Talk @ **PyConDE**
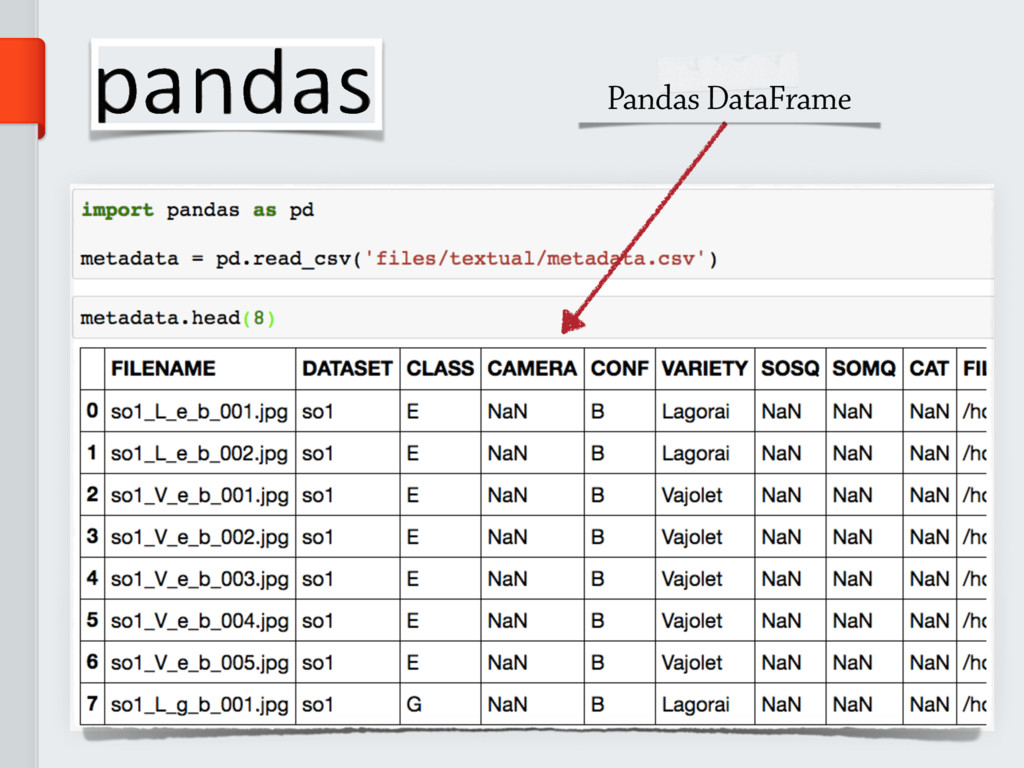
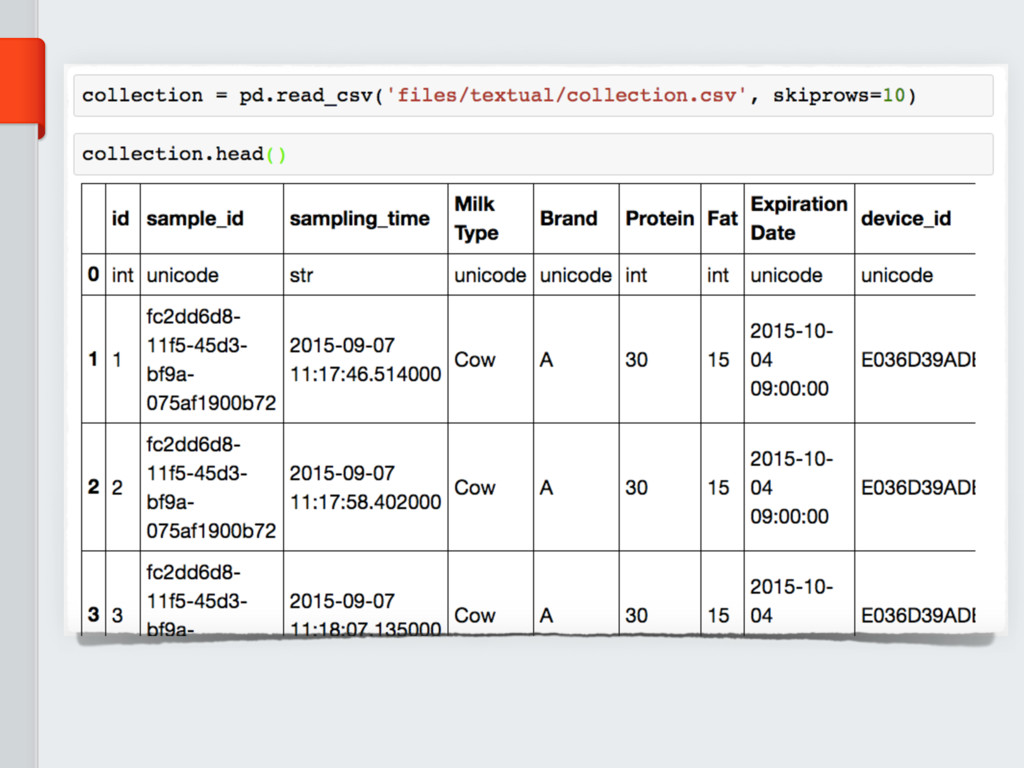
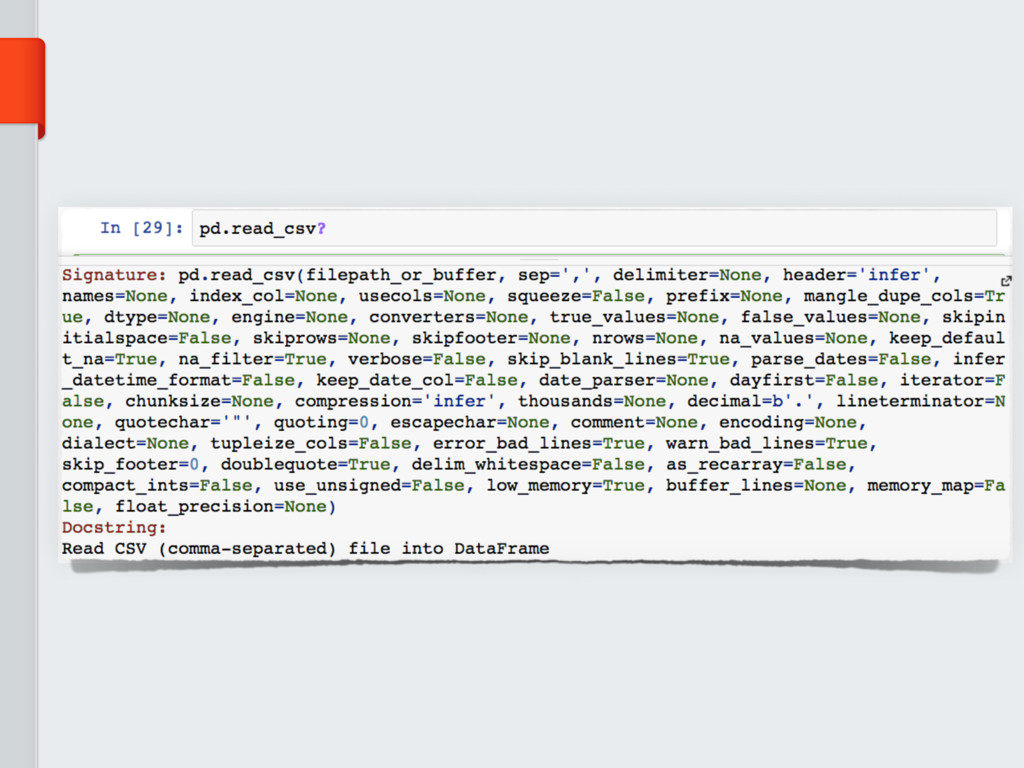
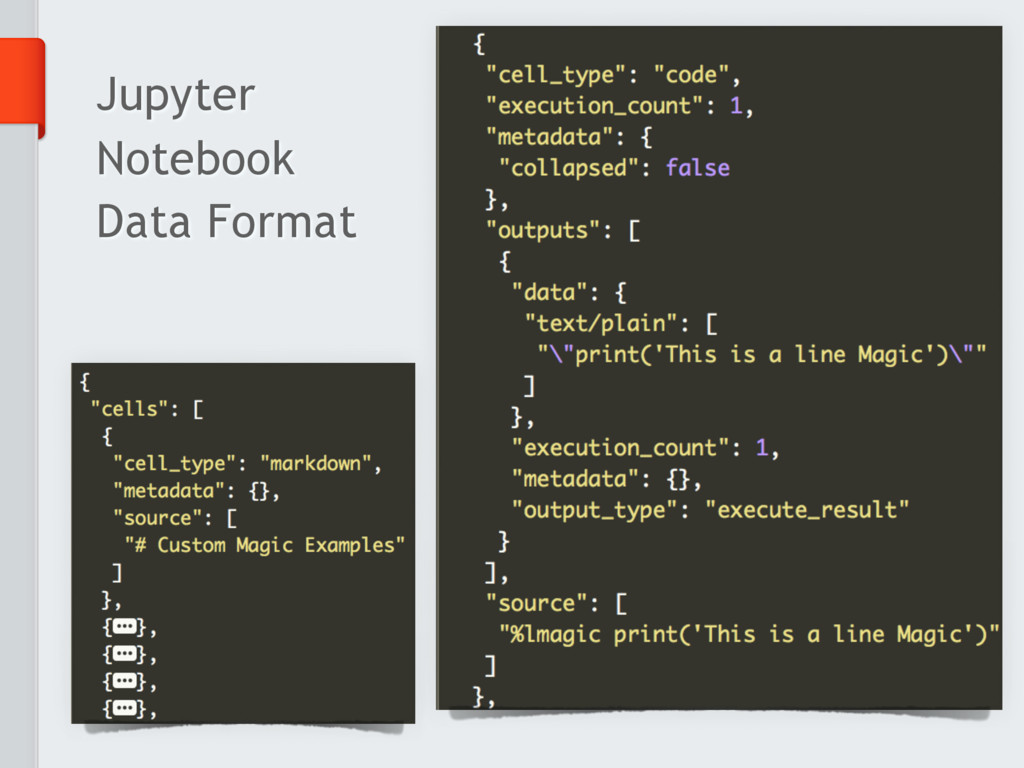
The CSV is the most widely adopted data format. It used to
store and share *not-so-big* scientific data. However, this format is not particularly
suited in case data require any sort of internal
hierarchical structure, or if data are too big. To this end, other data formats must be considered.
