Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
スケールするというのはどういうことなのか
Search
Sponsored
·
Ship Features Fearlessly
Turn features on and off without deploys. Used by thousands of Ruby developers.
→
Kurochan
October 22, 2023
Technology
5.3k
14
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
スケールするというのはどういうことなのか
社内の勉強会で発表しました
Kurochan
October 22, 2023
More Decks by Kurochan
See All by Kurochan
ABEMAのバグバウンティの取り組み
kurochan
1
1k
2026年の個人的テーマ: 「計算機を燃やせ🔥」
kurochan
1
160
つなぐ、届ける、変える- コンテンツ配信の最前線ト——ク
kurochan
0
150
サイバーエージェント流クラウドコスト削減施策「みんなで金塊堀太郎」
kurochan
4
3.3k
AWS Elemental MediaPackageと格闘🤼
kurochan
2
120
サイバーエージェントでのSlack活用事例 @ 2025
kurochan
5
260
15年入社者に聞く! これまでのCAのキャリアとこれから
kurochan
1
380
入門 電気通信事業者
kurochan
13
5.9k
AWS x さくらのクラウドのハイブリッドクラウドによる安価なフレッツ閉域網接続の実装
kurochan
9
6.3k
Other Decks in Technology
See All in Technology
ソフトウェアアーキテクチャ研修【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
220
壊して学ぶAWS CDK: そのcdk deployで消えるもの、残るもの
k_adachi_01
1
500
Playwright × AI Agent でE2Eテストはどう変わるか AI駆動テストの可能性と実用検証の結果
taiga7543
2
870
kaonavi Tech Night#1
kaonavi
0
170
データ活用研修 データマネジメント【MIXI 26新卒技術研修】
mixi_engineers
PRO
2
100
仕様駆動開発、導入半年。「本当に速くなってるの?」にデータで答える / AICon2026_hirakawa
rakus_dev
0
340
Claude Mythos、Fable...フロンティアAIの最新動向と企業のセキュリティ対策
flatt_security
0
130
AI時代におけるエンジニアの新たな役割──FDEとクオリアの探求/登壇資料(戸井田 裕貴)
hacobu
PRO
0
380
AI時代のPlaywright活用(システムテストを自動化する ー 実行エンジンにPla ywrightを選んだ理由)
ynisqa1988
2
1k
『モデル + ハーネス』で読み解く AIエージェント入門
oracle4engineer
PRO
2
190
プロダクト開発組織の現在地(Ver.2026/07) / product-organization
kaonavi
0
470
SoccerMaster: A Vision Foundation Model for Soccer Understanding
