Speech synthesis is a technology that generates speech waveforms corresponding to input text, and it has been a subject of sustained research for many years. The fundamental framework of statistical speech synthesis is to generate speech for any given input text based on a large database of paired speech waveforms and corresponding text. This generation process is generally divided into multiple stages—text analysis, acoustic modeling, and waveform generation—each of which is modeled using statistical machine learning techniques, and more recently, deep learning methods. In this talk, I will provide an overview of the progress made in statistical approaches to speech synthesis over the past few decades, incorporating personal episodes and even some failure stories from my own experience. I will also discuss ongoing challenges related to speech quality, controllability, and application diversity, and present my personal perspective on future directions in the field.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Concatenative synthesis (fixed-unit) Diphone synthesis • PSOLA [Moulines+, SPECOM 1990]](https://files.speakerdeck.com/presentations/6fe4da8bfaa14973bc1ce45b7d0f8c55/slide_4.jpg){kind=link}
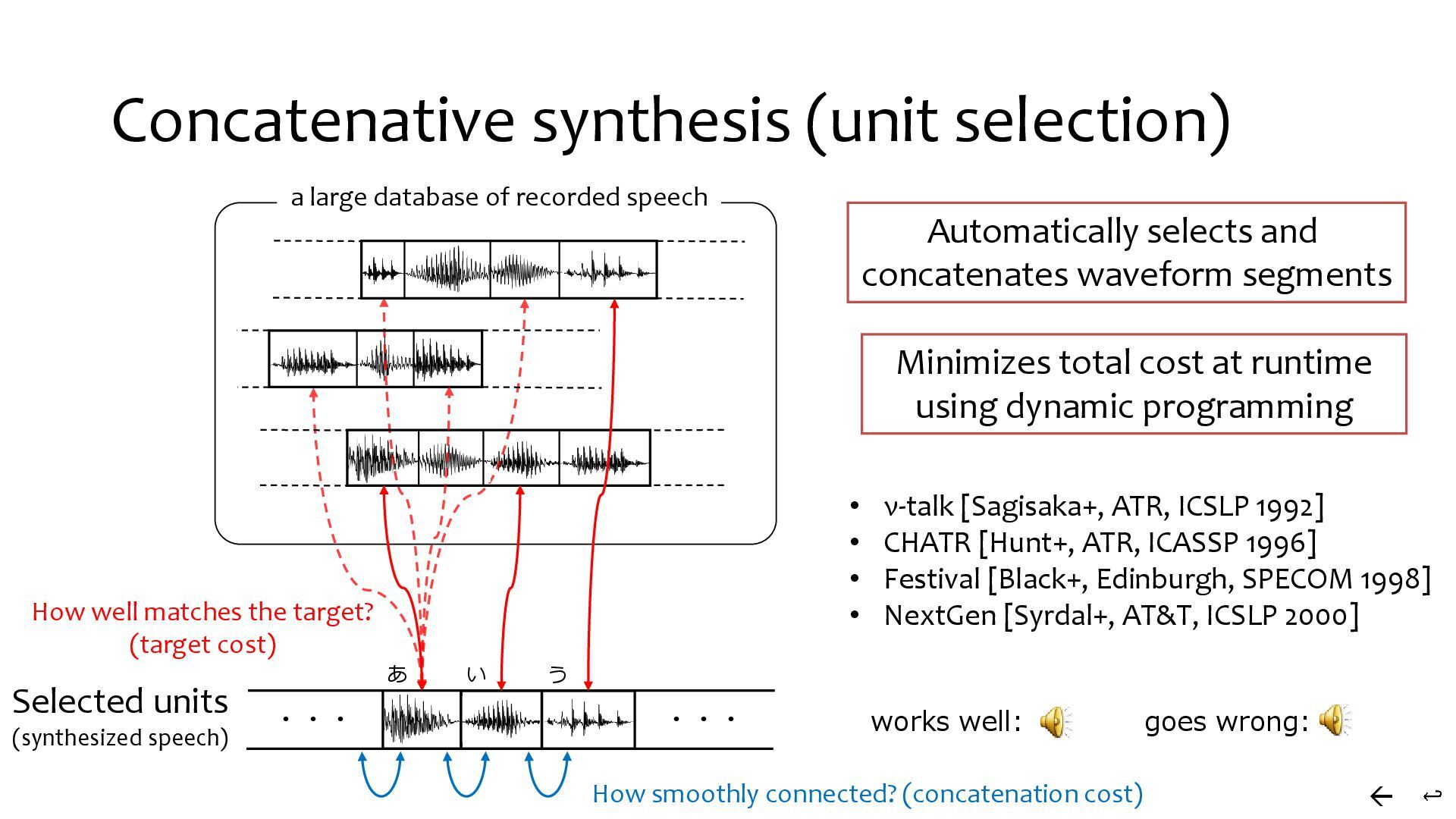{kind=link}
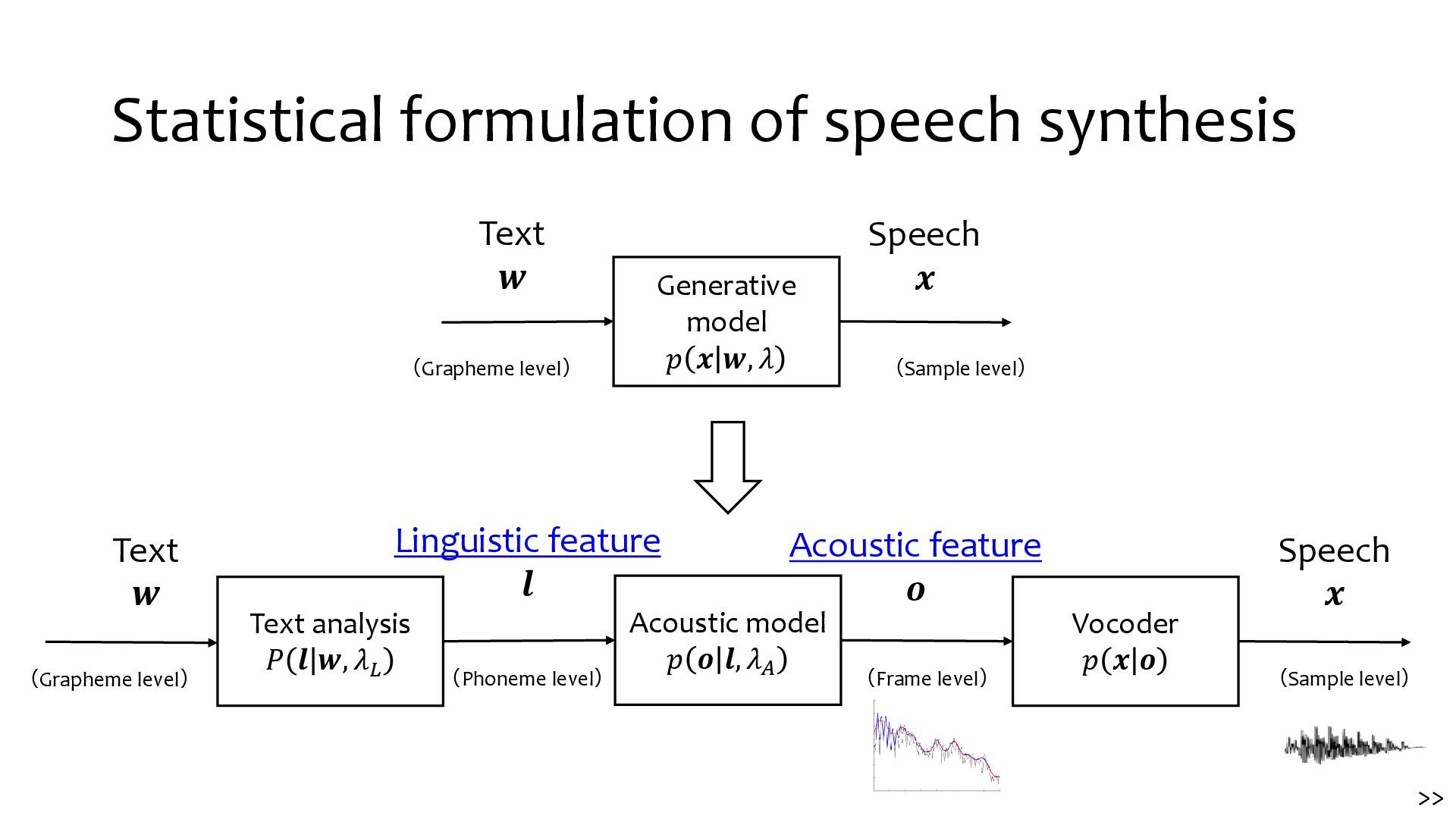{kind=link}
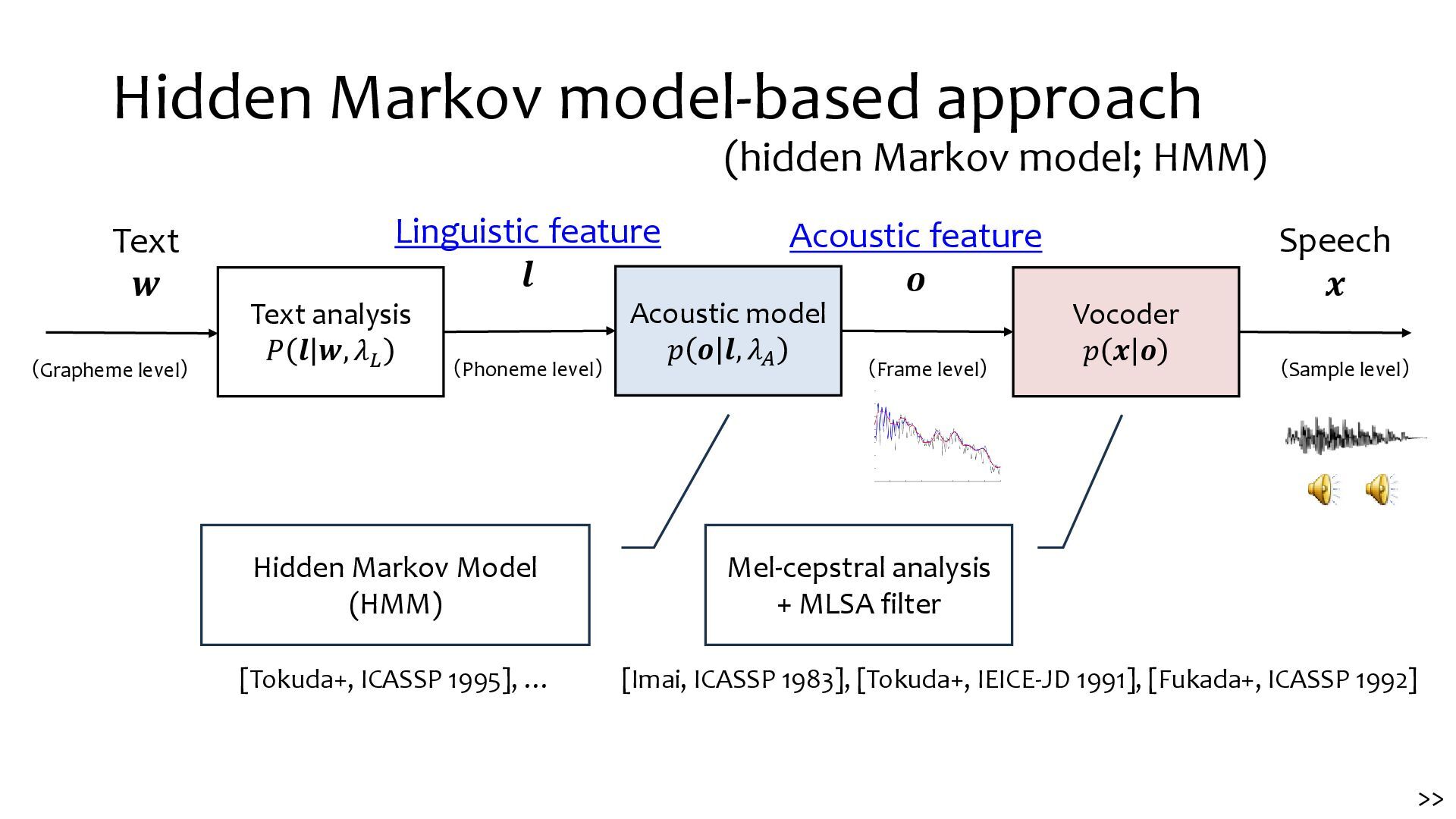{kind=link}
{kind=link}
