Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
インシデントマネジメント~実践あるのみ!インシデント対応訓練~
Search
Tech Leverages
PRO
November 22, 2023
Programming
12
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
インシデントマネジメント~実践あるのみ!インシデント対応訓練~
## 技術
SRE, インシデント, ポストモーテム, DevOps
Tech Leverages
PRO
November 22, 2023
More Decks by Tech Leverages
See All by Tech Leverages
Slackを「AIエージェントのHub」にする 〜 SlackbotとHolmesGPTで実現するAIOps
leveragestech
PRO
0
10
データ組織の転換期 一足飛びしない段階的戦略
leveragestech
PRO
0
96
並列化でチームのアウトプットを増やす
leveragestech
PRO
0
45
Engineering ManagerがAI時代に この先生きのこるには?
leveragestech
PRO
1
99
最新技術を"今は選ばない"という技術選定
leveragestech
PRO
0
550
毎⽇dumpされるDBにCDCは無⼒だっ た、、FederatedQueryで繋ぎ直した データ連携の試⾏錯誤
leveragestech
PRO
0
83
Tableauを活かすためにTableauに制約を設けた話
leveragestech
PRO
0
82
営業支援システムと歩んだ7年半の変遷
leveragestech
PRO
0
150
DMBOKを使ってレバレジーズのデータマネジメントを評価した
leveragestech
PRO
0
840
Other Decks in Programming
See All in Programming
Go言語とトイモデルで学ぶTransformerの気持ち / fukuokago23-transformer
monochromegane
0
150
Build-to-own AI: Agentic Development for Humans
inesmontani
PRO
0
110
AI時代に設計が 最大の生産性レバーになる 意図駆動開発とデータを消さない設計|Don't Delete Your Data or Your Intent — Design as the Deepest Lever in the AI Era
tomohisa
0
120
AI時代、エンジニアはどう育つのか -未経験エンジニアの成長を間近で見て考えたこと-
thasu0123
0
190
GDG Korea Android: 2026 I/O Extended ~ What's new in Android development tools
pluu
0
190
Laravelで学ぶ Webアプリケーションチューニング入門/web_application_tuning_101
hanhan1978
4
1.4k
광주소프트웨어마이스터고등학교 DevFest 특강 - 바이브 코딩 시대에서 주니어 개발자로 살아남는 방법
utilforever
1
160
Claude Team Plan導入・ガイド
tk3fftk
0
240
作るコストが小さくなった時代 幸せに働くために改めて考えたいこと 〜エンジニアとして価値を出し続けるために注視している二分野〜
yuppeeng
0
130
