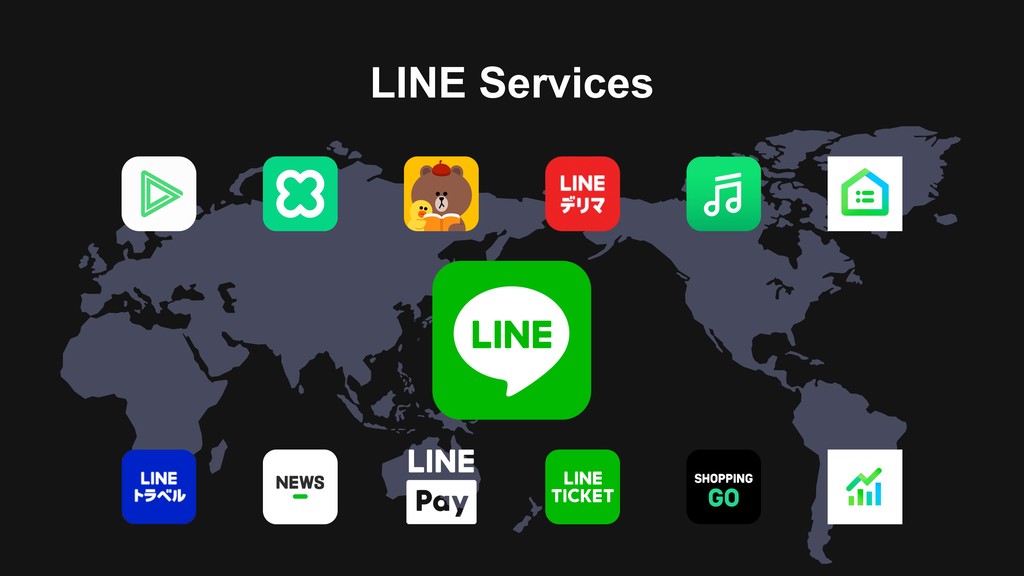
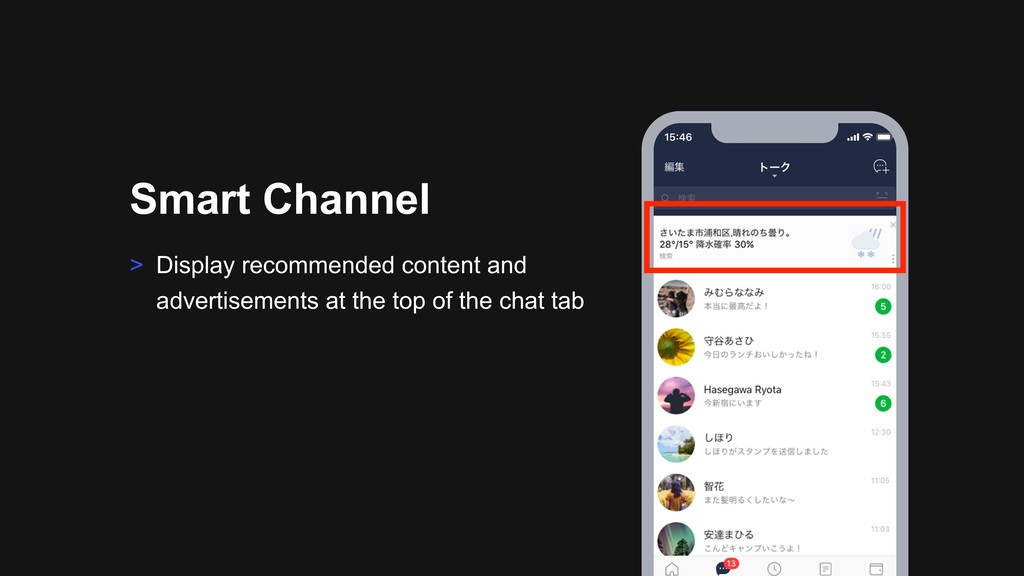
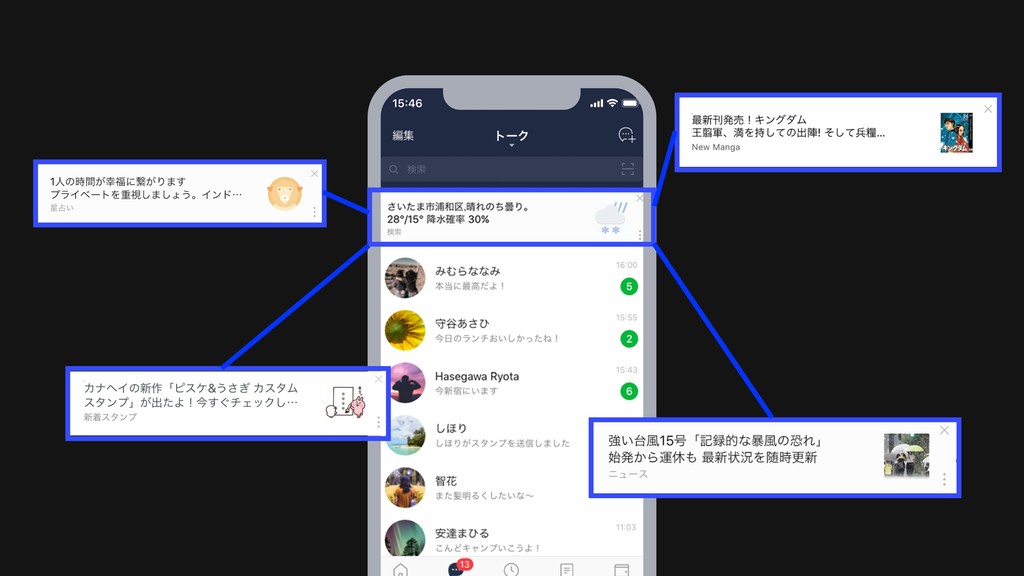
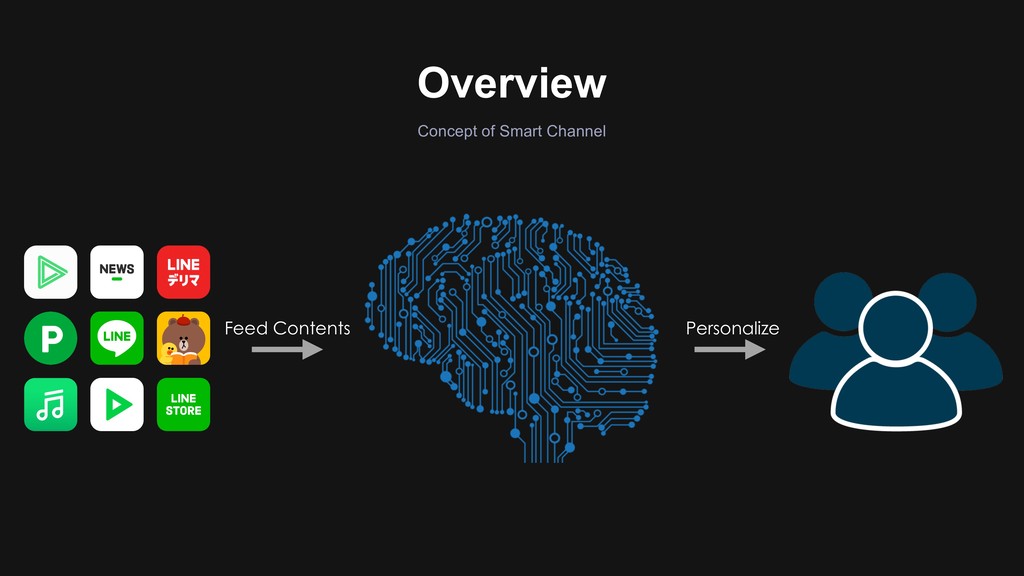
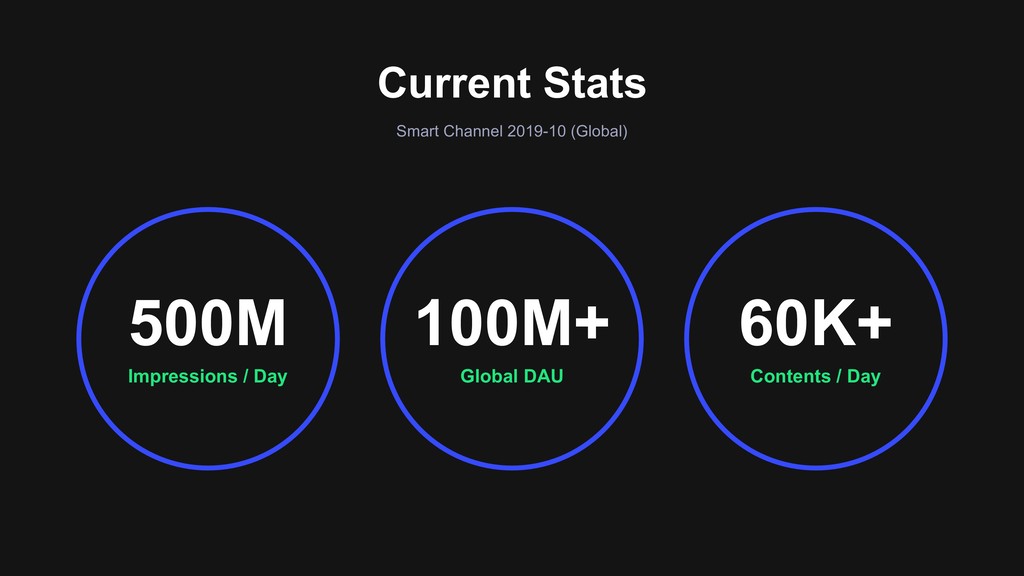
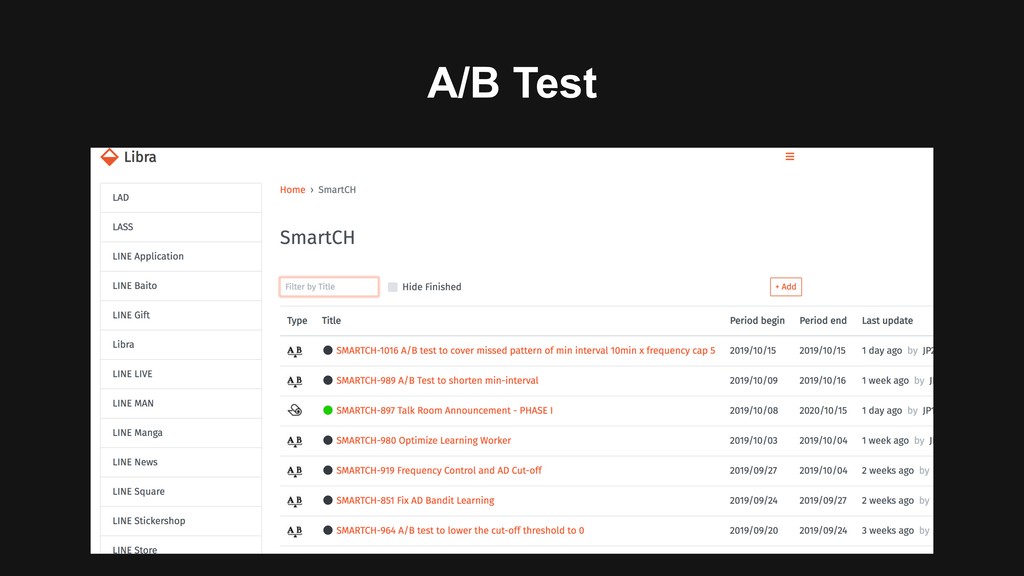
13:40-14:20/15:30-16:10 (2days) > Day1: B1-2 14:30-15:10 The Art of Smart Channel Continuous Improvements in Smart Channel Platform/Contents Related Sections
