grafos. • Graph DB’s. • Modelando y conectándonos al grafo con Python. • Caso de estudio: “App para citas” ◦ Problemática. ◦ Modelo IDEAL ◦ Primera solución. ◦ Avances ◦ Nuestra solución usando Python, Django y grafos! ◦ Tecnologias aplicadas • Arquitectura Final • Conclusiones y consideraciones
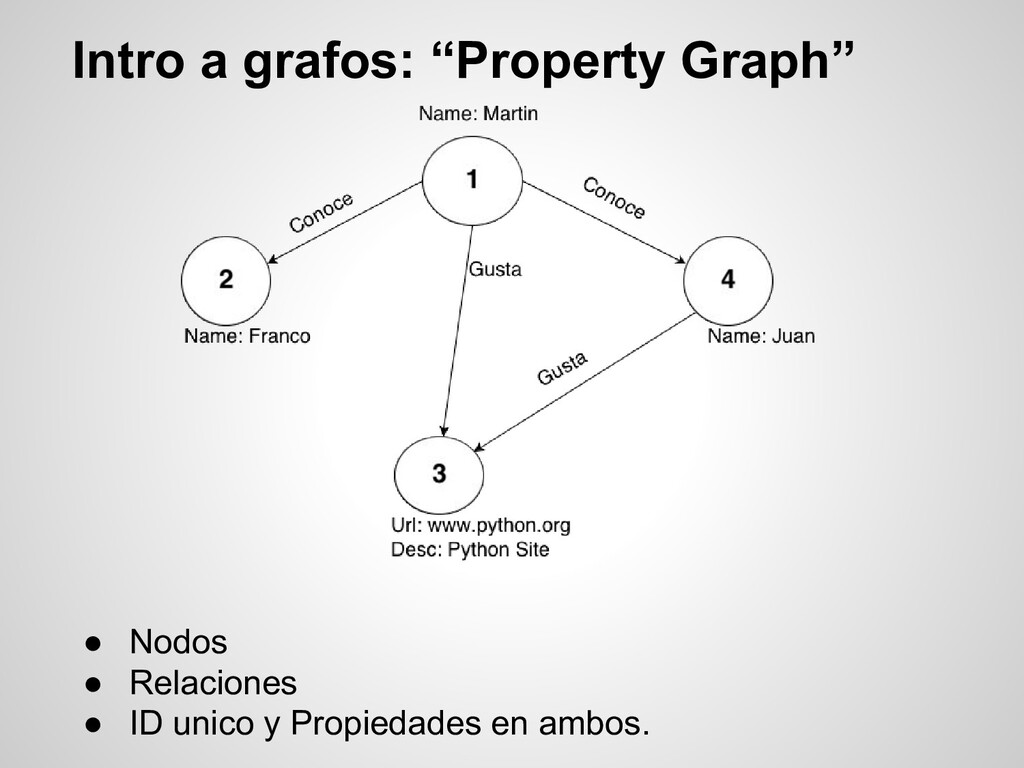
propiedades. Permiten realizar TRAVERSAL "Visitar los nodos de un grafo de una manera específica” Ejemplo: A*, Dijkstra, Floyd-Warshall, BFS, DFS, etc... Lenguajes de consultas específicos ( “EL SQL de los grafos”) Gremlin, Cypher, Thinkerpop, etc... Generalmente no es facil visualizar los datos del grafo, existen herramientas de terceros para facilitarlo. (Gephi, D3.js) Neo4j, TitanDB, OrientDB, FlockDB y varias más!
base de datos de grafos (NoSQL) 2. Permite abstraer el “modelo” del motor que usemos. 3. MUY simple de usar ! 4. MUY parecido al ORM de Django !!!! 5. Permite realizar consultas BASICAS, generalmente usando indices !!! Bulbflow (http://bulbflow.com/) pip install bulbflow (usen virtualenv)
current_datetime class Friend(Relationship): label = "friend" created_on = DateTime(default=current_datetime) Ejemplo completo: g = Graph(...) g.add_proxy(“persons”, Person) g.add_proxy(“friends”, Friend) martin = g.persons.create(**data1) cacho = g.persons.create(**data2) g.friends.create(martin, cacho) martin = g.vertices.index.lookup(id=19) martin.bothE() # tomamos las aristas desde martin martin.bothV() # tomamos los nodos desde martin
permita encontrar personas potencialmente interesantes para los usuarios, utilizando los datos de facebook para buscar entre los amigos y amigos de amigos” En criollo… Una aplicación para buscar pareja escarbando amigos de facebook!