kzykmyzw
0
180
Featured
See All Featured
Building an army of robots
kneath
306
46k
The SEO identity crisis: Don't let AI make you average
varn
0
520
Tell your own story through comics
letsgokoyo
1
1k
SEO in 2025: How to Prepare for the Future of Search
ipullrank
3
3.7k
Principles of Awesome APIs and How to Build Them.
keavy
128
18k
AI Search: Where Are We & What Can We Do About It?
aleyda
0
7.7k
Building AI with AI
inesmontani
PRO
1
1.1k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
760
Side Projects
sachag
455
43k
Embracing the Ebb and Flow
colly
88
5.1k
How To Stay Up To Date on Web Technology
chriscoyier
790
250k
Optimising Largest Contentful Paint
csswizardry
37
3.8k
Transcript
スケールするというのはどういうことなのか 株式会社サイバーエージェント AI事業本部 黒崎 優太 (@kuro_m 88 )
はなすこと • おもに⾮技術職向けに以下の解説をします • システムがスケールするっていうのはどういうことなのか • スケールさせるための基本的な考え⽅ • 基本情報技術者試験で出そうなくらいの内容でやさしくしたつもり •
キーワード • スケールアップとスケールアウト • アムダールの法則 • リトライ • 冪等性
[PR] イラスト図解でよくわかる ITインフラの基礎知識 • 興味持ったらぜひ🤔 • 書いたの5年前だけどそんなに変わってないはず https://gihyo.jp/book/ 8
スケールアップと スケールアウト
スケールするとは
スケールする • ⽇本語だと「規模が⼤きくなる」? • システムの要求の規模が⼤きくなっても処理能⼒をそれに合わせて拡張でき ること • 情報科学の知識が役に⽴ちます
スケールアップとスケールアウト
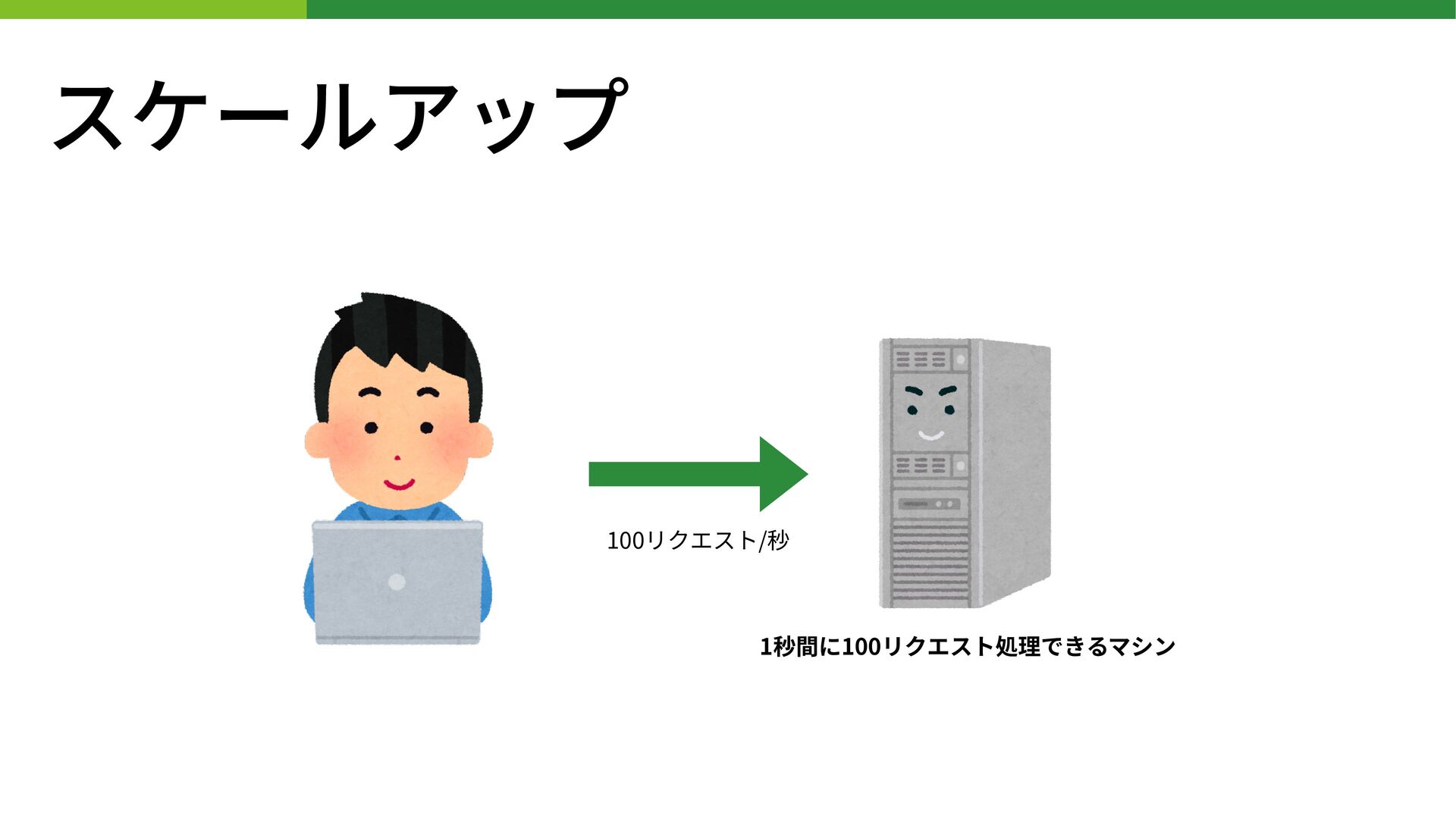
スケールアップ 1秒間に100リクエスト処理できるマシン 100リクエスト/秒
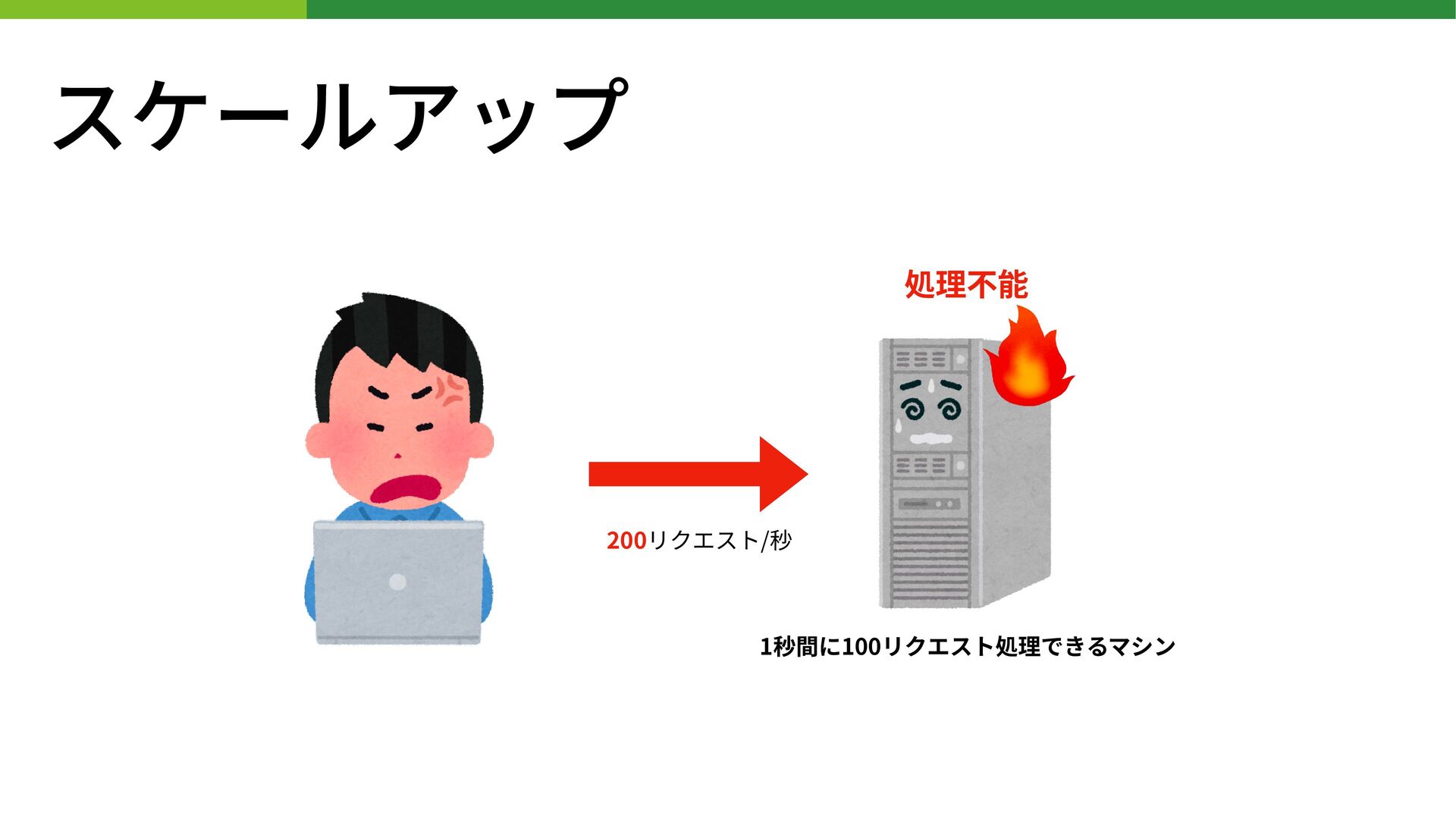
スケールアップ 1秒間に100リクエスト処理できるマシン 200リクエスト/秒 処理不能
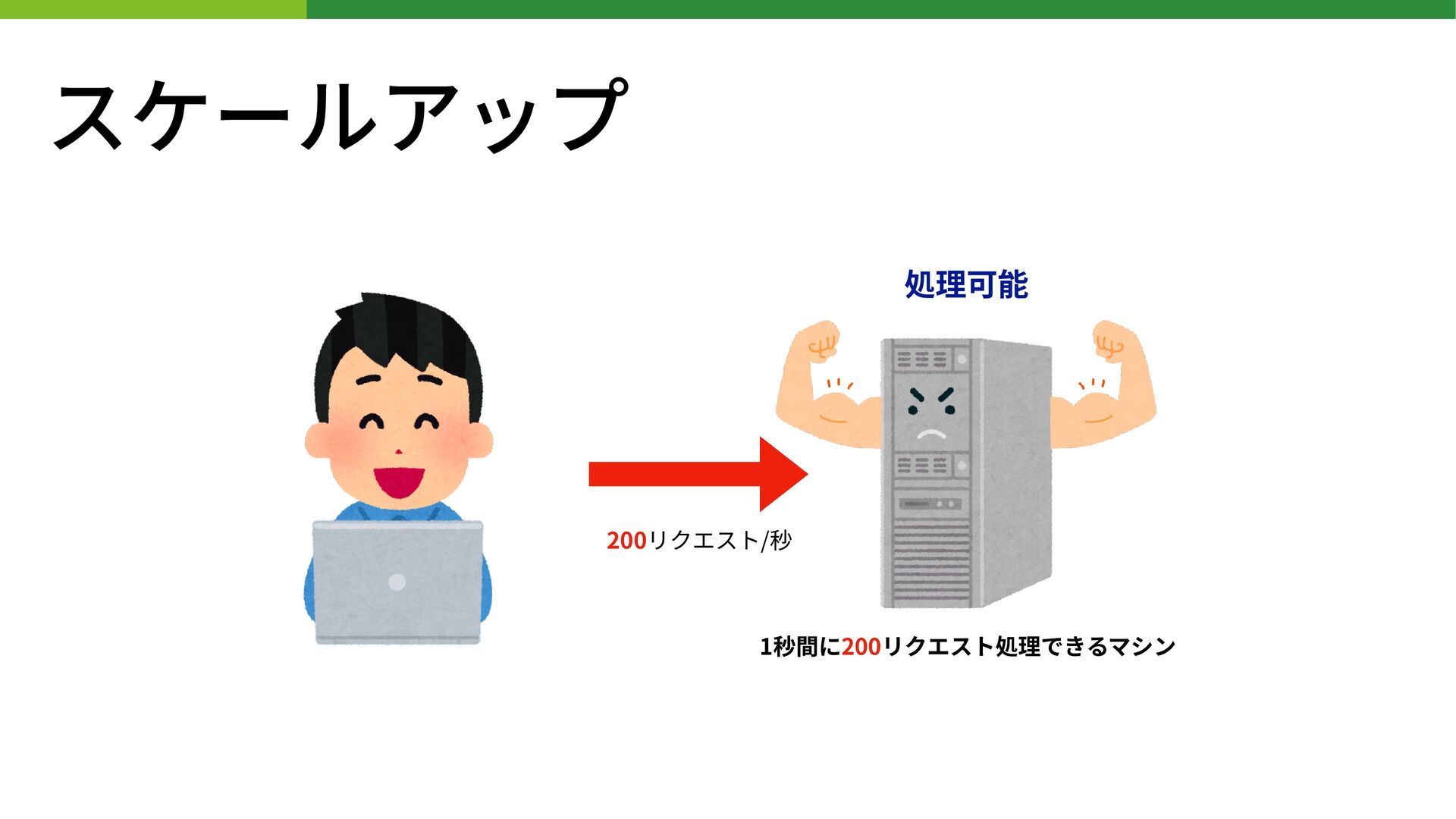
スケールアップ 1秒間に200リクエスト処理できるマシン 200リクエスト/秒 処理可能
スケールアップ • 処理するリソースをより単体性能の⾼いものに置き換える • リソース = サーバ等 • 1秒間に100リクエスト処理できるサーバを200リクエスト処理できるものに交換するなど •
