List DFG Research Fellow Centre des recherches linguistiques sur l’Asie Orientale Team Adaptation, Integration, Reticulation, Evolution EHESS and UPMC, Paris 2016/12/01 1 / 38
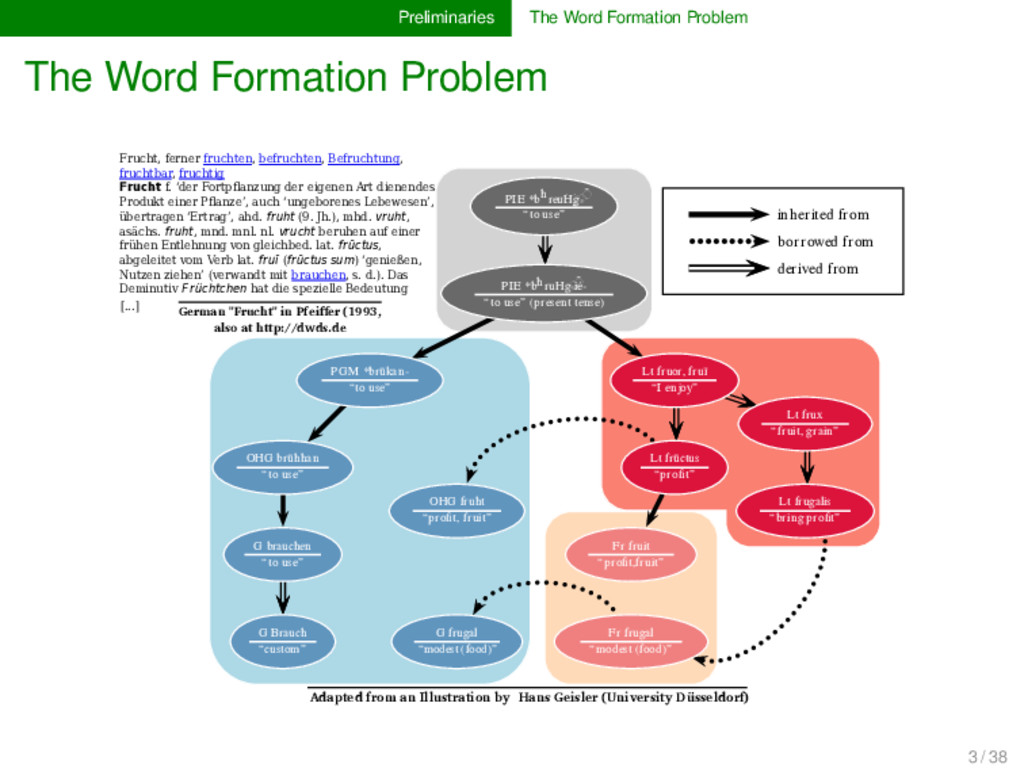
ferner fruchten, befruchten, Befruchtung, fruchtbar, fruchtig Frucht f. ‘der Fortpflanzung der eigenen Art dienendes Produkt einer Pflanze’, auch ‘ungeborenes Lebewesen’, übertragen ‘Ertrag’, ahd. fruht (9. Jh.), mhd. vruht, asächs. fruht, mnd. mnl. nl. vrucht beruhen auf einer frühen Entlehnung von gleichbed. lat. frūctus, abgeleitet vom Verb lat. fruī (frūctus sum) ‘genießen, Nutzen ziehen’ (verwandt mit brauchen, s. d.). Das Deminutiv Früchtchen hat die spezielle Bedeutung [...] German "Frucht" in Pfei�er (1993, also at http://dwds.de) 3 / 38
ferner fruchten, befruchten, Befruchtung, fruchtbar, fruchtig Frucht f. ‘der Fortpflanzung der eigenen Art dienendes Produkt einer Pflanze’, auch ‘ungeborenes Lebewesen’, übertragen ‘Ertrag’, ahd. fruht (9. Jh.), mhd. vruht, asächs. fruht, mnd. mnl. nl. vrucht beruhen auf einer frühen Entlehnung von gleichbed. lat. frūctus, abgeleitet vom Verb lat. fruī (frūctus sum) ‘genießen, Nutzen ziehen’ (verwandt mit brauchen, s. d.). Das Deminutiv Früchtchen hat die spezielle Bedeutung [...] German "Frucht" in Pfei�er (1993, also at http://dwds.de 3 / 38
ferner fruchten, befruchten, Befruchtung, fruchtbar, fruchtig Frucht f. ‘der Fortpflanzung der eigenen Art dienendes Produkt einer Pflanze’, auch ‘ungeborenes Lebewesen’, übertragen ‘Ertrag’, ahd. fruht (9. Jh.), mhd. vruht, asächs. fruht, mnd. mnl. nl. vrucht beruhen auf einer frühen Entlehnung von gleichbed. lat. frūctus, abgeleitet vom Verb lat. fruī (frūctus sum) ‘genießen, Nutzen ziehen’ (verwandt mit brauchen, s. d.). Das Deminutiv Früchtchen hat die spezielle Bedeutung [...] inherited from borrowed from derived from PIE *bhreu◌◌̯ Hg◌ ◌ ̑ - “to use” PIE *bhruHg◌ ◌ ̑ -ié- “to use” (present tense) PGM *ƀrūkan- “to use” OHG brūhhan “to use” G brauchen “to use” G Brauch “custom” OHG fruht “profit, fruit” G frugal “modest (food)” Fr fruit “profit,fruit” Fr frugal “modest (food)” Lt fruor, fruī “I enjoy” Lt frūctus “profit” Lt frux “fruit, grain” Lt frugalis “bring profit” Adapted from an Illustration by Hans Geisler (University Düsseldorf) German "Frucht" in Pfei�er (1993, also at http://dwds.de 3 / 38