20260722_microCMSで考える、AI時代のコンテンツ運用設計
yosh1
0
150
AWS DevOps AgentのAzure接続機能を検証して見えた活用法/Use Cases Verified for the AWS DevOps Agent's Azure Connectivity Feature
masakiokuda
0
170
Built Our Own Background Agent at LayerX #aidevex_findy
layerx
PRO
9
3.7k
Featured
See All Featured
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
Thoughts on Productivity
jonyablonski
76
5.3k
Making Projects Easy
brettharned
120
6.7k
Darren the Foodie - Storyboard
khoart
PRO
3
3.5k
Avoiding the “Bad Training, Faster” Trap in the Age of AI
tmiket
0
200
Refactoring Trust on Your Teams (GOTO; Chicago 2020)
rmw
35
3.7k
Visualization
eitanlees
152
17k
Navigating the moral maze — ethical principles for Al-driven product design
skipperchong
2
430
Building AI with AI
inesmontani
PRO
1
1.1k
Leveraging LLMs for student feedback in introductory data science courses - posit::conf(2025)
minecr
1
330
We Analyzed 250 Million AI Search Results: Here's What I Found
joshbly
1
1.7k
Believing is Seeing
oripsolob
1
170
Transcript
インシデントマネジメント 〜実践あるのみ!インシデント対応 訓練〜 テクノロジー戦略室SREチーム 蒲生廣人
| © Leverages inc. 2 • 所属: ◦ テクノロジー戦略室SREチーム • 経歴:
◦ 2017年4月 ITベンチャー 新卒入社 ◦ 2021年4月 レバレジーズ株式会社 中途入社 • 出身: ◦ 神奈川県横浜市 • 趣味: ◦ フットサル、ずっと真夜中でいいのに • トピック ◦ 観葉植物置き始めたけど枯れそう、、 • 好きなAWSサービス: ◦ ECS、CloudFront、Lambda 自己紹介 Introduction
| © Leverages inc. 3 • インシデント対応の難しさ ◦ なんで難しいの? • インシデントマネジメントの紹介
◦ タイムライン ◦ インシデントコマンドシステム ◦ インシデントマネジメントのベストプラ クティス ◦ 避けられるアンチパターン • インシデント対応訓練 ◦ 訓練の目的 ◦ SREチームでの事例 • まとめ アジェンダ INDEX
| © Leverages inc. 4 • インシデント対応を難しくしている要因につ いてざっくり理解してる • インシデントマネジメントの重要性をざっくり 理解してる
• インシデント対応訓練やりたいなあって気 持ちが芽生えてる 今日のゴール 目的・目標
インシデント対応の難しさ
