User identification is a fundamental, but yet an open problem in fraud detection.
Traditional approaches resort to user account information or browsing history.
However, such information can pose security and privacy risks, and it is not robust as can
be easily changed, e.g., the user changes to a new device or using a different application.
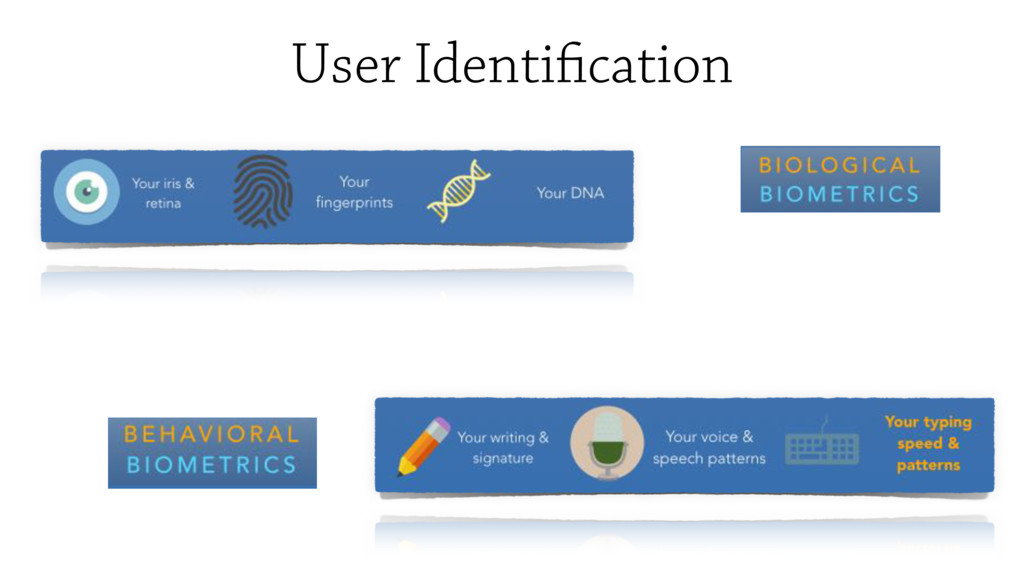