etymological dictionaries provide us with very detailed scenarios on processes in lan- guage change, including processes of inheri- tance, contact, and word formation, they present the knowledge in a prosaic fashion that resists quantification and makes it also very difficult to comprehend, especially for those who are not experts in the given language family. 3 / 38
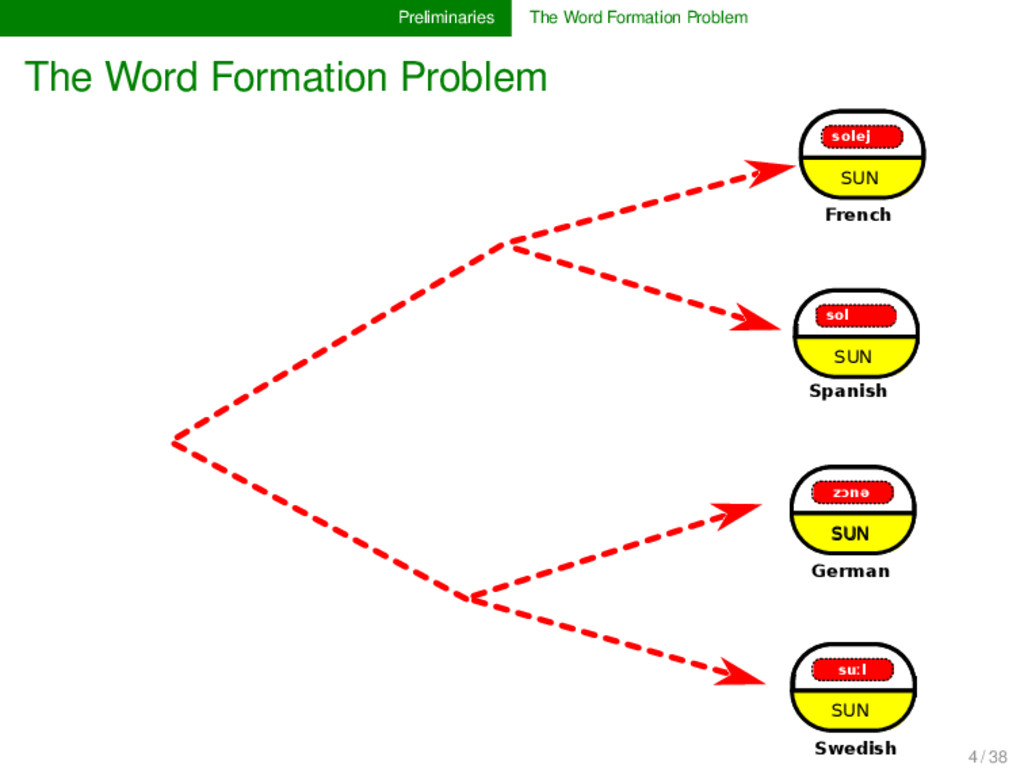
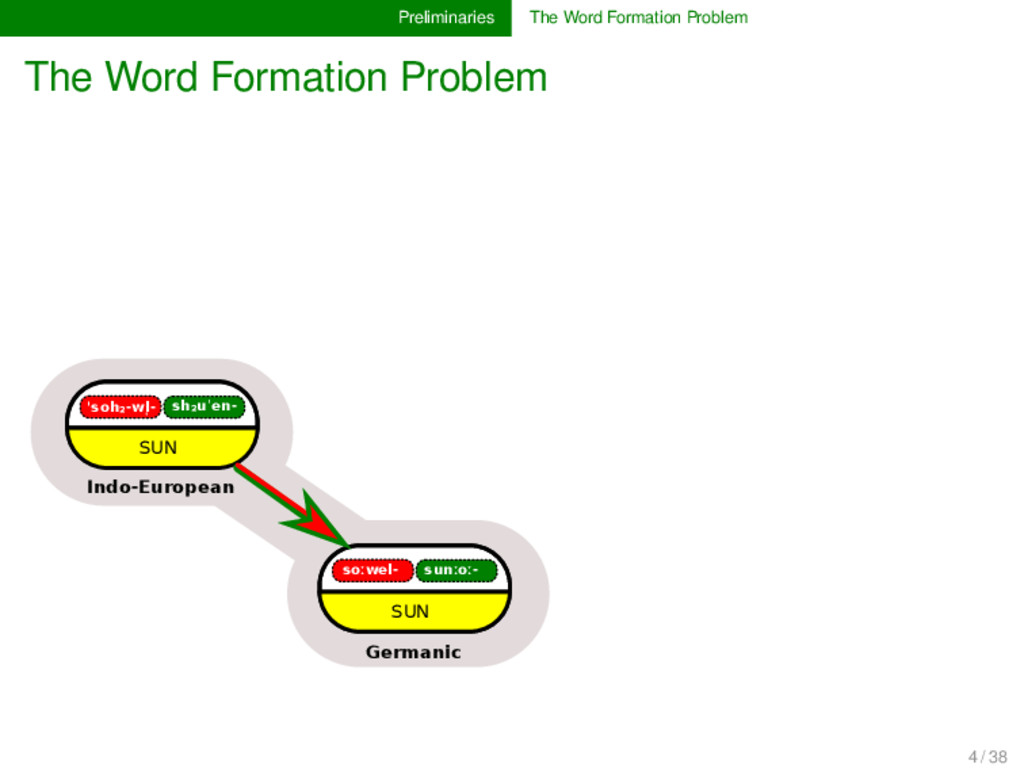
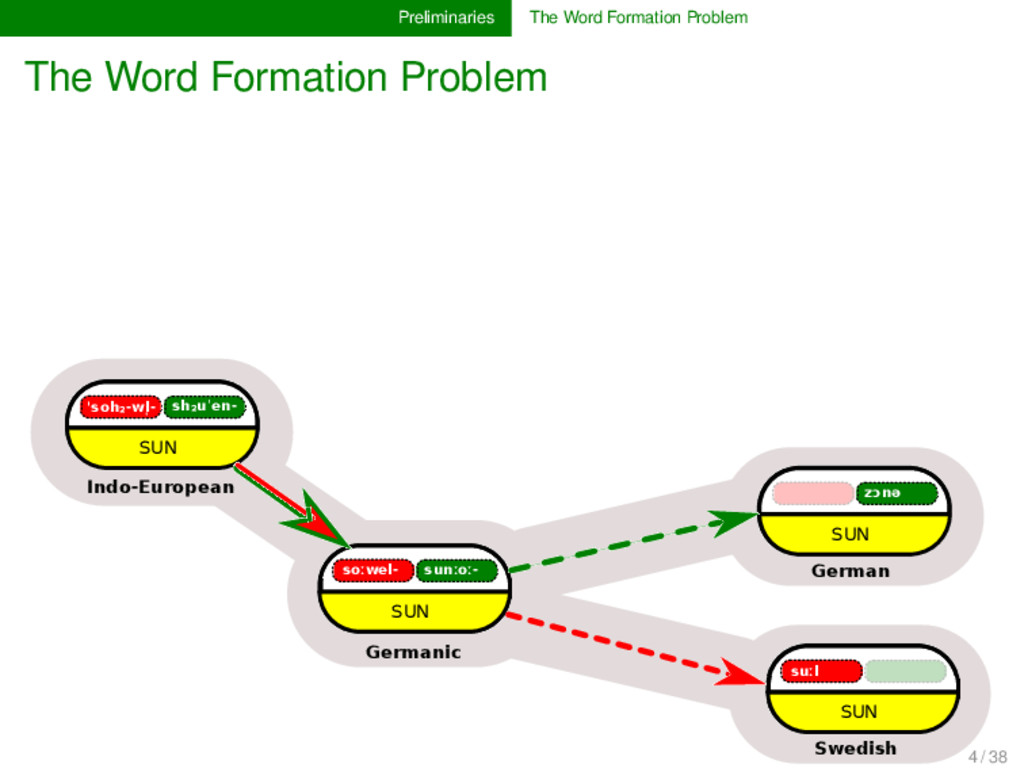
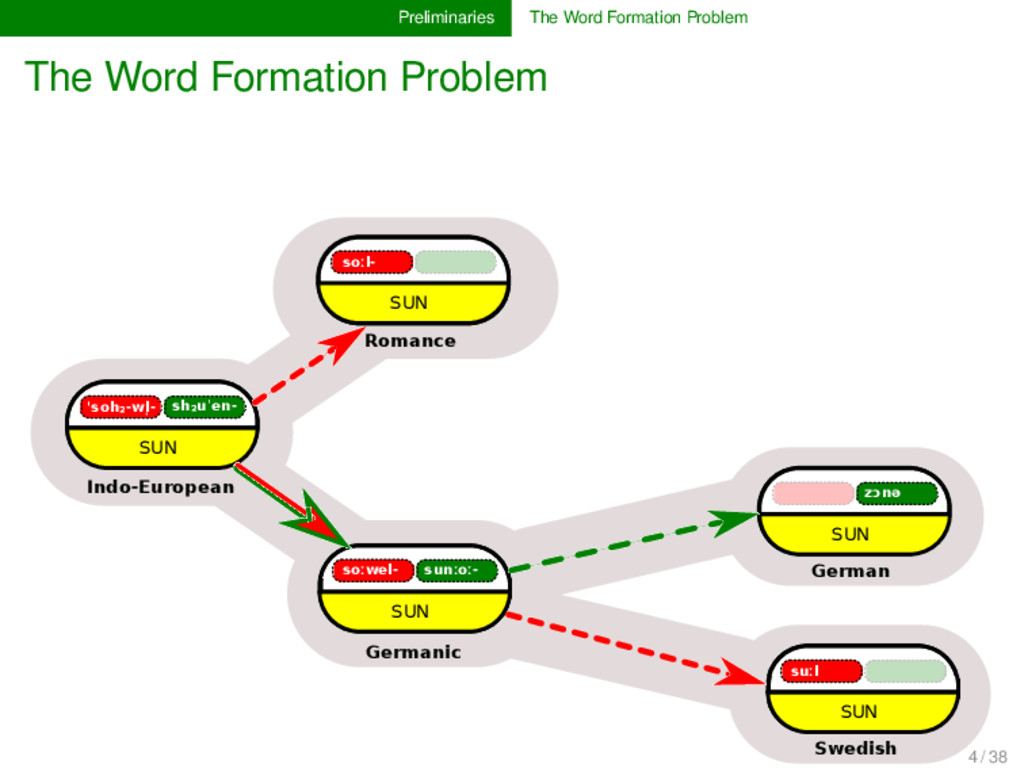
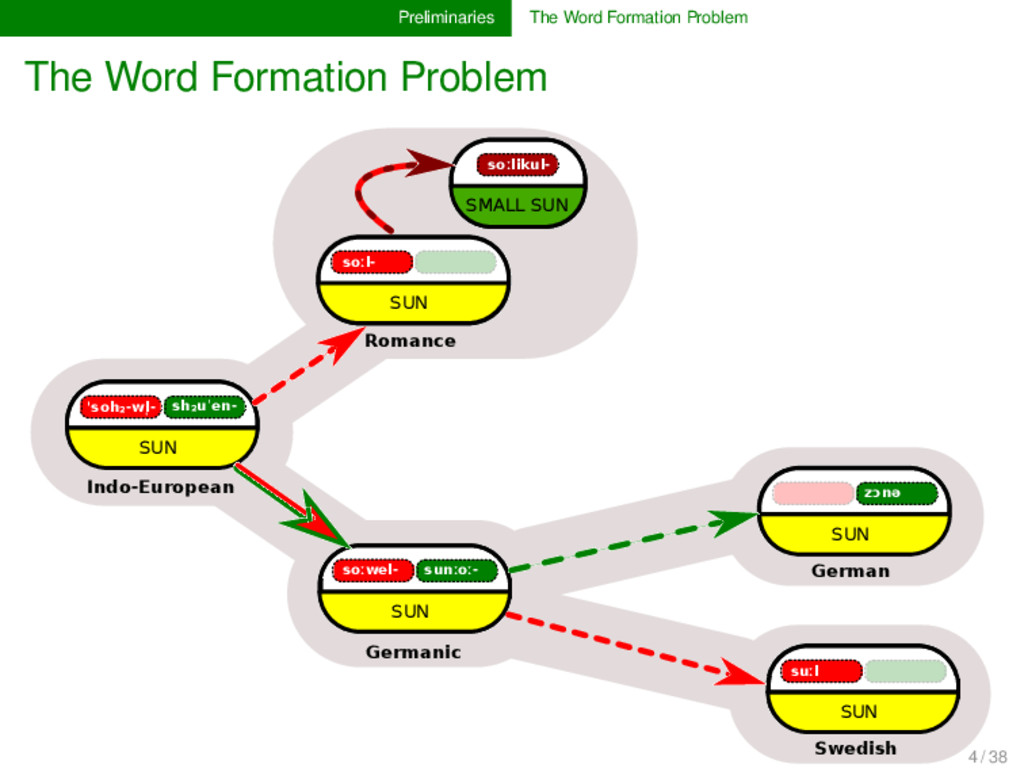
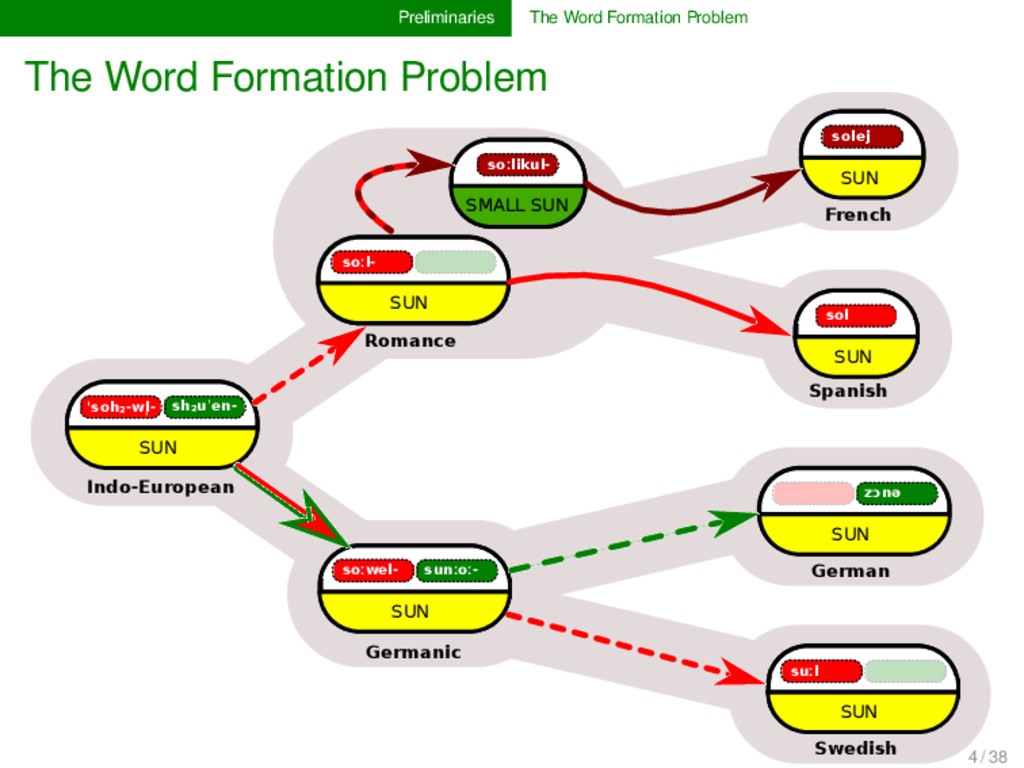
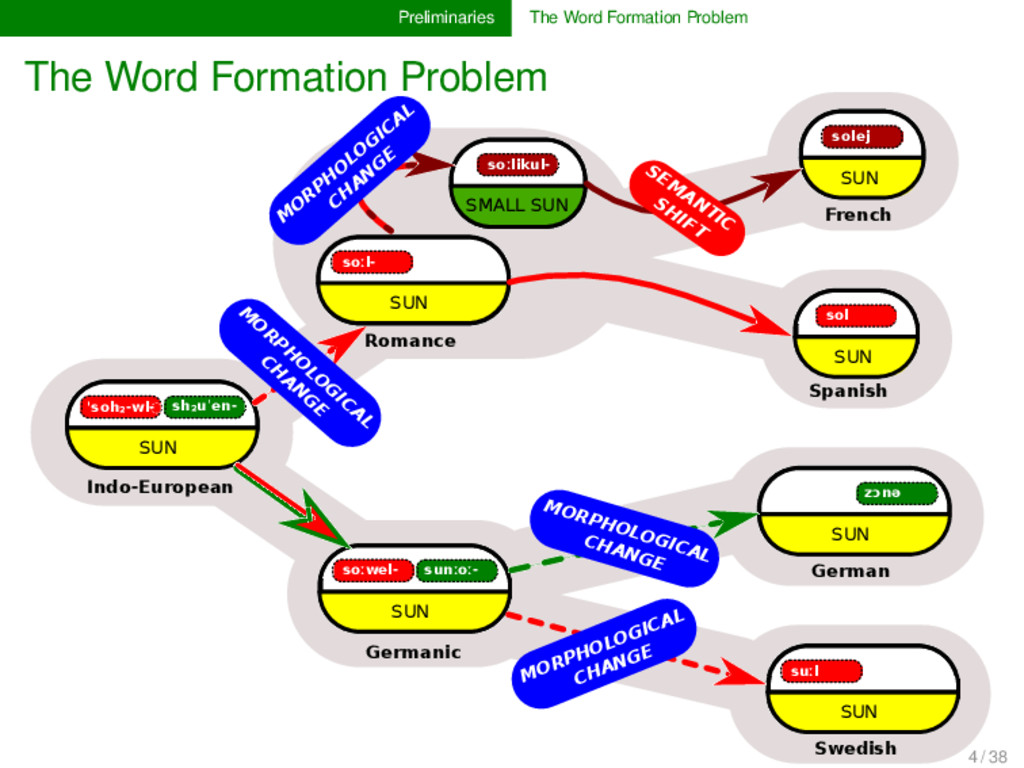
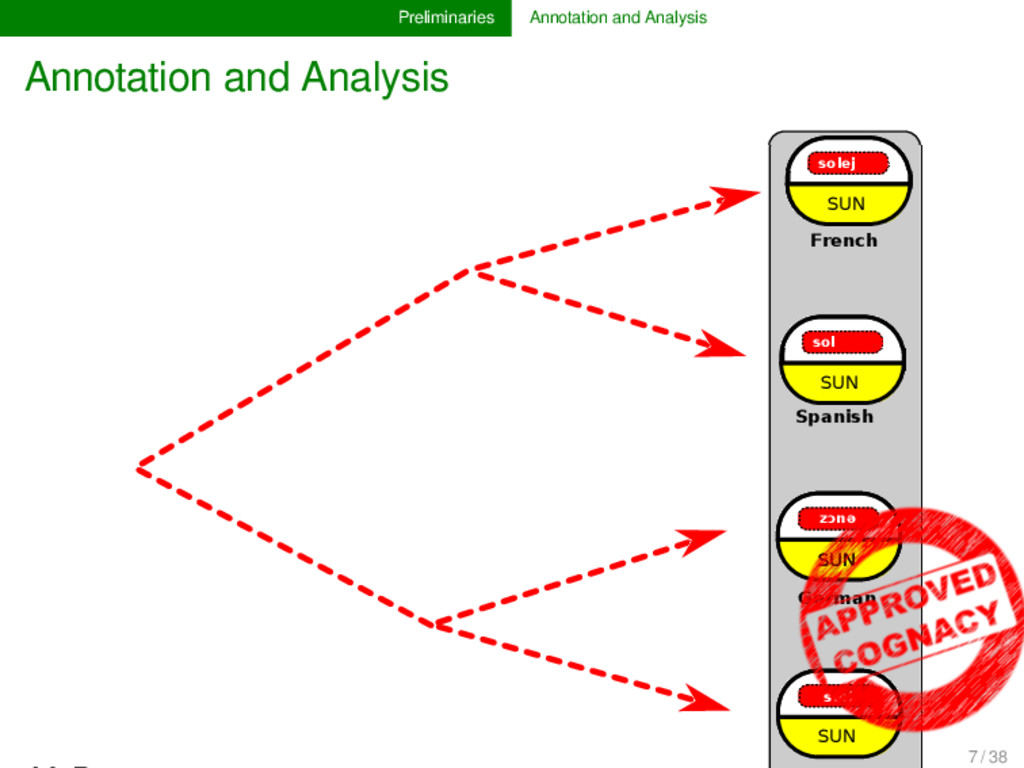
sh₂uˈen- SUN Indo-European soːwel- sunːoː- SUN Germanic soːl- SUN soːlikul- SMALL SUN Romance solej SUN French sol SUN Spanish zɔnə SUN German suːl SUN Swedish 4 / 38
- sh₂uˈen- SUN Indo-European soːwel- sunːoː- SUN Germanic soːl- SUN soːlikul- SMALL SUN Romance solej SUN French sol SUN Spanish zɔnə SUN German suːl SUN Swedish SEM ANTIC SHIFT M O RPH O LO G ICAL CH AN G E M O R PH O LO G ICA L CH A N G E MORPHOLOGICAL CHANGE MORPHOLOGICAL CHANGE 4 / 38
we find a way to increase the consis- tency of classical etymological accounts and the complexity of computational approaches to han- dle word formation processes in comparative- historical linguistics in a more reliable and more transparent way? 5 / 38
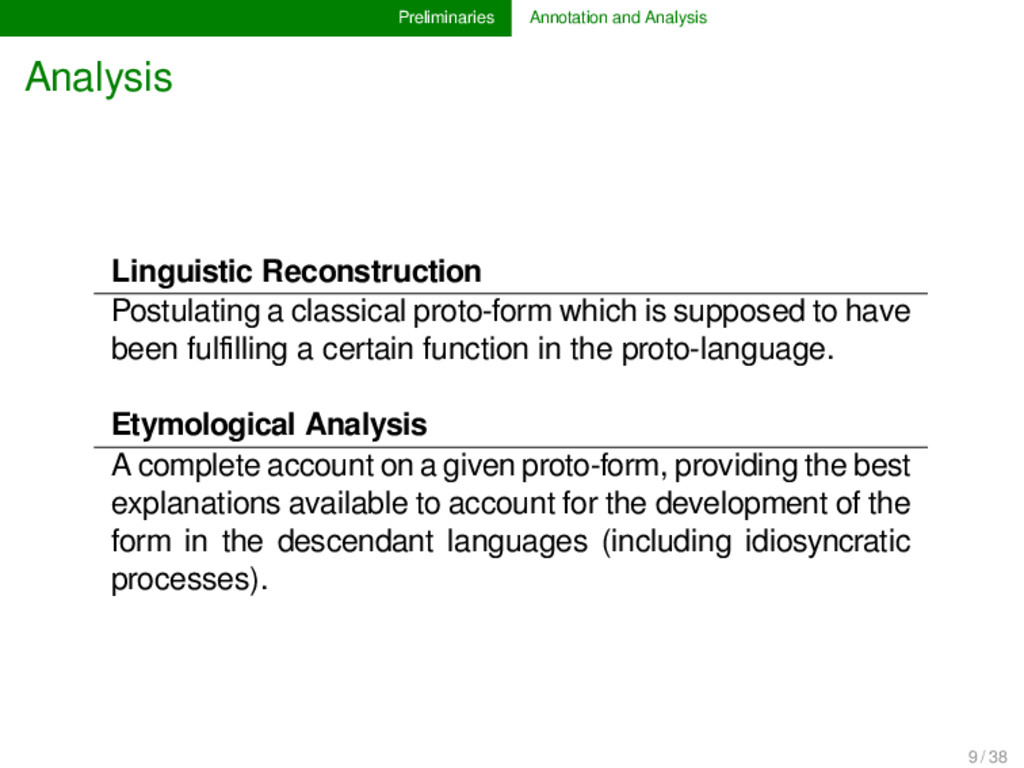
step in linguistic reconstruction, during which we assemble our evidence and identify related words and mor- phemes in and outside languages. Analysis The second, crucial step of linguistic reconstruction, dur- ing which we present our hypotheses in form of historical scenarios that explain how the relations that we annotated evolved into their current shape. 6 / 38
