research topic in the area of statistics and data analytics that uses hashing, subsampling and noise injection to enable crowdsourced learning while keeping the data of individual users completely private.” On WWDC2016, Craig Federighi (Apple) said [2], › [1] C. Dwork. Differential privacy. ICALP, 2006. › [2] https://www.wired.com/2016/06/apples-differential-privacy-collecting-data/
will be protected using “differential privacy,” the new gold standard in data privacy protection. › [3] https://www.census.gov/about/policies/privacy/statistical_safeguards/disclosure-avoidance-2020-census.html
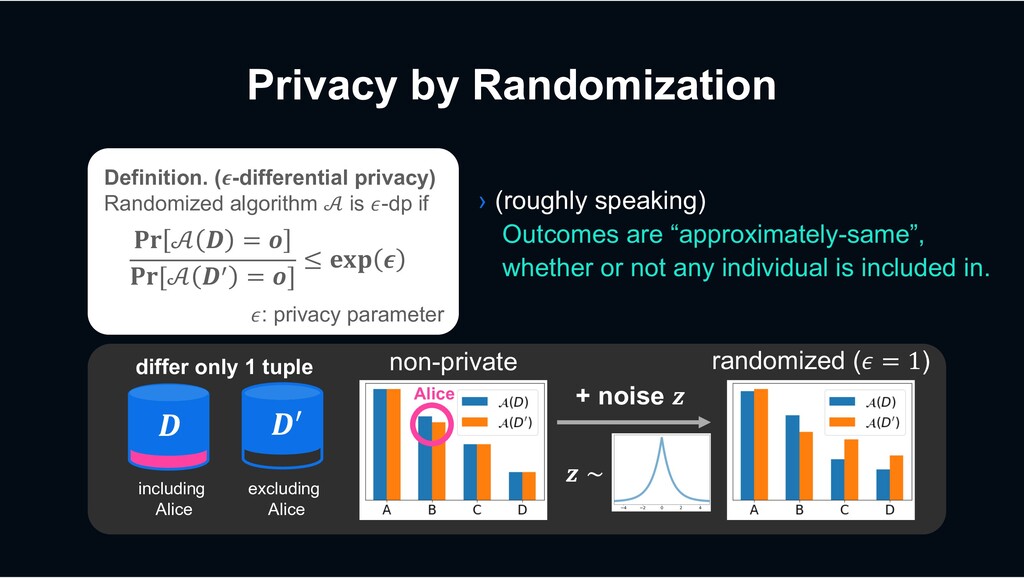
' #$[% !" = '] ≤ +,- . /: privacy parameter Definition. (.-differential privacy) Randomized algorithm % is /-dp if › (roughly speaking) Outcomes are “approximately-same”, whether or not any individual is included in. randomized (/ = 1) 1 ∼ + noise 1 including Alice excluding Alice Alice differ only 1 tuple
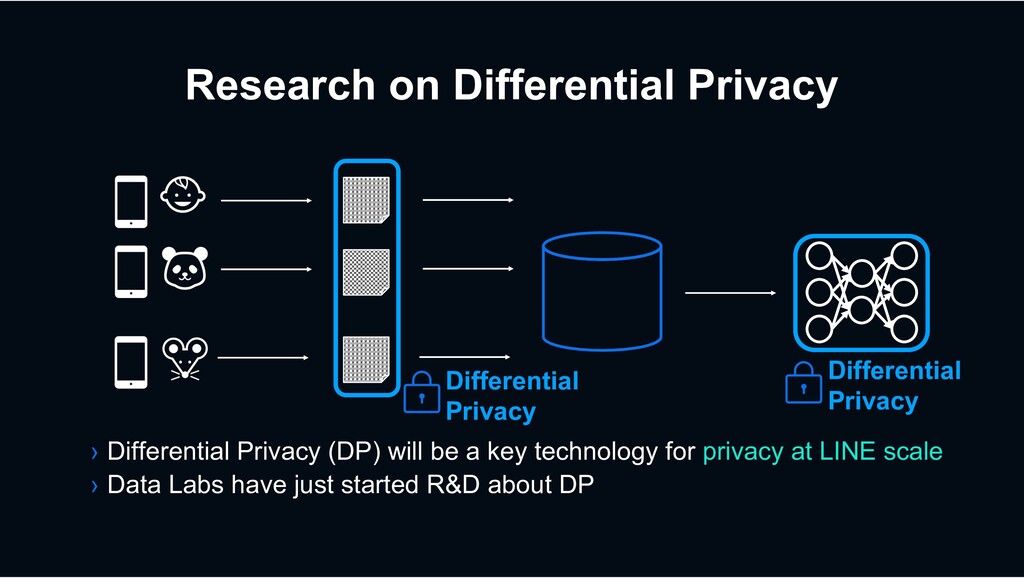
› With randomization mechanisms of differential privacy › For improving satisfactions of our services Deep Census of Our Users, that we have never reached, while preserving privacy Sharing Data, Stats, and AIs while preserving privacy › Knowledge circulation across our services › Share our insights with trusted partners › Make AIs robust against real (adversarial) environment
with injecting noise (DP-SGD [4] is well-known framework) › Model parameters satisfy differential privacy è parameters are sharable without privacy concerns › Use-case: Sharing ML models Learn Randomly & Respond as Usual Learn as Usual & Respond Randomly › Learn a model on a raw dataset › Introduce a random responding mechanism › Use-case: MLaaS (put a model on secure location and access via API) › [4] M. Abadi et al. Deep learning with differential privacy. ACM CCS, 2016.
