resources comparing to the more usual ones in terms of performance and readability. After learning a bit of SQL I could write queries complex enough that I didn’t know how to implement using Django. Could I put the two of them together?
✔ Index tables ✔ Paginate requests ✔ Use select_related and prefetch_related on querysets ✔ Use values, values_list, only and defer on querysets ✔ Setup database cache ✔ Use assertNumQueries method on tests
data while importing it - My machine cannot handle loading too much data to memory at once - Importing the data took forever - Putting the technical knowledge together with the domain was much harder then I had thought
law stating that all public data that’s not secret must be publicly available to anyone that has interest in it: the Information Access Bill (Lei de Acesso à Informação).
there, the access is not guaranteed for non technical people who would benefit from the information they provide. - Not every government agency complies with the law or take a long time to make the data available - The data is spread among multiple sources - Many datasets are in non open formats - Most of the people who have interest on the data don’t have the technical skills to process it
(@turicas) to gather public data, clean it and make it available for those who want to research it. - Datasets: https://brasil.io/datasets - GitHub: https://github.com/turicas/brasil.io - Support the project: https://apoia.se/brasilio
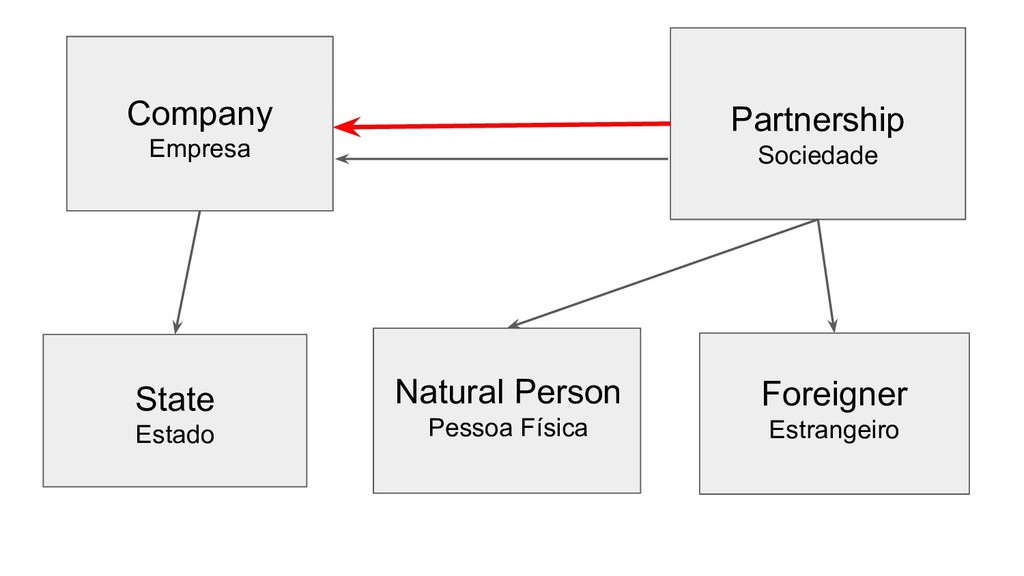
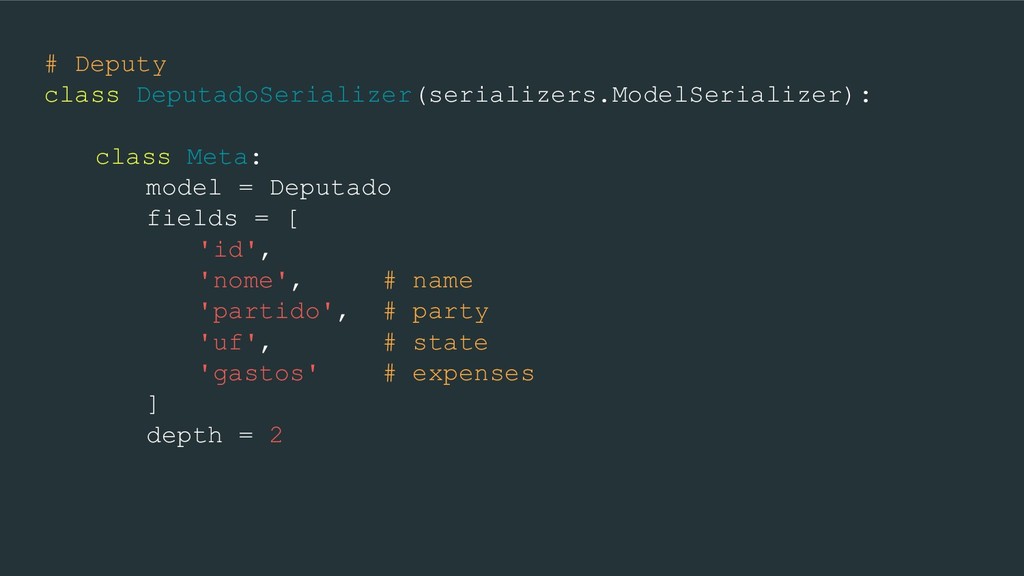
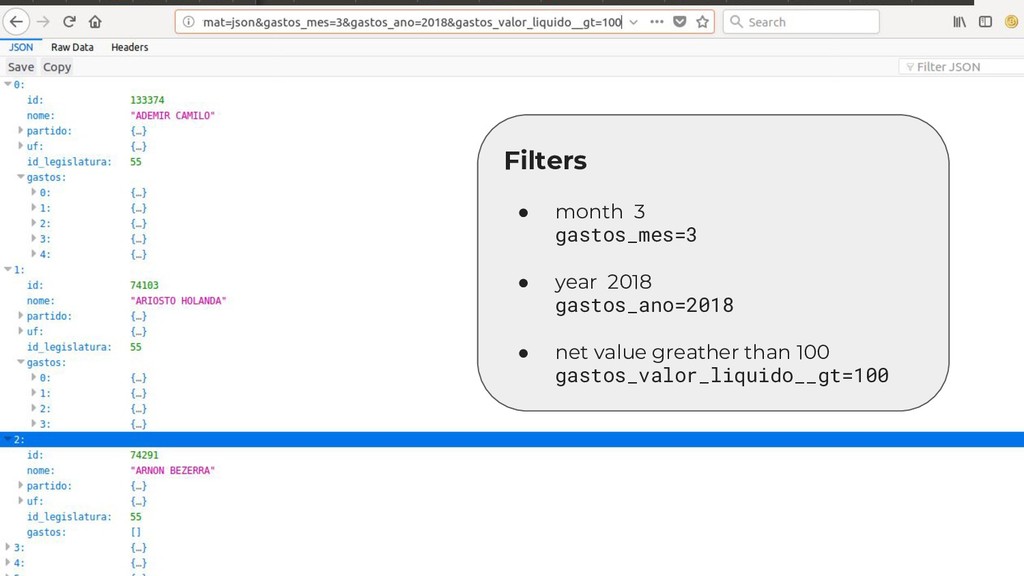
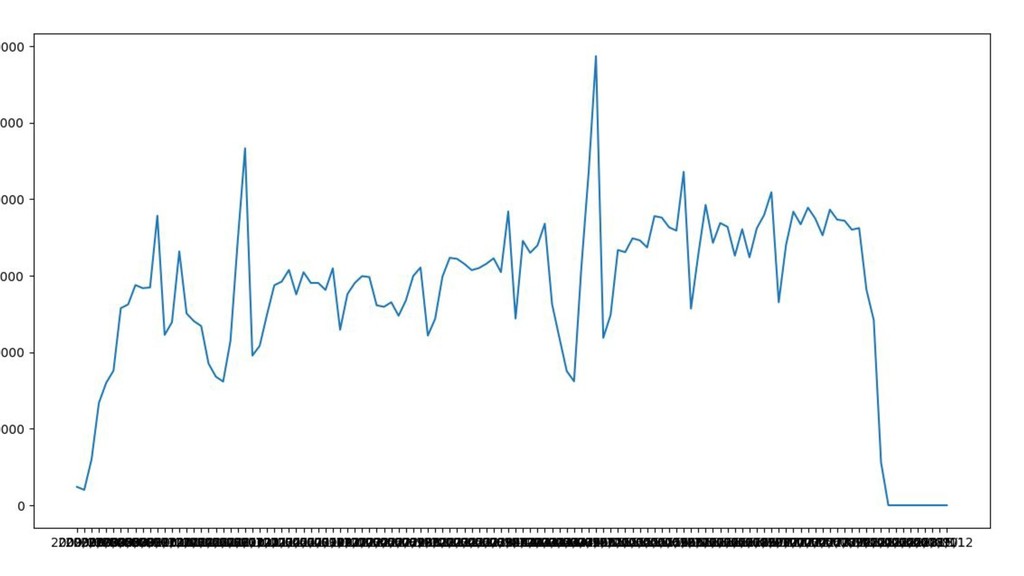
money on products and services related to the parliamentary activity and receive a refund for that. - Deputy’s unique identifier - Deputy’s party - Deputy’s name - Date of the expense - Reference month - Reference year - Amount spent - Description - Company CNPJ (if it’s company) - Some other fields...