of annotation in which we only state which relations hold between the entities we analyse and does not make specific assumptions regarding the historical pro- cesses which they result from. Etymological Annotation An interpretive step in the annotation in which certain parts of the reconstruction are already carried out and certain basic processes are postulated. 8 / 38
proto-form which is supposed to have been fulfilling a certain function in the proto-language. Etymological Analysis A complete account on a given proto-form, providing the best explanations available to account for the development of the form in the descendant languages (including idiosyncratic processes). 9 / 38
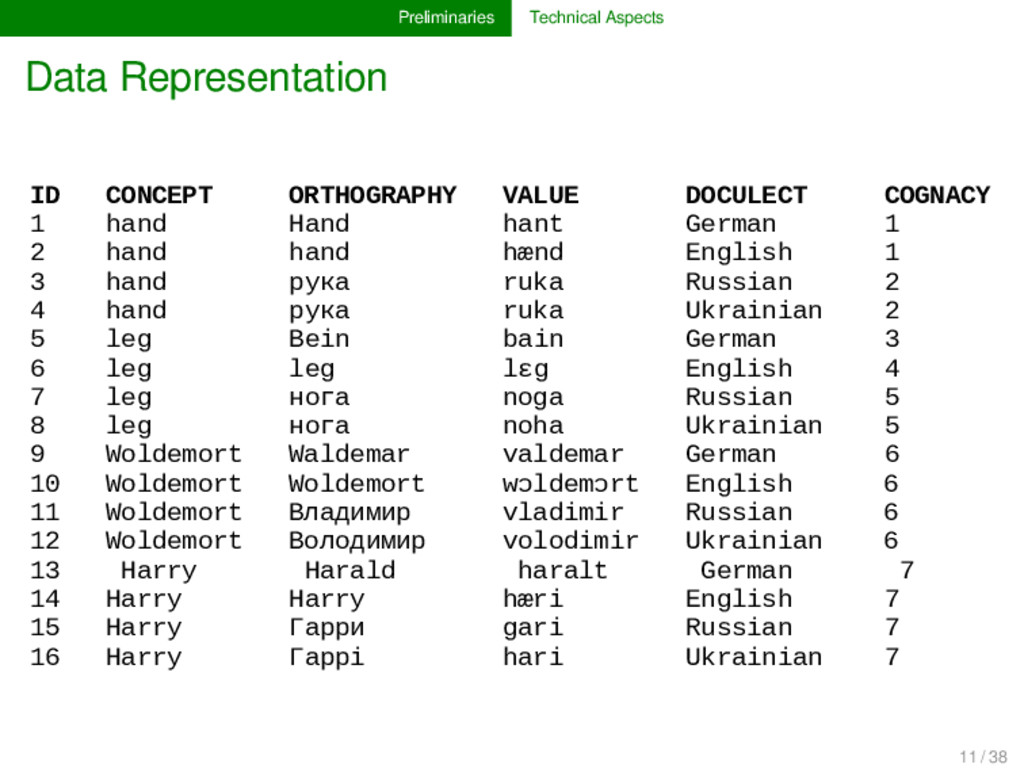
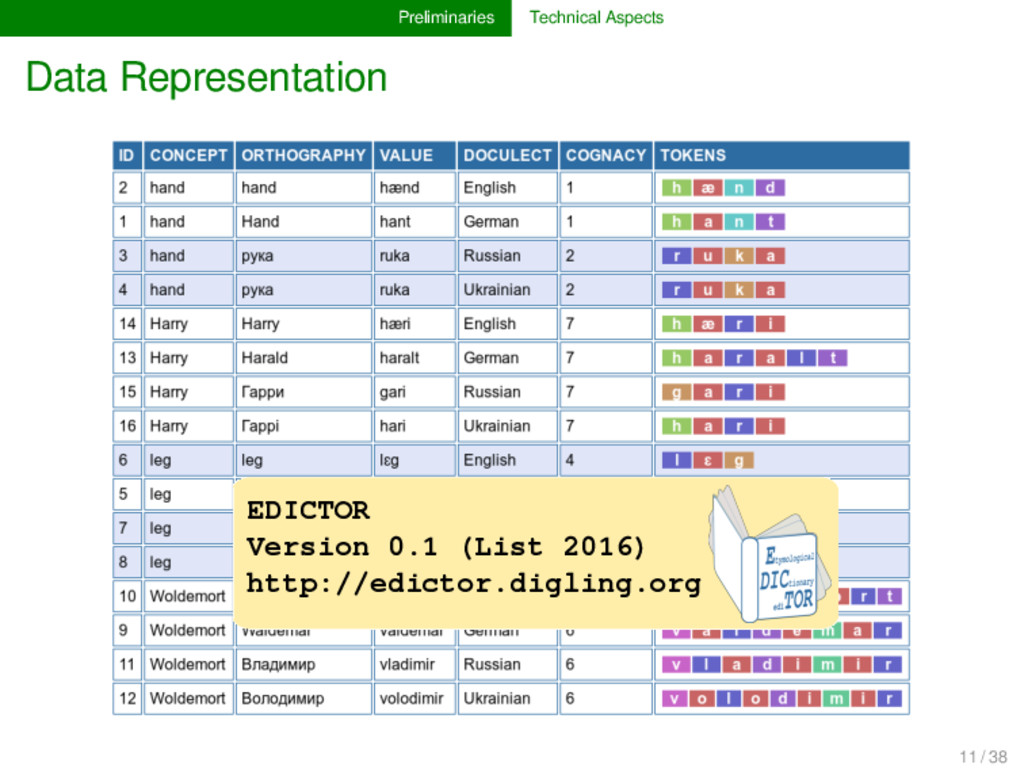
of words from various languages, in which each row corresponds to one word form in one language, marked by a unique identifier in the first column, with additional informa- tion regarding the word (meaning, pronunciation, cognacy, etc.) placed in additional columns. Word List Format Given the very abstract and lightweight character of this word list structure, it can be stored in all computer formats which allow for this kind of data, such as CSV (comma-separated values, pure text file) or more specific spreadsheet formats (Excel, LibreOffice, GoogleSheets, etc.). 10 / 38
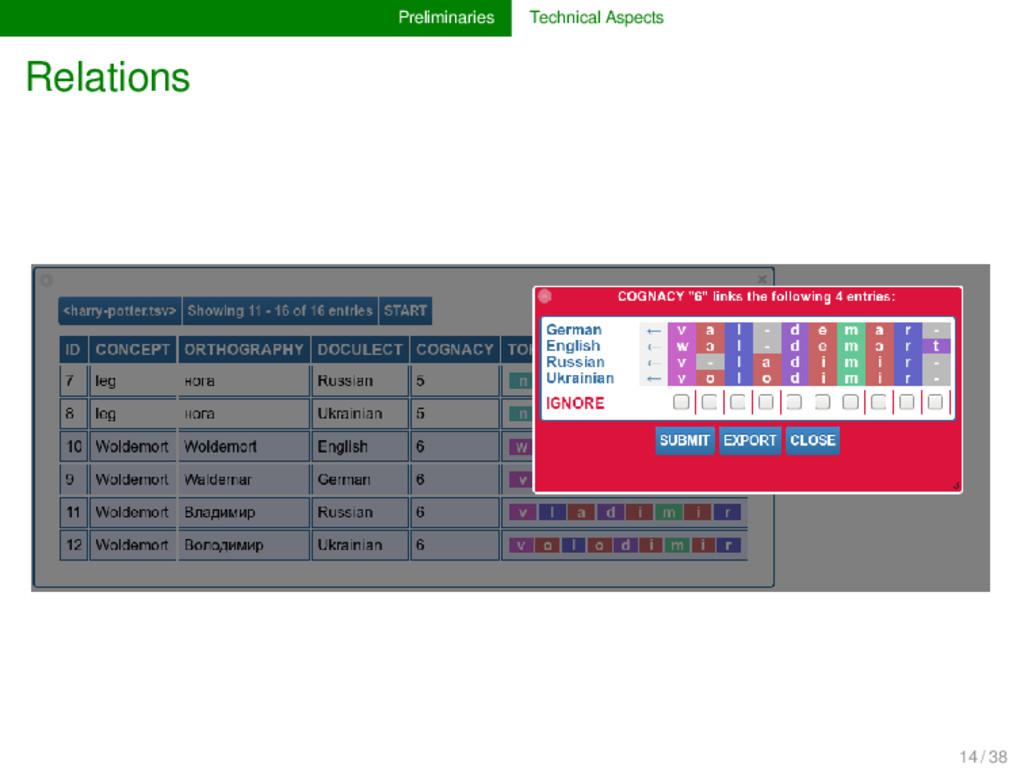
COGNACY 1 hand Hand hant German 1 2 hand hand hænd English 1 3 hand рука ruka Russian 2 4 hand рука ruka Ukrainian 2 5 leg Bein bain German 3 6 leg leg lɛg English 4 7 leg нога noga Russian 5 8 leg нога noha Ukrainian 5 9 Woldemort Waldemar valdemar German 6 10 Woldemort Woldemort wɔldemɔrt English 6 11 Woldemort Владимир vladimir Russian 6 12 Woldemort Володимир volodimir Ukrainian 6 13 Harry Harald haralt German 7 14 Harry Harry hæri English 7 15 Harry Гарри gari Russian 7 16 Harry Гаррi hari Ukrainian 7 11 / 38
of the language variety (EDICTOR prefers a simple name, without special charac- ters and whitespace). CONCEPT The gloss for the concept expressed by the word (content arbitrary, as long as different concepts are given different glosses). TOKENS Machine-readable representation of phonetic transcription. Space-segmented, that is, pho- netic/phonological units (“sounds”) are sepa- rated by spaces. 12 / 38
