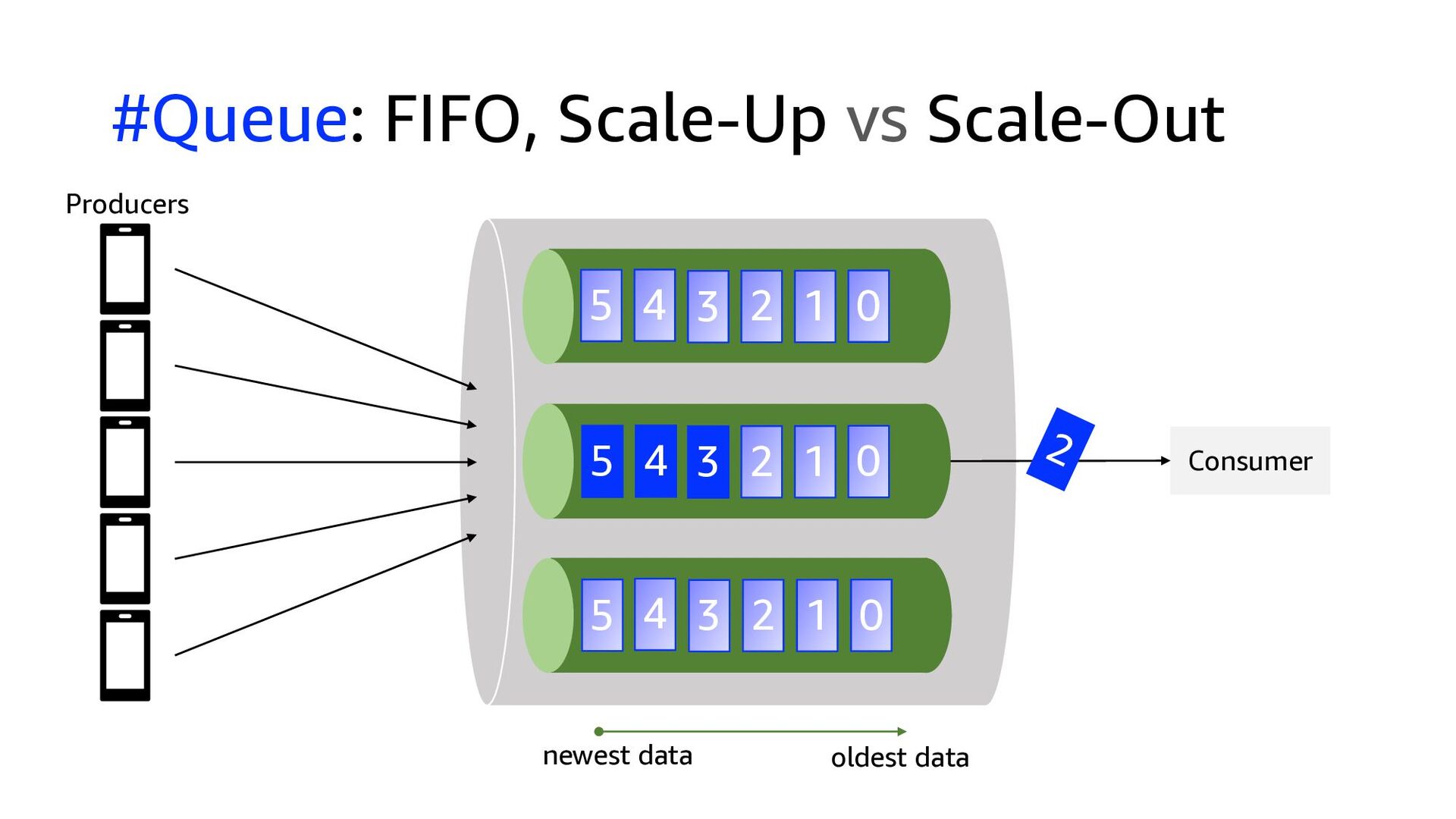
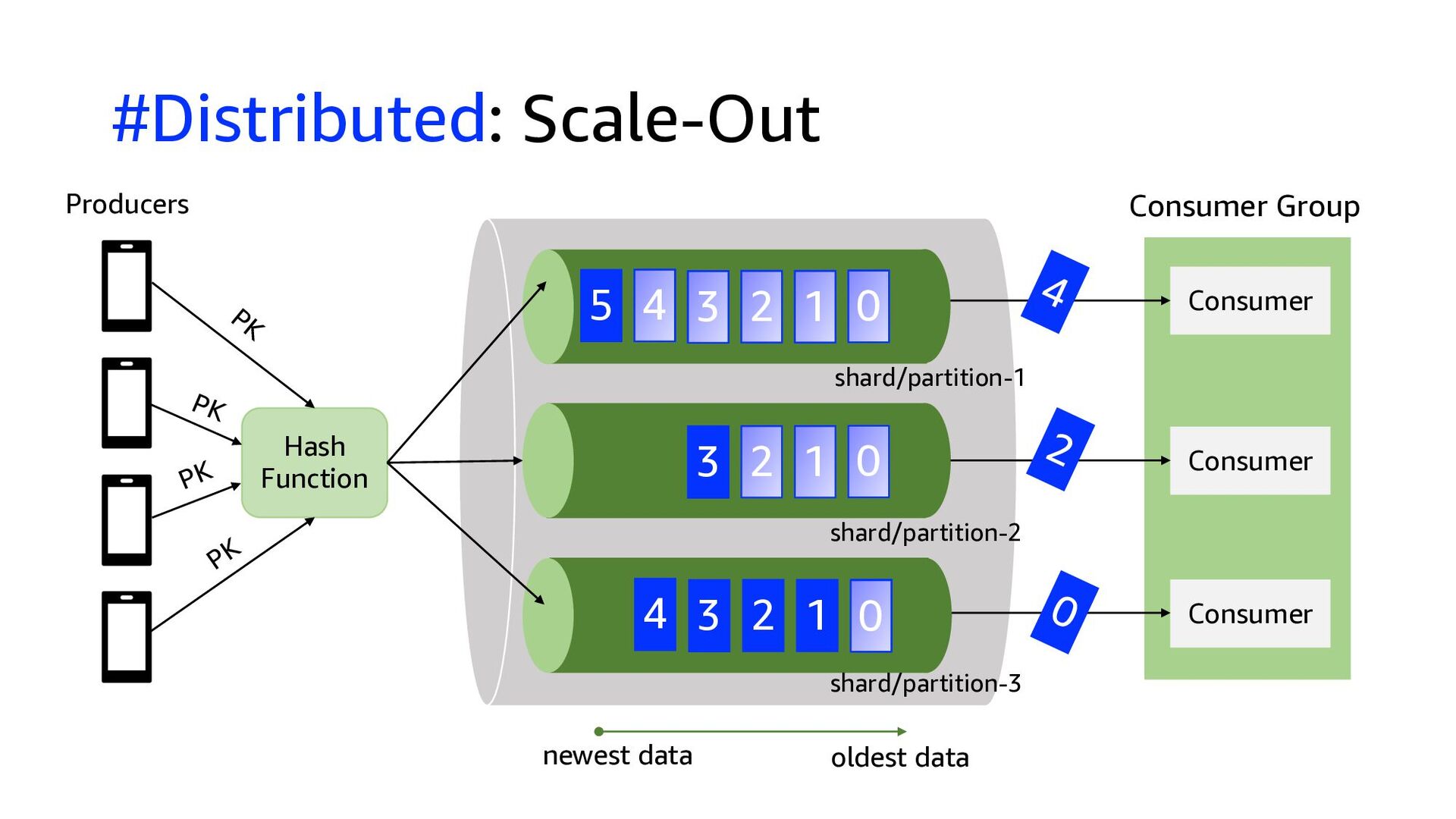
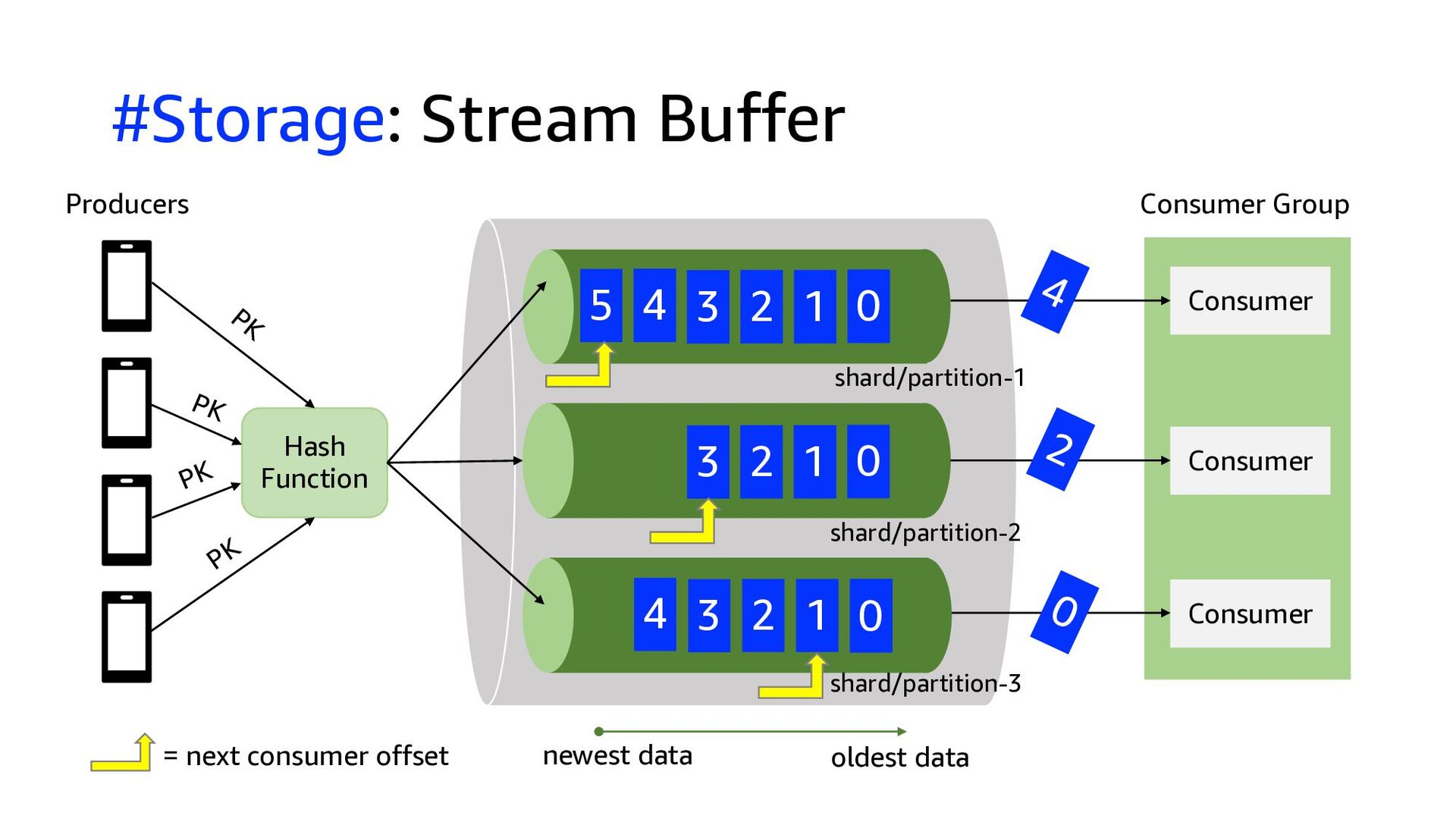
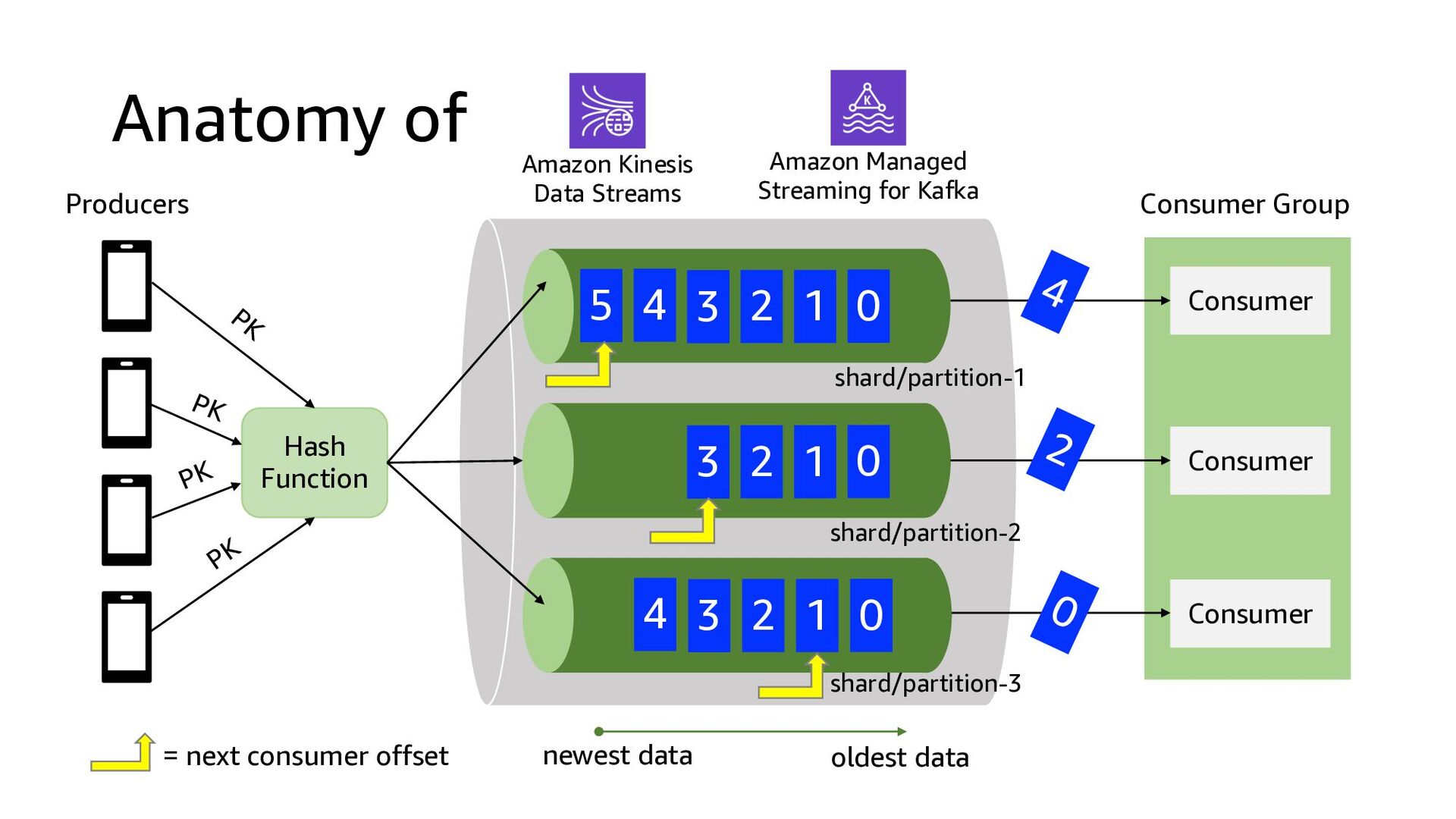