そもそもインシデントってなに どこからどこまでがインシデントなのさ 障害とインシデントって何が違うのさ
インシデントの定義
場合による
「何かが起こったときのこと」 by Google 「事業運営に重大な影響を与える可能性のある、サービ ス品質の計画外の中断または低下のこと」 by Amazon 「「何らかの対応が必要な課題」 by Netflix
None
レバテックでポストモーテムを書く基準 以下の条件の内、 2つ以上当てはまる場合 ・複数人のユーザーに影響があった ・障害発生期間が5分を超える ・過去似たような事象が発生しているまたは 将来起こる可能性が高い
障害とインシデントの違い
インシデント=「ITサービスを利用できない状態」 障害=インシデントを引き起こす要因の一つ by PagerDuty
None
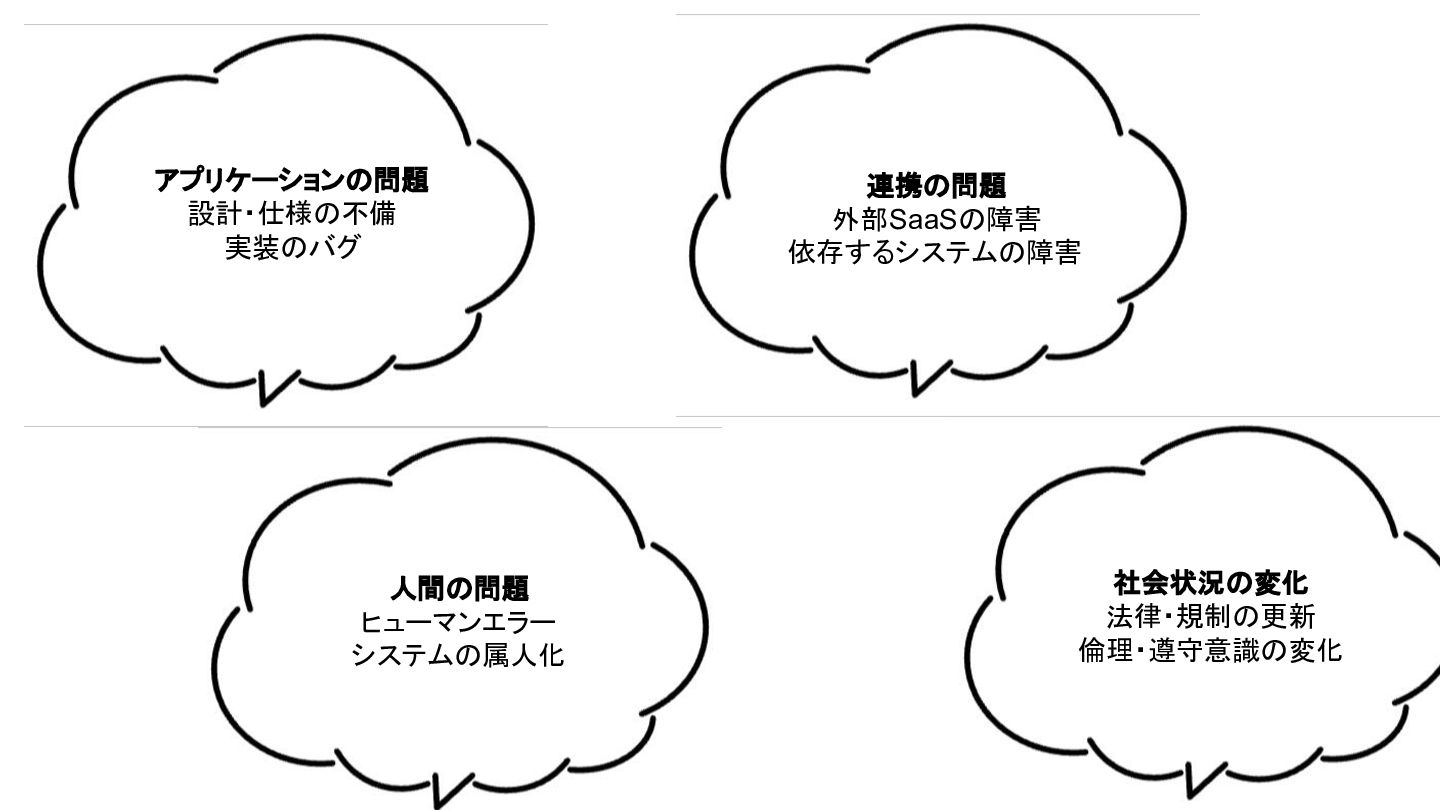
アプリケーションの問題 設計・仕様の不備 実装のバグ 連携の問題 外部SaaSの障害 依存するシステムの障害 社会状況の変化 法律・規制の更新 倫理・遵守意識の変化 人間の問題
ヒューマンエラー システムの属人化
全部防げる?
インシデントは起こるもの
誰もが自分のサービスが常にスムーズに動くことを臨 んでいますが、わたしたちは不完全な世界に生きてい るので、障害が発生することもあります
でもインシデント対応って難しいよね
• 対応スレッド作る • 第1報でインシデントを周知 • 関係者と担当開発チームに共有 • 状況を整理して初動を決める ◦ 影響範囲
◦ 原因・復旧の目処がつきそうか • 役割の割り振り • 優先順位の決定 • 復旧作業と並行して原因調査 • 状況を定期的に更新して関係者に共有 • 色々なところからくる問い合わせへの対応と説明 ◦ 他のシステムに影響が出ていれば共有して他チームへの協力依頼 を出す • 復旧したら関係者に周知 • 影響範囲と原因がわかっていない場合は引き続き調査 • ポストモーテム
• 部内関係者、Pマーク担当に共有 • 攻撃であれば攻撃の停止策を検討して実施 • 流出した個人情報の精査 • ユーザーへの対応検討 • 謝罪、事象の報告
• Pマーク担当にユーザー対応の進捗共有 • 「緊急事態対応報告書」「是正予防措置報告書」を記入し、 Pマーク運営へ 提出 • より厳しい再発防止策の検討 個人情報絡みのインシデントであればさらに、、 (弊社はPマークに属しているので以下の対応が必要)
None
人間への負荷 • 複雑なシステム構成による認知不可 • 状況・方法の不確実性が高い状況下で作業す るプレッシャー • 作業の疲労や緊張からくる身体・精神へのスト レス ◦
復旧作業のミスによる2次被害へのプ レッシャー • 多様な職種間コミュニケーションをまとめる難し さ 「機械と人間の重要な違いの一つは、機械は過負荷になると突然停止するのに対して、人間は ゆっくりと機能を落とすことである。この傾向は、人間が刻々と増大する情報処理要求に直面し た際に顕著となる」by 保守事故 ジェーム・リーズン
インシデントは起こるもの インシデント対応は難しい><
詰んでね?
インシデントマネジメントの紹介
システムを運用する組織においてインシデ ント対応に立ち向かう人間を支援する仕組 みや方法論
インシデントにエンジニアリングで立ち向かう • インシデントレスポンスのシフトレフト ◦ インシデント発生時のマニュアル・フロー整備 ◦ インシデント対応レベルのアセスメント実施 ◦ インシデント対応訓練の定期実施 ◦
脅威モデリング ◦ ドキュメント整備(システム構成図、データモデル) • インシデントマネジメントの支援の自動化
管理するのは障害じゃなくてインシデント?
