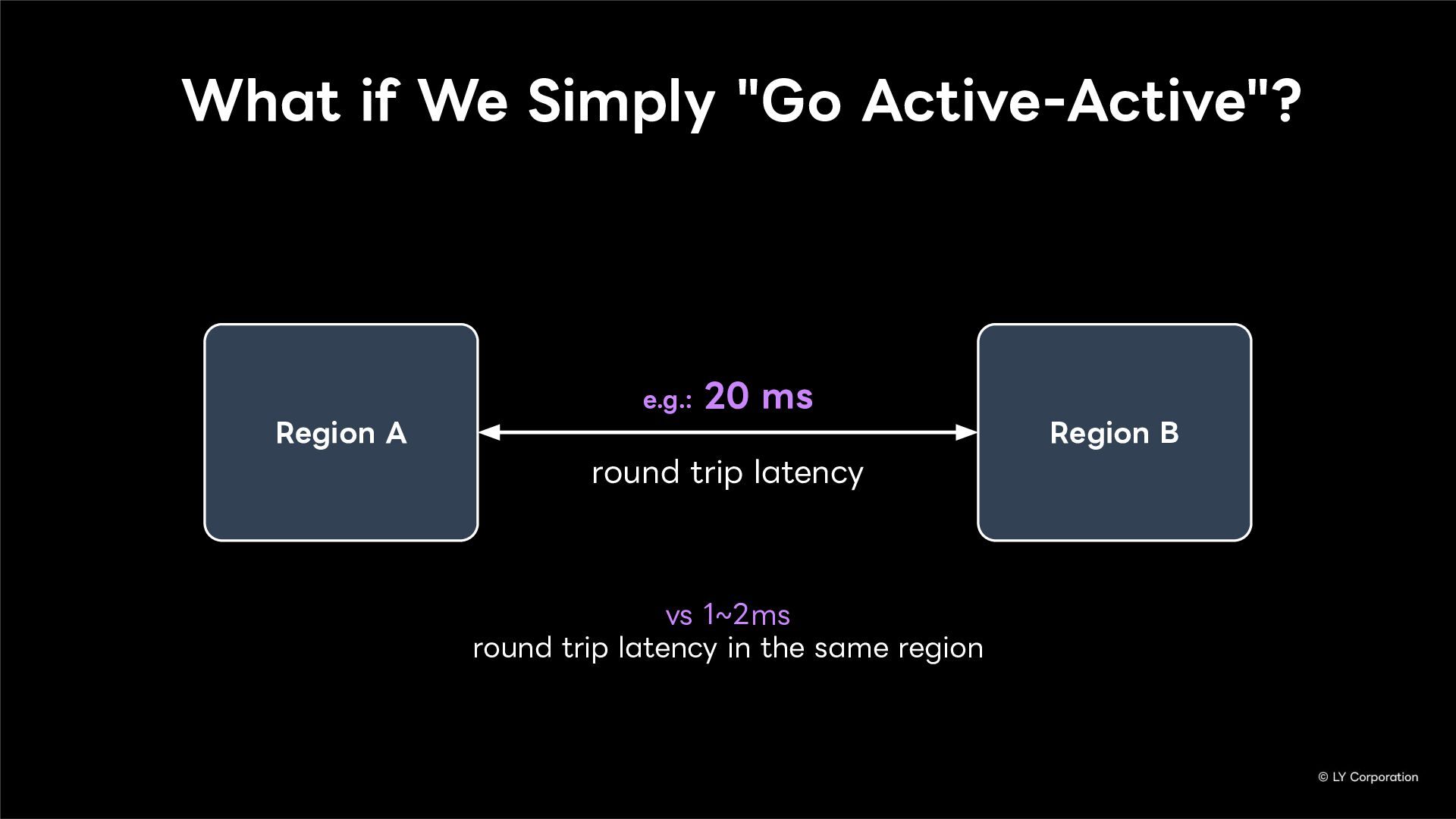
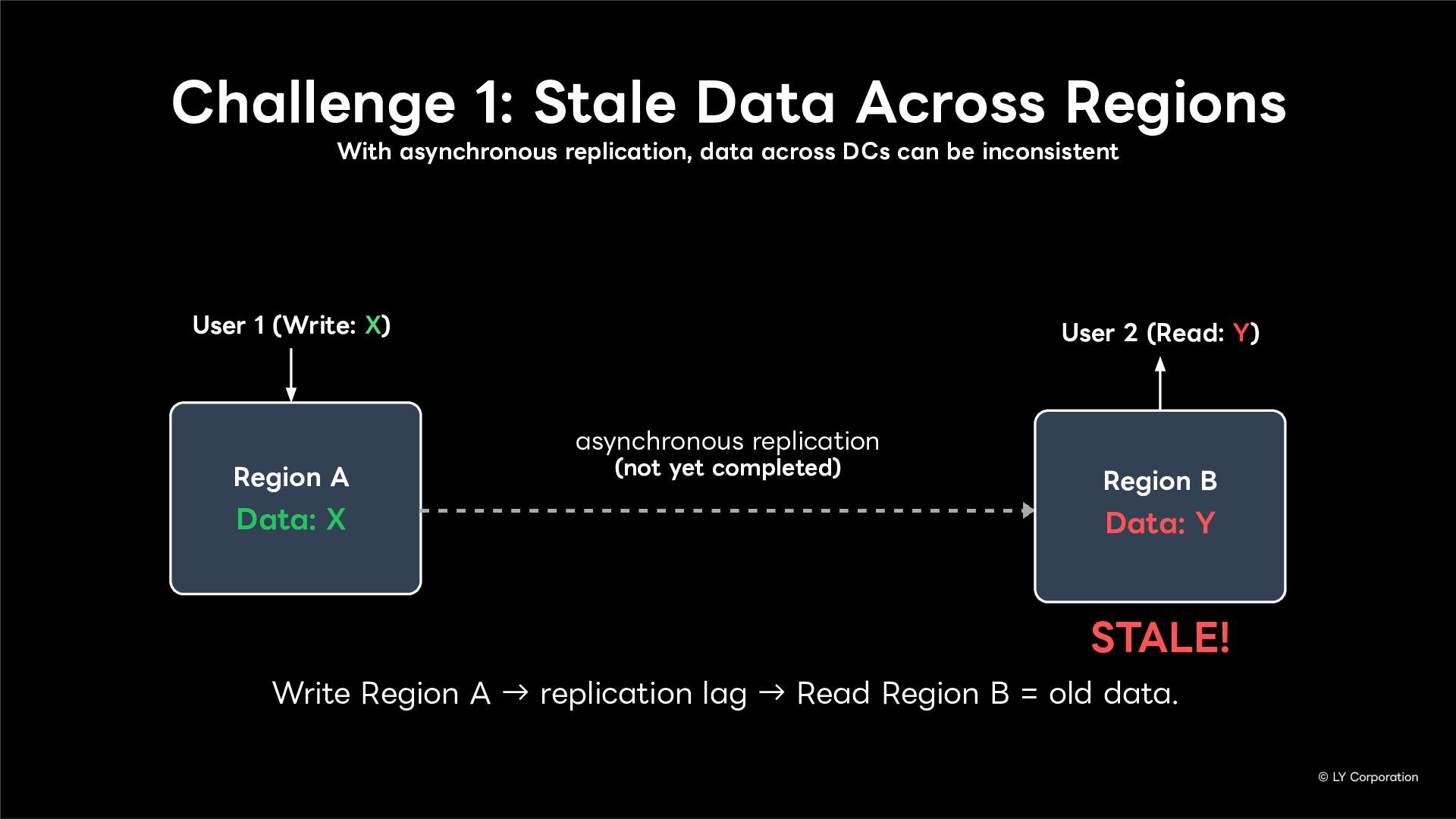
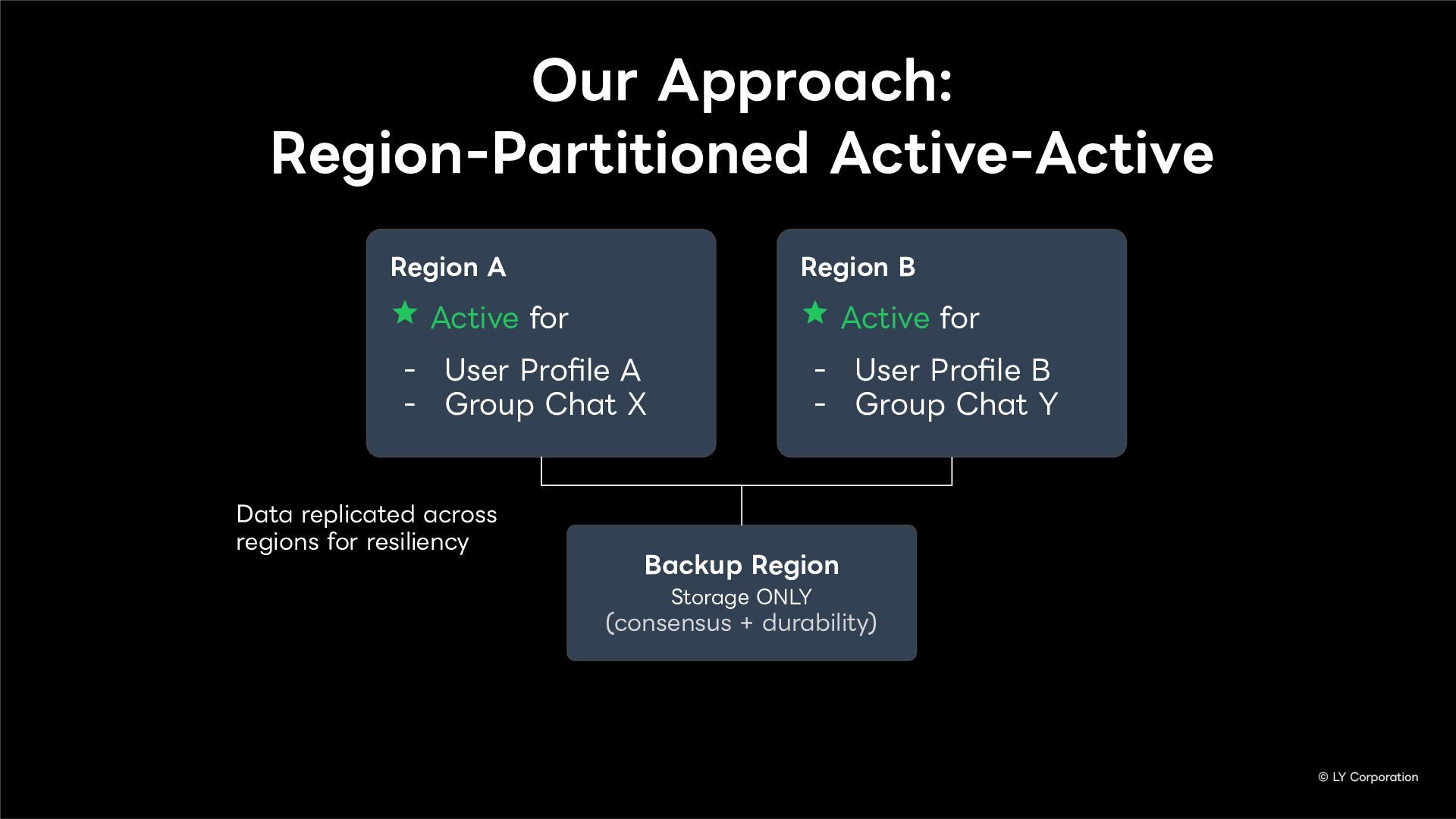
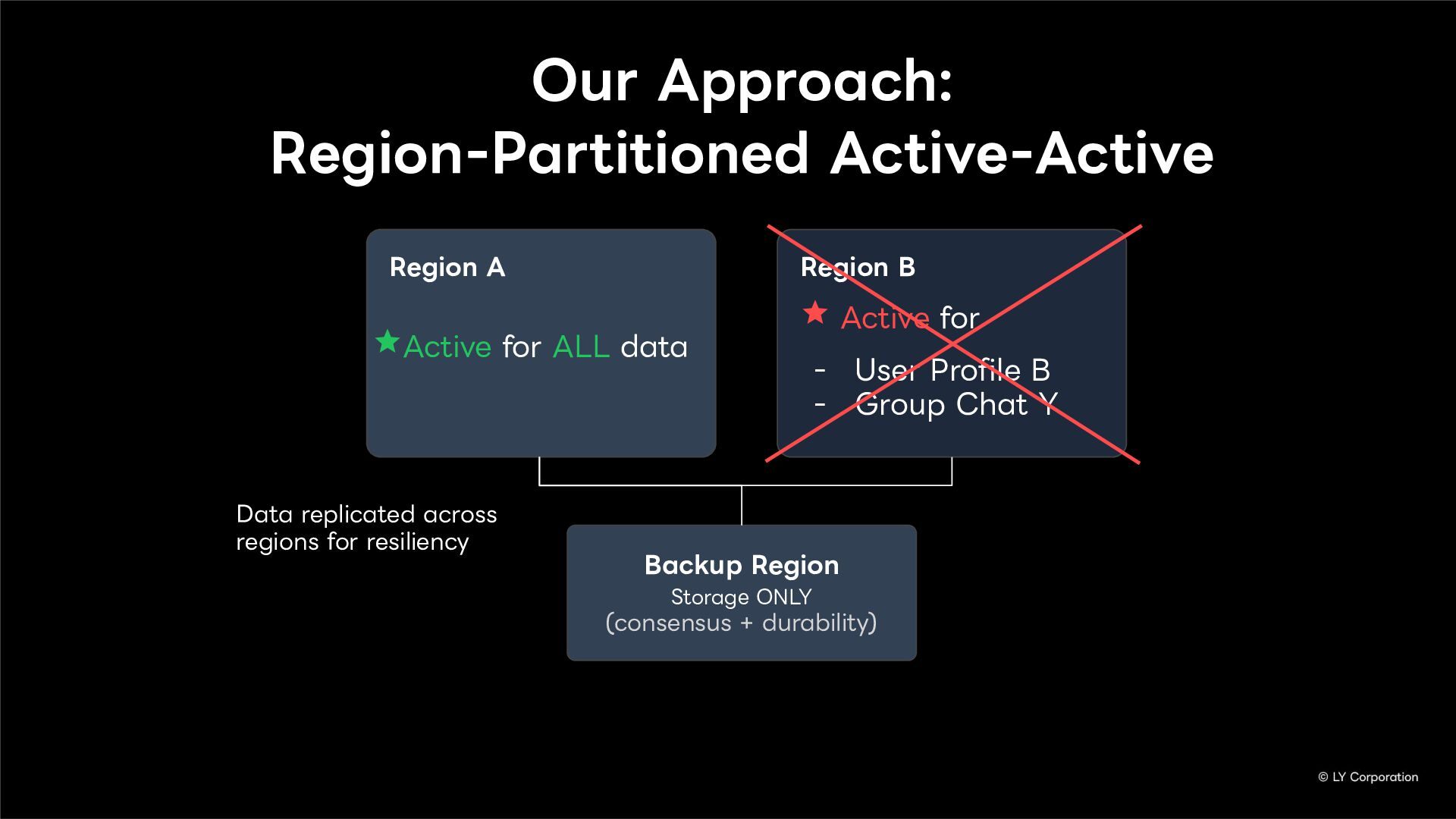
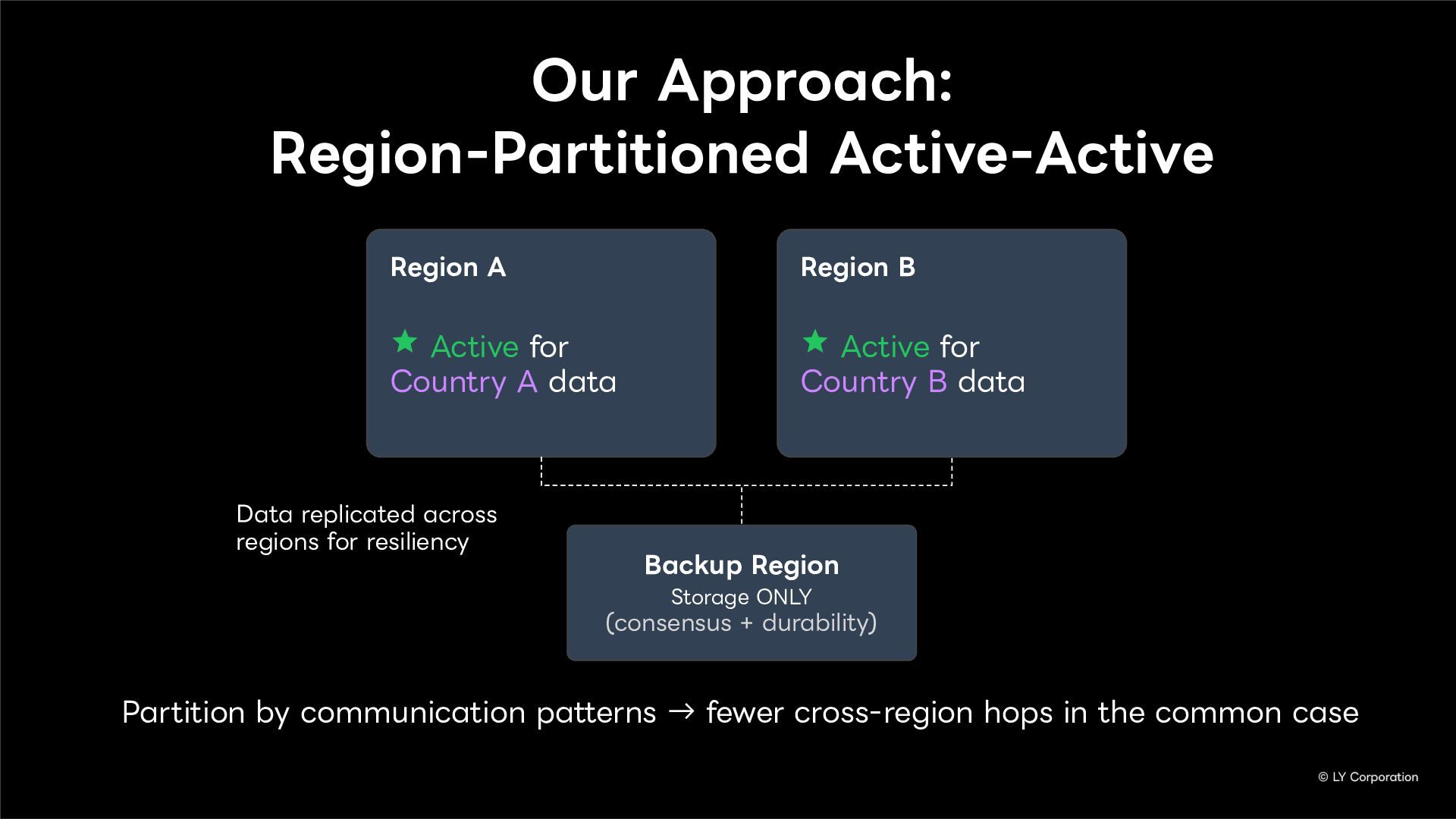
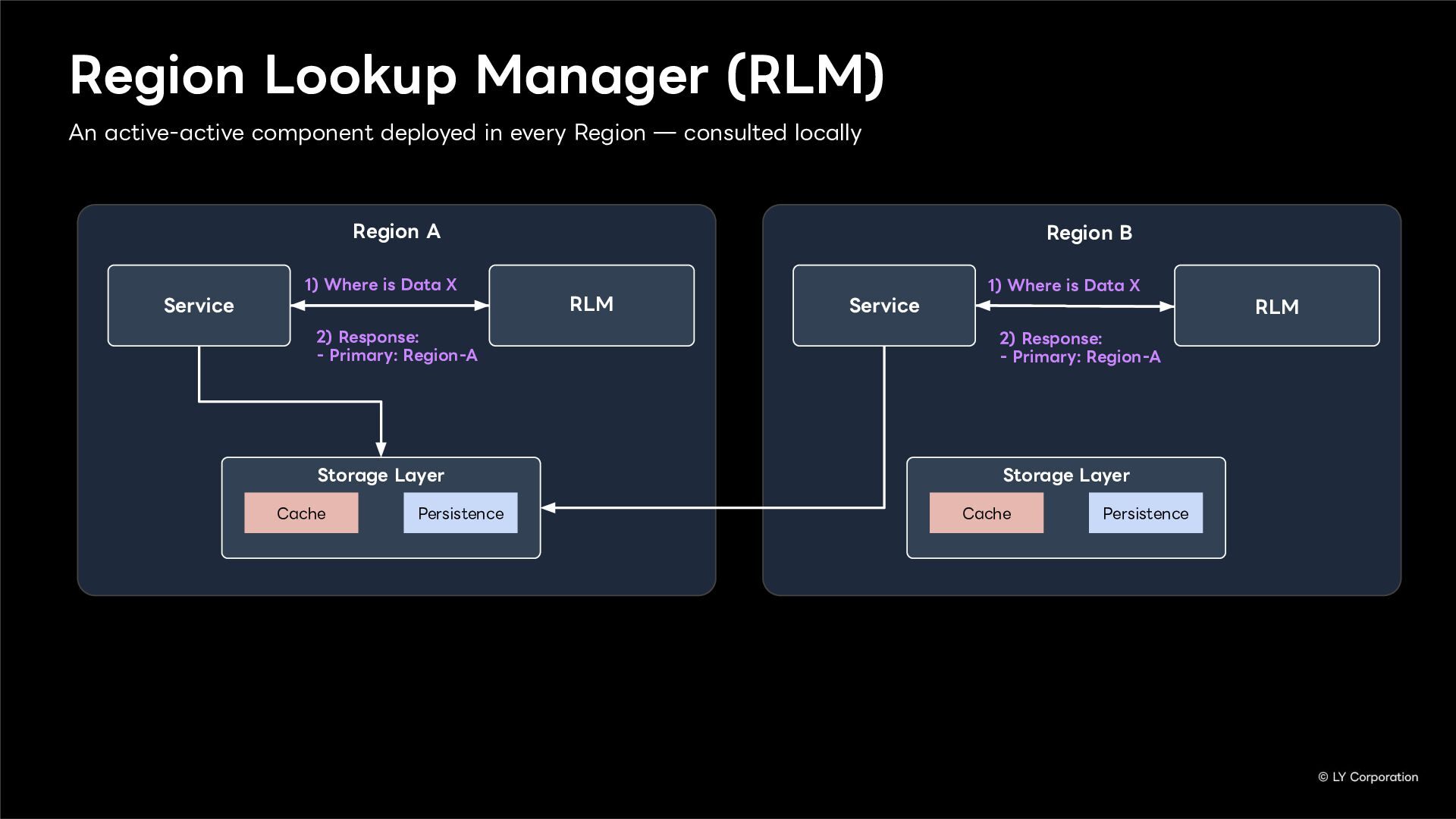
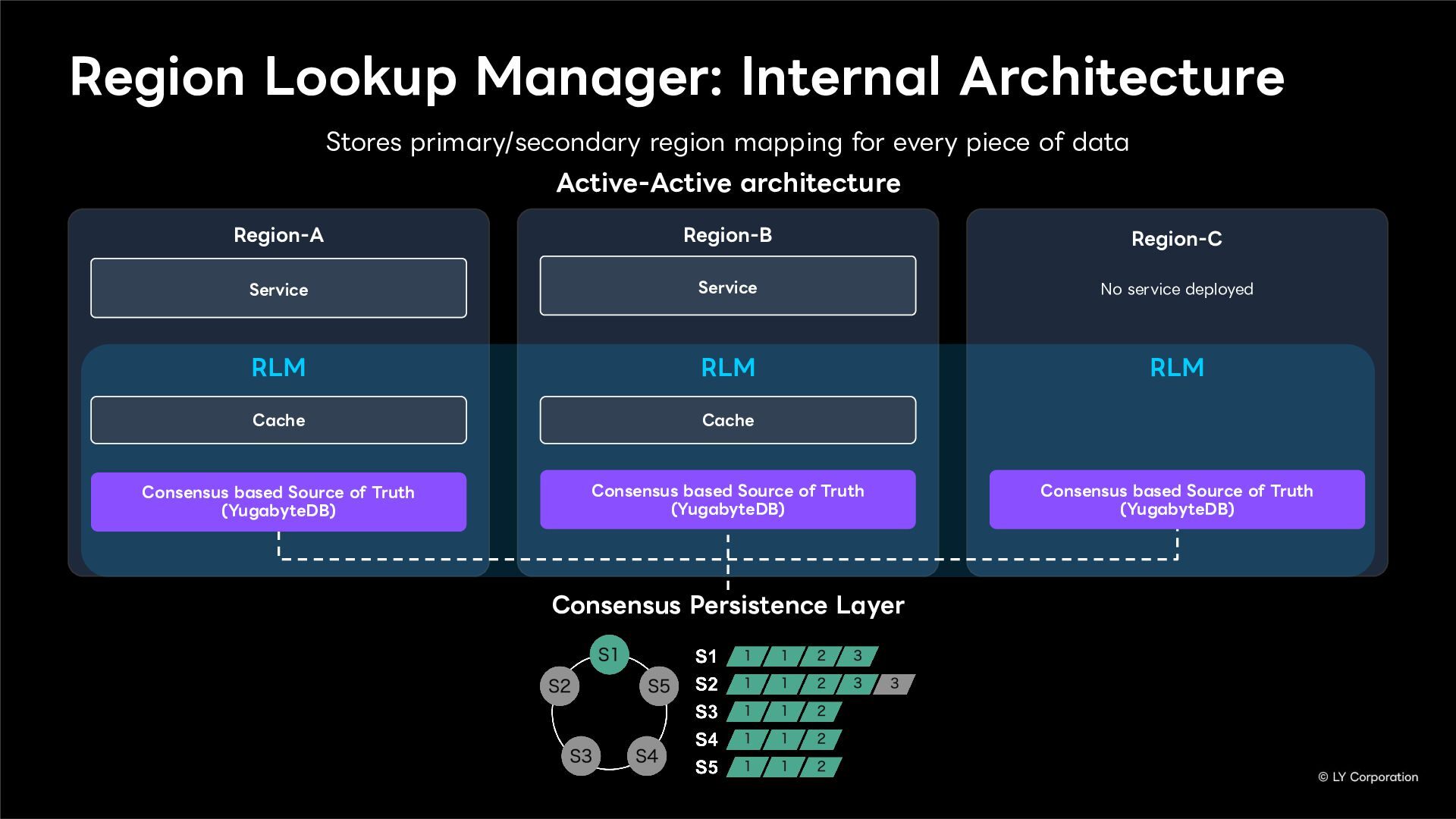
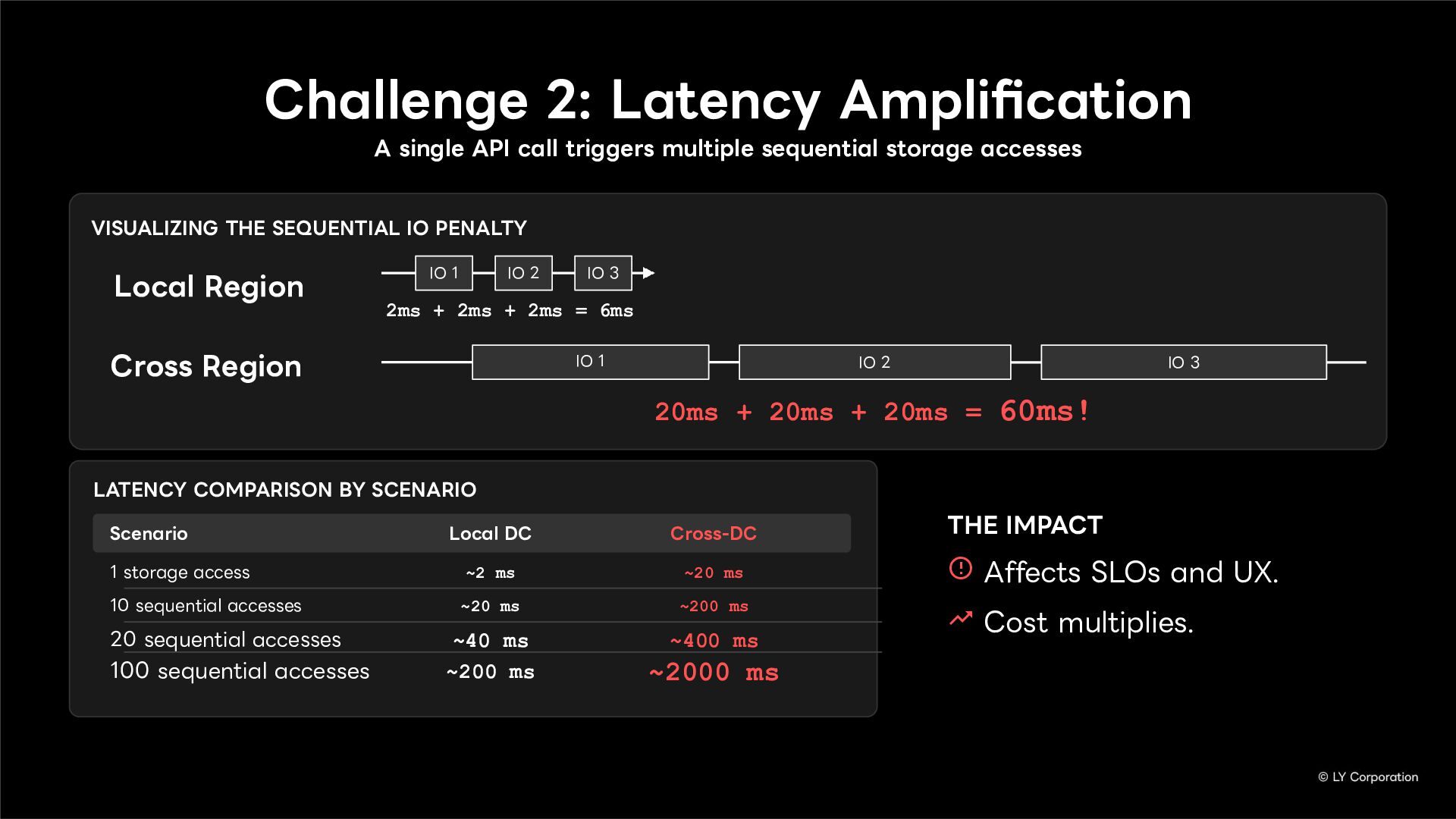
