2025.12.4に開催されたGoogle Developer Groups AI for Science - Japanの講演資料です.
概要: 人間の手が持つ「巧緻性」は,精密な操作,複数指の協調,力制御といった高度な能力からなり,これをコンピュータビジョンで理解することは,AR/VRやロボティクス,身体性を持つAIの発展において重要である.しかし,従来の2D画像処理では遮蔽や深度の曖昧性といった課題があり,幾何的・物理的整合性を考慮する3次元的な理解が不可欠である.本講演では,人間動作を扱うための3次元表現基盤(SMPL/MANO等)およびセンサー基盤(RGB/Depth/IMU等)の特性を整理し,センシング技術の現状とその限界について議論する.また,単眼画像からの手指再構成における最新の基盤モデルや,大規模な実世界映像の活用,拡散モデル等の生成技術を用いた動作の補完・予測といったモデリング技術についても解説する.最後に,微細な巧緻性の3次元的把握が,AIが身体性を持って世界を理解・操作する鍵となることを示唆する.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![࢈ۀԠ༻ͷഎܠ • ਓؒߦಈͷղੳɼAR/VRɼΞΫηγϏϦςΟɼϩϘςΟΫεͷల։ 5 ө૾ɾٕೳཧղ [K. Grauman+, CVPR’22] ARάϥε](https://files.speakerdeck.com/presentations/fc6700ea2eb64c2485e4252e6a937d67/slide_4.