インシデント=「ITサービスを利用できない状態」 障害=インシデントを引き起こす要因の一つ by PagerDuty
目的の違い 障害管理=障害の根本的な原因を探り、今後同じことが起きな いよう対処することが目的 インシデントマネジメント=目の前で起きている問題の解決が目 的
各所への影響を最小限にとどめ、 早期にサービスを復旧させるプロセス システムをもとに戻すことが目的ではない
他業種からの学び
タイムラインの定義の目的と効果 • インシデントのプロセスの構造化 ◦ 人間のメンタルモデルをある程度統一する • 組織内での用語・概念の統一 ◦ コストや改善の話がしやすくなる •
自動化の設計/実装のモデルになる ◦ 始めからすべて自動化を考えるのではなく一部の対応から始められる
タイムライン
インシデントコマンドシステム =緊急時における標準化された組織マネジメントの手法
1. まずはインシデントコマンダーを決める a. 指揮命令系統の確立 2. 被害状況の把握(サイズアップ) a. まずは目の前で起こっている被害の状況を把握する i. 事実に基づいた情報を伝える
b. その被害がどこまで広がっていきそうかを推測する i. これによって取るべき対応(必要な人員、コスト)が決まる 3. 被害を最小限に留める努力をする a. 何はともあれ人命優先(ITにおいてはメンバーの健康) 4. メンバーのチェックインとチェックアウトを管理する a. 人員にどのような人がどこで何をしているのかを把握する
インシデントマネジメントのベストプラクティス • 優先順位 ◦ まず出血を止め、次にサービスを回復し、それから根本原因の証拠を保存しましょう • 準備 ◦ インシデント管理の手順のドキュメント化 •
信頼 ◦ インシデントに関わる全員に、割り当てられた役割内で完全な自律性を持ってもらう • 自己観察 ◦ レスポンスに対応している間の自分の感情の状態に注意を払う。パニックや圧倒されている感 覚が生じてきたら支援を求める • 代案の検討 ◦ 選択肢を定期的に考慮し、インシデントレスポンスとして今やっていることをそのまま続けること が妥当なのか、あるいは他の筋道をとるべきなのか • 訓練 ◦ インシデントレスポンスのプロセスを定期的に利用し、身につける • 持ち回り ◦ インシデントコマンダーを持ち回りにしよう
インシデントマネジメントのベストプラクティス • 優先順位 ◦ まず出血を止め、次にサービスを回復し、それから根本原因の証拠を保存しましょう • 準備 ◦ インシデント管理の手順のドキュメント化 •
信頼 ◦ インシデントに関わる全員に、割り当てられた役割内で完全な自律性を持ってもらう • 自己観察 ◦ レスポンスに対応している間の自分の感情の状態に注意を払う。パニックや圧倒されている感 覚が生じてきたら支援を求める • 代案の検討 ◦ 選択肢を定期的に考慮し、インシデントレスポンスとして今やっていることをそのまま続けること が妥当なのか、あるいは他の筋道をとるべきなのか • 訓練 ◦ インシデントレスポンスのプロセスを定期的に利用し、身につける • 持ち回り ◦ インシデントコマンダーを持ち回りにしよう
避けられるアンチパターン • 群衆によるインシデント対応 • マジックスモークを消すのは私だ! • リカバリ時間ではなく障害回避の最適化
• 群衆によるインシデント対応 ◦ 「ボールから目を離さないが、ゾーンから足を踏み出さない」 ◦ わらわらと集まってきては問題に首を突っ込み始めること。あるいは誰もが各自の作業に没頭するだ けではいられなくなり、問題が解決されるまで脳裏にこびりついて注意を払わざるを得ない状態 ▪ インシデントコマンドシステムや訓練によって回避しよう ▪
システムを構築して必要な人が問題の管理にフルコミットして、他の人については必要が生じる までエネルギーを温存できるようにすることが重要
• マジックスモークを消すのは私だ! ◦ エリート戦士/ヒーローの文化は落とし穴です ◦ 周到な設計や予防の計画よりもインシデント対応の英雄的な行動を高く評価すること ▪ 優れたエンジニアリングよりも運用での忍耐に報いるのは誤ったインセンティブを与え、運用現 場の混乱とエンジニアの燃え尽きに直結する ▪
組織のレジリエンスを顧みずインシデントを一身に引き受ける誰かを称賛するのはだめよ
• リカバリ時間ではなく障害回避の最適化 ◦ 障害をなくすことに工数を使い、インシデントが発生した際の対処が改善されない ▪ インシデントは避けられない ▪ その回避にすべてを賭けるのではなく、うまく処理できるようになること
インシデント対応訓練
訓練?