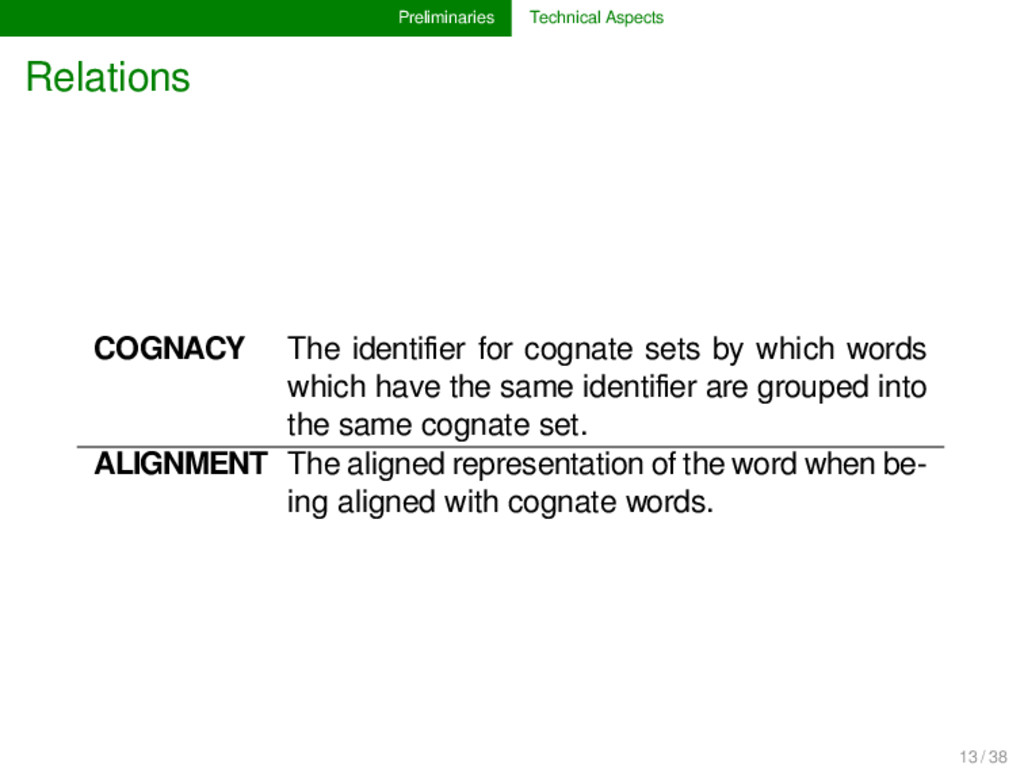
by which words which have the same identifier are grouped into the same cognate set. ALIGNMENT The aligned representation of the word when be- ing aligned with cognate words. 13 / 38
common work with Nathan Hill (SOAS, London). We developed the ideas for handling and analysing word formation in a project on the history of the Burmish language family. 16 / 38
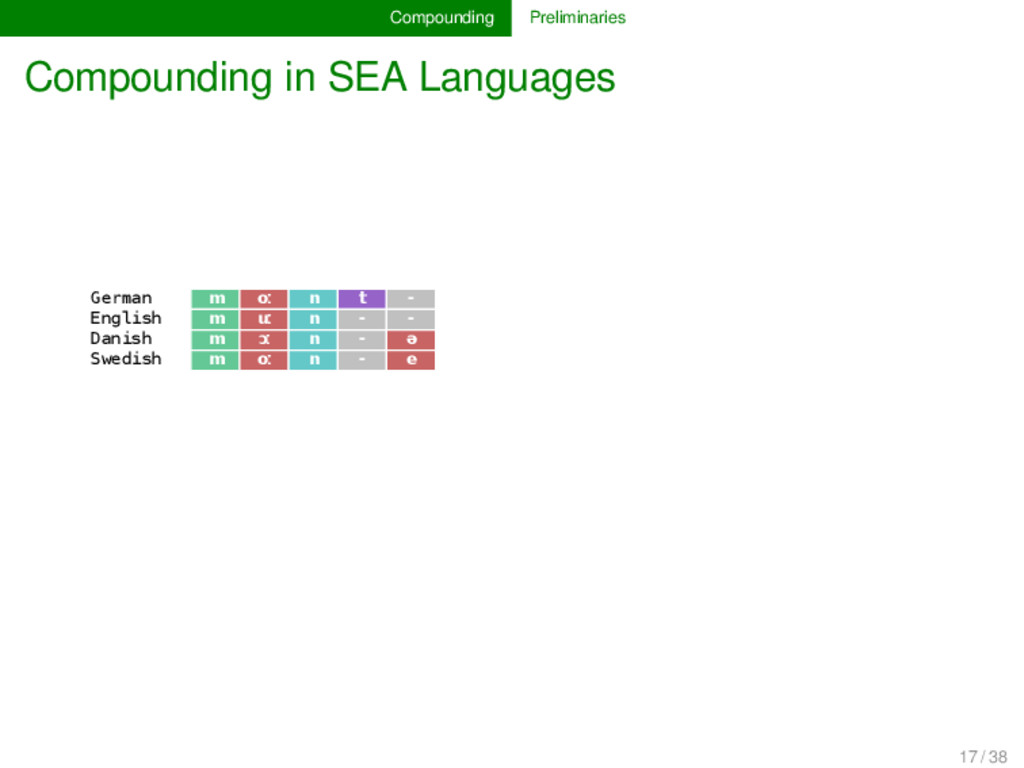
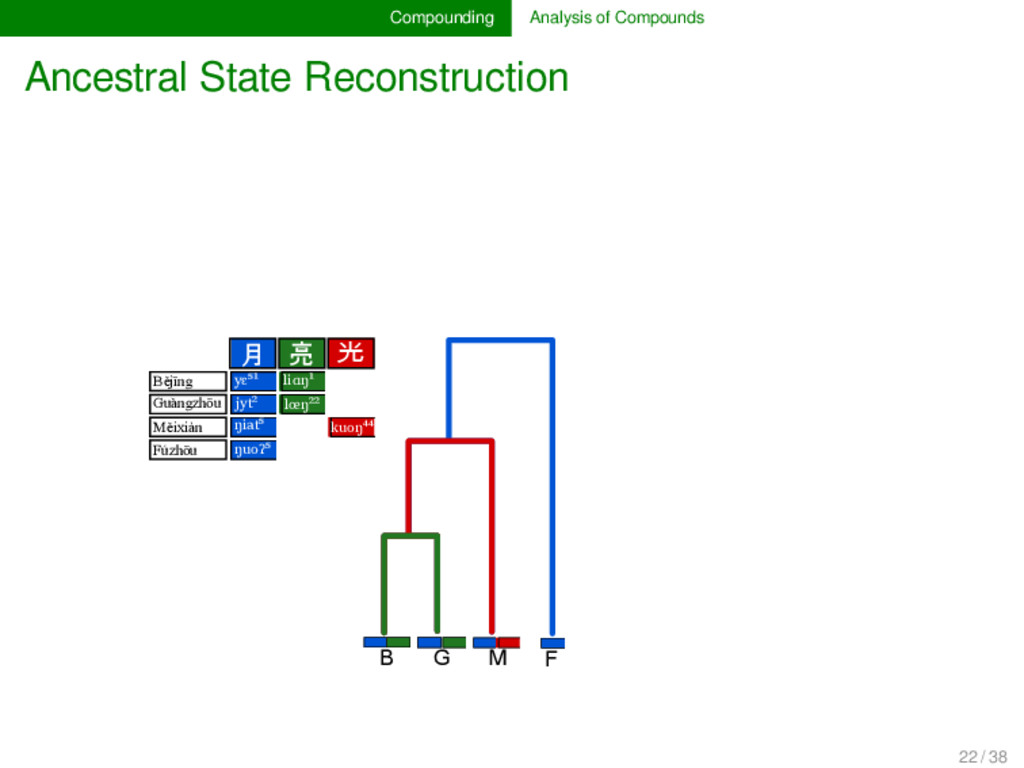
t - English m uː n - - Danish m ɔː n - ə Swedish m oː n - e Fúzhōu ŋ u o ʔ ⁵ - - - - - - - - - - Měixiàn ŋ i a t ⁵ - - - - - k u o ŋ ⁴⁴ Guǎngzhōu j - y t ² l - œ ŋ ²² - - - - - Běijīng - y ɛ - ⁵¹ l i ɑ ŋ - - - - - - 17 / 38
t - English m uː n - - Danish m ɔː n - ə Swedish m oː n - e Fúzhōu ŋ u o ʔ ⁵ - - - - - - - - - - Měixiàn ŋ i a t ⁵ - - - - - k u o ŋ ⁴⁴ Guǎngzhōu j - y t ² l - œ ŋ ²² - - - - - Běijīng - y ɛ - ⁵¹ l i ɑ ŋ - - - - - - 1 2 3 4 number of morphemes per word 0.0 0.2 0.4 0.6 0.8 1.0 relative frequency all words nouns Compounds in the basic vocabulary (Swadesh1952) across 23 Chinese dialects (data by Hamed and Wang 2006) 30% 50% 17 / 38
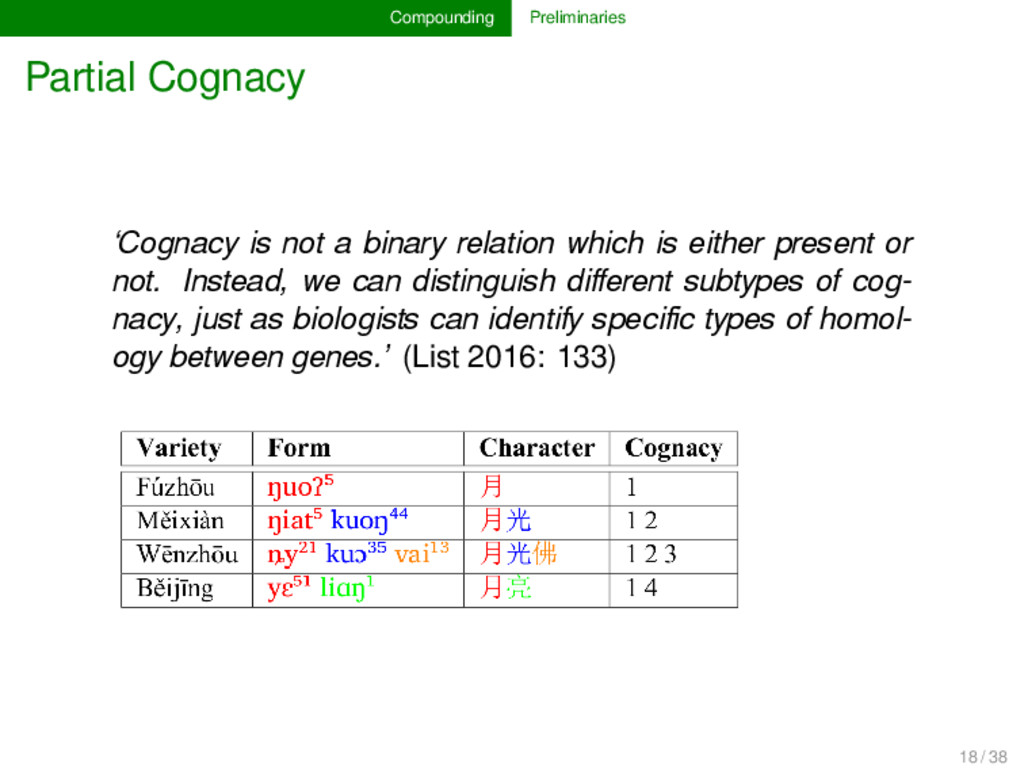
which is either present or not. Instead, we can distinguish different subtypes of cog- nacy, just as biologists can identify specific types of homol- ogy between genes.’ (List 2016: 133) 18 / 38
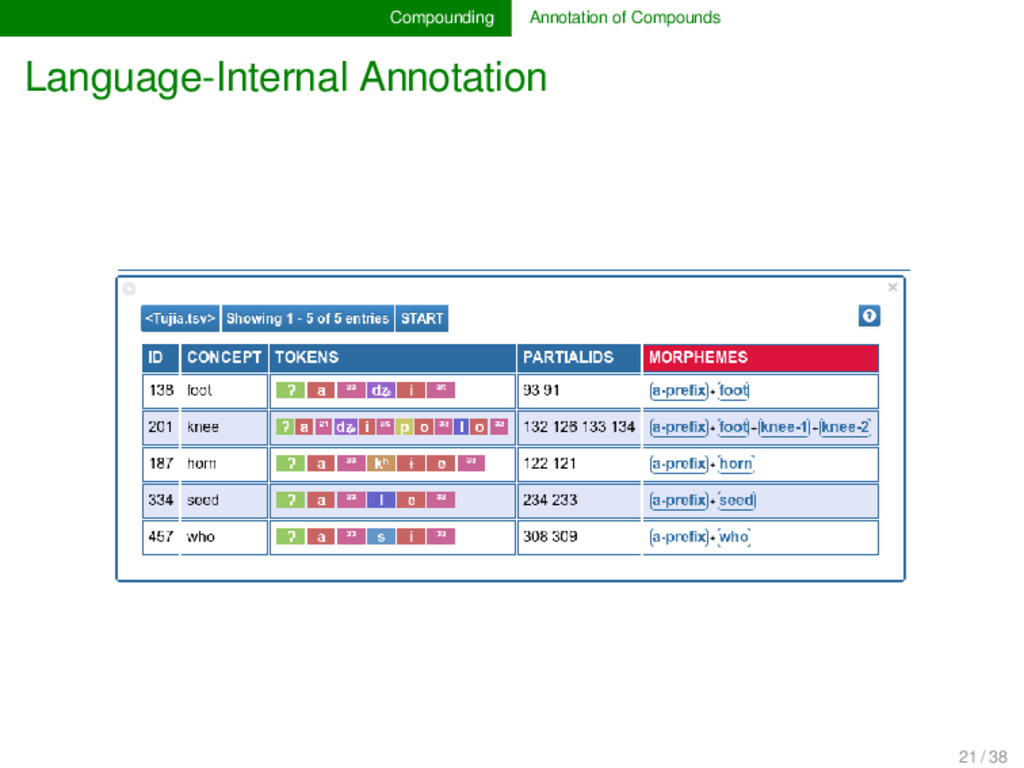
transcriptions are expanded by adding a layer of morphological segmentation in which different mor- phemes in the same word form are separated with a mor- pheme separation character (usually a +). PARTIAL_COGNATES Partial cognate relations are indicated with help of partial cognate identifiers which are separated by a space in the partial-cognate column. PARTIAL_ALIGNMENTS When aligning the words, we still write all alignments in only one column, but we align each morpheme in the word only for the partial cognate set to which it belongs. 19 / 38