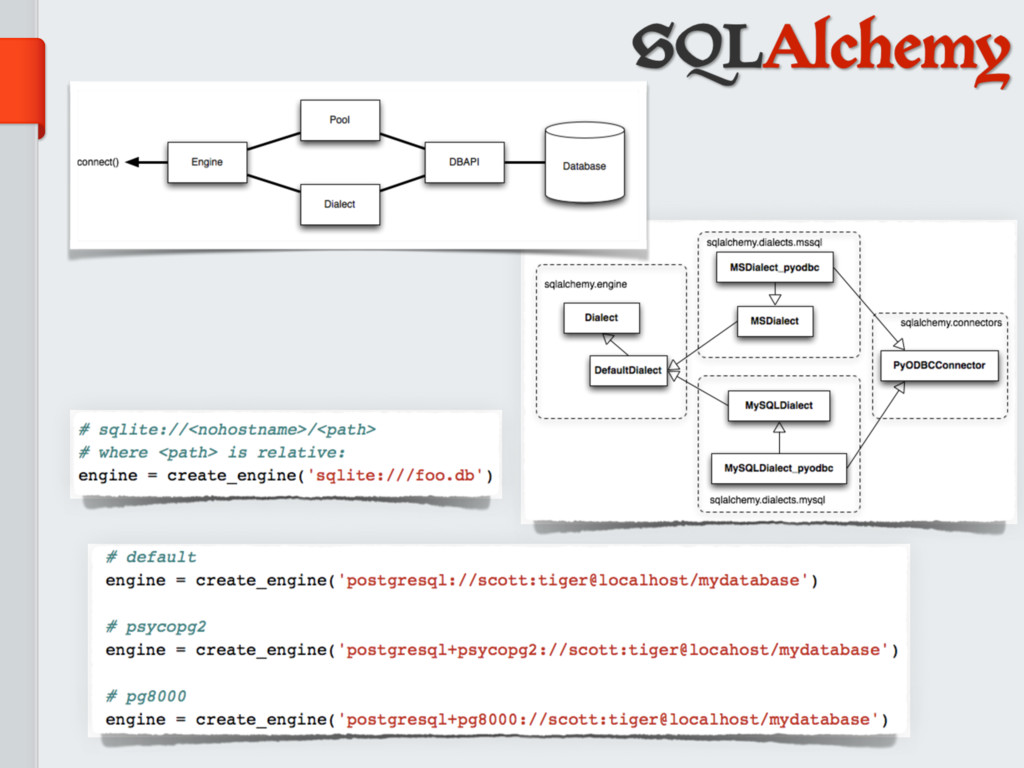
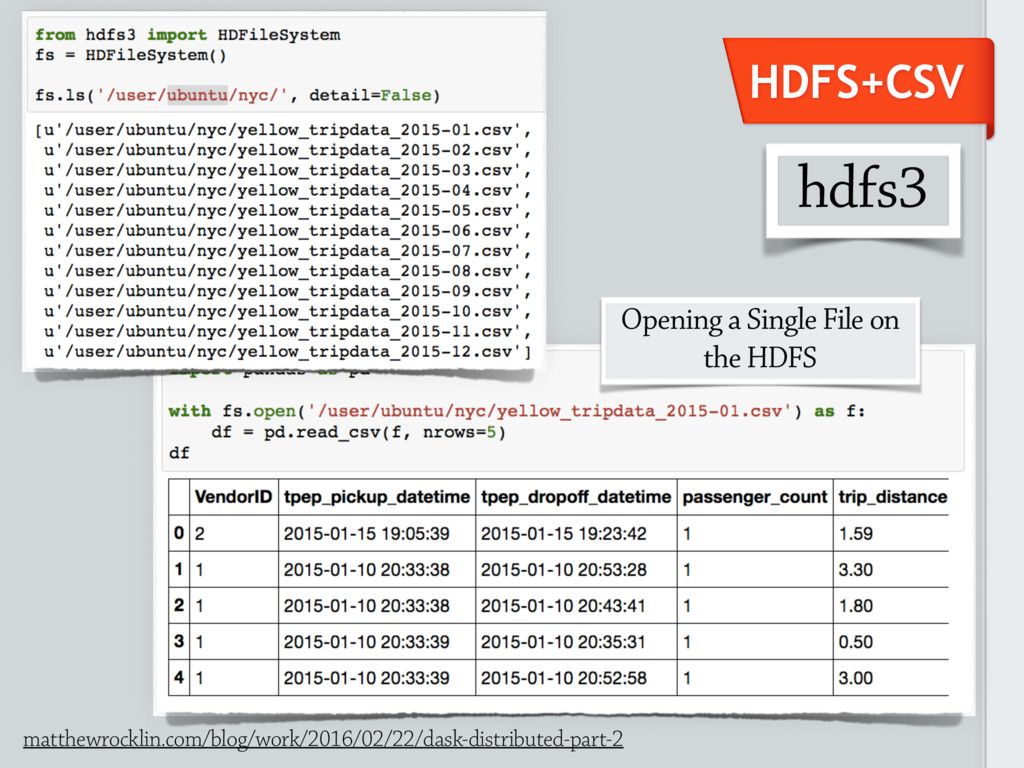
These formats may include *general purpose* solutions, e.g. [No]SQL databases, HDFS (Hadoop File System);
or may be specifically designed for scientific data, e.g. hdf5, ROOT, NetCDF.
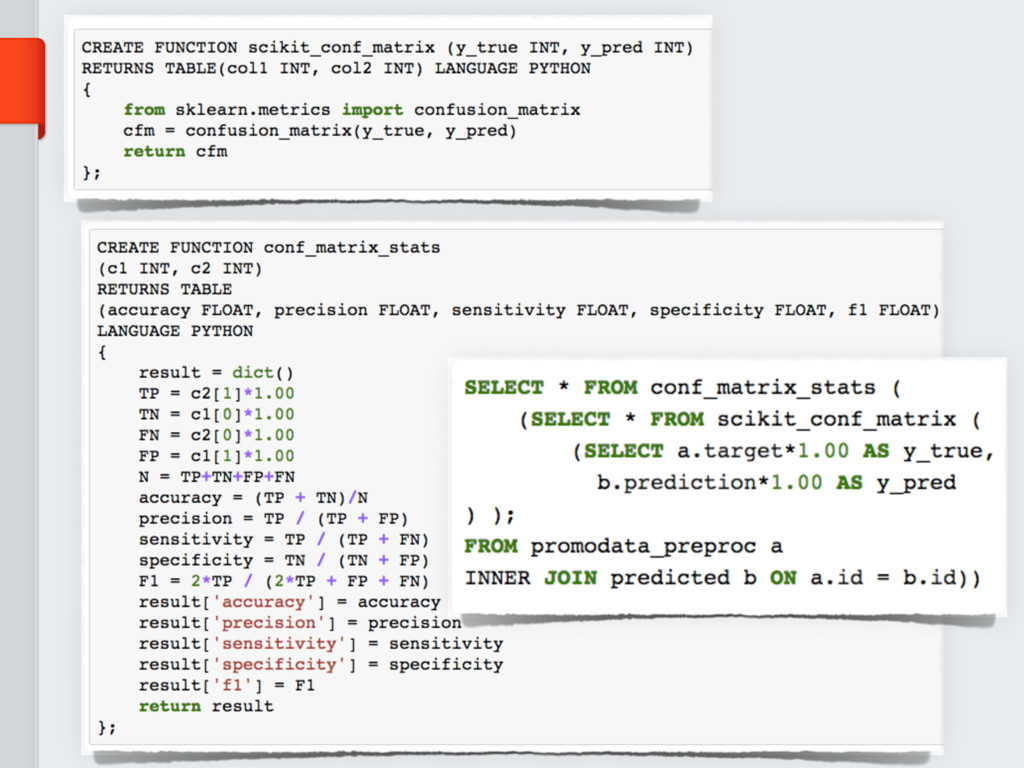
In this talk, the different data formats will be presented and compared w.r.t. their
usage for scientific computations along with corresponding Python libraries.
Finally, few notes about the new trends for **columnar databases** will be discussed for very fast
in-memory analytics (e.g. *MonetDB*).
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Thanks a lot for your kind attention +ValerioMaggio [email protected] it.linkedin.com/in/valeriomaggio](https://files.speakerdeck.com/presentations/da887b61d9484041b5a459fb9f107d00/slide_59.jpg){kind=link}