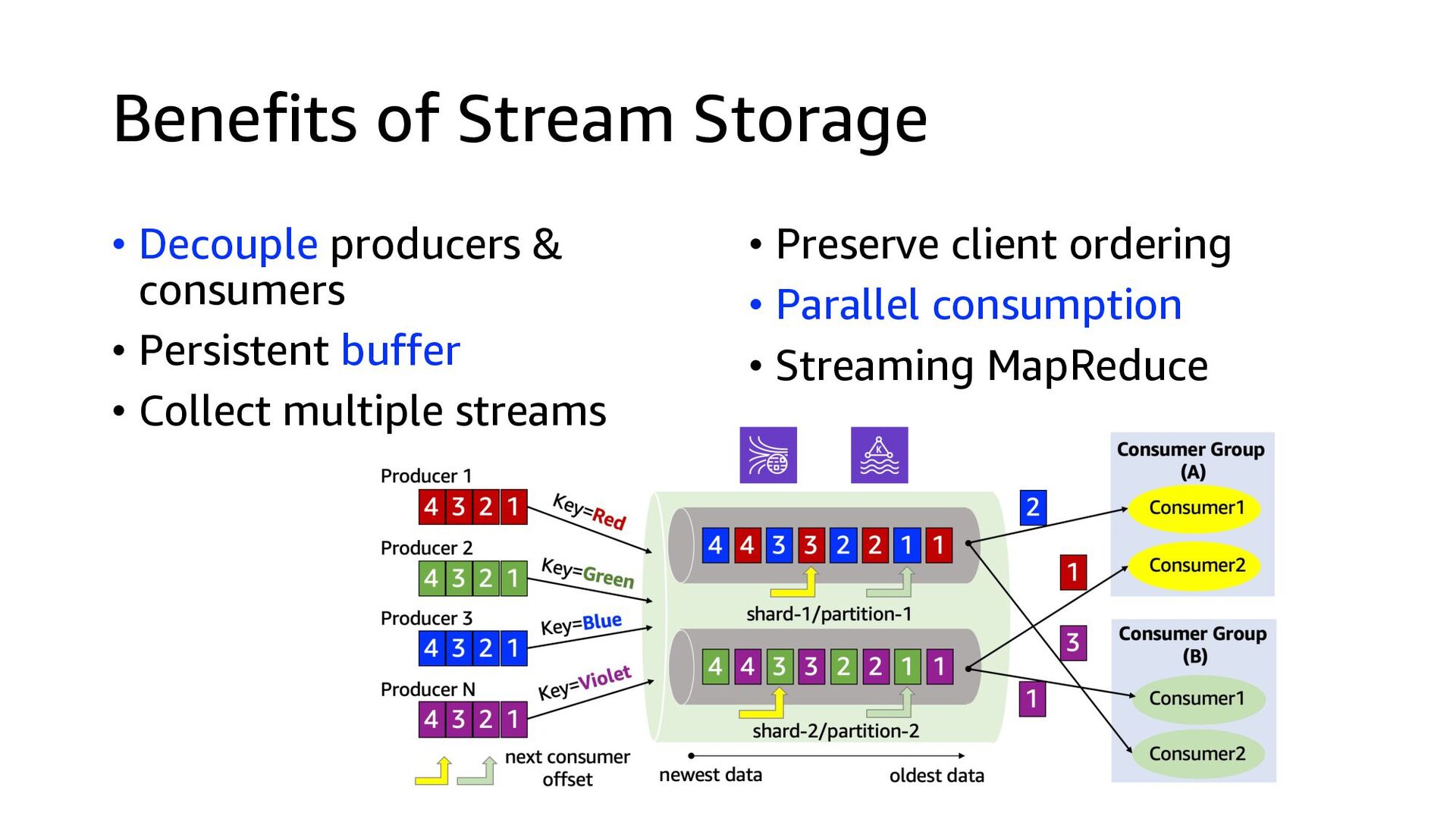
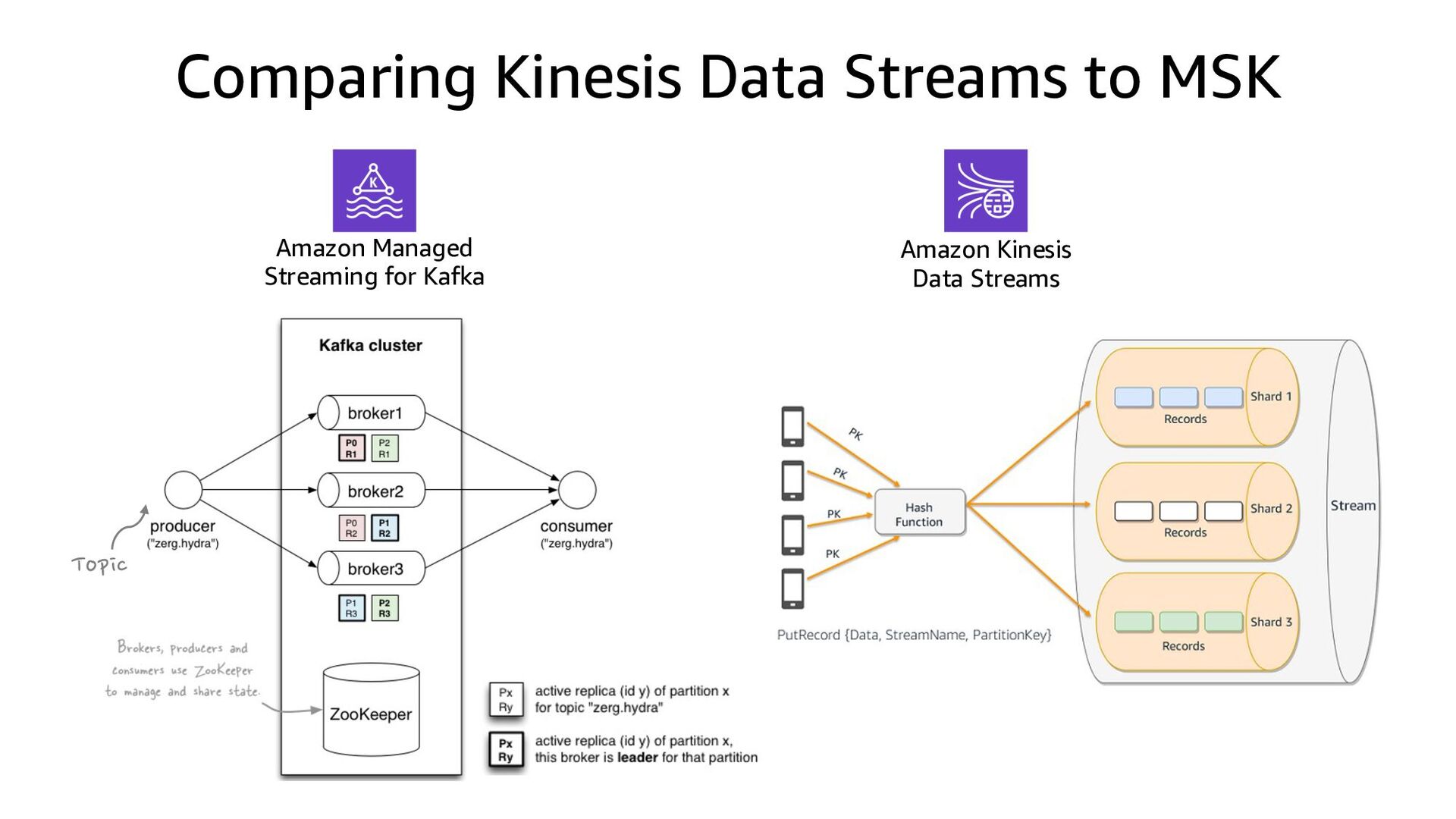
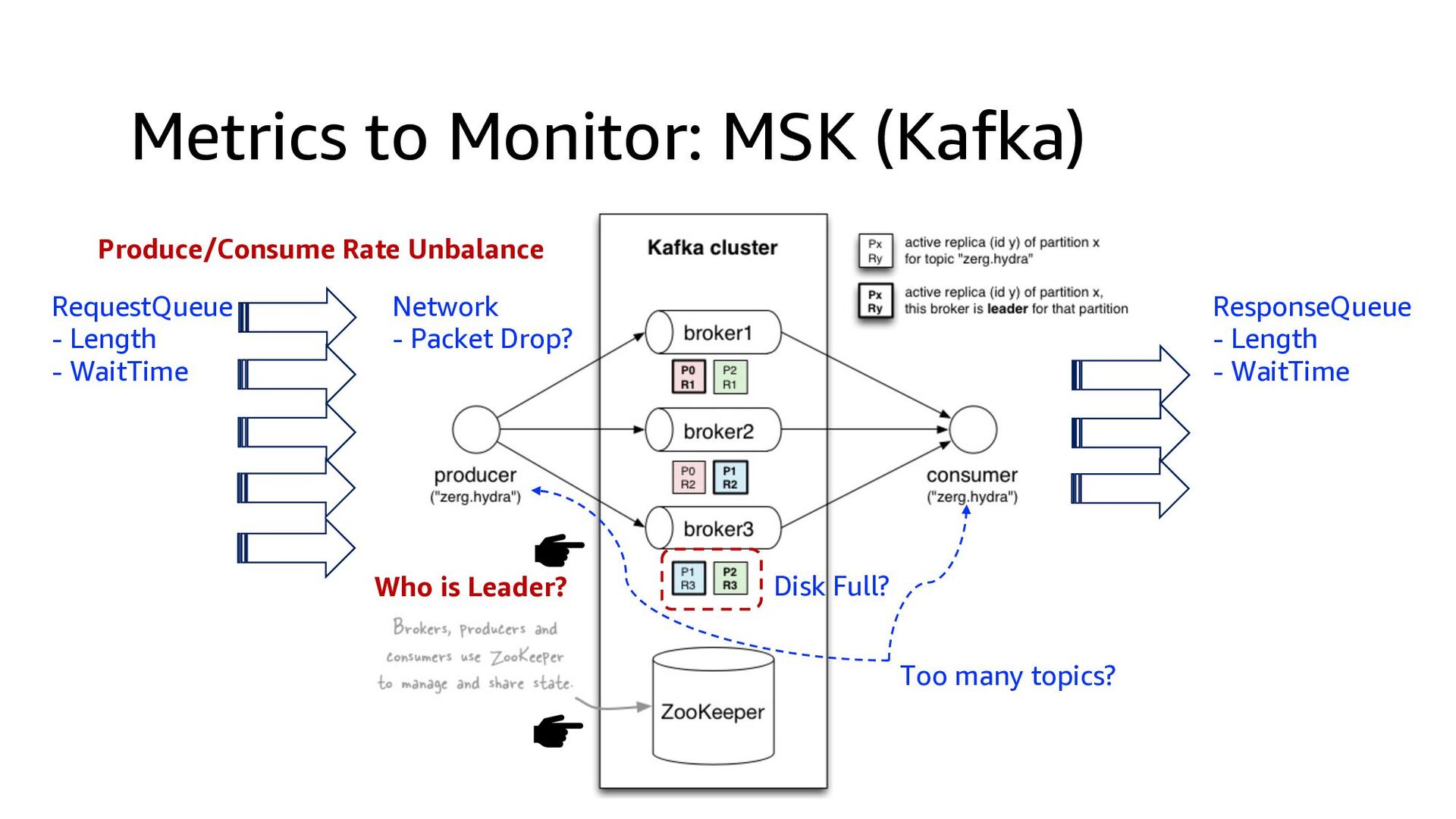
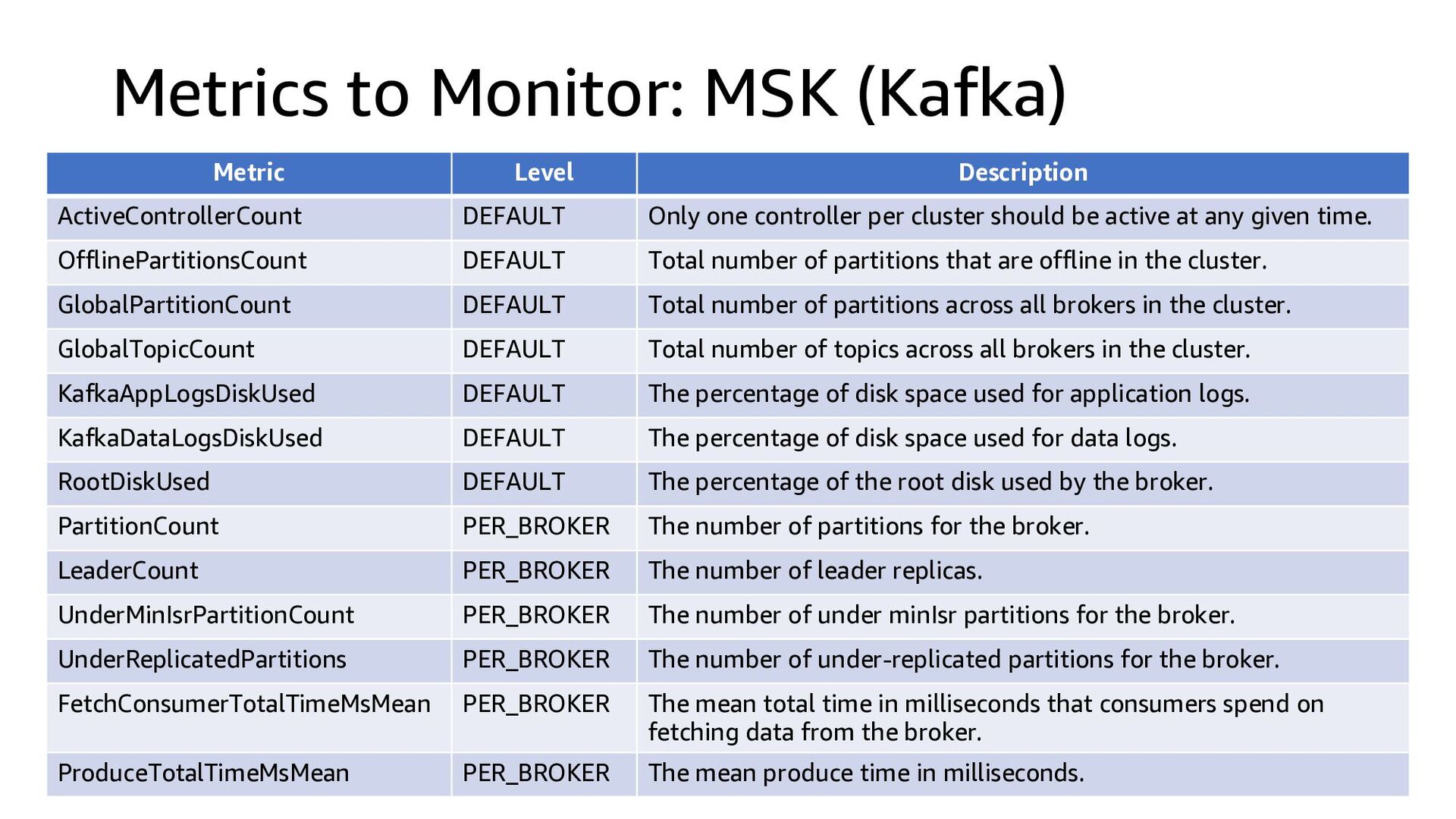