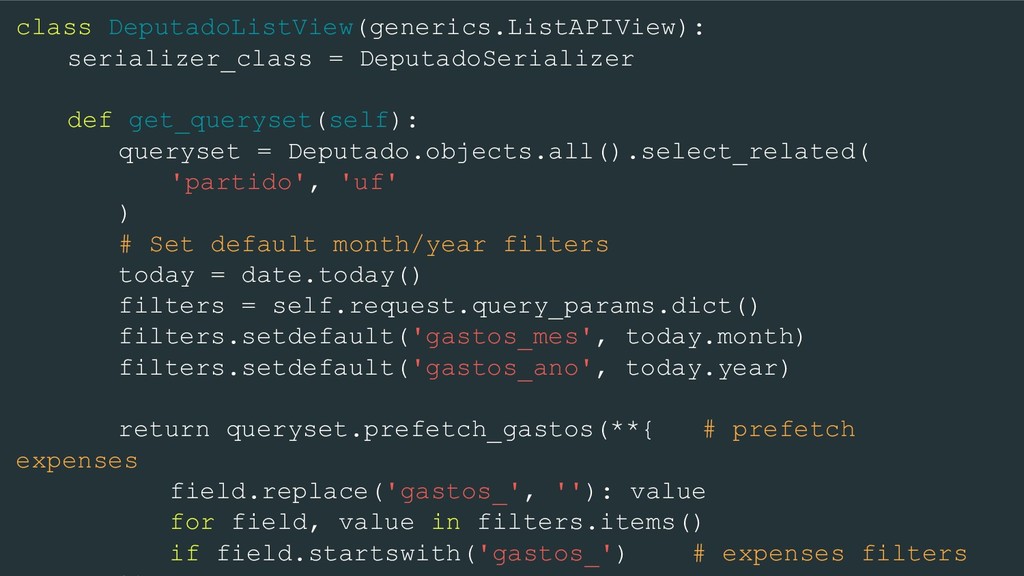
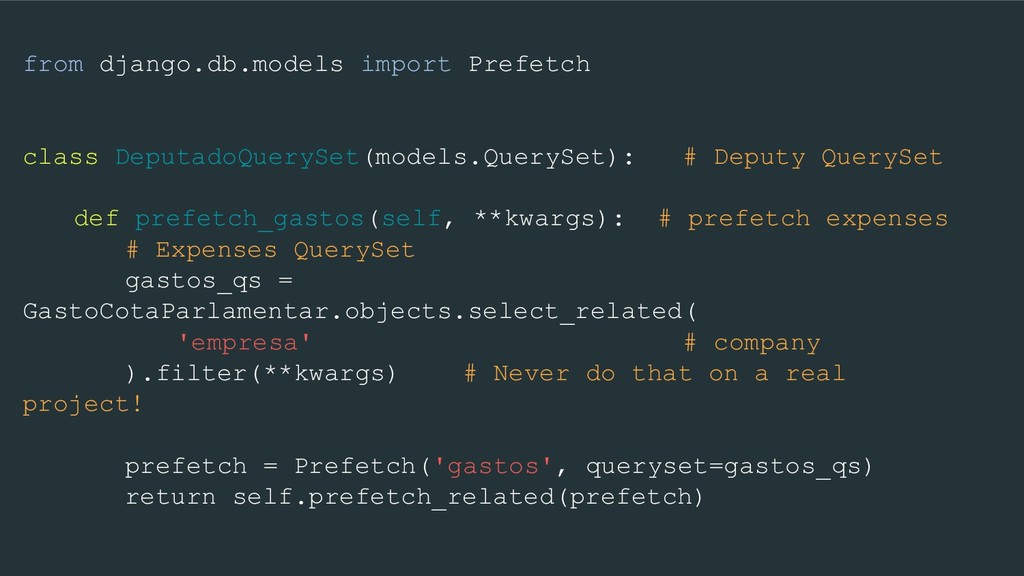
prefetch_gastos(self, **kwargs): # prefetch expenses # Expenses QuerySet gastos_qs = GastoCotaParlamentar.objects.select_related( 'empresa' # company ).filter(**kwargs) # Never do that on a real project! prefetch = Prefetch('gastos', queryset=gastos_qs) return self.prefetch_related(prefetch)
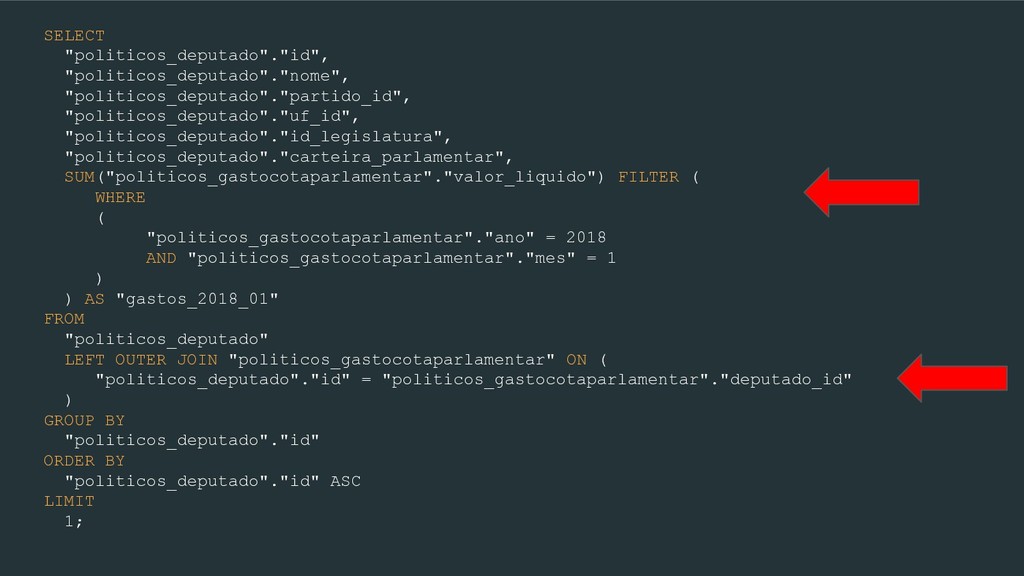