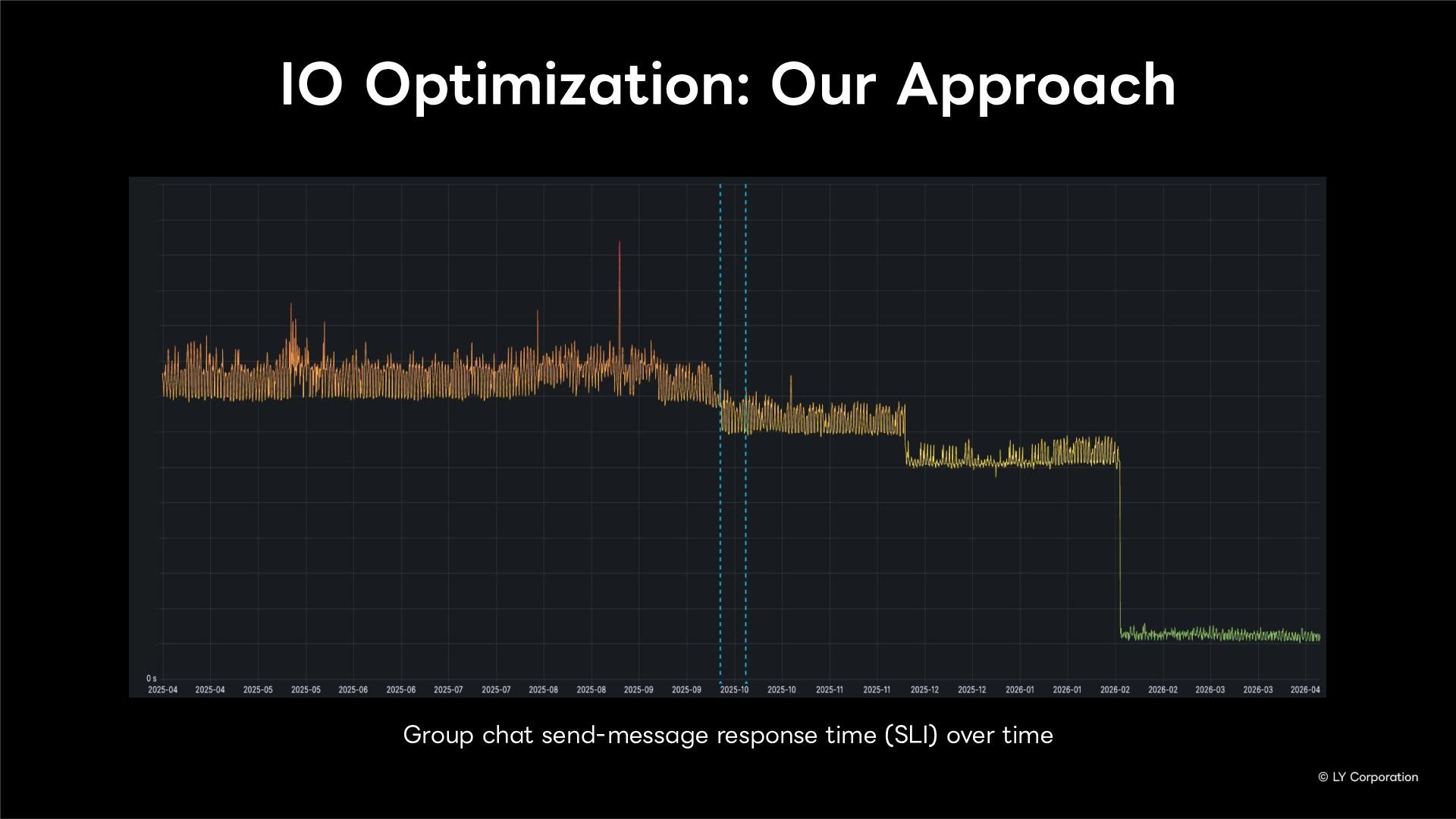
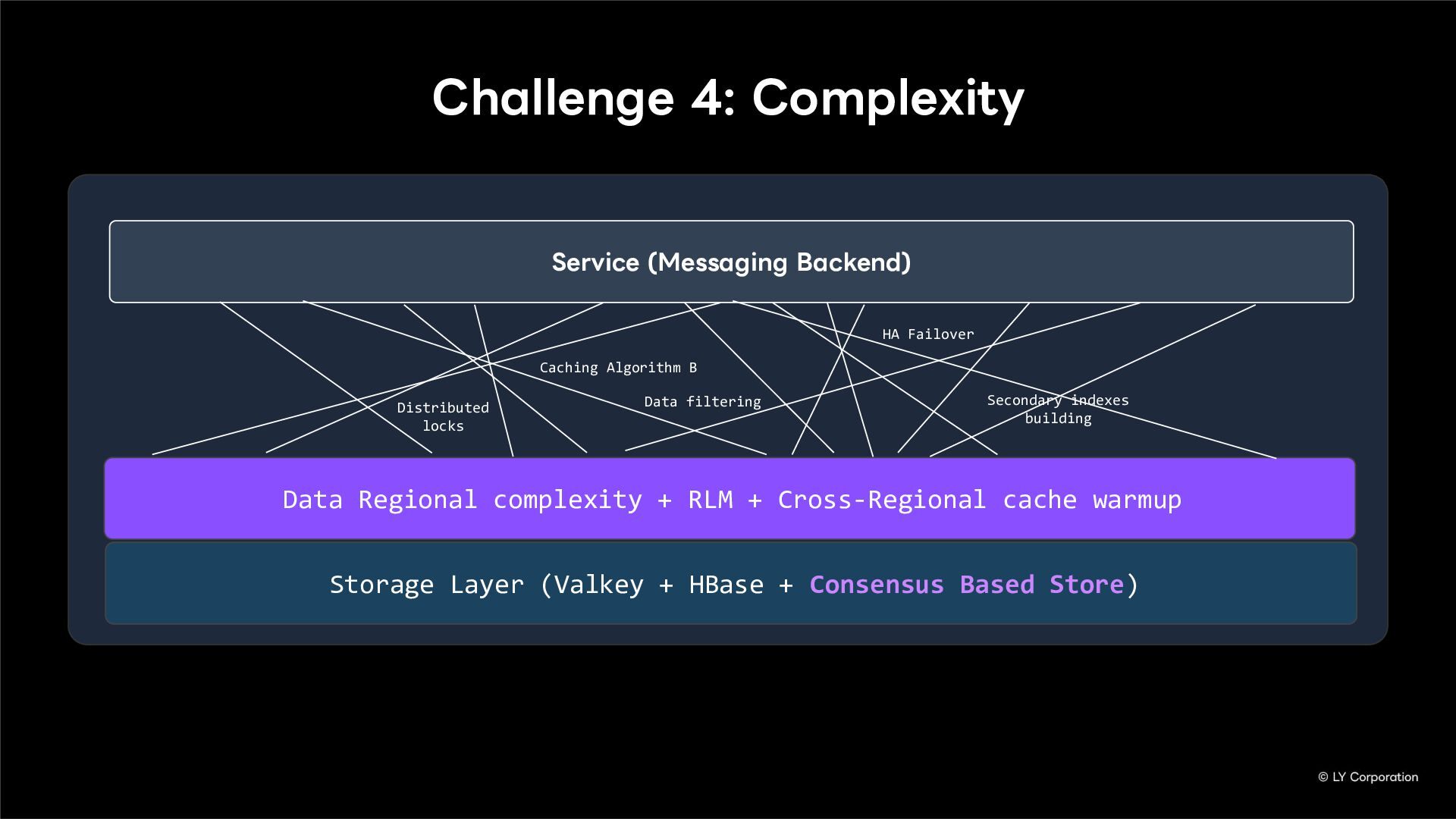
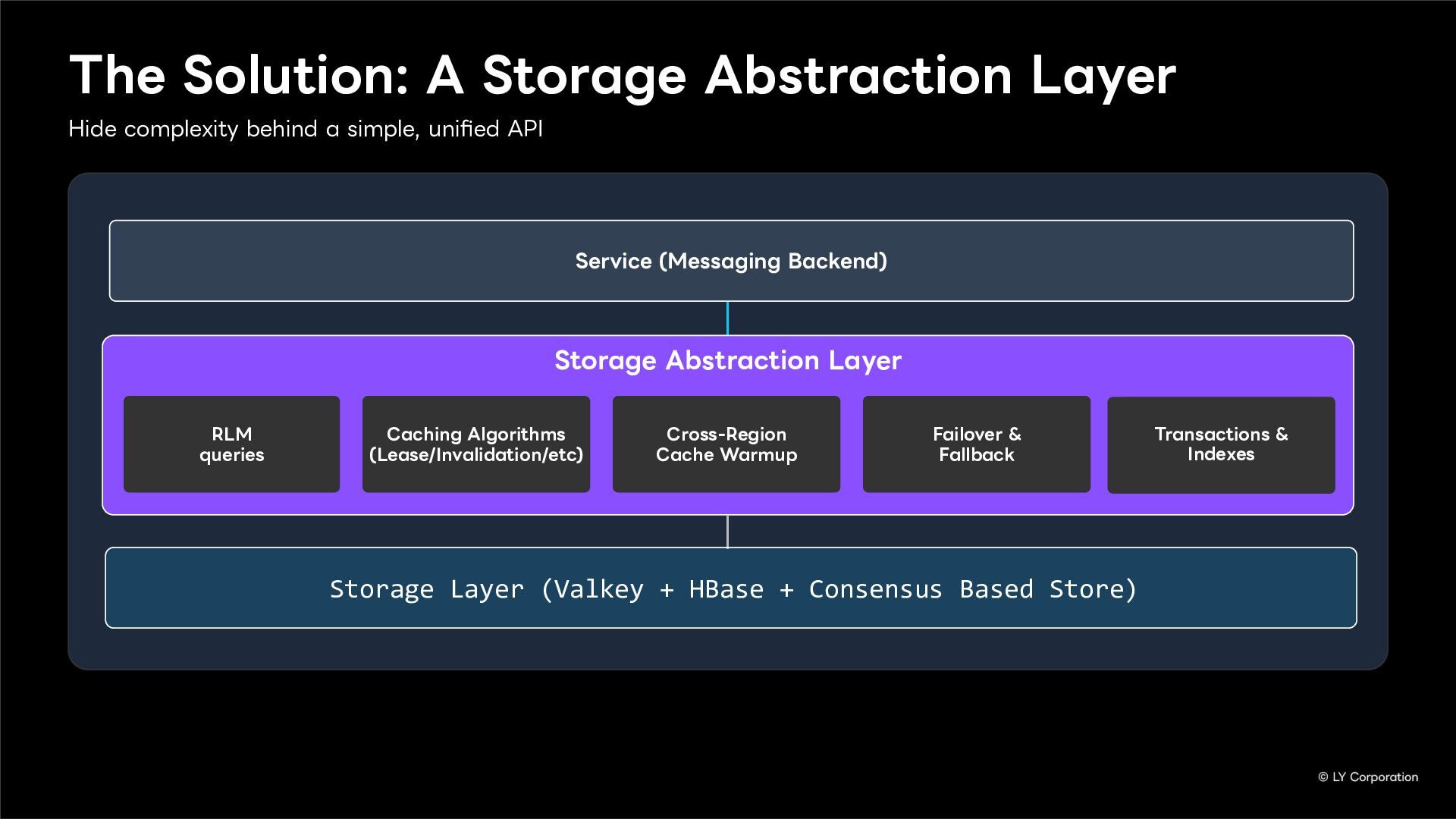
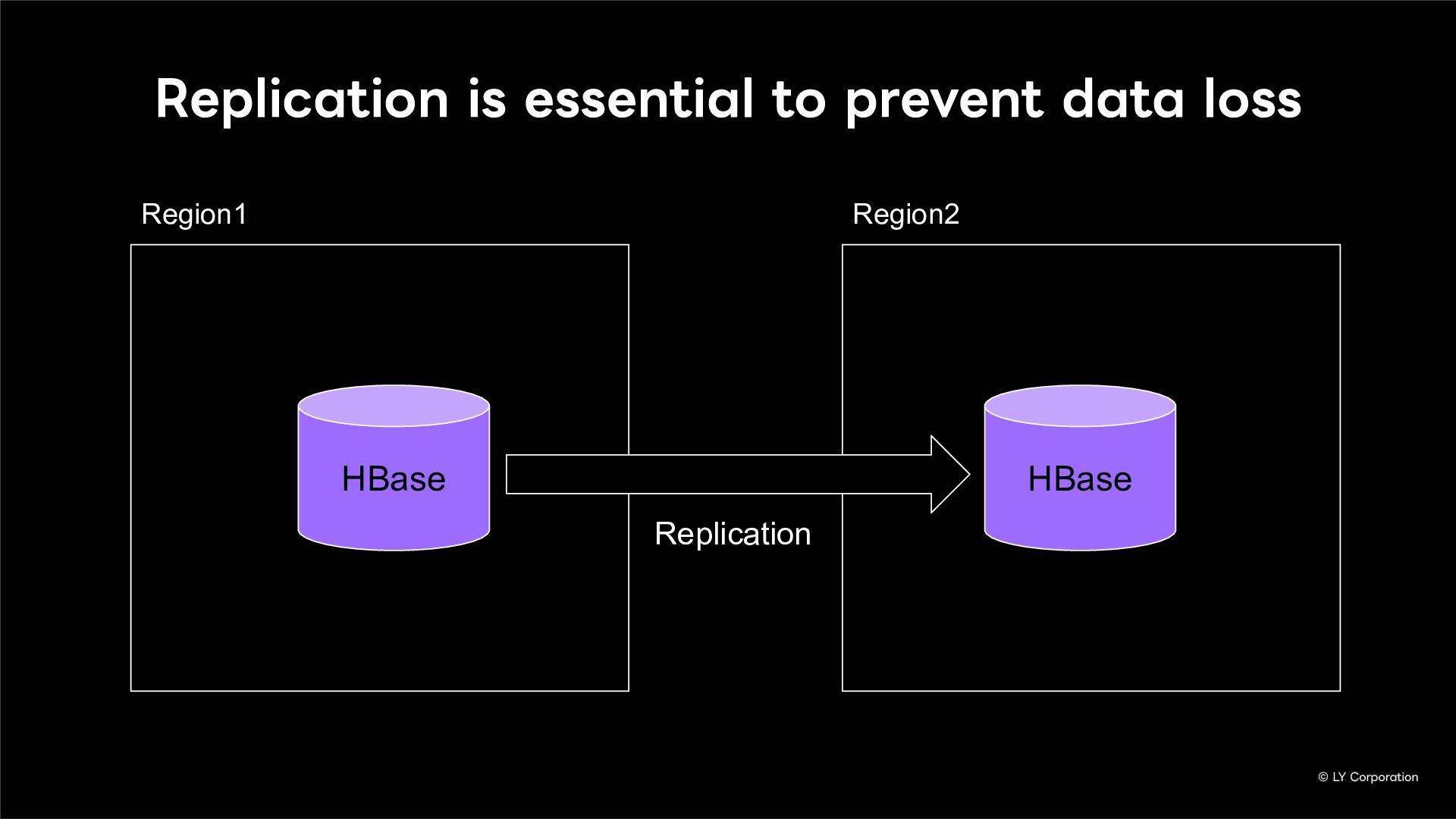
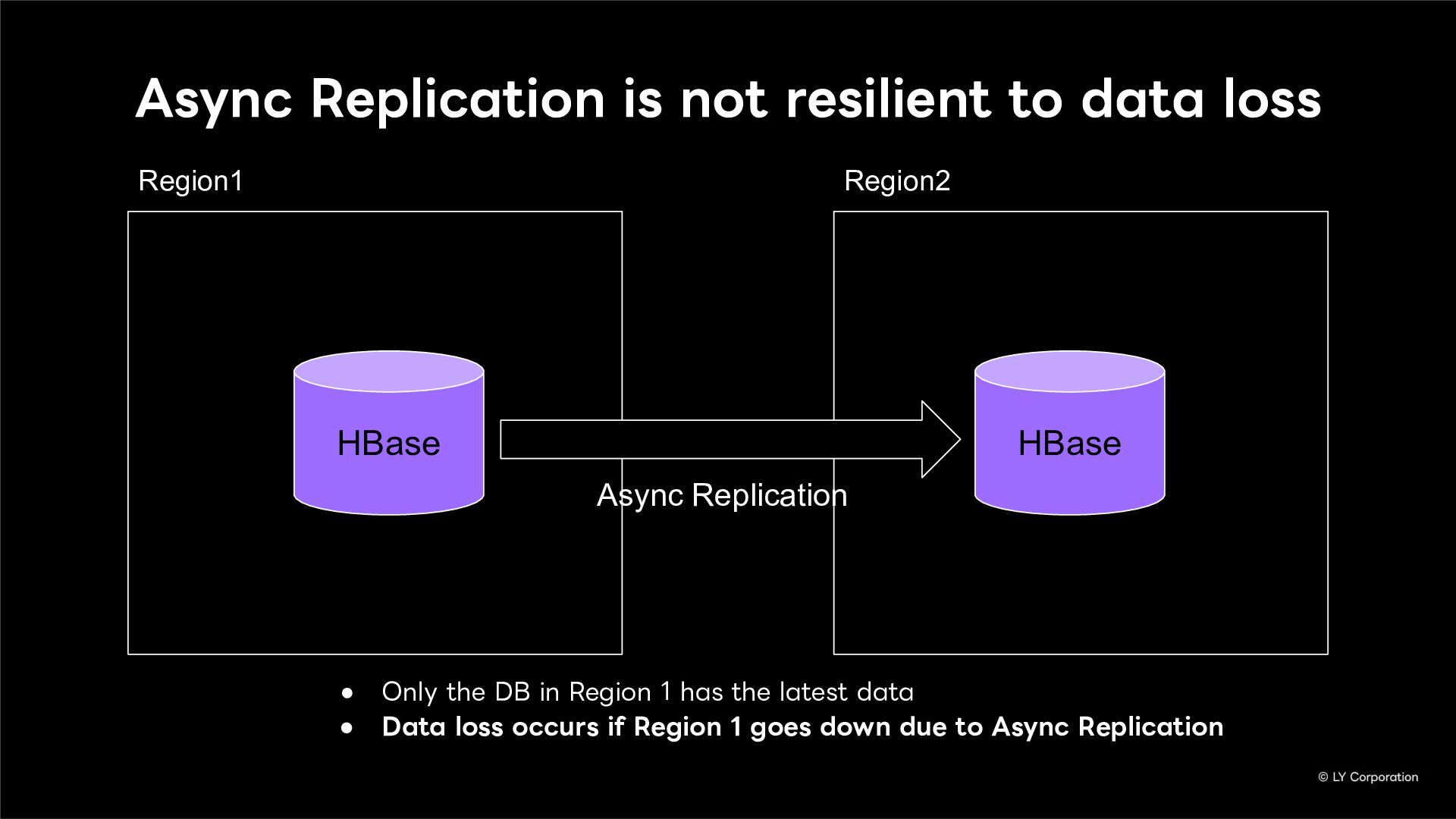
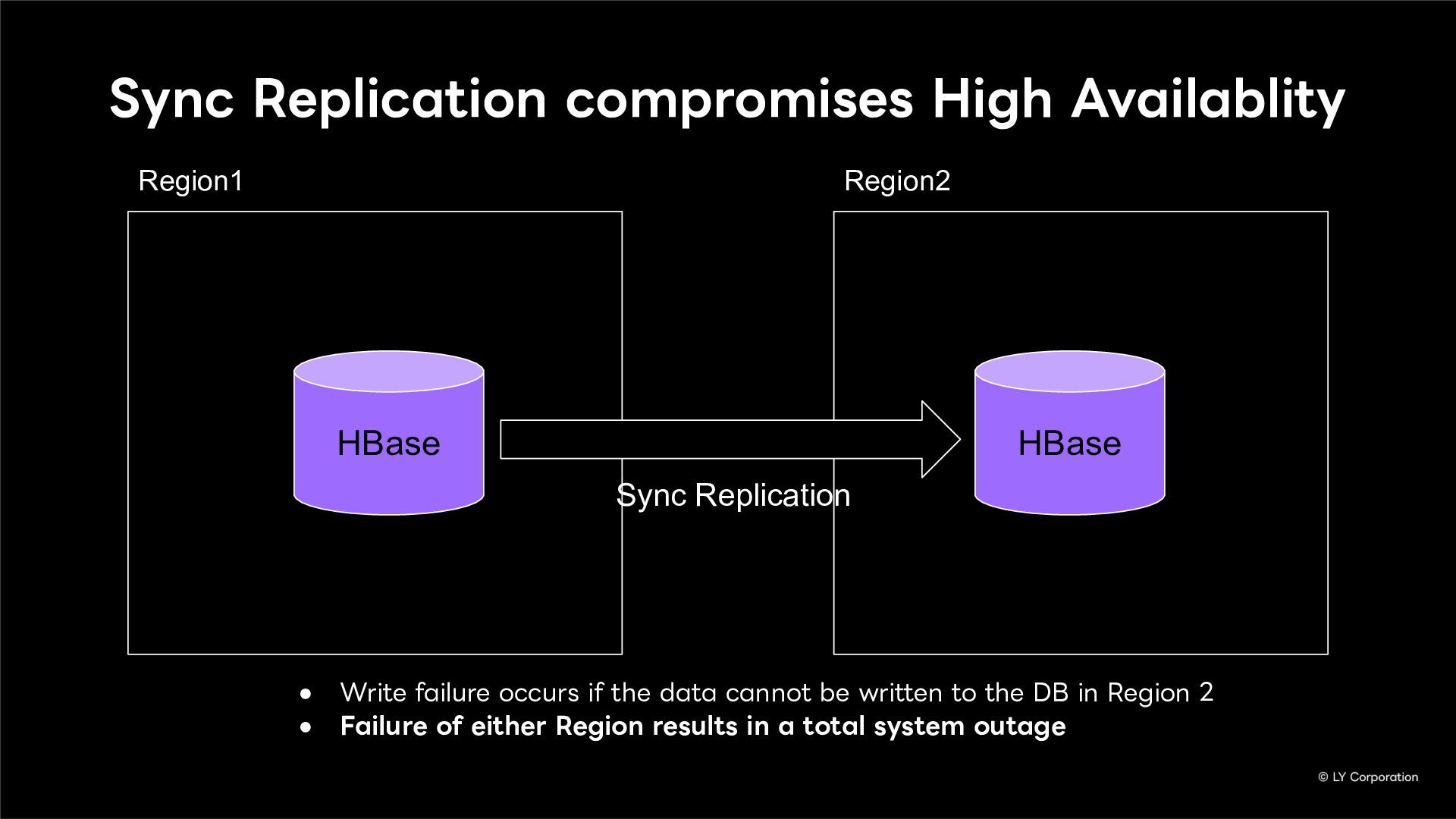
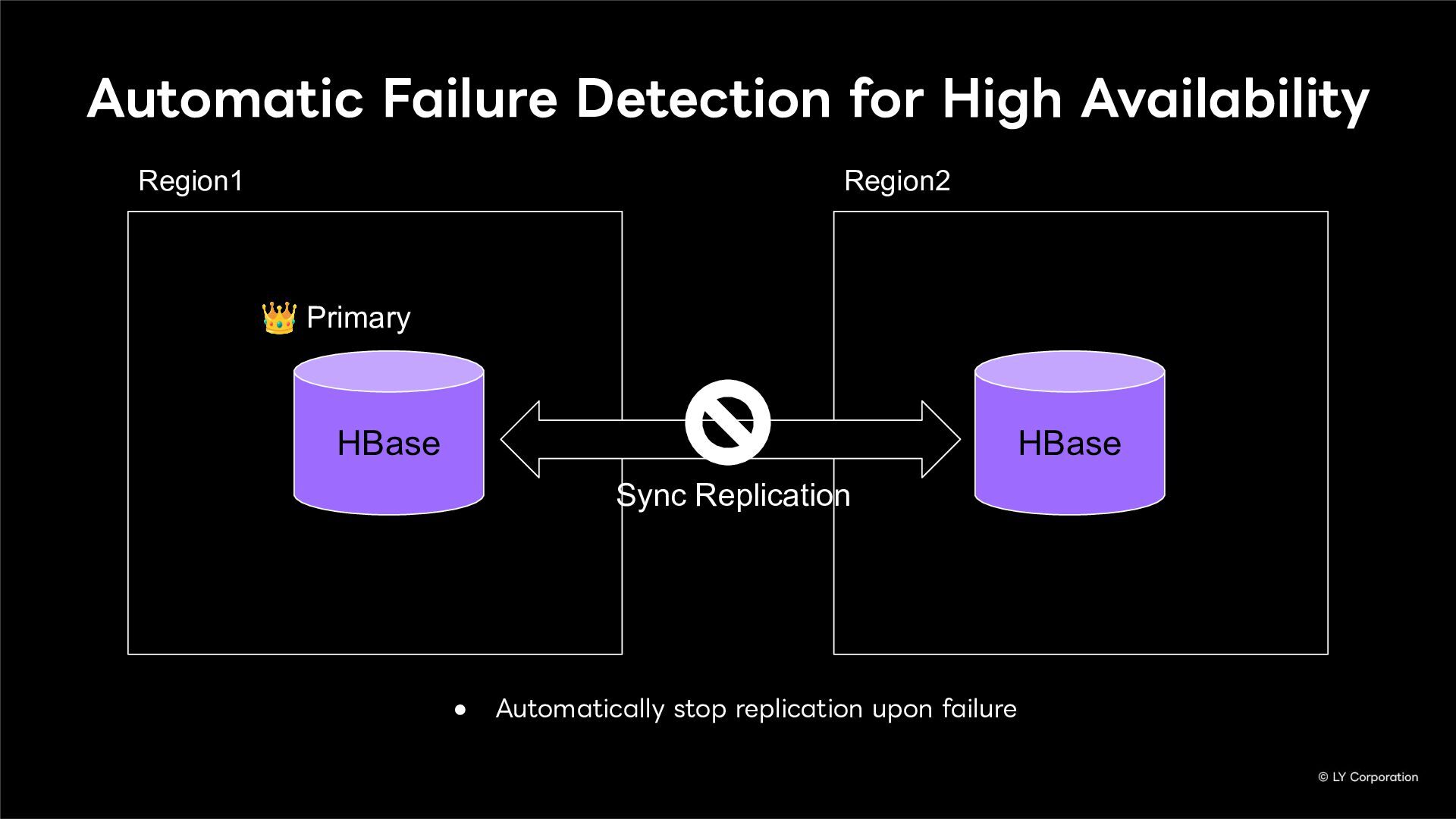