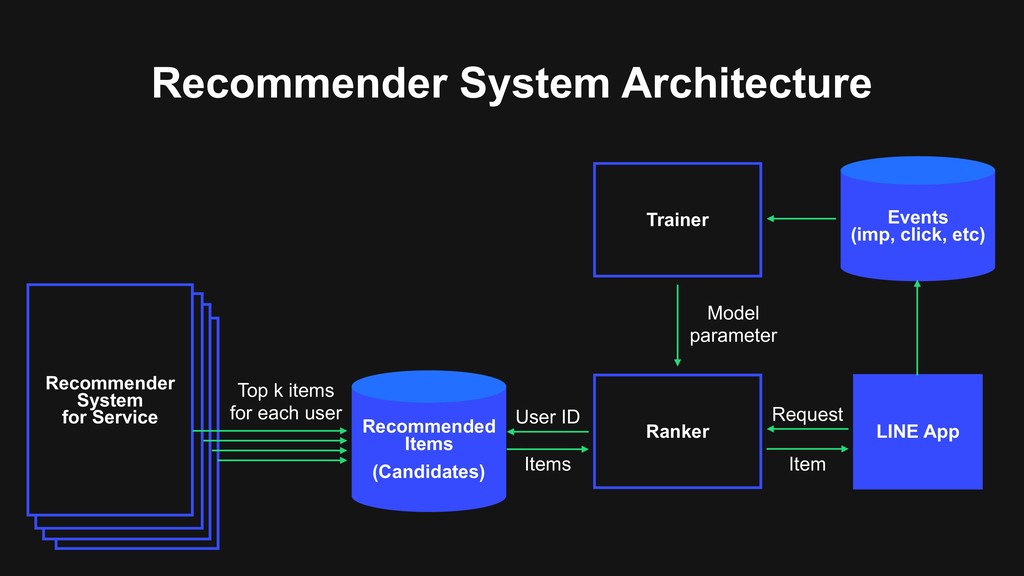
System for Service Recommender System for Service Recommender System for Service Recommended Items (Candidates) Ranker Trainer Events (imp, click, etc) LINE App User ID Items Model parameter Item Request Top k items for each user
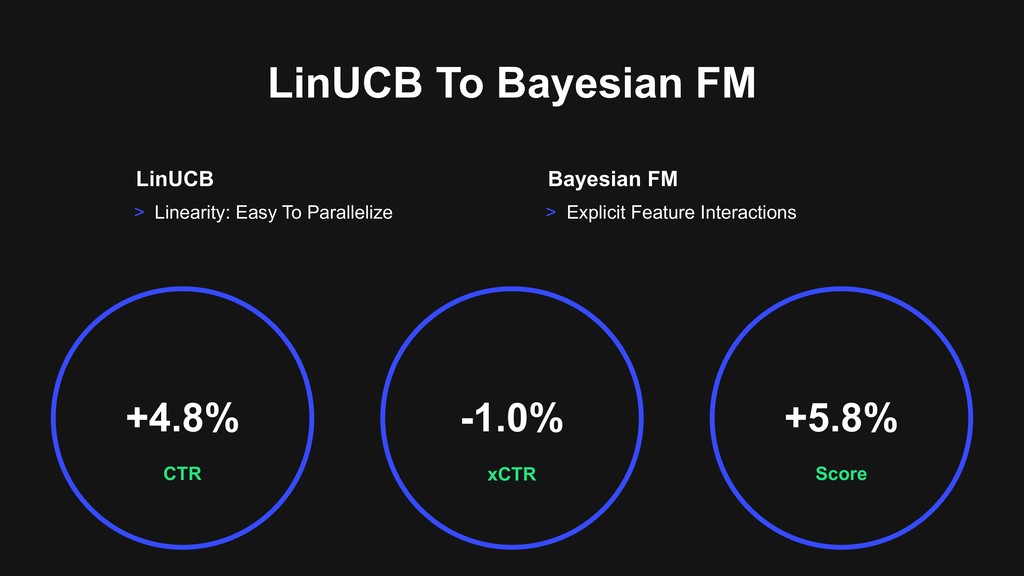
