Graphical Model. • Enables the use of prior knowledge to put a higher probability on hypotheses deemed more likely. • We’ll not discuss the Mathematics specifics for Bayesian Model in this talk • Don’t commit to a particular set of parameters (don’t attempt to compute the most likely hypothesis) • Dirichlet processes are used in this paper Adapted from Vincent Ng Class on Coreference resolution at UT Dallas
a two step processes. a) First, speakers introduce new entities into discourse (with proper or nominal expressions) b) Second, speakers refer back to entities already introduced (with pronouns) 4
of mentions (usually noun phrases) • A mention is a reference to some entity • There are three types of mentions: 1.Proper (names) 2.Nominal (descriptions) 3.Pronominal (pronouns) • Therefore, the coreference resolution problem is to partition the mentions according to their referents 5
is in the US4 , is a large, specialized corporation5 investing in the area of electricity generation. This power plant6 , which7 will be situated in Rudong8 , Jiangsu9 , has an annual generation capacity of 2.4 million kilowatts. 6
mathematical method. • It gives probabilities of how likely a set of random variables will lie in a certain probability distribution. 7 Blackbox α (Concentration Param) β (Distribution) Adapted from Janis Pagel talk in Discourse Theory and Computation (University of Stuttgart) (Melissa, The red-haired woman) (Melissa=0.05, The=0.05, red-haired=0.75 woman=0.15) Document Find adjective