annotated in this way can be directly converted into the “normal” cog- nate sets we know from the quantitative phy- logenetic analyses. Partial cognate annotation would be extremely tedious in spreadsheets or other formats. The EDICTOR tool, however, supports partial cognate annotation, and LingPy offers tools for partial cognate identification and alignment (List et al. 2016). 19 / 38
the morpheme-separated word forms fur- ther by using a very straightforward space-segmented for- mat of “word-form-glossing”, in which we use the same iden- tifier (a brief gloss for a concept) to gloss the structure of word forms. In this way, we can annotate the semantic structure of multi-morphemic compounds (compare Chinese shùpí 树皮 ‘bark’ tree skin), and at the same time anno- tate language-internal cognates (word families or “allofams”) in a transparent way. 21 / 38
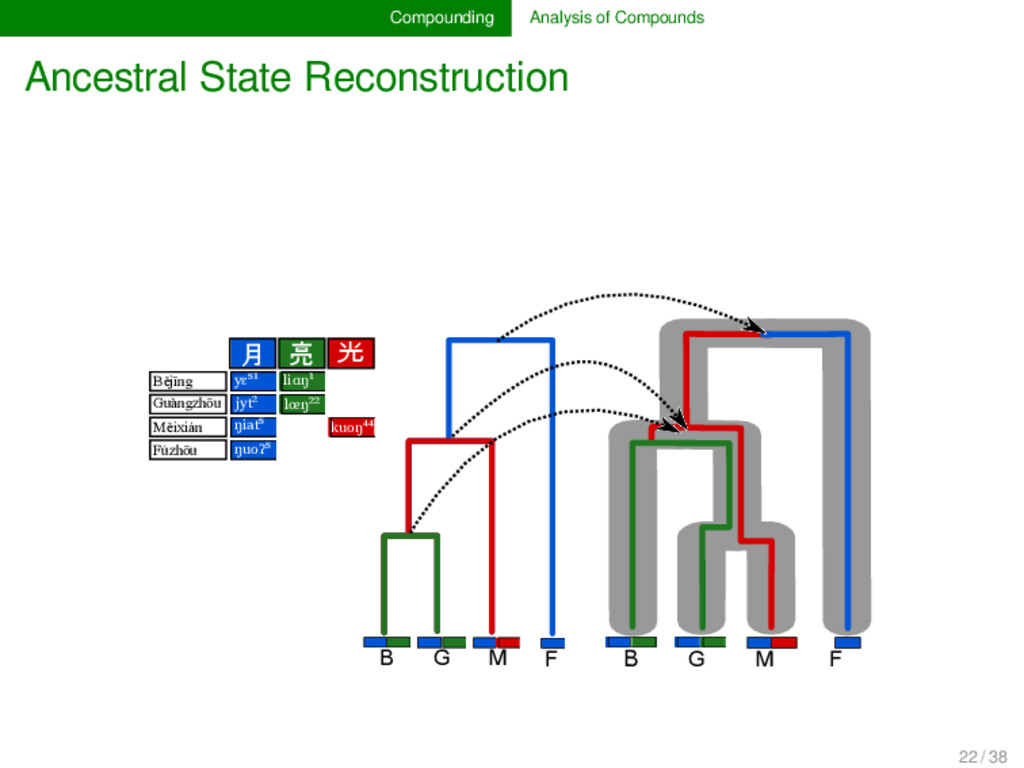
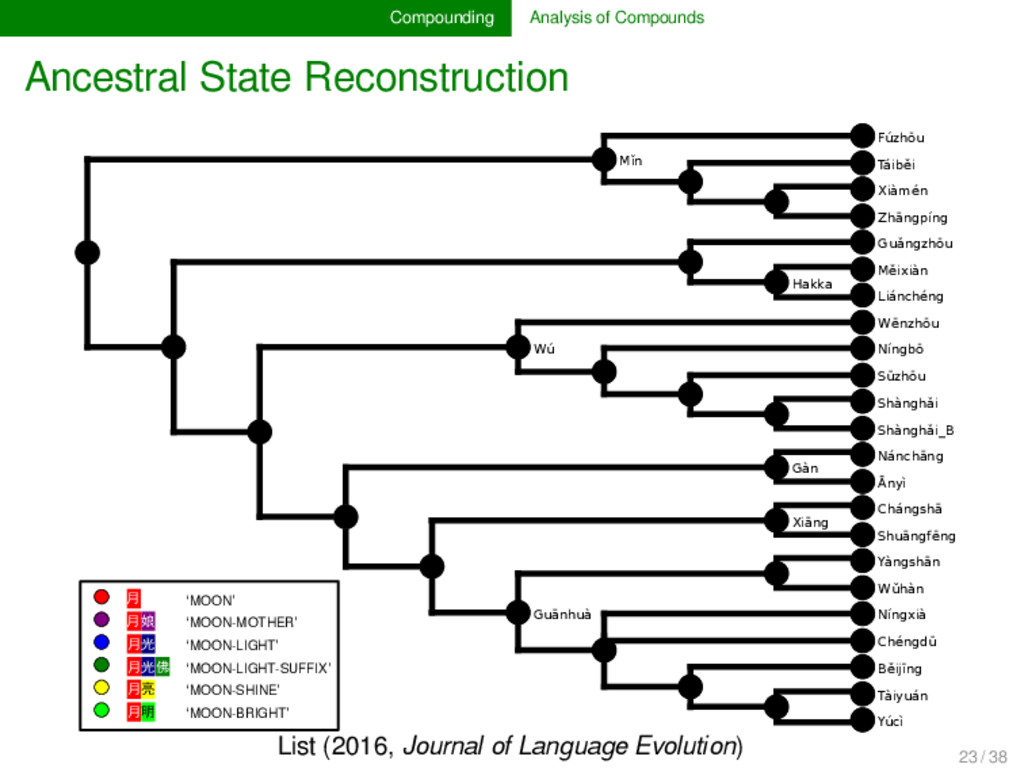
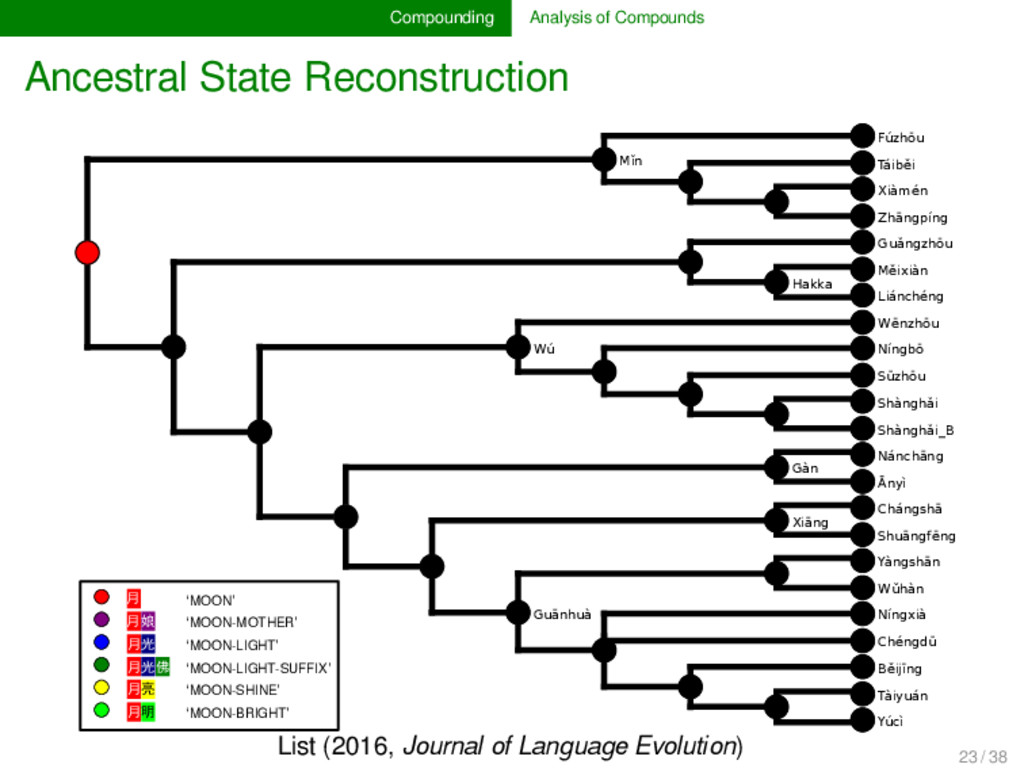
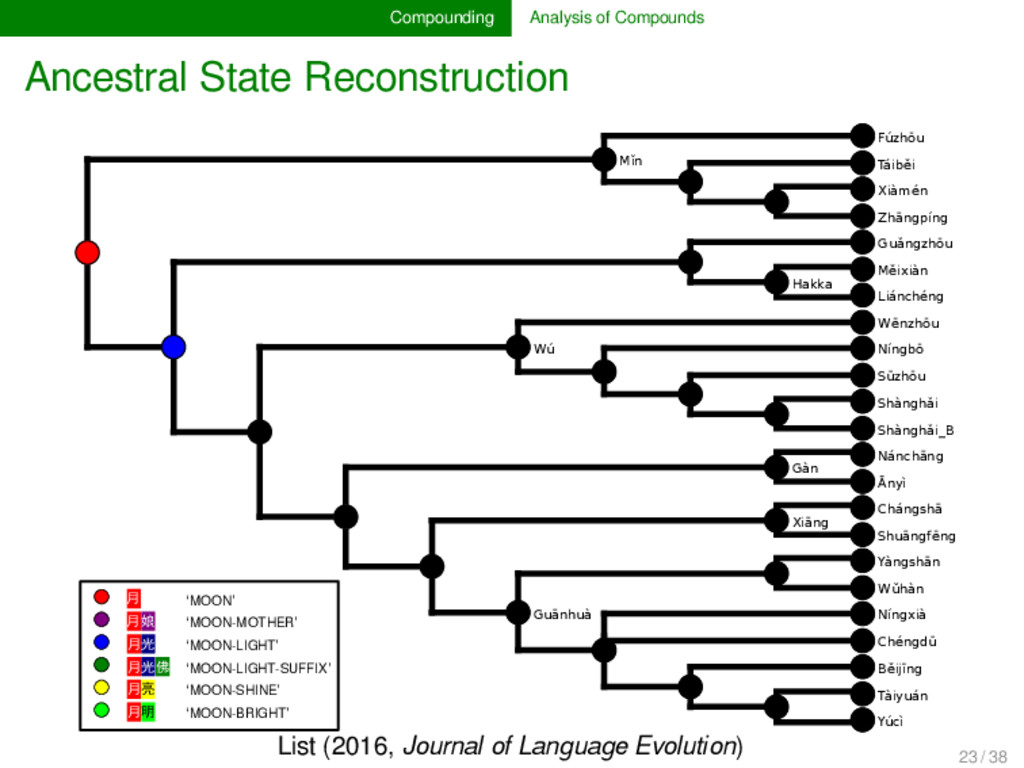
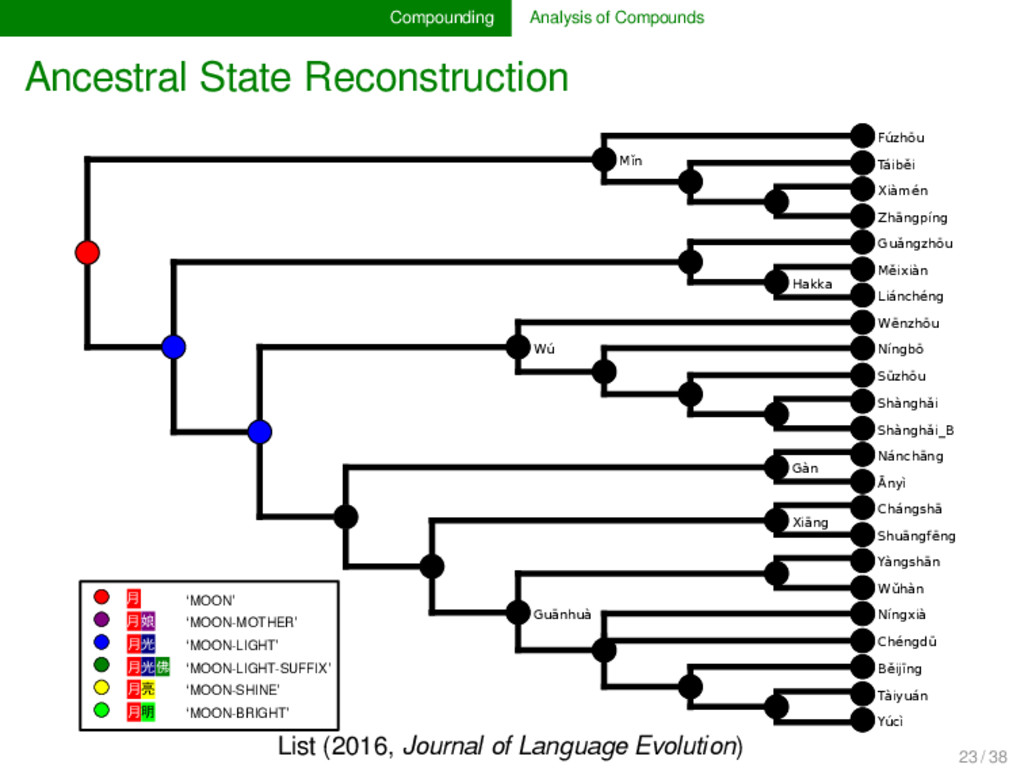
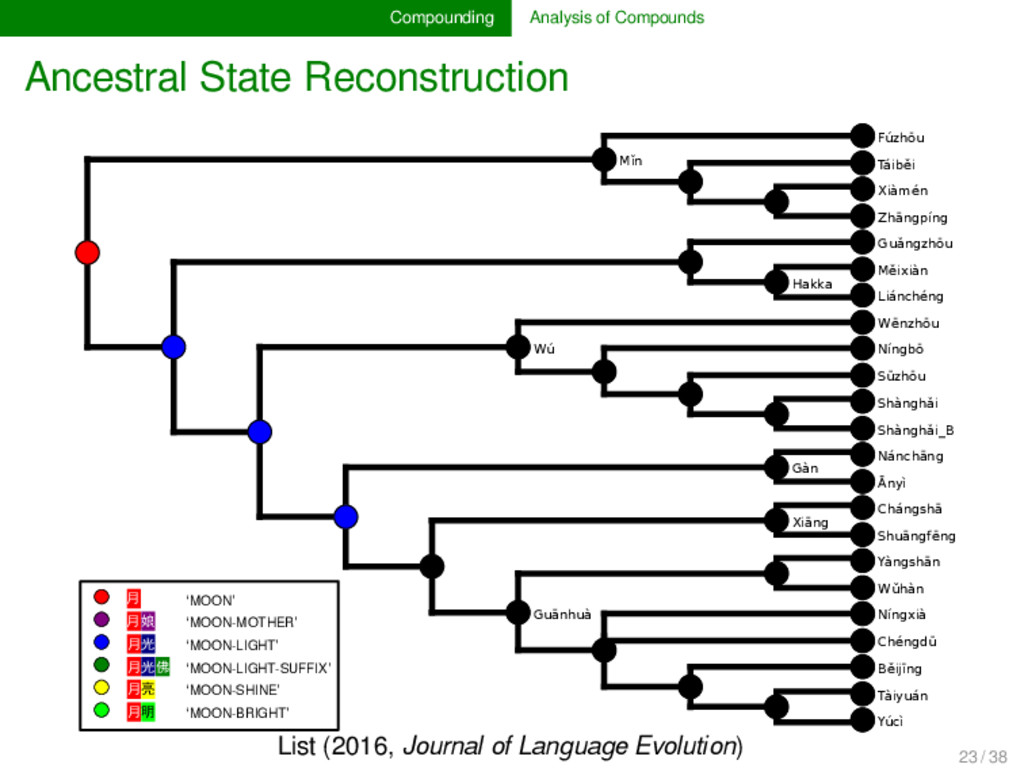
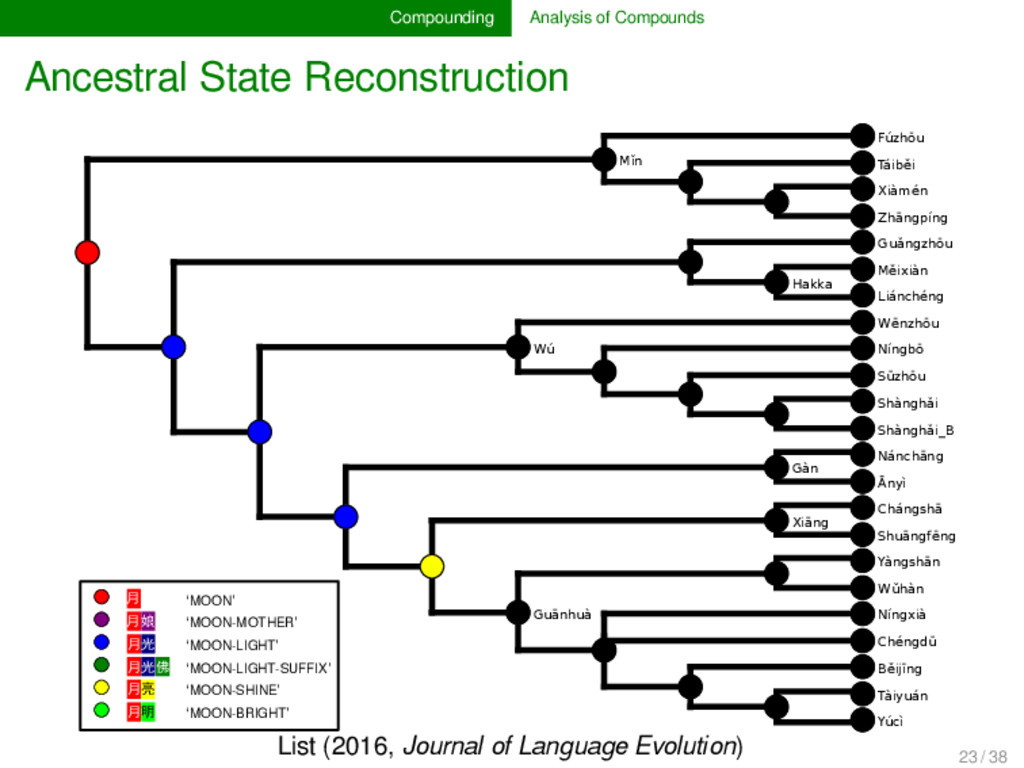
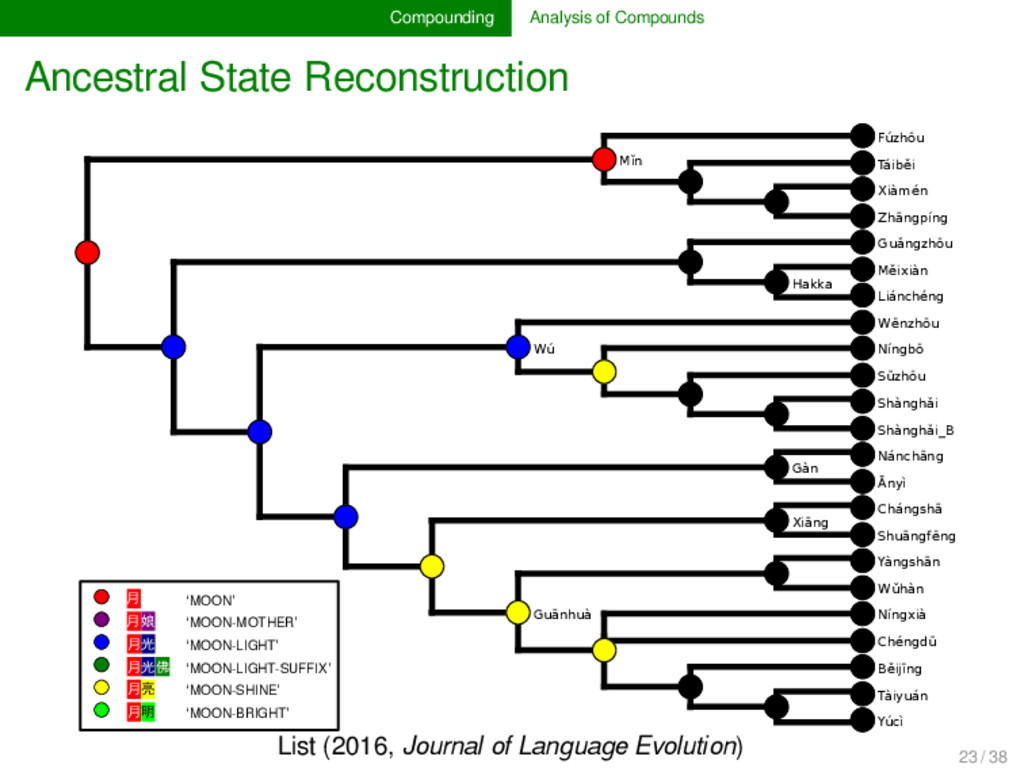
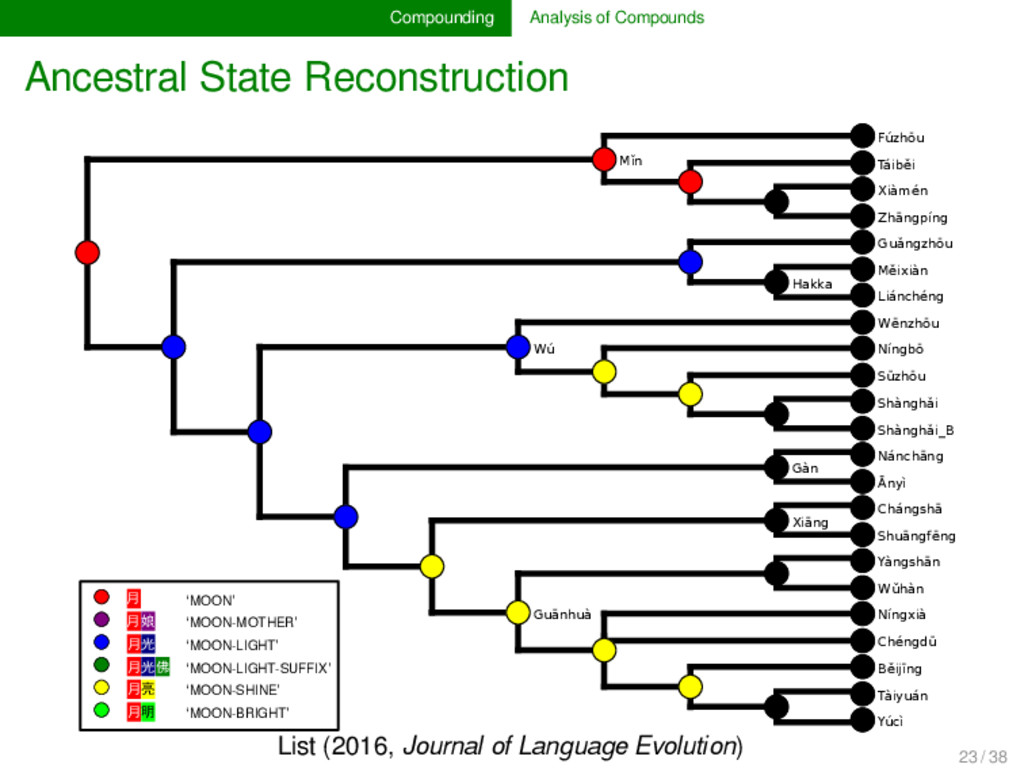
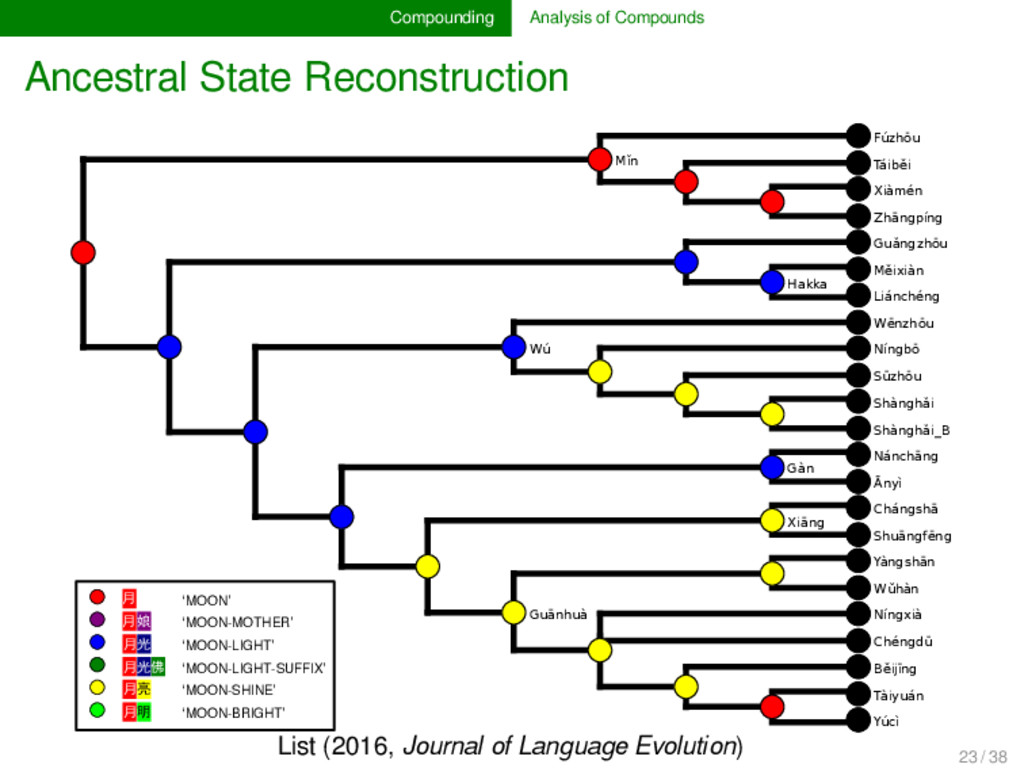
annotated the compounds in lexical data for partial cognacy, we can use various methods to infer how the data can be best explained by assuming different pro- cesses of change in compounding. Currently, only proto- types are available (see e.g., List 2016), but evolutionary biology offers with the framework of tree reconciliation meth- ods already a rich arsenal of methods which we can adapt to our linguistic needs in the future. Given that compound- ing is treated carelessly in most etymological dictionaries of SEA languages, the development of new quantitative analy- ses inspired from biological techniques may turn out as very fruitful for our discipline. 22 / 38
Mostly a-prefix followed by non-cognate items, e.g. Bola [a³¹ + thaʔ⁵⁵] vs. Achang [a31 + lum31[ ‘above’. 58 Mostly one plain noun vs. one with an additional part, e.g. Bola [tʃa◌̱ m⁵⁵] vs. Lashi [tsɔ◌̱ m⁵⁵ + mou⁵⁵] {cloud + sky} ‘cloud’. 53 Mostly one plain noun vs. one with an additional part in front, often simply the a-suffix, e.g., Atsi [siŋ²¹] vs. Achang [a³¹ + ʂəŋ³¹] ‘liver’. 