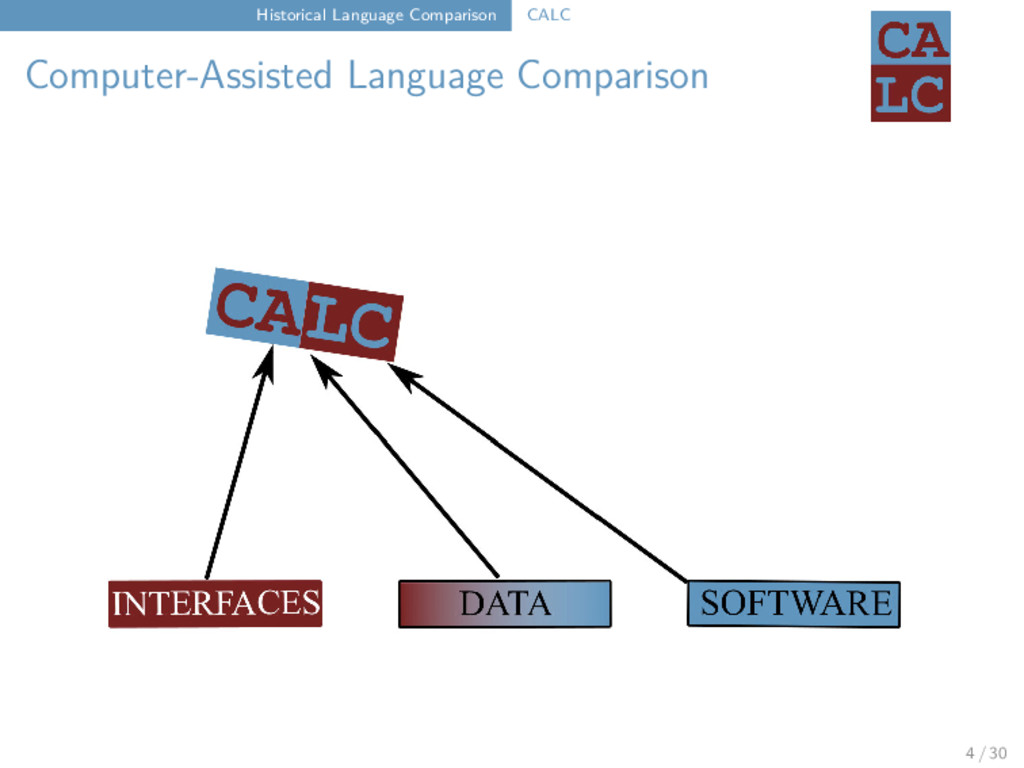
Framework Yunfan Lai and Johann-Mattis List Research Group “Computer-Assisted Language Comparison” Department of Linguistic and Cultural Evolution Max-Planck Institute for the Science of Human History Jena, Germany 2018-02-09 very long title P(A|B)=P(B|A)... 1 / 30
Tools CLDF Cross-Linguistic Data Formats (CLDF): - defines standards for data sharing - can be read and manipulated lated by different tools - http://cldf.clld.org 5 / 30
Tools CLDF Cross-Linguistic Transcription Systems - reference catalogs for sounds - links to transcription systems - links to transcription data - http://clts.clld.org 5 / 30
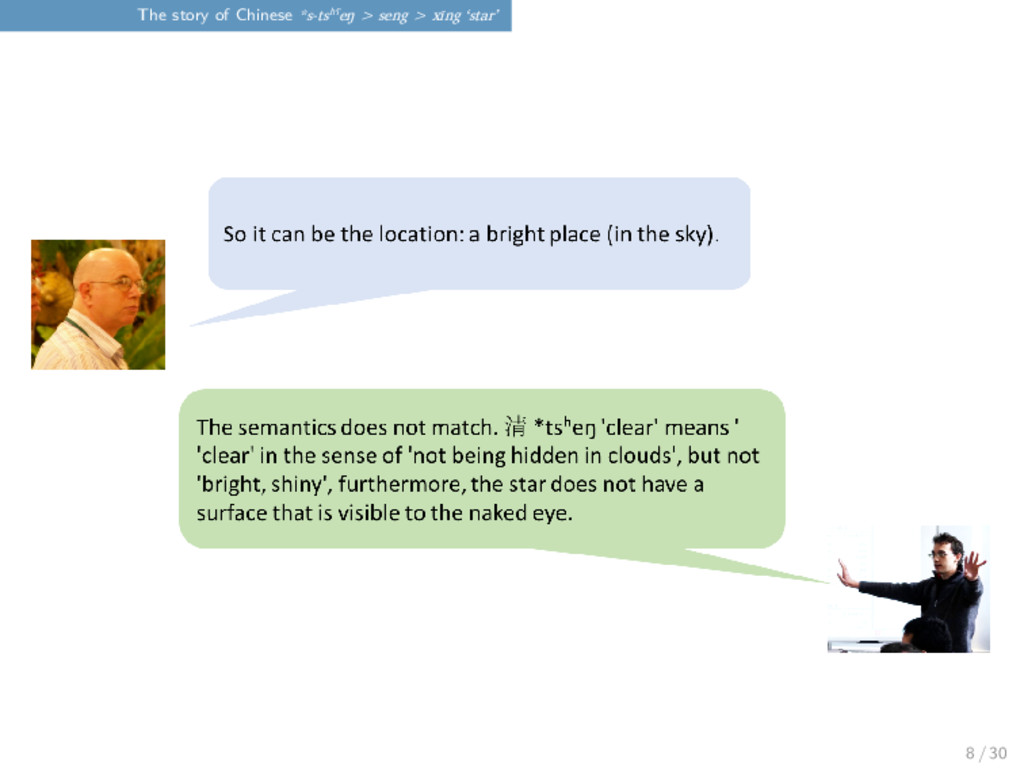
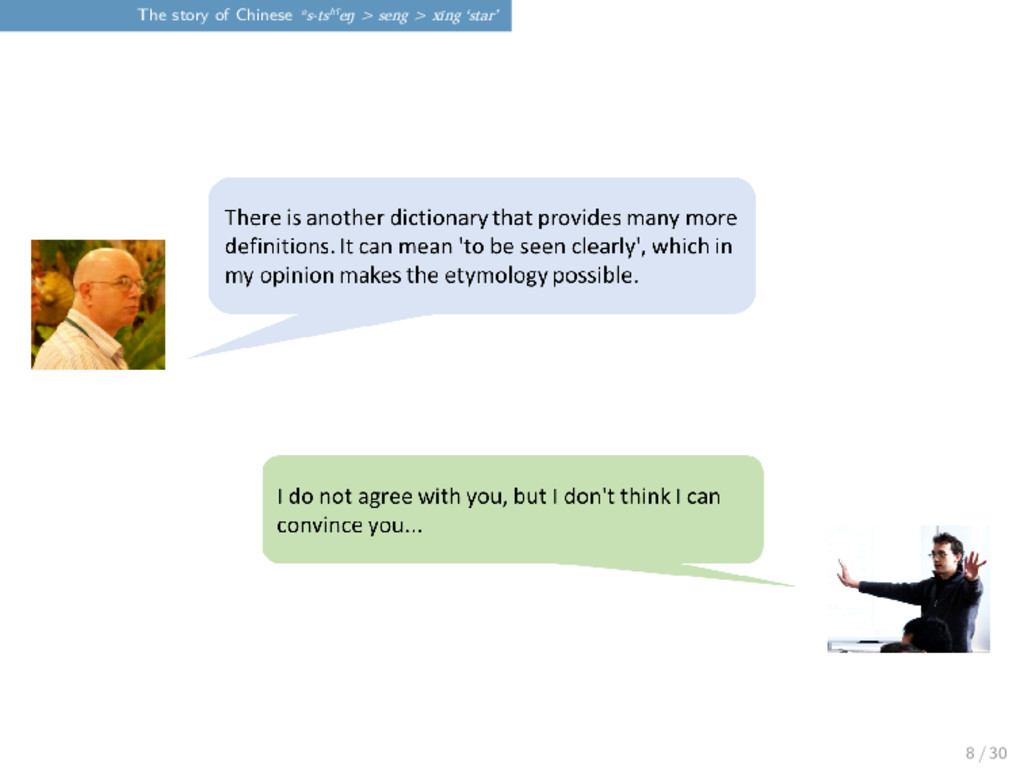
Just a couple of weeks ago, Laurent Sagart and Guillaume Jacques had a discussion on the Chinese word for “star”, which is reconstructed as *s-tsʰˤeŋ in Old Chinese by Baxter and Sagart (2014). 7 / 30
Reflections When discussing etymologies involving nominal and verbal derivation, we often end up discussing about vague semantic analyses, “educated guesses”, applied to languages largely understudied. 9 / 30
