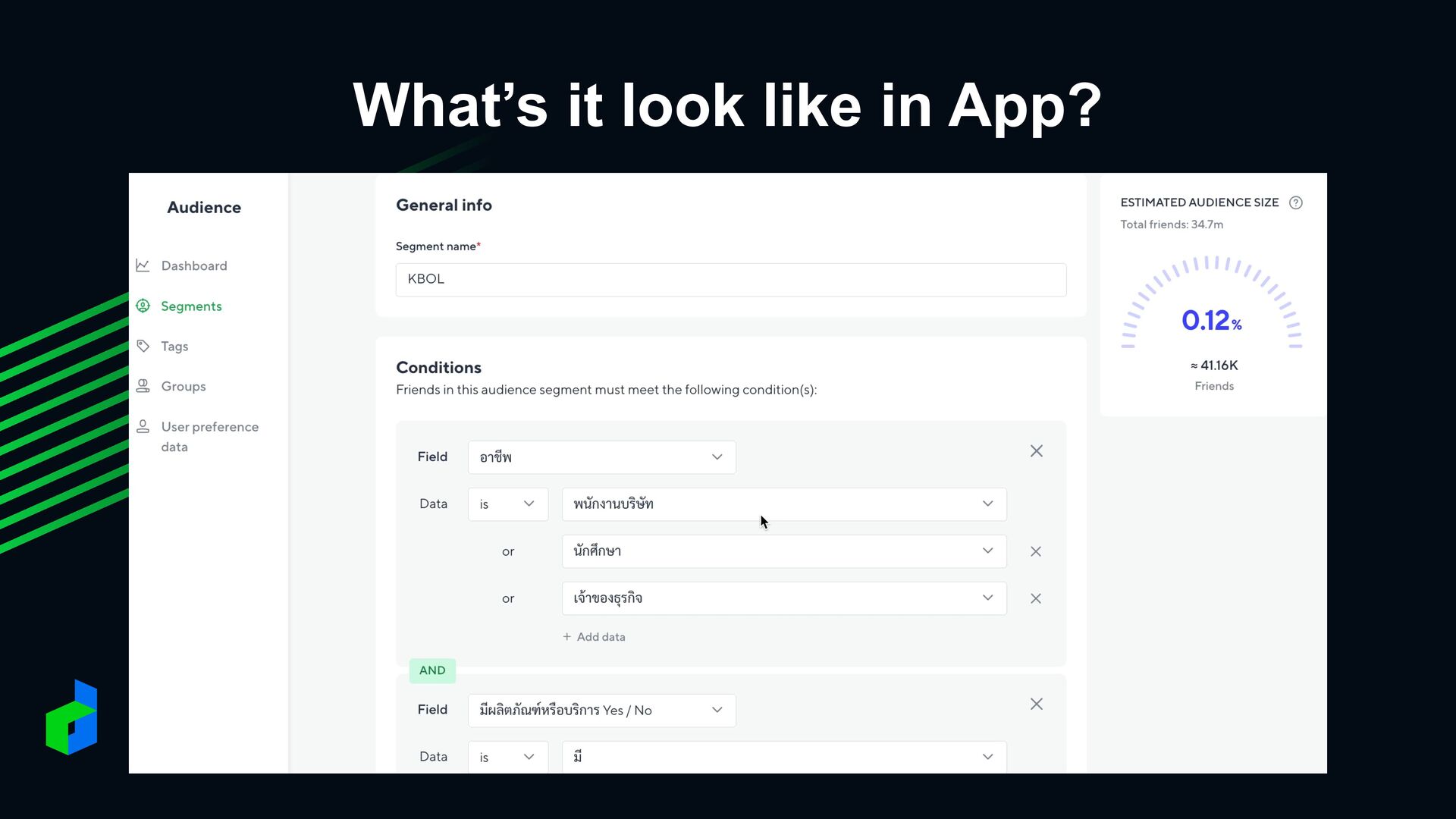
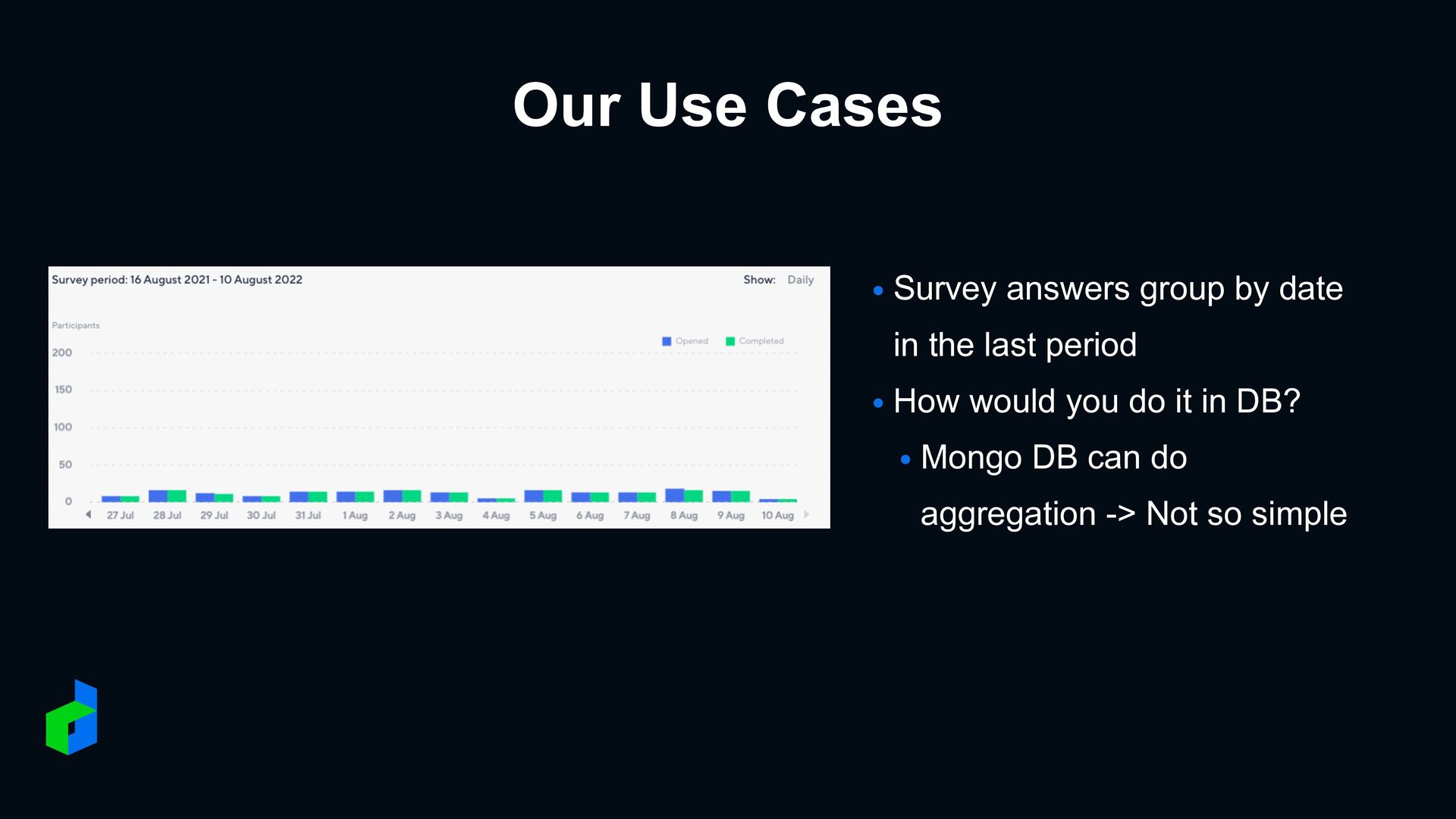
Chat messages • Tags, Groups • Data size (Billion+ rows) • Aggregate in real-time • i.e. How many users are in this tag and answer this survey? Problem Statement
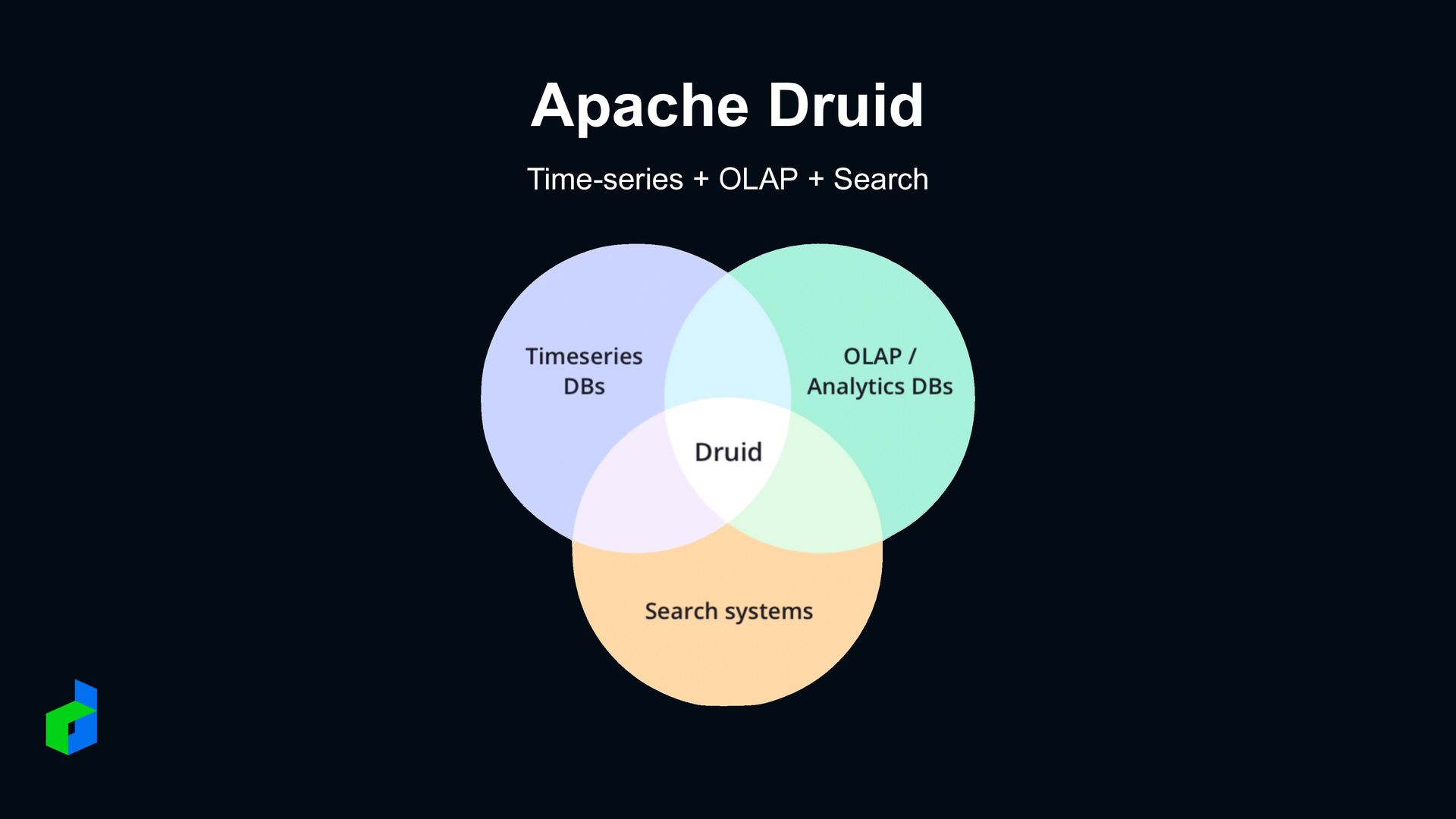
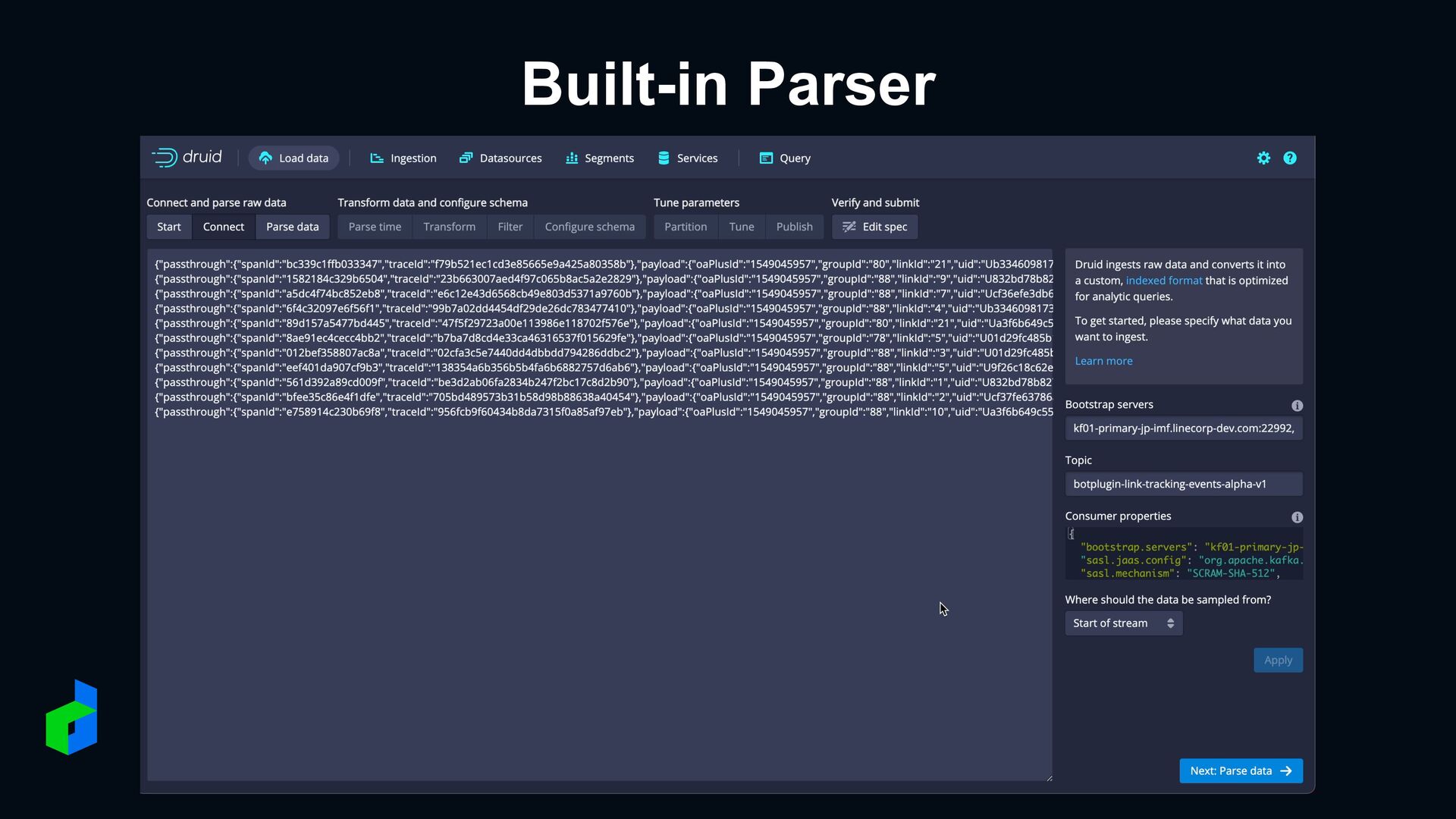
designed for fast slice-and-dice analytics on large data sets • Druid is most used where real-time ingest, fast query performance, and high uptime are important • Druid is commonly used for powering GUIs of analytical applications, or as a backend for highly- concurrent APIs that need fast aggregations. Druid works best with event-oriented data.
