presented during: https://www.meetup.com/Applied-Machine-Learning-by-Cubonacci/events/267873547/
Marijn Lems (iam.io) will take you through the process of training the deep learning model that they use for image matching.
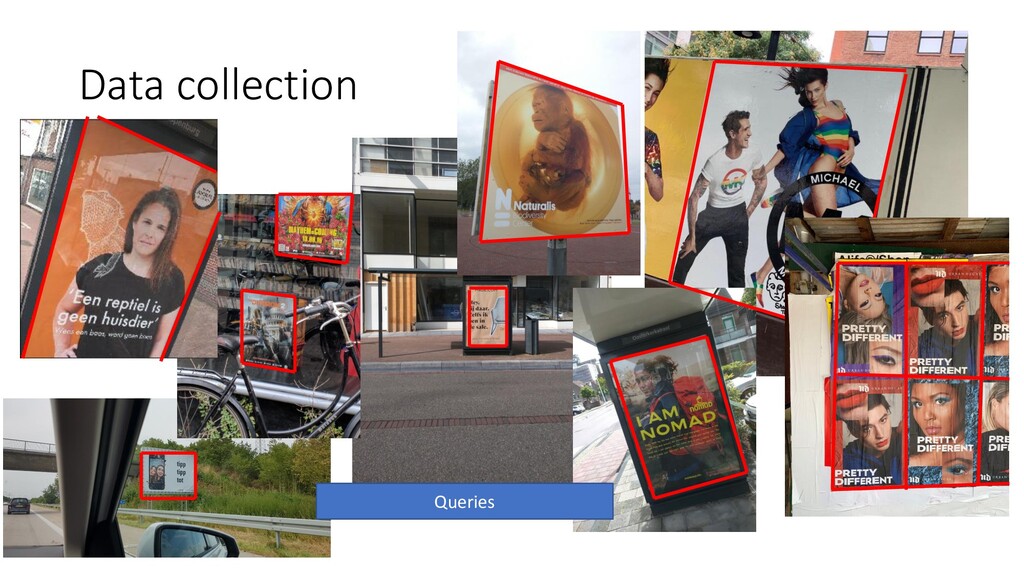
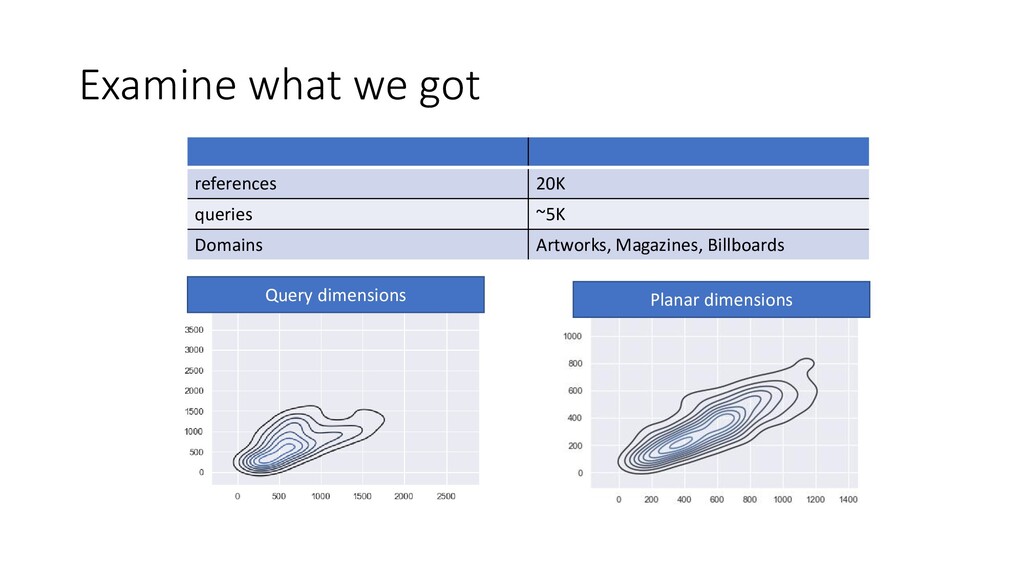
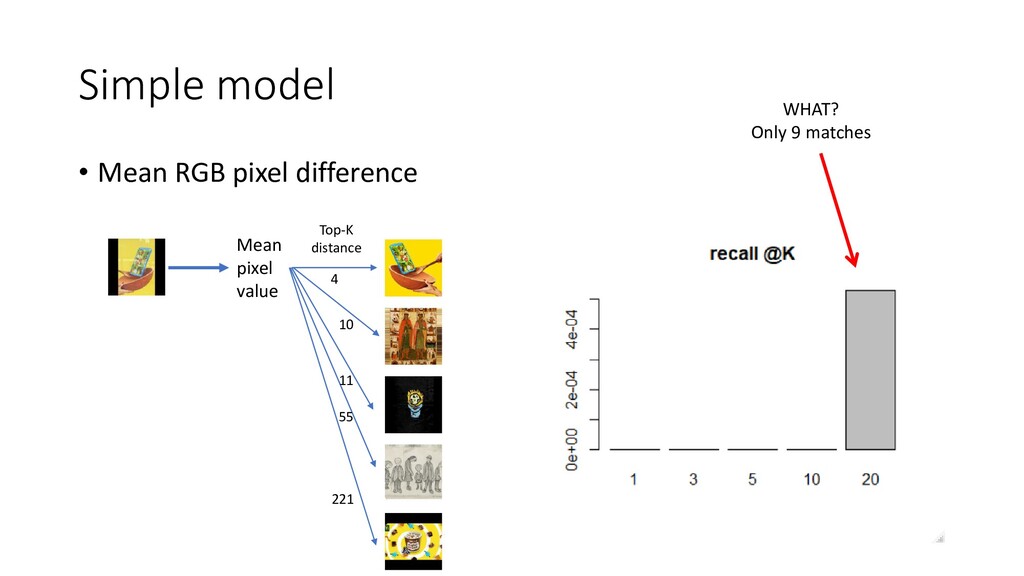
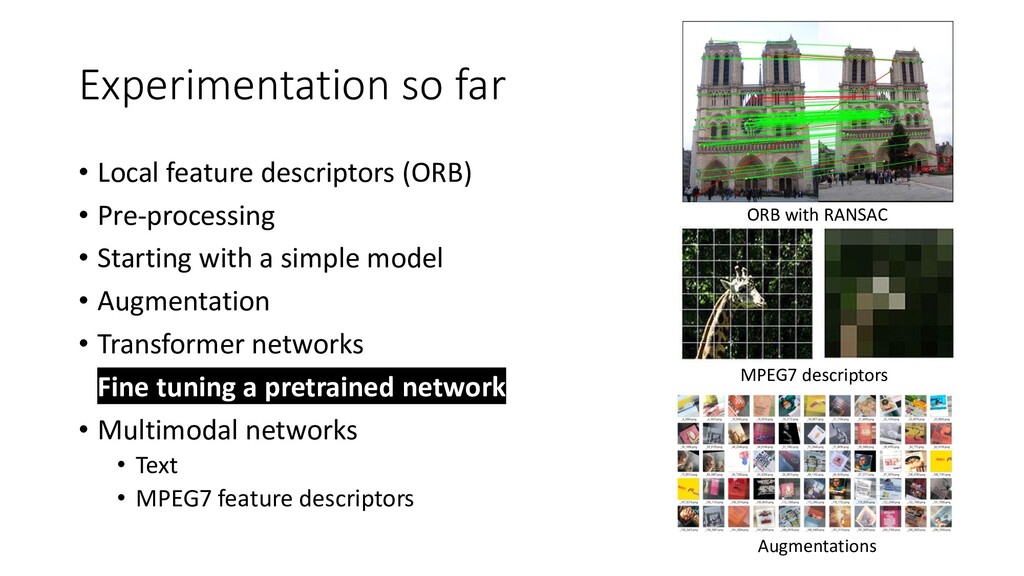
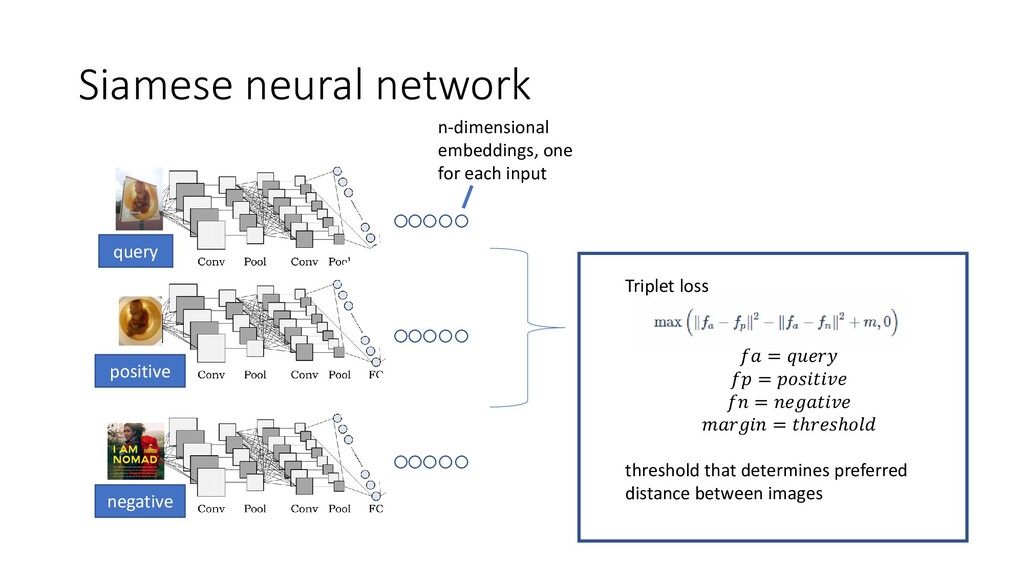
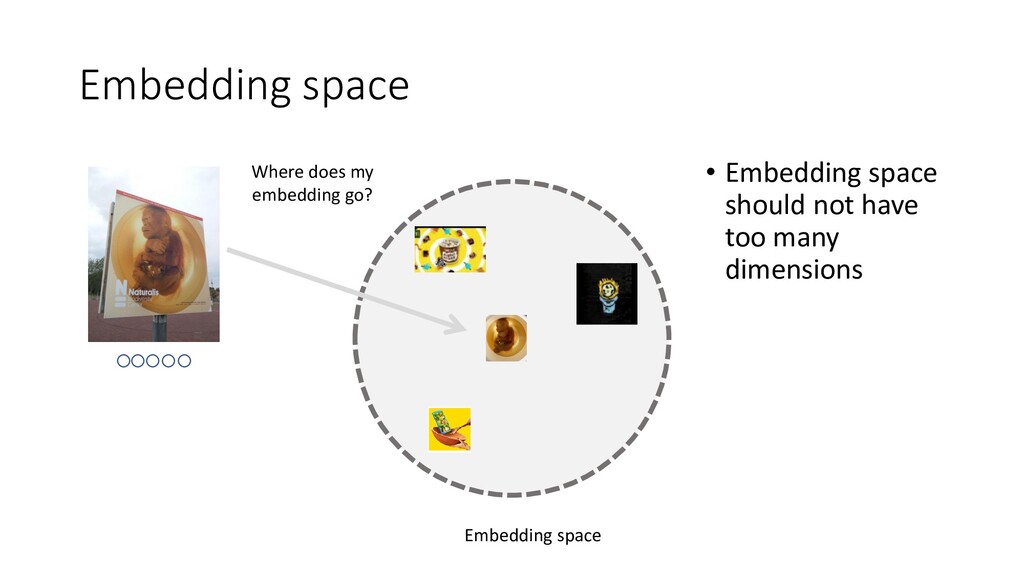
