Introducing Deep Learning requires a mixture of expertise
ranging from basic computer science concepts to more advanced
knowledge of linear algebra and calculus.
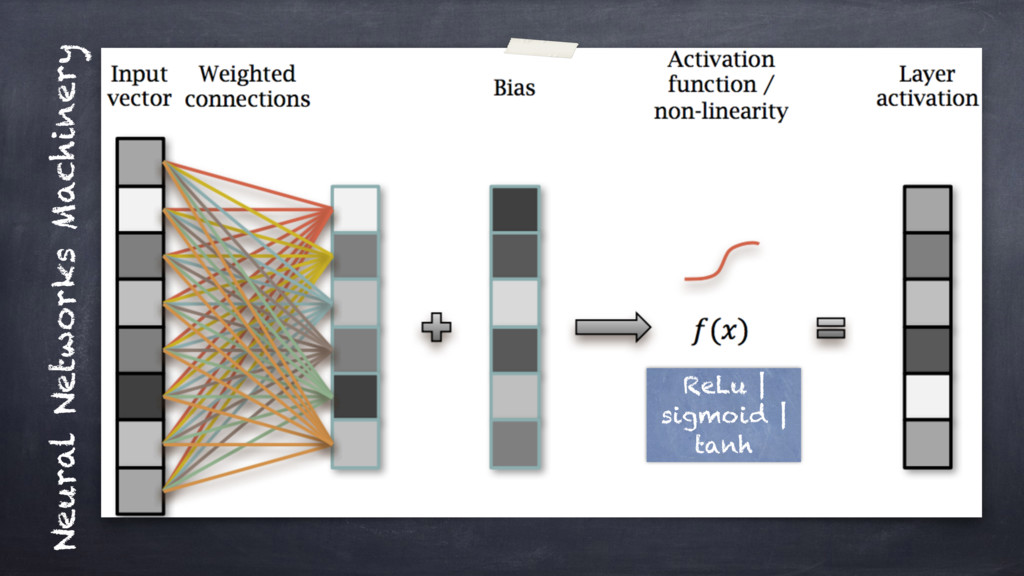
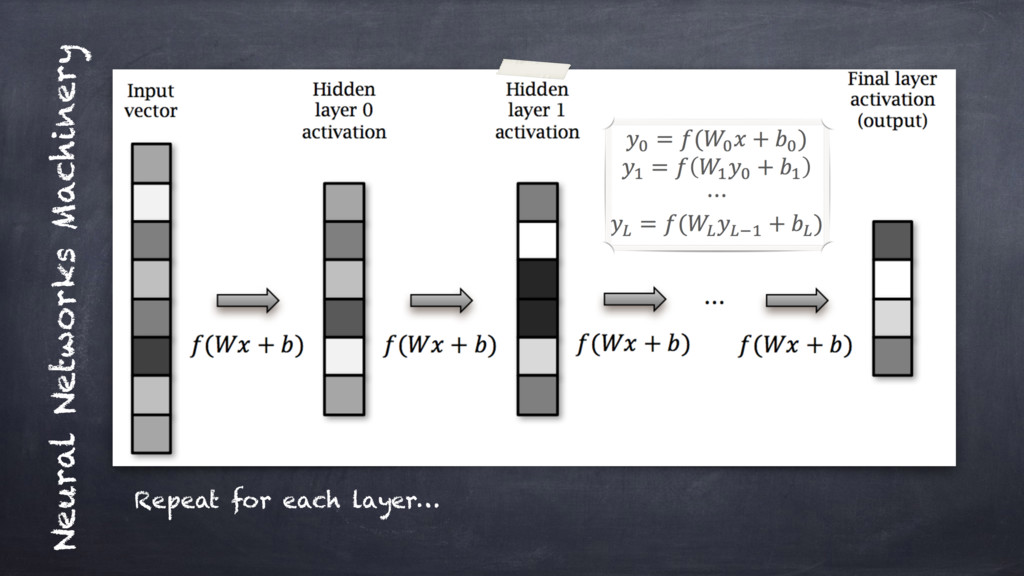
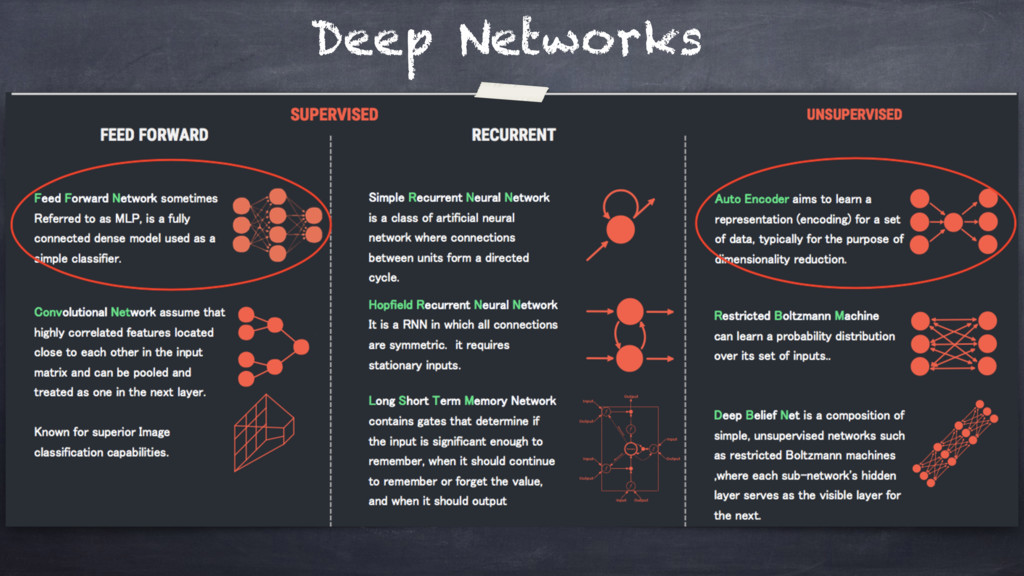
A classical introduction to the topic would go through explaining
about "activation functions", "optimisers & gradients", "batches", "feed-forward" and