交換するだけで性能向上が⾒込めるので簡単 • スケールアップはわりとすぐに限界が来る • そんなに都合のいいマシンは世の中に存在しないから • CPU 4 コアのマシンを96コアのマシンにすることはできても、1024コアのマシンは⾮現実的 • (あったとしても現代においては⾮常に⾼額でコスパが悪すぎる) • そのサーバが故障したときの影響がデカくなる(リスク集中)
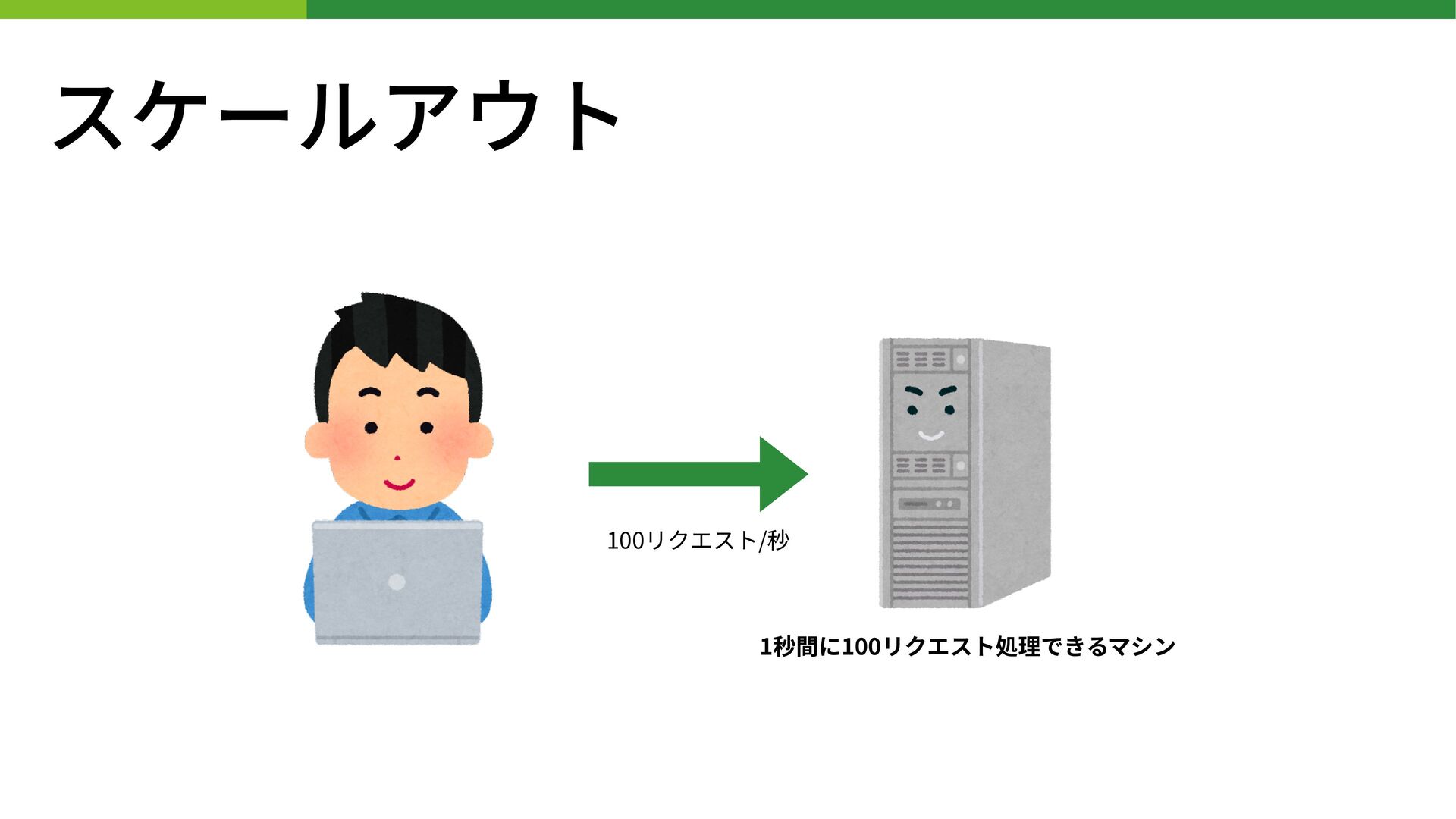
スケールアウト 1秒間に100リクエスト処理できるマシン 100リクエスト/秒
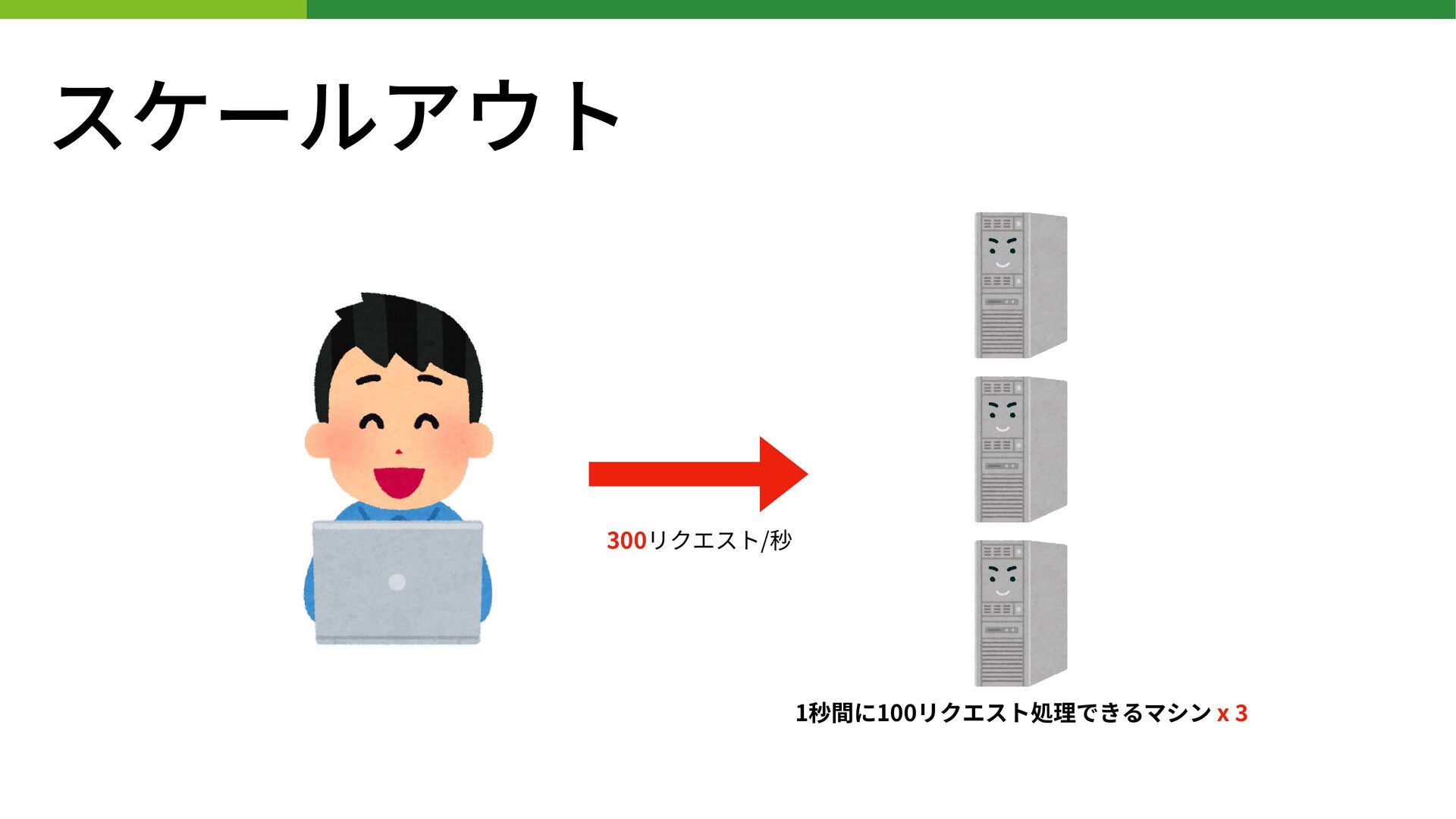
スケールアウト 1秒間に100リクエスト処理できるマシン x 3 300リクエスト/秒
スケールアウト • 処理するリソースの単体性能は変えずに数を増やす • サーバを増やせば性能向上が⾒込めるので、スケールさせやすい • 安価なサーバを⼤量に買って並べるなど • スケールアップと組み合わせるのもOK •
スケールアウトできるものであることが前提 • サーバ1台でしか処理できないソフトウェアの場合、サーバを増やしてもスケールしない
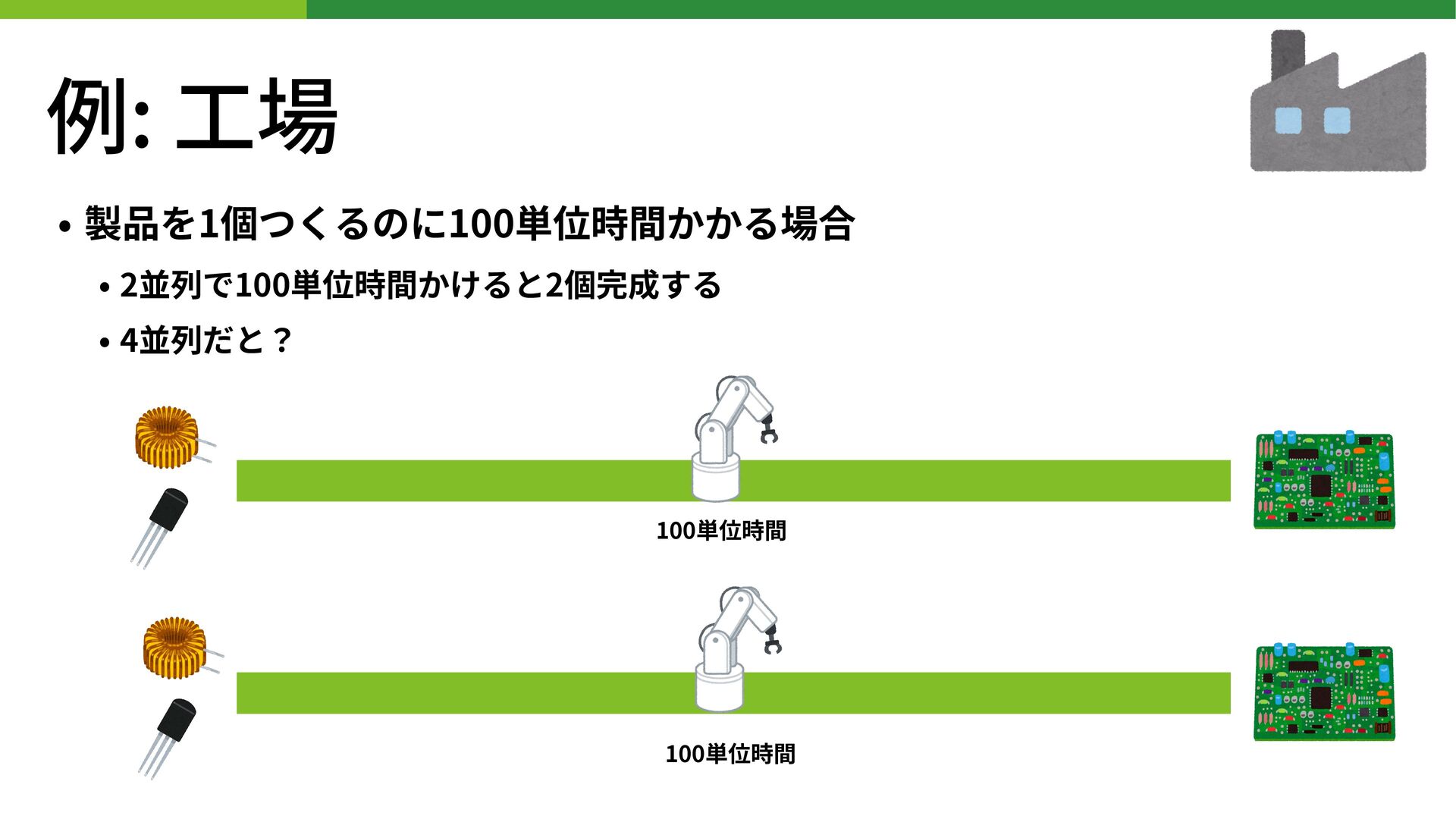
例: ⼯場 • 製品を1個つくるのに100単位時間かかる場合 • 2並列で100単位時間かけると2個完成する • 4並列だと? 100単位時間 100単位時間
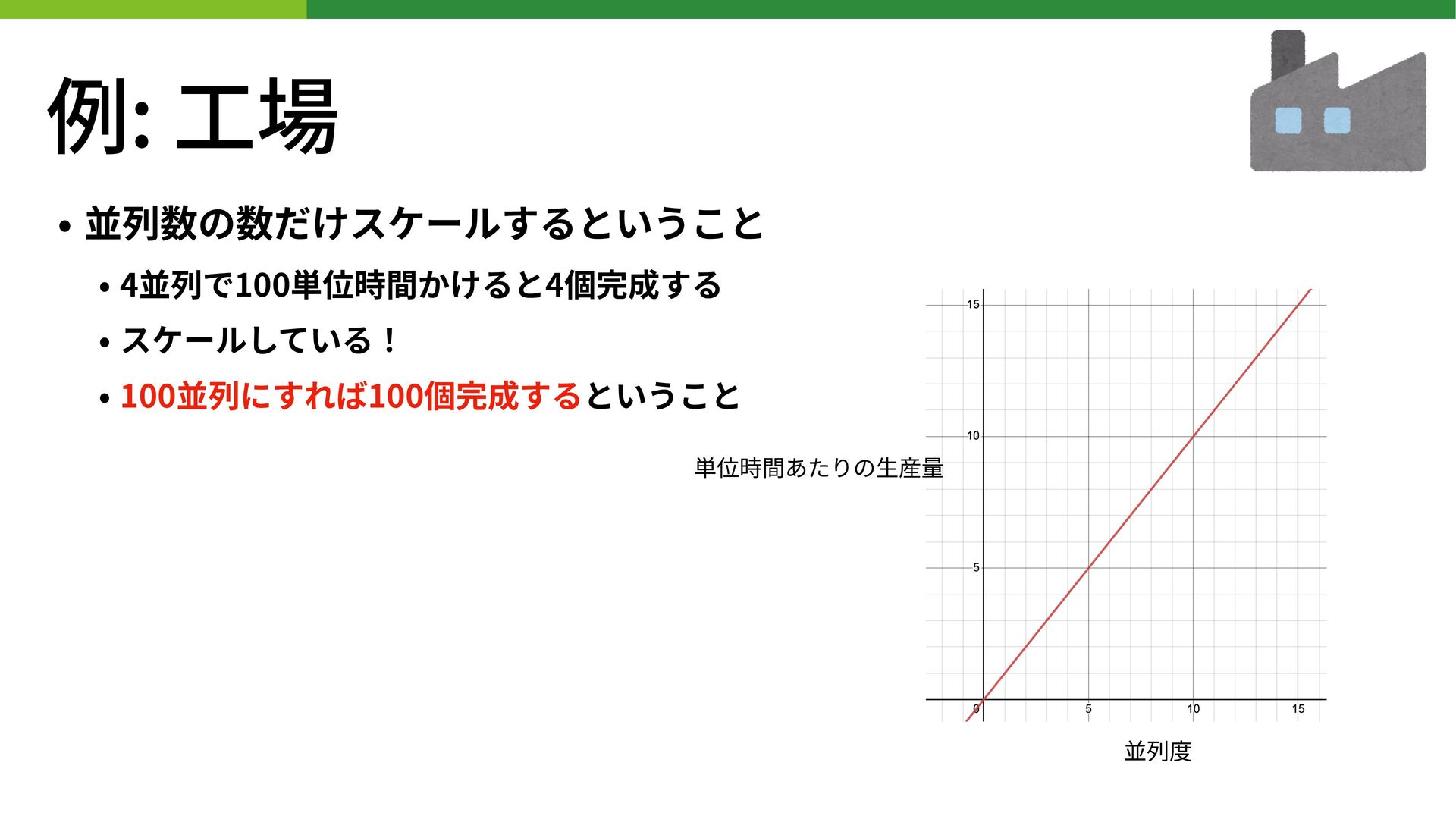
例: ⼯場 • 製品を1個つくるのに100単位時間かかる場合 • 4並列で100単位時間かけると4個完成する • スケールしている! 100単位時間
例: ⼯場 • 並列数の数だけスケールするということ • 4並列で100単位時間かけると4個完成する • スケールしている! • 100並列にすれば100個完成するということ
