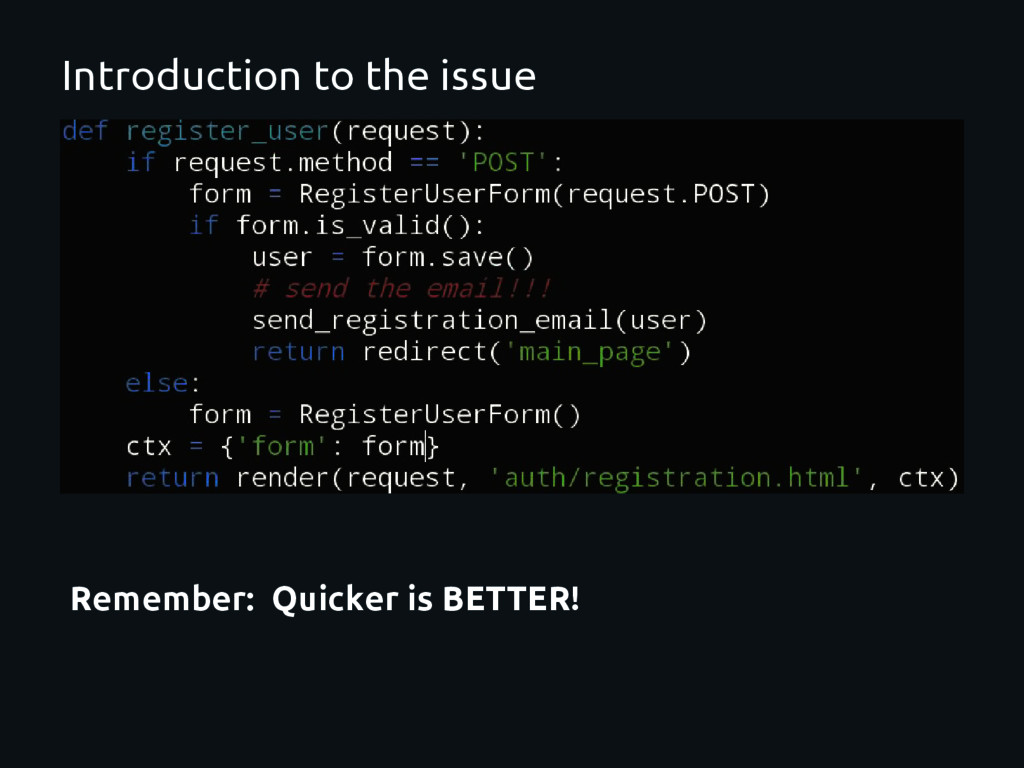
cycle Can not move it to another host Prone to be a “bottleneck” Error handling is not DRY send_registration_email(user) its blocking It does not scale! The “heavy” work MUST be outside of the Request-Response cycle. Heavy: “Everything which could add an unnecessary delay, some overhead or it is not needed immediately”
like a DICT (key-value) Allows to decouple the system Allows to distribute the system Allows the communication between technologies Allows to scale in a “more” natural way disadvantages Now System == Distributed System Adds more complexity to the stack Needs more maintenance