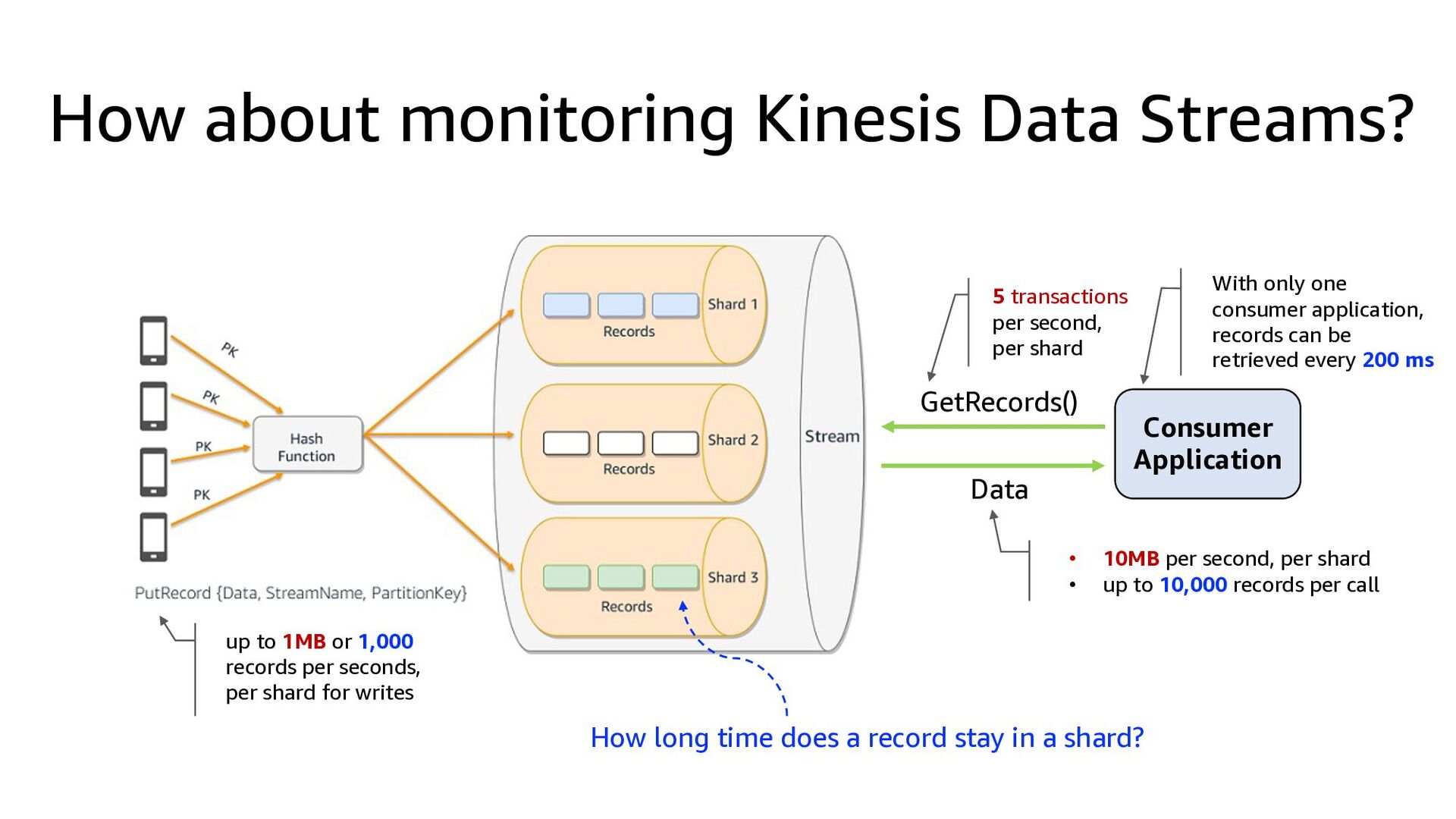
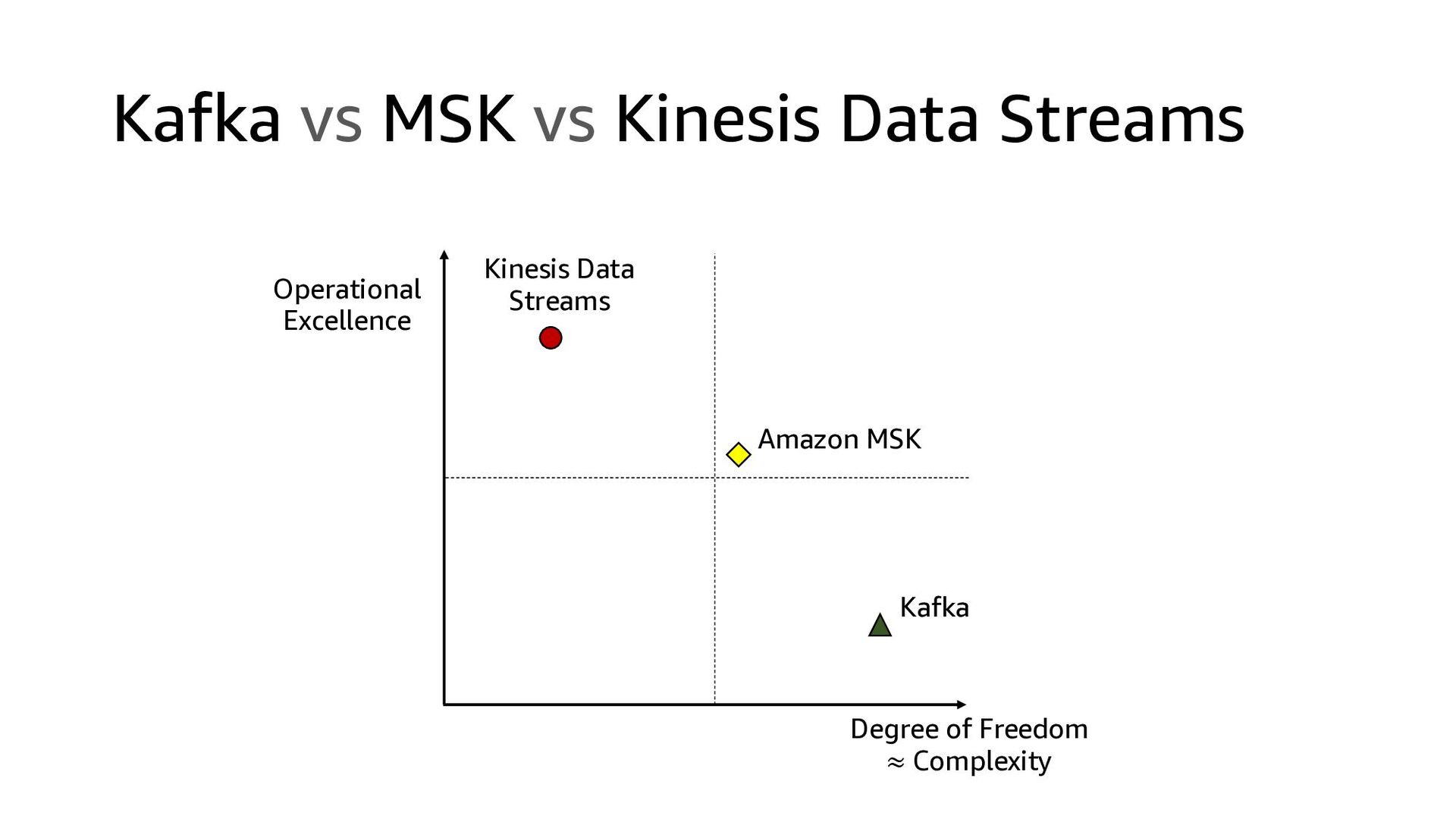
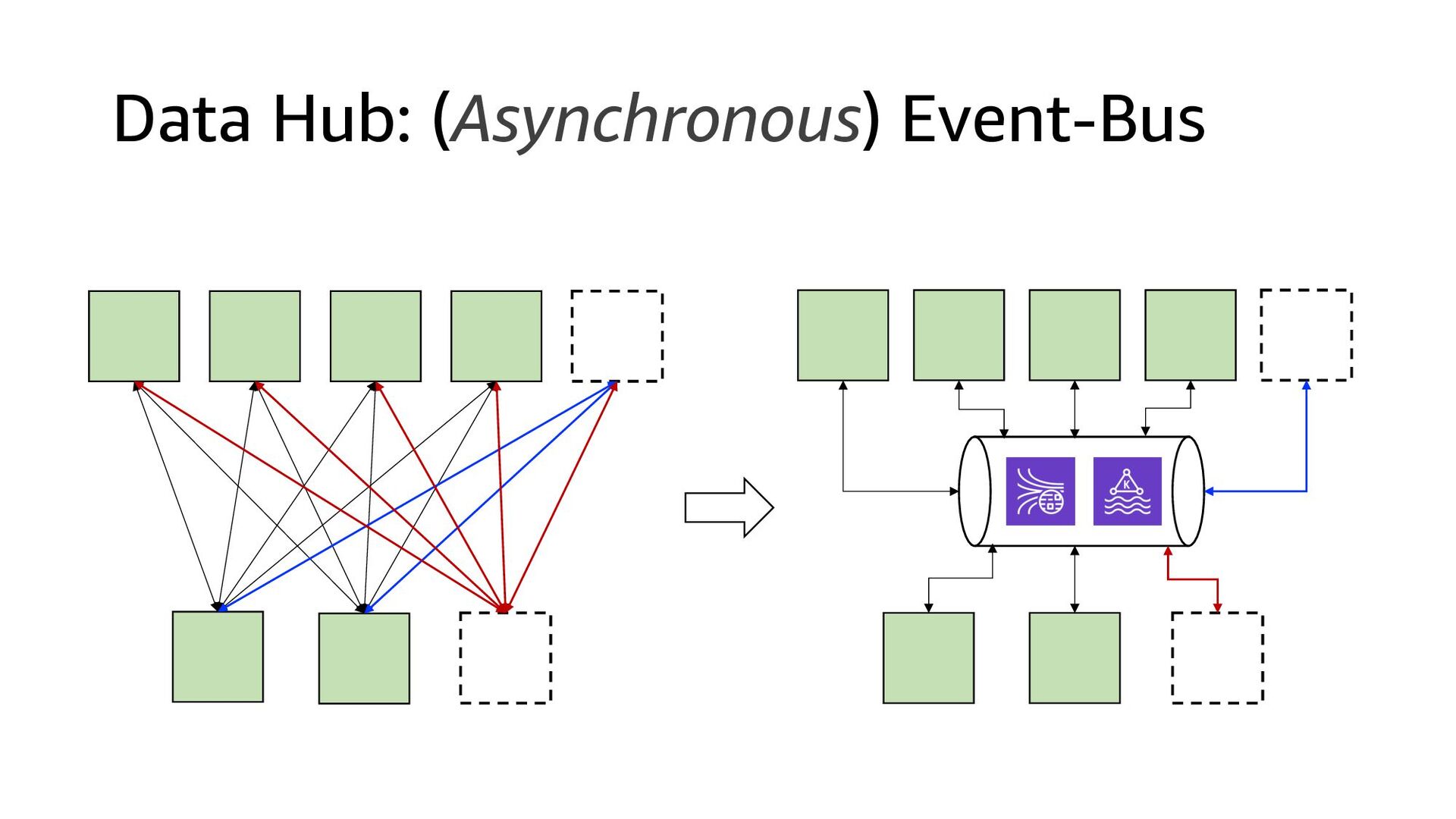
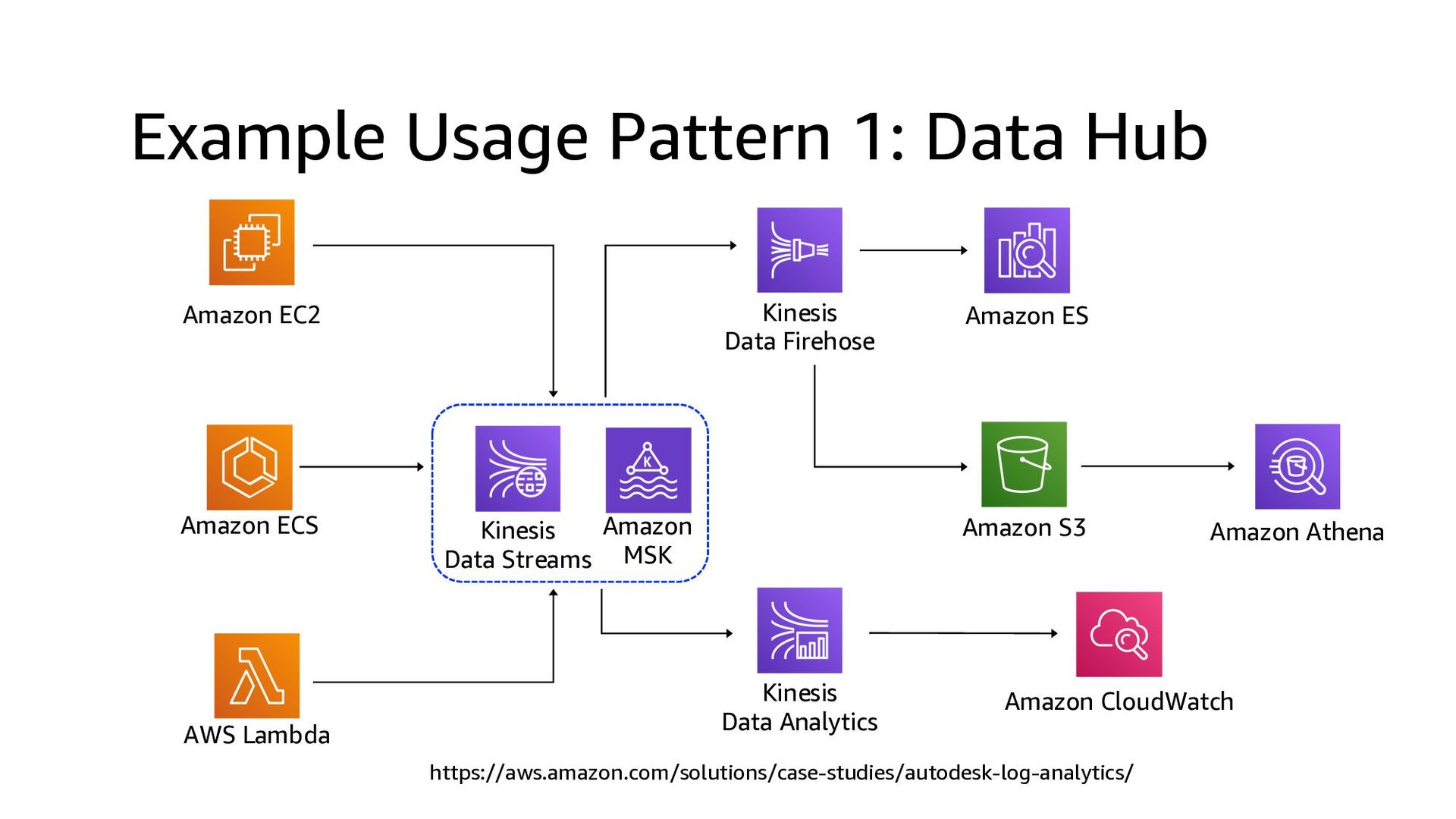
