Introducción a los brokers de mensajes • Algunos brokers de mensajes • Soluciones propuestas a la problemática ◦ Arquitectura ◦ Analysis ◦ Resumen • Extra: Lock distribuido • Extra: Taskqueue (Appengine) • Pensamientos y conclusiones Agenda
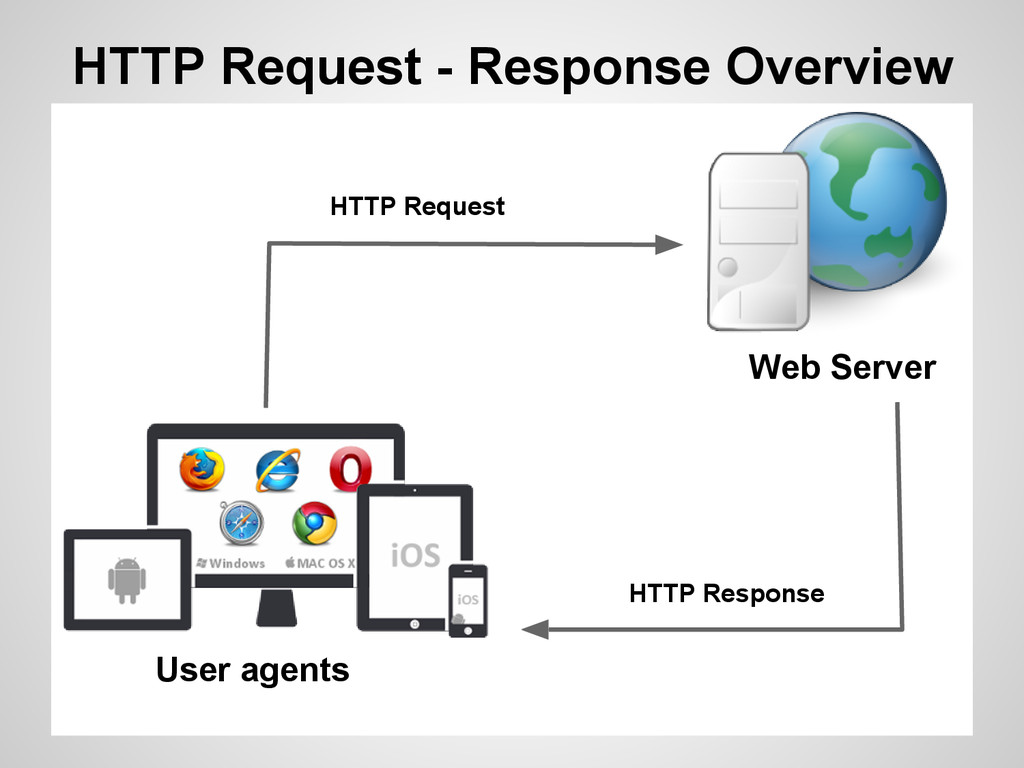
Request-Response (pregunta-respuesta). Protocolo SIN estados. Posee varios verbos (GET, POST, PUT, DELETE, ...) Define varios User-Agent Apps cliente (browser, crawlers, etc) Proxies