un “juego” • Aprovechar los datos de facebook (friends, likes) • Facil de mantener • Facil de poner en producción/actualizar • Debe andar “rápido” • Debe escalar • Debe ser BARATO ($$$) • ... • etc
• Muchos datos “basura” • Muchos updates/inserts • Muchas request a Facebook • MUCHO procesamiento • Algunos datos cambian “bastante” • Escalar es complicado • La API de Facebook es “rara” • ... • Escalar muchas veces == $$$
= models.StringProperty() friends = model.StringProperty(repeated=True) friends_of_friends = model.KeyProperty() member = model.BooleanProperty(default=False) #Muchos mas Se necesita mucho procesamiento y recursos para que la app funcione “correctamente”. Todos los algoritmos se hacen en memoria.
mantener • MUY difícil mantener los datos sincronizados entre facebook y la app • MUY tedioso, complicado, lento generar las “potenciales citas” • Se torna inusable =( • MUCHAS queries al datastore para los procesos principales • MUCHAS request a Facebook • MUCHO procesamiento offline (taskqueue de appengine) • Tenemos datos viejos la mayoría del tiempo =( • MUCHO $$$ en appengine • IMPOSIBLE escalar
mantener • MUY difícil mantener los datos sincronizados entre facebook y la app • MUY tedioso, complicado, lento generar los “potenciales” citas” • Se torna inusable =( • MUCHAS queries al datastore para los procesos principales • MUCHAS request a Facebook • MUCHO procesamiento offline (taskqueue de appengine) • Tenemos datos viejos la mayoría del tiempo =( • MUCHO $$$ en appengine • IMPOSIBLE escalar
Se agregó una instancia de AWS para correr un servicio (API REST) que se encarga del trabajo “pesado” relacionado a los merge entre las listas de amigos y amigos de amigos…. También sirve como un cache de listas. Básicamente realizaba operaciones de intersecciones entre conjuntos usando REDIS y mantenía todo en memoria. Con esto buscamos aliviar el trabajo a la instancia de AppEngine y tratar de escalar el cuello de botella con la generacion de “potenciales” usuarios.
un poco más, programar fué MUY divertido y entretenido y aprendimos mucho! El testing….horrible/imposible/impredecible/etc, posta que fue duro! Comenzamos a tener problemas nuevos pero no solucionamos los viejos referidos al “core” de la app (generar citas, buscar amigos de amigos). Realmente no escaló, comenzamos a tener más problemas de cache que otra cosa y sumado a eso aumentaron las request, antes Facebook y ahora AWS, esto es $$$.
grafos” • Evaluamos alternativas (tecnología, infraestructura, algoritmos, etc) • Encontramos las DB orientadas a GRAFOS !!! • Comenzamos a investigar, instalar, comparar, probar con distintas DB orientadas a Grafos (Neo4j, TitanDB, alguna otra). • Usamos vagrant para hacer VM’s de test. • Contacto con la comunidad (Gracias Javier de la Rosa!) y nos empezamos a emocionar!!!
partes: Procesos críticos: La generacion de “potenciales citas” para los usuarios. Descubrir amigos de amigos (2 niveles) Descubrir amigos de amigos de amigos (3 niveles) Descubrir amigos en común etc... Procesos NO críticos: Obtener los datos de Facebook Actualizar datos Crear nuevos usuarios Mantener datos relacionados con la app. etc...