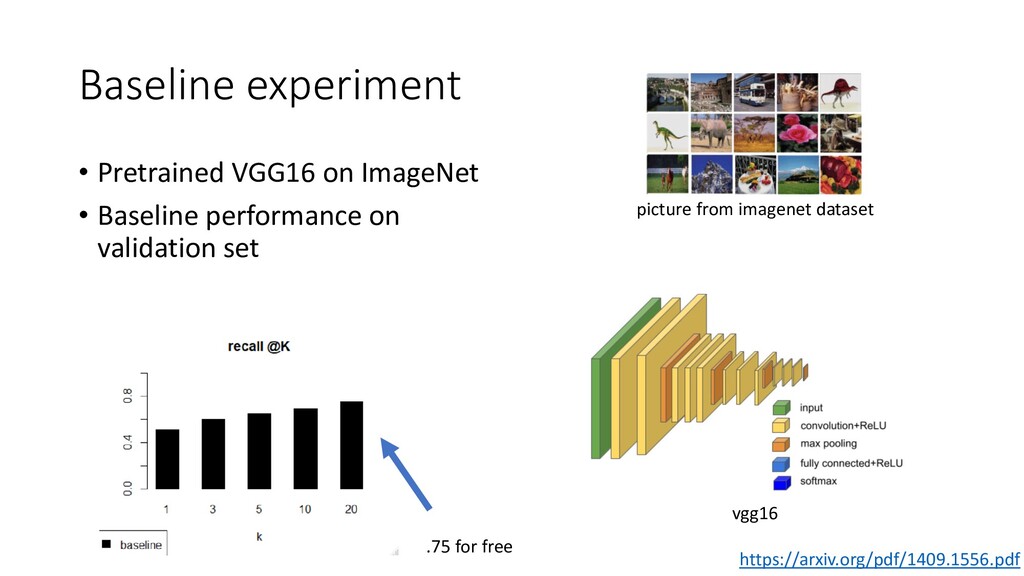
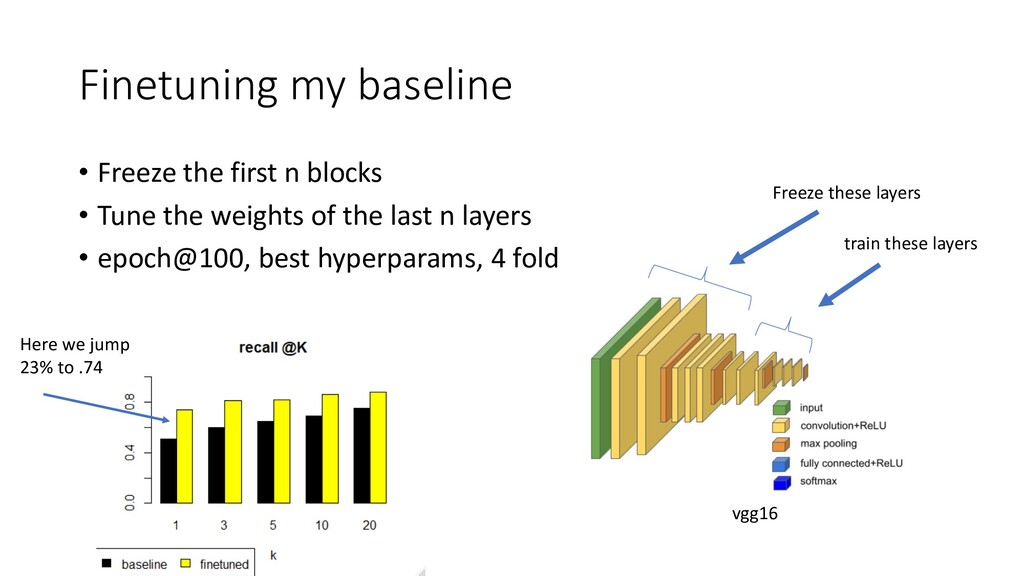
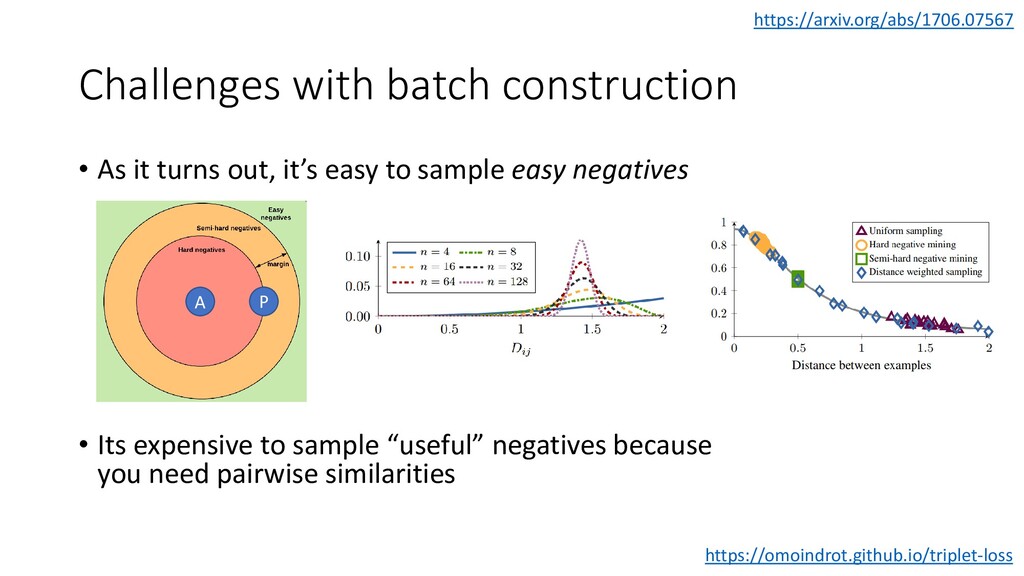
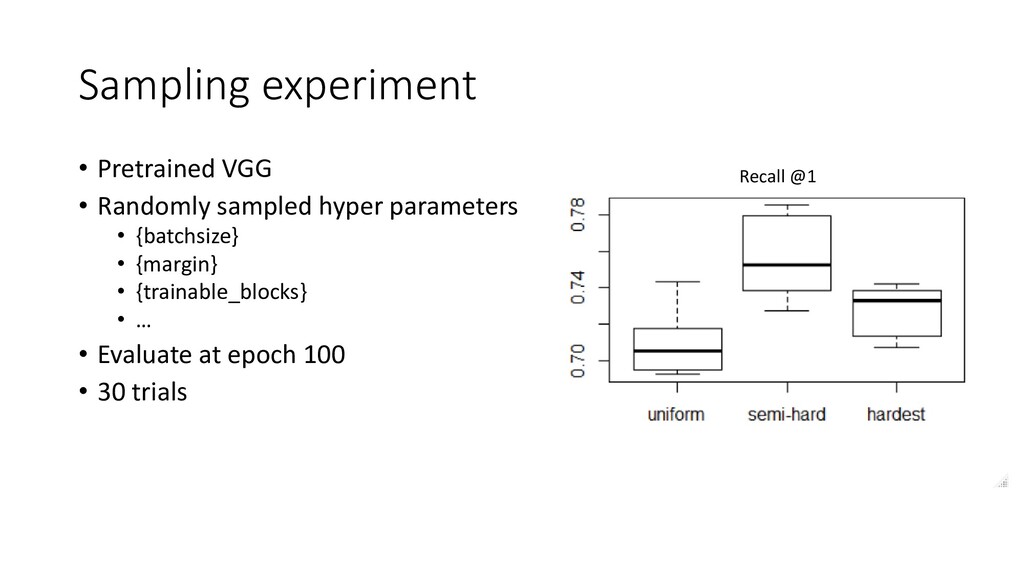
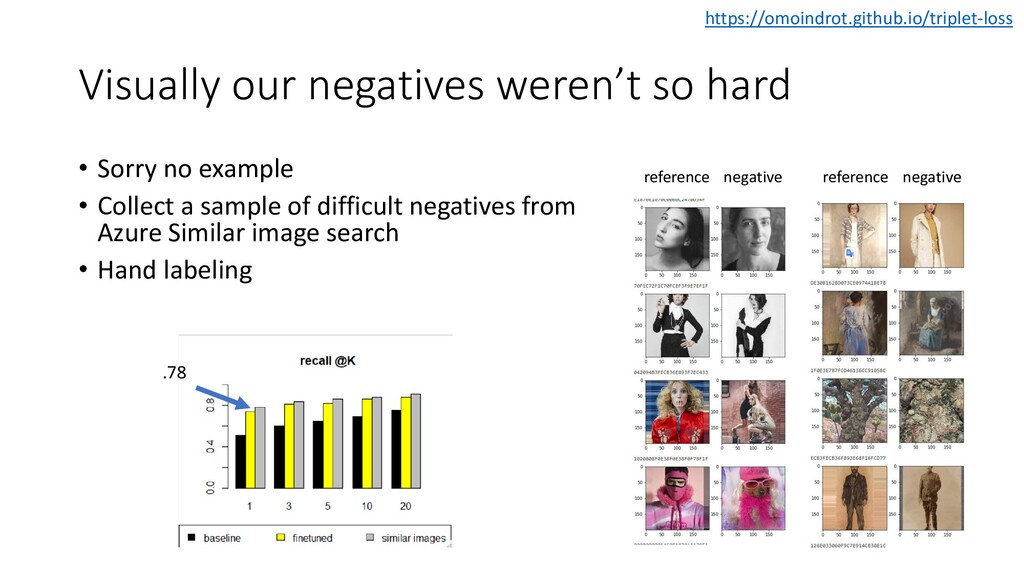