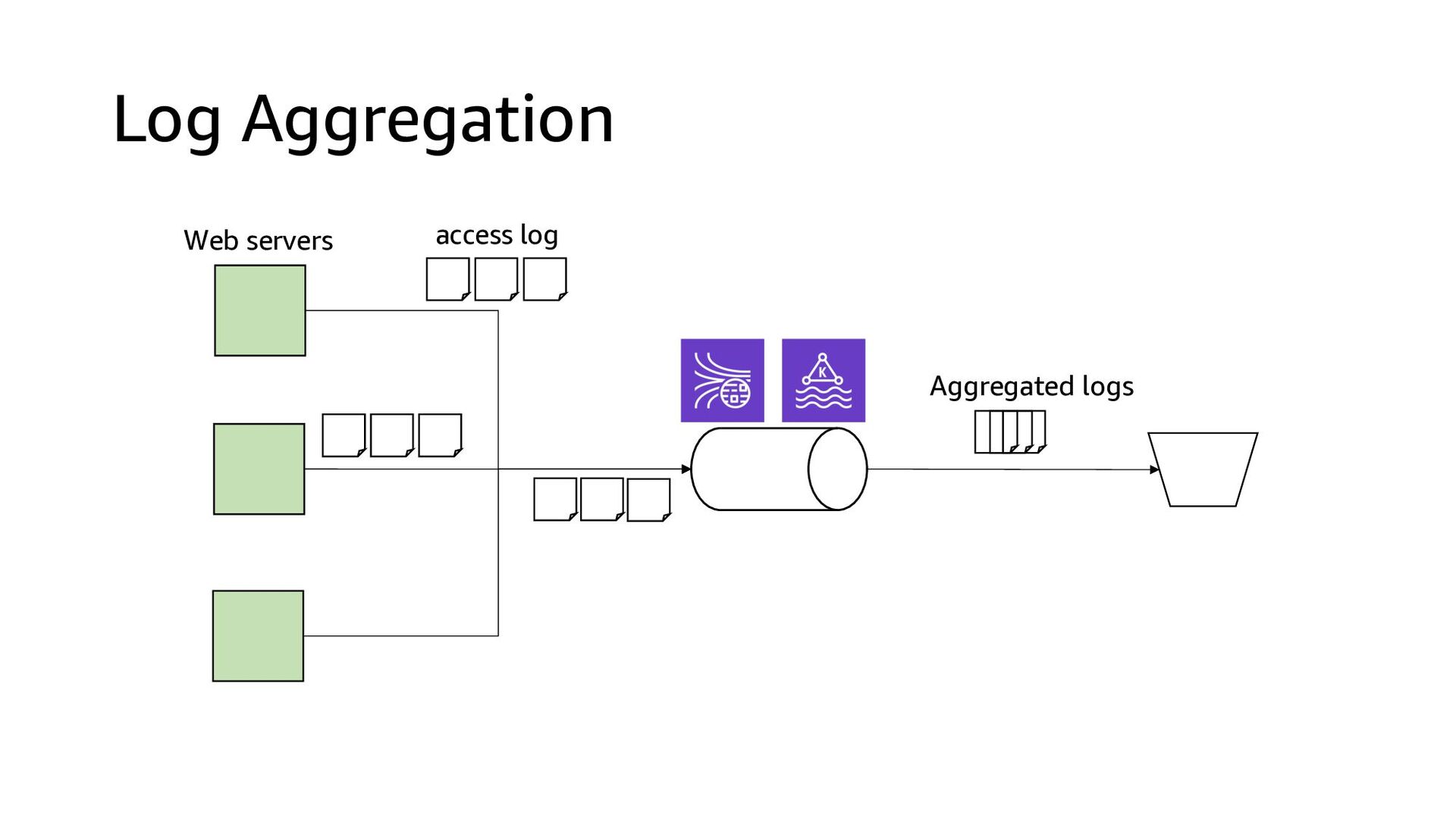
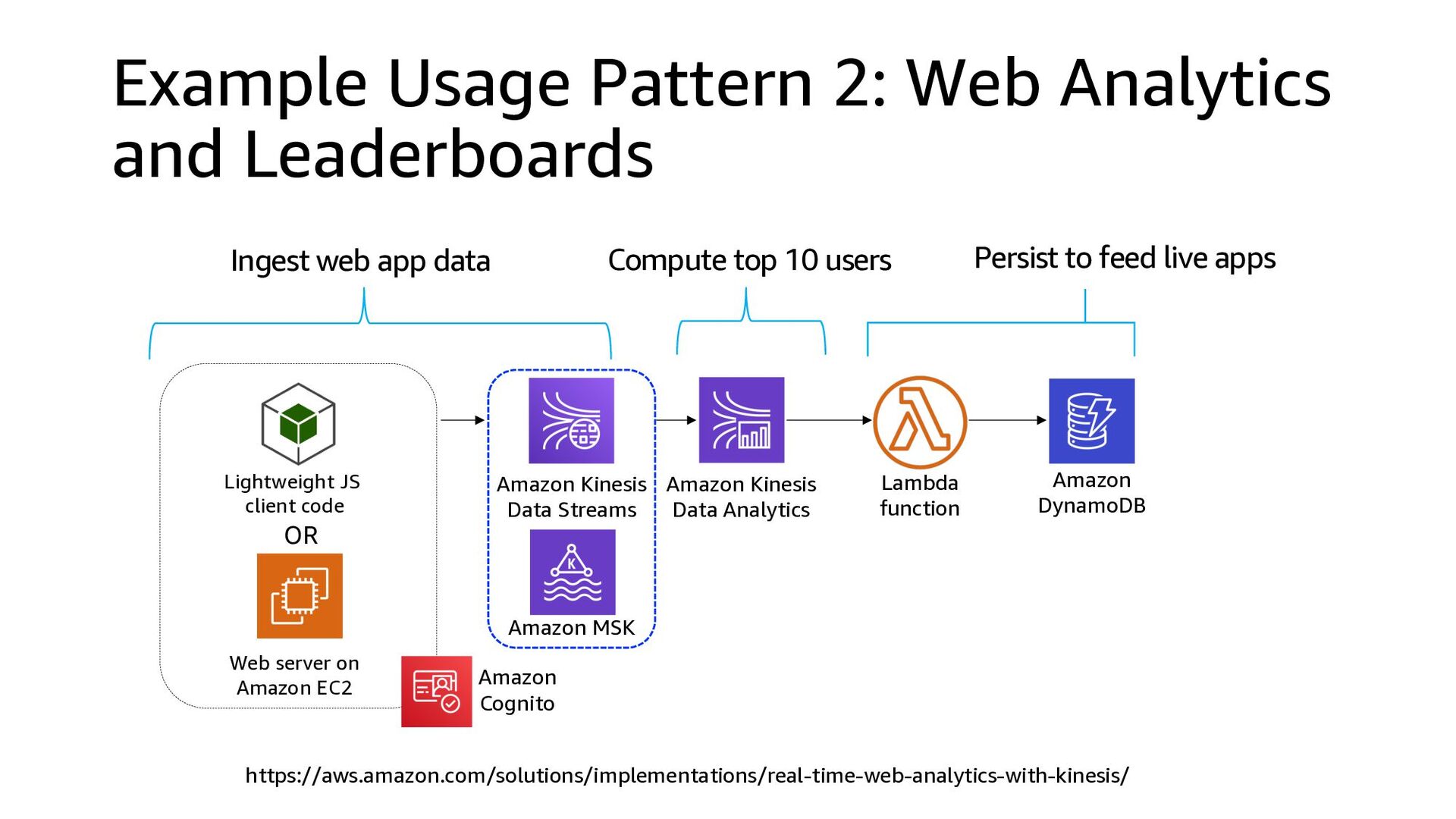
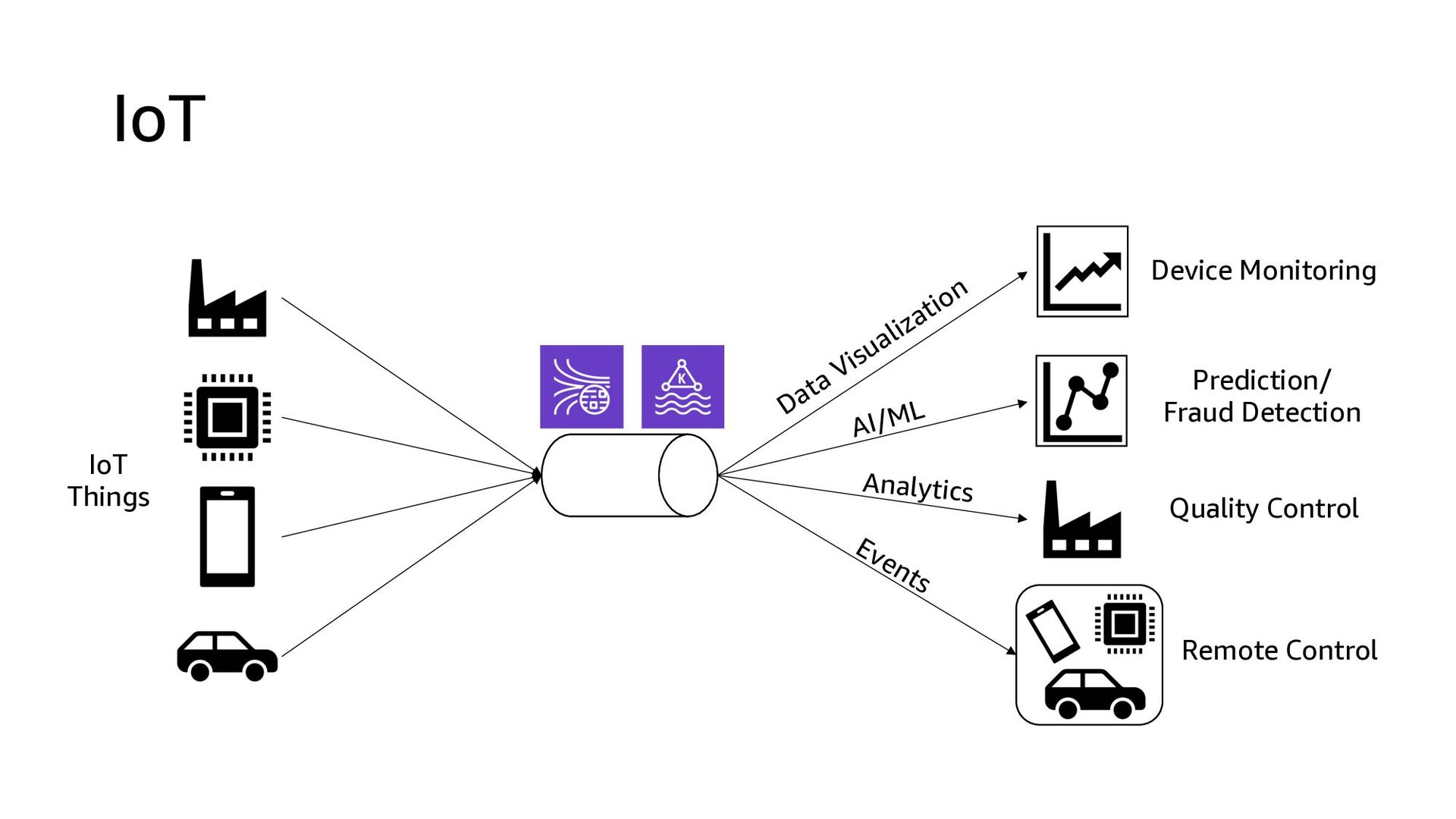
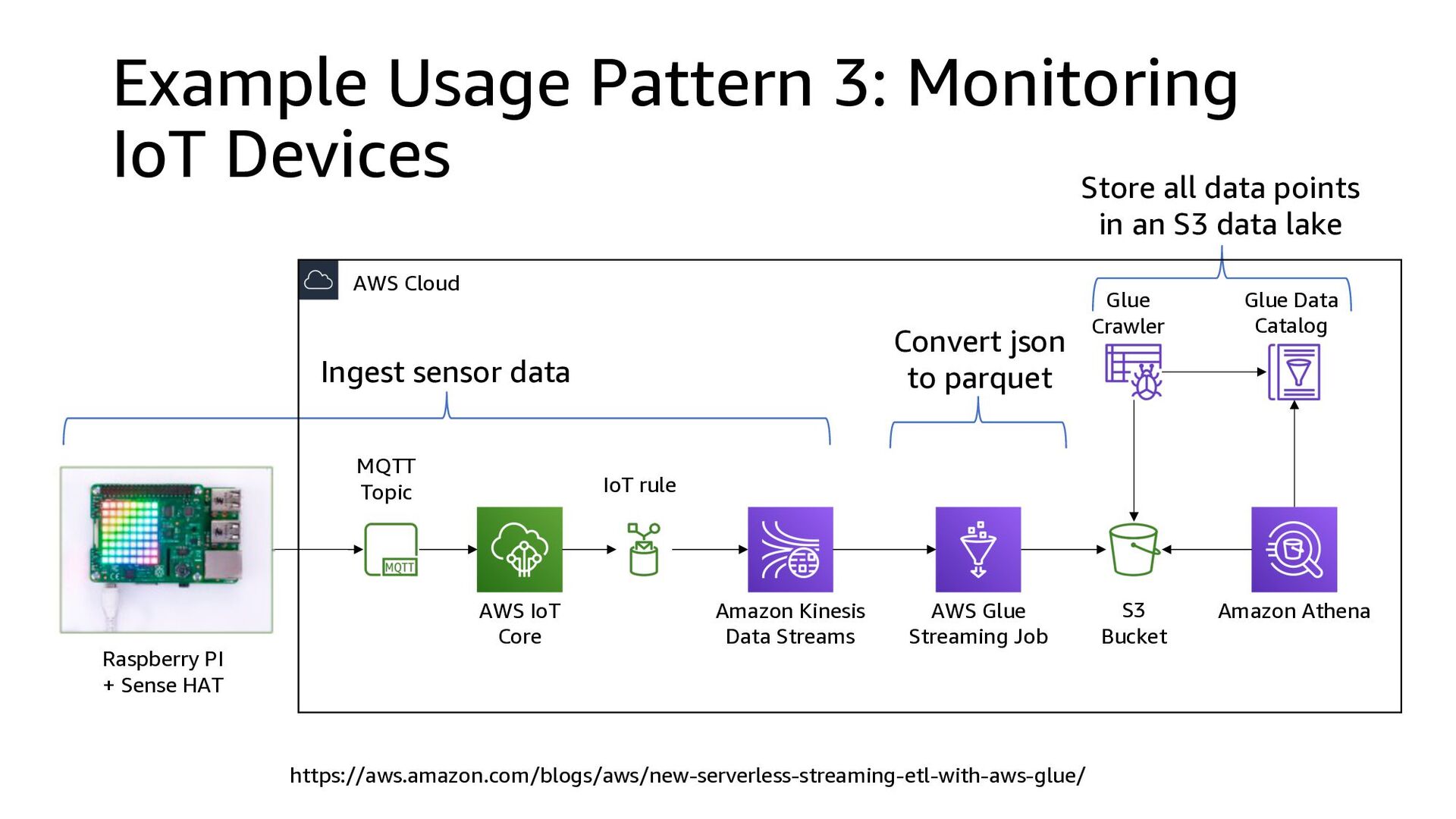