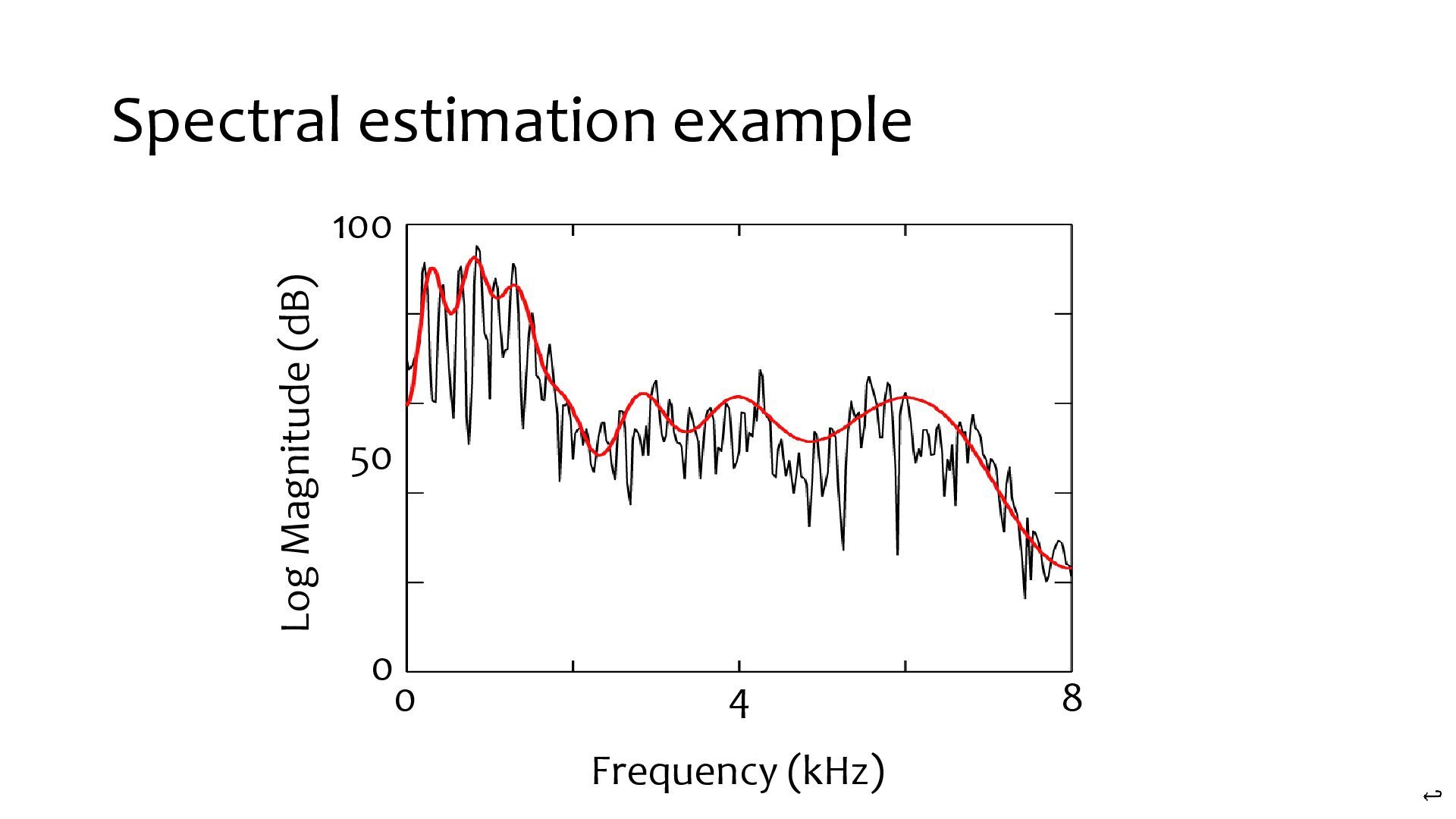{kind=link}
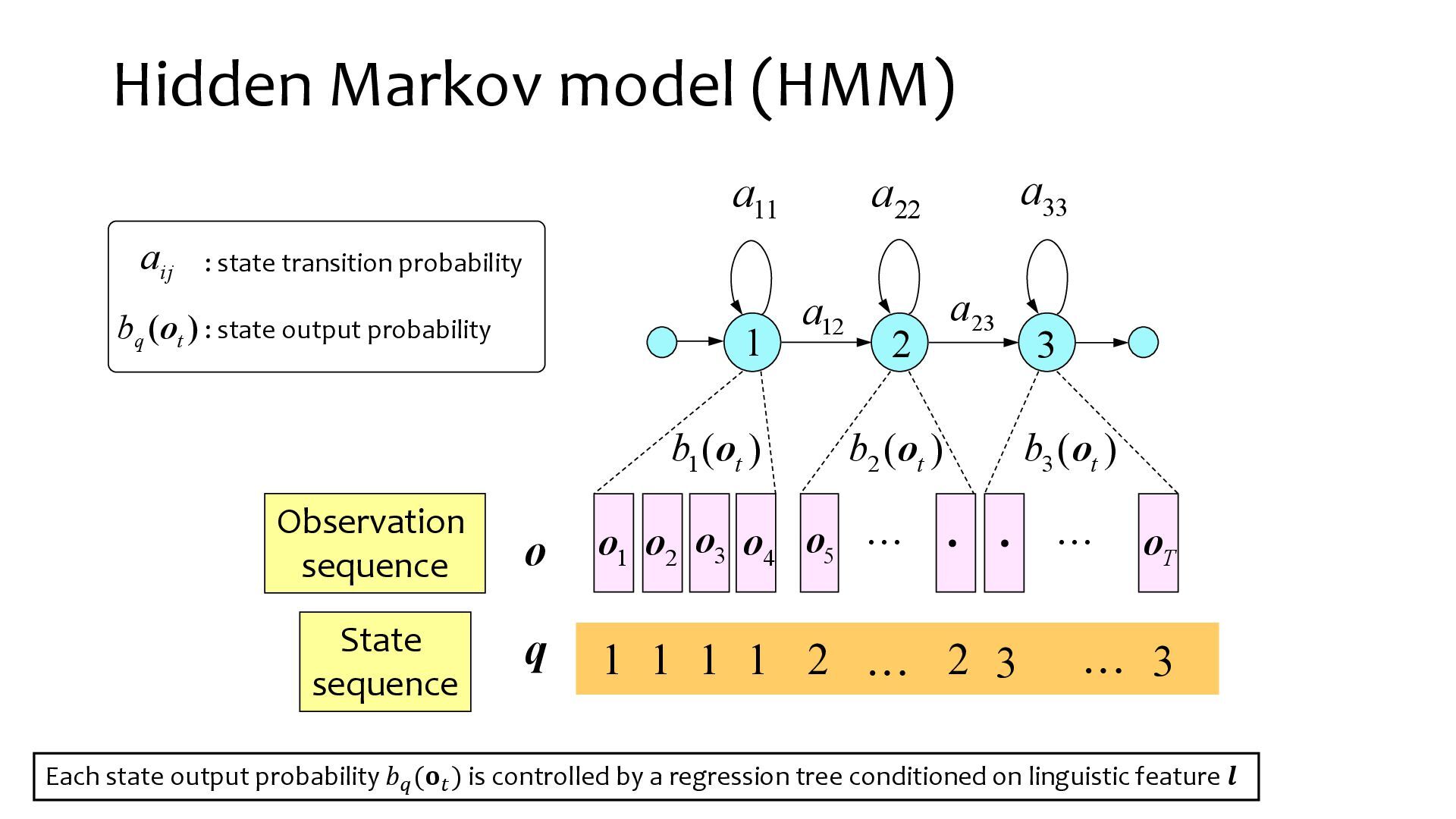{kind=link}
{kind=link}
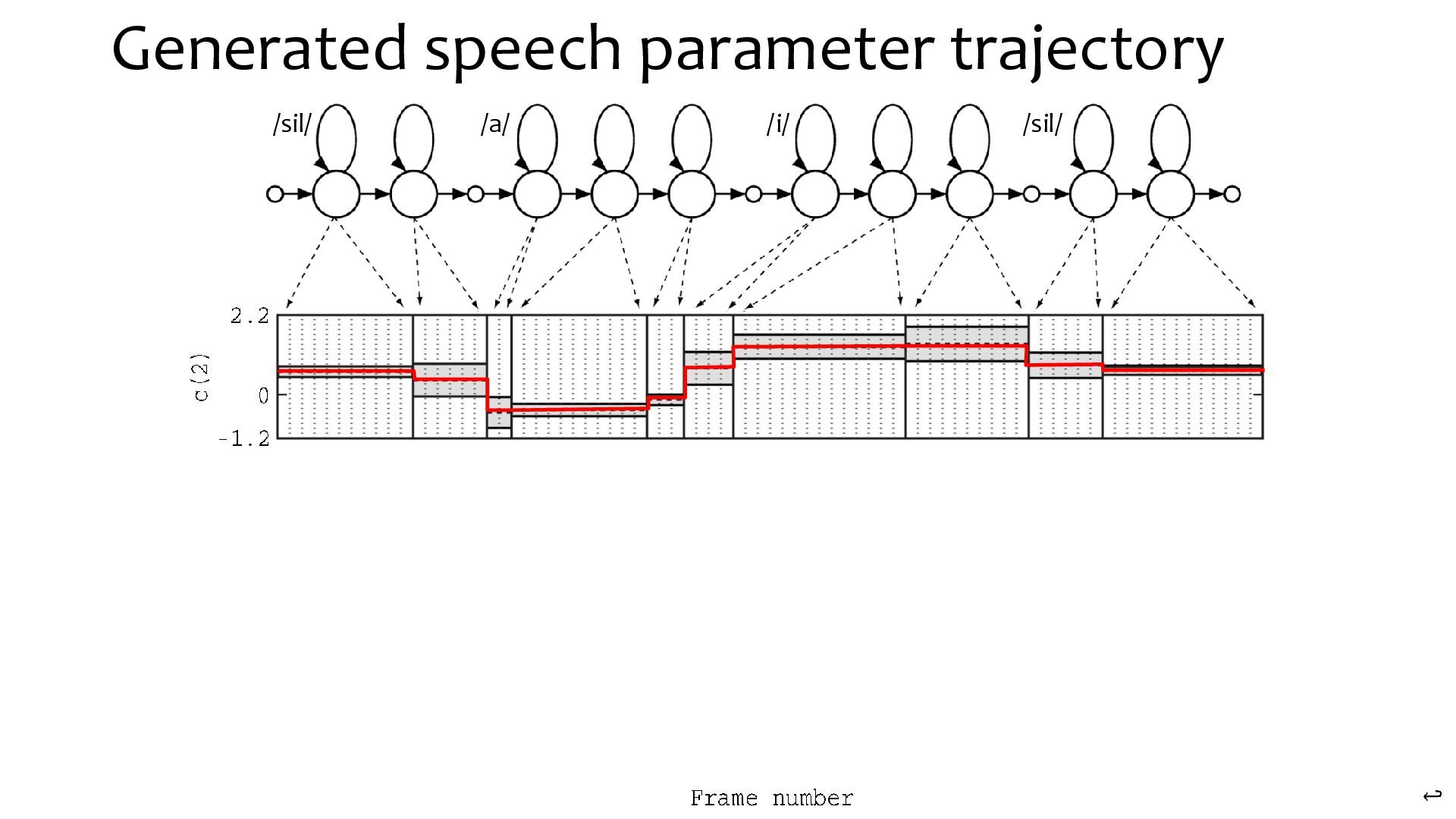{kind=link}
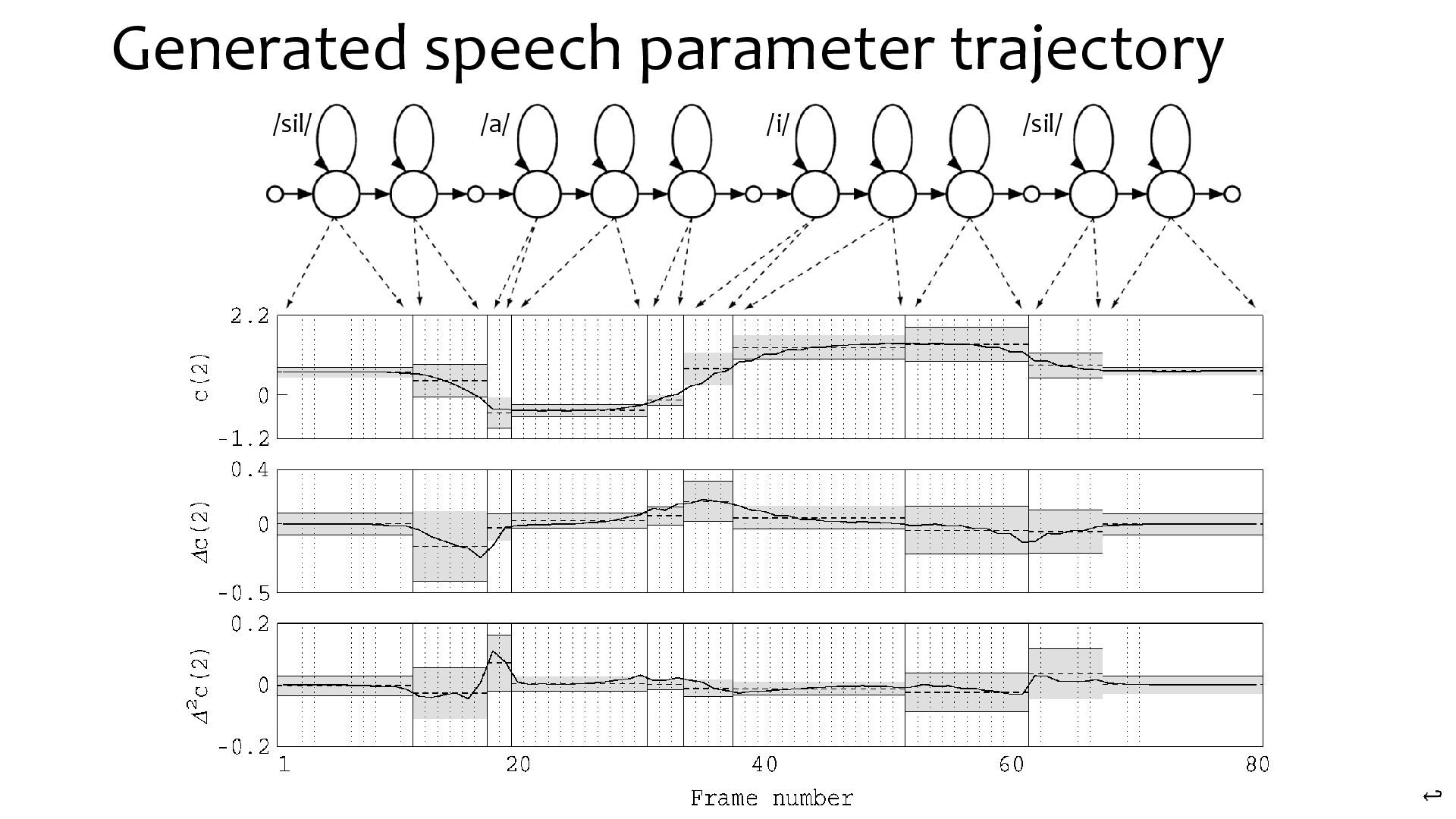{kind=link}
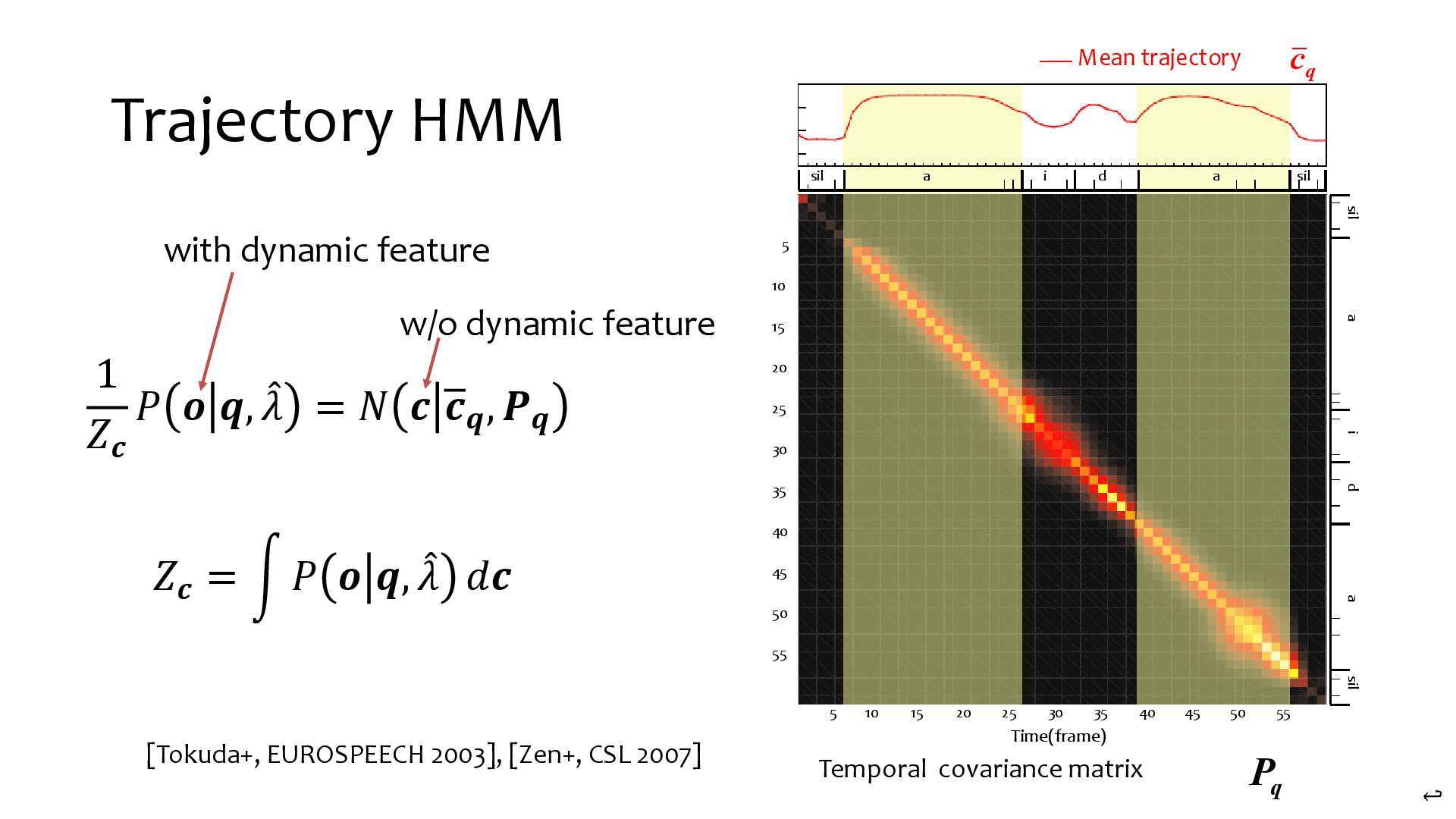{kind=link}
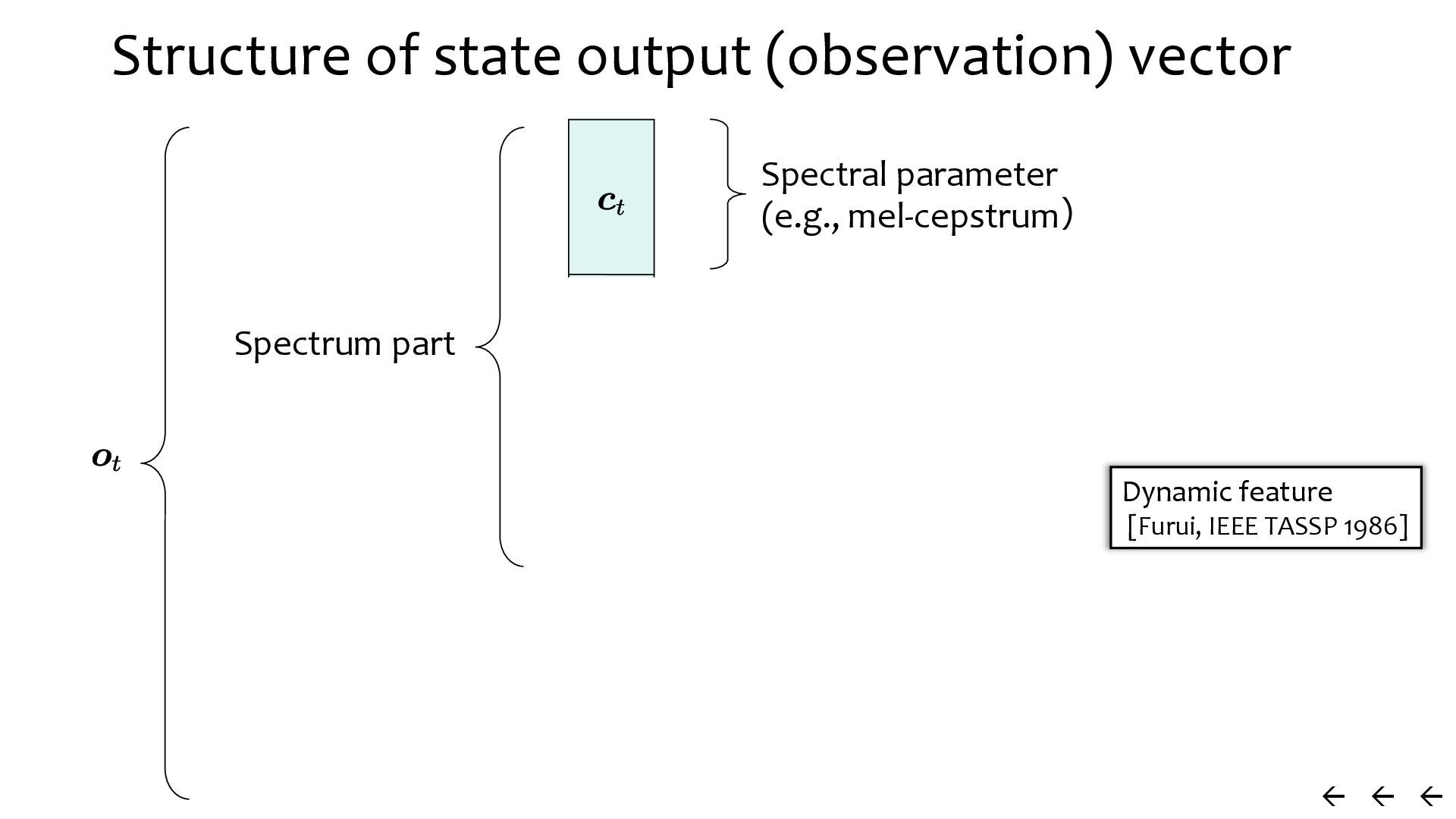{kind=link}
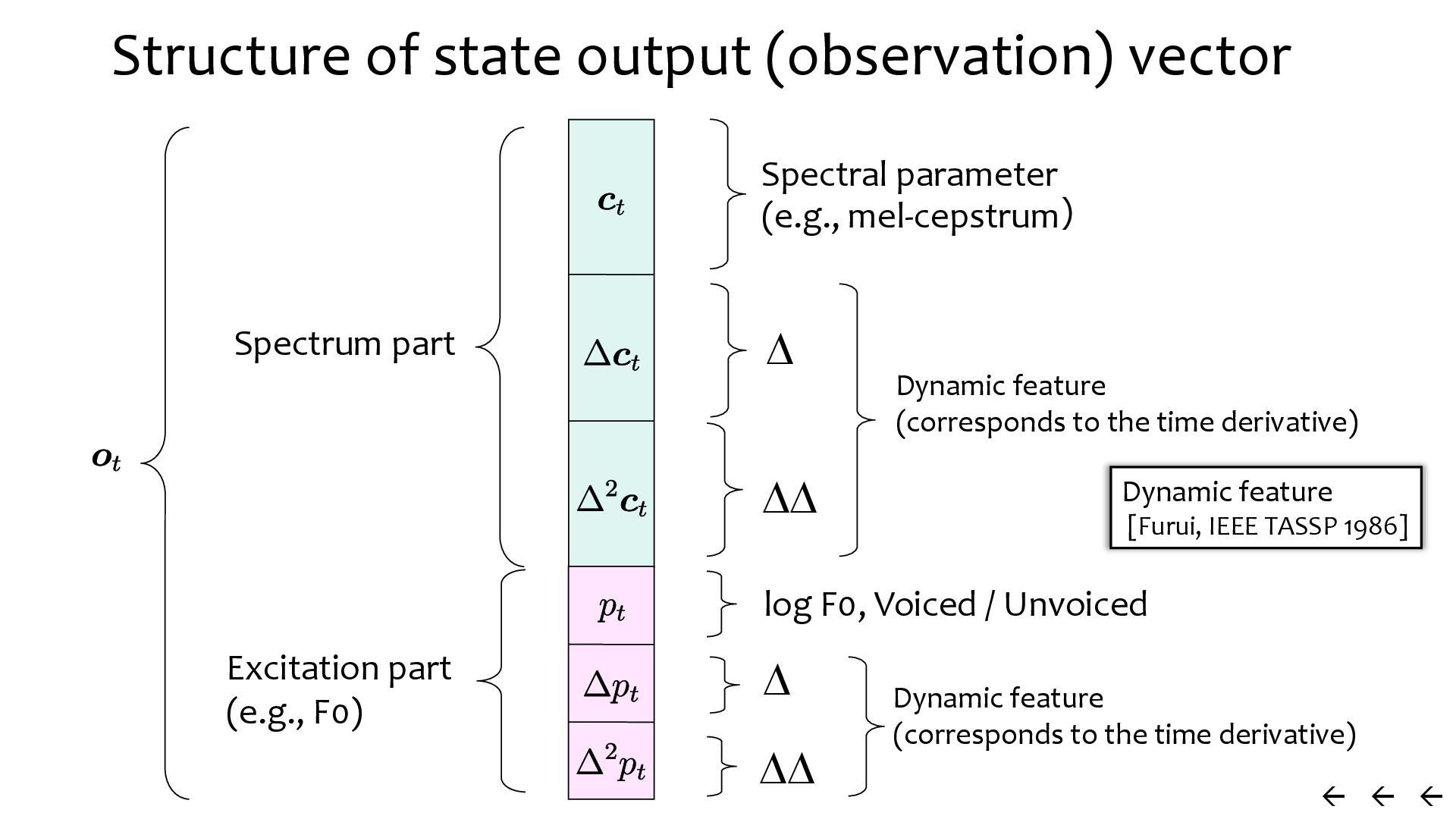{kind=link}