Loss ℒ Compute Gradient ∇# ℒ Add Noise Update Params $ › DP-SGD makes a gradient differentially private, and hence model parameters are also dp. › Privacy consumption at an iteration is derived with % and & w. p. % = (/* * training samples noise scaler & › [4] M. Abadi et al. Deep learning with differential privacy. ACM CCS, 2016.
of gradient › Sensitivity: the maximal change of a function’s output when changing a sample in batch (or DB) › Ex. Counting: 1, Histogram: 2 Gradient’s sensitivity is intractable, thus CLIPPING! › DP-SGD employs clipping !" norm of the gradient by a constant # › Sample a noise from Gaussian whose variance is #$ " to craft a randomized gradient
Random Sampling ! training samples ̅ #$ = #$ +'$ ̅ #( = #( +'( ̅ #) = #) +') Privacy Accounting *$ *$ *( *$ *( *+ *),$ *) … noise '- is sampled from the Gaussian whose mean = 0 and var = ./ ( learning process is stopped when the privacy budget is exhausted … … … This illustration is the simplest accounting way.
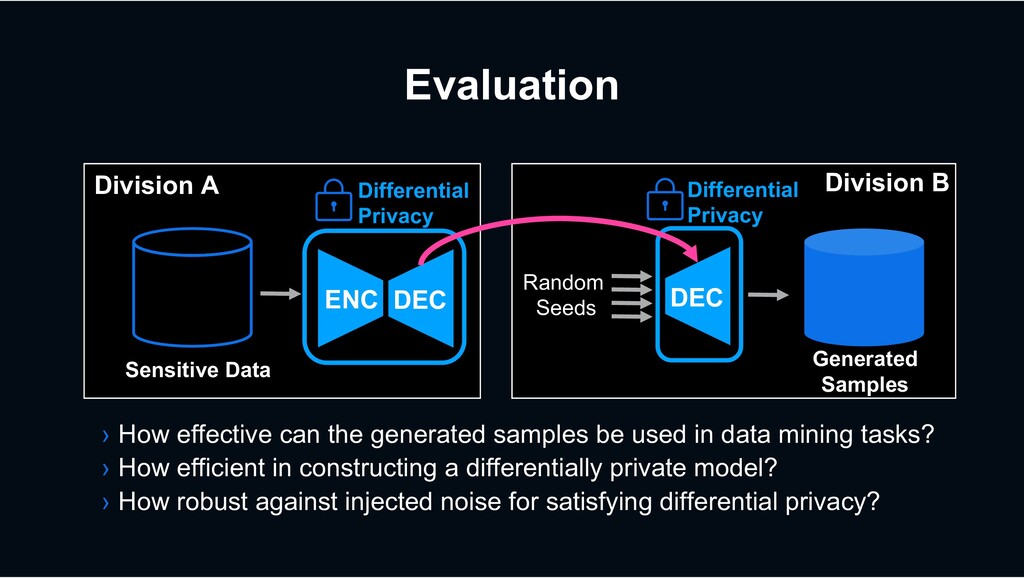
Division B Synthesized Data › We have developed differentially private deep generative models for sharing sensitive data while preserving privacy of individuals Differential Privacy Differential Privacy Generative model
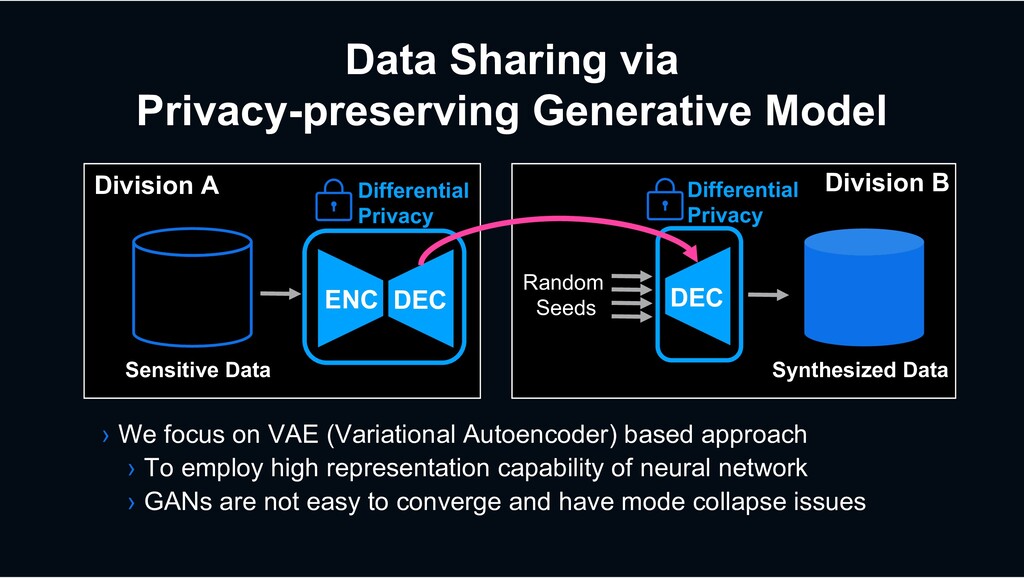
Division B Synthesized Data › We focus on VAE (Variational Autoencoder) based approach › To employ high representation capability of neural network › GANs are not easy to converge and have mode collapse issues Differential Privacy Differential Privacy ENC DEC DEC Random Seeds
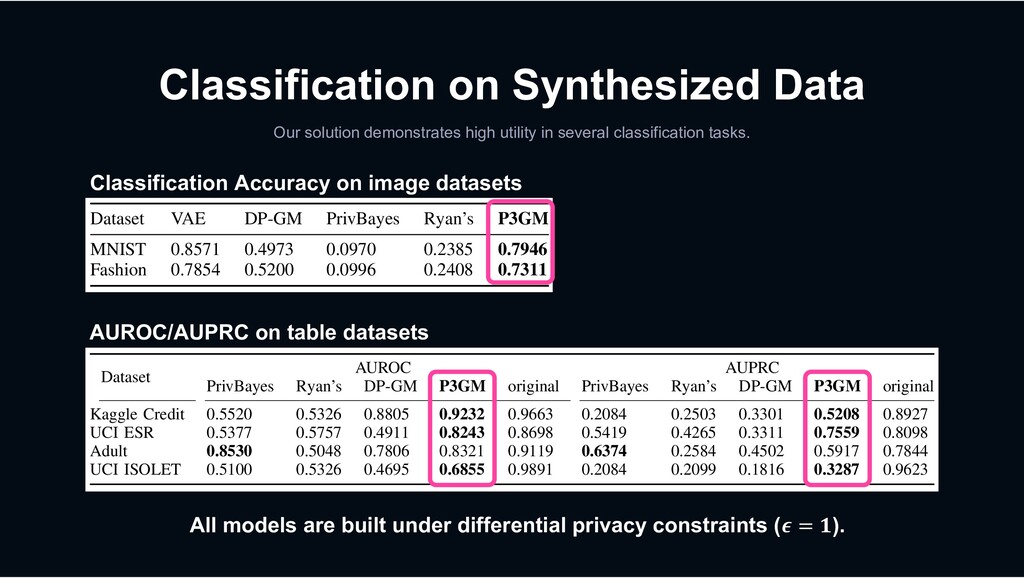
are built under differential privacy constraints (! = #). › [5] G. Acs et al. Differentially private mixture of generative neural networks. TKDE, 2018.