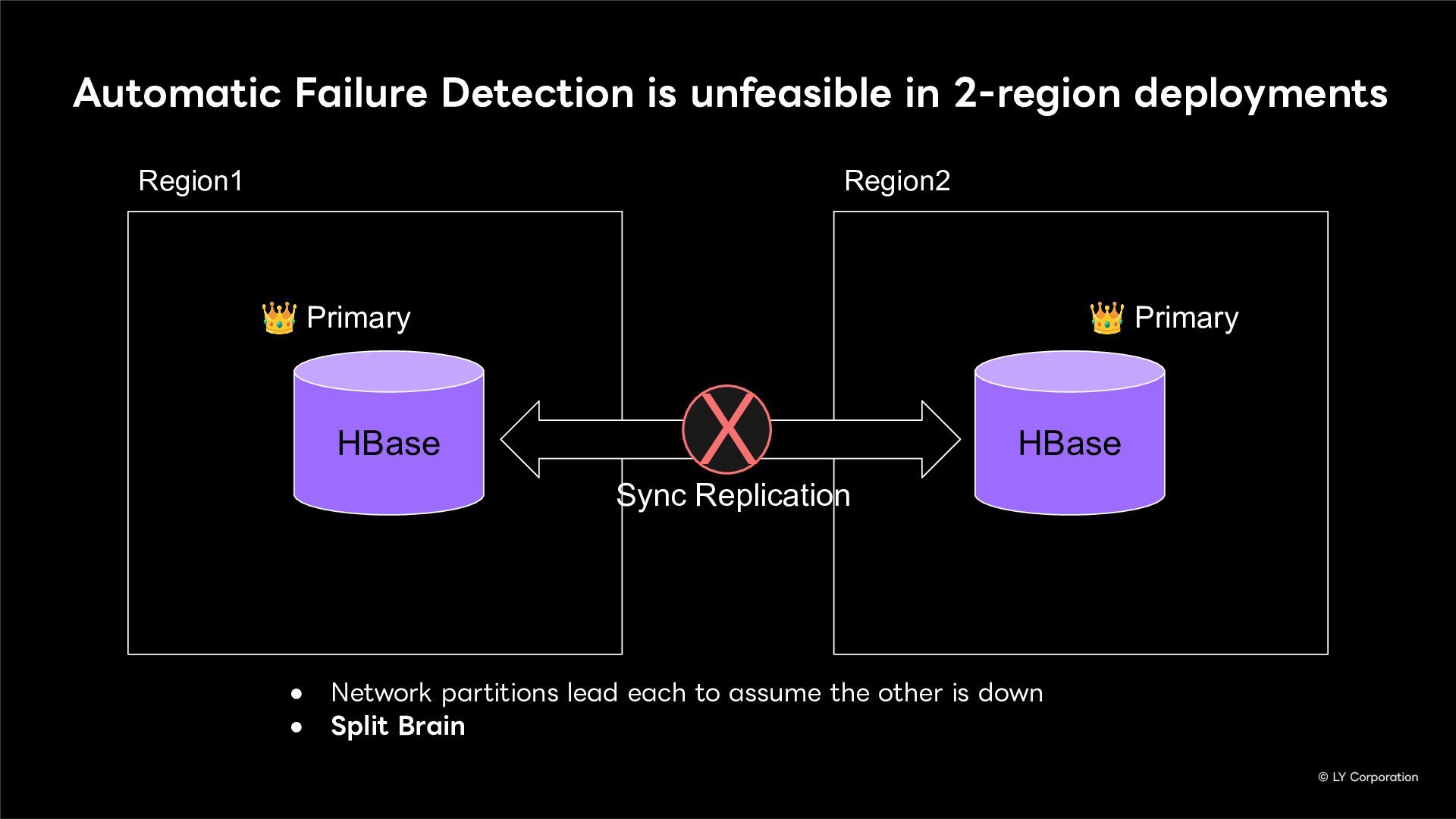
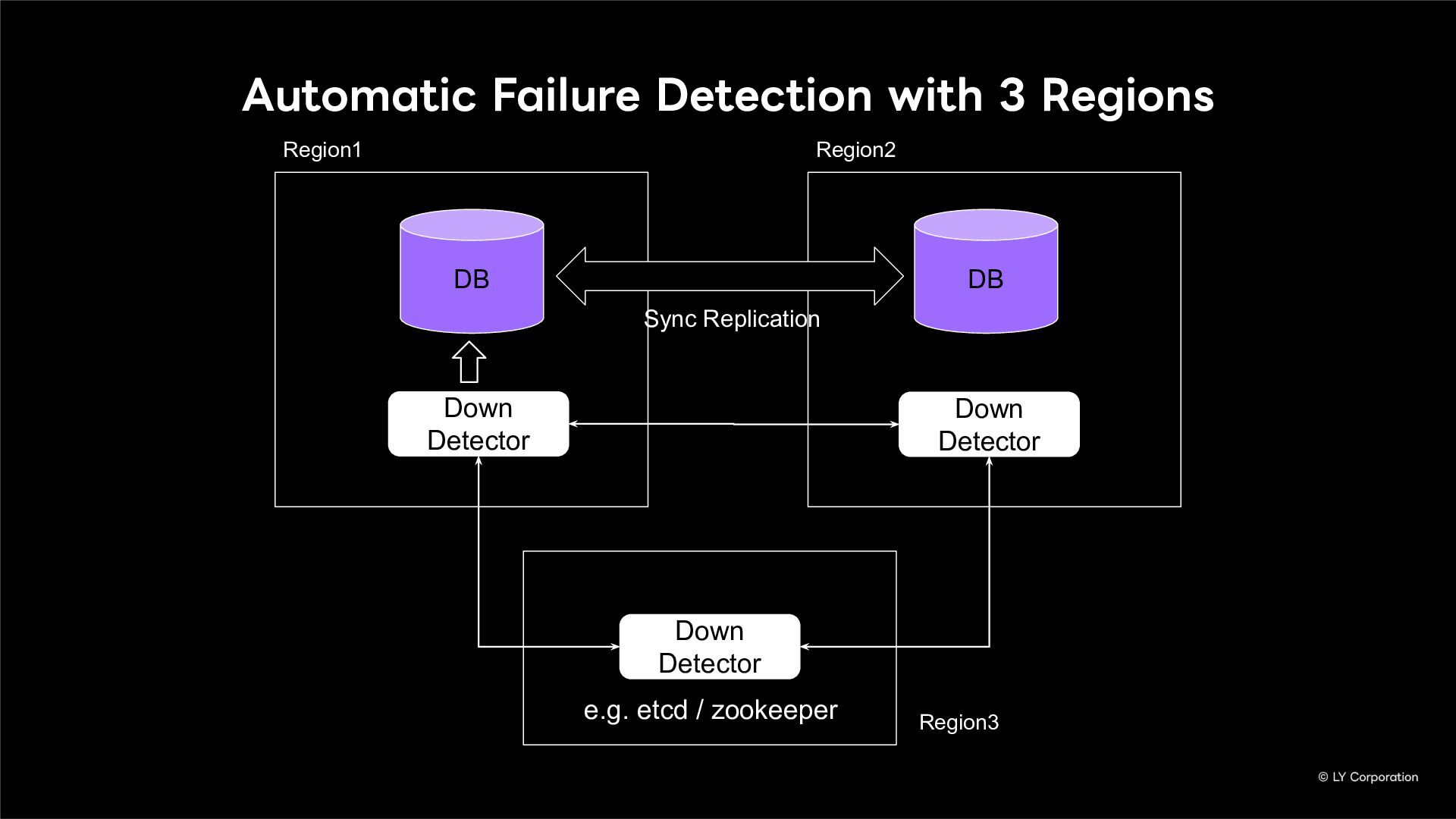
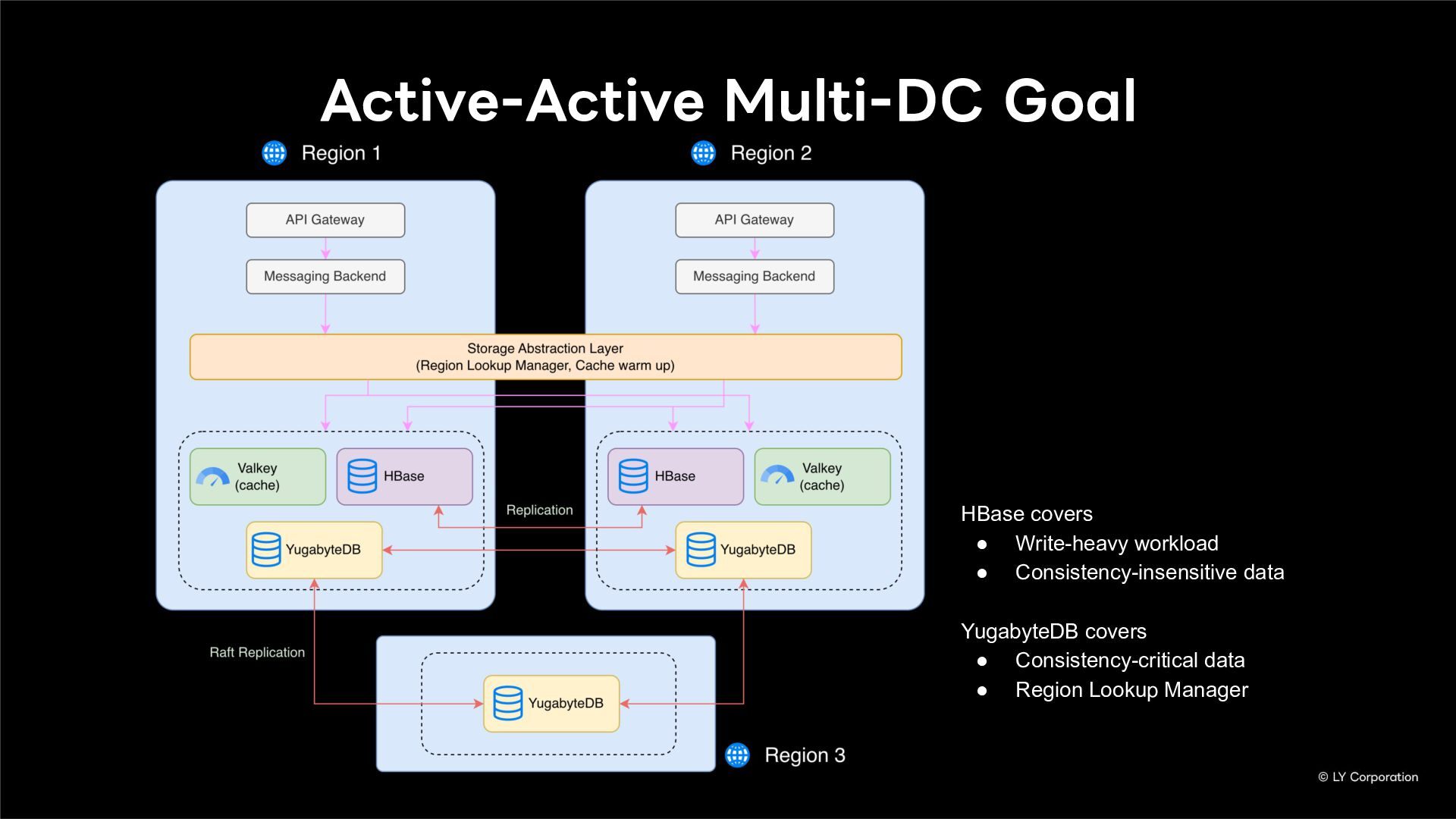
To further enhance business continuity, the LINE Messaging service is embarking on a transition toward a multi-datacenter Active-Active architecture. Implementing this architecture at LINE's