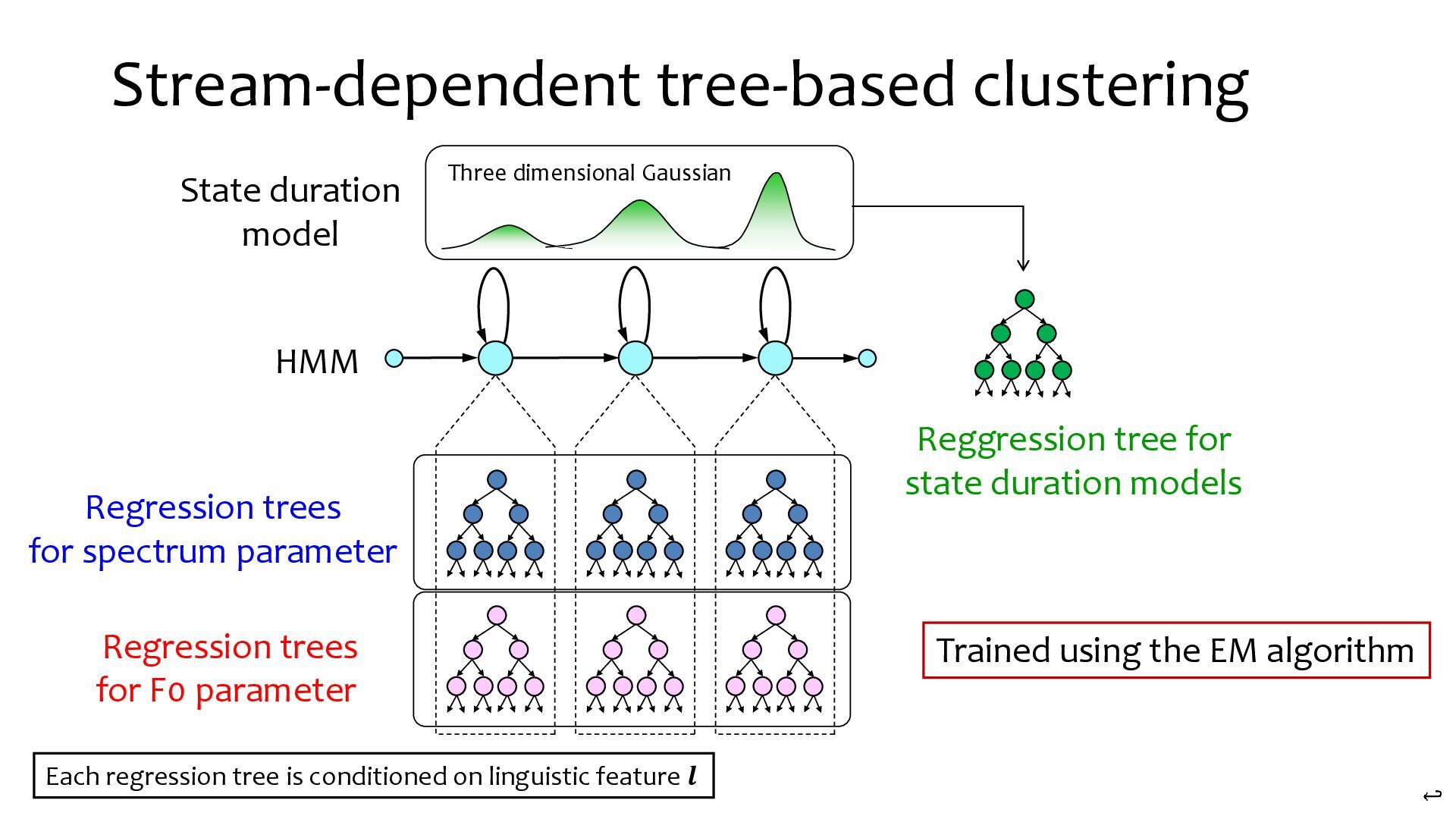{kind=link}
{kind=link}
{kind=link}
{kind=link}
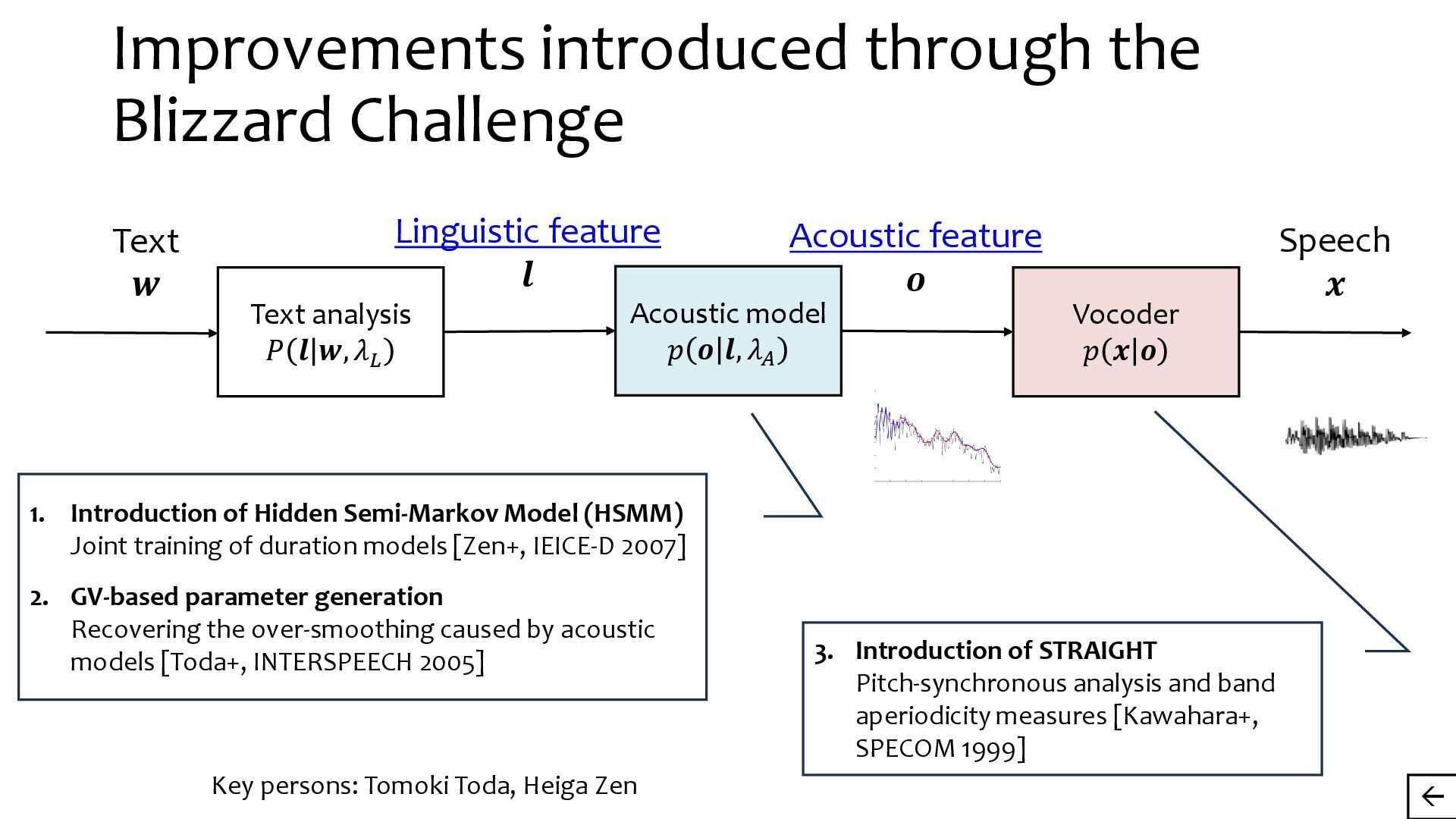{kind=link}
{kind=link}
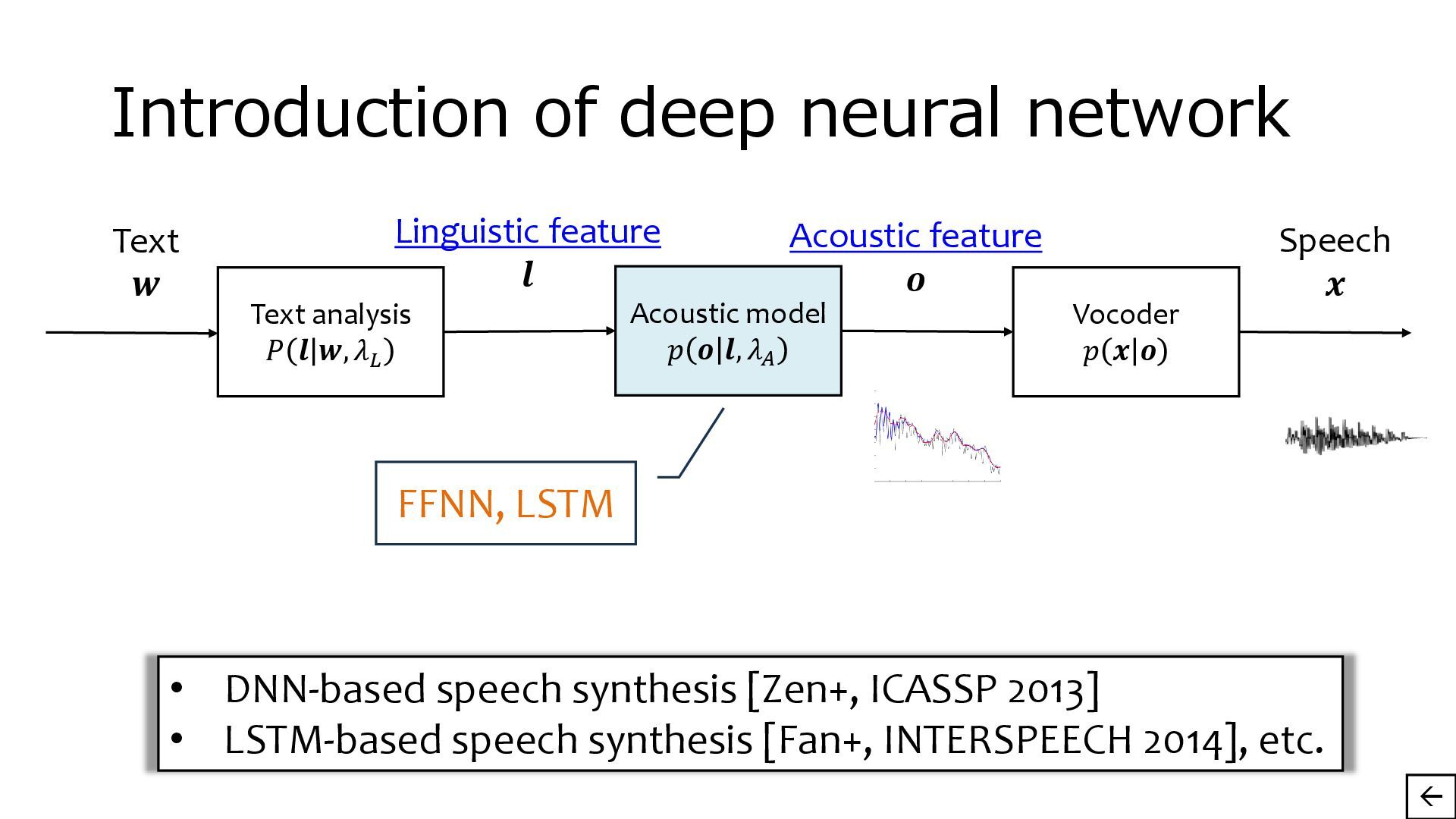{kind=link}
{kind=link}
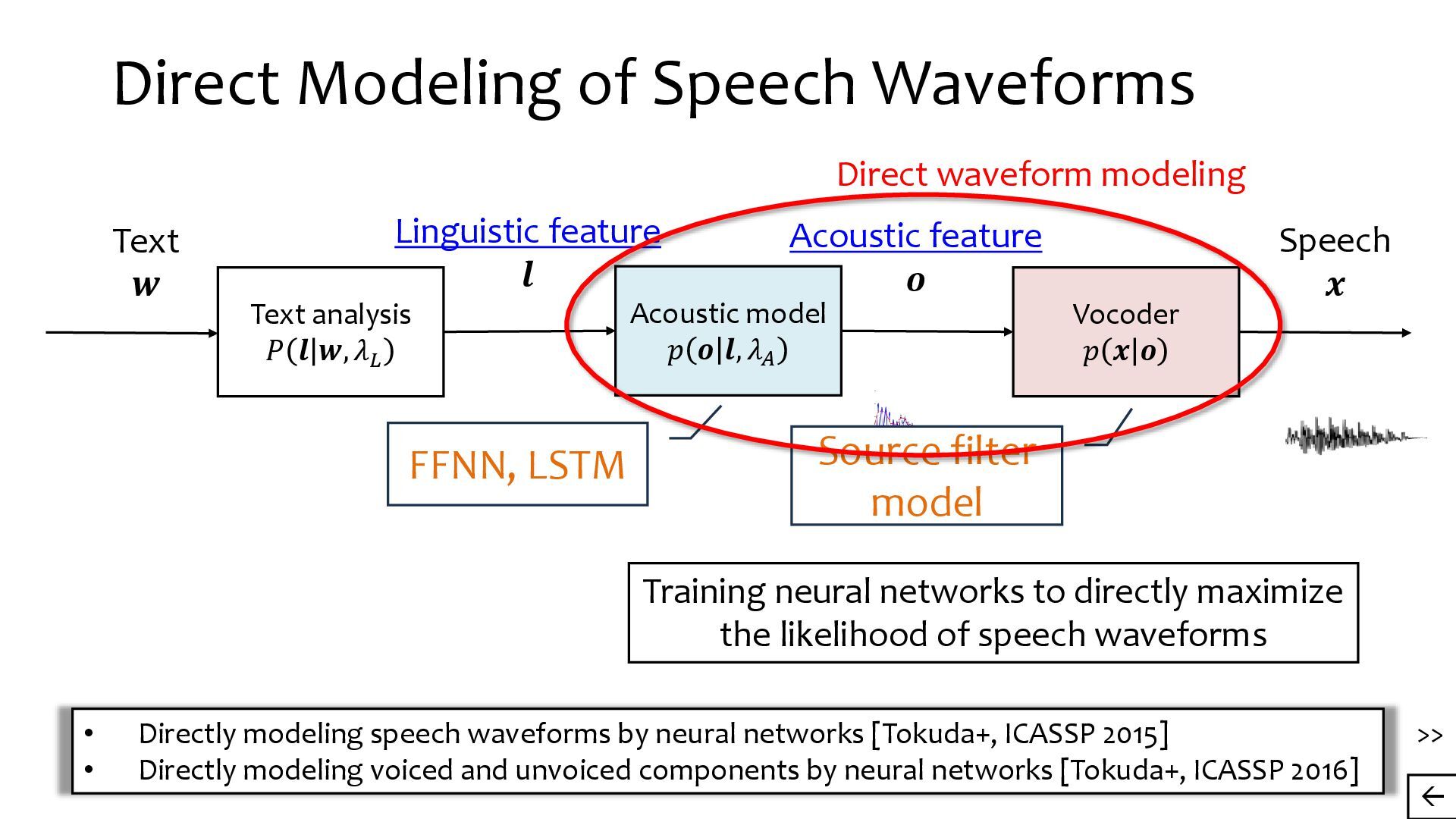{kind=link}
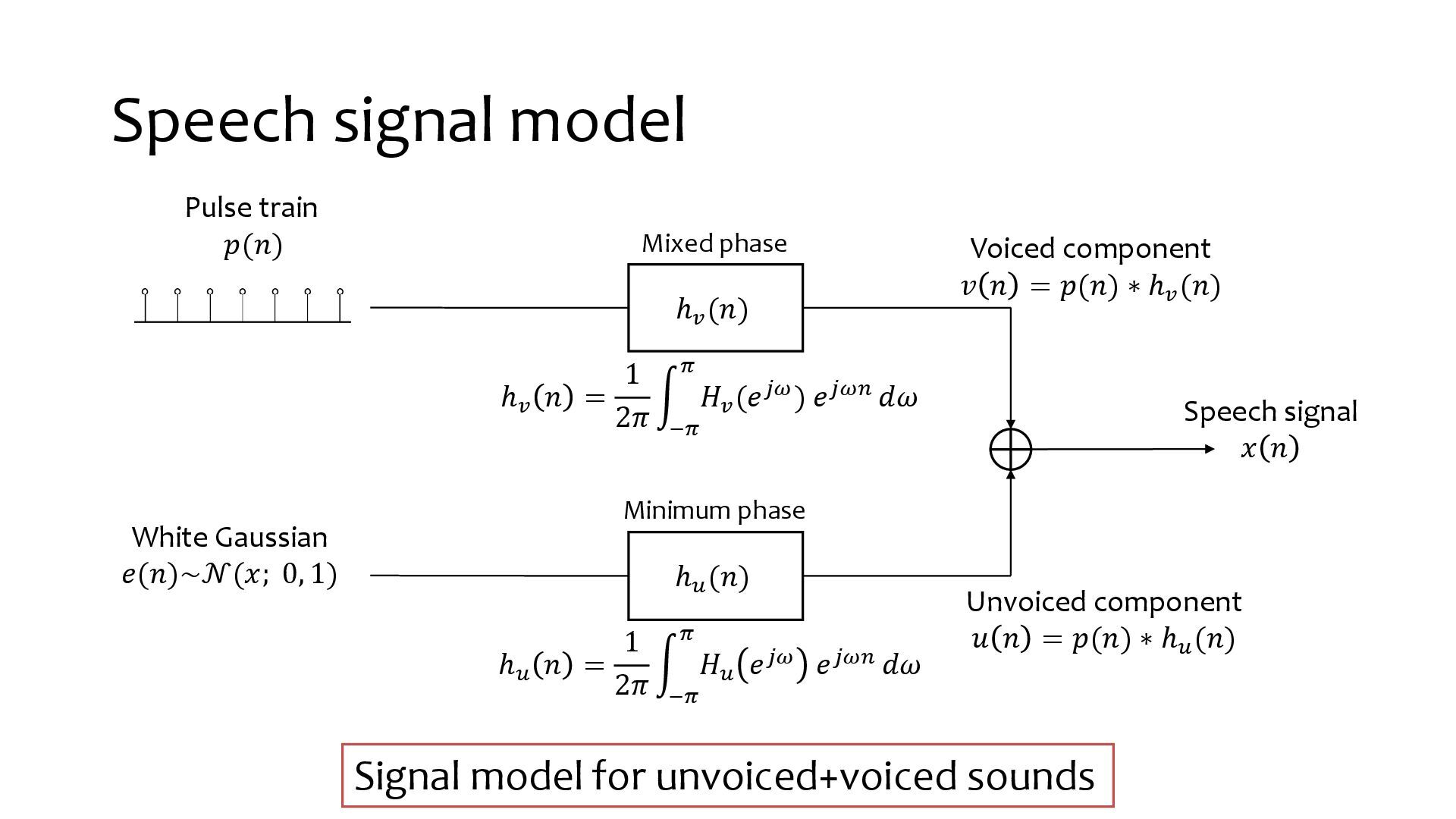{kind=link}