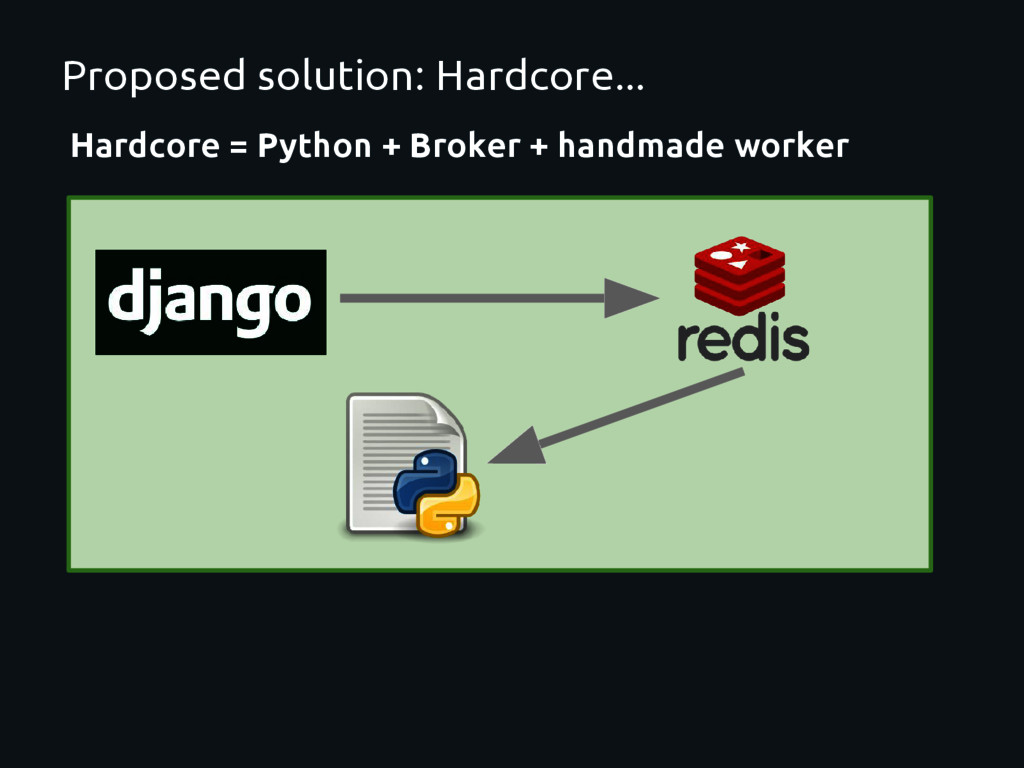
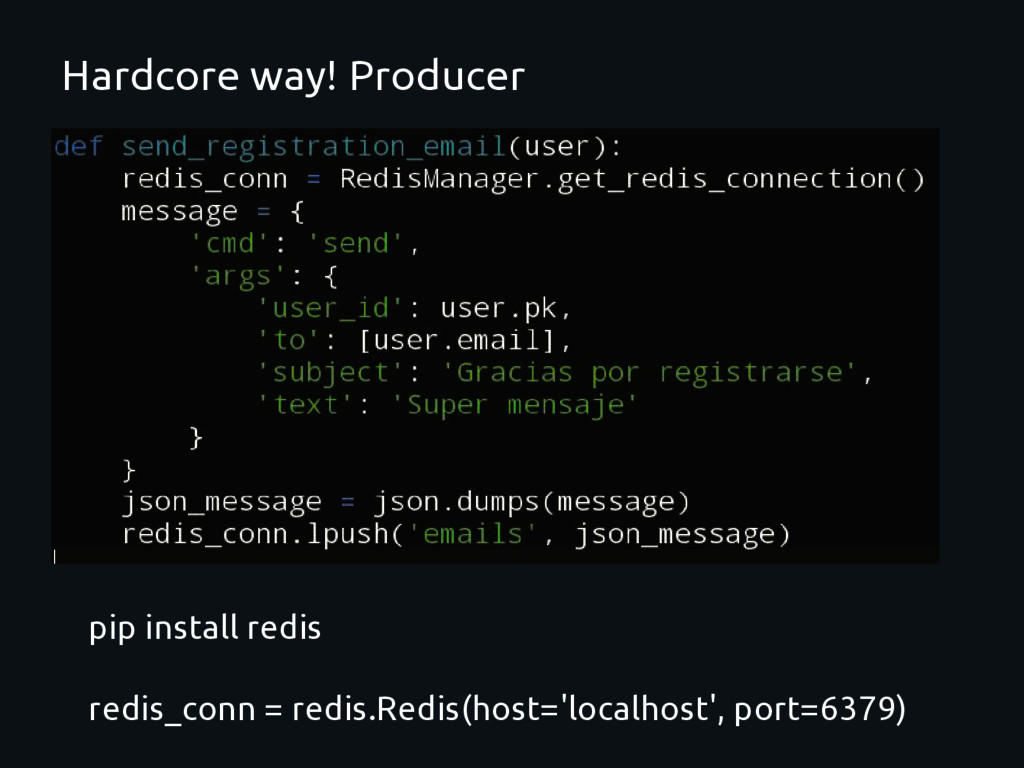
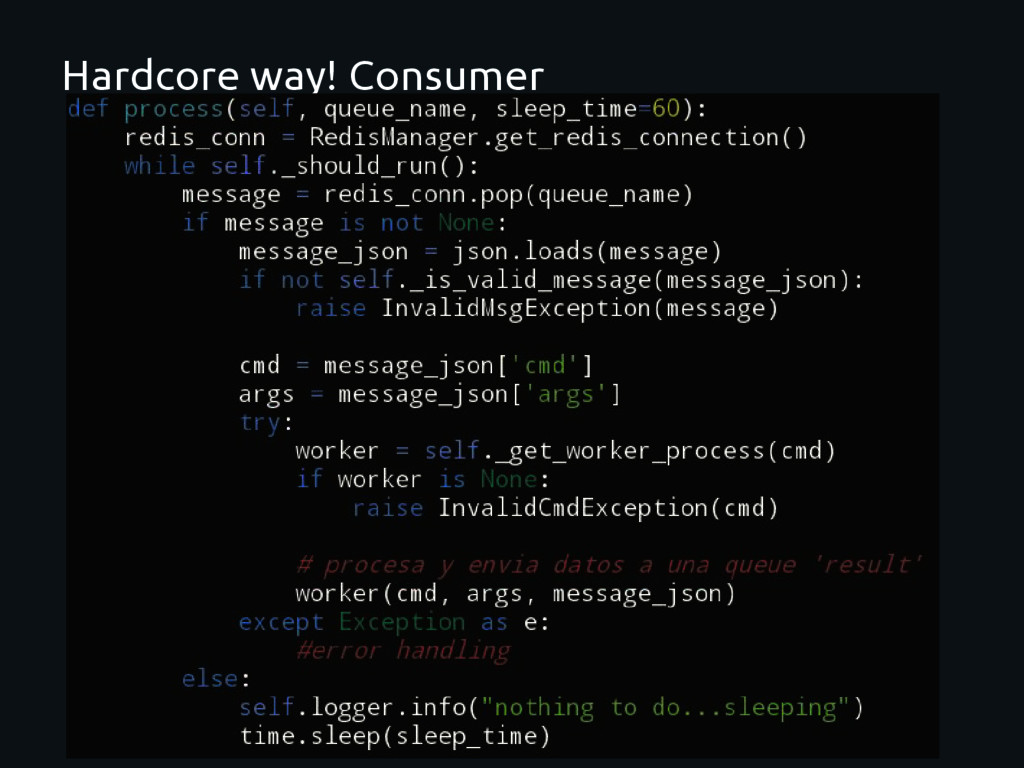
framework Decouple the system Move the heavy work to other place Absolute control from devs All should be done “from scratch” Stick to a single broker (Redis) Limited scalability Lots of code should be “re-written” Monitoring? Administration ?
based on distributed message passing. It is focused on real-time operation, but supports scheduling as well. The execution units, called tasks, are executed concurrently on a single or more worker servers.