WHERE ( "politicos_gastocotaparlamentar"."ano" = 2018 AND "politicos_gastocotaparlamentar"."mes" = 1 ) ) AS "gastos_2018_01" FROM "politicos_deputado" LEFT OUTER JOIN "politicos_gastocotaparlamentar" ON ( "politicos_deputado"."id" = "politicos_gastocotaparlamentar"."deputado_id" ) GROUP BY "politicos_deputado"."id" ORDER BY "politicos_deputado"."id" ASC LIMIT 1;
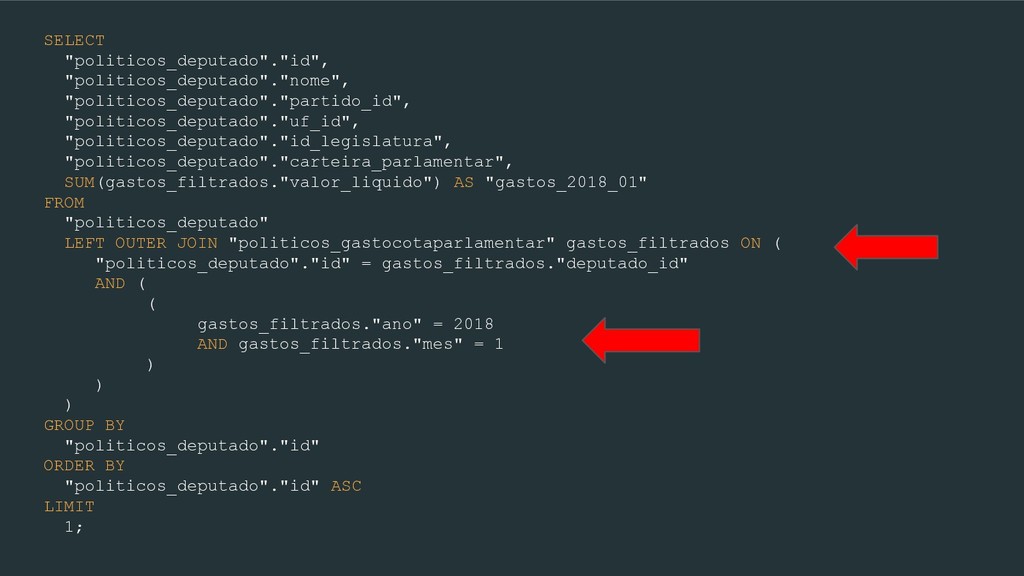
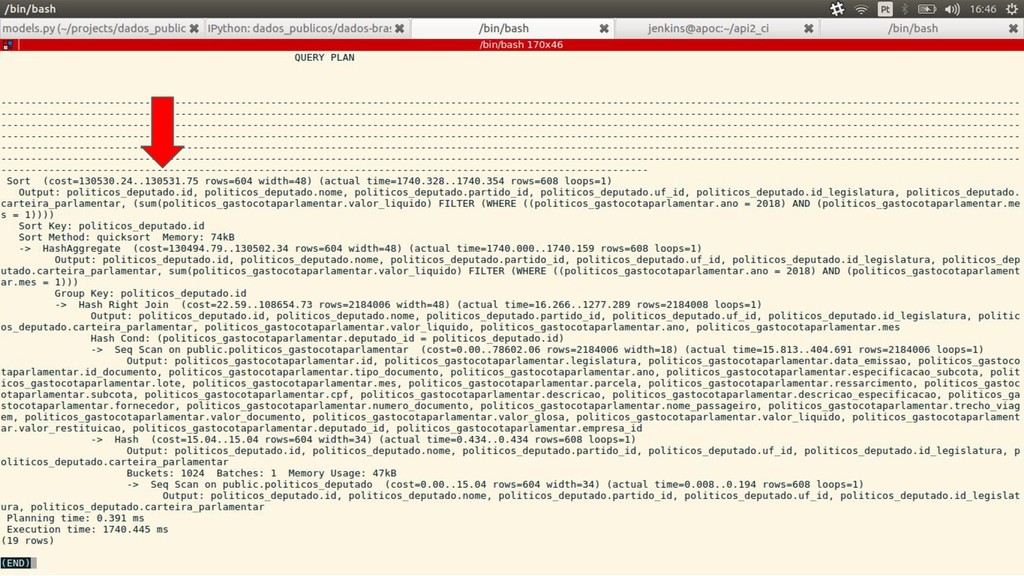
