ITコンサルタント l 略歴 l 2021/03 京都⼤学⼤学院情報学研究科 修了 l 2021/04 建設系企業に就職(情シス職) l 2023/11 NCDC⼊社 l 趣味など l 読書(百年の孤独をちまちま読む) l 気になってる本︓記号創発システム論ー来るべきAI共⽣社会の「意味」理解に向けてー l ポケモンGO l オタ活 l 好きなAWSサービス l Amazon Bedrock, Amazon CloudWatch 3
l 太宰治を読んだことがない⼈に、「⾛れメロスRAG」の性能評価はできない 2. 返答が微妙だった時の、分析が難しい l そもそもその返答は正しいのか︖ 誤りなのか︖ l ナレッジが⾜りないのか︖ l RAGの回答精度が低いのか︖ l モデル性能が低いのか︖ l プロンプトが邪魔をしているのか︖ l などなど… 6
Bedrock で contextual grounding check を実⾏で きるようになりました(2024/08) l Grounding: モデルからの出⼒が、ナレッジベースの情報にどれだけ基づ いているかを0~1で評価した値 l Relevance: モデルからの出⼒が、ユーザーの質問内容とどれだけ関連し ているかを0~1で評価した値 l GroundingとRelevanceを両⽅評価することで、ハルシネーションを起こ している可能性が⾼い回答をフィルターすることが可能 l Guardrailsのコンソール画⾯では値を確認することができる l Agentに組み込んだ状態で、かつcheckを通過した時の値がどこから も確認できないのが課題 l CloudWatchでモニタリングしたいんです… 8
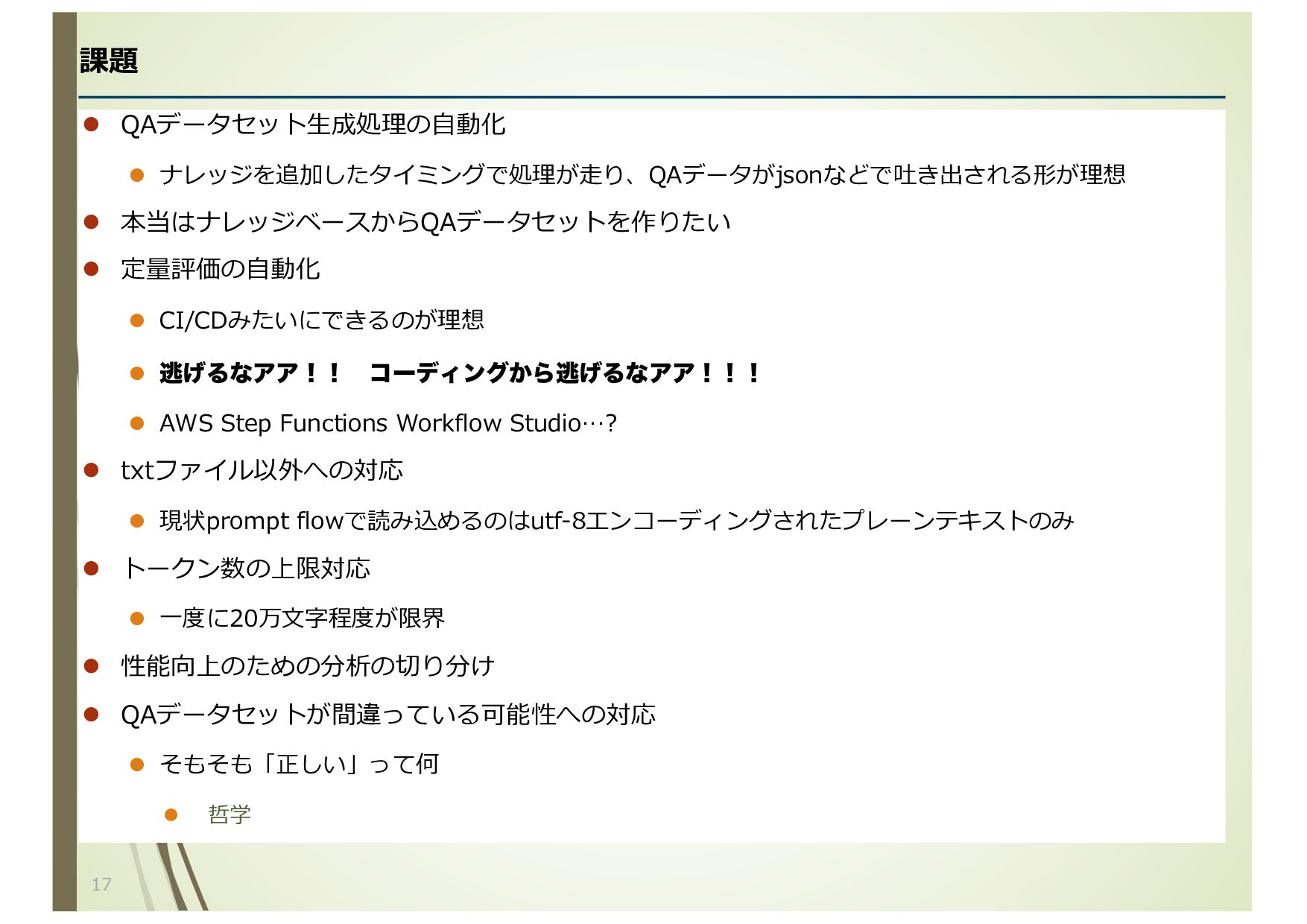
CI/CDみたいにできるのが理想 l ಀ͛ΔͳΞΞʂʂ ίʔσΟϯά͔Βಀ͛ΔͳΞΞʂʂʂ l AWS Step Functions Workflow Studio…? l txtファイル以外への対応 l 現状prompt flowで読み込めるのはutf-8エンコーディングされたプレーンテキストのみ l トークン数の上限対応 l ⼀度に20万⽂字程度が限界 l 性能向上のための分析の切り分け l QAデータセットが間違っている可能性への対応 l そもそも「正しい」って何 l 哲学 17
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}