Reflections When discussing etymologies involving nominal and verbal derivation, we often end up discussing about vague semantic analyses, “educated guesses”, applied to languages largely understudied. All scholars would probably agree that to advance these discussions (which may easily turn in circles), stricter formalization could help to set up a boundary for our disagreements. 9 / 30
Reflections Many attempts to formalize semantic change have been made, but they are not feasible to help us investigate the questions at hand. It would be good if we had 10 / 30
Reflections Many attempts to formalize semantic change have been made, but they are not feasible to help us investigate the questions at hand. It would be good if we had large-scale samples of abstract and concrete patterns of derivational semantics, which are stored in such a way that we can directly compare across multiple language families and retrieve general assessments of the plausibility and frequency of patterns under discussion. 10 / 30
Reflections What we find instead are very detailed single-language accounts on derivation patterns, which are usually not comparable across languages. 11 / 30
Reflections What we find instead are very detailed single-language accounts on derivation patterns, which are usually not comparable across languages. Our dilemma is: if we go large-scale, our analyses are useless for single languages, but if we go small-scale, we loose comparability, as the patterns are too specific for one language. 11 / 30
Reflections We can overcome the scaling problem by establishing comparable small-scale analyses, which adhere to standards, represent data in human- and machine-readable form, and embrace the Zen of Python: “simple things should be simple, complex things should be possible” 12 / 30
Gloss qʰrɑ́ to be big s-qʰrɑ́ to cause to be big kʰɑ̂ to give s-kʰɑ̂ to cause to give rǽ to write s-rǽ to cause to write tsʰû to be boiled v-ftsʰû > f-tsʰû to boil 17 / 30
Gloss Intransitive Gloss ftɕʰə̂ to melt tr. dʑə̂ to melt intr. kʰlǽ to perish glǽ to die out ntɕʰətɕʰɑ́v to trip ndʑədʑɑ́v to tumble ntsʰɑ̂ɣ to wear dzɑ̂ɣ to be there (attached) pʰrə̂ to loosen brə̂ to become loose tɕʰǽv to break tr. dʑǽv to break intr. tɕə̂rə to tear dʑə̂rə to be torn intr. 18 / 30
Gloss vzɑ́r to be spicy l-zɑ́v to cause to be spicy jdʑə̂r to mill jdʑə̂-l to cause to mill tʰê to drink s-tʰé to cause to drink çtə̂ to be short s-tə́m to shorten 19 / 30
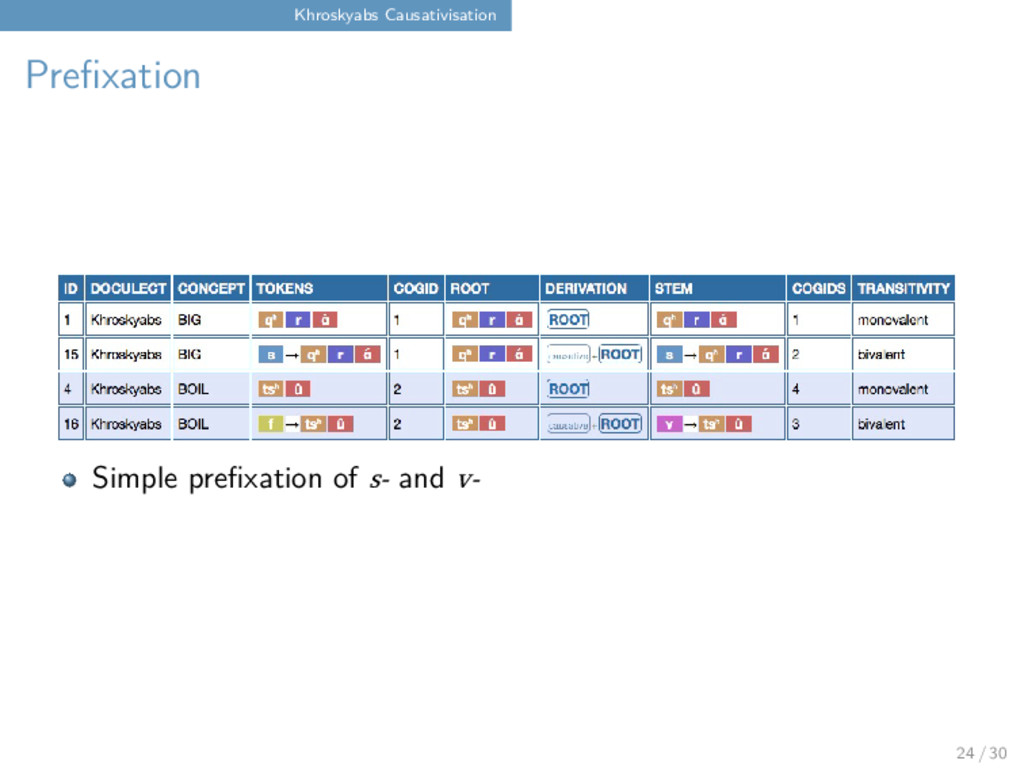
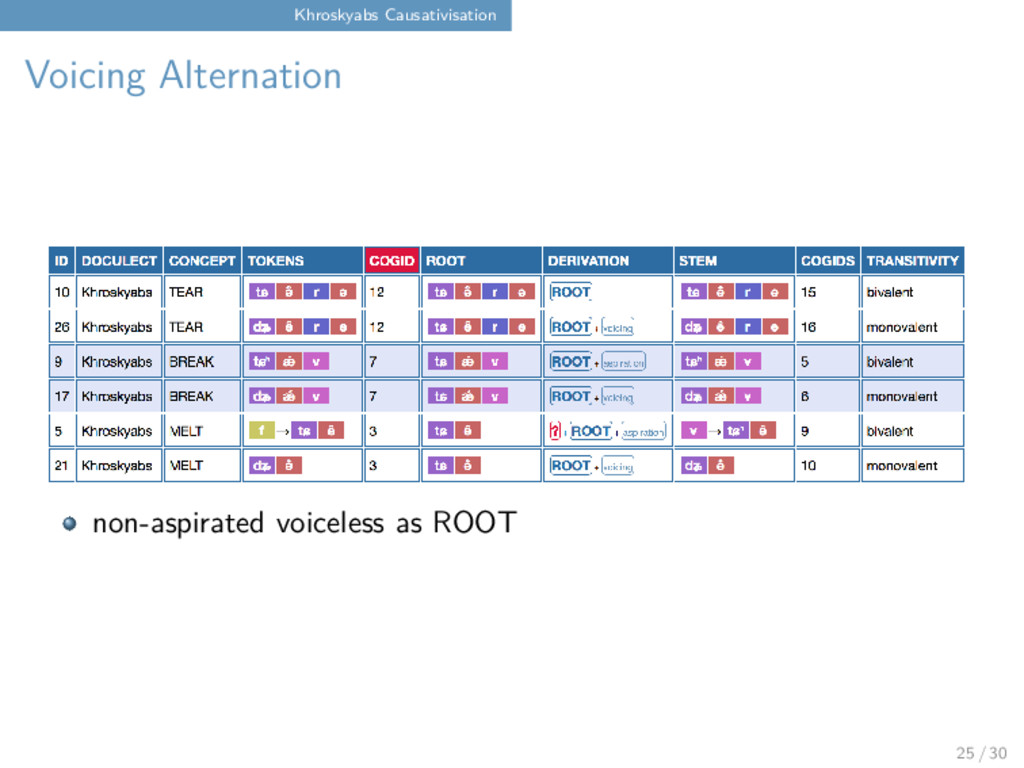
approach to guarantee comparability across languages, and establish a first list of causative concepts along with their source concepts: BOILED vs. BOIL TRIP vs. TUMBLE PERISH vs. DIE OUT SHORT vs. SHORTEN ... 20 / 30