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![υʔϜऩσʔλྫ 23 InterHand2.6M ྆खͷΠϯλϥΫγϣϯ [G. Moon+, ECCV’20] Goliath-SC ࣗݾ৮ʹؔ͢Δશಈ࡞ [T.](https://files.speakerdeck.com/presentations/fc6700ea2eb64c2485e4252e6a937d67/slide_22.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
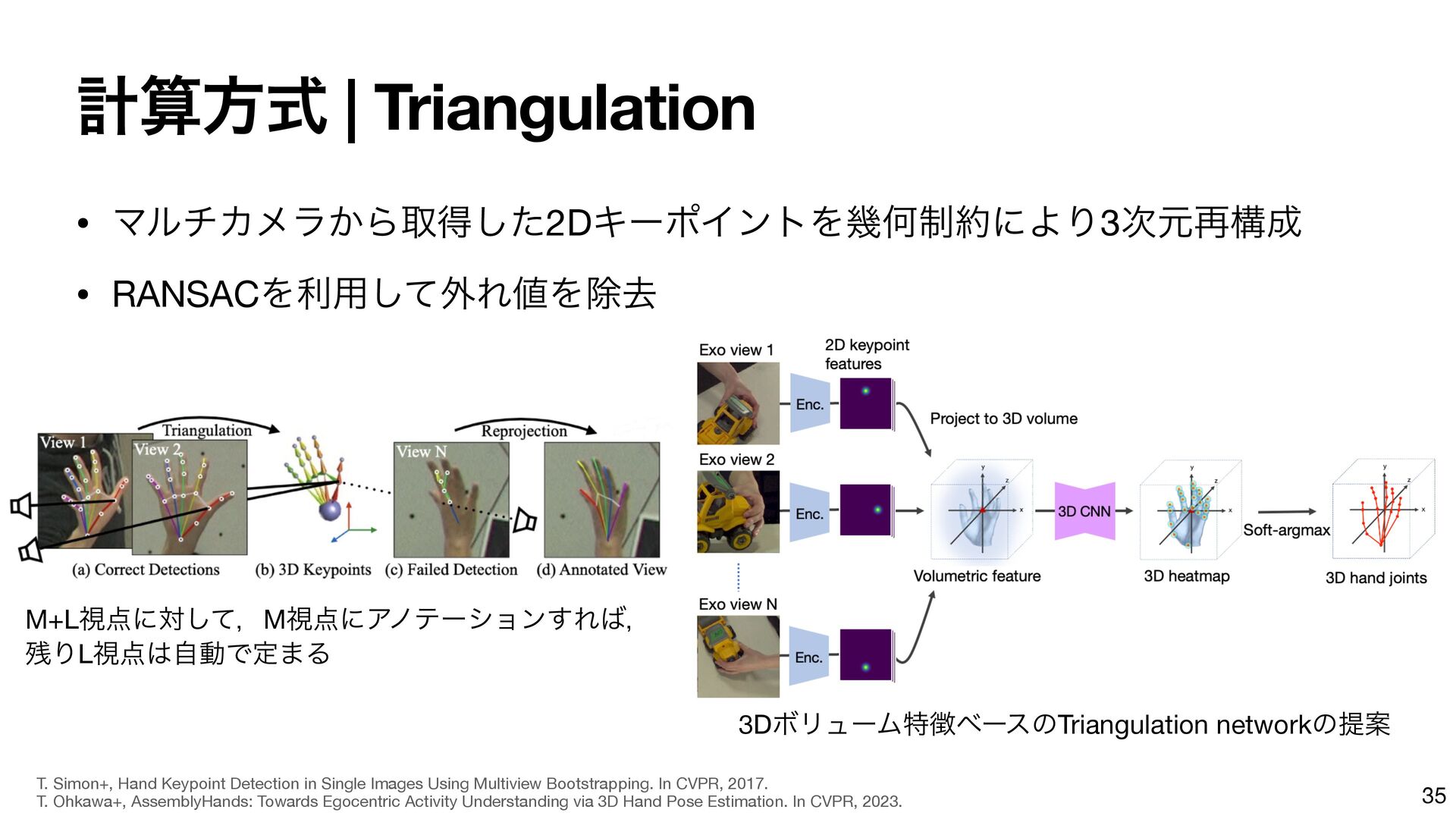{kind=link}
{kind=link}
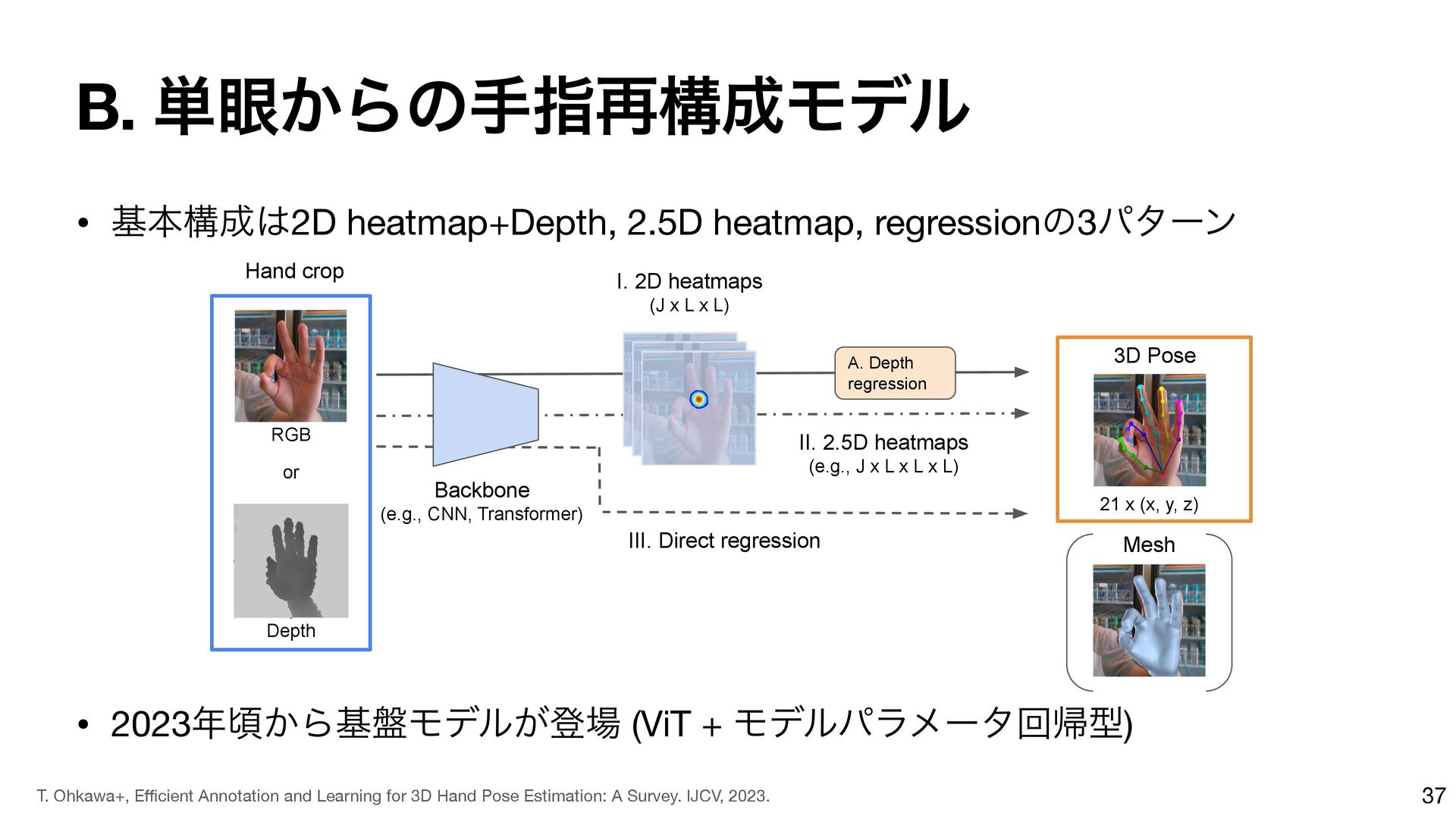{kind=link}
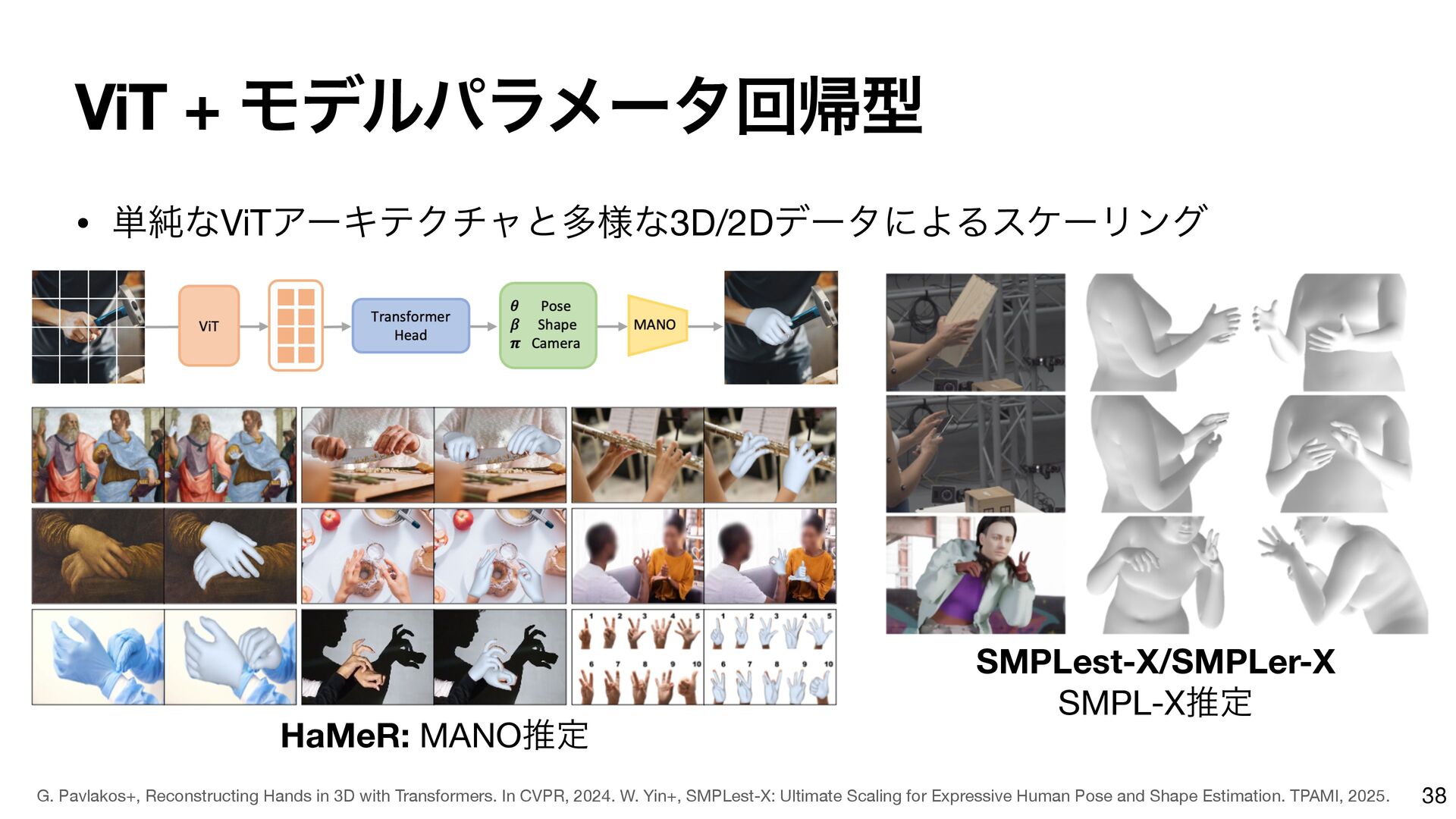{kind=link}