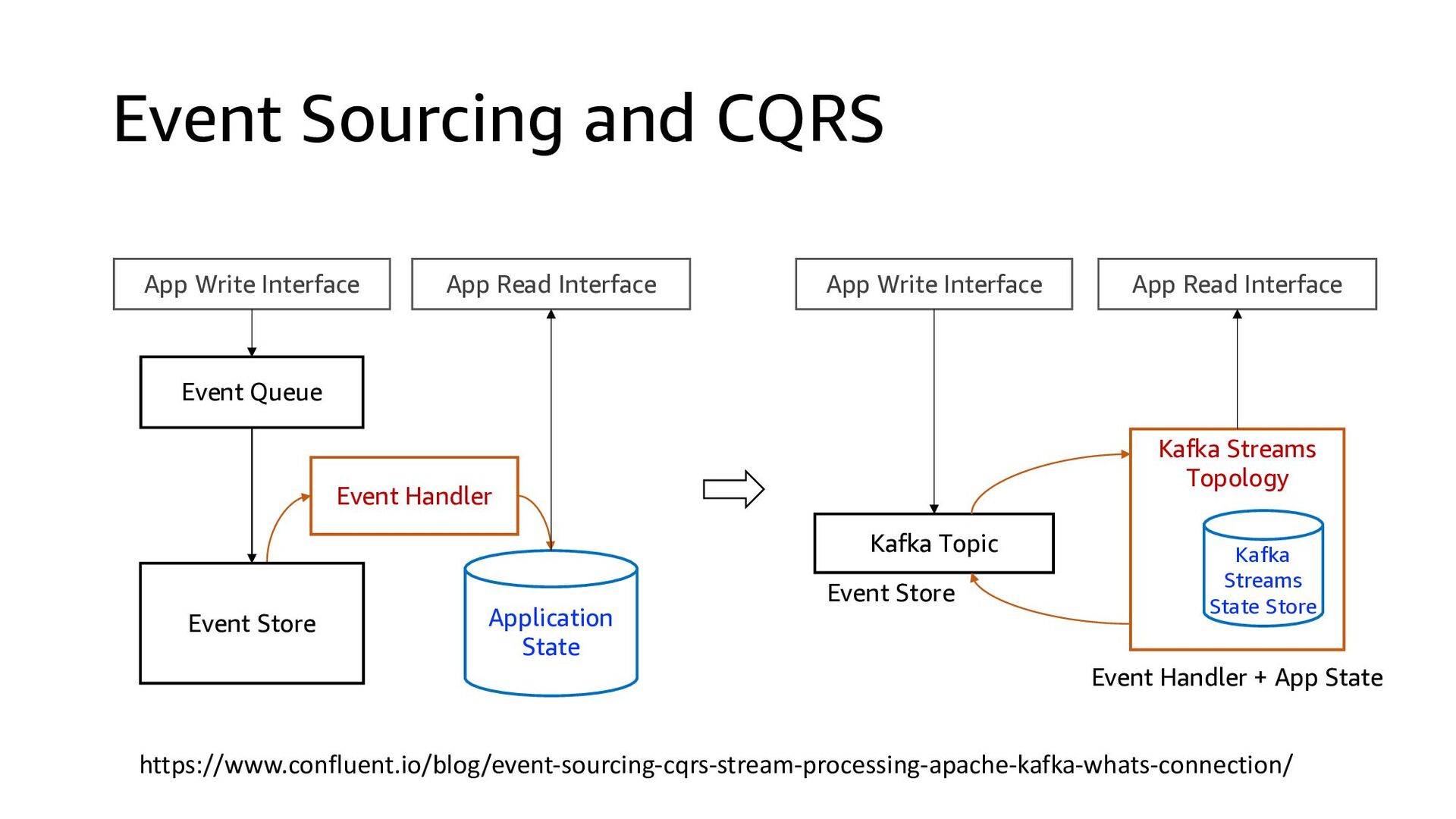
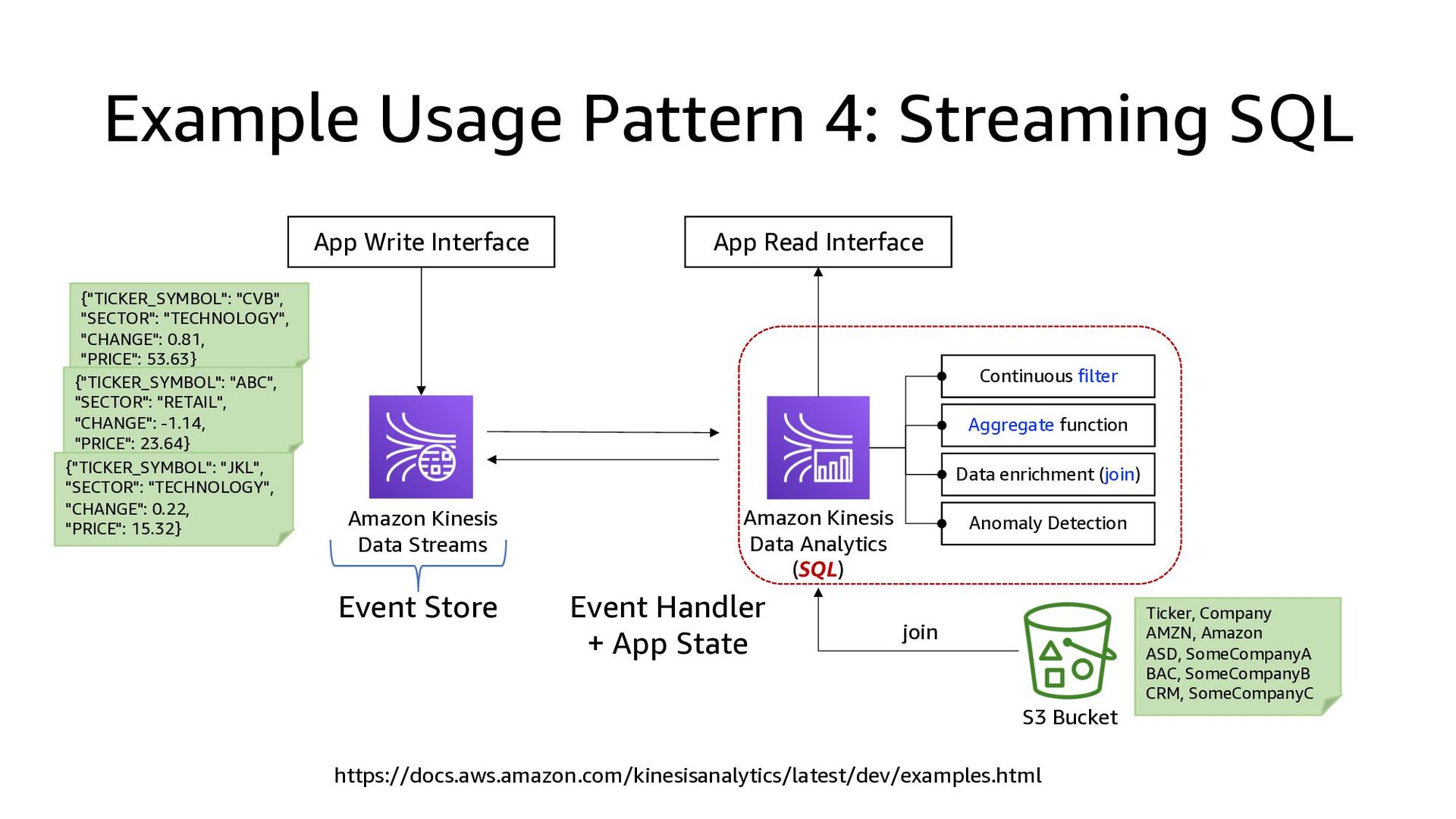
This presentation compares Amazon Kinesis Data Streams to Managed Streaming for Kafka (MSK) in both architectural perspective and operational perspective. In addition, it shows common architectural patterns: (1) Data Hub: Event-Bus, (2) Log Aggregation, (3) IoT, (4) Event sourcing and CQRS.
{kind=link}
{kind=link}
{kind=link}
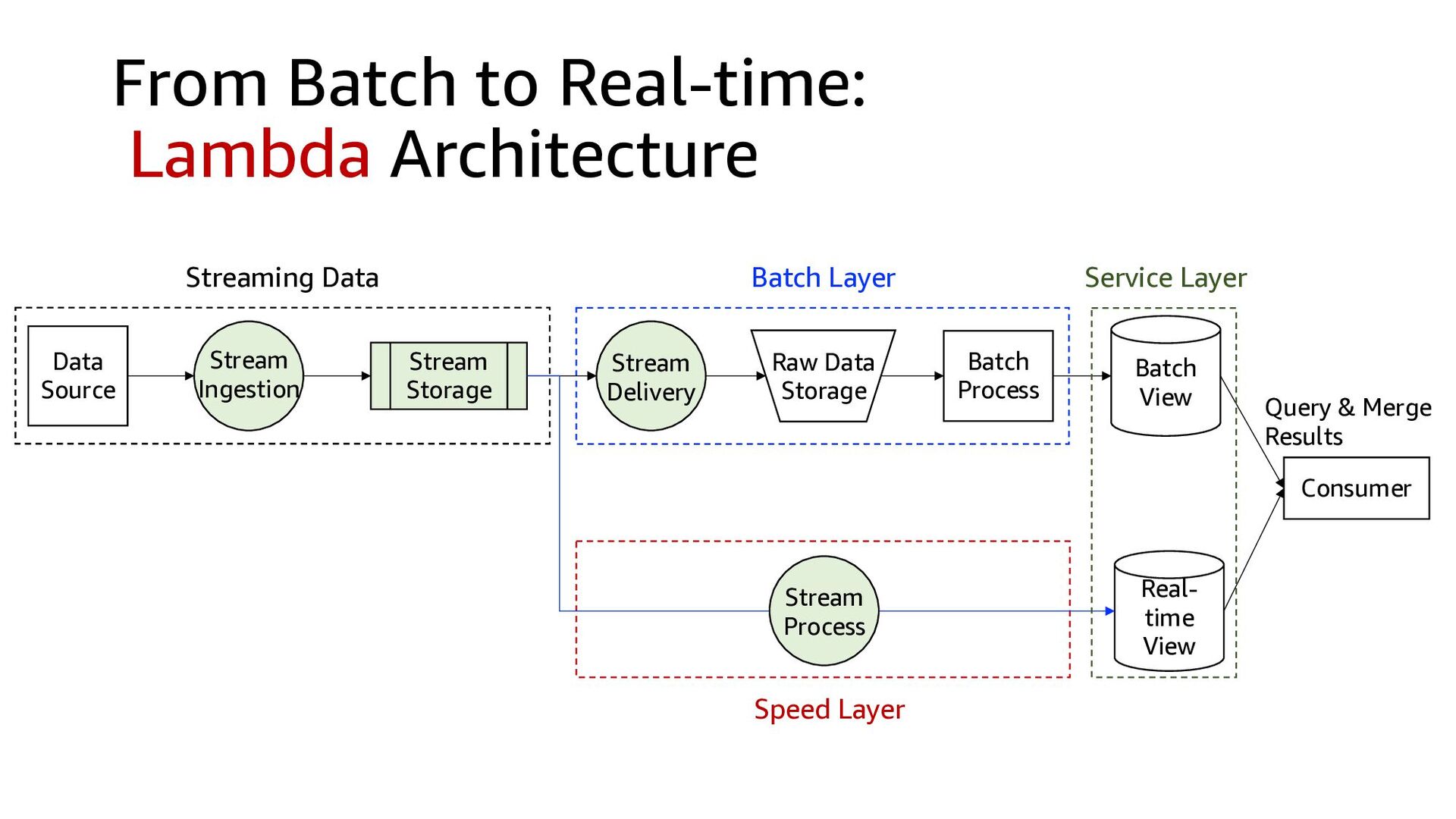{kind=link}
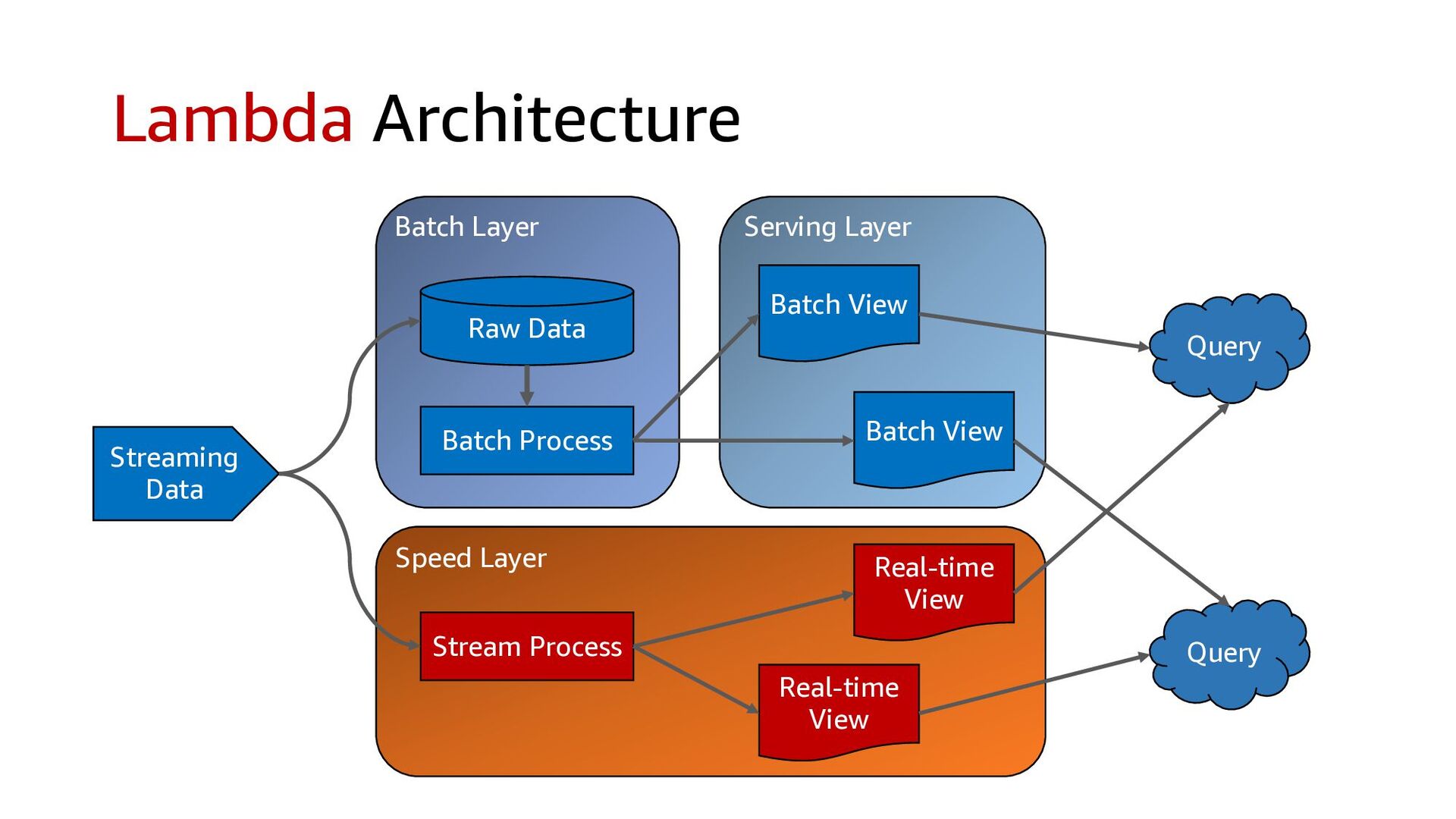{kind=link}