immense scale and high-traffic volume presents unique and significant challenges for databases and distributed systems alike.
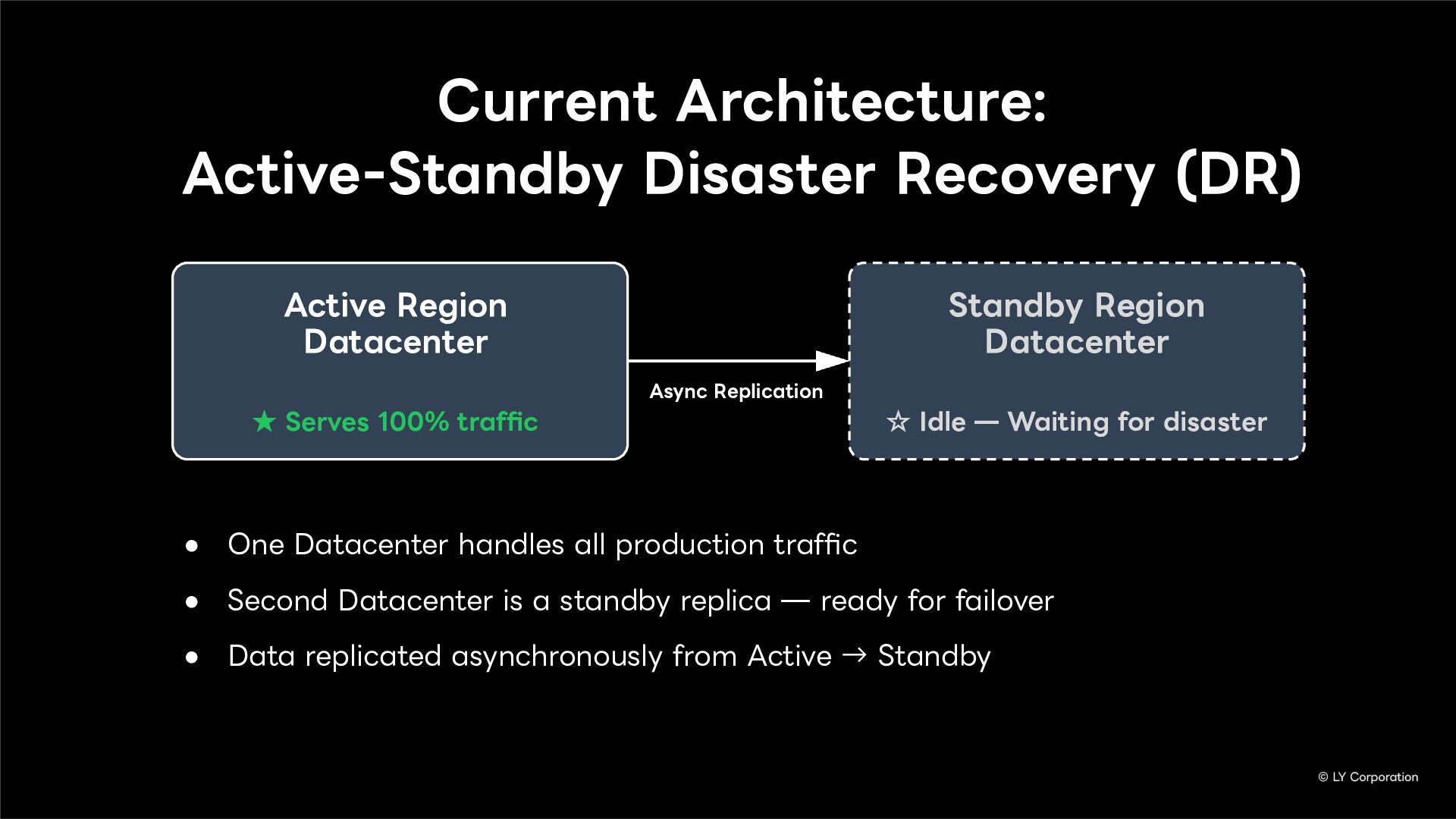
In this session, we will explore our journey through this architectural evolution. We will first discuss the current status and limitations of our existing Disaster Recovery (DR) framework, followed by the insights and reasoning behind adopting a multi-datacenter Active-Active setup. We will also share the technical hurdles we faced along the way and our vision for future challenges in keeping one of the world's largest messaging platforms resilient.