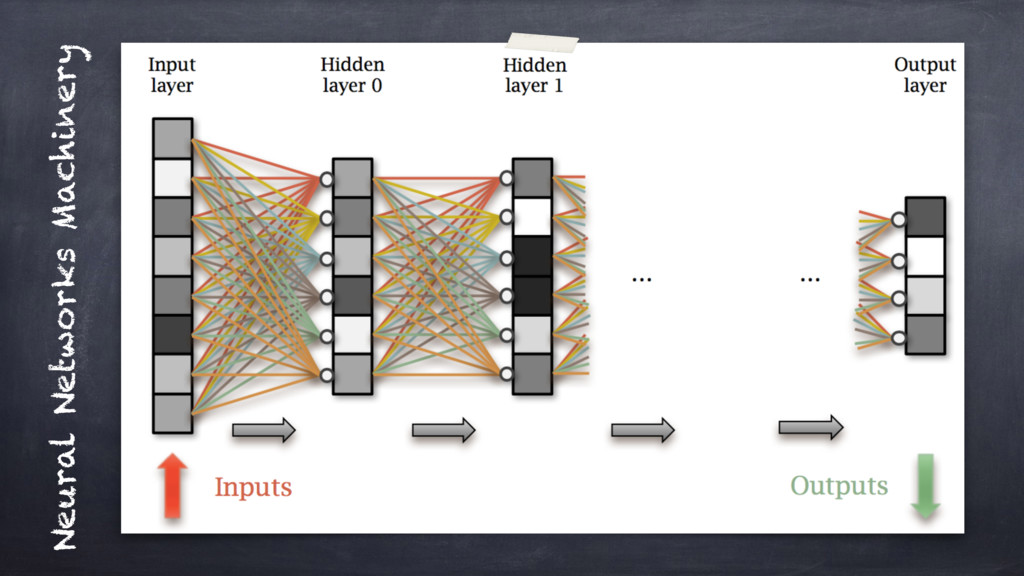
"recurrent" multi-layer networks.
This is the "conventional" way: leveraging on a more theoretical perspective to ultimately explain how to
effectively implement Artificial Neural Networks (ANN).
The other way, namely the "unconventional way", to introduce Deep Learning
is from the perspective of the computational model it requires.