他業種からの学び
インシデント対応訓練の目的 インシデントレスポンスのプロセスを定期的に利用し、身につける 逆に訓練をしない場合のリスク (1)システムに対して歴が浅いメンバーが Opsリードとなってぶっつけ本番でやるのは危険 Opsリードの人がシステムの構成などをキャッチアップできていないままインシデント対応を行うと 作業した結果、状態が悪化したりステークホルダーとの調整がうまくいかなかったりする場合がある (2)一部のメンバーがインシデント対応を巻き取ってしまう システムへの理解が深かったりスキルがあるメンバーはインシデントへの反応が早いし対応も的確で 1人でやれてし
まうケースが多い。 そのためそういった一部のメンバーに対応が集中してしまい、他のメンバーがインシデント対応を経験する機会が失 われてしまって結果単一障害点につながってしまう。 (3)コミュニケーションリードやインシデントコマンダーの人が必要な情報連携をいきなりやるのが難しい いろんなチーム間、職種間のコミュニケーションが必要になる中で連携すべき情報をまとめて説明する難易度の高さ がある
インシデント対応訓練の流れ • 事前準備 ◦ ゲームマスター(GM)が訓練用のAWS環境を作成してインシデント内容を決める(対応時間目安は 30分く らい) ◦ 参加メンバーで3人チームを作って以下の役割をふる ▪
インシデントコマンダー ▪ コミュニケーションリード ▪ Opsリード ▪ 参加メンバー外で事業部メンバー役を用意( GMが兼任してOK) ◦ GMが訓練用環境へのアクセス権を全員に付与 • 訓練 ◦ GMが訓練用環境のシステム構成を説明 ◦ GMが発生させるインシデント内容を簡単に共有(サイトが落ちる、一部の機能が停止する、など) ◦ インシデントを発生させる ◦ 参加メンバーが各々の役割で動いてインシデント対応を行う ◦ 事業部メンバーがインシデント解消を宣言できるまで or制限時間まで対応 • フィードバック ◦ インシデント解消を宣言できたかを改めて確認 ◦ 各チームごとにうまくいったこと、幸運だったこと、改善できることを出し合う