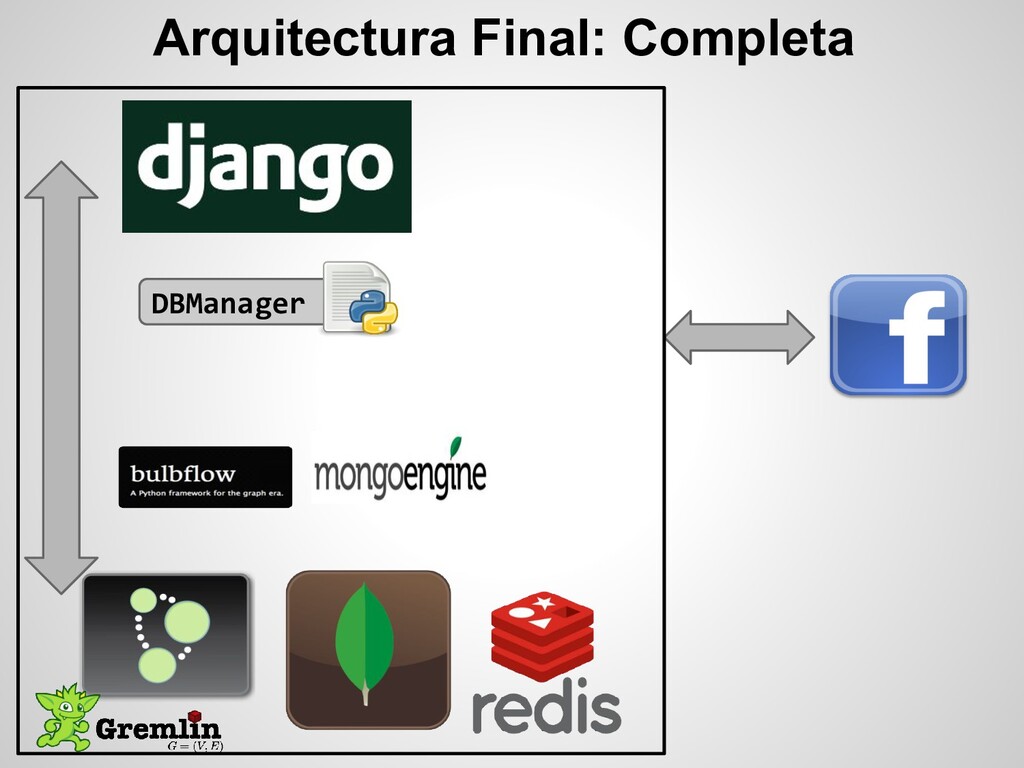
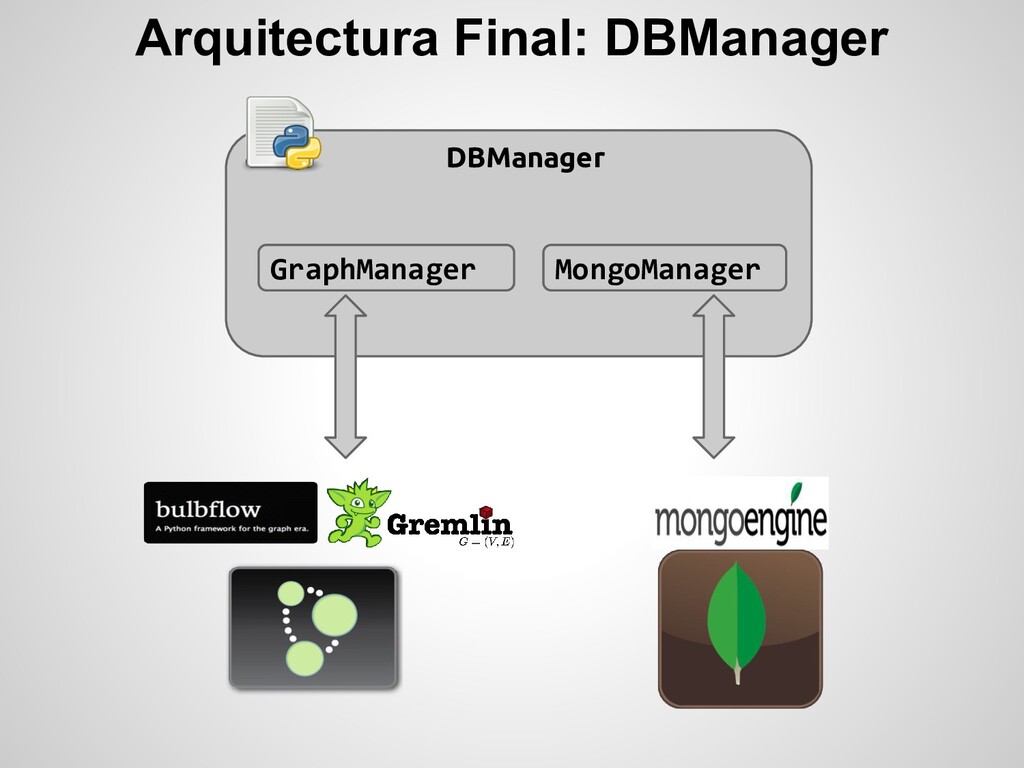
para todo lo relacionado a la lógica de la aplicación. users, cities, potentials, user_stats, user_preferences, etc Y se utiliza Neo4j para almacenar nodos que representan a cada usuario y amigos dentro del sistema y relaciones que indican quien es amigo de quien. Utilizando Redis para encolar tareas que se ejecutan en background, como por ej. TRAVERSAL del grafo para buscar “potenciales citas” o “buscar amigos en común” para un usuario.