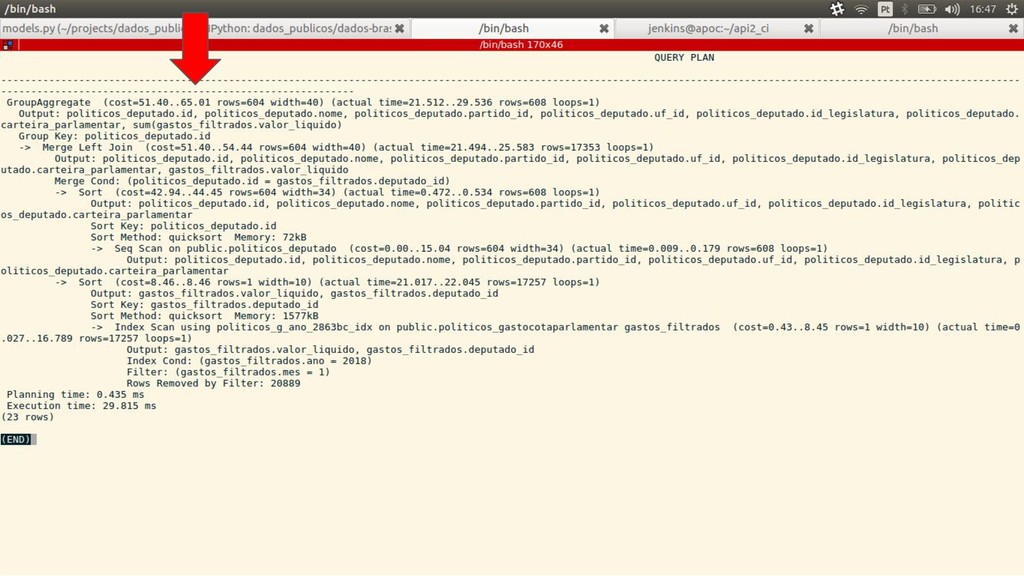
FROM "politicos_deputado" LEFT OUTER JOIN "politicos_gastocotaparlamentar" gastos_filtrados ON ( "politicos_deputado"."id" = gastos_filtrados."deputado_id" AND ( ( gastos_filtrados."ano" = 2018 AND gastos_filtrados."mes" = 1 ) ) ) GROUP BY "politicos_deputado"."id" ORDER BY "politicos_deputado"."id" ASC LIMIT 1;
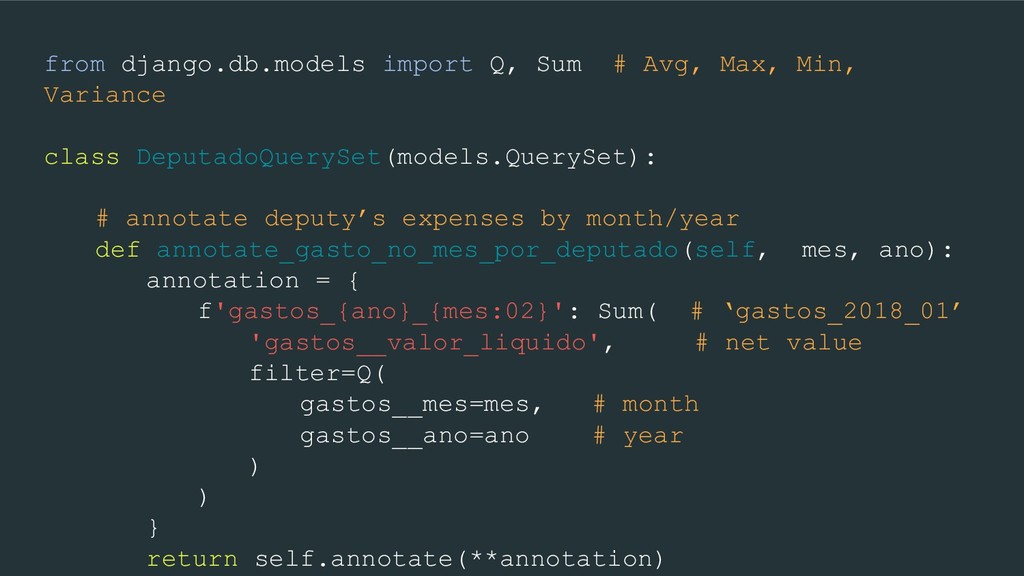