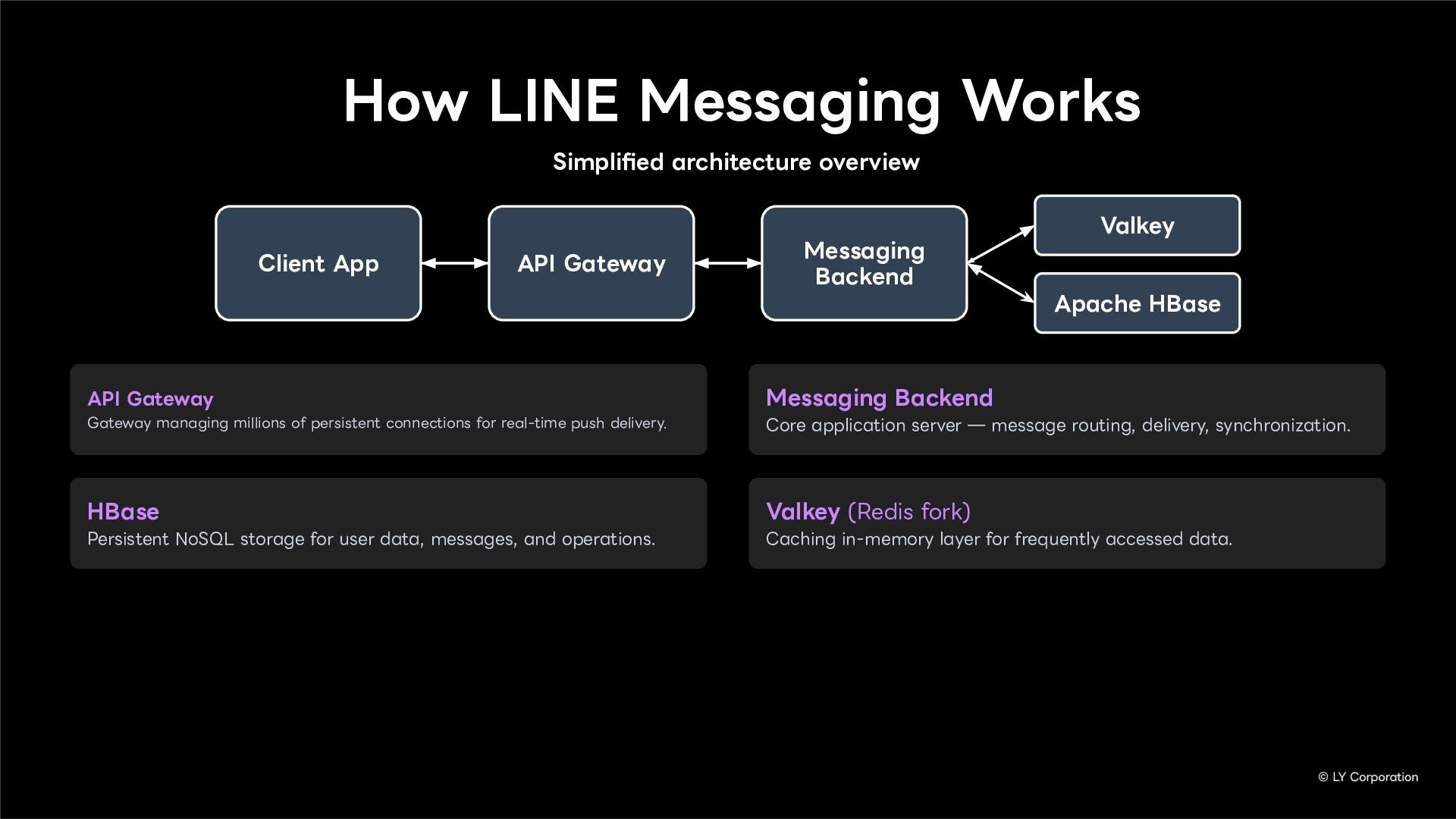
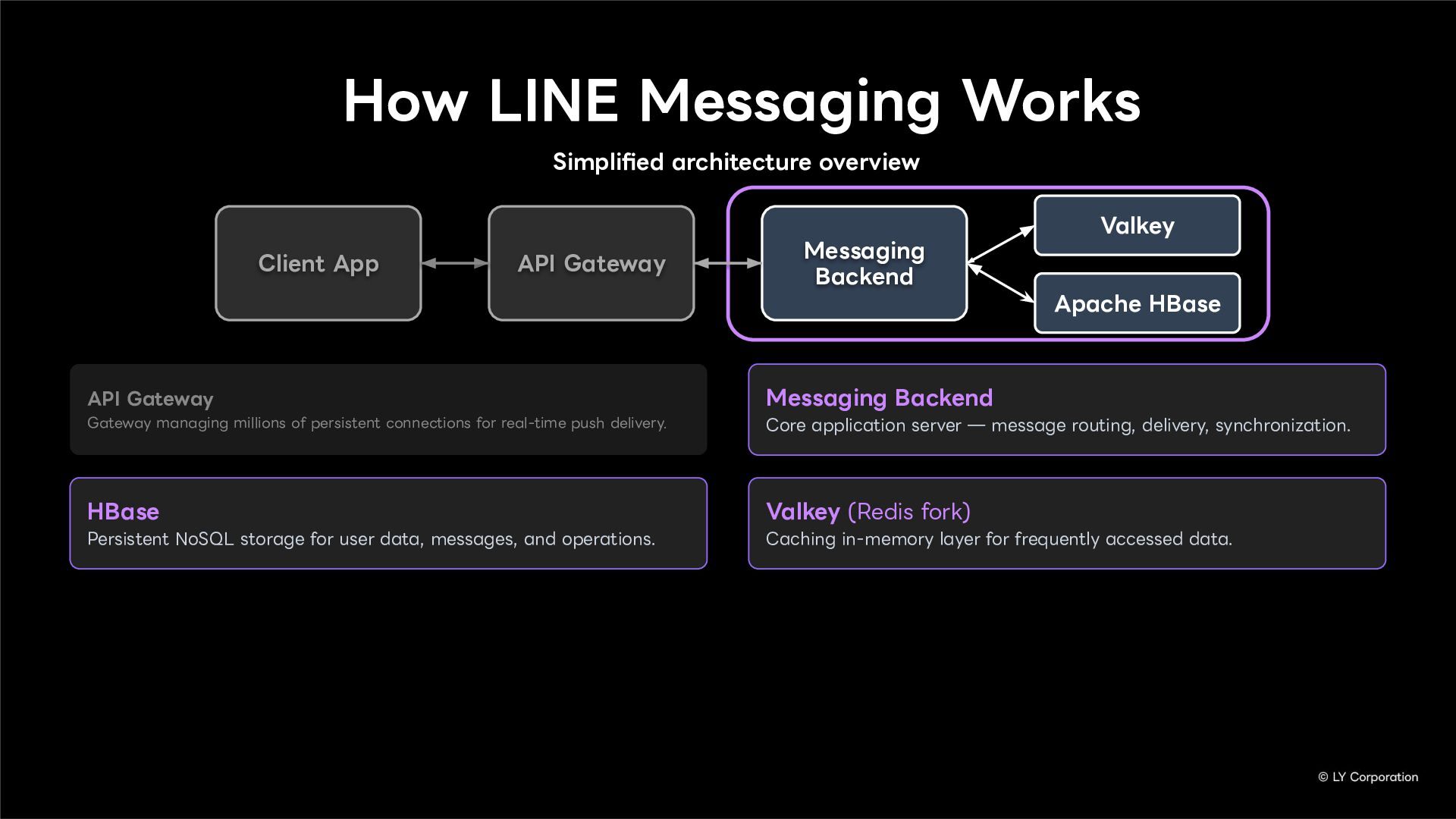
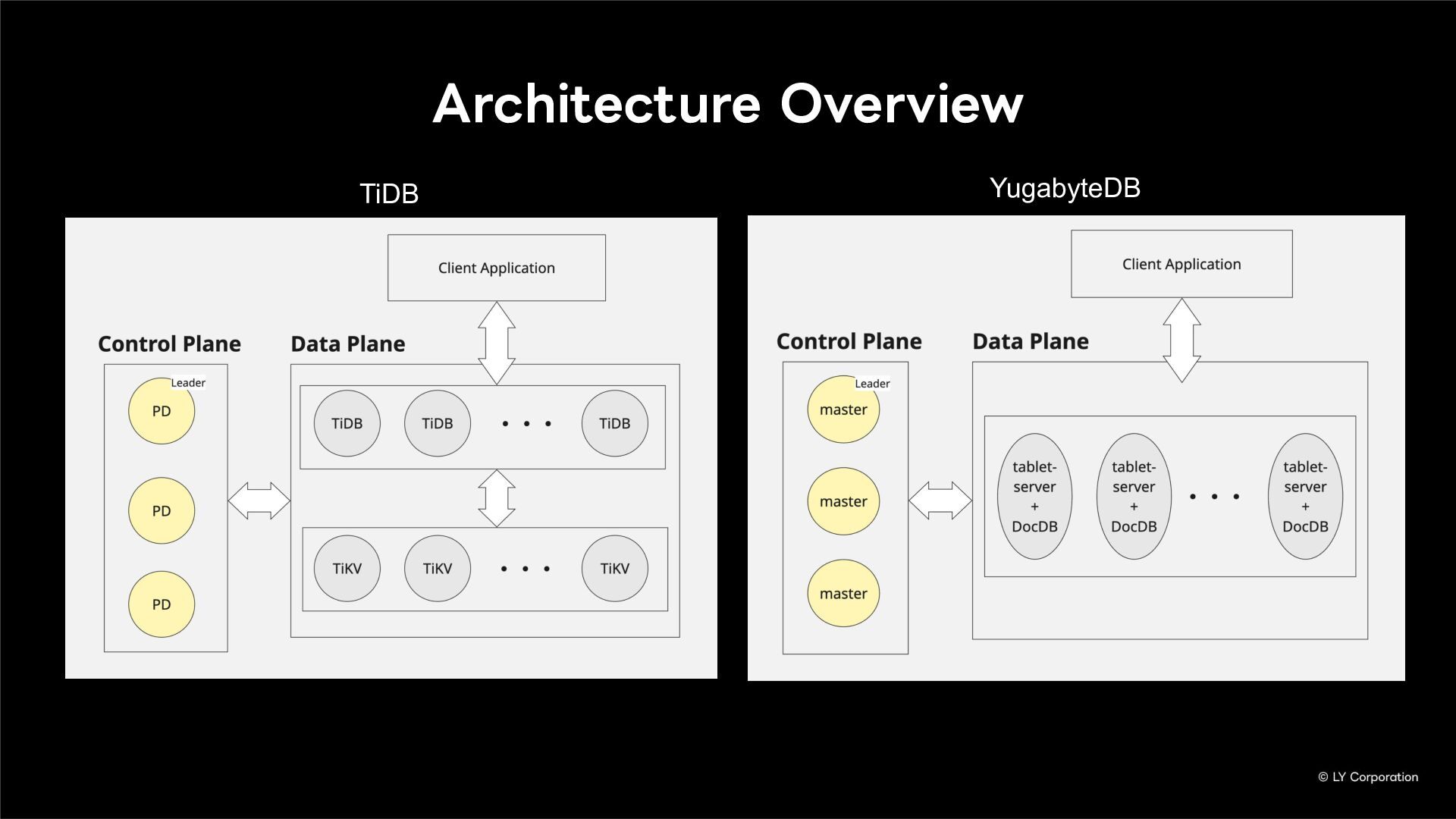
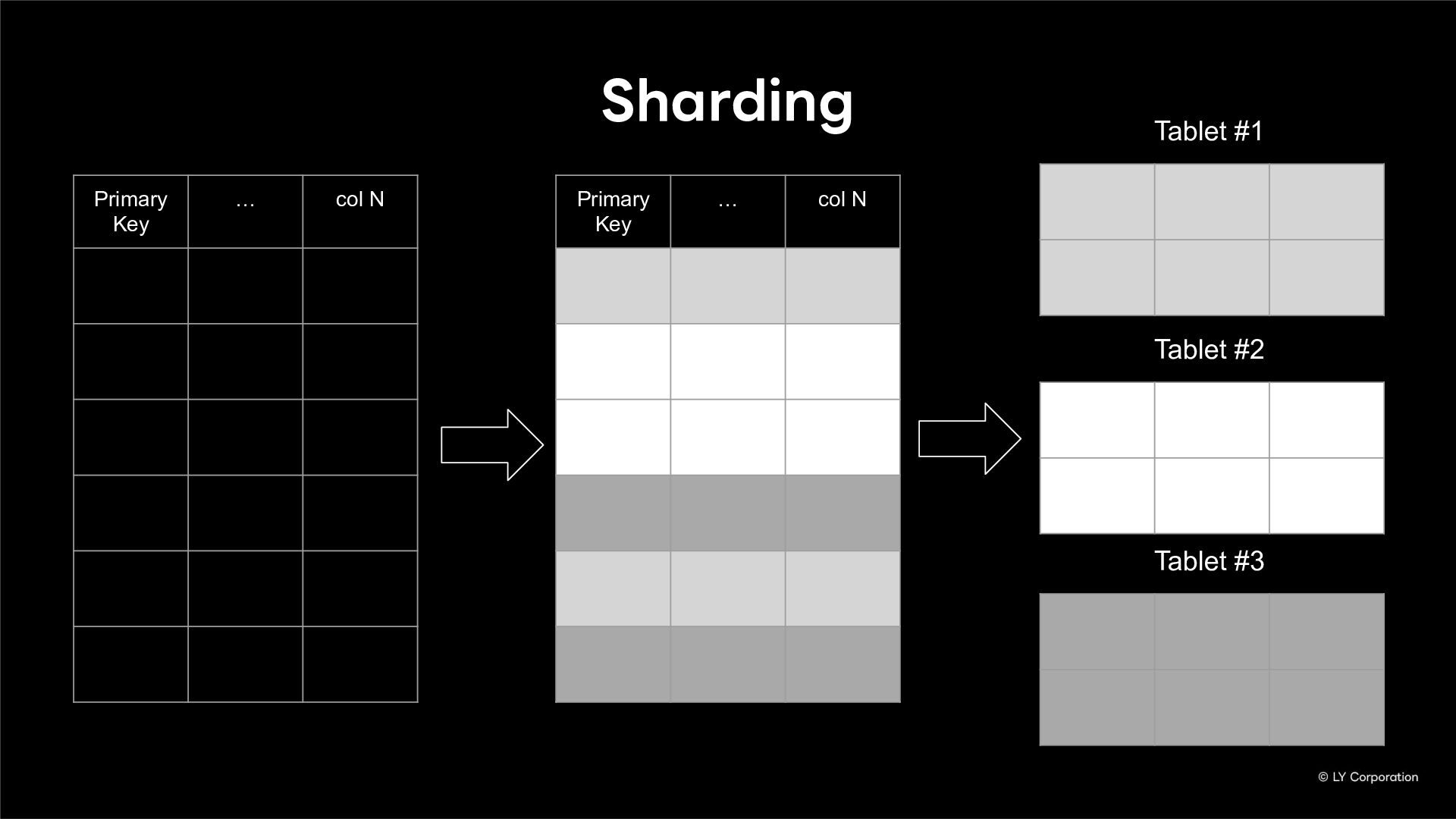
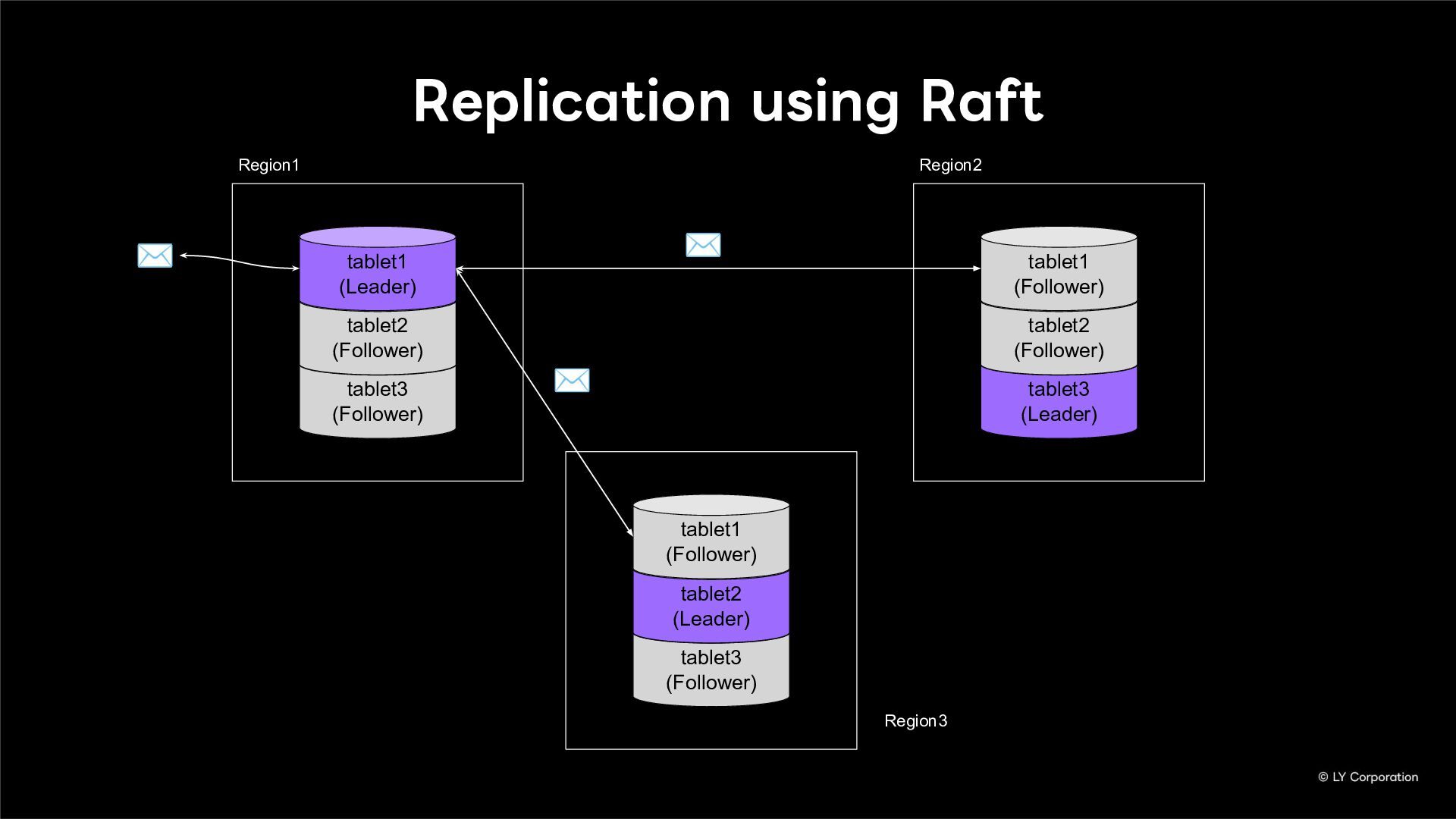
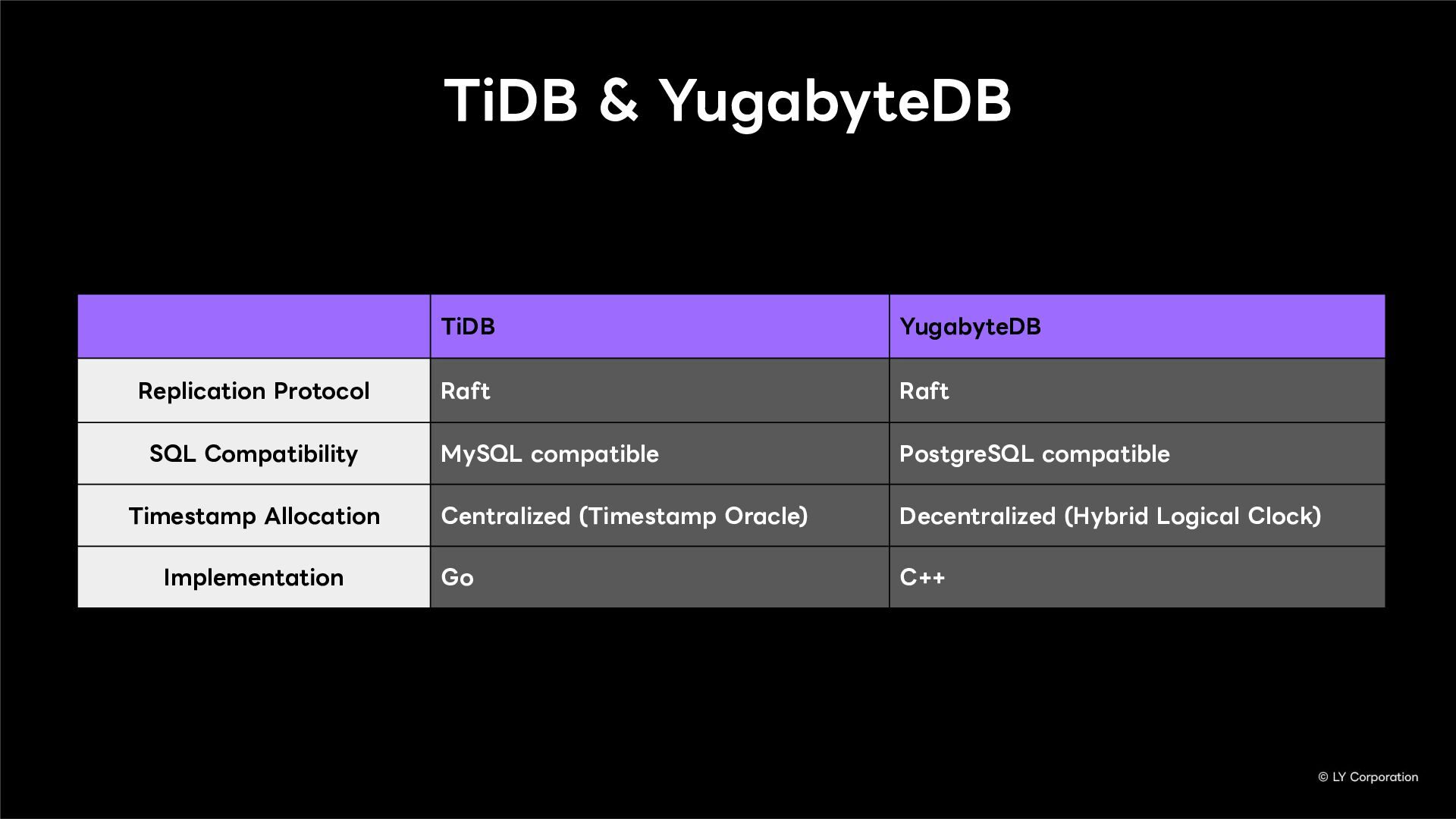
Additionally, we will introduce YugabyteDB as a key technology