Expected Score 0.6 Current Expected Score 0.1 Current Expected Score Item B Item C Item D > Ranker chooses an item from candidates A, B, C … by using contextual bandits > Each expected score is computed by a prediction model corresponding to the item
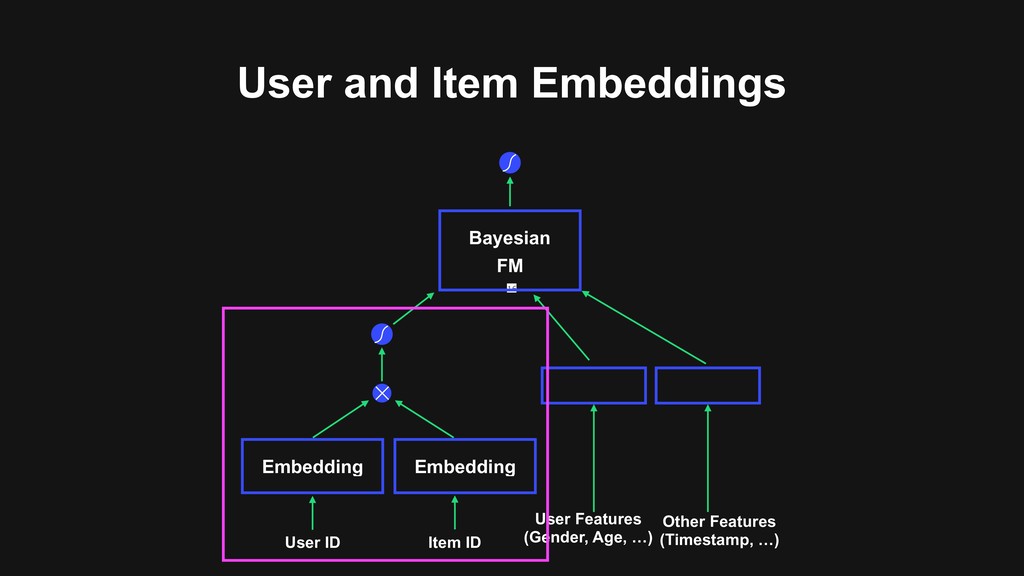
Balance Exploration-Exploitation Tradeoff > Laplace Approximation Bayesian Factorization Machine (FM) as an Arm