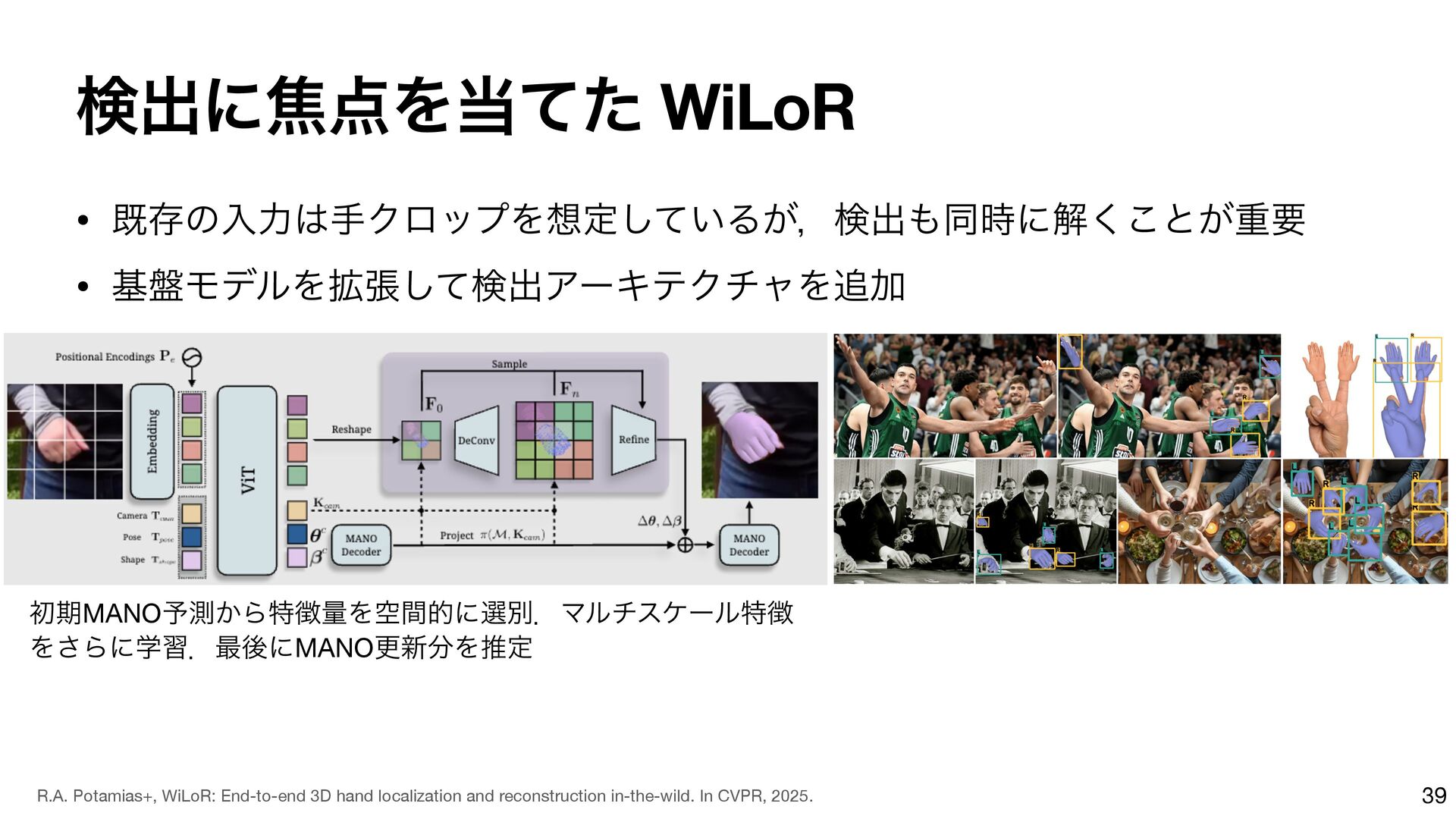{kind=link}
{kind=link}
{kind=link}
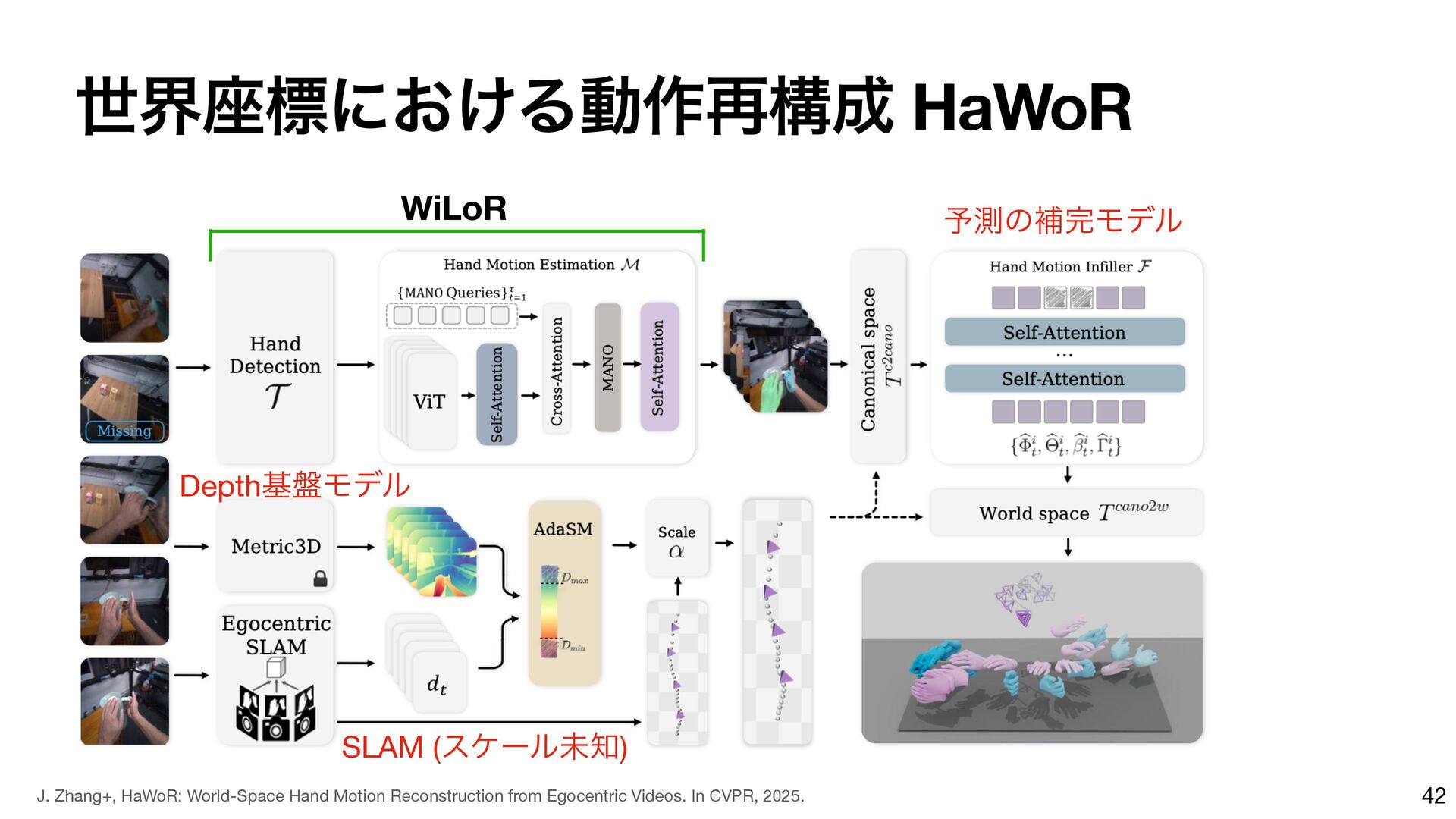{kind=link}
{kind=link}
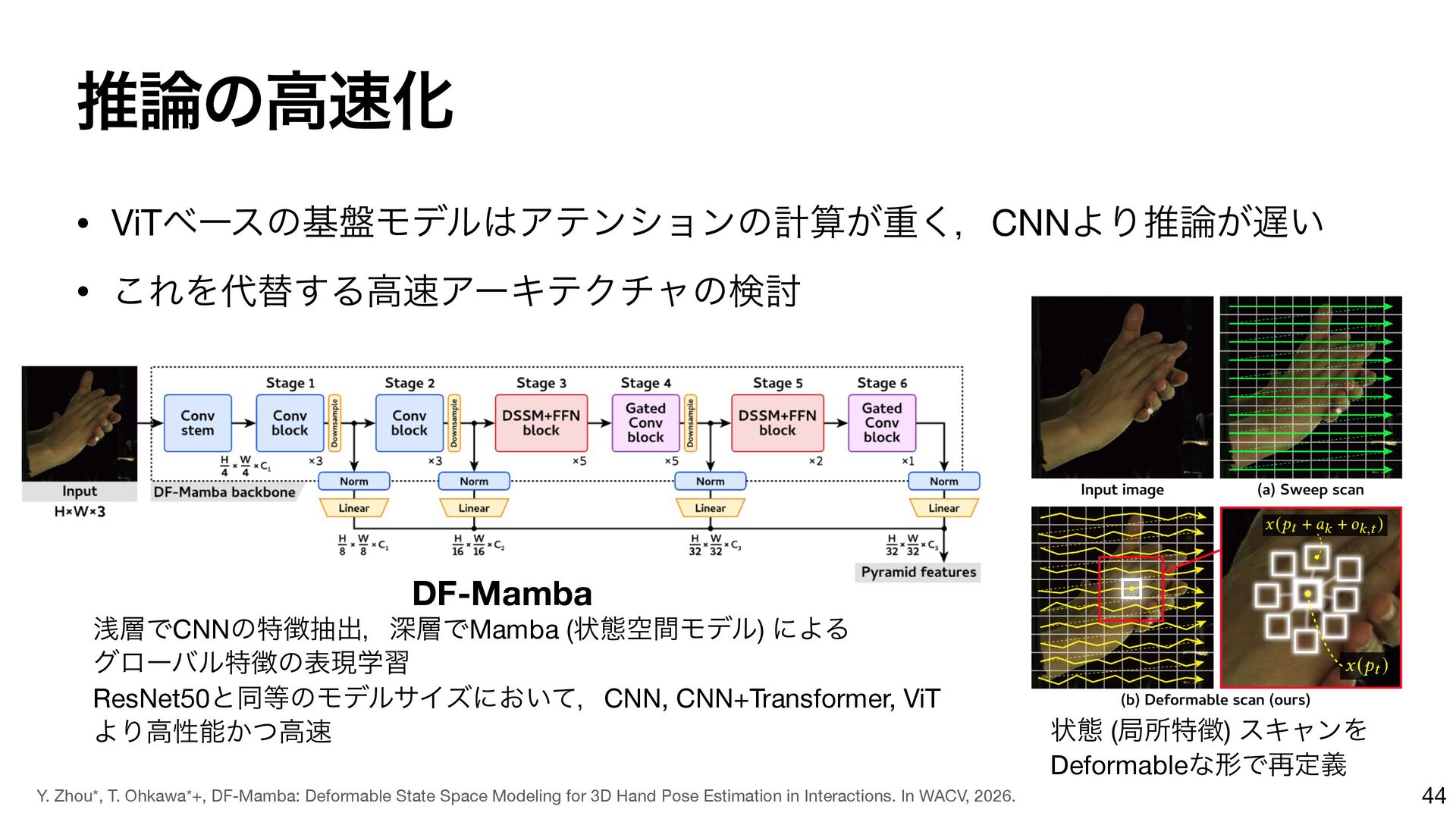{kind=link}
{kind=link}