enabling this transition, detailing how we selected and integrate it into our messaging backend.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
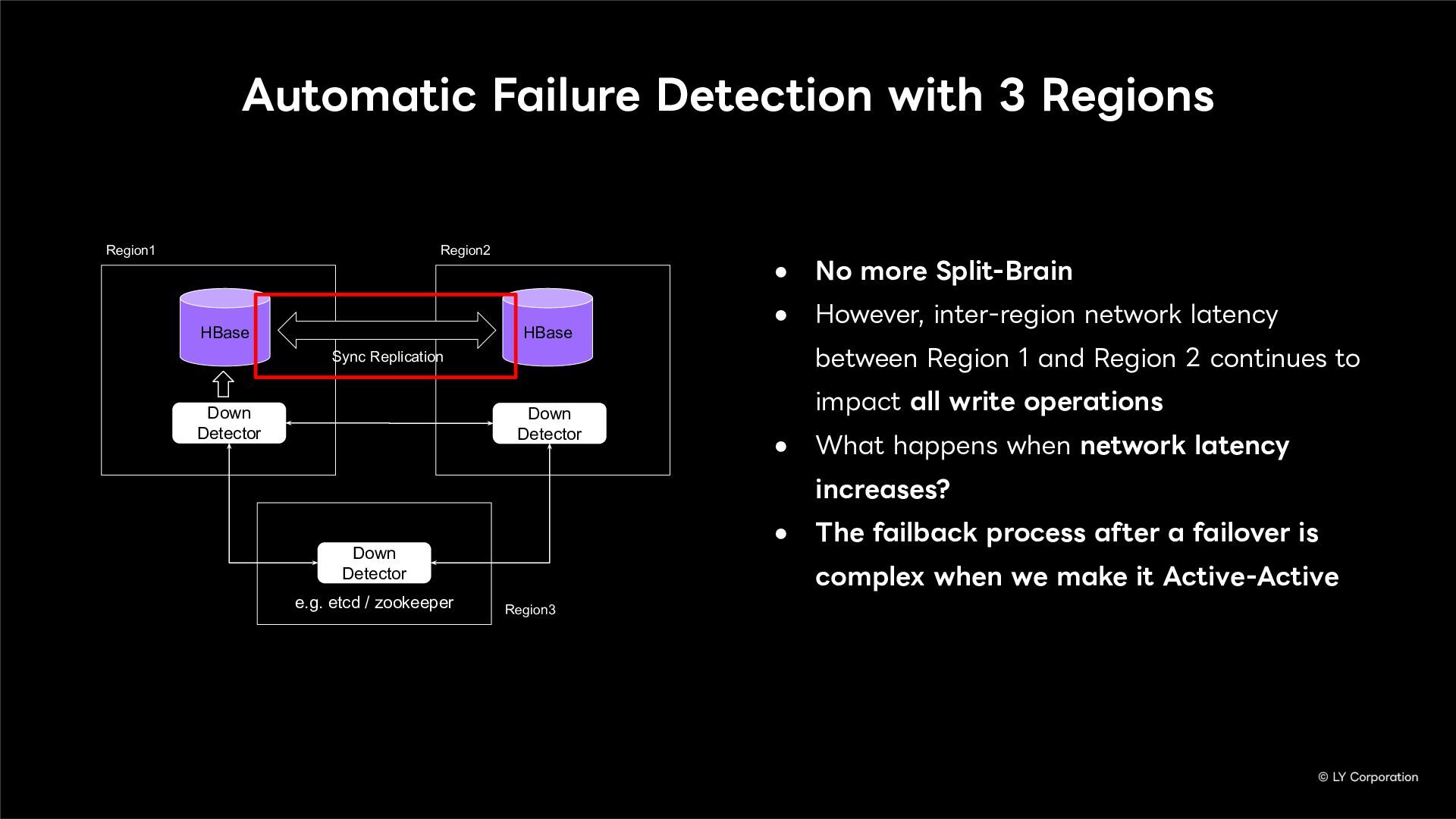{kind=link}
{kind=link}
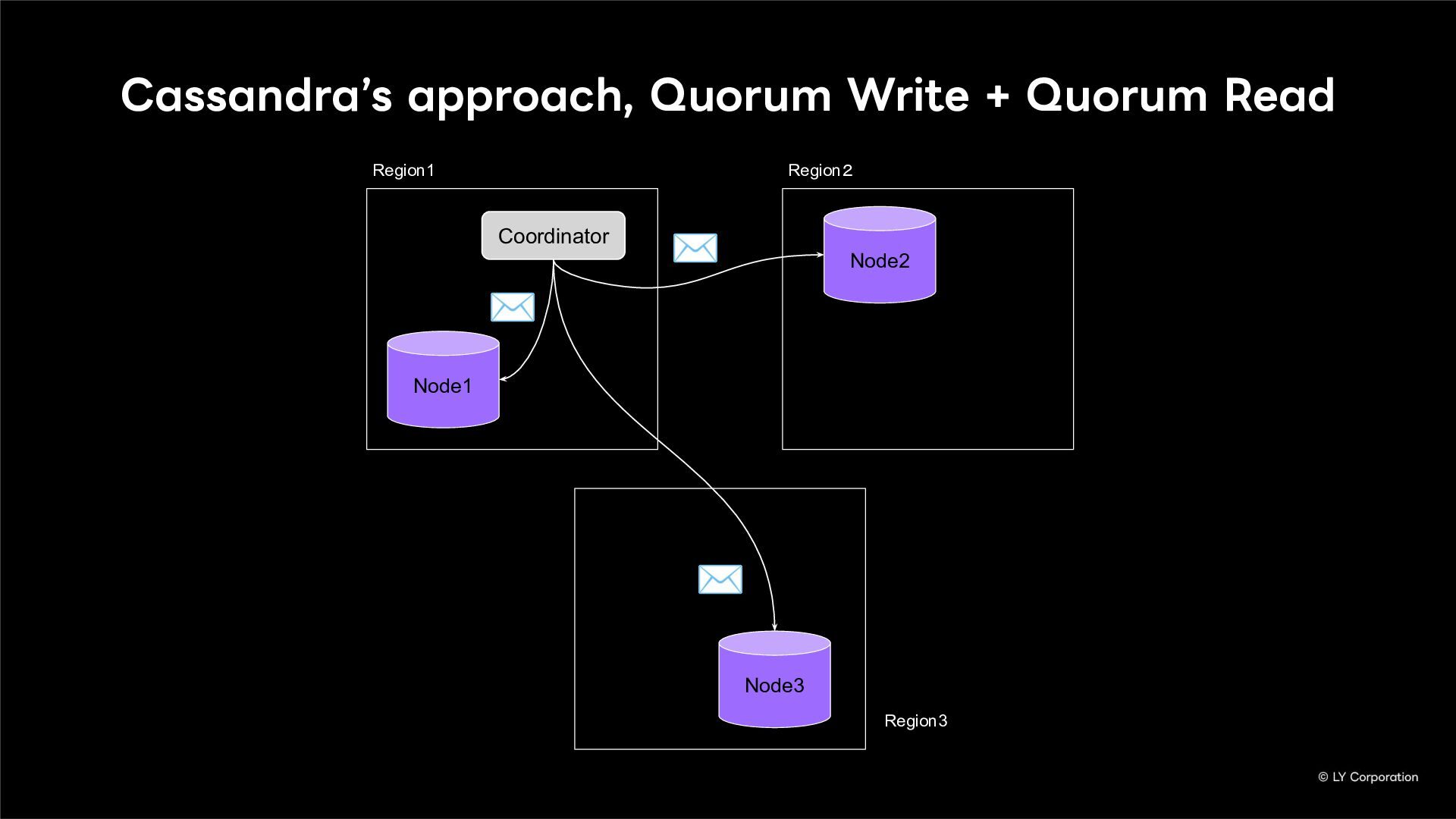{kind=link}
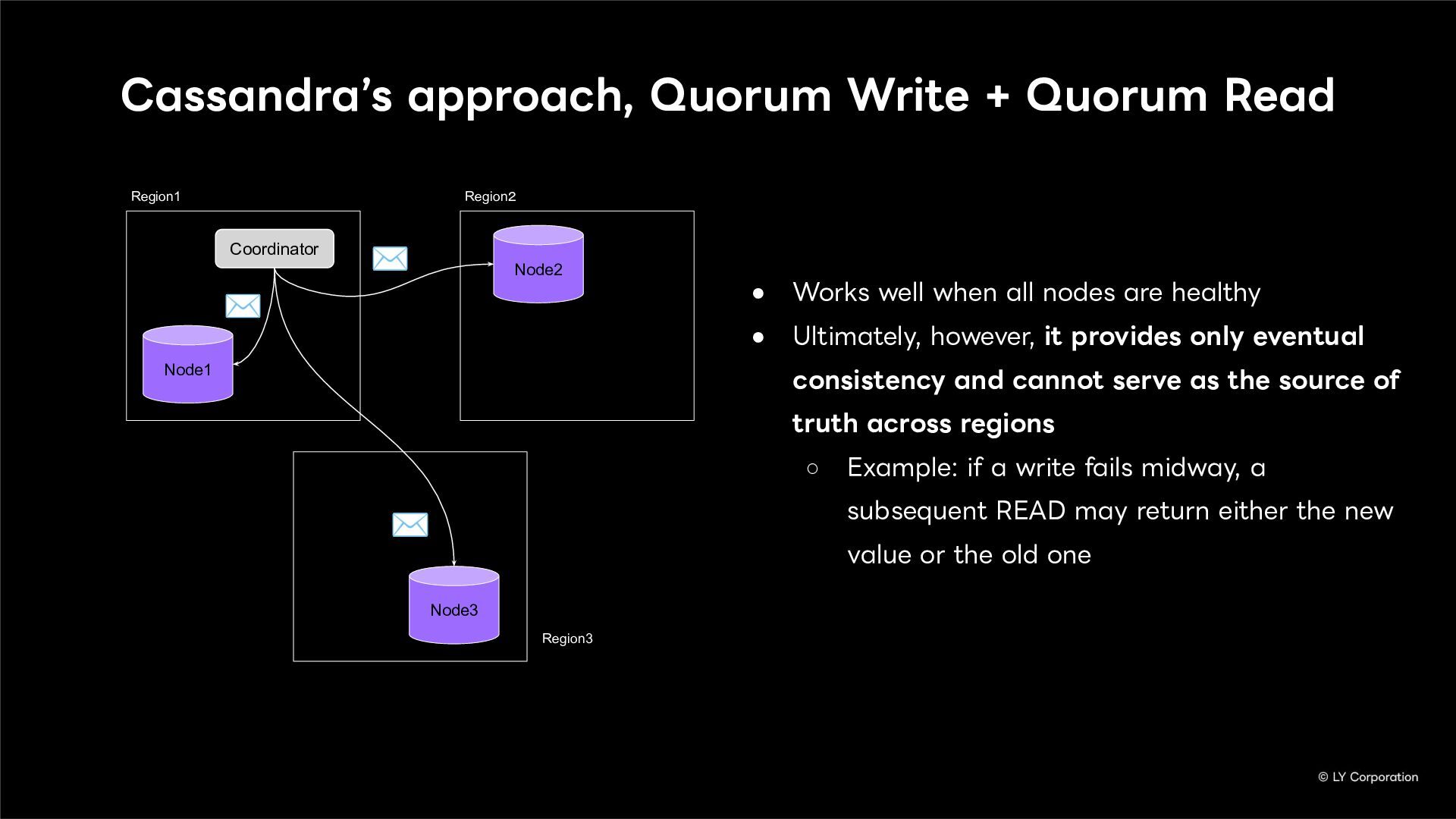{