webservers MÁS RÁPIDO SE RECIBE UN RESPONSE MEJOR ES! Repaso HTTP (HyperText Transfer Protocol)
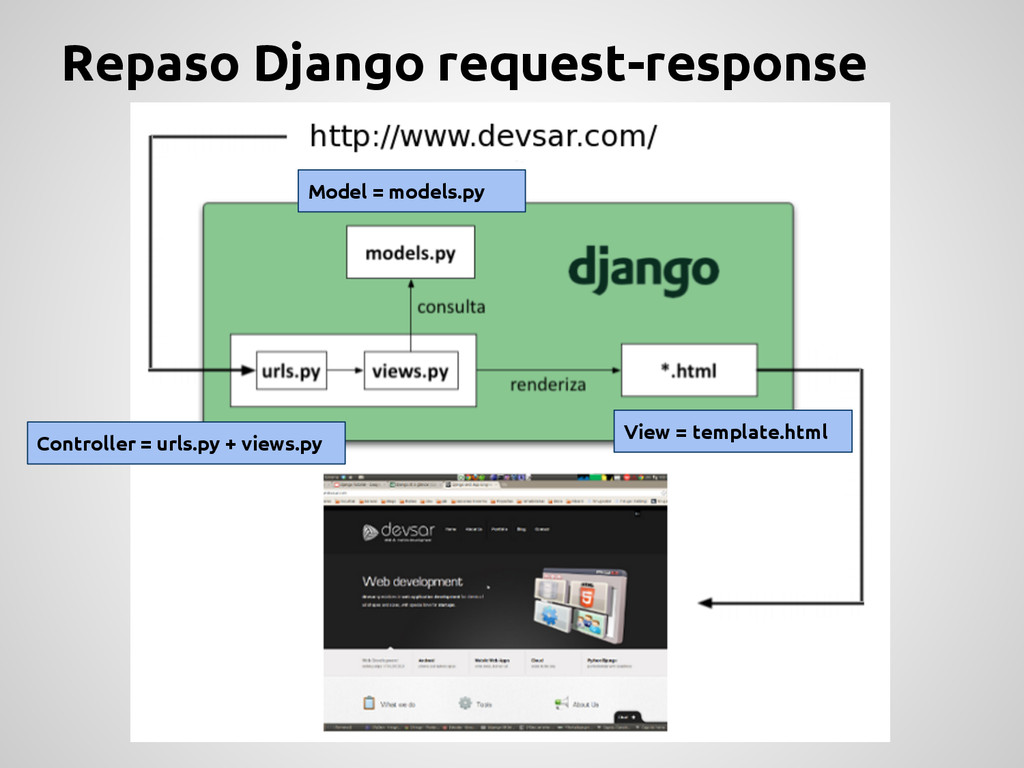
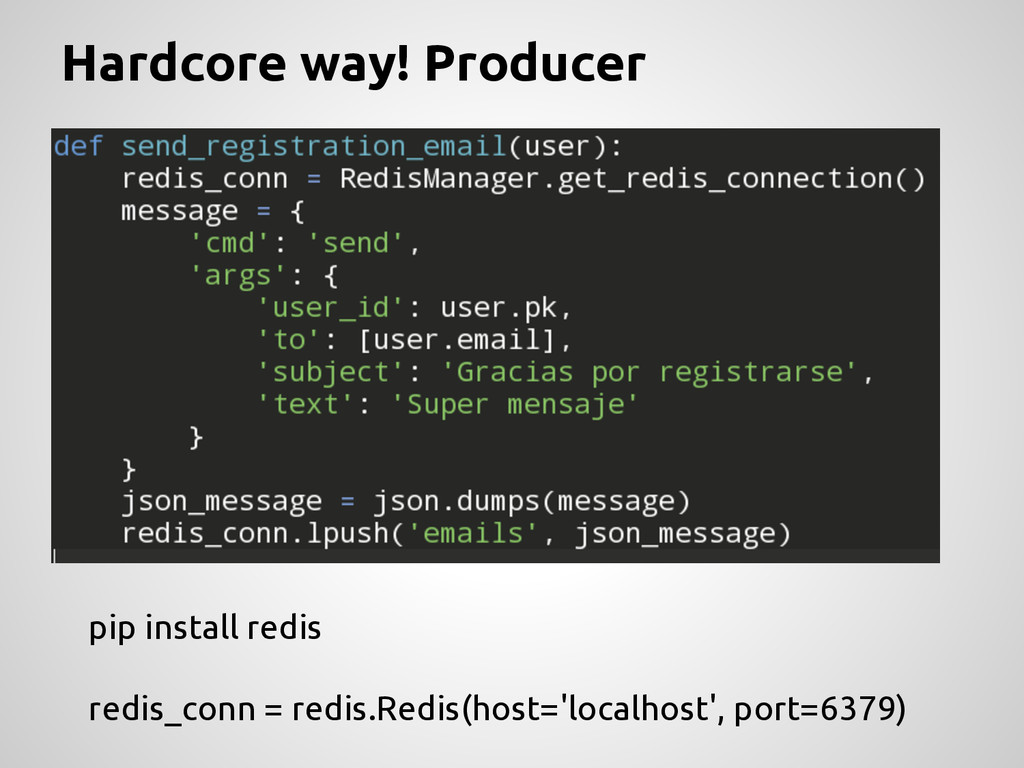
No puede moverse a otra máquina Propenso a ser un “cuello de botella” Necesita manejo de errores extras (poco DRY) send_registration_email(user) es bloqueante No escala! El trabajo “pesado” DEBE sacarse del ciclo Request-Response. Pesado: “Todo aquello que puede demorar, agregar overhead o no es necesario inmediatamente”
