A talk given at WOSSAT.NZ on 16 April 2019. Information discussion of PostgreSQL history, the project, how to get involved, and selected features I like.
using it • How I started working on it • Why I love database hacking • About PostgreSQL: • Why is its name so weird? • What kind of thing is it? • Where did it come from? • Why is it free? • Who is behind it today? • How do we make it? • Selected features I love: • SERIALIZABLE • Parallel query • PostGIS • What might the future hold? • If time permits: live patch testing
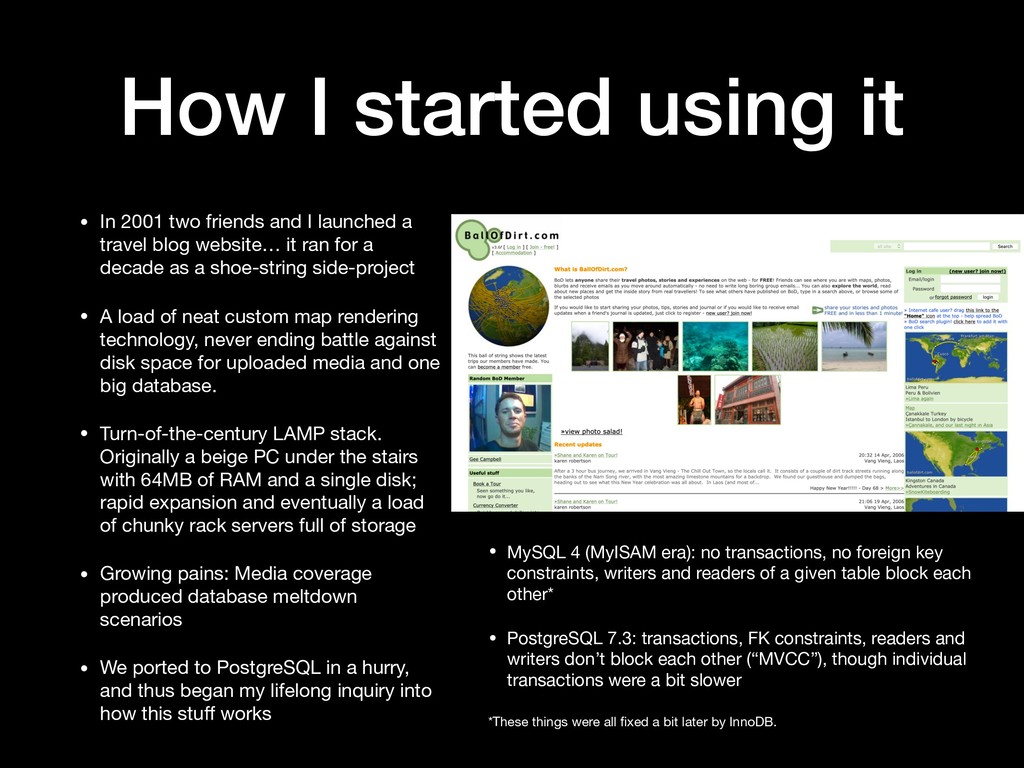
and I launched a travel blog website… it ran for a decade as a shoe-string side-project • A load of neat custom map rendering technology, never ending battle against disk space for uploaded media and one big database. • Turn-of-the-century LAMP stack. Originally a beige PC under the stairs with 64MB of RAM and a single disk; rapid expansion and eventually a load of chunky rack servers full of storage • Growing pains: Media coverage produced database meltdown scenarios • We ported to PostgreSQL in a hurry, and thus began my lifelong inquiry into how this stuff works • MySQL 4 (MyISAM era): no transactions, no foreign key constraints, writers and readers of a given table block each other* • PostgreSQL 7.3: transactions, FK constraints, readers and writers don’t block each other (“MVCC”), though individual transactions were a bit slower *These things were all fixed a bit later by InnoDB.
