vvpkg: A cross-platform data deduplication library in C++14
Design and implementation of vvpkg, the storage layper of Sciunit2 (https://sciunit.run/). The name “vvpkg” stands for “Virtual Versionized Packaging.”
a list of files ▪ v2 package may archive roughly the same set of files, with some added/modified/removed files ▪ Imagine there is a next-generation .deb package that you can choose to install Vim 7.0 or Vim 8.0, what would be the package's internal? 3
is added/modified/removed between two versions. What if there is a binary file that is slightly modified between the two package versions, and that file contributes to 95% of the package size? ▪ Tracking does nothing to this problem 4
data deduplication – at sub-file granularity ▪ If we have a deduplication scheme that works well at sub-file granularity, it should be able to deduplicate tarballs ▪ If v1 package and v2 package are represented as tarballs (or any uncompressed archives), the problem is solved 5
original file be A, the new file be B, split A into fixed size chunks, find these chunks starting from anywhere in B, form delta file that consists of COPY commands and RAW data ▪ Optimization: hash the chunks in A with both weak hash (rolling checksum) and strong hash, computing rolling hashes in B is less costly, verify against the strong hash after finding a potential match[1] ▪ Problem: the delta file may be optimal between two versions, but not optimal among many versions 6
Split both A and B into lists of blocks of unknown size, each block ends with a fixed-size string called “boundary.” A boundary may start from anywhere in a file, and the lower N bits of its weak hash code (Rabin fingerprint) must be zero. Store and identify all blocks with their strong hashes.[2] ▪ If the weak hash code is uniformly distributed in bits, the chance of any content to become a boundary is 2− 7
define thresholds ▪ To avoid = 0, define the lower bits requirement to be a nonzero value ▪ Run two CDC at the same time, one to look for blocks of half of the expected size ▪ Gear hash + normalized chunk sizes (FastCDC[3]) 8
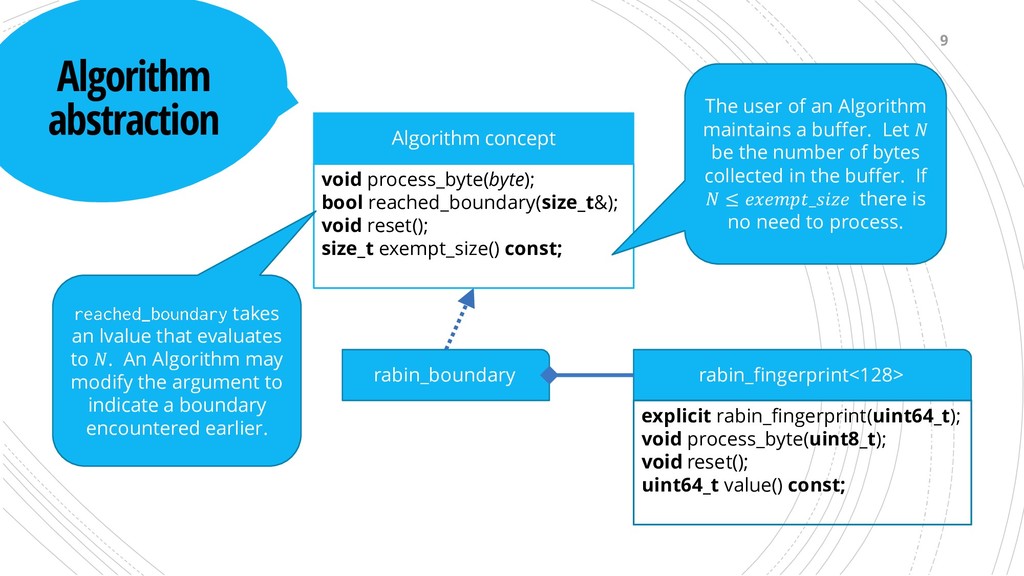
reset(); size_t exempt_size() const; rabin_fingerprint<128> explicit rabin_fingerprint(uint64_t); void process_byte(uint8_t); void reset(); uint64_t value() const; The user of an Algorithm maintains a buffer. Let be the number of bytes collected in the buffer. If ≤ _ there is no need to process. 9 takes an lvalue that evaluates to . An Algorithm may modify the argument to indicate a boundary encountered earlier.