el usuario en Mongodb, se obtienen datos del profile de Facebook, si existe pero no esta marcado como miembro entonces se convierte en miembro y se actualizan los datos en Neo4j y Mongodb sino se inserta en Neo4j y Mongodb un nodo, document nuevo. Se obtienen los amigos y se hace un Insert/update en batch tanto a Neo4j como a Mongodb la info que se tiene de cada amigo es reducida. Luego se hace insert/update/delete de las aristas (relaciones) necesarias en Neo4j. Se encola un job en Redis para generar “potenciales citas” para el user que se registro. El worker usa Gremlin.
por medio de REDIS se encolan trabajos. Un worker (Python) llama al script de Neo4j escrito en Gremlin (“SQL de los grafos”) y le pasa el fbid del usuario y las preferences. El script se para en el nodo del fbid y hace un TRAVERSAL en profundidad hasta 3 niveles (amigos, amigos de amigos, amigos de amigos de amigos). Por cada uno de los nodos que va visitando se fija si cumple las preferences que se le pasaron, si las cumple lo colecta sino lo ignora y pasa al próximo. El worker toma cada uno de esos nodos e inserta en Mongodb en la collection potentials. Más tarde con Python se aplica un nivel de filtro más como por ejemplo GeoLocation usando GeoSpatial index.
dedicado al grafo Miembros ~20K DB Size 13.9 M Nodos 32.4 M Aristas (un solo tipo “friends”) 62.7 M Propiedades Registrar un usuario Insertar un user y todos sus amigos Promedio de amigos por usuario: ~700 Tiempo promedio de inserts/updates: ~715.5/seg
117.4K Max 1.3M Tiempos Media: 0.89 seg Promedio: 8.4seg Max: 60 seg (si en 60 seg no retorna se cancela) Los “TRAVERSAL” sin el grafo podían tardar HSSSS!!!
de grafos! Estan emergiendo y mejorando mucho y rápido. Al pasar el tiempo la cantidad de nodos que se insertan debería tender a cero. Podemos hablar de tener un grafo “estático” en algún momento. Hacer esta aplicación con Pytho, Django y Neo4j estuvo BUENISIMO! Sólo tuvimos que escribir código “raro” para el TRAVERSAL el resto TODO PYTHON!! NO LE ESCAPEN A ESTAS DB’s si las necesitan!
de grafos! Los inserts no son baratos siempre. Los TRAVERSAL son excelentes! Las Graph DB’s como cualquier otro motor necesitan tunning y análisis. Se necesita MUCHA RAM para que el grafo esté en memoria y las consultas sean más rápidas. Guardar en los nodos y relaciones lo mínimo e indispensable para resolver el problema. Utilizar el grafo para problemáticas de grafos, generalmente cuando necesitamos TRAVERSAL o tenemos mucha interrelación de datos. Algo mas me debo olvidar...
![Recorriendo Nodos con Python Martin Alderete [email protected] Martin Riva [email protected]](https://files.speakerdeck.com/presentations/332a32da0bed4c3b9e0c791a9a09cdd3/slide_0.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Muchas Gracias! ¿Preguntas? Martin Alderete [email protected] Martin Riva [email protected] while](https://files.speakerdeck.com/presentations/332a32da0bed4c3b9e0c791a9a09cdd3/slide_39.jpg){kind=link}