a set of pairwise coreference decisions Use discriminative learning with features encoding properties such as distance and environment • However, there are several problems with this approach Rich features require a large amount of data à Not available always Greedy approach is generally adopted which works well only for pairwise model.. 8
Used English translations of the Arabic and Chinese treebanks. 95 documents, 3905 mentions Access restricted (LDC*), only training data available • MUC-6 Data from the 6th Message Understanding Conference Training, development and test data available No manual annotation of head and mention type 10 Linguistic Data Consortium
data is provided as input: The true mention boundaries The head words for mentions ACE - this is already given MUC-6 – Right most token is taken The mention types 12
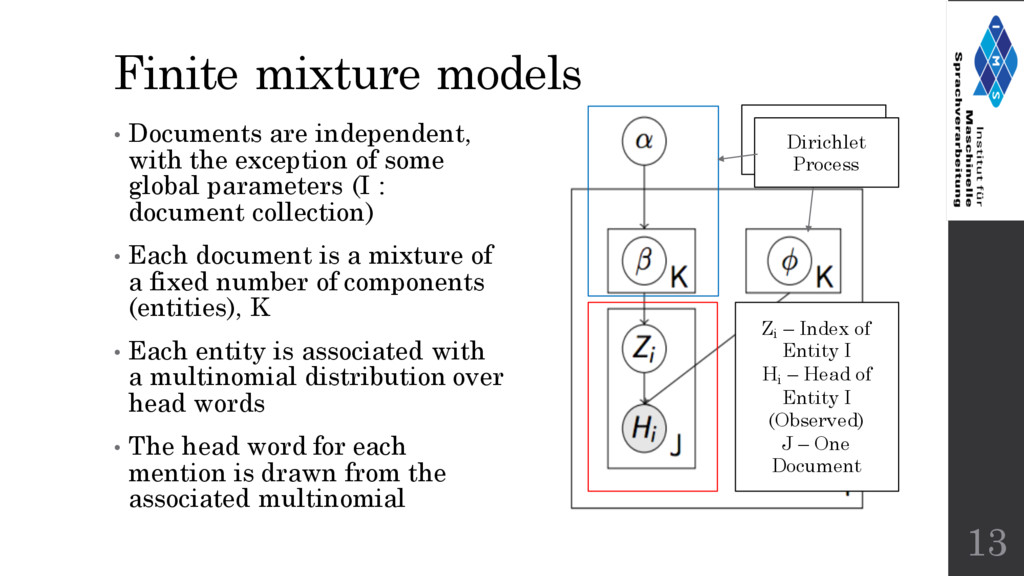
of some global parameters (I : document collection) • Each document is a mixture of a fixed number of components (entities), K • Each entity is associated with a multinomial distribution over head words • The head word for each mention is drawn from the associated multinomial 13 Zi – Index of Entity I Hi – Head of Entity I (Observed) J – One Document Feature vector Dirichlet Process
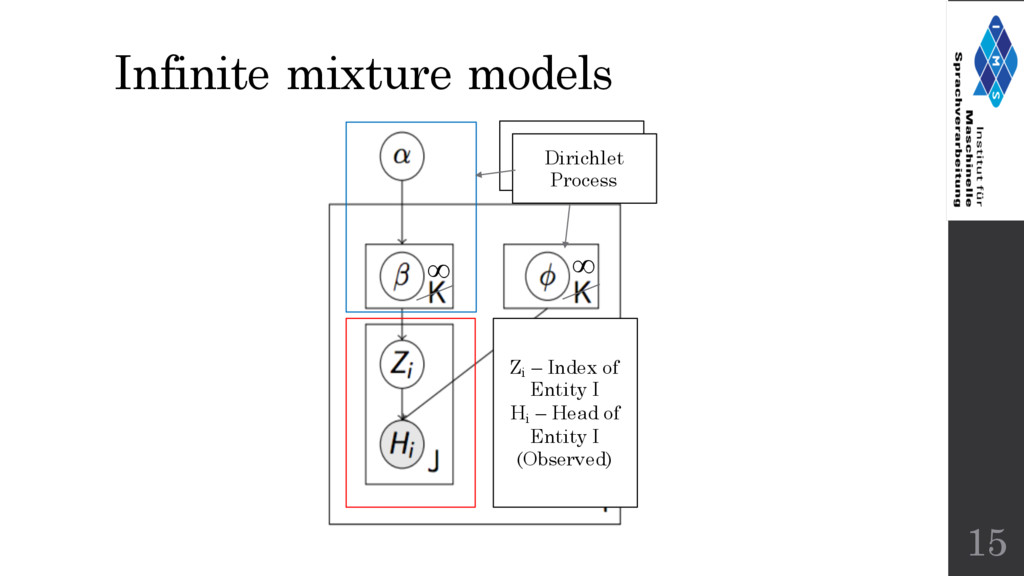
number of entities, K • In real life it is not possible to have a fix value of K entities in a document. • What we want is for the model to be able to select K itself. • Solution : Replace the finite Dirichlet with the non- parametric Dirichlet process (DP) 14 Finite mixture models : Problems