by constant-divisor in 32-bit codegen in MSVC is slow ▪ It just produced a division routine ▪ Background: ▪ DIV r64 throughput ~80-95 cycles ▪ DIV r32 throughput ~20-26 cycles, latency similar ▪ MUL r64 throughput 1 cycles, latency 4 cycles ▪ Get your copy of Intel® 64 and IA-32 Architectures Optimization Reference Manual today! Multiply by constant-divisor optimization 10
less vulnerability than SHA256, short ▪ Efficient on both 64-bit and 32-bit architecture ▪ There is no “one” hash function to satisfy all these ▪ Fortunately we don’t have to use the same hash function on different architectures ▪ BLAKE2b-160 and BLAKE2s-160 are chosen 11
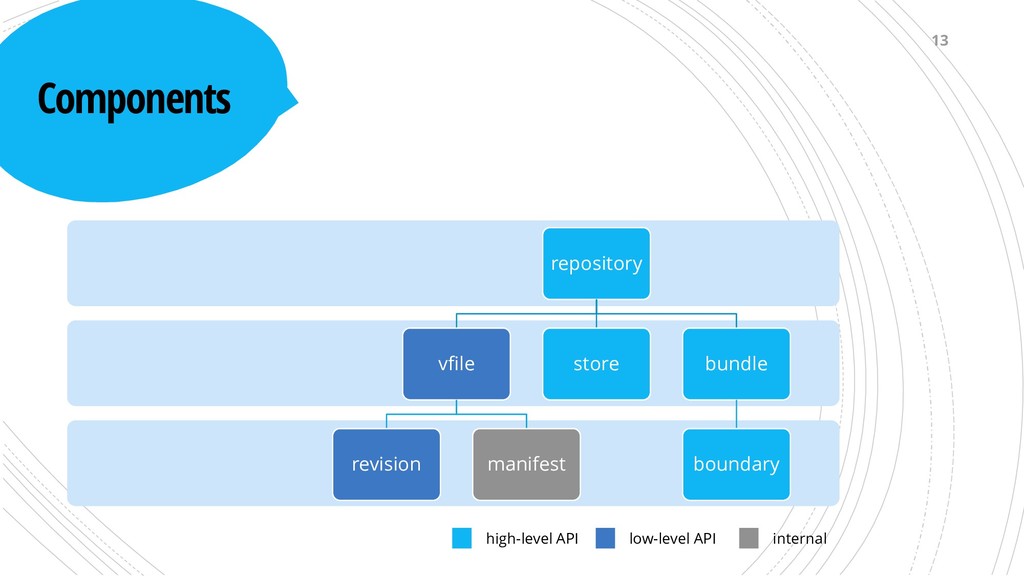
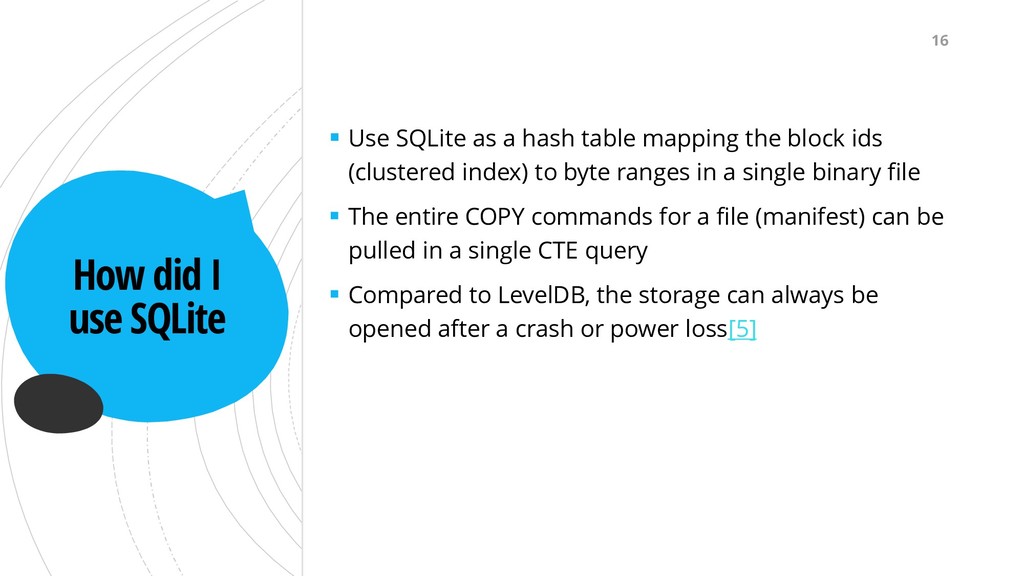
hash table mapping the block ids (clustered index) to byte ranges in a single binary file ▪ The entire COPY commands for a file (manifest) can be pulled in a single CTE query ▪ Compared to LevelDB, the storage can always be opened after a crash or power loss[5] 16