makes it difficult to learn multiple tasks simultaneously (i.e., both encoding and decoding in end-to-end) › Required to be converged by small epochs due to privacy budget
difficult to learn multiple tasks simultaneously (i.e., both encoding and decoding in end-to-end) OUR SOLUTION: Simplified Two-Phase Algorithm › Required to converge small epochs due to privacy consumptions
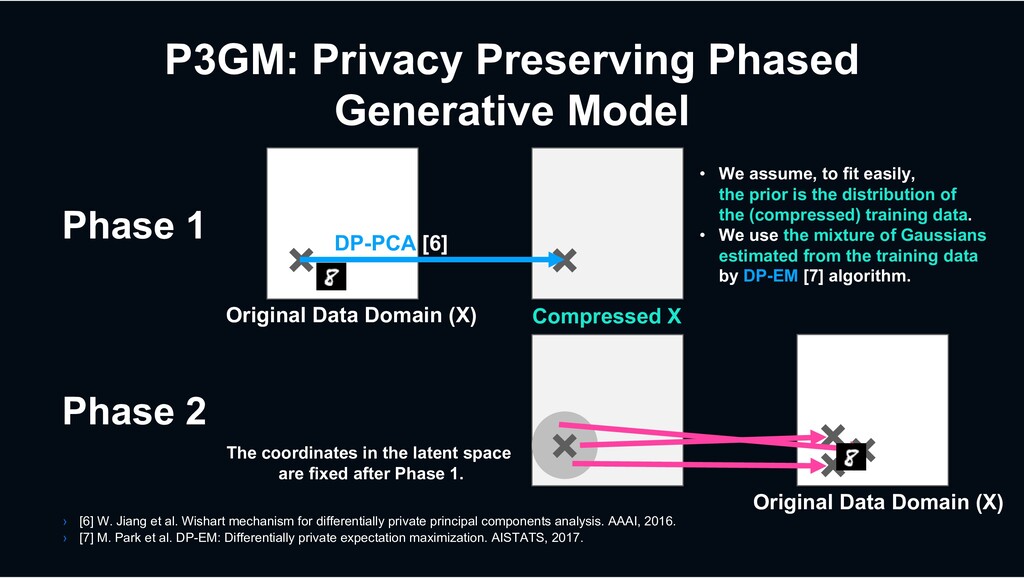
(X) • We assume, to fit easily, the prior is the distribution of the (compressed) training data. • We use the mixture of Gaussians estimated from the training data by DP-EM [7] algorithm. × DP-PCA [6] × × × × Original Data Domain (X) Compressed X Phase 1 Phase 2 The coordinates in the latent space are fixed after Phase 1. › [6] W. Jiang et al. Wishart mechanism for differentially private principal components analysis. AAAI, 2016. › [7] M. Park et al. DP-EM: Differentially private expectation maximization. AISTATS, 2017.
How effective can the generated samples be used in data mining tasks? › How efficient in constructing a differentially private model? › How robust against injected noise for satisfying differential privacy? Differential Privacy Differential Privacy ENC DEC DEC Random Seeds
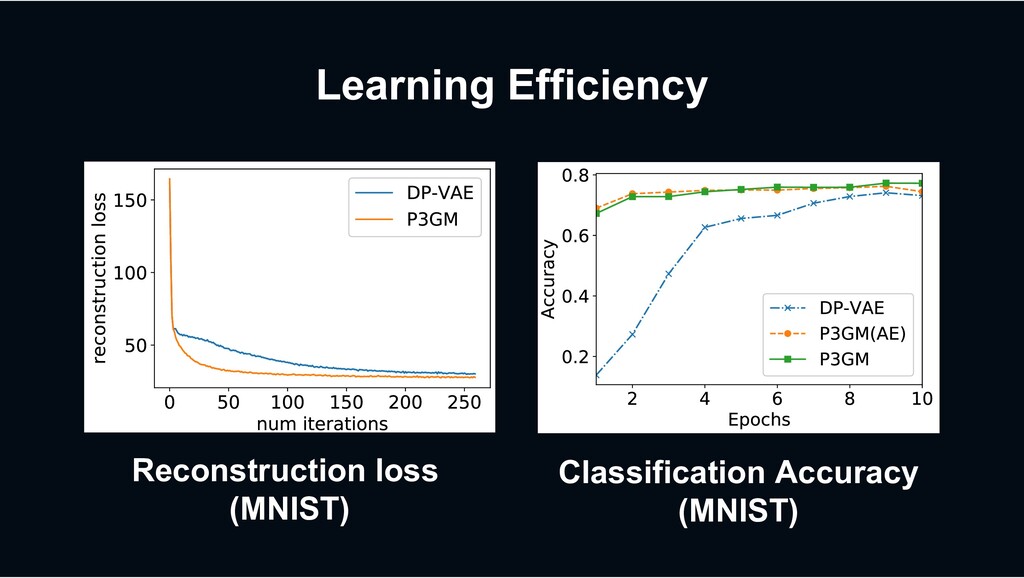
accuracy (MNIST). (d strates higher learning efficiency than DP-VAE. More simple model increases m (a) Reconstruction loss (MNIST). (b) Reconstruction loss (Kaggle Credit) (c) Cl Fig. 7: P3GM demonstrates higher learning efficiency than DP-VAE. Reconstruction loss (MNIST) Classification Accuracy (MNIST)
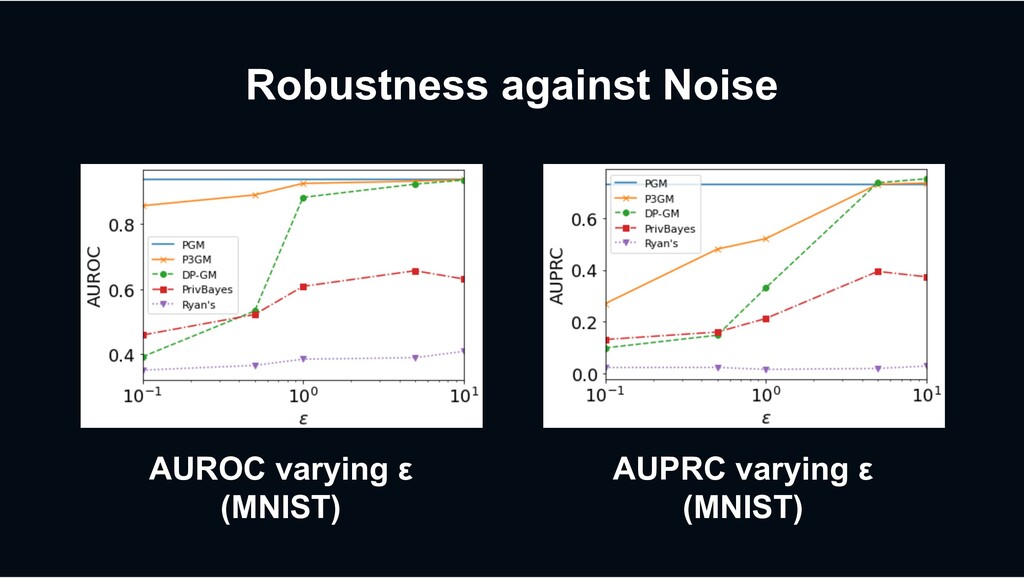
0.0996 (a) AUROC Fig. 4: Utility in fraud detectio 3 0.0970 0.2385 0.7946 0 0.0996 0.2408 0.7311 (b) AUPRC ud detection (Kaggle Credit). Fig. 5: Reducing dimension improves accuracy (MNIST). Fig. 6: O high-dim Too much small dimensionality lacks for embedding. From the result, d p = [ solution with balancing the accuracy an reduction on the MNIST dataset. B. Learning Efficiency AUROC varying ε (MNIST) AUPRC varying ε (MNIST)