We discuss some fun and interesting challenges during data collection, hand labeling, cleaning, preparation, modelling and operationalization. Then we will dig deeper in what type of CNN architectures for image matching proved to work and how we optimized hyper parameters. We will look into deep representation learning and cover sampling procedures that boosted image matching performance.
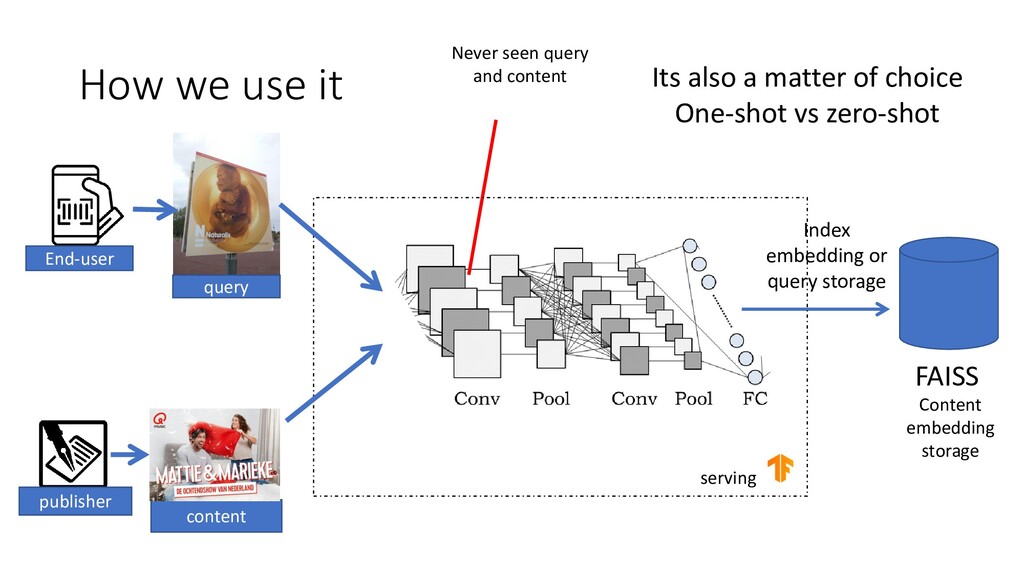
ImageLink (a product of iam.io) replaces QR codes using image matching technology. Instead of scanning a QR code, you scan images. A new and exciting way of activating your (printed) assets.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}