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
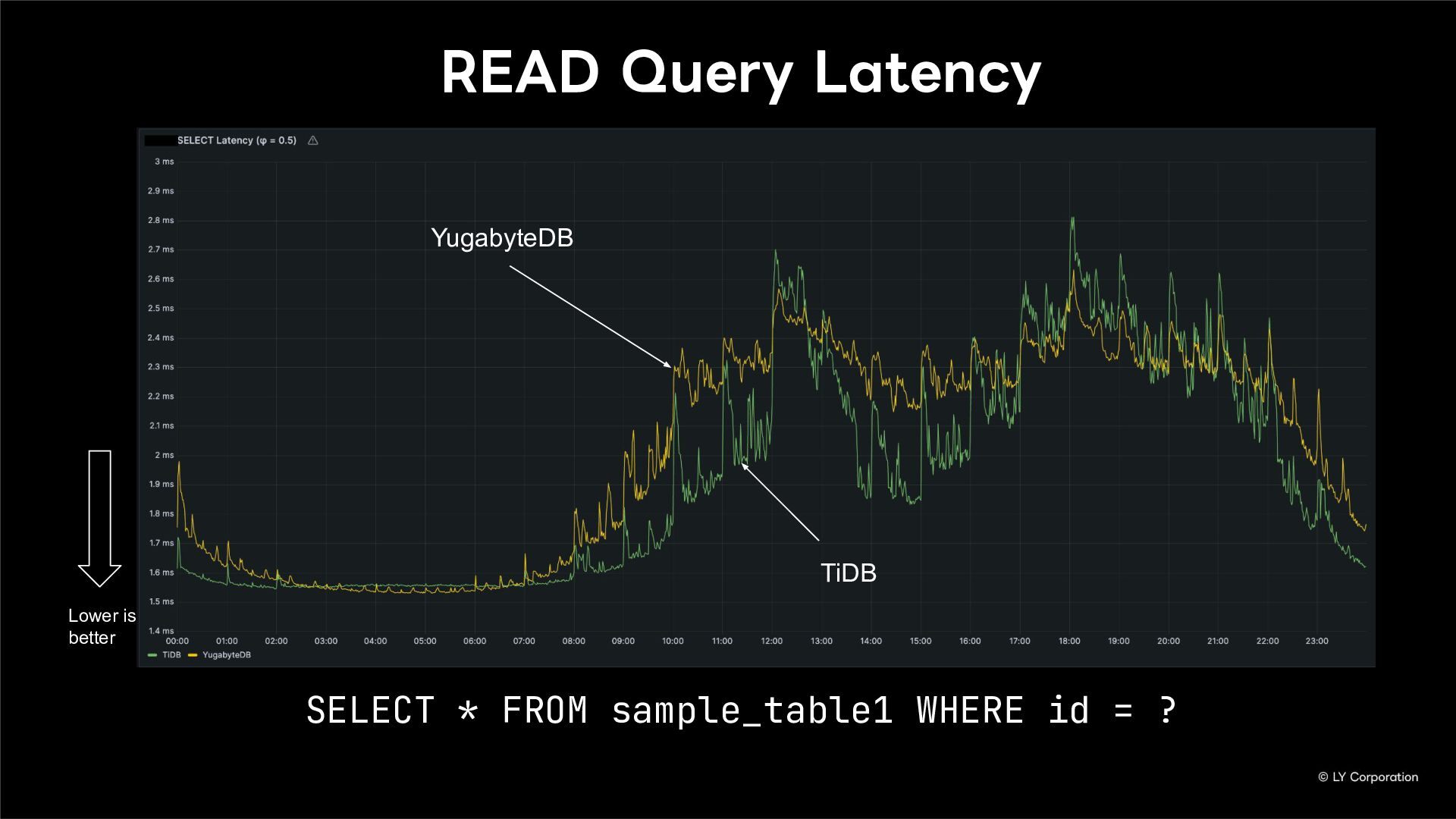{kind=link}
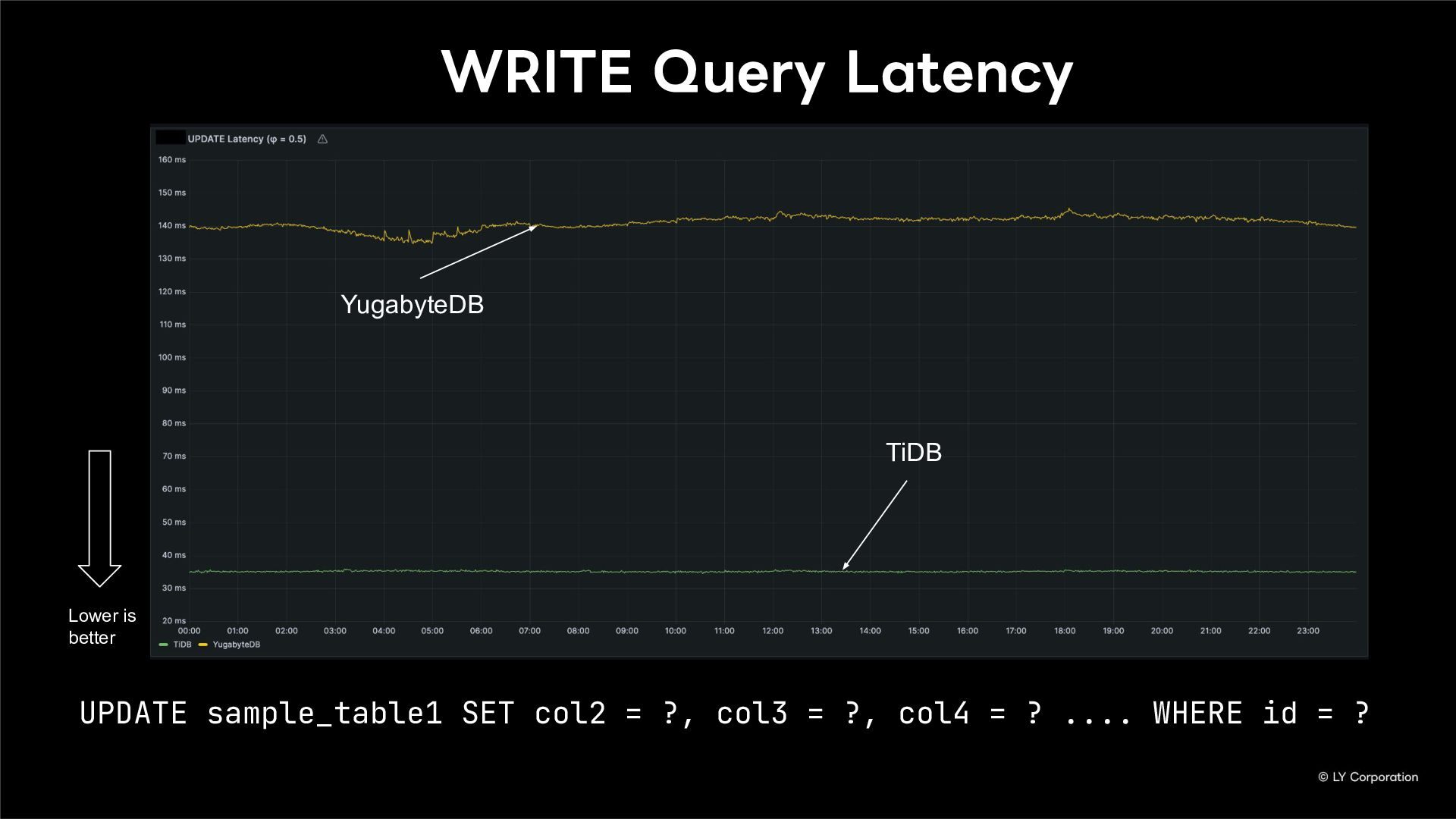{kind=link}
{kind=link}
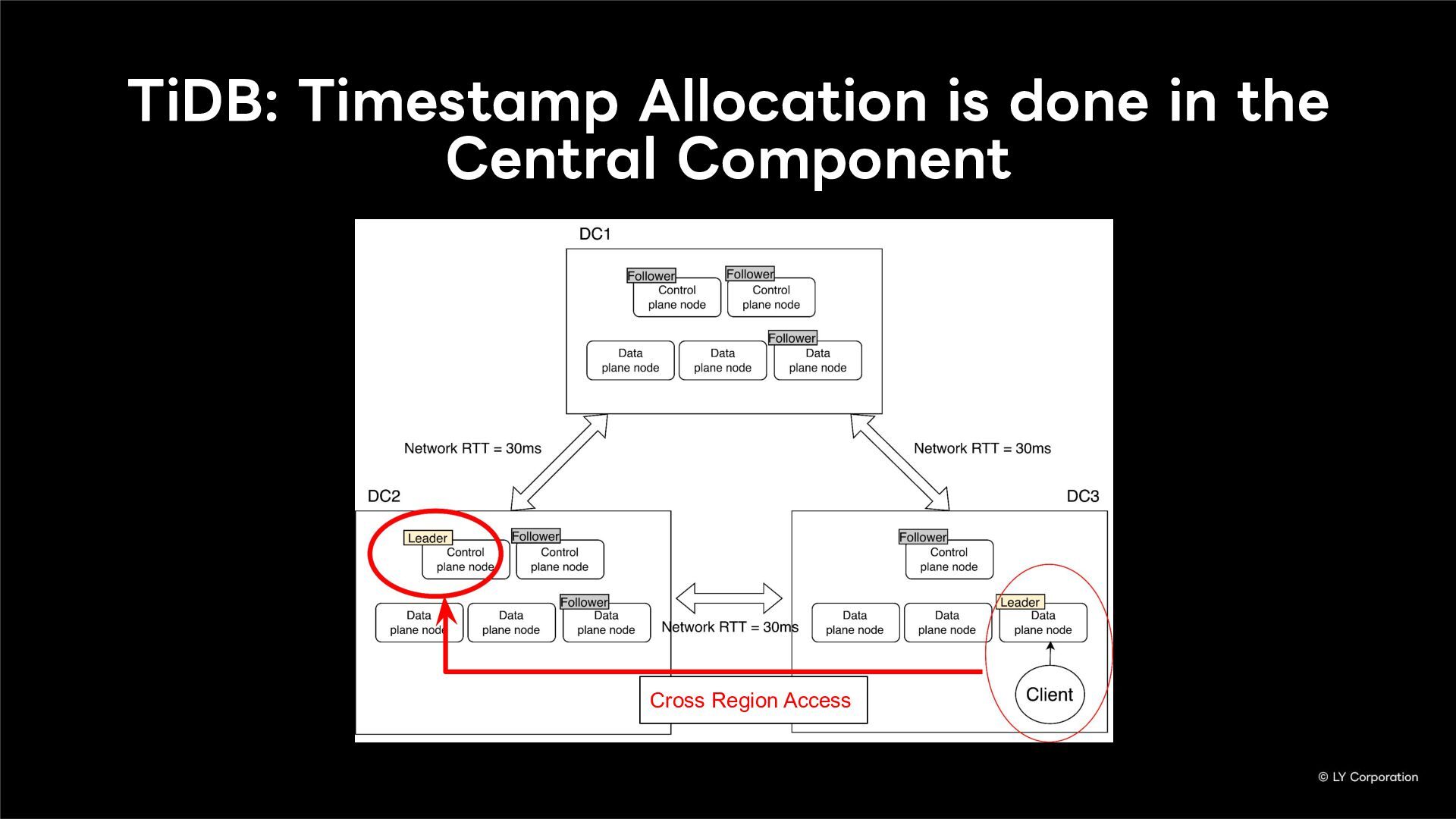{kind=link}
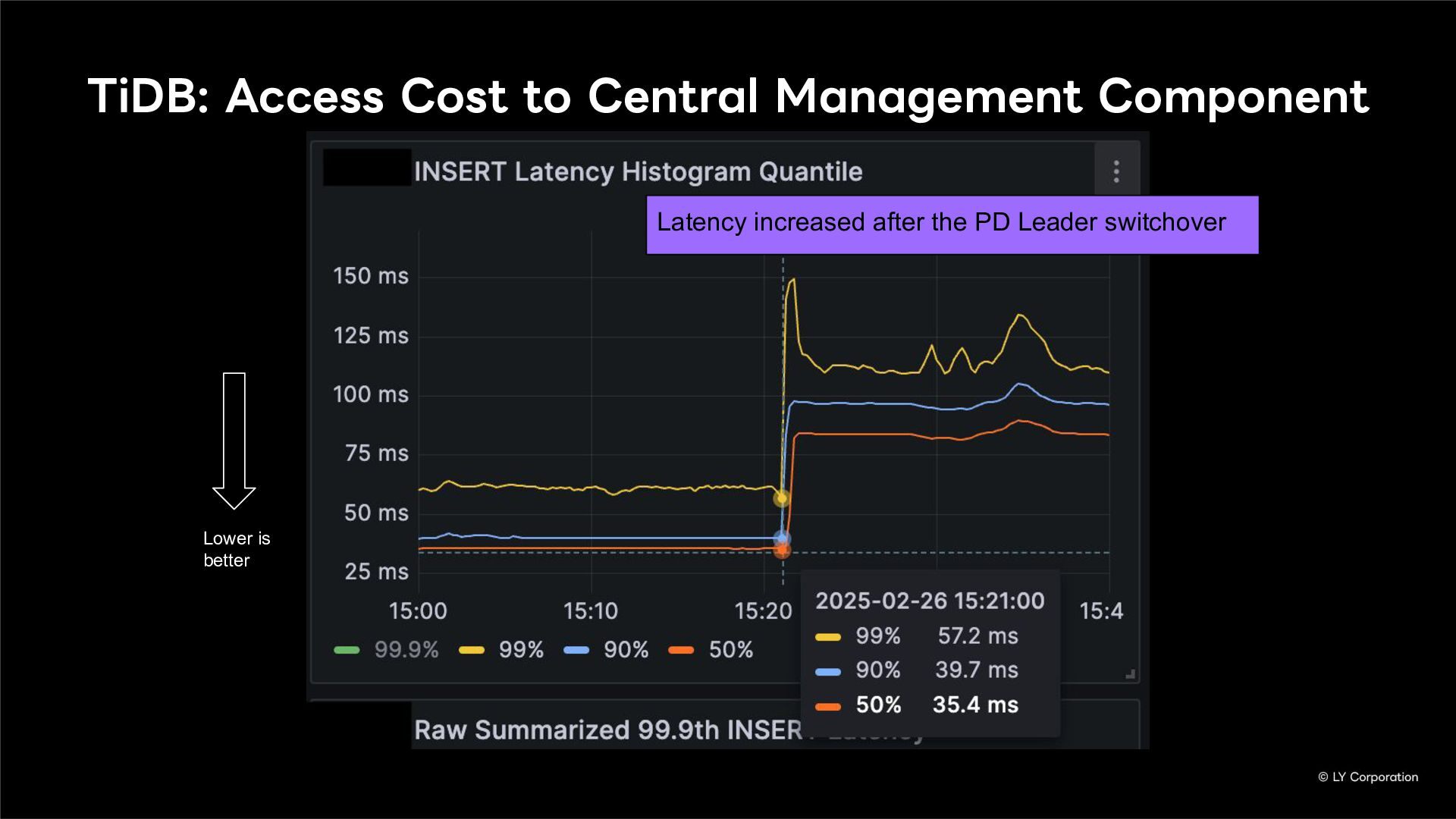{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}