36 Common main noun, but different preceding noun, e.g., Bola [mjaŋ⁵⁵ + kʰui³⁵] {thunder + dog} vs. Lashi [wɔm³¹ + kʰui⁵⁵] {bear + dog} ‘wolf’. 34 The common part is prefixed in one word and suffixed in the other, e.g., Atsi [u²¹ + tsham⁵¹] {head + hair} vs. Rangoon [shɑ◌̃ ²² + pĩ²²] {hair + ?} ‘hair (of head)’. remaining 77 30 unique patterns are remaining, 15 only occuring once Partial Cognate Patterns in Burmish Languages (Hill & List WIP) 24 / 38
cognate pattern anal- ysis has not been carried out in linguistics so far. It may, however, turn out to provide us with important evidence on the directionality of certain patterns. Regardless of directionality, it may also be interesting to see to which degree language families in which compounding is fre- quent differ in their major patterns. 25 / 38
common work with Guillaume Jacques (CRLAO, Paris), who provided a first explicit annotation of verbal derivation in Kiranti languages (an annotated version of Jacques forthcoming, A reconstruction of Proto-Kiranti verb roots, Folia Linguistica Historica). We de- veloped the ideas for handling and preliminary ideas for analysing derivation in several discus- sions during the last months. 27 / 38
grib grib.ma sgrib ɴgrib Exemplary derivations of word forms from the Tibetan root *rib 'to be dark', as proposed by Jacques (2016, Une famille de mot en Tibétain, URL: https://panchr.hypotheses.org/1273), visualized as a derivation tree. The form itself is not attested, but it can be supposed based on the semantic relations between the members of the word family. 28 / 38
plays a much more crucial role in derivations than in plain transparent compounds. Instead of a simple morpheme segmentation, an annotation of deriva- tions needs to account for this aspect. Paradigmatic Aspect While compounds are syntagmatic structures, derivations may further show paradigmatic variation. If derivation is expressed by a voicing contrast, as, for example, the anti- causative in some Kiranti languages (Jacques forthcoming), this is a paradigmatic change which cannot be modeled with help of alignments. A transparent annotation of derivations also needs to account for this. 29 / 38