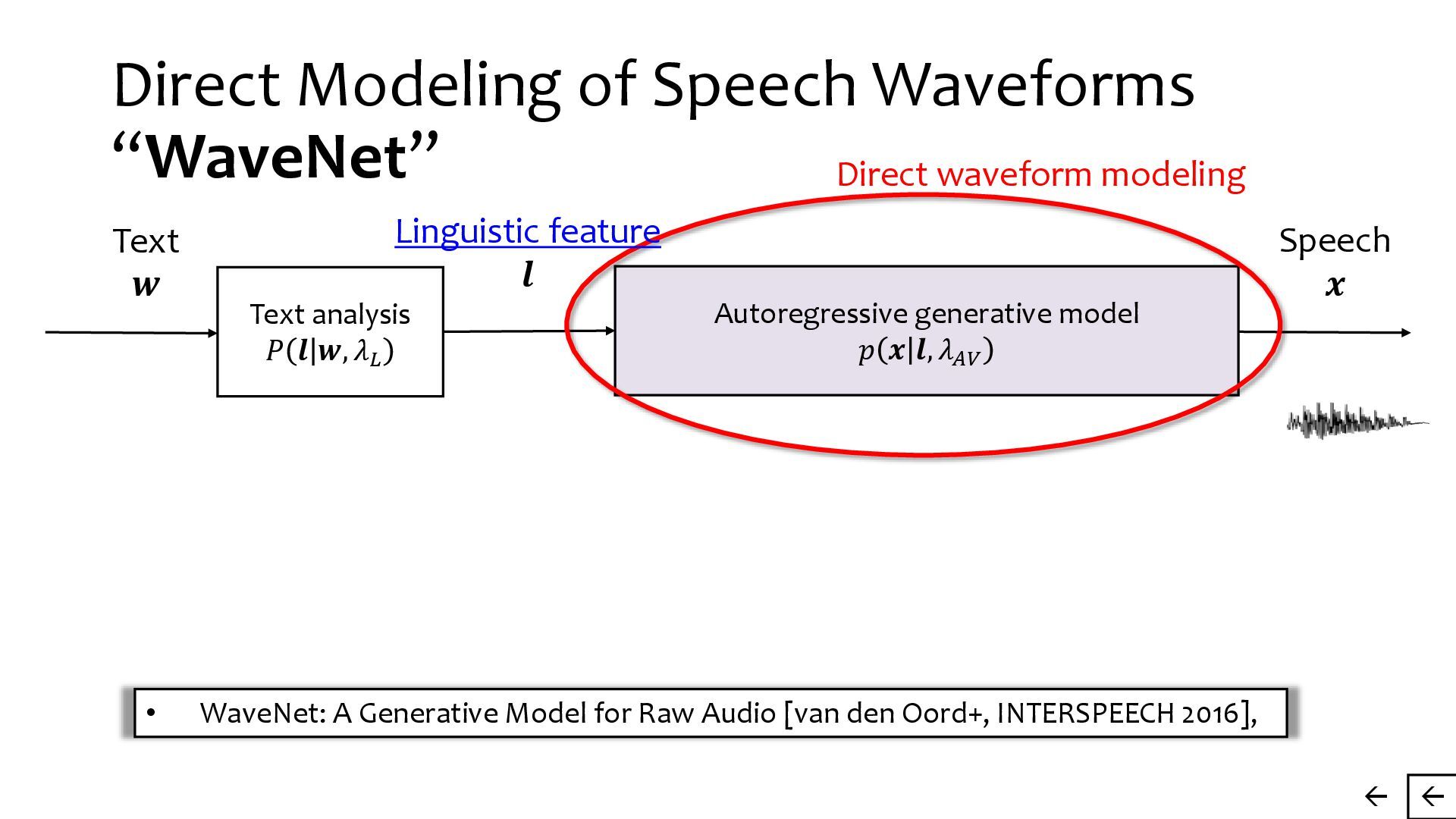{kind=link}
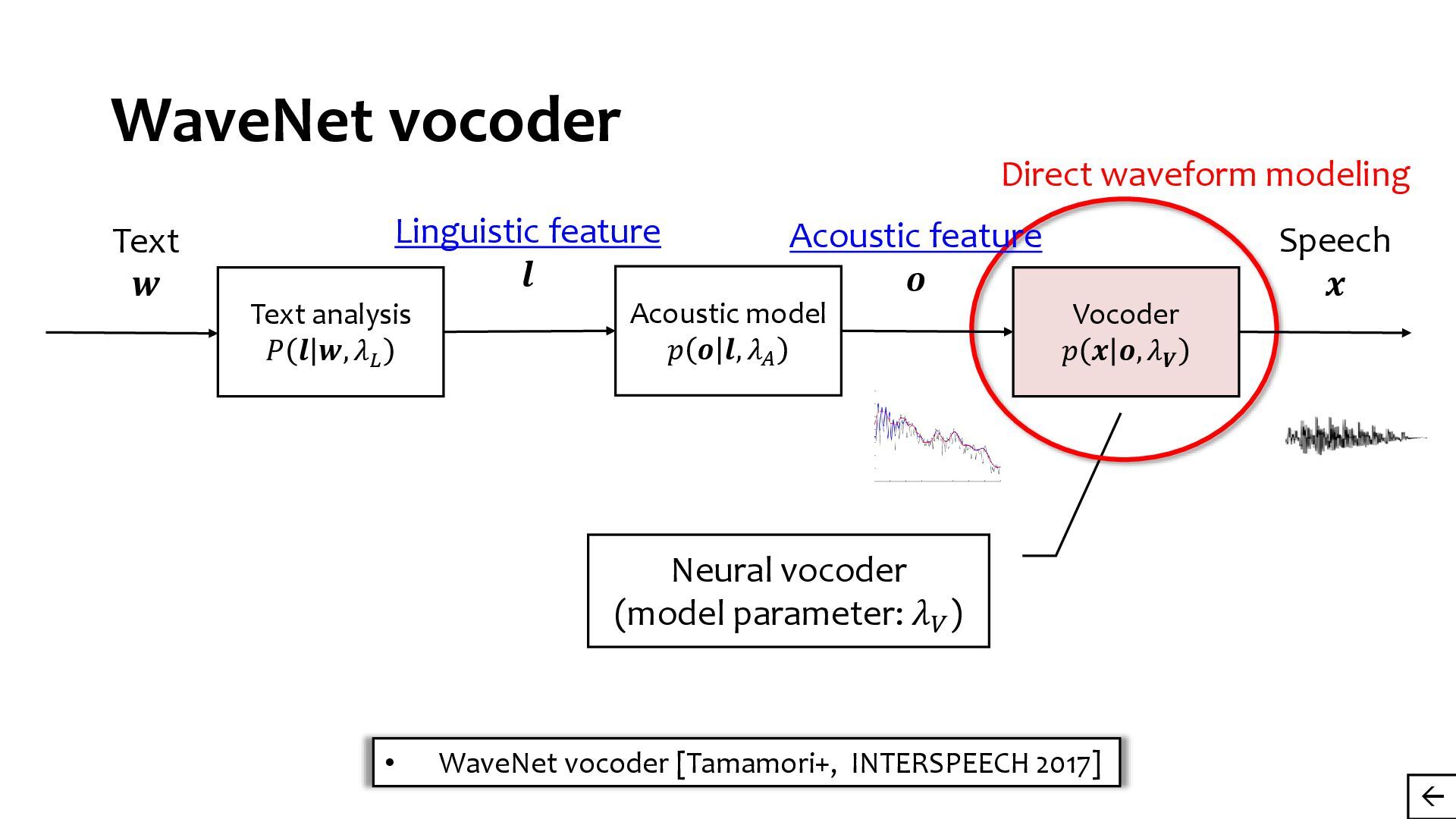{kind=link}
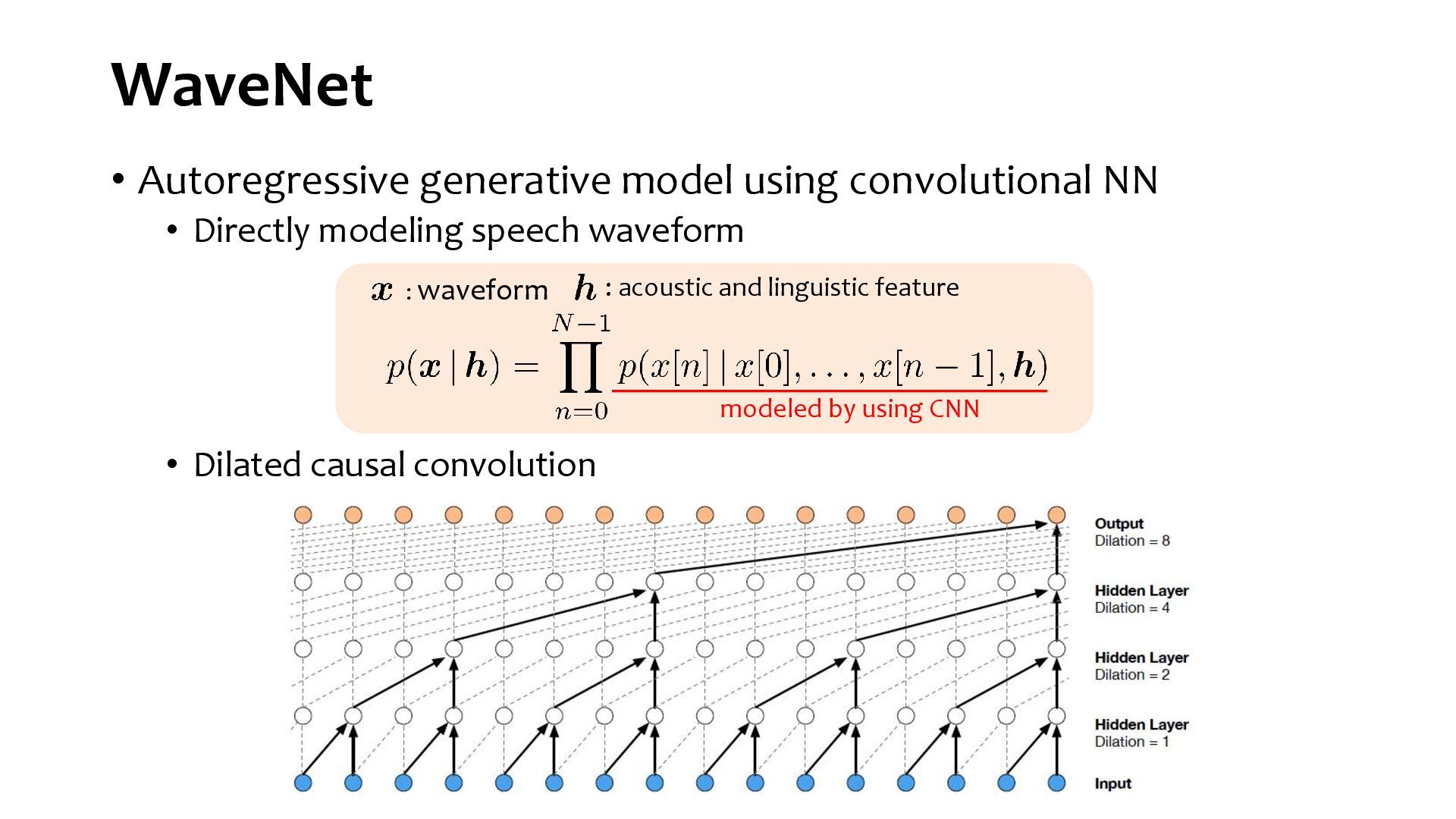{kind=link}
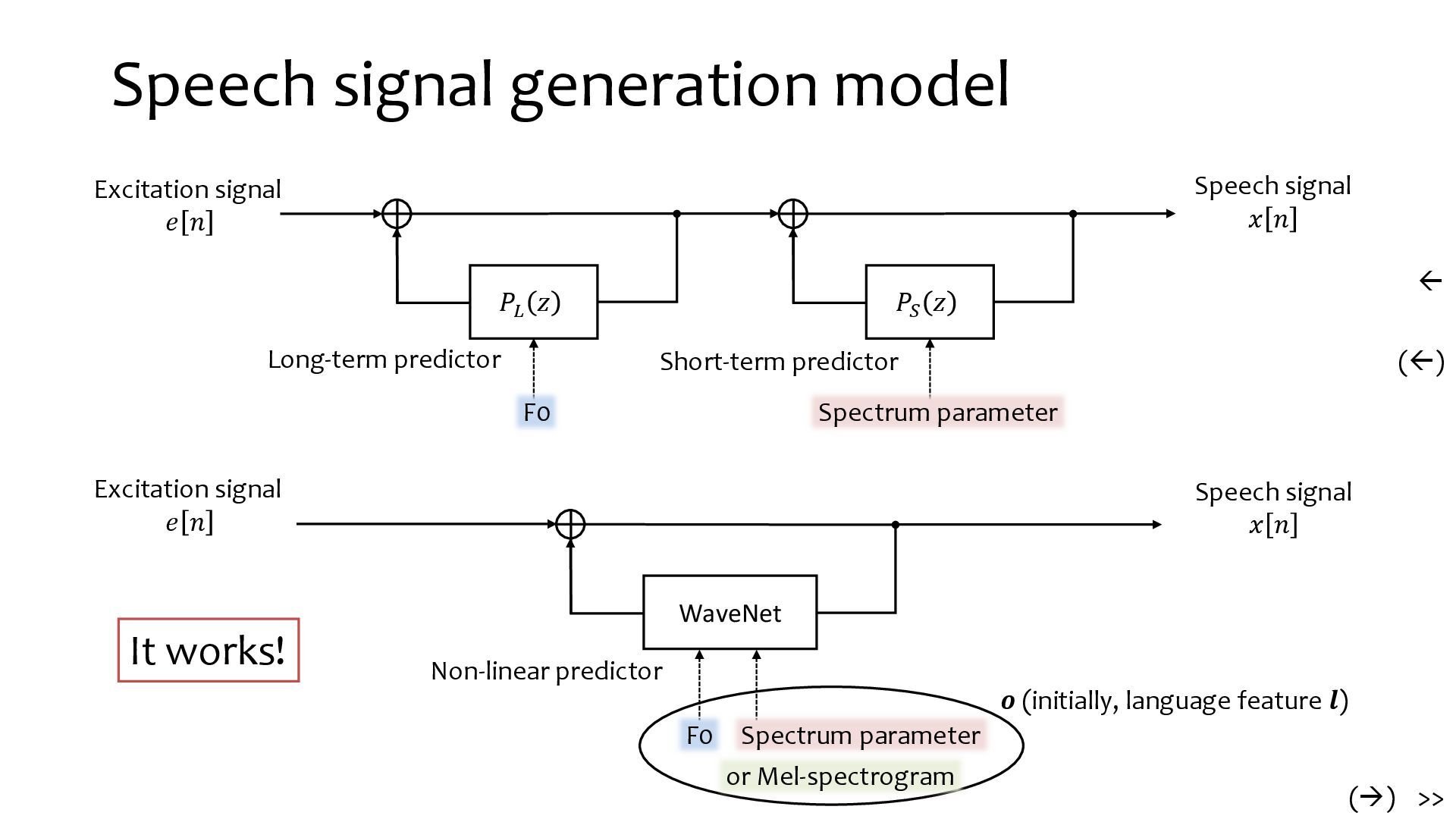{kind=link}
{kind=link}
{kind=link}
![PeriodNet: neural vocoder based on periodic/aperiodic decomposition [Hono+, ICASSP 2020]](https://files.speakerdeck.com/presentations/6fe4da8bfaa14973bc1ce45b7d0f8c55/slide_33.jpg){kind=link}