employer was using Oracle (and DB2, and …*) and I wanted to be able to use PostgreSQL. • A DBA pointed out that it didn’t have the SKIP LOCKED feature that we wanted for a job queue processing part of a project. • After many late nights developing a patch to scratch that itch, I finally hit send on an email to [email protected], thus beginning a number of cycles of patch revisions based on community feedback, until it was committed in release 9.5. • This helped me get a job working on it during daylight hours ~4 years ago when my family moved to NZ. *My hypothesis is that every company has log10(employees * years) different databases
is hiding in here somewhere: (in no particular order) networking, protocols, parsers, query planning, query execution, parallel algorithms, concurrency control, buffer management, IO management, scheduling problems, low level bit twiddling, high level query transformations, data flow problems, garbage collection, free space management, cache management problems, transaction processing, crash recovery, lock management, custom IPC primitives, memory allocators, operating system portability problems, interpreters, compilers, standards conformance, … etc etc etc • It’s OK to not understand large chunks of it at a time. Different people, different specialisations, and there is always more stuff to enjoy learning later! • So many unsolved optimisation problems and things to improve, and it’s worth doing: people use databases in every sphere of human activity… and they always want them to be better!
> On Wed, Jul 12, 2006 at 07:39:05PM +0300, Petronenko D.S. wrote: >> Can i get data in postgre from non-postgre db? > The name is PostgreSQL or Postgres, not postgre. It might help to explain that the pronunciation is "post-gres" or "post-gres-cue-ell", not "post-gray-something". I heard people making this same mistake in presentations at this past weekend's Postgres Anniversary Conference :-( Arguably, the 1996 decision to call it PostgreSQL instead of reverting to plain Postgres was the single worst mistake this project ever made. It seems far too late to change now, though. regards, tom lane • The name of its influential predecessor INGRES was an acryonym: INteractive Graphics REtrieval System • POSTGRES was its authors’ next project. • S -> SQL when the query language was changed from QUEL. Traces of QUEL remain (for example the Q in libpq.so).
database management system, implementing ISO SQL*. • RRBMSs give you independence from physical representation: Tell the computer what you want mostly in terms of set logic, and it figures out the procedural steps. • RDBMSs avoid anomalies using normalisation, referential integrity and transaction isolation. Facts are represented in just one place in strongly typed schemas, you can’t remove data that is referenced somewhere else, and tricky concurrency hazards can be avoided. • Relational database theory was a revolutionary idea in 1970, with implementations arriving in the mid to late 70s, and got rid of whole categories of messy data problems that plagued the users of 1960s and 1970s database systems and MongoDB users. • Not the best tool for every job, but certainly a reasonable default choice especially for things where individual datums really matter (money/accounting). *Not the only relational query language and maybe not the most theoretically sound, but it has comprehensively won (see also QUEL, Tutorial D, …)
others developed relation database theory (1970), SQL (1974) and System R (first shipped 1977) at IBM’s San Jose labs. Though they were late to ship, they wrote influential papers and the ideas spread quickly. • Stonebraker and Wong developed Ingres at UC Berkeley in the early/mid 70s, bringing relational ideas to VMS and Unix, which was also beginning to explode. • POSTGRES, 1986-1995: A fresh start to research user defined types and indexes, parallelism, strange new storage formats, etc. Prototyped in Lisp, then C. Migrated from QUEL to SQL in 1995. • PostgreSQL, 1996-: An outside team unconnected with Berkeley sets up the modern project. Initial conditions: big ideas coming out of IBM + R&D funding from the military + widespread availability of Unix systems + licences permitting commercial exploitation + whatever magic potion was in the Bay Area drinking water
use the “BSD” licence, which came from the nascent BSD Unix project at Berkeley. This allowed them to commercialise it outside the university. First with Ingres, and then again with POSTGRES. • Illustra was the name of their commercial POSTGRES fork. Many others have done the same sort of thing: AsterData, Netezza, Greenplum, ParAccel (now Amazon Redshift), PipelineDB, Amazon Aurora Postgres, EnterpriseDB Postgres Advanced Server, … • The upstream PostgreSQL project continues to thrive.