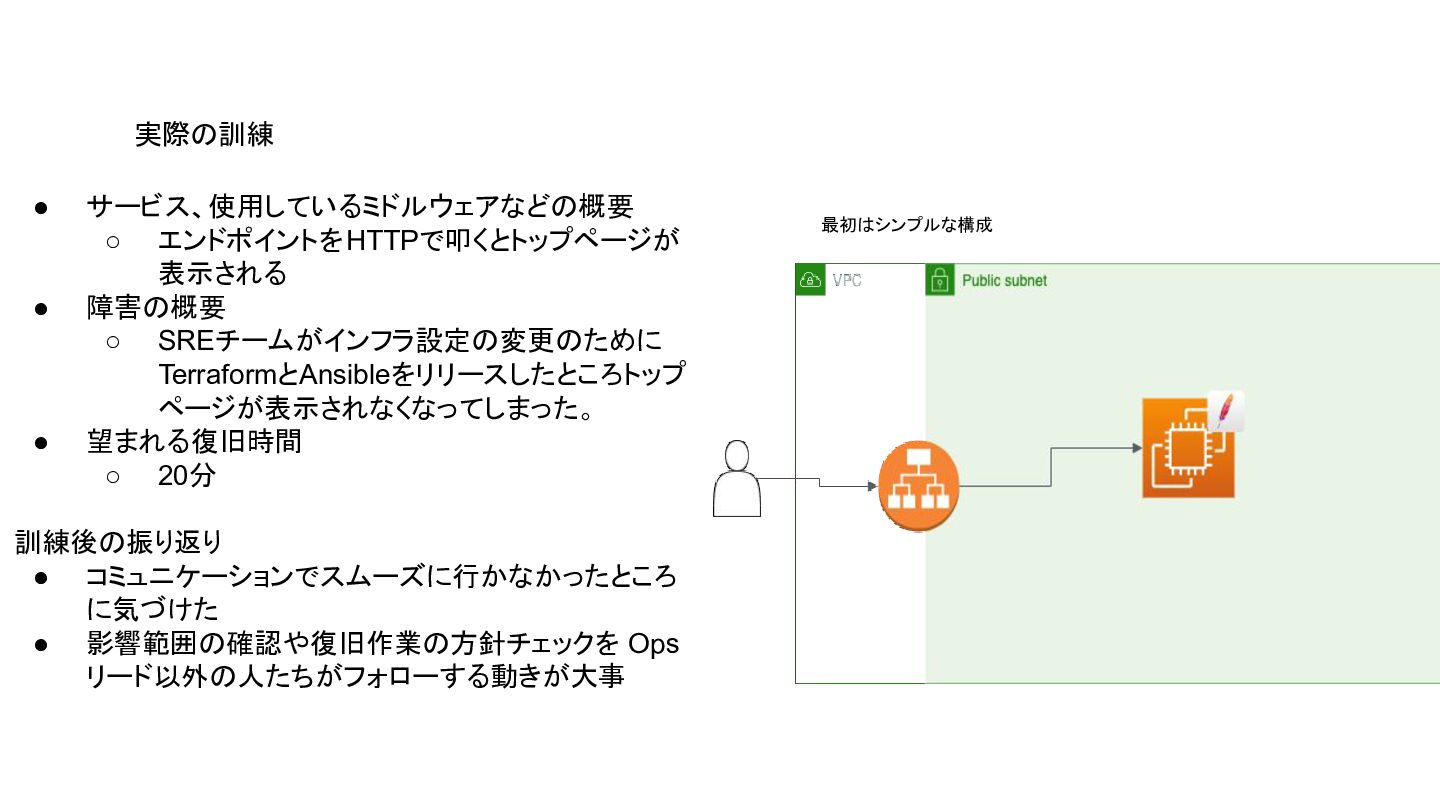
実際の訓練 • サービス、使用しているミドルウェアなどの概要 ◦ エンドポイントをHTTPで叩くとトップページが 表示される • 障害の概要 ◦ SREチームがインフラ設定の変更のために
TerraformとAnsibleをリリースしたところトップ ページが表示されなくなってしまった。 • 望まれる復旧時間 ◦ 20分 訓練後の振り返り • コミュニケーションでスムーズに行かなかったところ に気づけた • 影響範囲の確認や復旧作業の方針チェックを Ops リード以外の人たちがフォローする動きが大事 最初はシンプルな構成
ポイント • 事前準備 ◦ システム構成 ▪ 訓練を行う環境をどこに置くか ◦ シナリオ ▪
ポストモーテムの事例を使おう • 訓練 ◦ 負荷の与え方 ▪ 時間制限 ▪ 事業部役の人がコミュニケーションを複雑にし てみる
まとめ
まとめ • インシデント対応の難しさ ◦ インシデントは起こるもの ◦ インシデント対応を難しくしている要因 ▪ 人間にかかる様々なプレッシャー •
インシデントマネジメントの紹介 ◦ タイムライン ◦ インシデントコマンドシステム ◦ 避けられるアンチパターン • インシデント対応訓練の目的とポイント ◦ インシデントレスポンスのプロセスを定期的に利用し、身につける ◦ ぶっつけ本番を避け、なるべく多くのメンバーにインシデントを疑似体験してもらう ◦ ポストモーテムを有効活用して訓練の中では意識的に負荷をかけよう
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}