Indexing with bitmap indexes • Compression • Dictionary encoding with id storage minimization for String columns • Bitmap compression for bitmap indexes • Type-aware compression for all columns
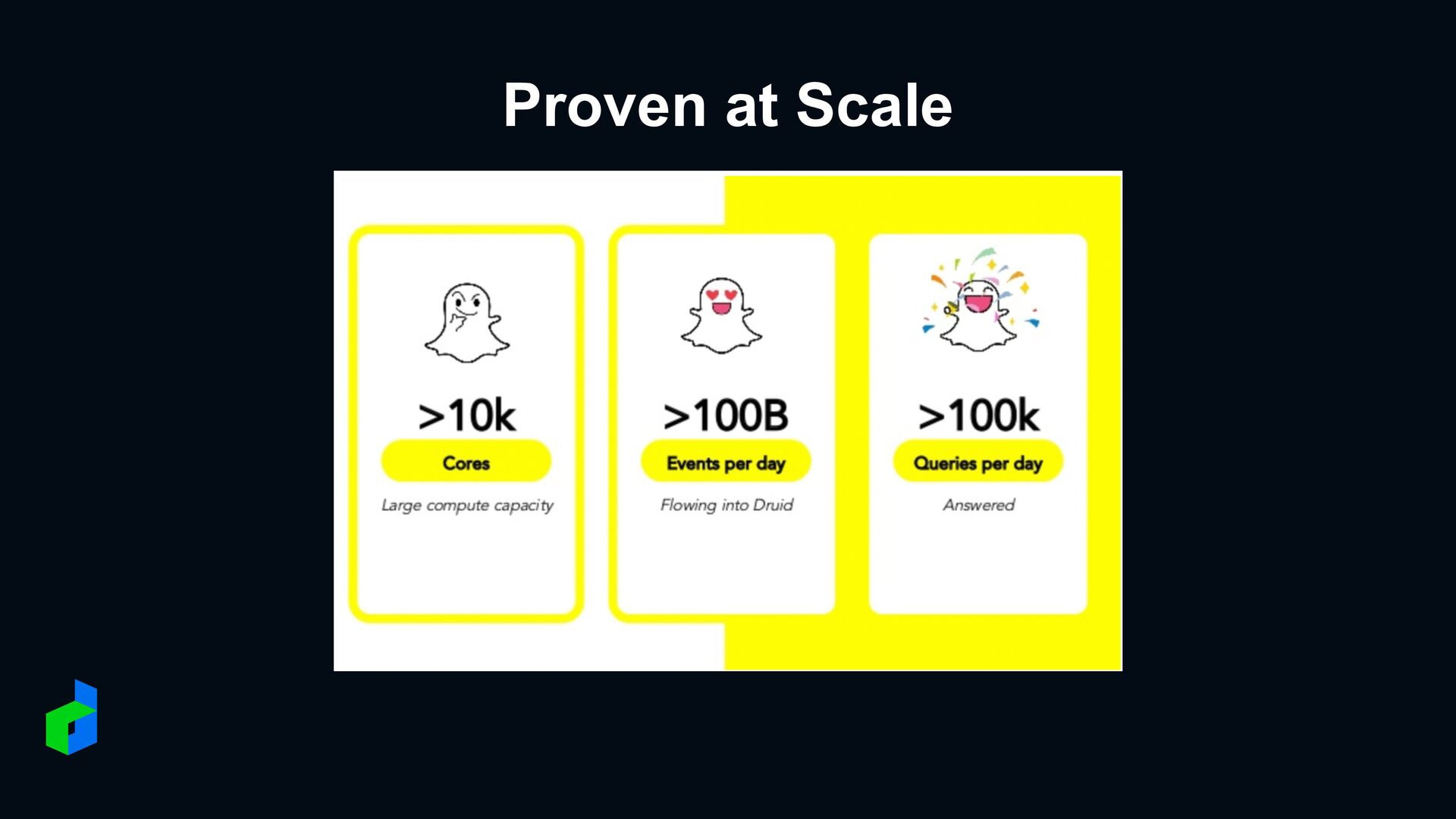