approach to guarantee comparability across languages, and establish a first list of causative concepts along with their source concepts: BOILED vs. BOIL TRIP vs. TUMBLE PERISH vs. DIE OUT SHORT vs. SHORTEN ... We then investigate how these pairs are linked with each other in the target language, for example by affixation (and what kind of affixation) voicing alternations (frequent in Sino-Tibetan) suppletion or else? 20 / 30
DLCE of MPI-SHH has already established many of the important tools or is currently working on their implementation. As of now, the most important tools for this study are: Concepticon (List et al. 2016, as our reference catalogue for meanings), Glottolog (Hammarström et al. 2017, as our reference catalogue for languages), CLTS (List et al. in Prep., our reference catalogue for sound segments), CLDF (Forkel et al. in Prep., our overarching standard for data exchange), CLICS (List et al. 2014, our cross-linguistic approach for measuring semantic similarity), EDICTOR (List 2017, our tool for data annotation and analysis) 21 / 30
of the CALC project. The goal is to provide data in human- and machine readable form, allow for both a comparison across and inside a given language, embrace standards while also allowing for flexible and language-specific solutions, support efficiency by providing a healthy mixture between scripts (in Python) and web-based tools (EDICTOR, in JavaScript) to assist the annotation process. Before we can annotate, however, we need to understand what and how we can do this! 22 / 30
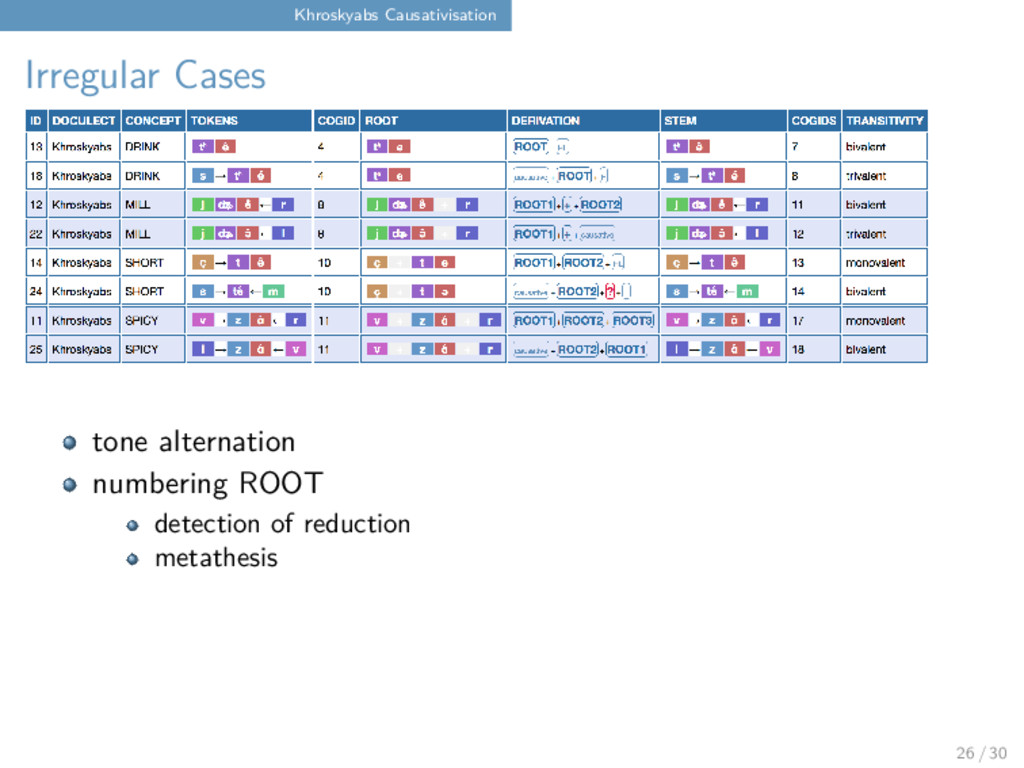
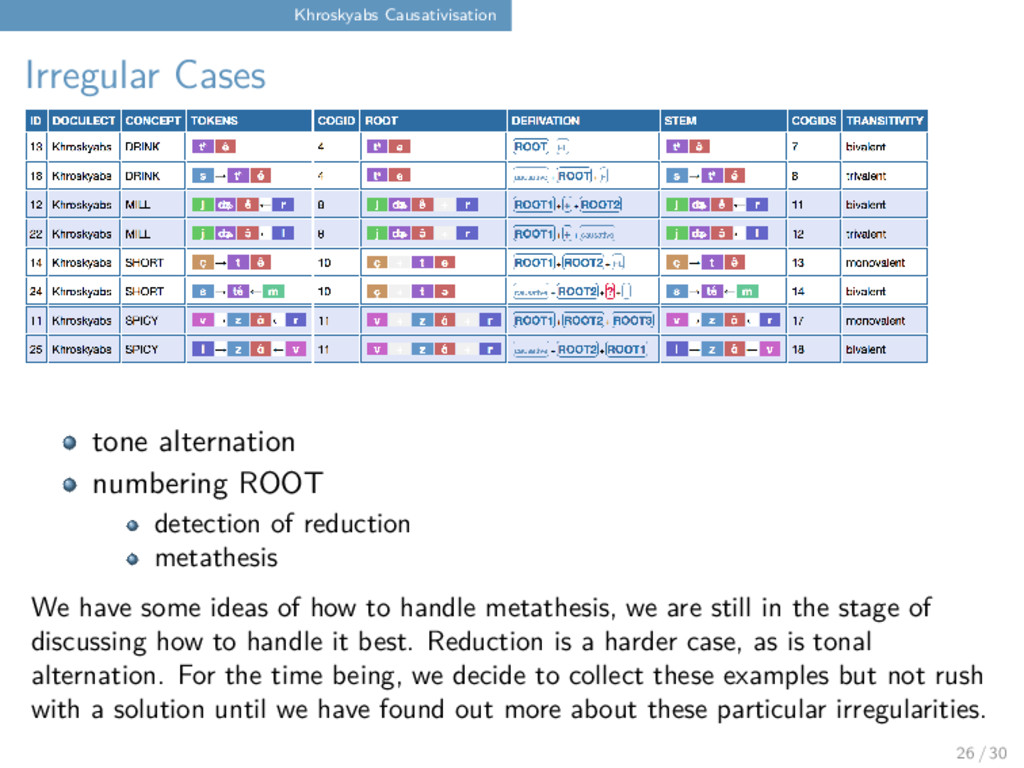
reduction metathesis We have some ideas of how to handle metathesis, we are still in the stage of discussing how to handle it best. Reduction is a harder case, as is tonal alternation. For the time being, we decide to collect these examples but not rush with a solution until we have found out more about these particular irregularities. 26 / 30
fact that our data is linked to our standards, we can expand the comparison from one to many dialects of Khroskyabs, use our questionnaires and annotation frameworks for other Sino-Tibetan languages (preliminary work on Kiranti with Guillaume Jacques has been carried out) compare derivation patterns across unrelated languages and make typologists happy 27 / 30
our approach will lead to improved: transparency (human- and machine-readable data) efficiency (thanks to algorithms and annotation tools designed for the tasks at hand) re-usability (in typological studies and historical language comparison) 29 / 30
our approach will lead to improved: transparency (human- and machine-readable data) efficiency (thanks to algorithms and annotation tools designed for the tasks at hand) re-usability (in typological studies and historical language comparison) So far, we are just about to get started, but many things are already in place, and we are keen on exploring the possibilities, but also the disadvantages of our preliminary ideas with you! 29 / 30
history now, but suppose we follow up on our standardised annotation of linguistic data on the micro-level, we can harvest cross-linguistic data on the macro-level. If we expand the analyses of verbal derivation in Khroskyabs to more languages of the Sino-Tibetan family, we may be able to substantiate the typological plausibility of hypotheses regarding Chinese “star”, reliably reconstruct the meaning of its stem, determine the function of the prefix, and draw explicit pathways of semantic change. 30 / 30
But many word histories are similar. If we start classifying them, what we may learn can go easily beyond the history of the word for “star” in Chinese. 30 / 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}