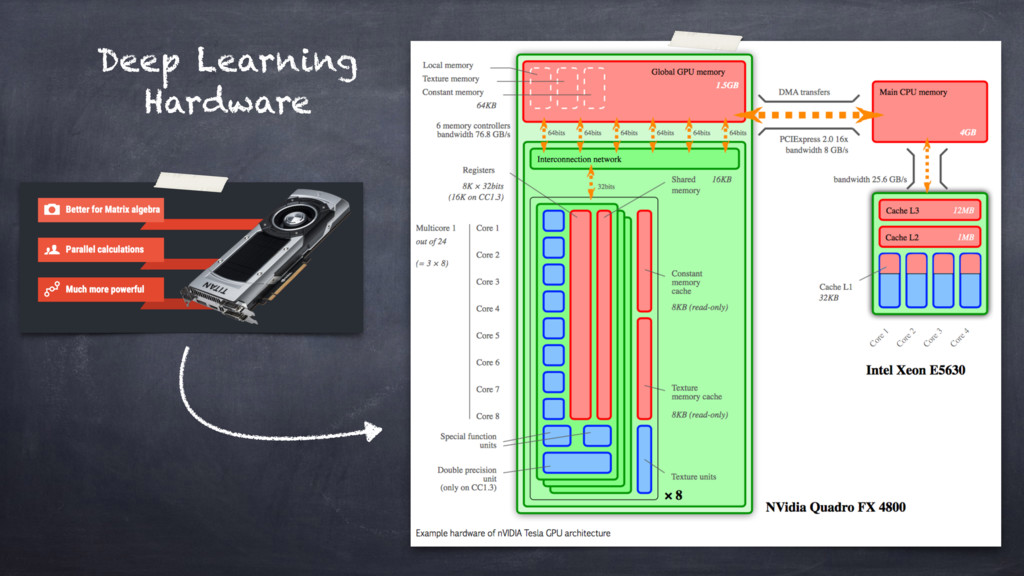
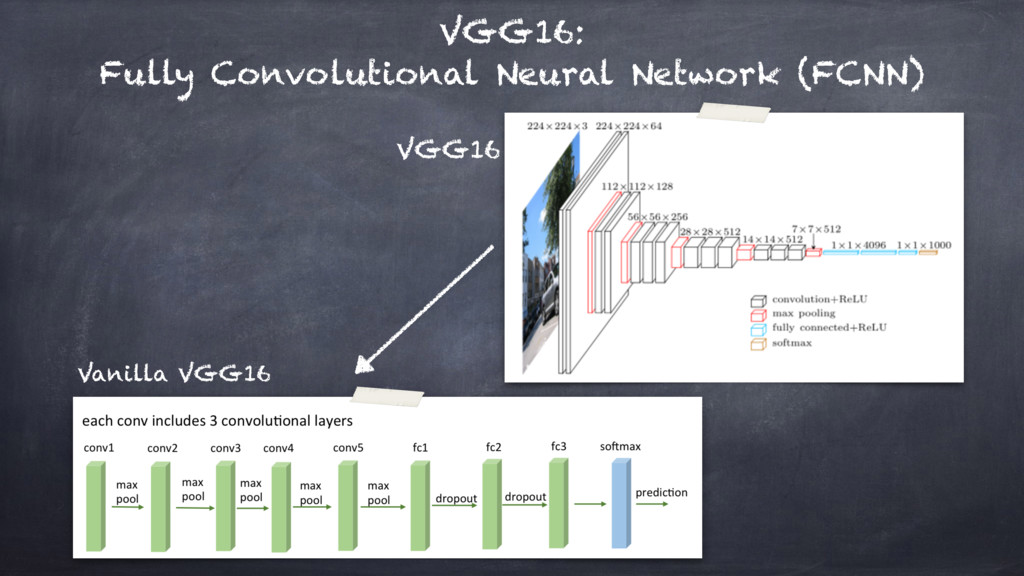
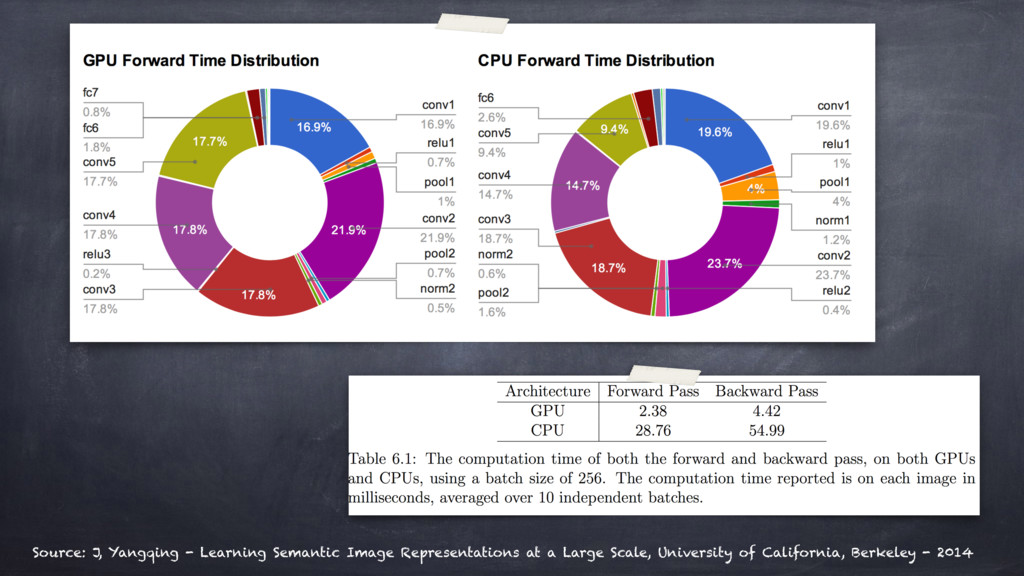
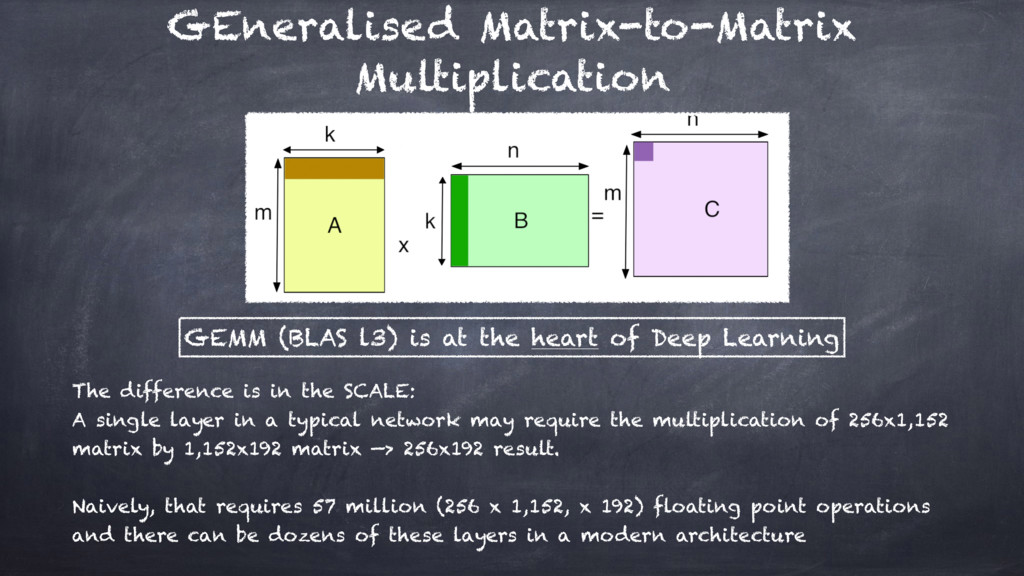
Therefore, this is the case when you may want to describe ANNs in terms of "Accelerated Kernel Matrix Multiplication" and
the gem[m|v] BLAS library, parallel execution models, and CPUs vs GPUs computing.