As a general idea for annotation, we can model syntagmatic derivation in a similar way in which we propose to model compounding. As a rule, the machine-readable transcription of words is provided in morpheme-segmented form. Hierarchical Annotation In most cases, the hierarchical aspect can be modeled by annotating that one element attaches to another element. Bantawa sakt ‘to weed’, an applicative derivation of an in- transitive verb, can thus be written as "s a k ← t", indi- cating that the applicative-marker "t" attaches as suffix to the main morpheme (Jacques forthcoming). 30 / 38
requires two additional layers, to al- low for a sufficiently abstract handling. Each word form is linked to a root in a separate ROOT column, and a stem in a separate STEM column. The syntagmatic derivations can be placed in a DERIVATION column, in which derivation is annotated in a similar form, as we used for the word-form- glossing. The hierarchical relations underlying the derivations need to be handled independently of the word list and can be passed in form of directed networks to the word list. 31 / 38
follows the partial cognate annotation principle, but word forms with paradigm variation in their stems are assigned different identifiers, reflecting the fact that they cannot be aligned. An additional cognate identifier is needed to make sure that different stems can be assigned to the same root. 31 / 38
language-internal annotation also for language-external annotation, with the difference, that our root and stem cells will now serve for the proto-form of the proposed proto-language. Problems we cannot yet suffi- ciently handle are those where the actual derivation cannot be traced back to the proto-language, as this will require to introduce intermediate ancestral forms. More examples are needed to handle these cases. 32 / 38
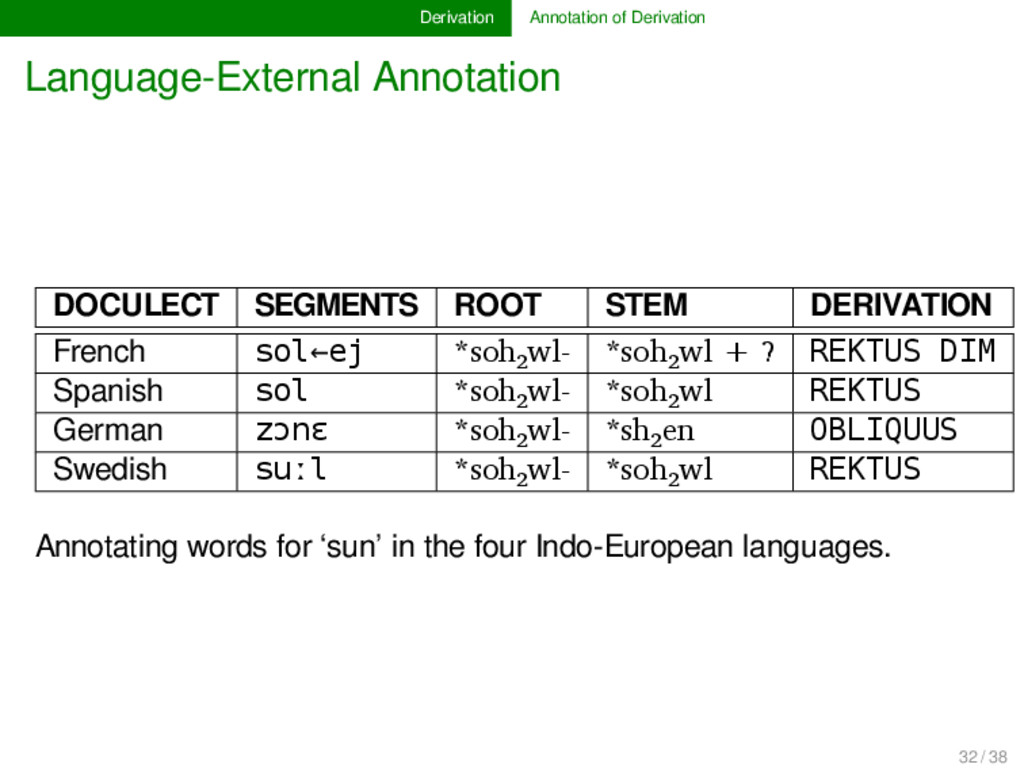
DERIVATION French sol←ej *soh₂wl- *soh₂wl + ? REKTUS DIM Spanish sol *soh₂wl- *soh₂wl REKTUS German zɔnɛ *soh₂wl- *sh₂en OBLIQUUS Swedish suːl *soh₂wl- *soh₂wl REKTUS Annotating words for ‘sun’ in the four Indo-European languages. 32 / 38