mentions, but do not make sense for pronominal mentions. • F1 = 54.5 on development set • The Weir Group1 , whose2 headquarters3 is in the US4 , is a large, specialized corporation5 investing in the area of electricity generation. This power plant6 , which7 will be situated in Rudong8 , Jiangsu9 , has an annual generation capacity of 2.4 million kilowatts. Infinite mixture models : Problems 16
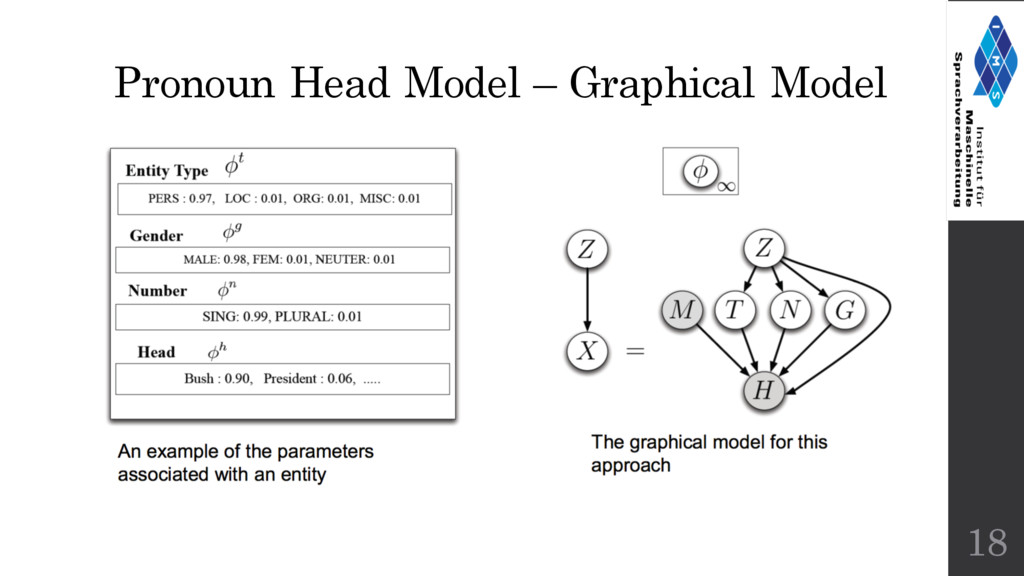
word for a mention we consider more than the entity specific multinomial distribution over head words. • i.e Add more linguistic feature to enrich our model. • Features added : Entity type (Person, Location, Organization, Misc.) Gender (Male, Female, Neuter) Number (Single, Plural) 17
The model corrects the systematic problem of pronouns being considered. Still there is no local preference for pronominal mentions existing in this model. • The Weir Group1 , whose1 headquarters2 is in the US3 , is a large, specialized corporation4 investing in the area of electricity generation. This power plant5 , which6 will be situated in Rudong7 , Jiangsu8 , has an annual generation capacity of 2.4 million kilowatts. • Solution : Introduce Salience in model. Pronoun Head Model : Problems 19
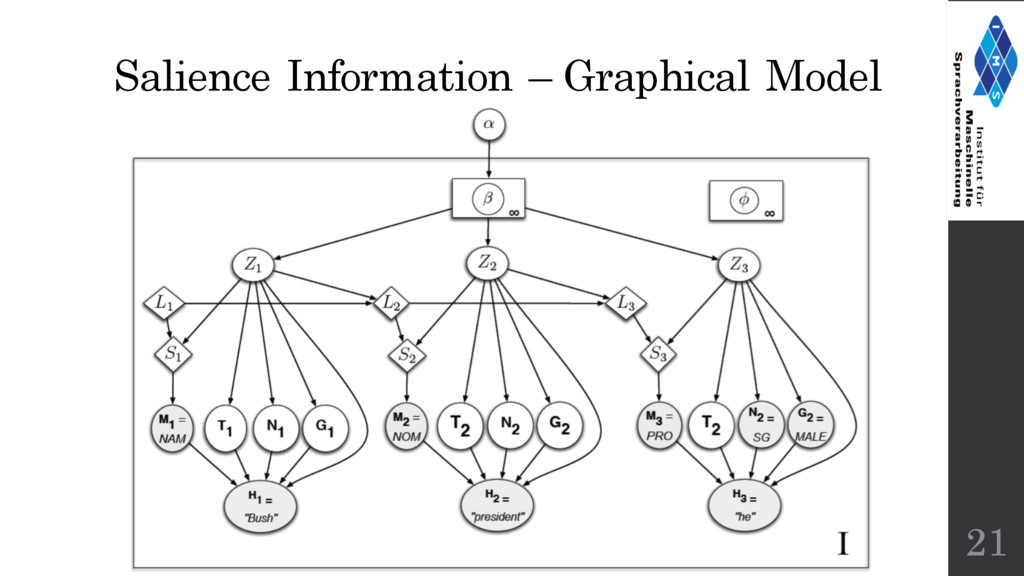
in the current discourse. • Idea: Add salient weights, so that it becomes more likely to align a pronoun to the most salient entity 20 Adapted from Janis Pagel talk in Discourse Theory and Computation (University of Stuttgart)
a salience value of 0 • As we process the discourse, the salience value of each entity will change When we encounter a mention, we update the salience scores (* 0.5 for each entity and add 1 to current entity) 22