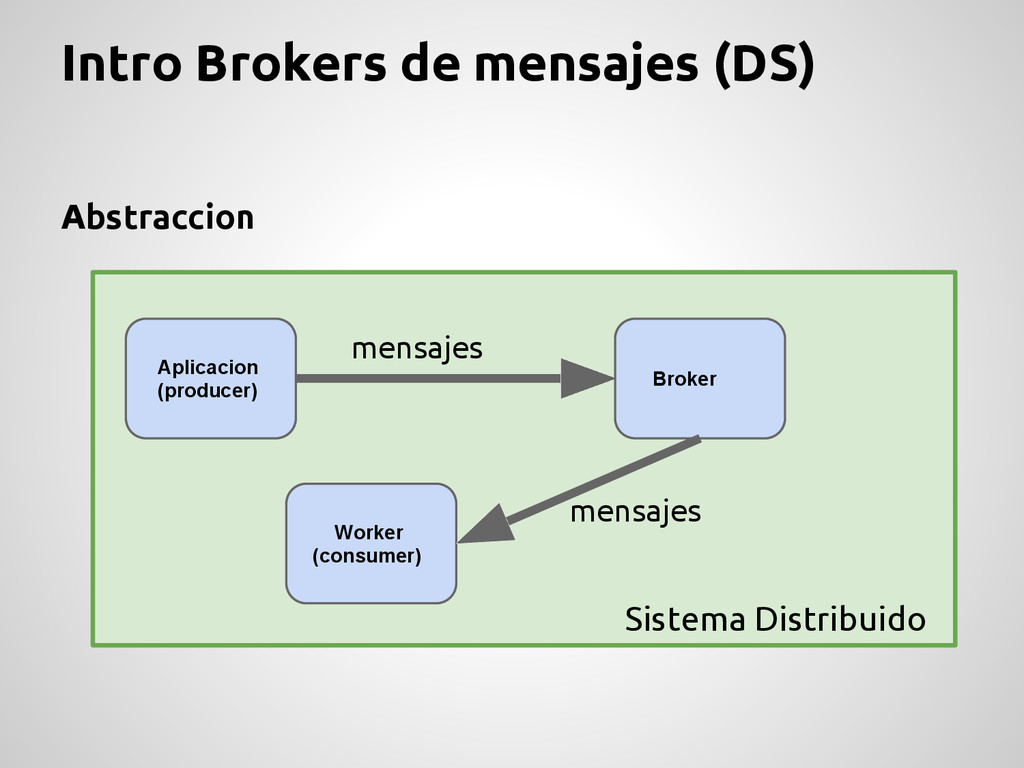
(FIFO-like) Generalmente se parecen a una HASH (key-value) Permiten desacoplar el sistema Permiten distribuir el sistema Permiten la intercomunicación entre tecnologías Permiten escalar de forma “mas” natural Desventajas Pensemos que Sistema == Sistema distribuido Agregan complejidad al stack Necesidad de mantenimiento
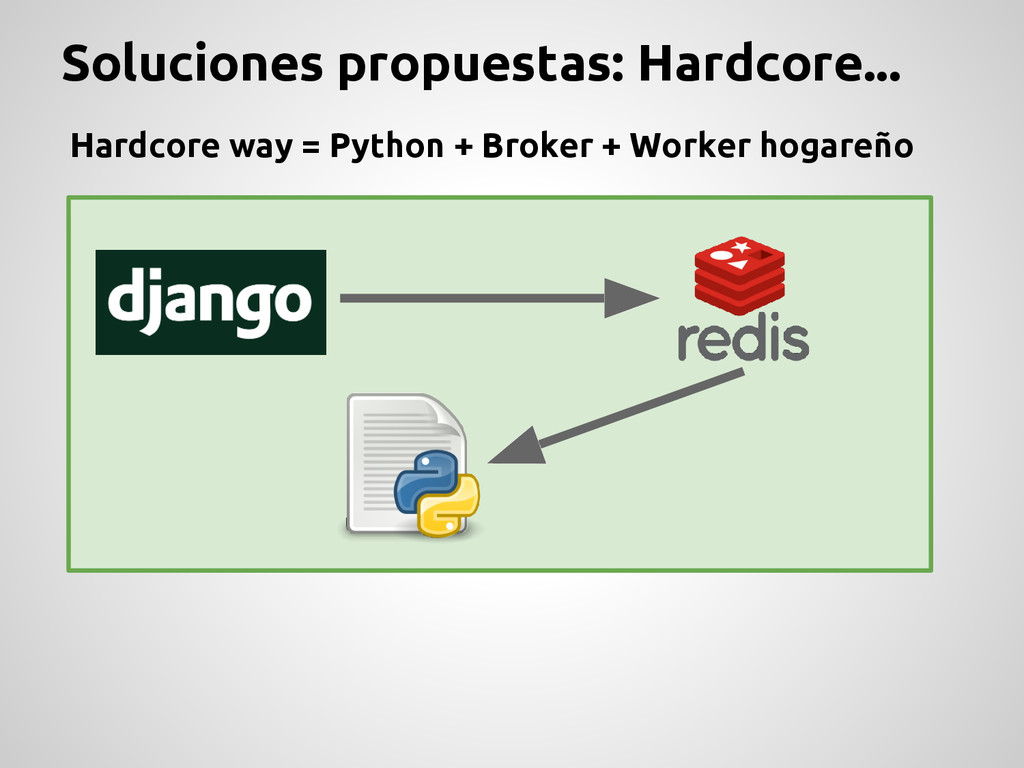
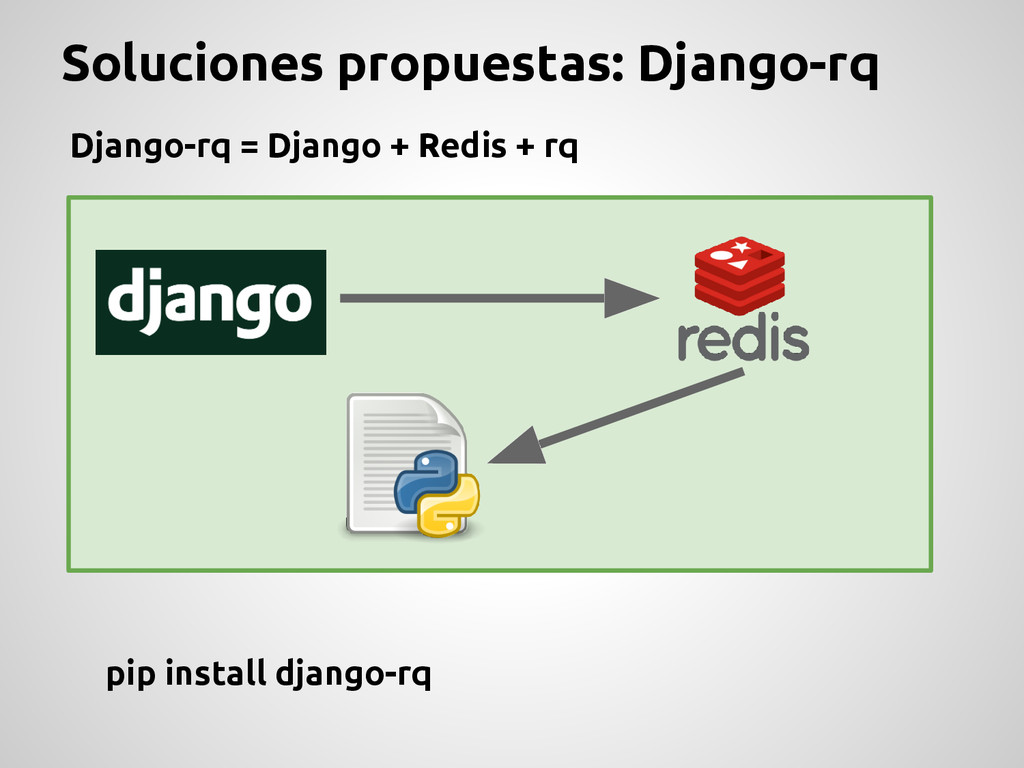