the manifest of a file – a list of hexadecimal block ids ▪ Easy to debug, easy for network exchange in the future ▪ build JSON directly in file ▪ react to hashes through callbacks ▪ Powered by RapidJSON SAX API[6] 17
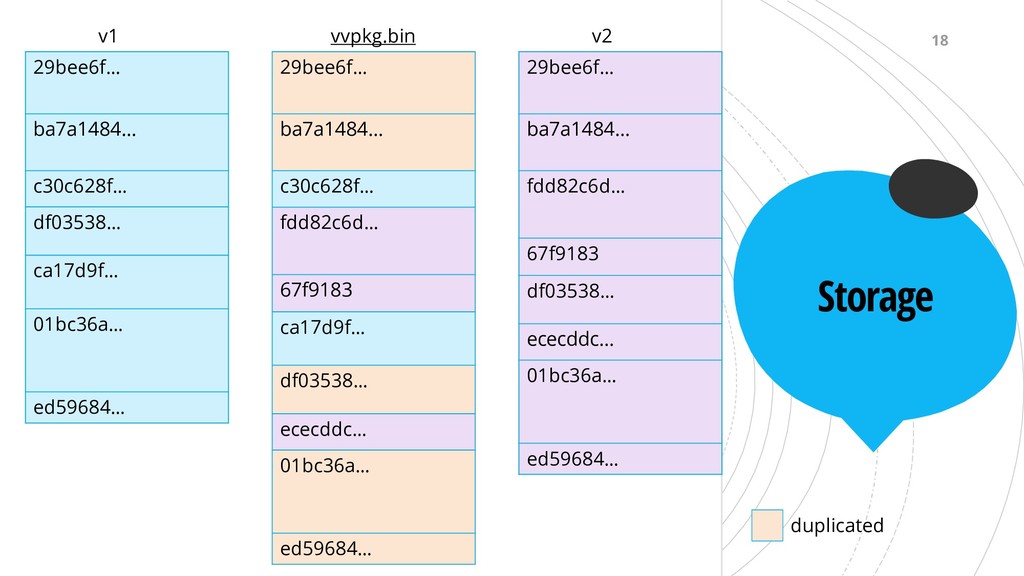
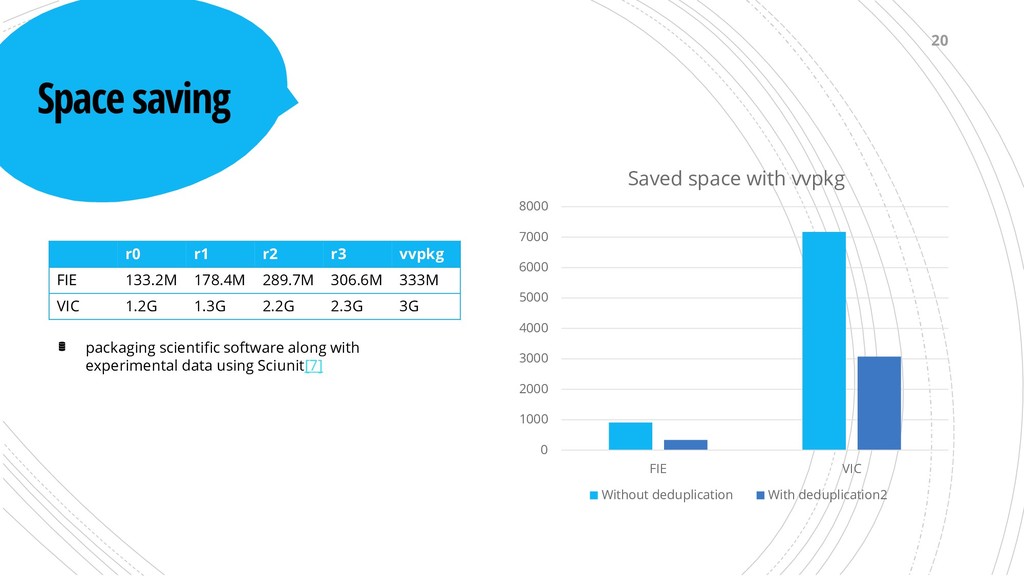
289.7M 306.6M 333M VIC 1.2G 1.3G 2.2G 2.3G 3G 0 1000 2000 3000 4000 5000 6000 7000 8000 FIE VIC Saved space with vvpkg Without deduplication With deduplication2 20 packaging scientific software along with experimental data using Sciunit[7]
File System https://pdos.csail.mit.edu/papers/lbfs:sosp01/lbfs.pdf 3. FastCDC: A Fast and Efficient […] https://www.usenix.org/node/196197 4. Message Digest Library for C++ https://wg21.link/n4449 5. Files are hard https://danluu.com/file-consistency/ 6. RapidJSON SAX API http://rapidjson.org/md_doc_sax.html 7. Sciunits: Reusable Research Objects https://arxiv.org/abs/1707.05731 21
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Strong hash abstraction ▪ HashProvider[4] concept ▪ H::init(&c) ▪ H::update(&c,](https://files.speakerdeck.com/presentations/62f09eb73e5a433490f997d3f8acdcb2/slide_11.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}