The model now correctly aligns the pronouns to the most salient entity mention. • The Weir Group1 , whose1 headquarters2 is in the US3 , is a large, specialized corporation4 investing in the area of electricity generation. This power plant5 , which5 will be situated in Rudong6 , Jiangsu7 , has an annual generation capacity of 2.4 million kilowatts. Salience Information : No Problems 23
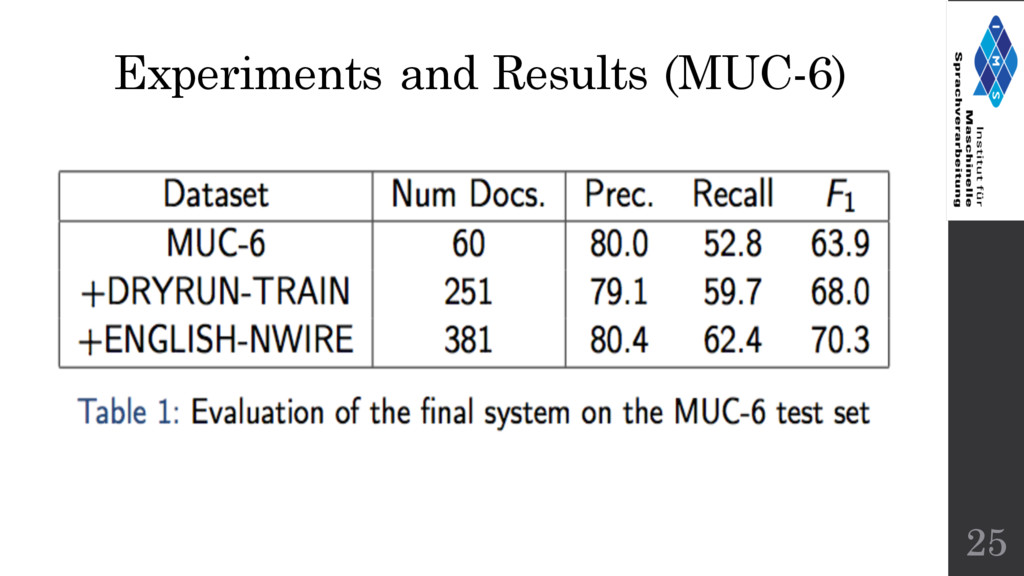
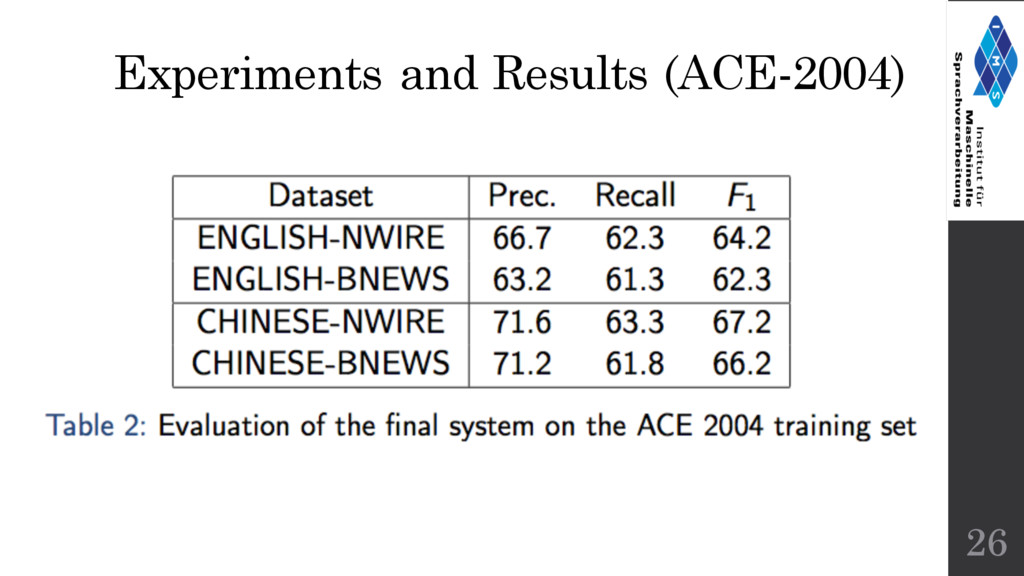
other systems are supervised. • Most comparable supervised system on MUC-6 test set: F1 = 73.4 (compare to F1 = 63.9 of Haghighi and Klein). • Unsupervised systems often tend to under-perform supervised systems. Considering this the results in the current Unsupervised setting are reasonably alright. • Higher performance on Chinese data due to due to the lack of prenominal mentions as well as fewer pronouns as compared to English 27
Resolution. • Adding salience to pronoun entity model results in the best performance. • Results of this Unsupervised approach are comparable with state-of-the-art Supervised approach towards Coreference Resolution. 29
resolution in a nonparametric bayesian model. In J. A. Carroll, A. Bosch, & A. Zaenen (Eds.), Proceedings of the 45th annual meeting of the ACL (Vol. 45, pp. 848–855). Association for Computational Linguistics. • Ng, V. (2008). Unsupervised models for coreference resolution. In Proceedings of the conference on empirical methods in natural language processing (pp. 640–649). Stroudsburg, PA, USA: Association for Computational Linguistics. • Brandon Norick talk in UoI, Urbana Champaign • Janis Pagel Talk in Discourse Theories and Models class. 30
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}