long standing community members to make hard decisions — pgsql-core@ • Security team — handles security bugs — security@ • Code of conduct committee — complaints about inappropriate behaviour — coc@ • Infrastructure team — manages project websites, source repositories and much more — pgsql-www@ • Committers — control what makes it into the tree, with new committers invited periodically • Code contributors (companies, hobbyists, students/GSOC), testers, reviewers, proof-readers… — pgsql-hackers@ • IRC, Slack, … communities — #postgresql on Freenode • Translators — messages in the software, manuals — pgsql-translators@ • Packagers — manage packages, via our own package repos and distro repos • Users, bug reporters and testers — pgsql-bugs@, pgsql-general@, pgsql-performance@ • Regional non-profit organisations — organising conferences and representing the project regionally • Postgres Women — supporting and encouraging women to participate in all of the above — pgsql-women@ • Special interest groups and associated projects — PostGIS, JDBC drivers, PgAdmin, … • Sponsoring companies — hardware, conferences, salaries, code and financial contributions, … … and probably more groups that I am forgetting right now
contributing to discussions • Up to ~250 proposed patches in consideration at a time • 4-5 “Commitfests” per year • One major release per year How do we make it?
magic solution that is not widely used. • Suppose you have a bunch of complicated business logic checks before allowing something to happen. A concurrent transaction does the same. If coded naively, both transactions can decide to proceed even though they would have behaved differently if one had run before the other. The traditional solution is explicit locking, but experience shows that this is error prone. • SERIALIZABLE allows you to program in a naive way, pretending that all transactions are run one after another in some sequence. • Most other databases that have SERIALIZABLE implement it “pessimistically”, locking everything you read. PostgreSQL implements it “optimistically”, rejecting some transactions that overlap in incompatible ways. Both approaches need users to retry.
execute each query. That’s OK if you’re running lots of small queries, but not ideal if you’re running a small number of concurrent big long queries and have idle hardware. • In recent releases we have developed parallel query processing, to make better use of hardware. • The biggest speed-ups are in CPU-intensive aggregation work, scans and joins of whole tables.
was to support GIS applications (recall the GRES in Ingres and POSTGRES) and funky data types and index types that would require. It’s a testament to PostgreSQL’s extensibility that PostGIS is an extension. • PostGIS powers a squillion find-me-a-taxi/pub/house/… apps, land registries, scientific applications, and much, much more. • Regrettably, I don’t know very much about it. Luckily, other WOSSAT people do! But the following simple examples show the power of spatial indexes: SELECT * FROM pubs WHERE ST_DWithin(location, ST_MakePoint(-41.290,174.771), 100) SELECT * FROM pubs ORDER BY location <-> ST_MakePoint(-41.290,174.771) LIMIT 10
the “tableam” API in PostgreSQL 12, expect to see new table storage formats emerge: • column stores, time-series optimised, …? • one project my company is working on is “Zheap”, which aims to remove the need for the dreaded VACUUM • Currently, expressions can be compiled and executed as machine code with LLVM. In future we hope to compile whole query plans for faster execution. • Direct IO? Future NVRAM interfaces? … • More partition support. • More kinds of parallelism. Better resource limits. • More kinds of federation, sharding and cluster-ware and replication and scaling? • Multithreading (instead of processes)? Built-in connection pooling? • What do you think we need to work on?
![A rambling tour of PostgreSQL WOSSAT.NZ, 16 April 2019 [email protected]](https://files.speakerdeck.com/presentations/e22933ec5f6f4e7c9018e55e20a27fdb/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![• [email protected] • ~140 people contributing code • ~500 people](https://files.speakerdeck.com/presentations/e22933ec5f6f4e7c9018e55e20a27fdb/slide_10.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}