This is exactly the perspective I intend to pursue in this talk.
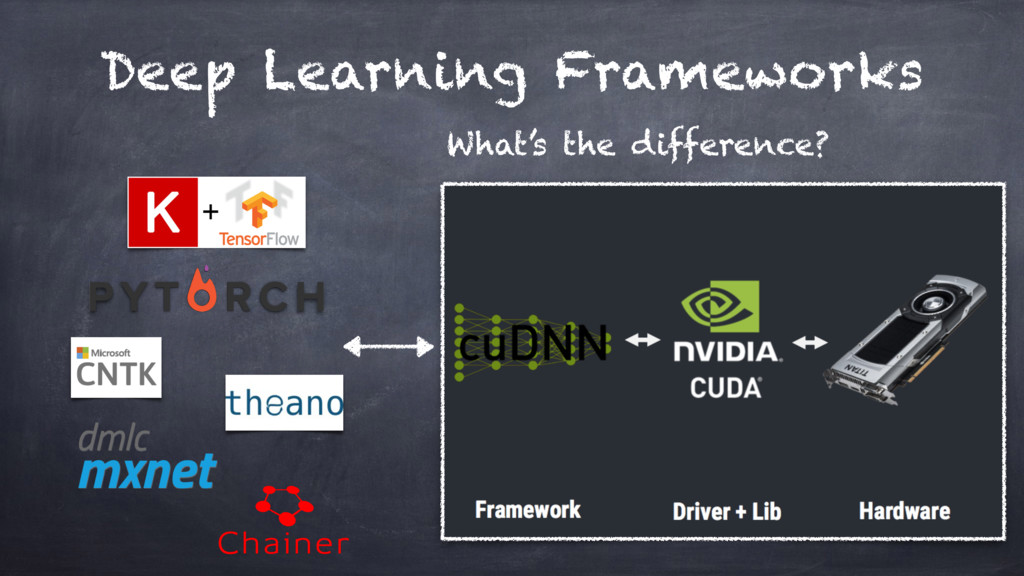
Different libraries and tools from the Python ecosystem, namely theano, tensorflow, and pytorch, will be presented
and compared, specifically in terms of their underlying computational models.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}