injections by simple two-phased learning algorithm › Outperform existing methods in terms of utility of synthesized data › Our paper and code is public on arXiv and GitHub, respectively. › [Paper] https://arxiv.org/abs/2006.12101 › [Code] https://github.com/tsubasat/P3GM Introduced research achievements about Differentially Private Generative Model Differential Privacy is “Privacy by Randomization” and “Privacy at Scale” › Differential privacy has been utilized for gathering stats and sharing ML outcomes › DP-SGD is a standard framework to make a machine learning differentially private
[2] https://www.wired.com/2016/06/apples-differential-privacy-collecting-data/ › [3] https://www.census.gov/about/policies/privacy/statistical_safeguards/disclosure-avoidance- 2020-census.html › [4] M. Abadi et al. Deep learning with differential privacy. ACM CCS, 2016. › [5] G. Acs et al. Differentially private mixture of generative neural networks. TKDE, 2018. › [6] W. Jiang et al. Wishart mechanism for differentially private principal components analysis. AAAI, 2016. › [7] M. Park et al. DP-EM: Differentially private expectation maximization. AISTATS, 2017.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![What is Differential Privacy [1] ? “Differential privacy is a](https://files.speakerdeck.com/presentations/184bf7a9e78543e5a60fc051df192492/slide_4.jpg){kind=link}
![Disclosure Avoidance in US Census 2020 [3] 2020 Census results](https://files.speakerdeck.com/presentations/184bf7a9e78543e5a60fc051df192492/slide_5.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![DP-SGD [4] Differentially Private Stochastic Gradient Descent Random Sampling Compute](https://files.speakerdeck.com/presentations/184bf7a9e78543e5a60fc051df192492/slide_13.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Preview: Synthesized Data MNIST VAE+DP-SGD DP-GM [5] Ours All models](https://files.speakerdeck.com/presentations/184bf7a9e78543e5a60fc051df192492/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![References › [1] C. Dwork. Differential privacy. ICALP, 2006. ›](https://files.speakerdeck.com/presentations/184bf7a9e78543e5a60fc051df192492/slide_30.jpg){kind=link}
{kind=link}