単位時間あたりの⽣産量 並列度
アムダールの法則
並列度を上げればあげるほど処理能⼒は拡張されるのか? • 理論上はそう • 現実は…? • ⼈間界でもそんなうまい話はないはず https://www.maruzen-publishing.co.jp/item/?book_no= 3
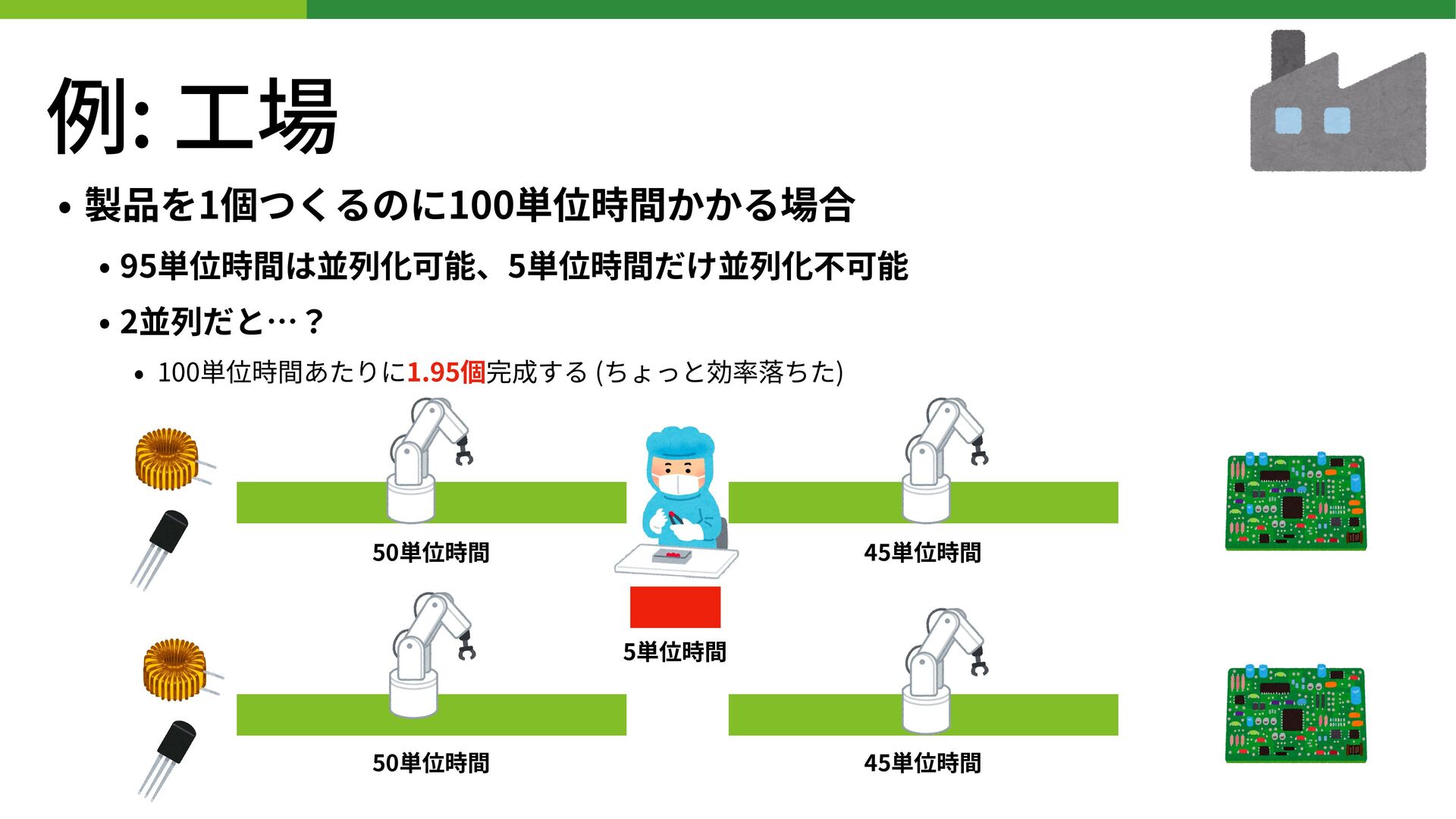
例: ⼯場 • 製品を1個つくるのに100単位時間かかる場合 • 95単位時間は並列化可能、5単位時間だけ並列化不可能 • 2並列だと…? • 100単位時間あたりに1.95個完成する
(ちょっと効率落ちた) 50単位時間 50単位時間 5単位時間 45単位時間 45単位時間
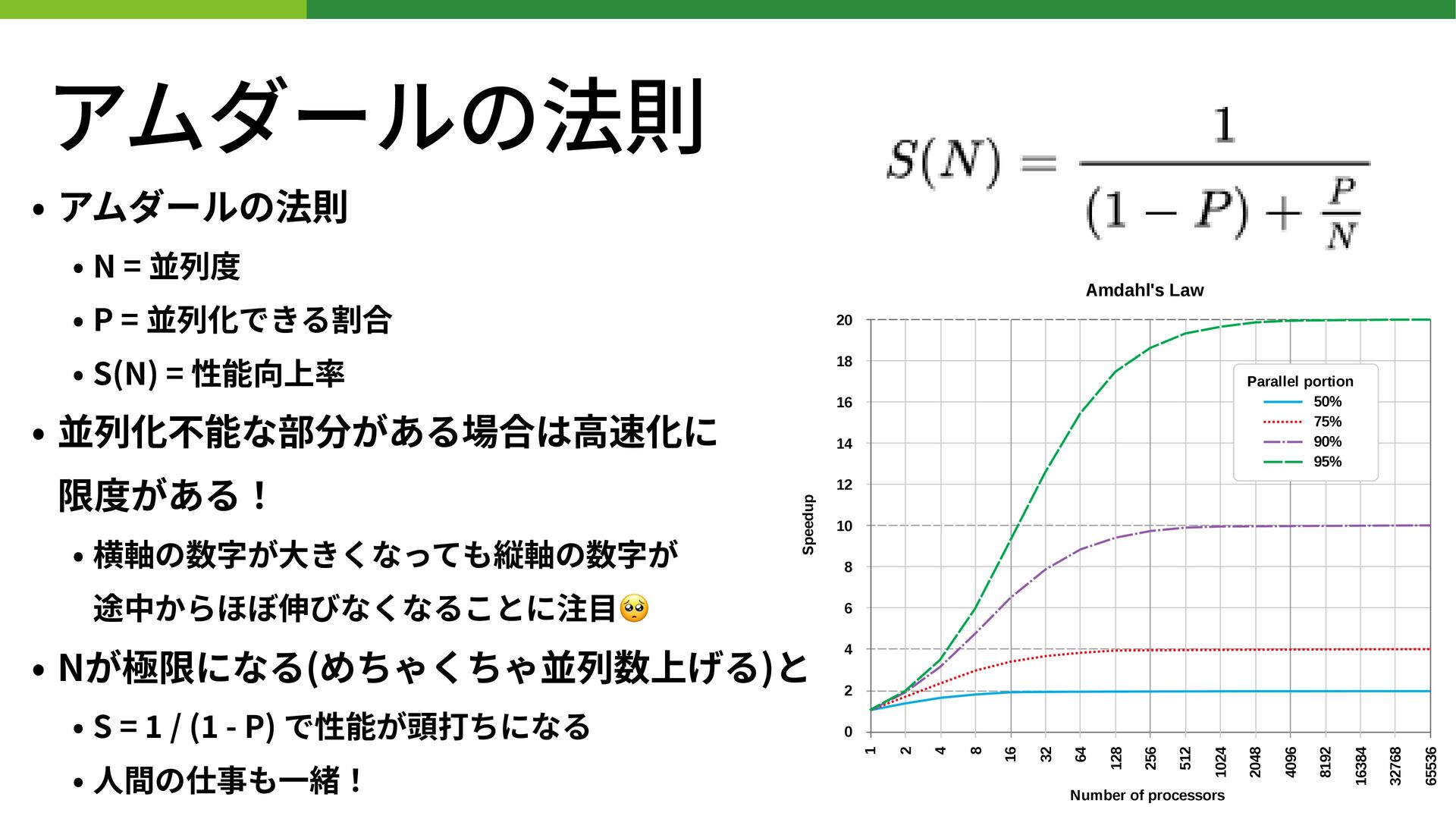
アムダールの法則 • アムダールの法則 • N = 並列度 • P =
並列化できる割合 • S(N) = 性能向上率 • 製品を1個つくるのに100単位時間かかり、95%が並列化可能な場合 • 2並列だと1.95個 • 4並列だと3.47個 • 10並列だと6.89個 • 1,000並列だと19.62個 • 10,000並列だと19.96個 • 100,000並列だと19.99個 (全然効率上がってない…!🥺)
アムダールの法則 • アムダールの法則 • N = 並列度 • P =
並列化できる割合 • S(N) = 性能向上率 • 並列化不能な部分がある場合は⾼速化に 限度がある! • 横軸の数字が⼤きくなっても縦軸の数字が 途中からほぼ伸びなくなることに注⽬🥺 • Nが極限になる(めちゃくちゃ並列数上げる)と • S = 1 / ( 1 - P) で性能が頭打ちになる • ⼈間の仕事も⼀緒!