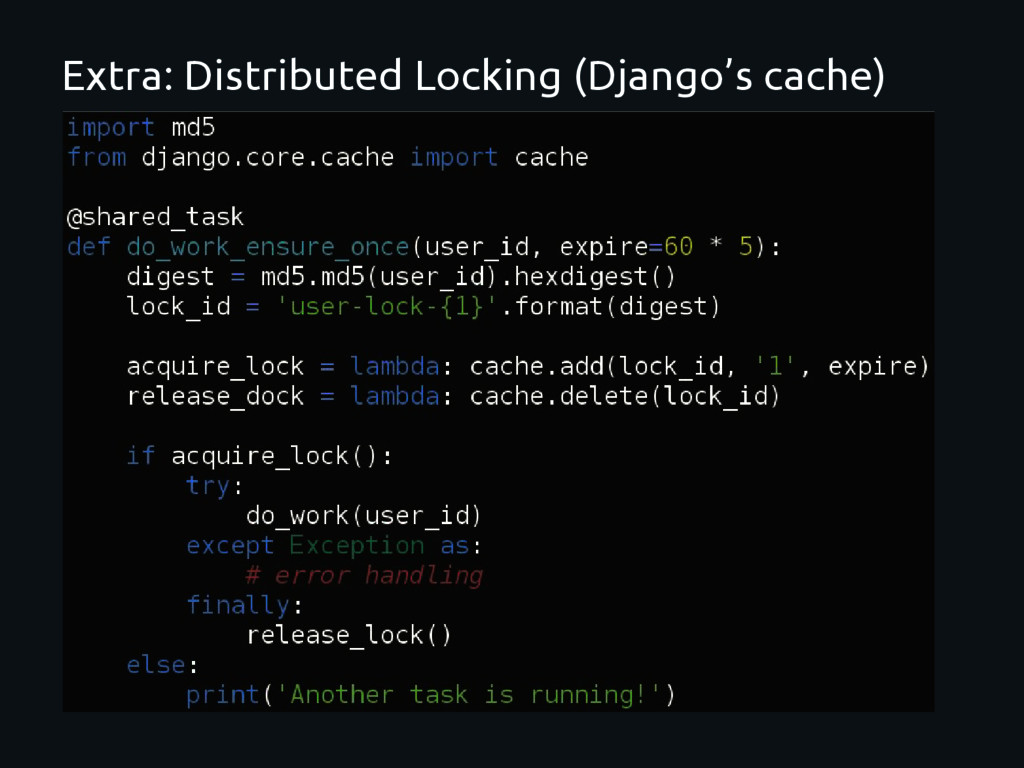
Define what happen when a task is called. Define what to do when a worker receive the a task. Every task has a name. Basically callables objects with “magic”. By convention are placed in tasks.py Created using a decorador: @shared_task (from celery import shared_task)
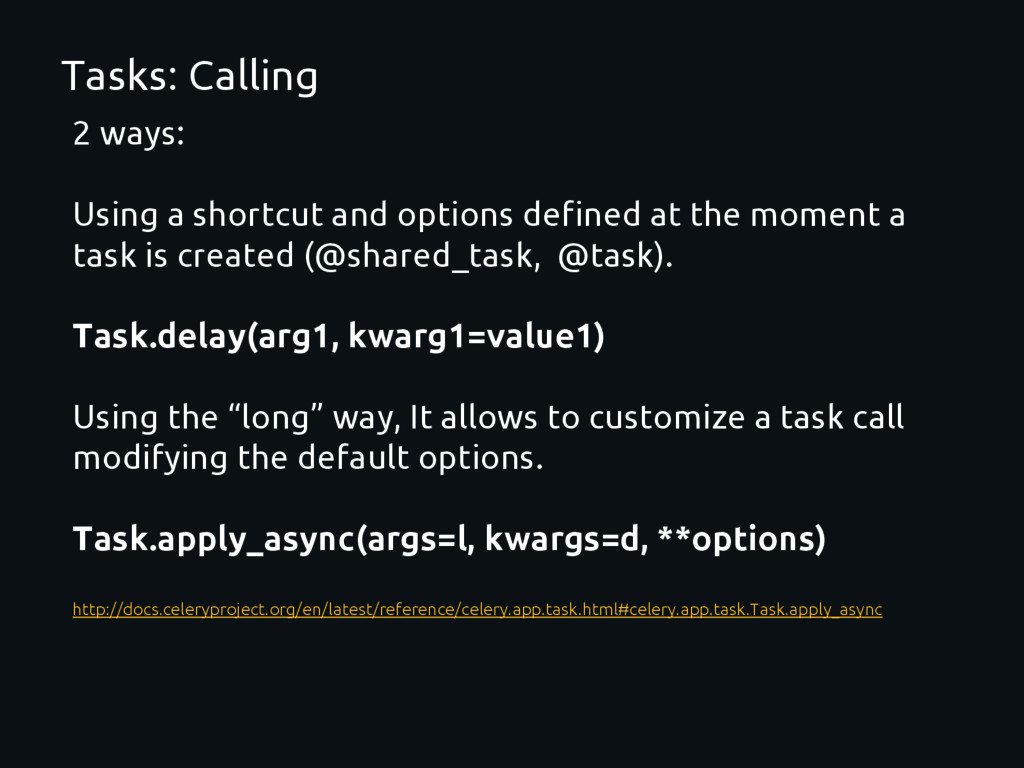
at the moment a task is created (@shared_task, @task). Task.delay(arg1, kwarg1=value1) Using the “long” way, It allows to customize a task call modifying the default