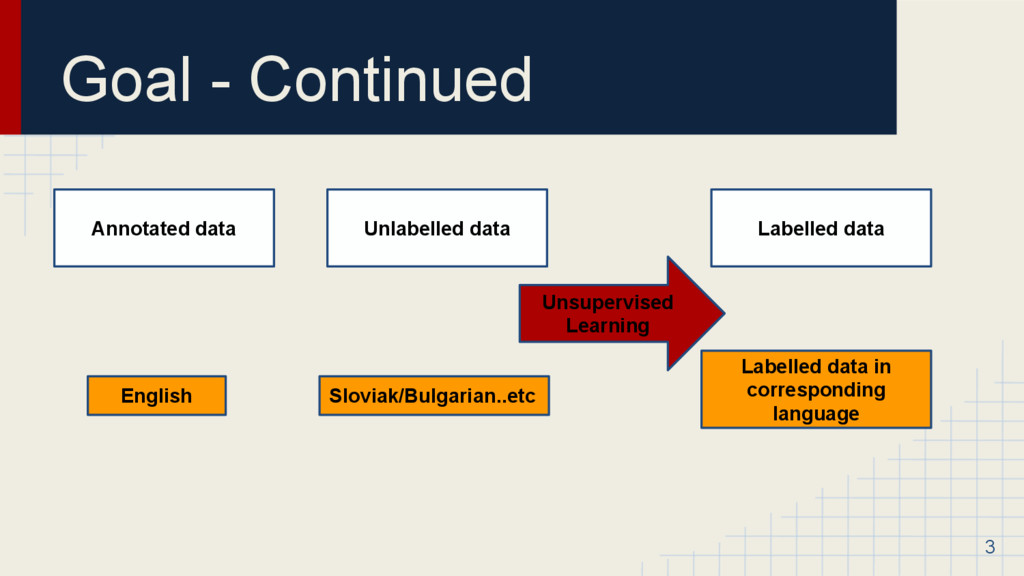
language without any labelled data in that language. We take help from annotated data in other language and see how it may influence to infer the POS tagging in other language cross lingually. 2
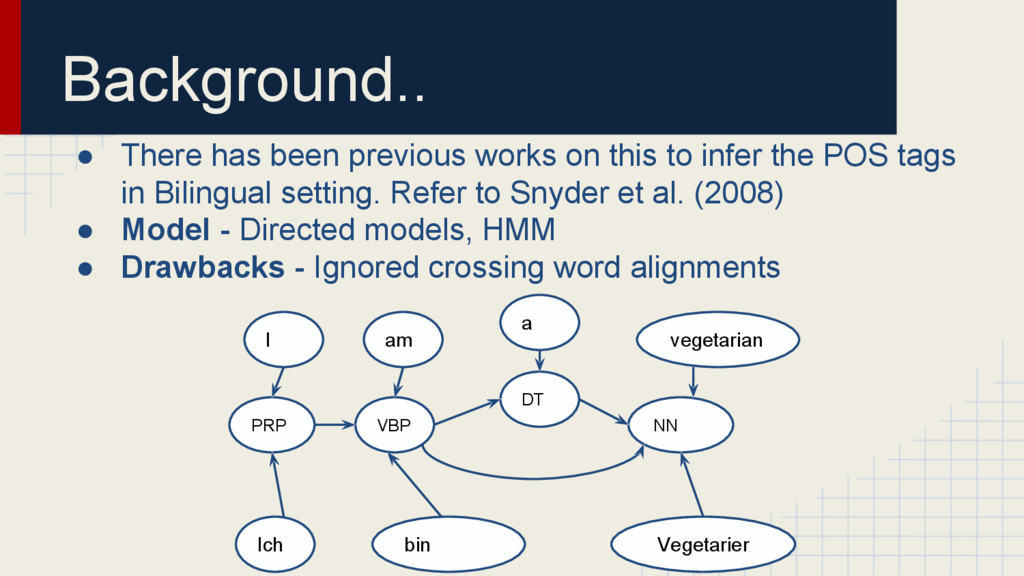
infer the POS tags in Bilingual setting. Refer to Snyder et al. (2008) • Model - Directed models, HMM • Drawbacks - Ignored crossing word alignments I am vegetarian bin a Ich Vegetarier PRP VBP NN DT
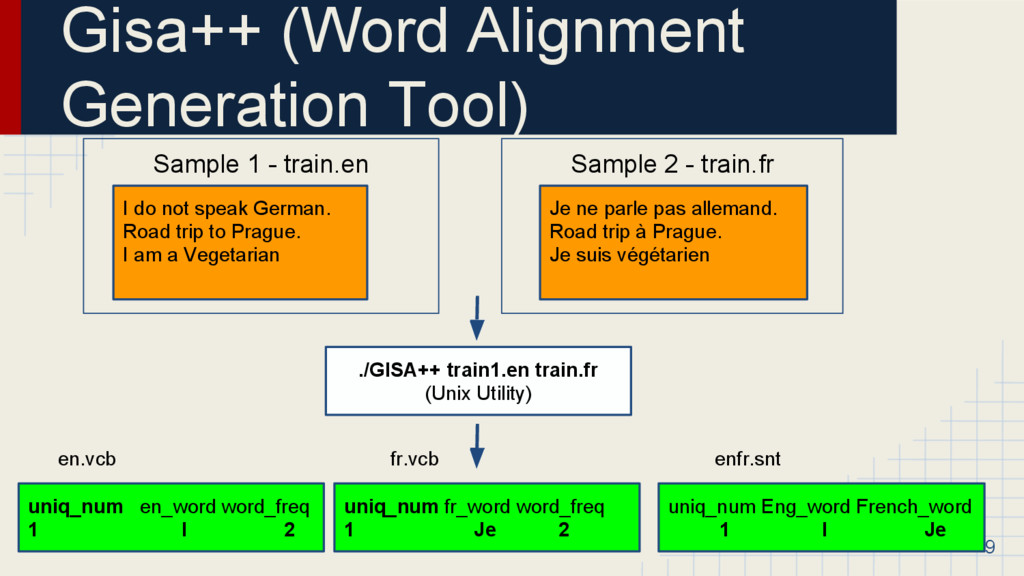
I do not speak German. Road trip to Prague. I am a Vegetarian Sample 2 - train.fr Je ne parle pas allemand. Road trip à Prague. Je suis végétarien ./GISA++ train1.en train.fr (Unix Utility) uniq_num en_word word_freq 1 I 2 uniq_num fr_word word_freq 1 Je 2 uniq_num Eng_word French_word 1 I Je en.vcb fr.vcb enfr.snt
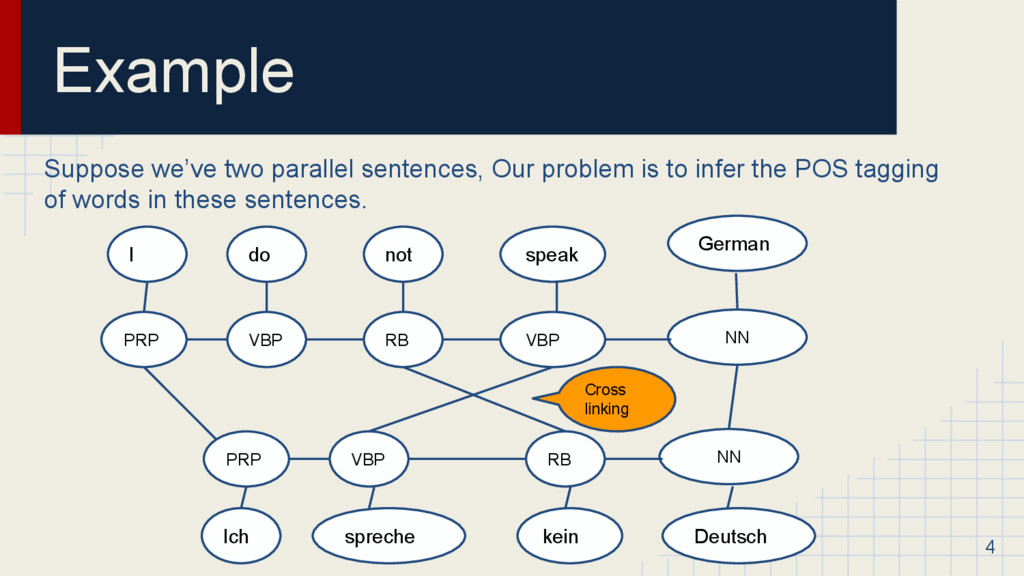
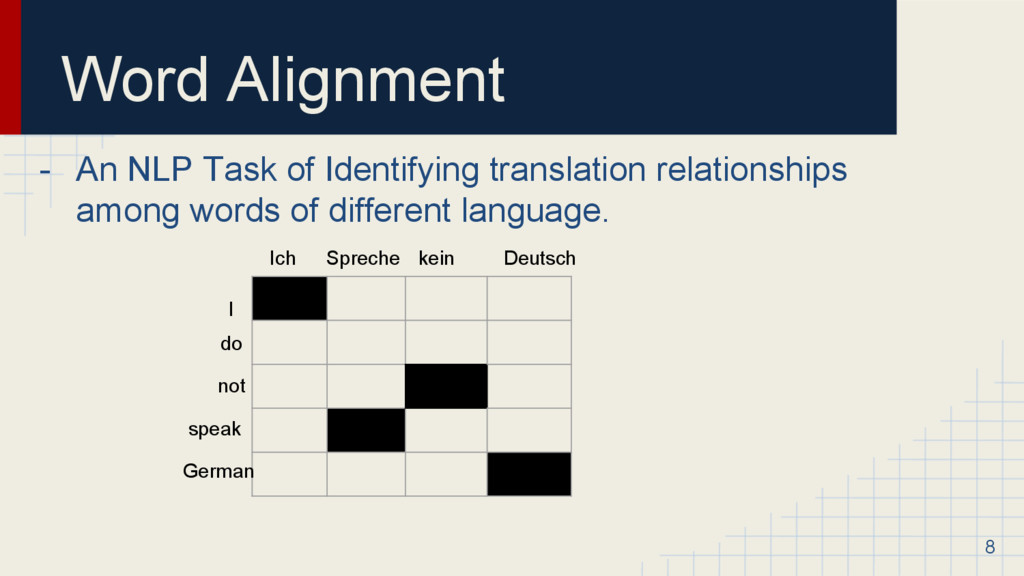
: Two parallel sentences S<s1, s2… sn>, T<t1, t2 .. tn> I do not speak German = Ich spreche kein Deutsch. ◦ A : Set of word alignments in both these word sequences. Tool used : Giza++ (I, Ich=1, speak, spreche =2 etc...) ◦ Output : X,Y i.e sequences of POS tags for corresponding sentence pairs (X is already given, we need to infer Y) tags like NN, PRP etc that we’re interested in 10