スケールさせるには • できる限り並列化不可能な部分をなくす • Shared Nothing vs Shared Everything
失敗を許容する
失敗が許容できないシステム • 絶対にリクエストの失敗が許されないシステムを考えてみる • ユーザがN⼈いてそれぞれ1リクエストする場合 • N = 100 :
1 0 0 回に1回の失敗が許されない • N = 1 , 000 : 1 , 00 0 回に1回の失敗が許されない • N = 10 , 000 : 10,000回に1回の失敗が許されない🔥 • 失敗を許容しない場合、ユーザ数が増えるほどシステムの要件が厳しくなる • 無理 • たまに失敗するのは諦めるしかないのか…?🤔
失敗を許容する = 諦める? • 例: 100回に1回エラーが発⽣するサーバ • エラーの発⽣確率 = 1%
• クライアントが1回リトライしてもエラーになる確率 = 1% x 1 % = 0 . 01 % • クライアントが2回リトライしてもエラーになる確率 = 1% x 1 % x 1 % = 0 . 0 001 % • エラーが確率的に発⽣する場合、リトライすれば成功しそう! • 必ずしも 失敗を許容する = 諦める ということではない • もちろんエラー率99%とかだとリトライしてもあまり意味がない 失敗 リトライ 成功
リトライ / 冪等性
何も考えずにリトライすると… • とあるクライアント • サーバがエラーレスポンスを返したのですぐにリトライしました • またエラーだったのでリトライを10回繰り返しました • サーバが障害によりレスポンス不能だった場合に、
クライアントが100台居た場合に何が起きるか • 10回リトライ x 1 00 台 = 1000リクエスト • サーバが障害になるとトラフィックが1,000倍になる🔥 • 回復不能!負のループ!