options. Task.apply_async(args=l, kwargs=d, **options) http://docs.celeryproject.org/en/latest/reference/celery.app.task.html#celery.app.task.Task.apply_async
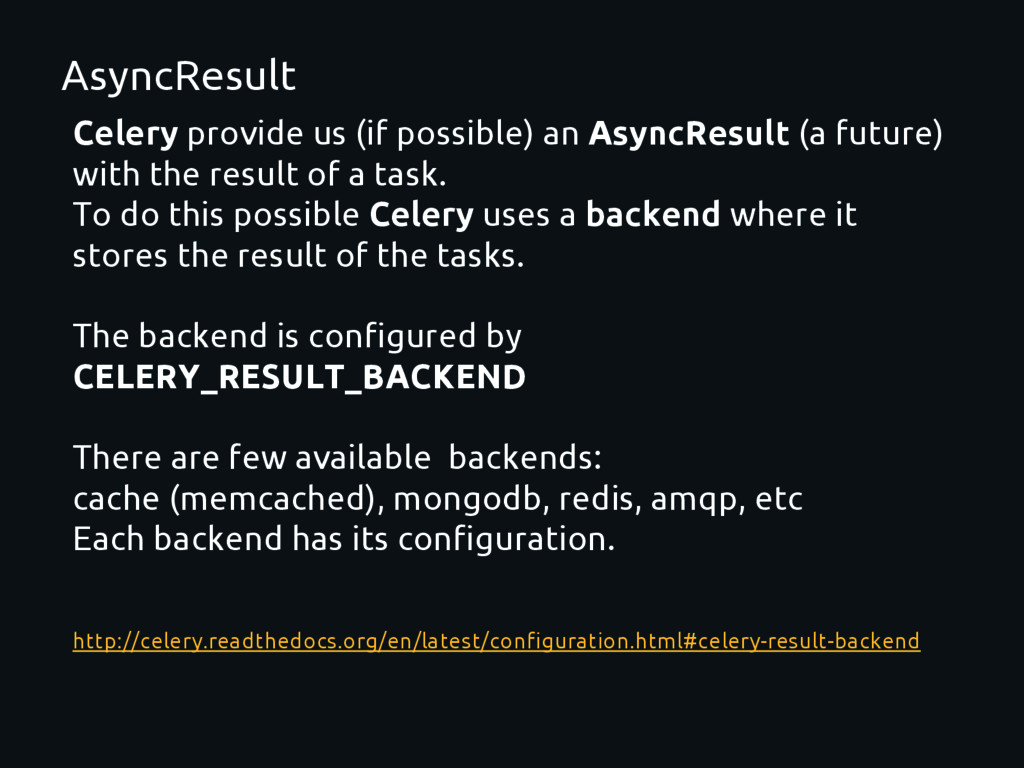
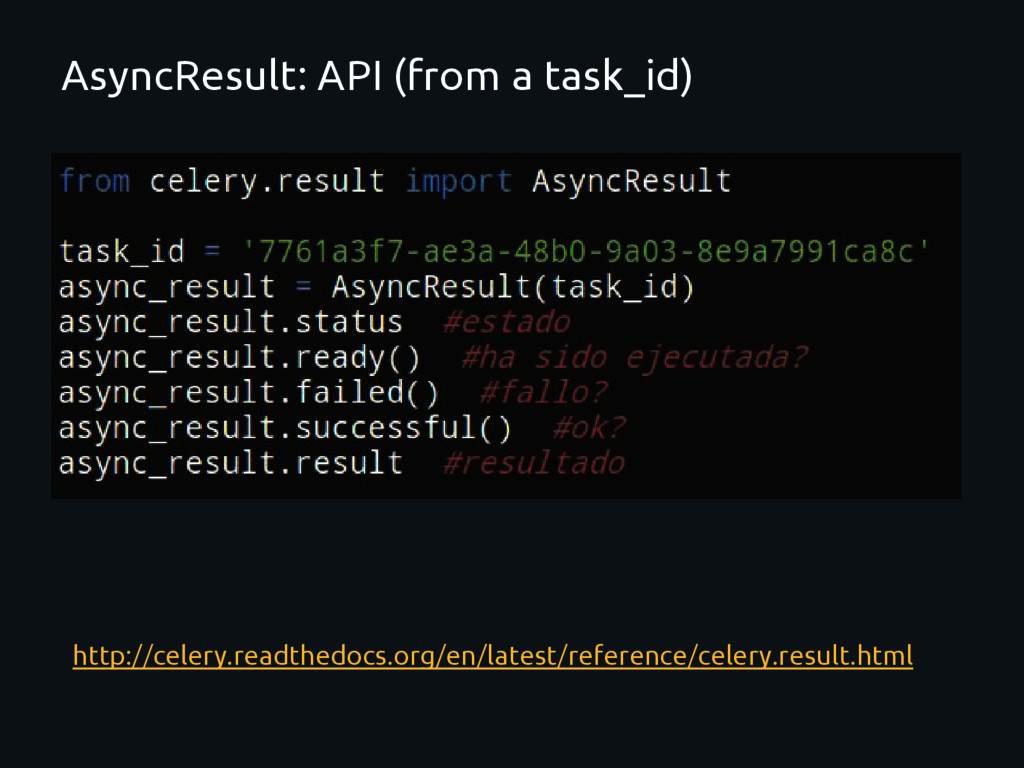
with the result of a task. To do this possible Celery uses a backend where it stores the result of the tasks. The backend is configured by CELERY_RESULT_BACKEND There are few available backends: cache (memcached), mongodb, redis, amqp, etc Each backend has its configuration. http://celery.readthedocs.org/en/latest/configuration.html#celery-result-backend