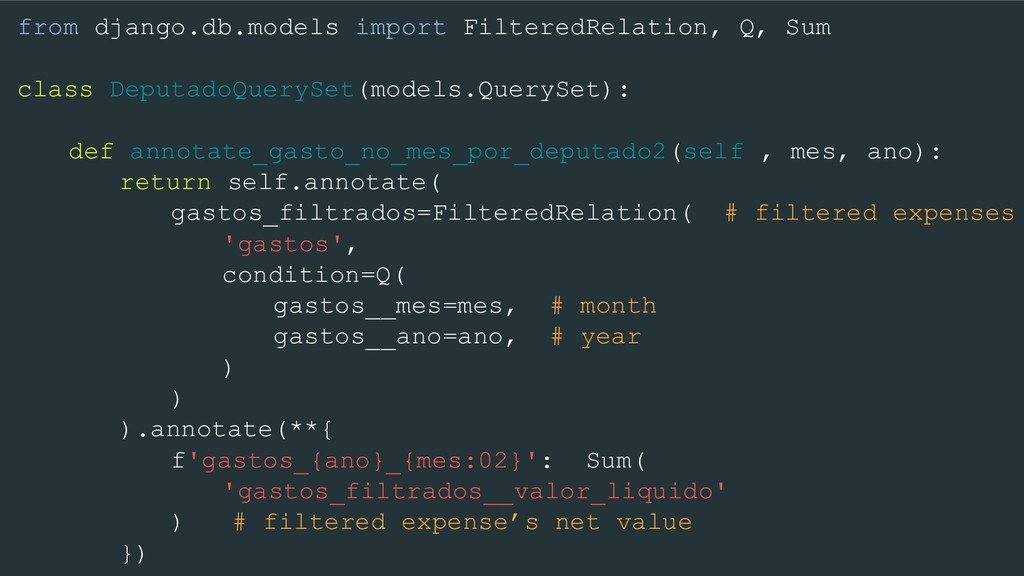
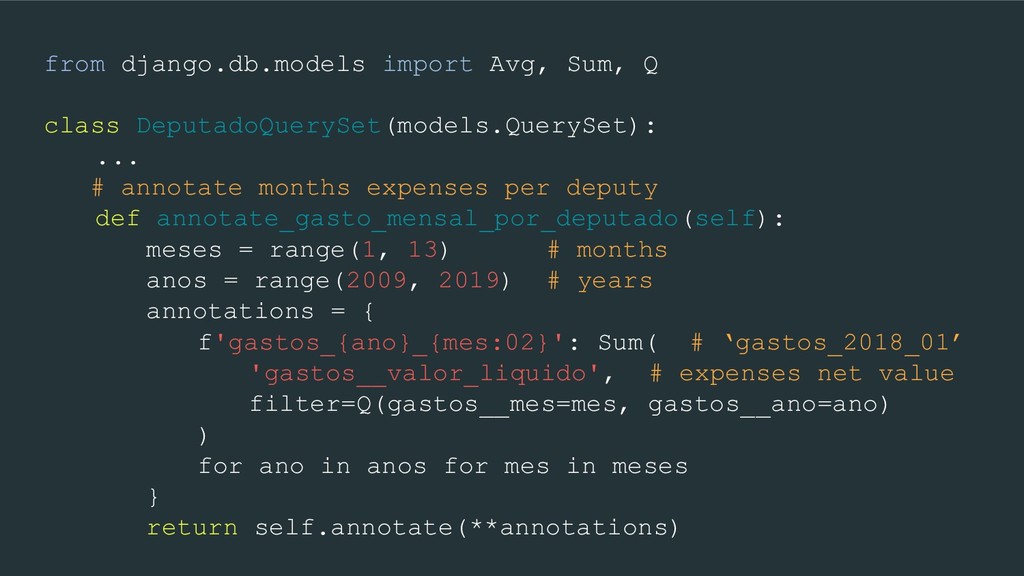
annotate months expenses per deputy def annotate_gasto_mensal_por_deputado(self): meses = range(1, 13) # months anos = range(2009, 2019) # years annotations = { f'gastos_{ano}_{mes:02}': Sum( # ‘gastos_2018_01’ 'gastos__valor_liquido', # expenses net value filter=Q(gastos__mes=mes, gastos__ano=ano) ) for ano in anos for mes in meses } return self.annotate(**annotations)