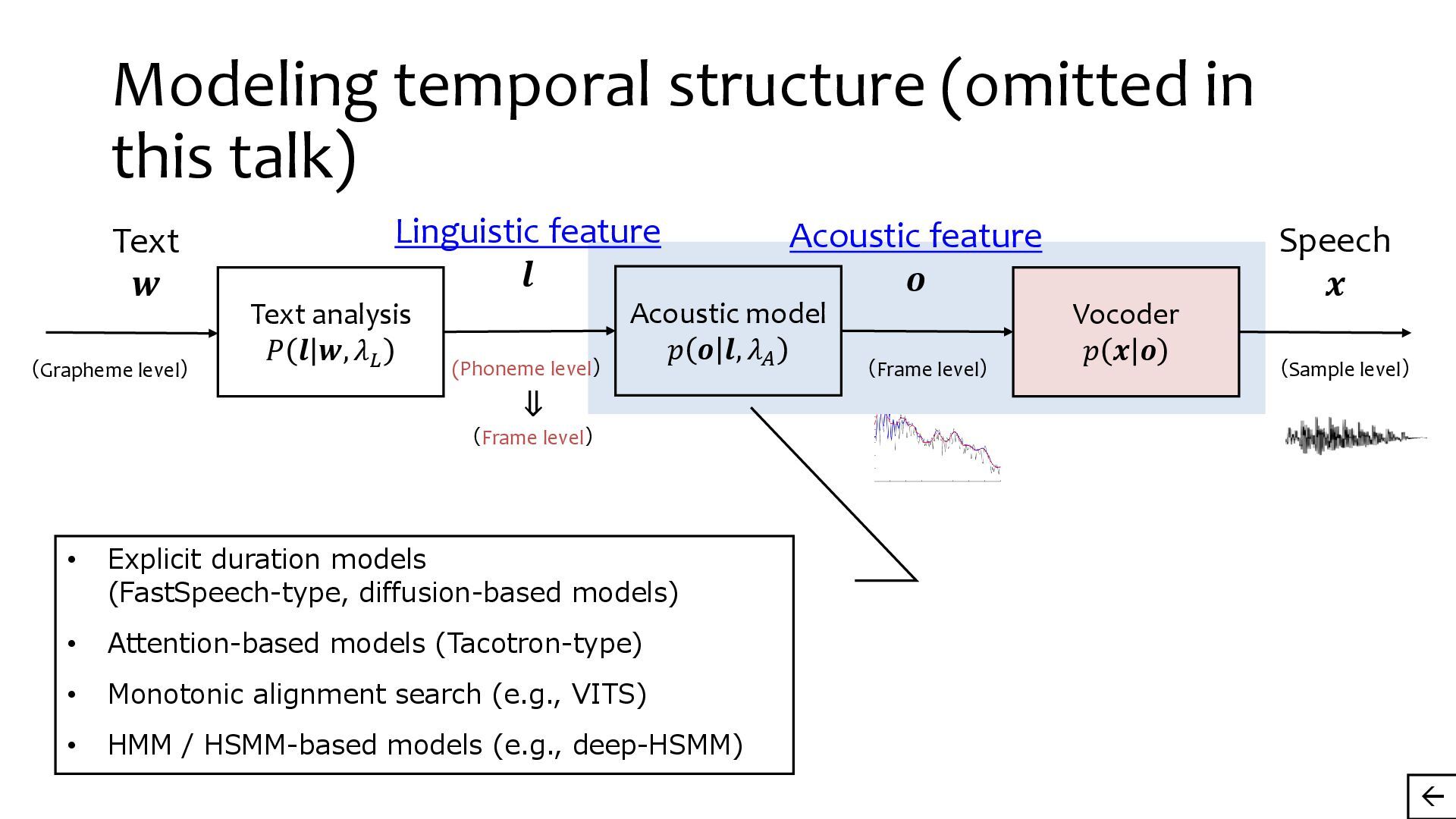{kind=link}
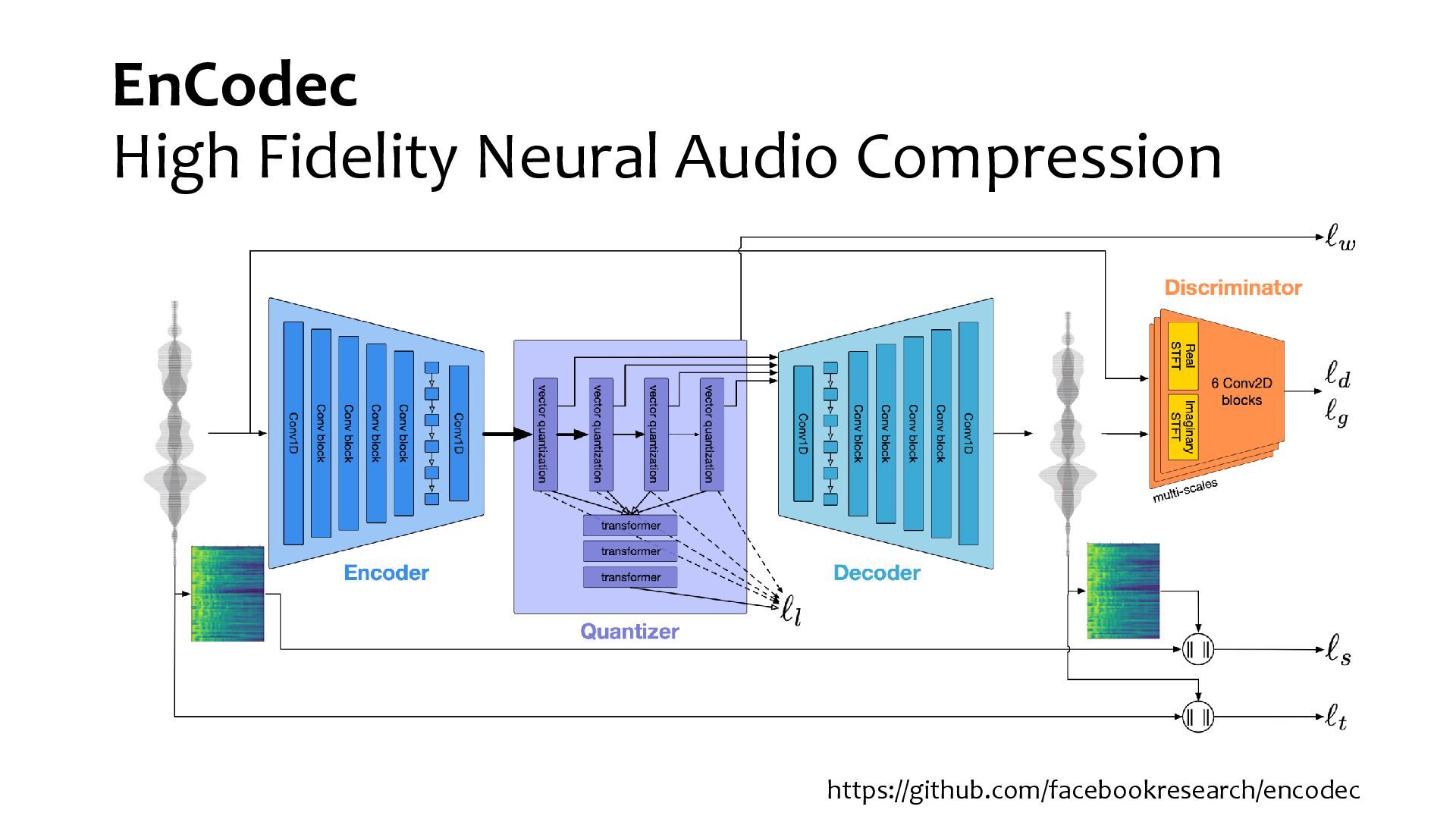{kind=link}
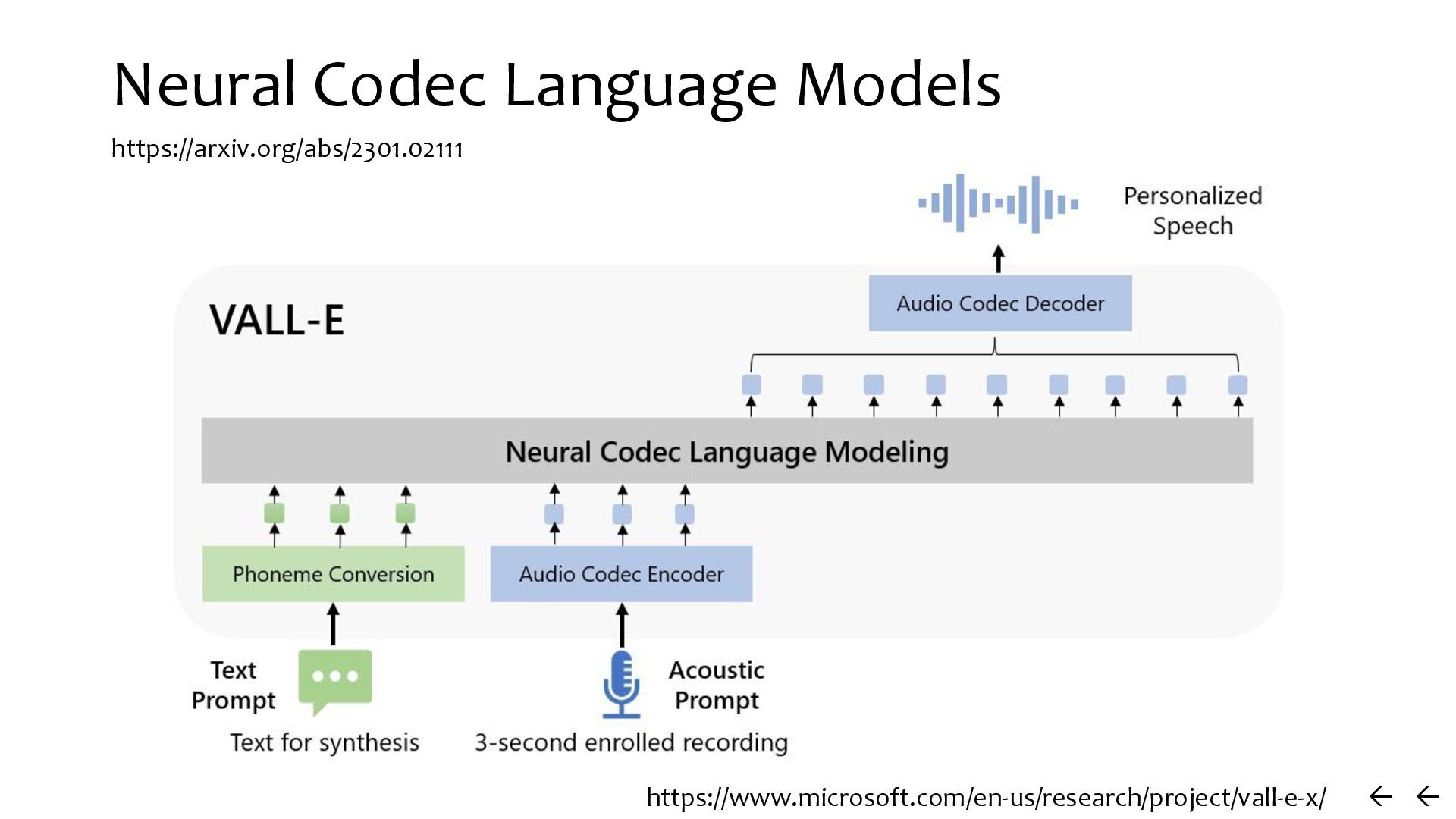{kind=link}
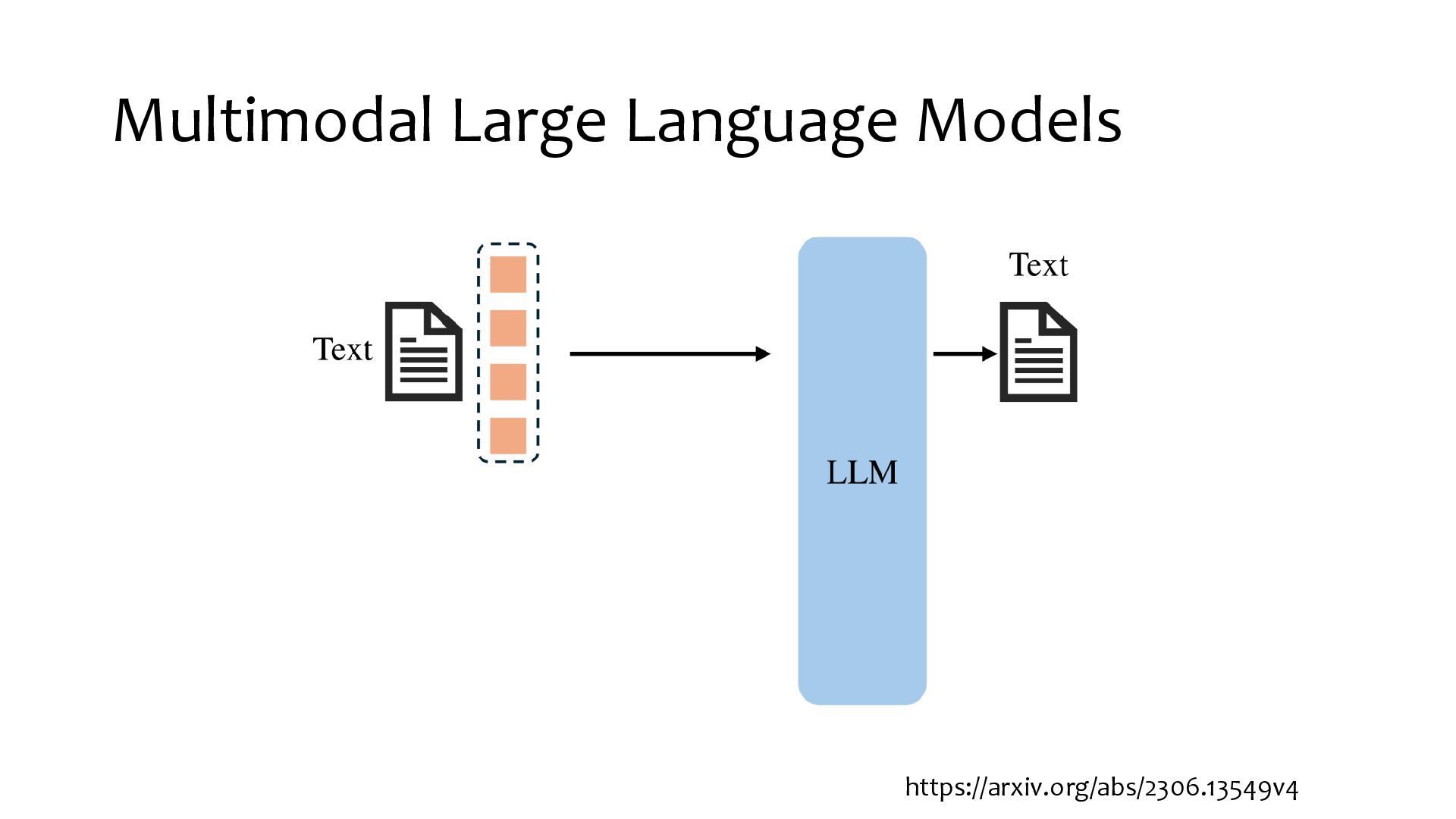{kind=link}
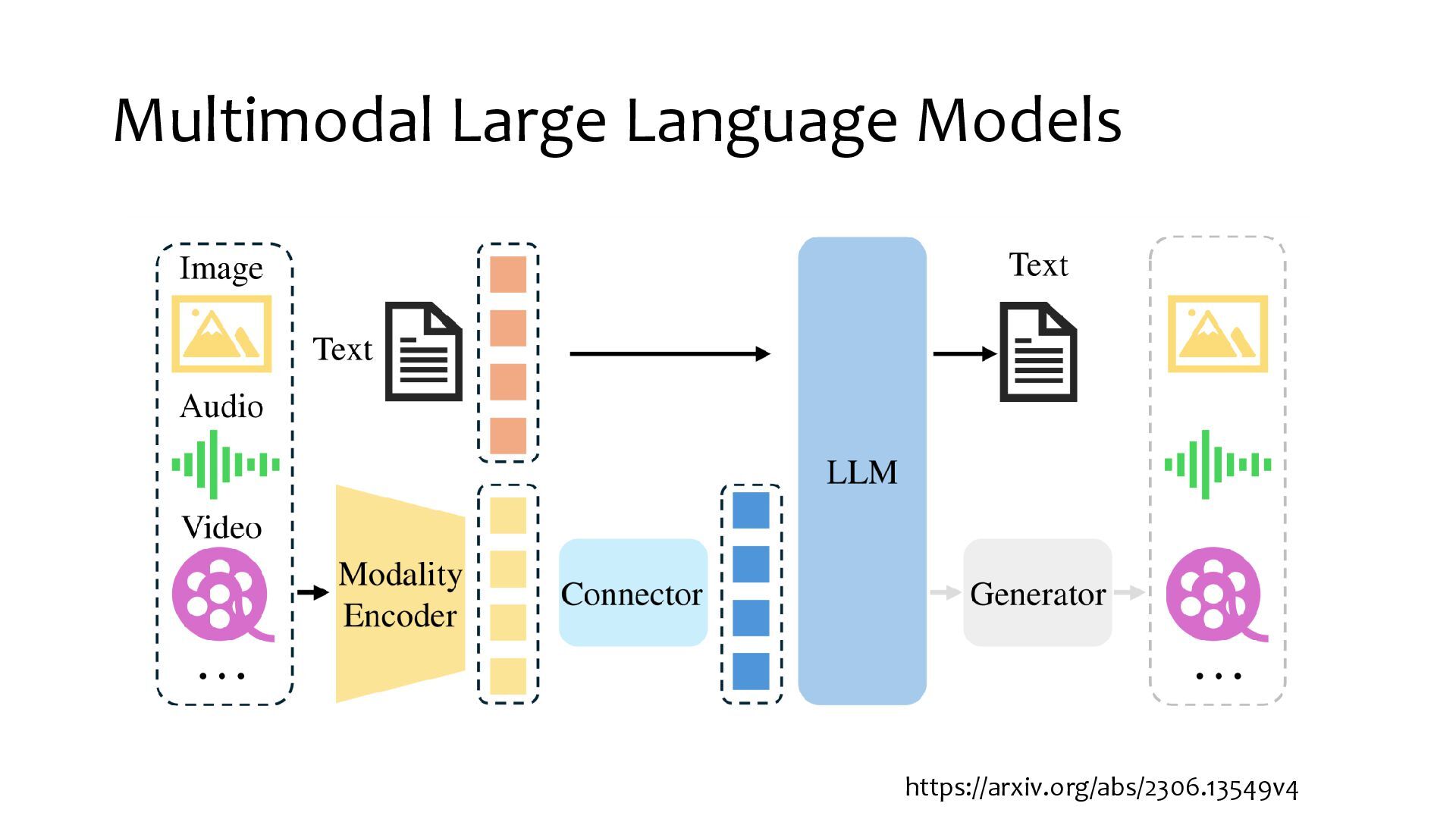{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}