as well as process chunks. For this purpose Celery uses something called PRIMITIVES. group: Executes task in parallel.. chain: Links tasks, add callback ( f(g(a)) ). chord: A group plus a callback (Barrier). map: Similar to Python map(). chunks: Separates a list of elements in small parts. http://docs.celeryproject.org/en/latest/userguide/canvas.html
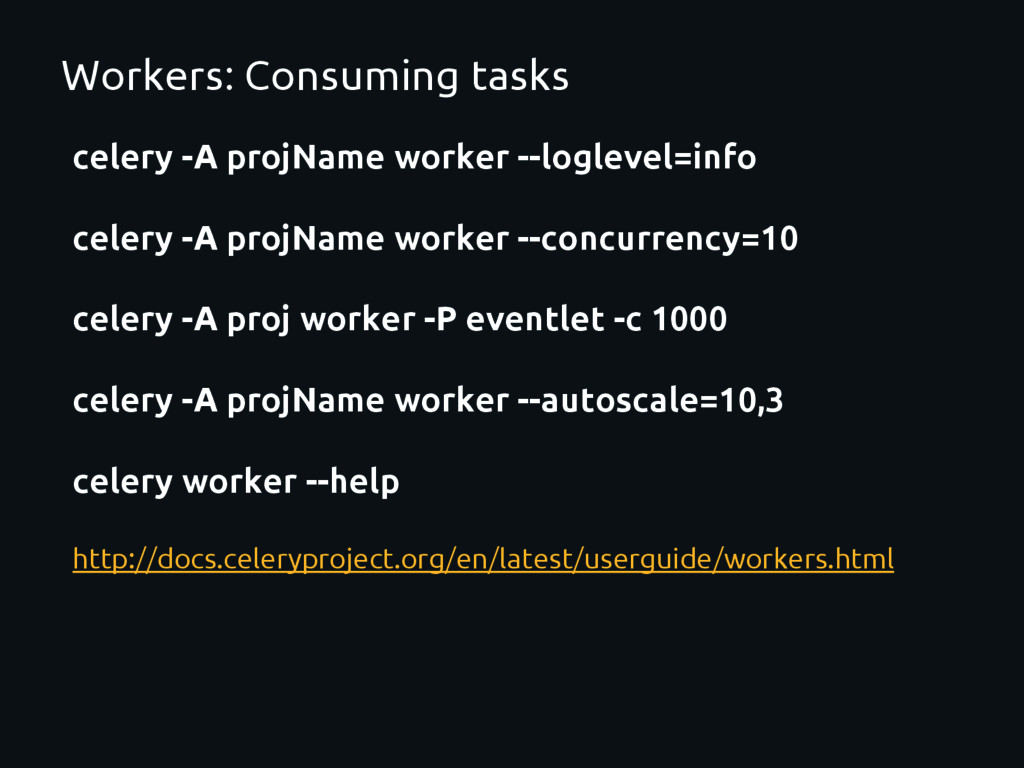
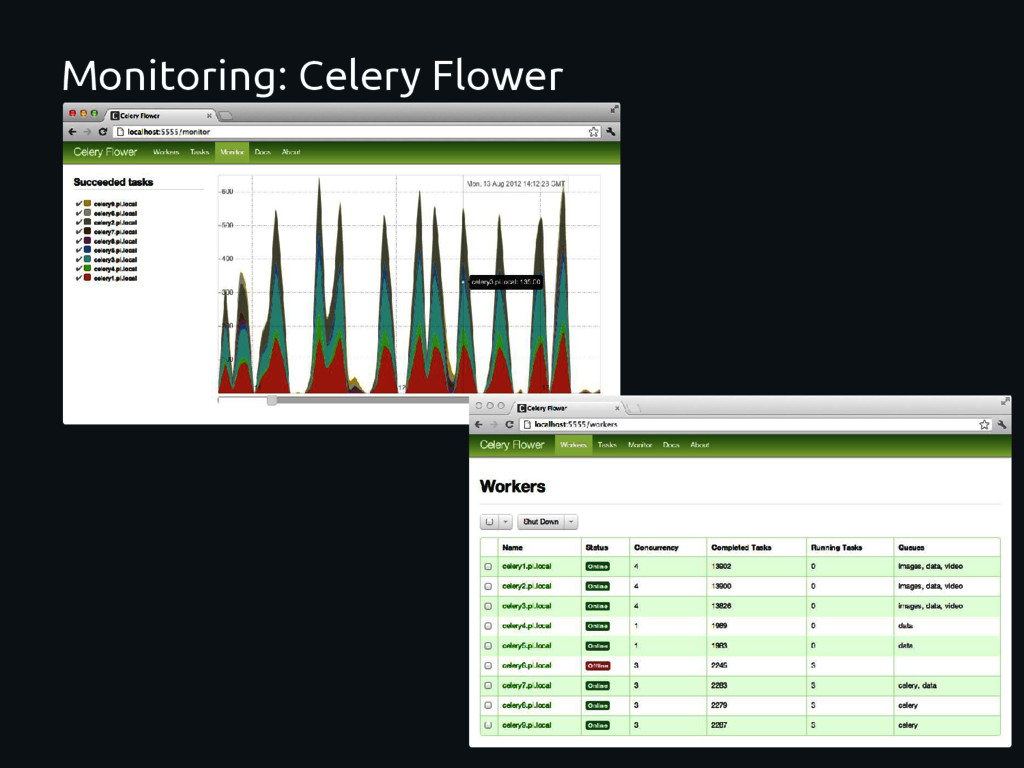
about the tasks. Graphs and stats. Remote Control: Status and stats of the workers. Shutdown or reboot workers. Control autoscaling and pool size. See tasks execution status tareas. Queues administrations. ETC… pip install flower celery -A projName flower --port=5555
with flexible architectures Allow communication between technologies AMQP is a good protocol (www.amqp.org). Distributed Systems: Are complex but scalable Add complexity to the stack Allow to distribute work loads Require maintenance/monitoring Harder to debug (more when multi-worker) More services but smaller (micro-services)
Is the framework that each Pythonista should test when play with DS. Is a mature projects with good support. Has a good documentation. Is simple to configure and run. Is a WORLD to learn and understand in deep. Could be extended “easily”. (signals, management commands, remotes). Has LOTS of settings and features Should be monitored as a normal service. Something that I do not know… =)
![“Asynchronous working with Python/Django” Martin Alderete @alderetemartin [email protected]](https://files.speakerdeck.com/presentations/d43709e87ecb45589f54f8293005d188/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Muito Obrigado ¿Perguntas? Martin Alderete @alderetemartin [email protected]](https://files.speakerdeck.com/presentations/d43709e87ecb45589f54f8293005d188/slide_30.jpg){kind=link}
{kind=link}
{kind=link}