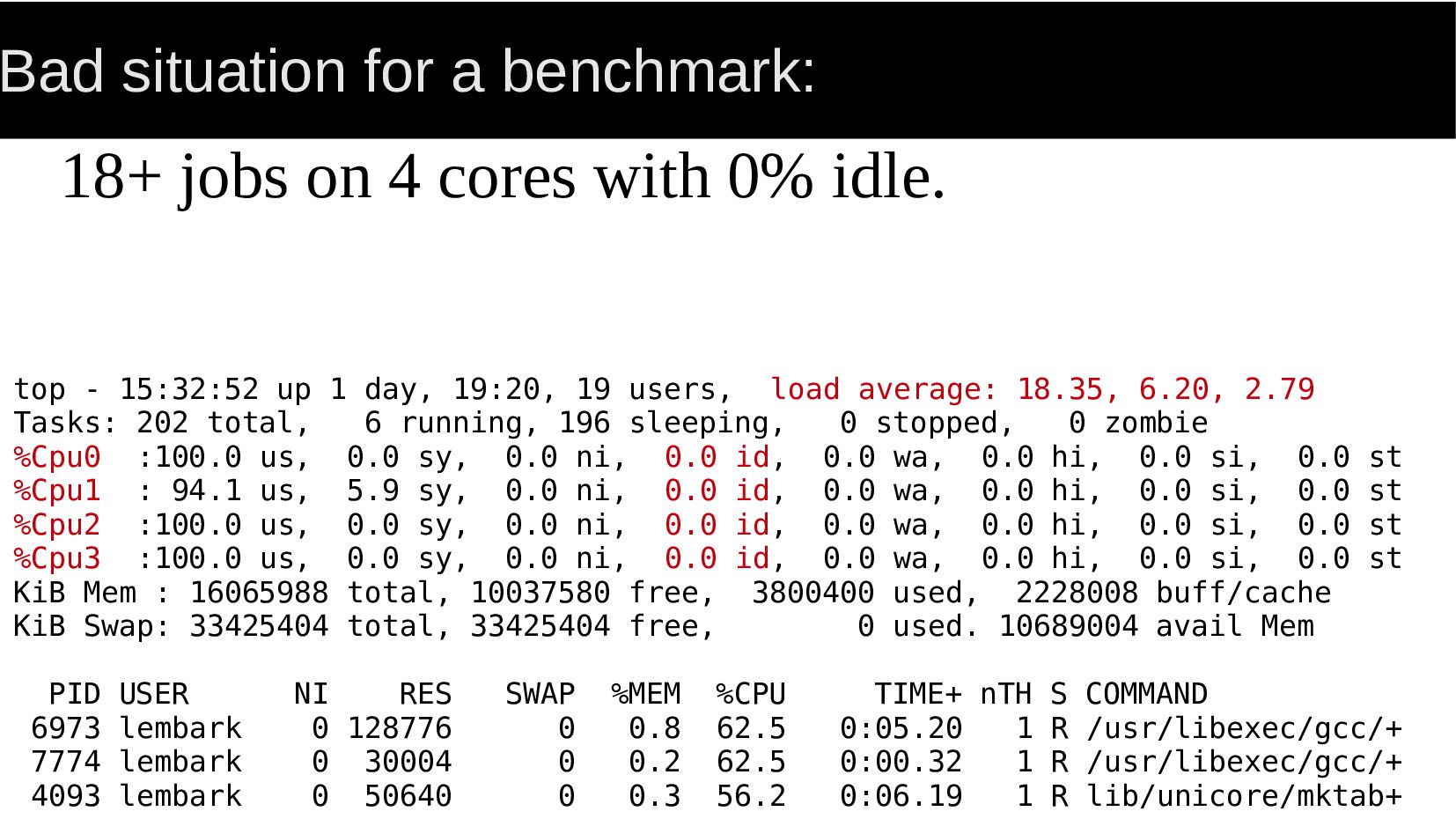
with 0% idle. top - 15:32:52 up 1 day, 19:20, 19 users, load average: 18.35, 6.20, 2.79 Tasks: 202 total, 6 running, 196 sleeping, 0 stopped, 0 zombie %Cpu0 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu1 : 94.1 us, 5.9 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu2 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st %Cpu3 :100.0 us, 0.0 sy, 0.0 ni, 0.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 16065988 total, 10037580 free, 3800400 used, 2228008 buff/cache KiB Swap: 33425404 total, 33425404 free, 0 used. 10689004 avail Mem PID USER NI RES SWAP %MEM %CPU TIME+ nTH S COMMAND 6973 lembark 0 128776 0 0.8 62.5 0:05.20 1 R /usr/libexec/gcc/+ 7774 lembark 0 30004 0 0.2 62.5 0:00.32 1 R /usr/libexec/gcc/+ 4093 lembark 0 50640 0 0.3 56.2 0:06.19 1 R lib/unicore/mktab+
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}