Producer Desacopla el sistema Mueve el trabajo pesado a otro lado Control absoluto por parte de los desarrolladores Todo debe ser hecho “from scratch” Pegado a un solo broker (Redis) Escalabilidad limitada Se re-escribe mucho código Monitoreo ? Administracion ?
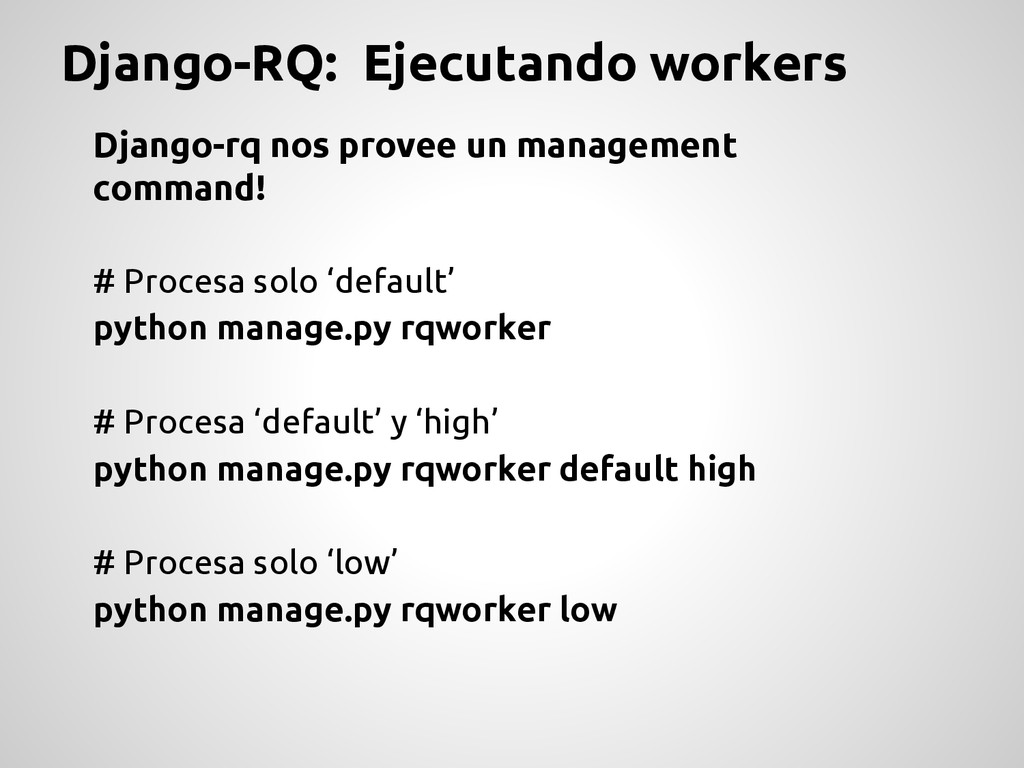
# Procesa ‘default’ y ‘high’ python manage.py rqworker default high # Procesa solo ‘low’ python manage.py rqworker low Django-rq nos provee un management command!