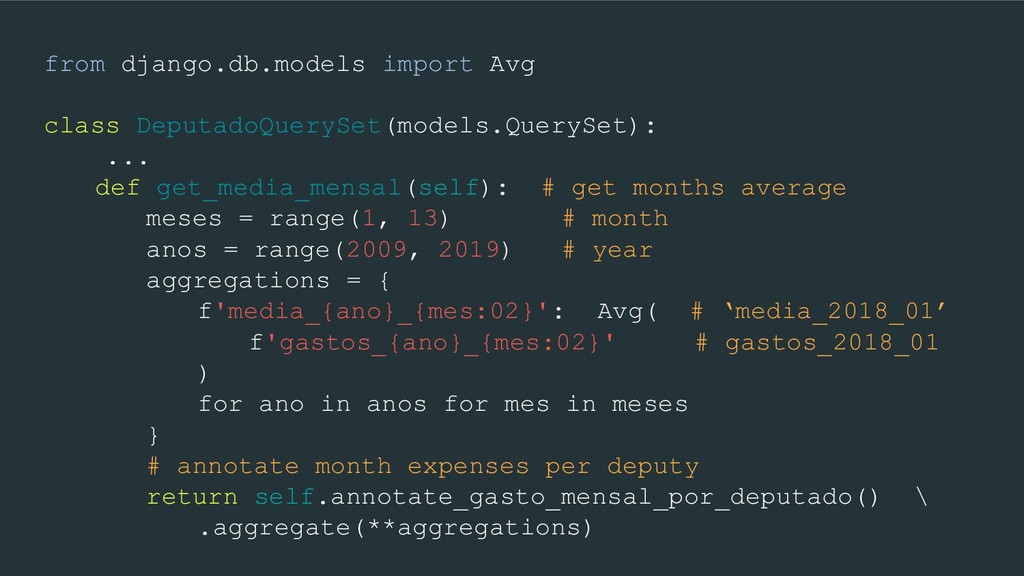
get months average meses = range(1, 13) # month anos = range(2009, 2019) # year aggregations = { f'media_{ano}_{mes:02}': Avg( # ‘media_2018_01’ f'gastos_{ano}_{mes:02}' # gastos_2018_01 ) for ano in anos for mes in meses } # annotate month expenses per deputy return self.annotate_gasto_mensal_por_deputado() \ .aggregate(**aggregations)