of Contextual Bandits Output User ID Item ID User Features (Gender, Age, …) Other Features (Timestamp, …) Bayesian FM Embedding Embedding
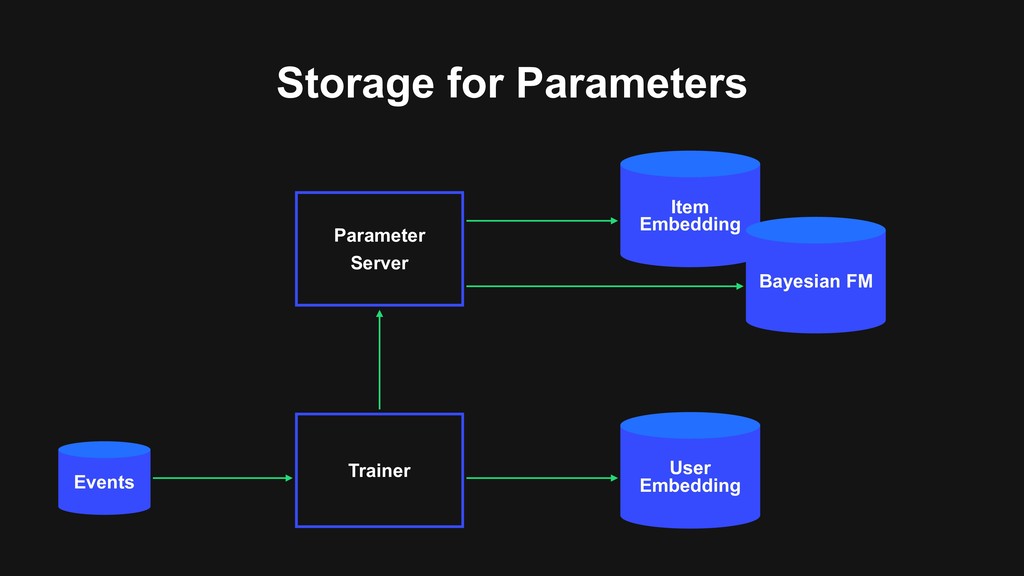
parameter server and trainers. In the situation, learning doesn't work well just by accumulating the gradient in the parameter server. Asynchronous Distributed Online Learning Deceleration Backtrack