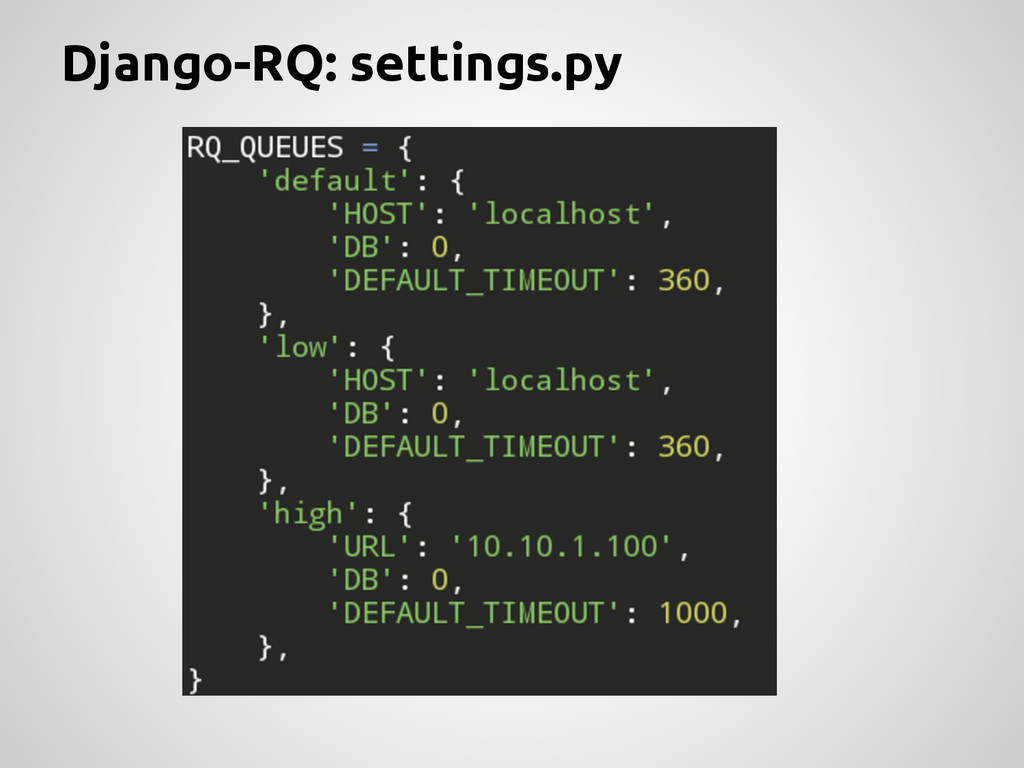
“Queues” en las settings Concepto de “Job” y “Worker” Abstracción de la conexión contra Redis Abstracción de la comunicación con Redis Comando de Django para ejecutar workers Debemos crear jobs y ejecutar un worker Solo para Redis No almacena Resultados (debemos hacerlo nosotros) Para proyectos no muy demandantes ni que necesiten escalar mucho anda bien :)!
based on distributed message passing. It is focused on real-time operation, but supports scheduling as well. The execution units, called tasks, are executed concurrently on a single or more worker servers.
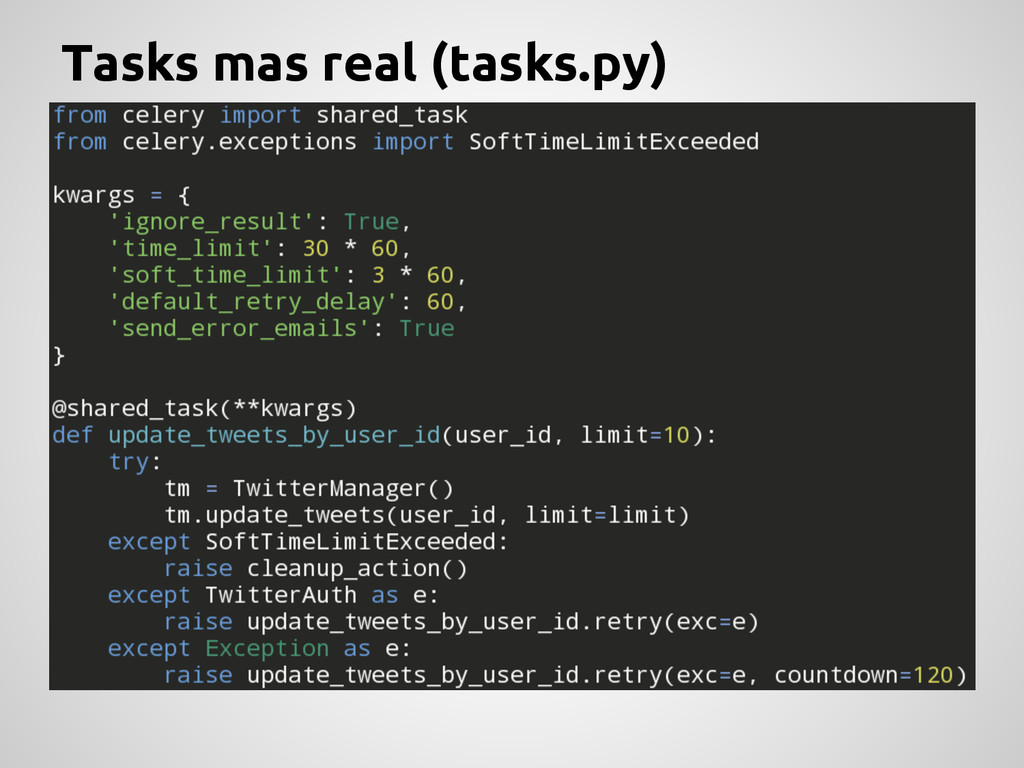
una clase. Tienen 2 responsabilidades: Definir que pasa cuando una task es llamada. Definir que hacer cuando el worker recibe la task. Todas las tasks tiene un nombre único. Son basicamente callables de python con magia. Por convension van en tasks.py Se crean usando un decorador: Reusable django apps/libraries @shared_task (from celery import shared_task) App concreta @task (from celery.task import task)