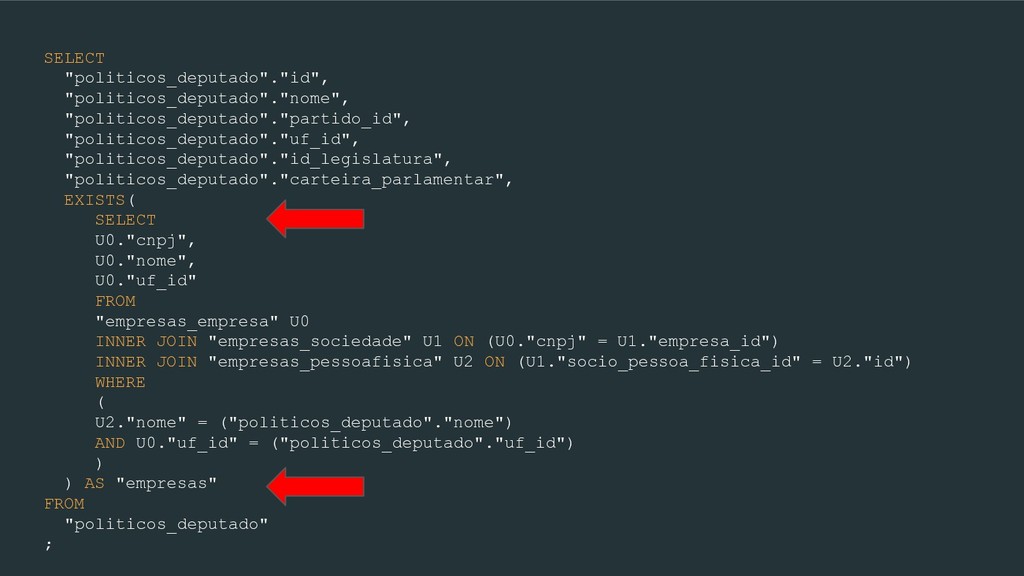
U0."nome", U0."uf_id" FROM "empresas_empresa" U0 INNER JOIN "empresas_sociedade" U1 ON (U0."cnpj" = U1."empresa_id") INNER JOIN "empresas_pessoafisica" U2 ON (U1."socio_pessoa_fisica_id" = U2."id") WHERE ( U2."nome" = ("politicos_deputado"."nome") AND U0."uf_id" = ("politicos_deputado"."uf_id") ) ) AS "empresas" FROM "politicos_deputado" ;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}