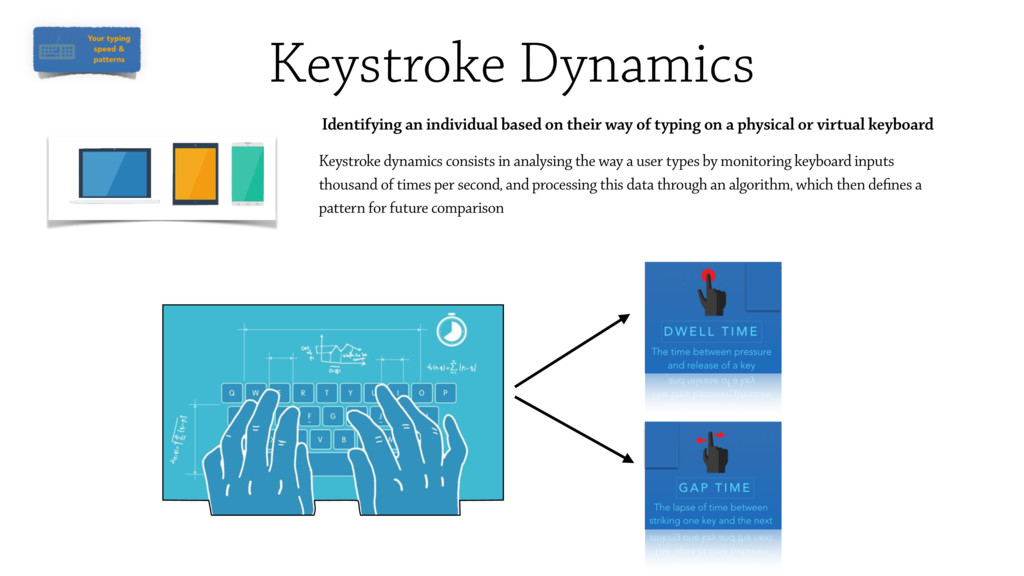
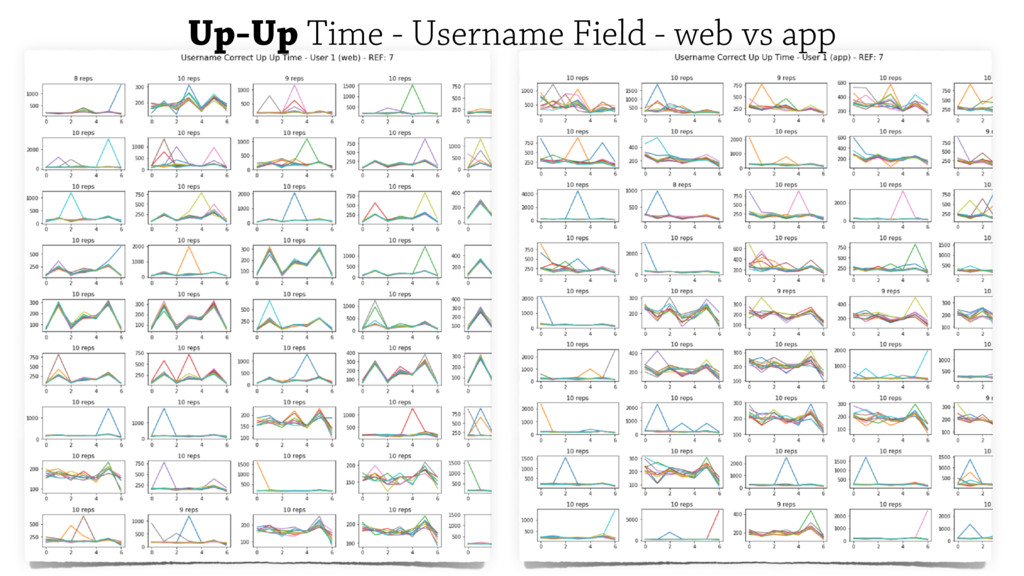
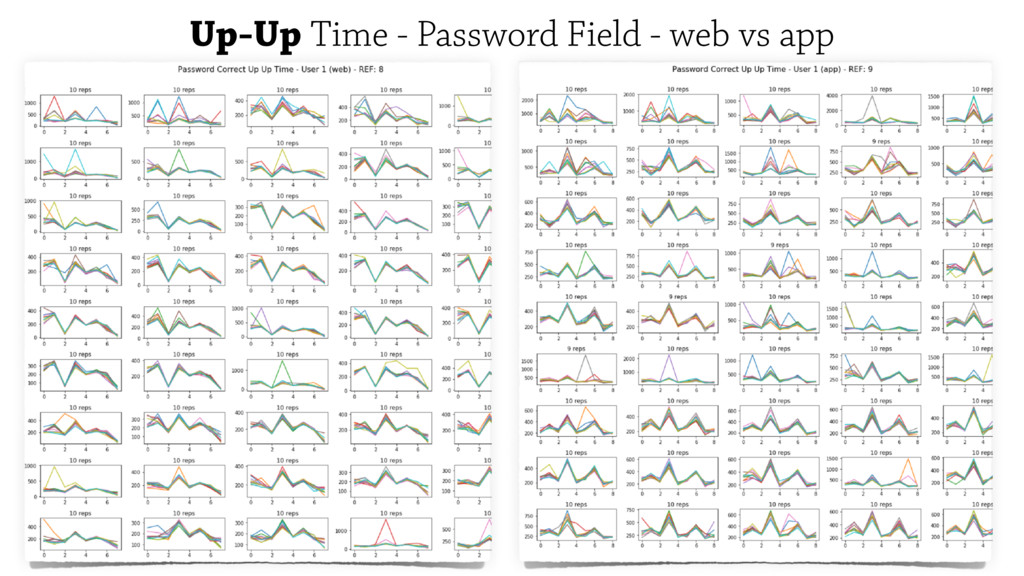
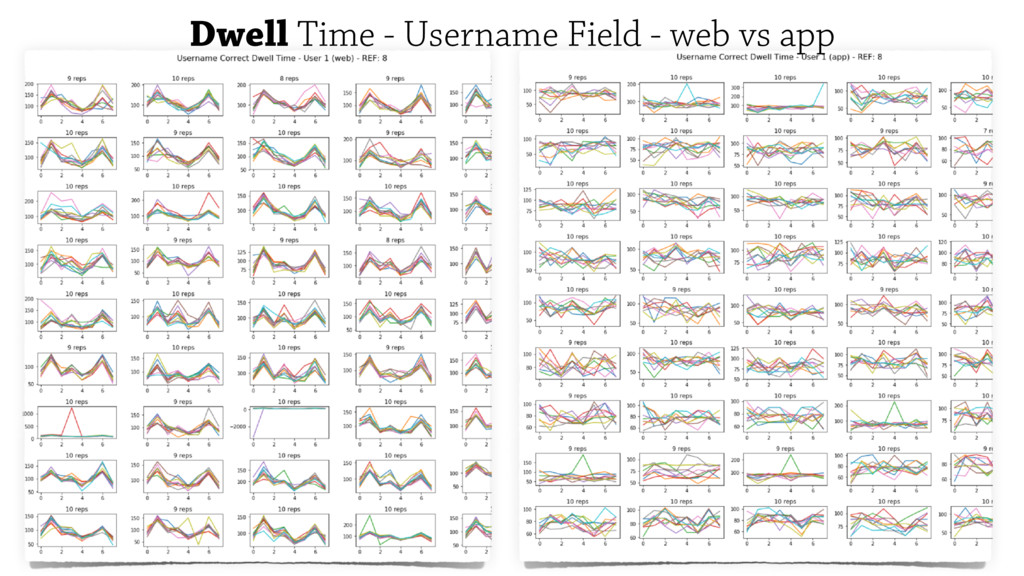
Monitoring biometric information including a user’s typing behaviours tends to produce
consistent results over time while being less disruptive to user’s experience.
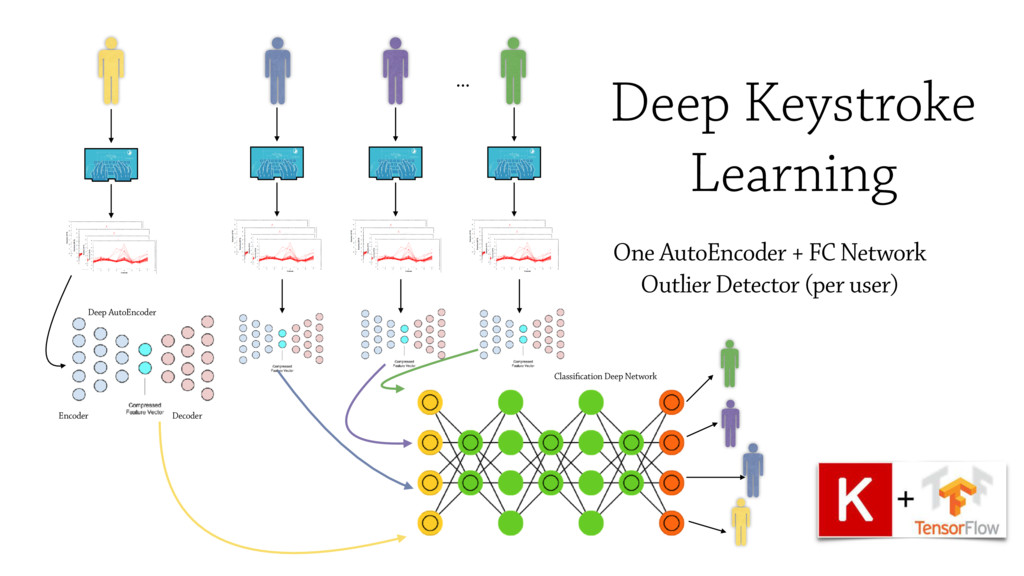
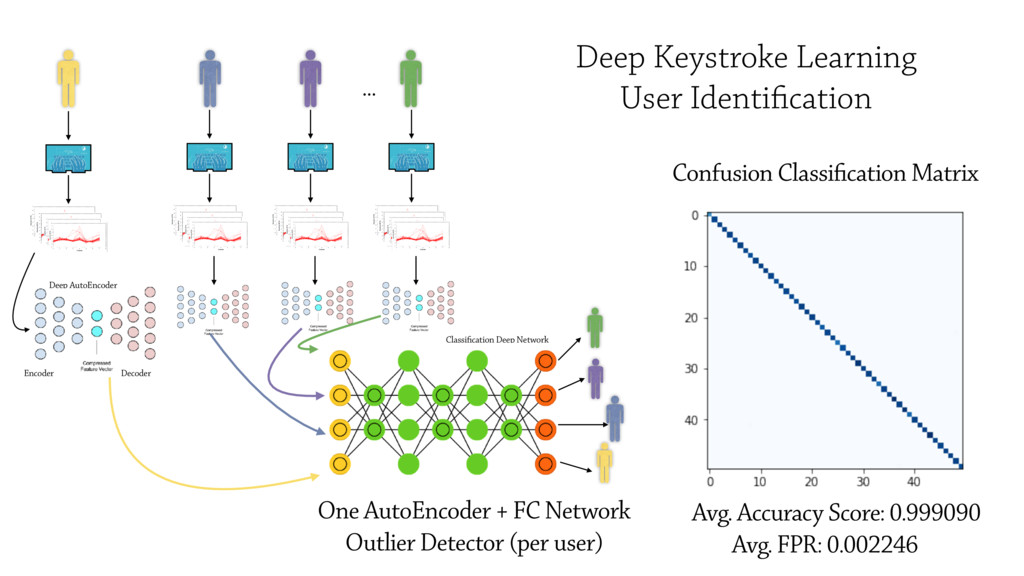