opciones definidas en el momento de crear la tarea (@shared_task, @task). Task.delay(arg1, kwarg1=value1) Usando la forma “larga”, permite customizar la llamada a la tarea modificando opciones de la tarea. Task.apply_async(args=l, kwargs=d, **options) http://docs.celeryproject.org/en/latest/reference/celery.app.task.html#celery.app.task.Task.apply_async
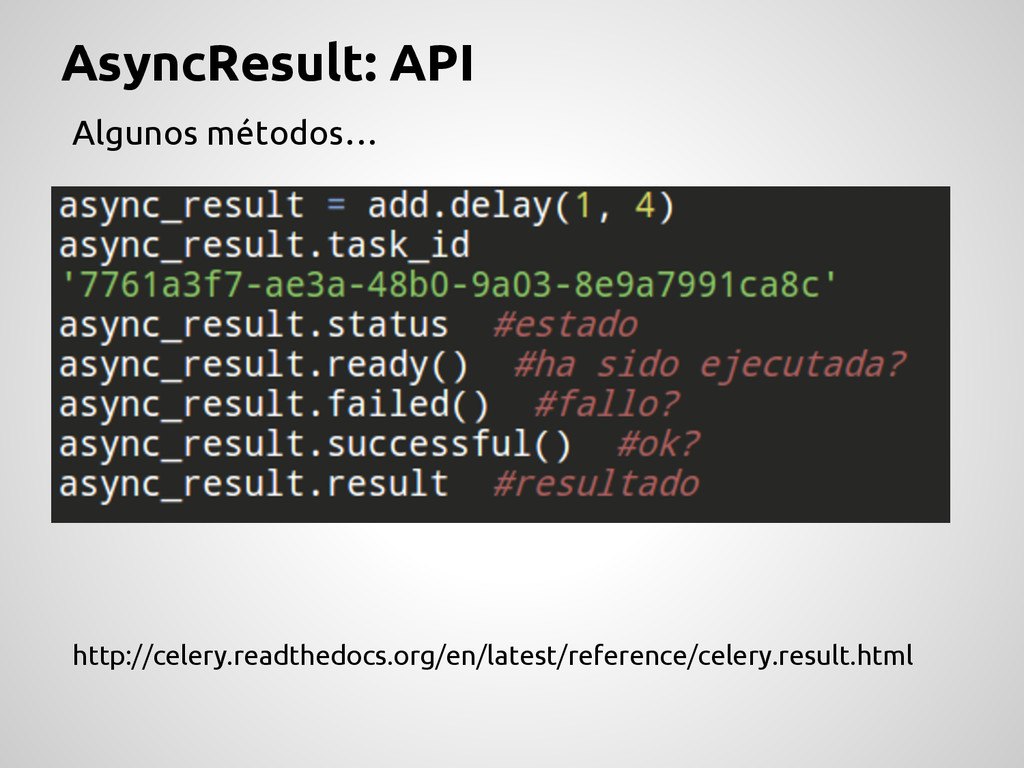
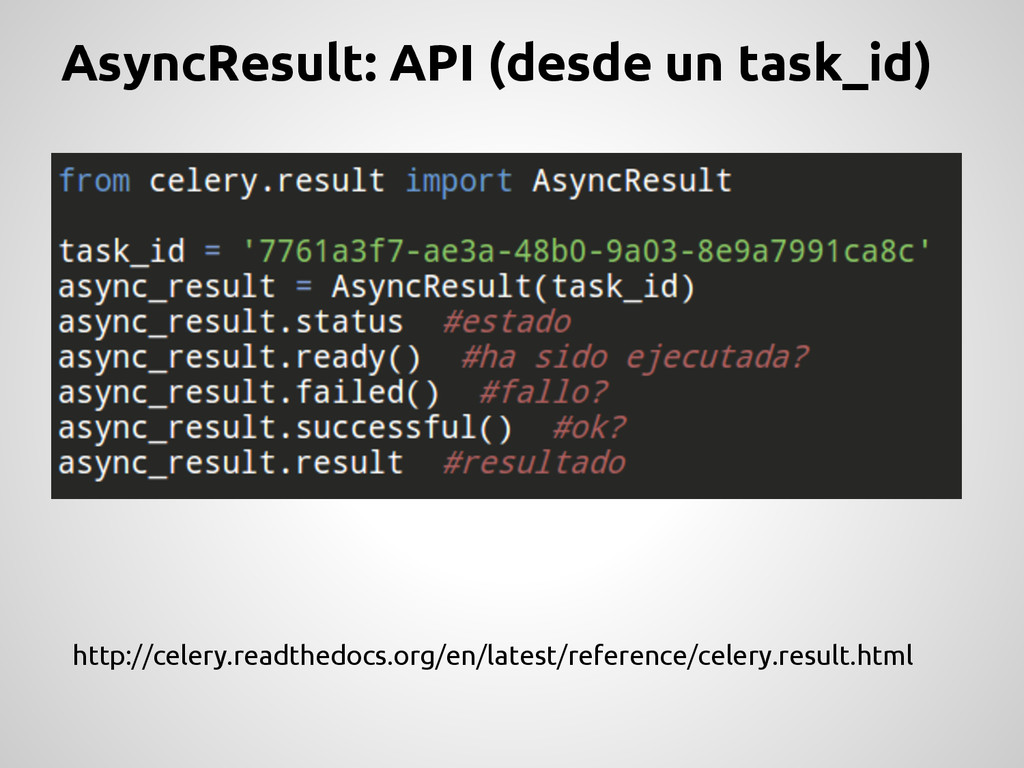
future) con el resultado de ejecutar una tarea. Para que esto sea posible Celery utiliza un backend en donde almacena los resultados de las tareas. Este backend se configura en CELERY_RESULT_BACKEND Algunos backend validos son: cache (memcached), mongodb, redis, amqp, etc Cada backend tiene su configuracion. http://celery.readthedocs.org/en/latest/configuration.html#celery-result-backend
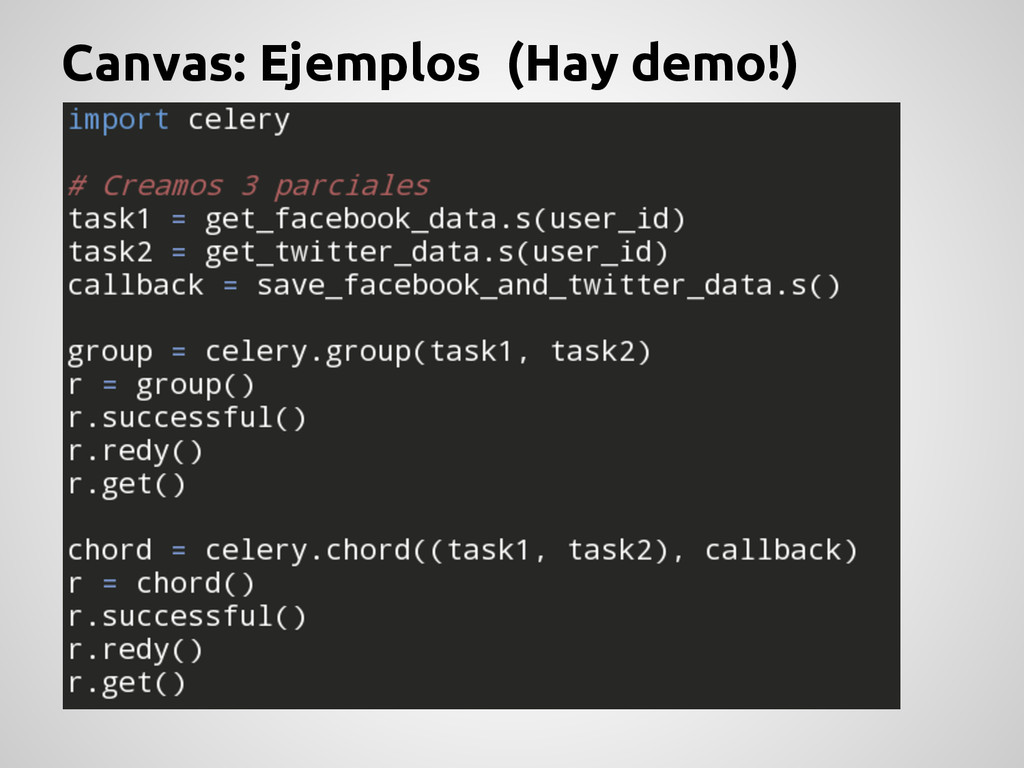