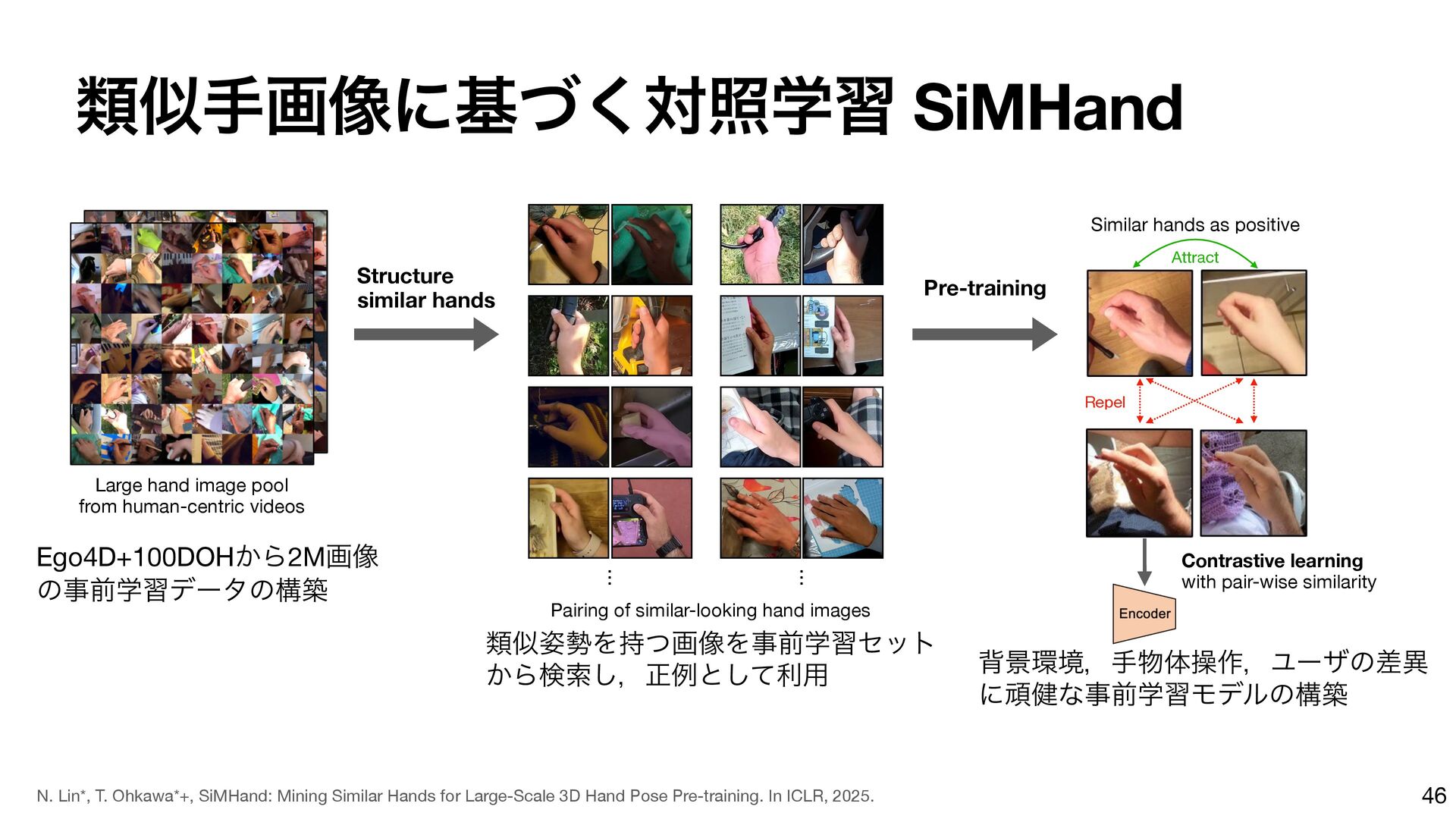{kind=link}
{kind=link}
{kind=link}
{kind=link}
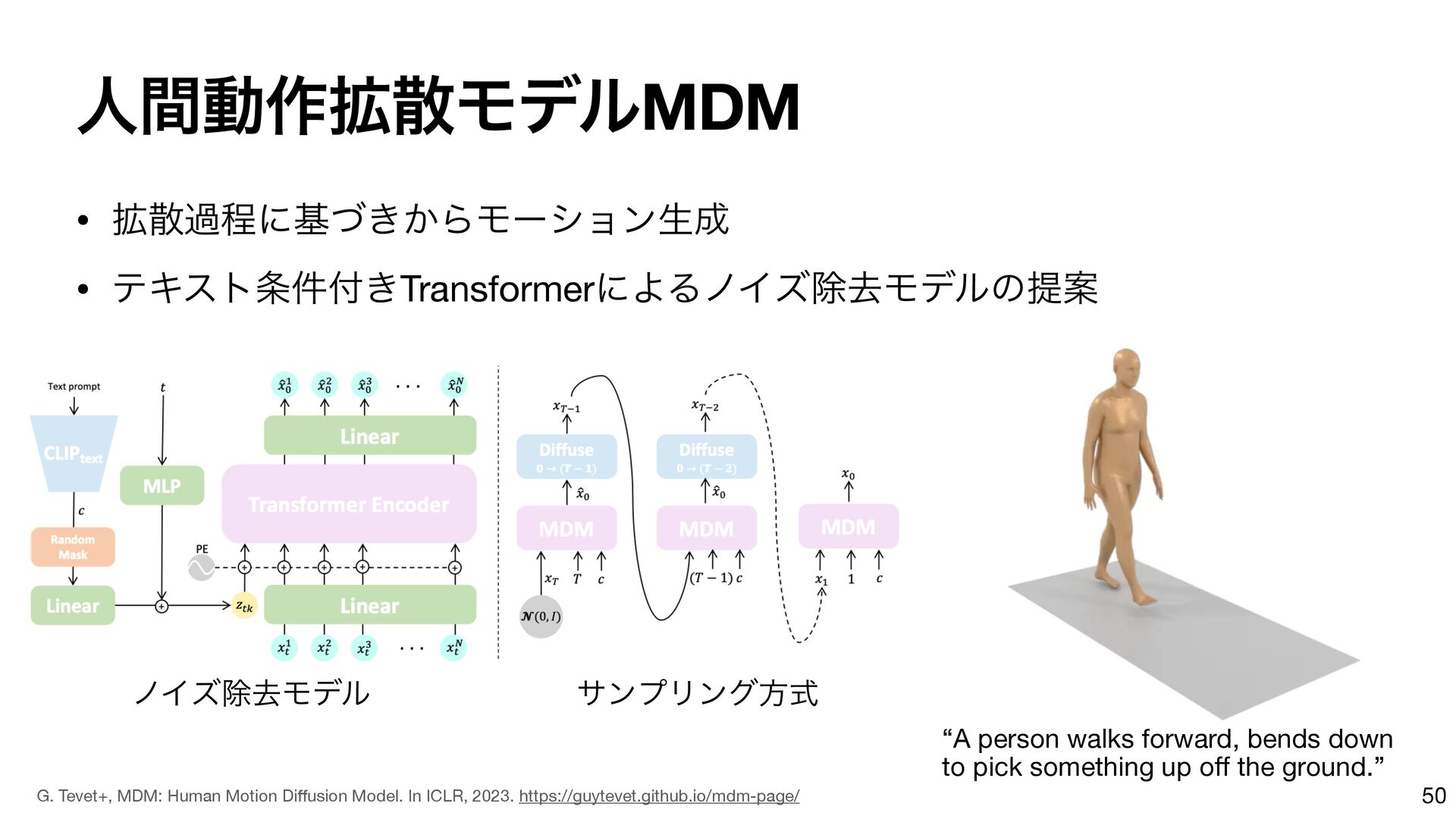{kind=link}
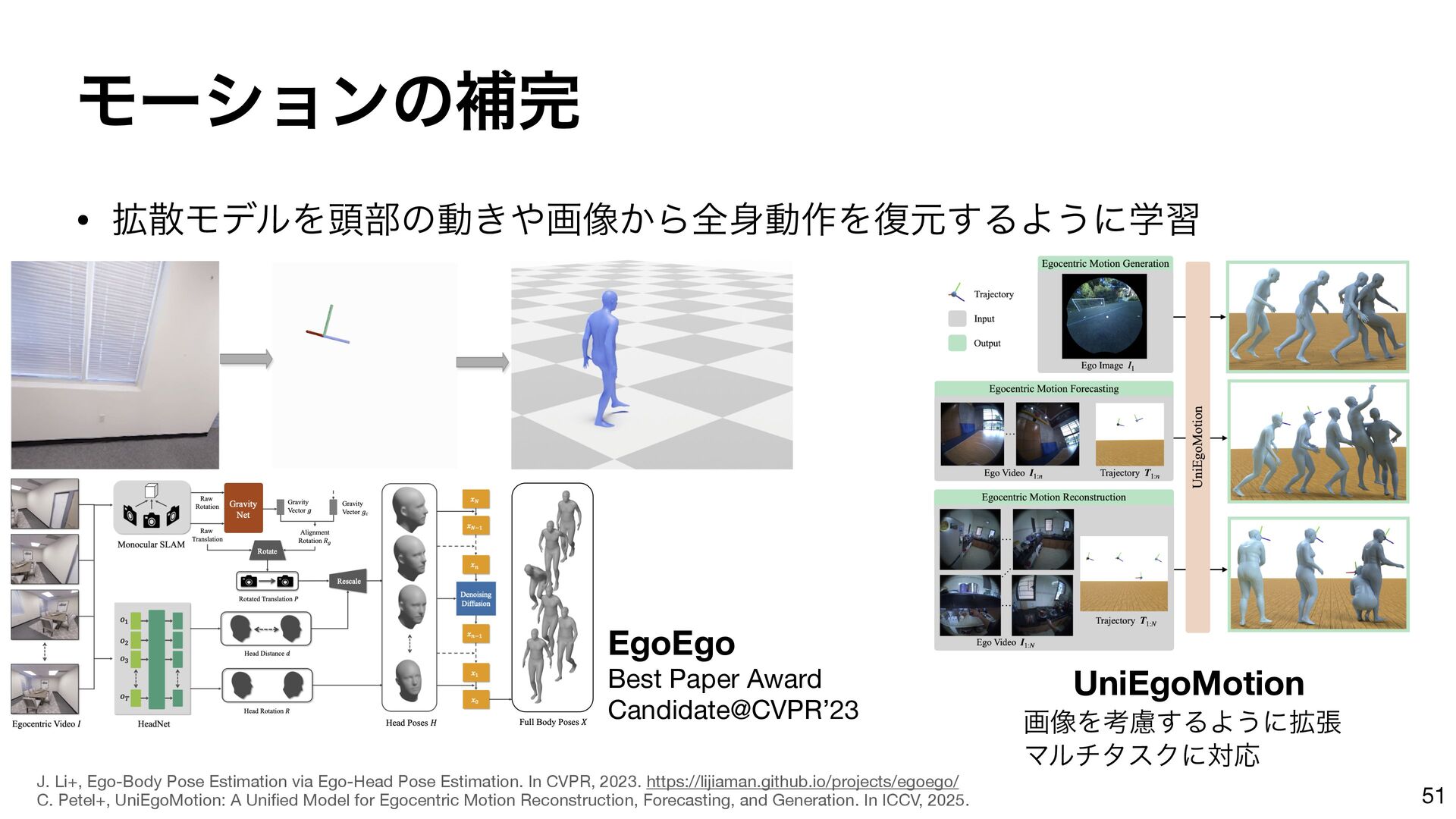{kind=link}
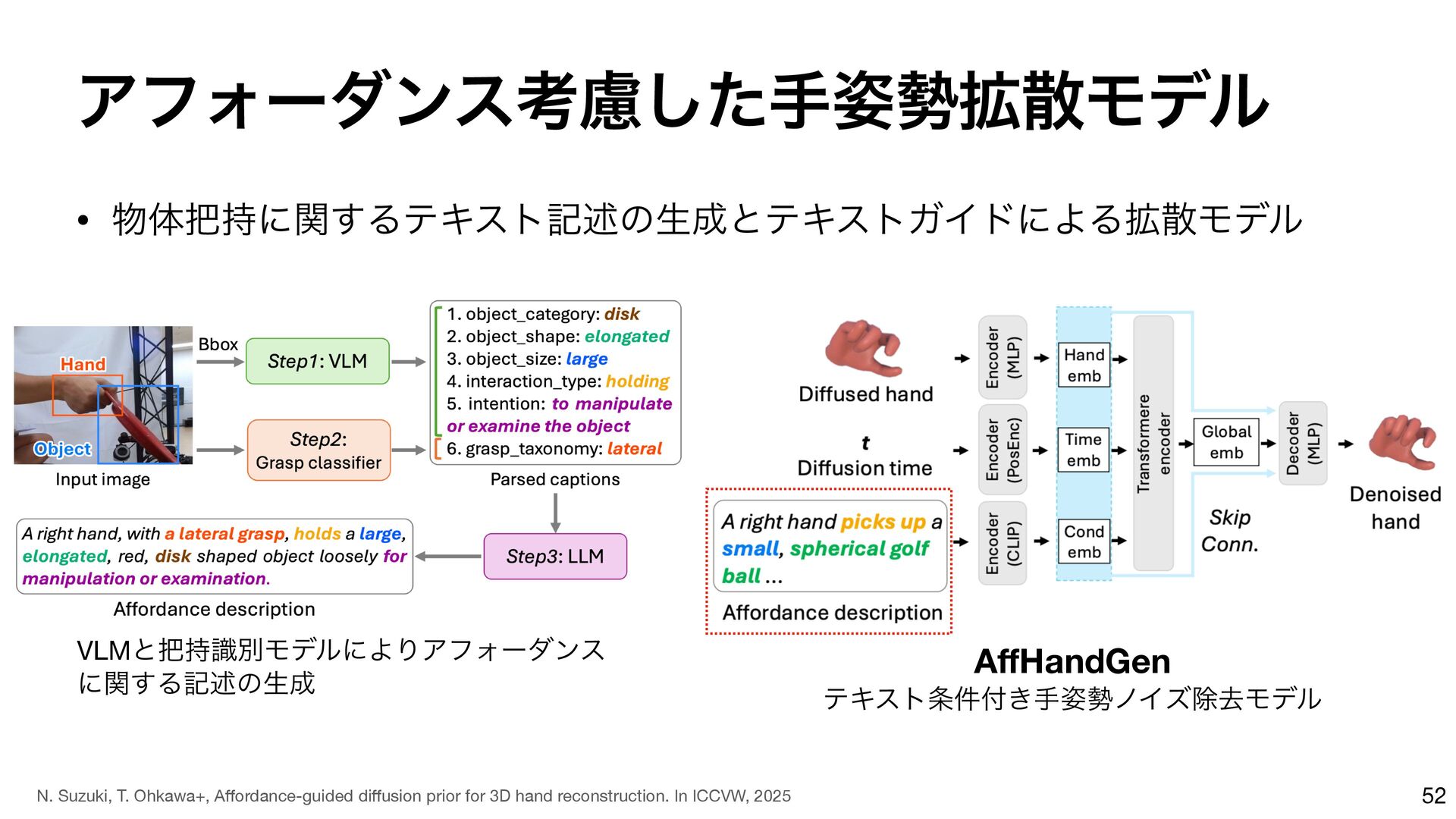{kind=link}
![ΞϑΥʔμϯεߟྀͨ͠ख֦࢟ࢄϞσϧ 53 HaMeR [G. Pavlakos, CVPR’24] Ours Description: “A](https://files.speakerdeck.com/presentations/fc6700ea2eb64c2485e4252e6a937d67/slide_52.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}