as provided by G. Jacques, the data structure in the demo application could be generated automatically. The same applies to the stems, which were derived by applying the conversion rules proposed for each derivation process. Already in this preliminary form, the data provides a much larger degree of transparency than the clas- sical etymological dictionaries, and further analyses can be easily carried out. 32 / 38
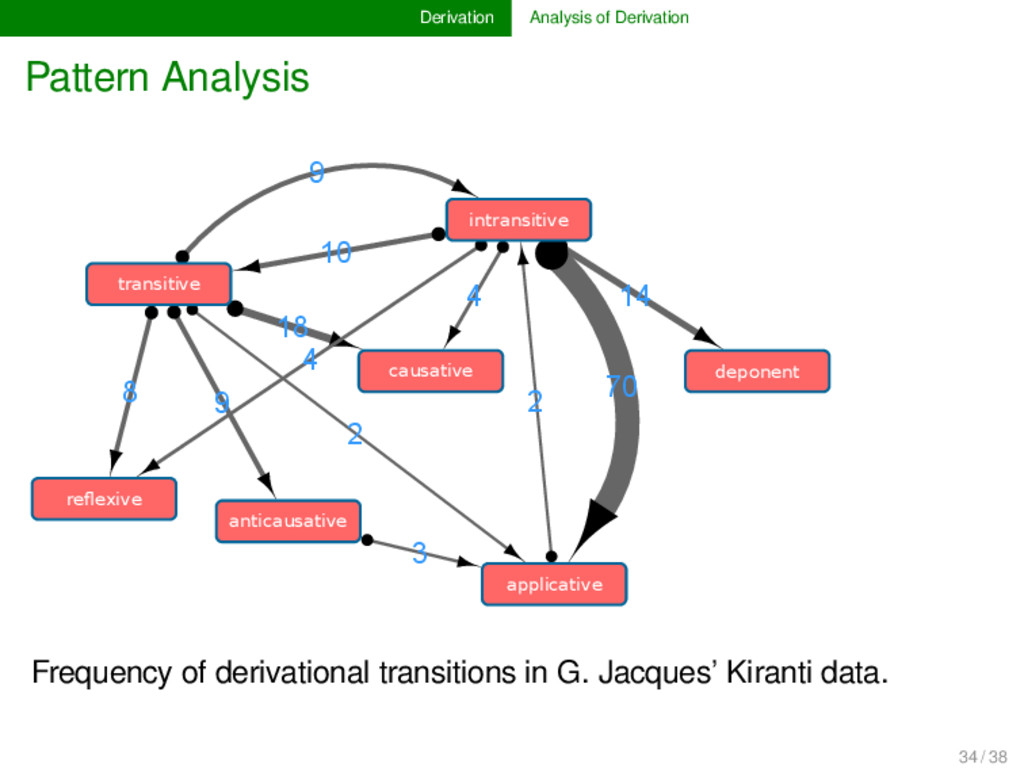
in compounding processes is really hard to estimate (and may well be highly language-specific or even show no preference at all), we need a reference phy- logeny to get initial insights into the major processes. In derivation, however, we usually have a clear idea regarding the direction of the processes. Since directional processes are very useful for phylogenetic estimation, we suppose that a larger dataset annotated in this form, may be very suitable for phylogenetic reconstruction methods. For this, however, more languages need to be added to G. Jacques’ Kiranti database. 33 / 38
handle analogy, but we need to handle it at some point, both in annotation and analysis. Software and Tools We need better heuristics to produce proper data and the tools to correct computational preprocessing within the frameworks for annotation which we define. Complexity and Comparability We surely do not cover all what is possible in languages at the moment, be it in synchrony or diachrony, so we need to develop more and more examples to enhance our specifica- tion. 36 / 38
ciency of the new biological methods applied to linguistic data. But if we, as linguists, fail to annotate our data in such a way that it can be easily compared across languages and applications, if we do not work harder to make our data transparent enough so that it can be read by humans and machines, we should not complain that computational lin- guists use lousy data and lousy algorithms. Better and suf- ficient algorithms will come, if only we manage to increase the comparability of our linguistic data. 37 / 38
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}