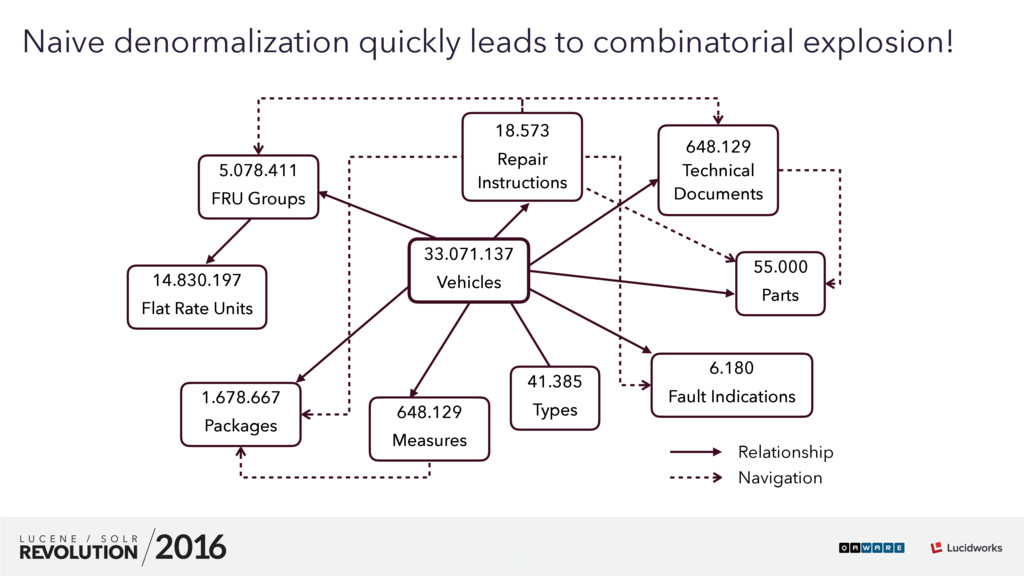
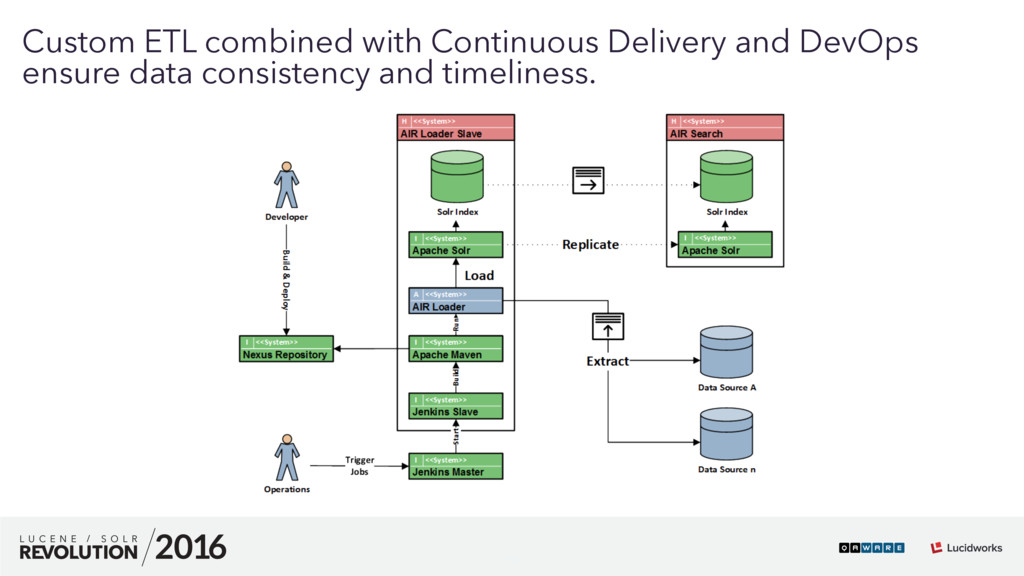
We are searching the unknown. How can you find hidden and unknown relationships in unrelated relational data silos? How can you search the relevant information in a 10^56 dimensional space? How do you create a consistent yet up to date information network for over 20 languages on a daily basis? And how on earth do you convince IT governance to let you use Solr for this kind of job? All this sounds impossible? This talk will give the answers and present a detailed case study and success story about how we used Apache Solr to build a search based business intelligence and automotive information research application for a major German car manufacturer. This talk has been presented at the Lucene/Solr Revolution 2016 in Boston. #LuceneSolrRev #ApacheSolr #qaware
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![& Mario-Leander Reimer Chief Technologist, QAware GmbH [email protected] https://www.qaware.de https://slideshare.net/MarioLeanderReimer/](https://files.speakerdeck.com/presentations/85b4117327344881bf1a41a11756cc3e/slide_31.jpg){kind=link}