tareas, agregar callbacks, como así también procesar chunks de argumentos. Para esto se utiliza lo que Celery llama PRIMITIVAS. partial: Crea funciones parciales. group: Ejecución en paralelo. chain: Encadena tareas( f(g(a)) ). chord: Un grupo más un callback (Barrier). map: Similar a map() de Python. starmap: Similar a map() pero usa *args chunks: Separa una lista larga de elementos en partes. http://docs.celeryproject.org/en/latest/userguide/canvas.html
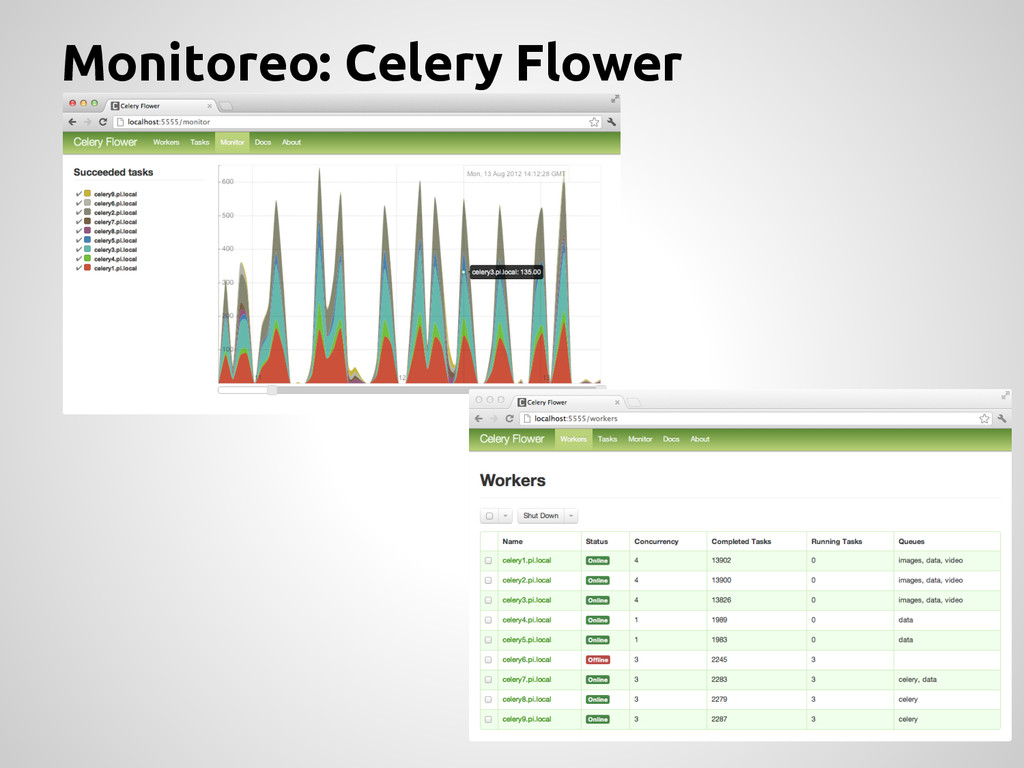
de tareas. Información sobre las tareas. Graficos y estadisticas. Control remoto: Estado y estadísticas de los workers. Apagado y reinicio de workers. Controlar autoscaling y pool size. Ver tareas que estan en ejecución. Administracion de queues. ETC… pip install flower celery -A projName flower --port=5555
Permiten sistemas con arquitecturas flexibles. Permiten la intercomunicación entre tecnologías. AMQP es un muy buen protocolo (www.amqp.org). Los sistemas distribuidos: Son complejos pero escalables. Agregan complejidad en el stack. Permiten distribucion del trabajo. Requieren mantenimiento/monitoreo constante Dificiles de debugear (mas si son multi-worker). Cada vez más servicios y pero más pequeños.
Es EL framework que todo Pythonista en sistemas distribuidos tiene que probar. Es un proyecto con mucho soporte/desarrollo. Tiene muy buena documentación. Es simple de configurar y poner en marcha. Es UN MUNDO para aprender y entender en profundidad. Se puede extender “facilmente” (signals, management commands, remotes). Tiene MUCHAS settings y features que aun no conozco/entiendo… Debe ser monitoreado como cualquier servicio. Algo seguro podemos charlar entre todos :)!
![Trabajando de forma asíncrona en Django/Python Martin Alderete @alderetemartin [email protected]](https://files.speakerdeck.com/presentations/9f9776c0530e0132f28166a11fd8407a/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Muchas Gracias! ¿Preguntas? Martin Alderete @alderetemartin [email protected]](https://files.speakerdeck.com/presentations/9f9776c0530e0132f28166a11fd8407a/slide_43.jpg){kind=link}
{kind=link}
{kind=link}