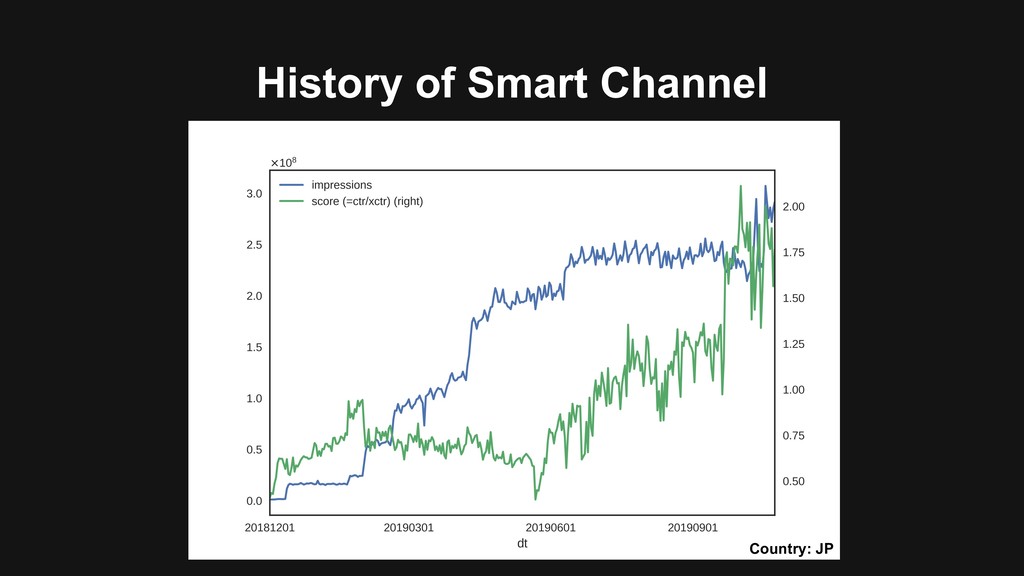
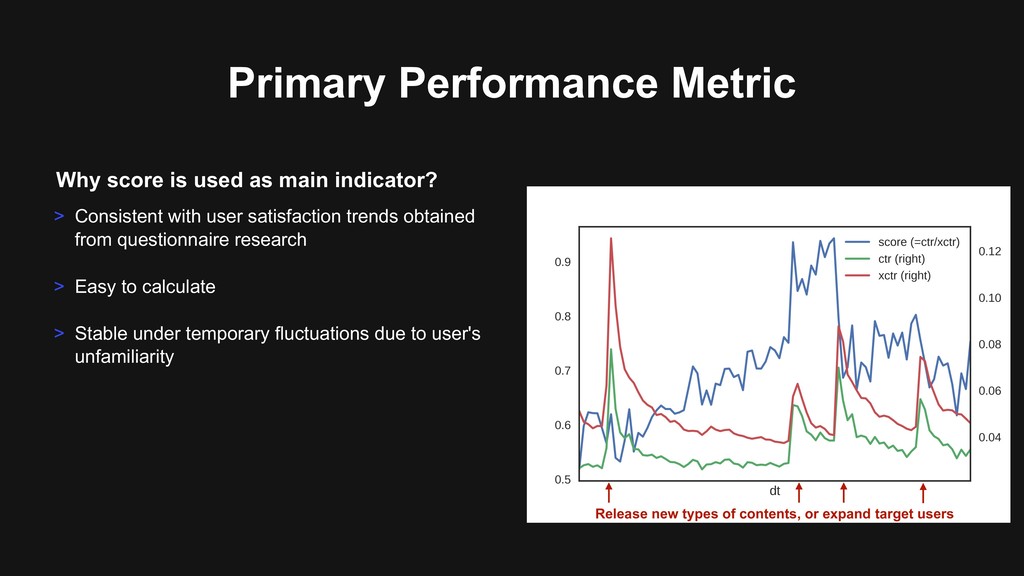
from questionnaire research > Easy to calculate > Stable under temporary fluctuations due to user's unfamiliarity Why score is used as main indicator? Release new types of contents, or expand target users
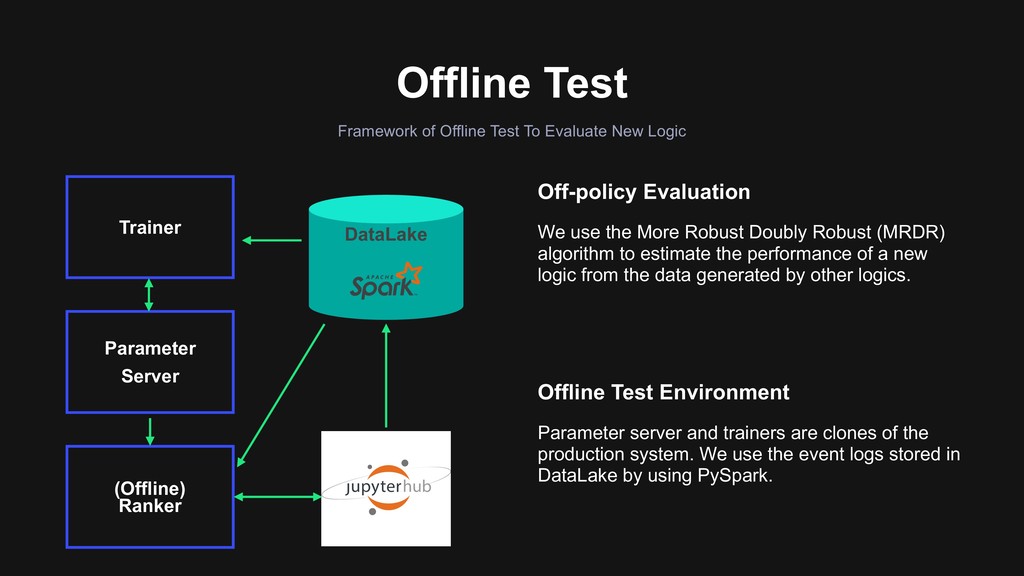
Robust (MRDR) algorithm to estimate the performance of a new logic from the data generated by other logics. Framework of Offline Test To Evaluate New Logic Offline Test Environment Parameter server and trainers are clones of the production system. We use the event logs stored in DataLake by using PySpark. Trainer Parameter Server (Offline) Ranker DataLake
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}