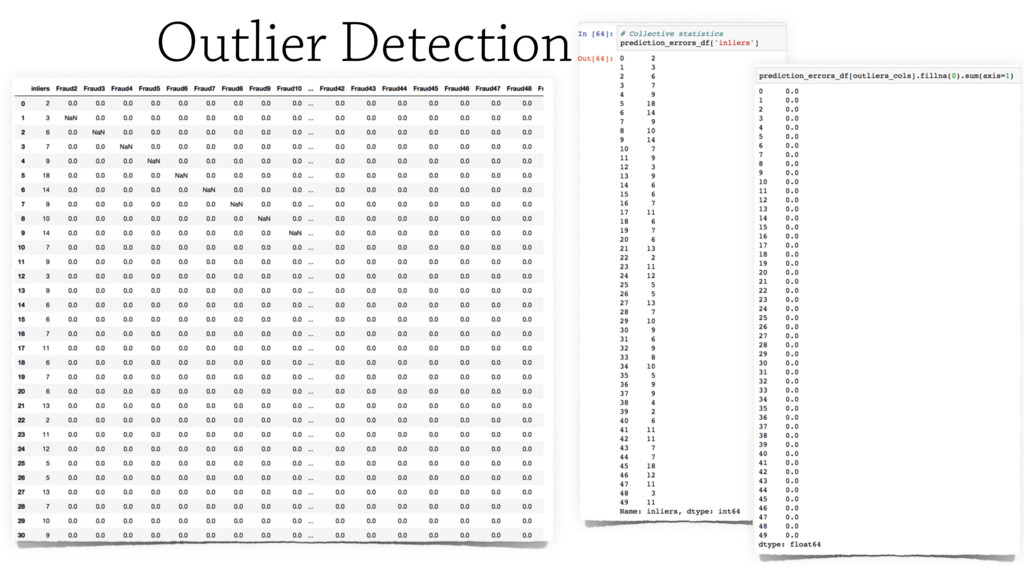
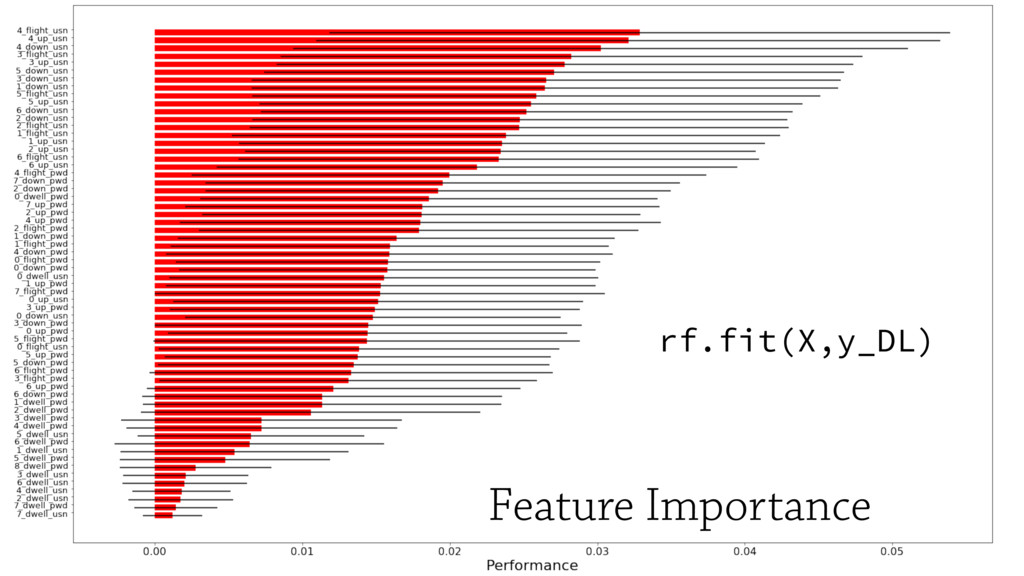
In this talk I will present the Machine Learning pipeline I set up to prevent frauds in user
authentications. Challenges for processing and filtering real user data
accessing bank accounts from web and mobile devices will be discussed, along
with the deep neural networks adopted to learn to detect impostors.