バックオフ • 何も考えずに即時リトライすることの危険性を回避する⼿法 • ⼀定期間待ってからリトライする • バックオフ • 「⼀定期間」を指数関数的に伸ばしていくことが⼀般的(Exponential Backo
ff ) • サーバ障害発⽣時のクライアントの例: • 失敗→2秒後にリトライ→4秒後→8秒後、16秒後、32秒後、64秒後、128秒後… • 即座にリトライしてもダメだった場合、リトライの量が爆発しないように 待機時間を伸ばしていくことでサーバを守る
ジッター • 同じタイミングにクライアントからのアクセスが集中すると困る • リトライ時に間隔をあけても多数のクライアントのアクセス周期が集中すると 困る • リトライにゆらぎ(ジッター, Jitter)を与える •
例: リクエスト失敗→2秒+0〜3秒後にリトライ→4秒+0〜3秒後、8秒+0〜3秒後… • 徐々に周期がズレていくはず • リトライ以外でもジッターは有効 • Push通知の送信タイミングにジッターを加えることでアクセスのスパイクを緩和するなど
何も考えずにリトライすると…(その2) • 決済が2回実⾏された! • 商品が10個発送された! • ⾝に覚えのない履歴が追加された! • 何かしら事故りそうな予感👼
事故って困るケースってなんだろう • 決済履歴の取得に失敗したのでリトライしたら成功した => 困らない • 決済中に通信エラーになったのでリトライしたら2重に決済された => 困る! •
違いは「冪等性(べきとうせい)」があるかどうか • 何回やっても同じ結果になるかどうか
冪等でない処理を冪等にする技術 • 冪等にするための⼿法の⼀例 • 決済: • 🙅 危険な例: 100円の決済が成功したかわからないのでリトライした •
🙆 安全な例: 100円の決済(ID=abc)が成功したかわからないのでリトライした • 決済にIDが付与されていると、同じリクエストが来たかどうか判別可能 • サーバは同じリクエストが2回来たことを検知したら「すでに受け付けました」というレ スポンスを返却して処理をスキップすればいい • クライアントは成功した確証が得られなければリトライすればいい
その他のスケールさせるためのしくみ
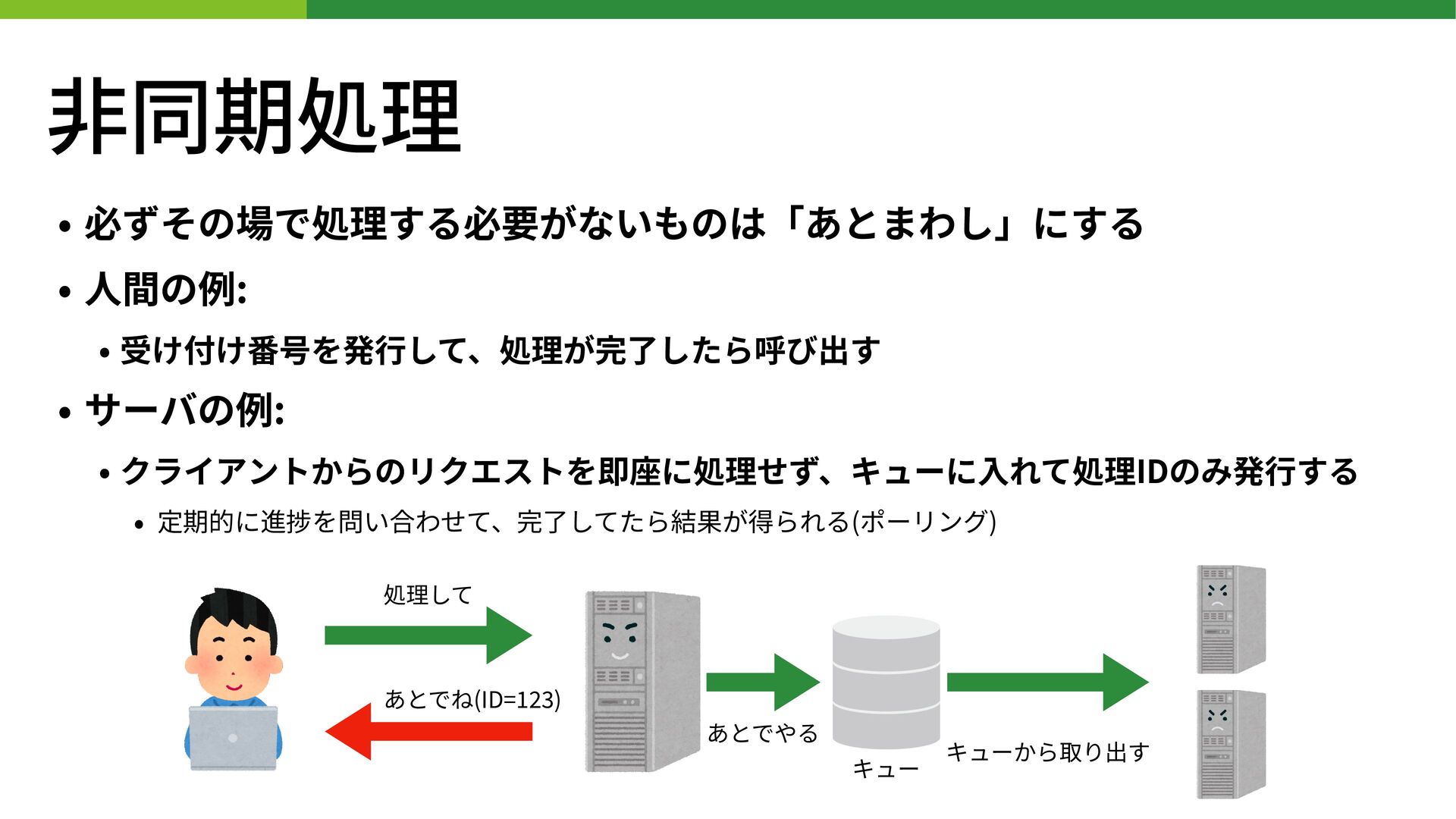
⾮同期処理 • 必ずその場で処理する必要がないものは「あとまわし」にする • ⼈間の例: • 受け付け番号を発⾏して、処理が完了したら呼び出す • サーバの例: •
クライアントからのリクエストを即座に処理せず、キューに⼊れて処理IDのみ発⾏する • 定期的に進捗を問い合わせて、完了してたら結果が得られる(ポーリング) 処理して あとでね(ID= 1 23 ) あとでやる キュー キューから取り出す
結果整合性 • 結果整合性(Eventual Consistency)という概念もある • システムを分散(スケールアウト)させつつ整合性を取ることができる技術 • 今回は扱いません、⼤規模にスケールするシステムではこの概念が出てくることが多い • 例:
Con fl ict-free Replicated Data Type https://speakerdeck.com/kurochan/scala-with-cats-case-study-crdts
まとめ • システムがスケールするというのはどういうことなのか • スケールアップとスケールアウトの違い • アムダールの法則により単に並列度を⾼めても限界があること • 絶対に失敗しないことよりも最終的に失敗しないことをとる⽅が合理的である
(ことが多い) • 処理が冪等であればリトライが容易であること
None
{kind=link}
{kind=link}
![[PR] イラスト図解でよくわかる ITインフラの基礎知識 • 興味持ったらぜひ🤔 • 書いたの5年前だけどそんなに変わってないはず https://gihyo.jp/book/ 8](https://files.speakerdeck.com/presentations/dc83d12529eb40f8a0dc75abe22fde1f/slide_2_1742168620.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}