predicted words (of course for the best fit of predicted sequence of POS tags). We need to optimise the weight vector to have the best likelihood. 13 Optimisation Maximum Likelihood Estimation Contractive Estimation
In class we’ve seen a class of algorithms for such optimisation i.e Hill Climbing algorithm. But they’ve a problem of “local maxima”. MLE = Maximizing the likelihood function. Log Likelihood is simply the log of likelihood function 14 https://onlinecourses.science.psu.edu/stat504/node/27
equation by introduction of a neighbourhood function. In our case we would define a neighborhood function for sentences, N(s;t) which maps a pair of sentences to a set of pairs of sentences. 15 http://www.cs.cmu.edu/~nasmith/papers/smith+eisner.acl05.pdf We tweak Normalization constant as a part of Neighbourh.. function
model • MRF model doesn’t work well with MLE as compared to HMM. The weights vector is not normalized properly and the “local maxima” problems is not solved (though it works well with HMM). • CE results showed a better normalized distribution to weights and hence this is chosen to optimise the equation. “local maxima” problems is solved 16
Suitability 1. Supervised Learning: • Trained a monolingual supervised MRF model to compare to the results of supervised HMMs. • Our model vs HMM -difference in accuracy less than 0.1%. 2. Unsupervised Learning: 18 Language Random HMM MRF Bulgarian 82.7 88.9 93.5 English 56.2 90.7 87.0 Sloviac 83.4 85.1 89.3 Slovene 84.7 87.4 94.5
only 5% of sentences with crosslinking • MRF bilingual model is applied on Europarl corpus (tested on French- English pair) 20 Language with Cross linking w/o Cross linking English 73.8 70.3 French 56.0 59.2
(http: //people.csail.mit.edu/desaic/pdf/chen+dyer+cohen+smith.unsup11.pdf) • Unsupervised multilingual learning for POS tagging (http://www.aclweb. org/anthology/D08-1109.pdf) • Contrastive Estimation: Training Log-Linear Models on Unlabeled Data (http://www.cs.cmu.edu/~nasmith/papers/smith+eisner.acl05.pdf) • Classes by Andrew Ng on Machine Learning (coursera.org) 22
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}