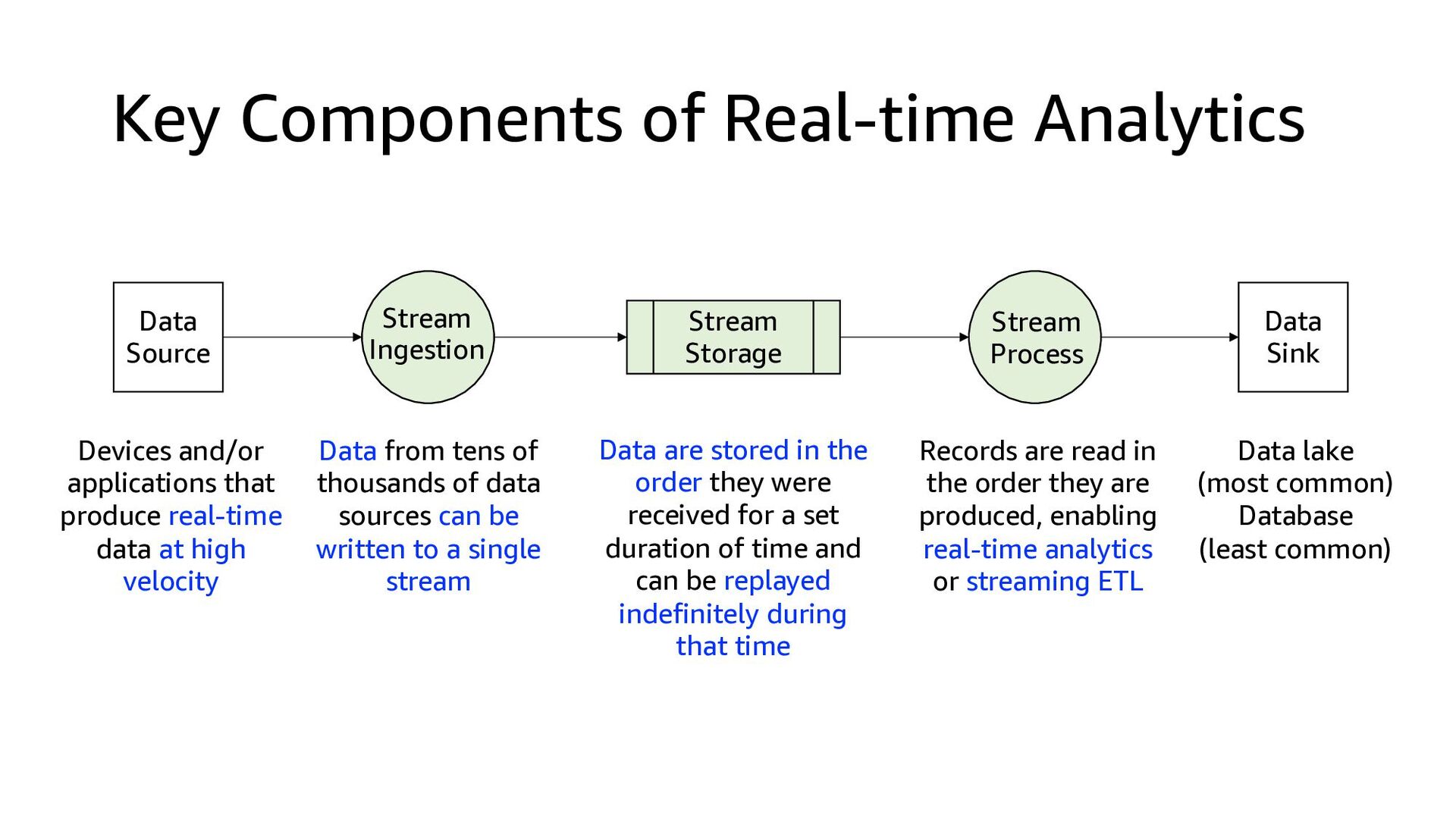{kind=link}
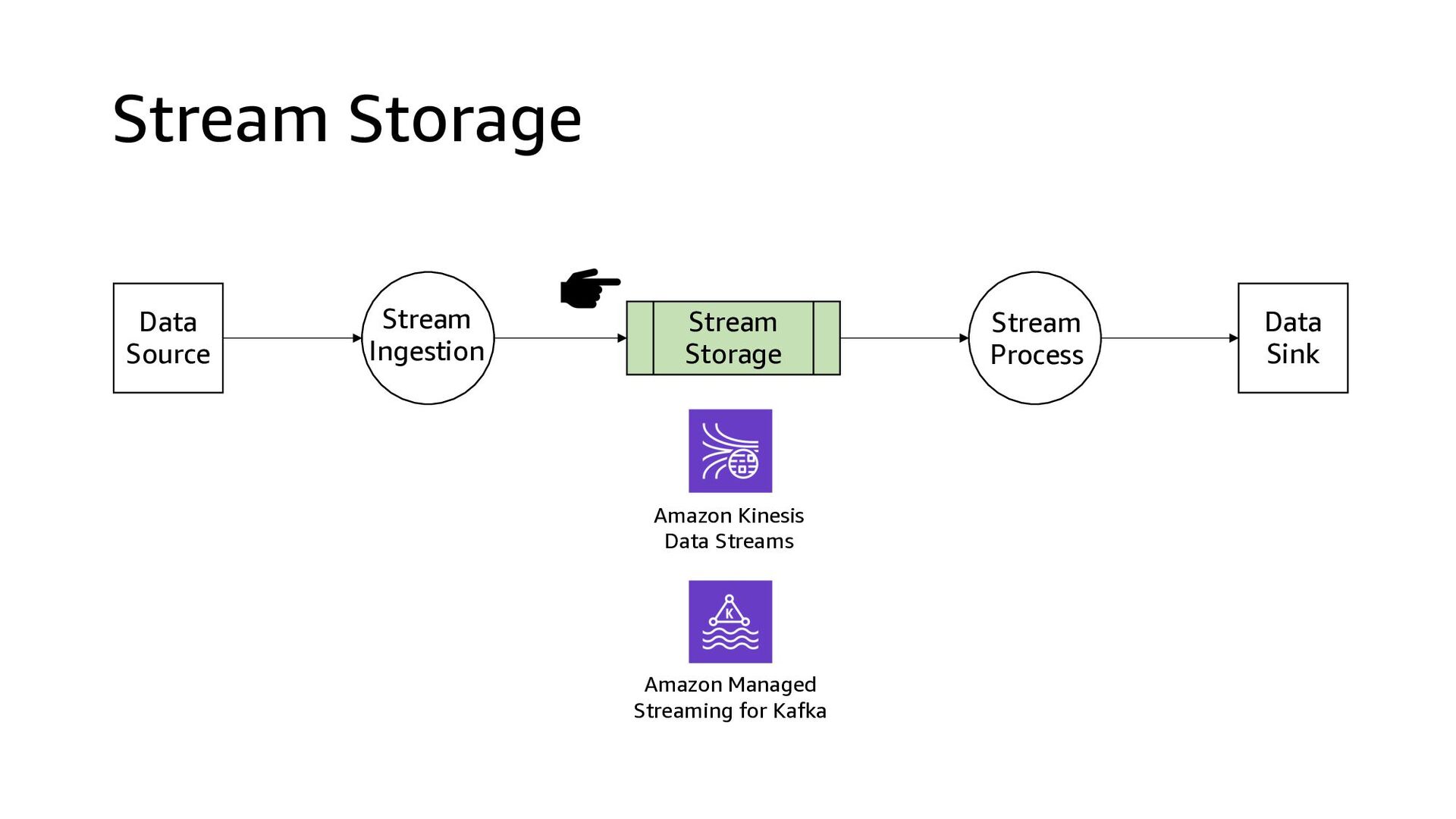{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}