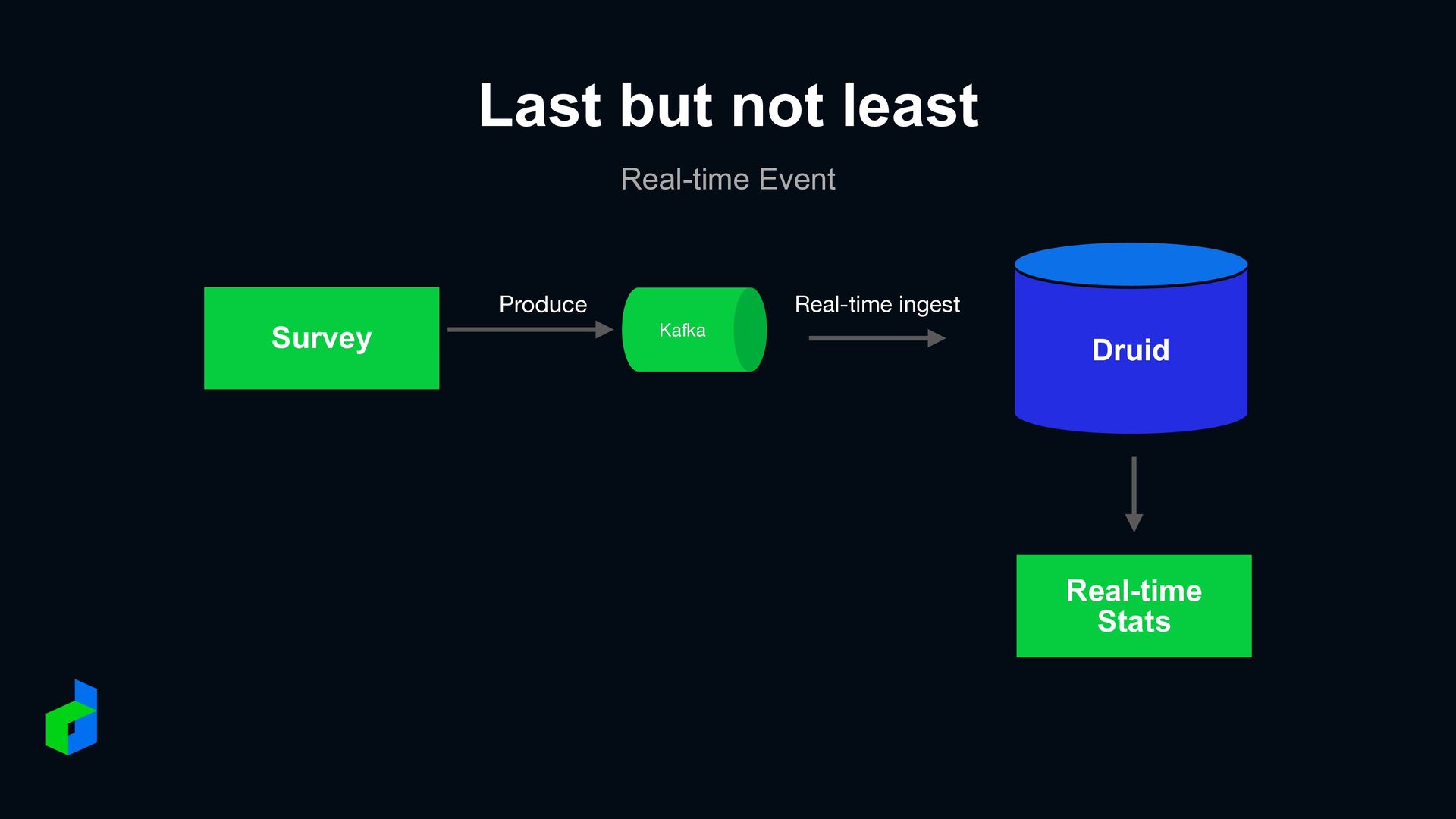
in database • Sub-second query aggregation on millions+ set • Do aggregation with Theta Sketch estimate • Get data from Hadoop HDFS • Real-time data from Apache Kafka
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}