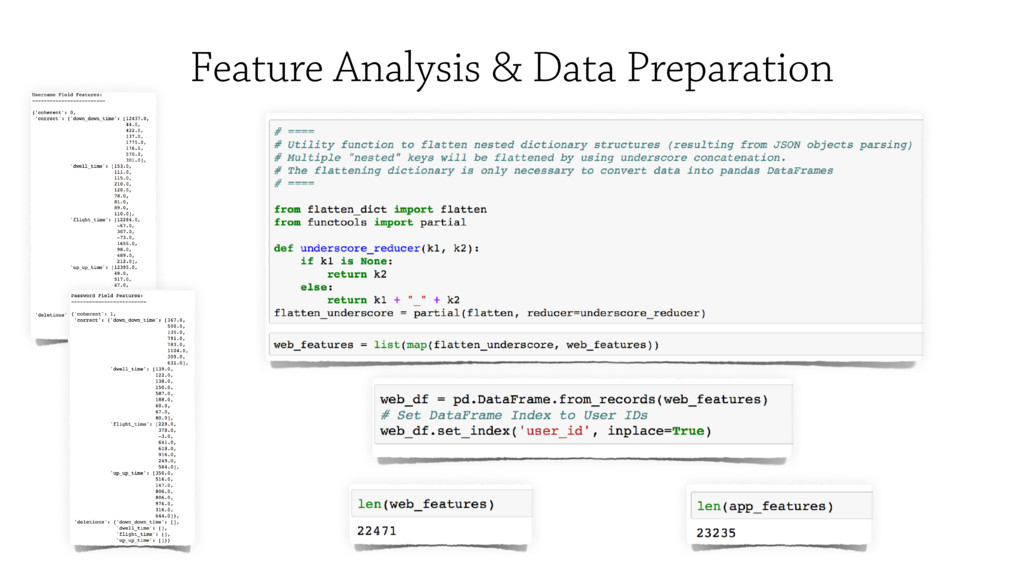
During the talk, I will present the Pythonic tools (e.g. `pandas`) and data formats
(i.e. `hdf5` and `json`) I used to collect and store data, as well as those to
configure the machine learning process (i.e. `scipy.cluster`, `sklearn` and `keras`).
The talk is meant for data scientists, as well as for practitioners with no specific background in
machine or deep learning. Basic knowledge of `pandas` and other `numpy` based
scientific libraries is assumed.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks a lot for your kind attention +ValerioMaggio [email protected] it.linkedin.com/in/valeriomaggio](https://files.speakerdeck.com/presentations/e3bbbcd6af4f492a89c96d9e6806e60f/slide_28.jpg){kind=link}