As large language models excel in generating fluent text, a fundamental question arises: how can we make such language understandable and appropriate for readers with diverse proficiency levels? While “text simplification” has long been studied in NLP, most approaches rely on vague or task-specific notions of difficulty. This talk introduces a framework that grounds text complexity control in a defined scale of linguistic difficulty, enabling models to adapt syntax, vocabulary, and meaning to reader proficiency in a principled and measurable way. I will present computational methods for sentence difficulty prediction, contextual lexical simplification, and proficiency-aligned rewriting, which optimize readability and meaning preservation. By moving from ad-hoc heuristics to standardized definitions, we establish text complexity control as a principled framework for studying how linguistic form, meaning, and proficiency interact in language understanding.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
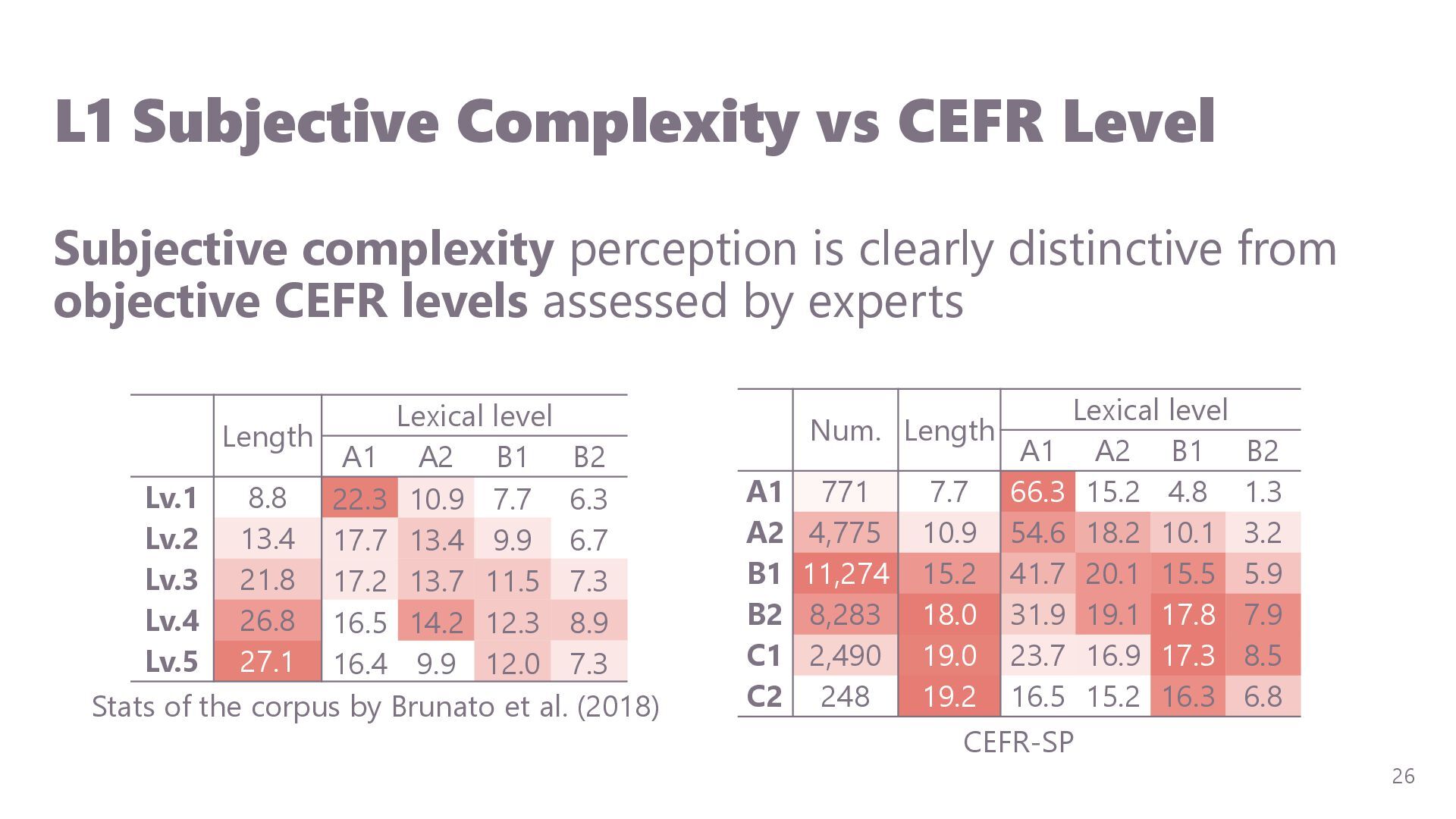{kind=link}
{kind=link}
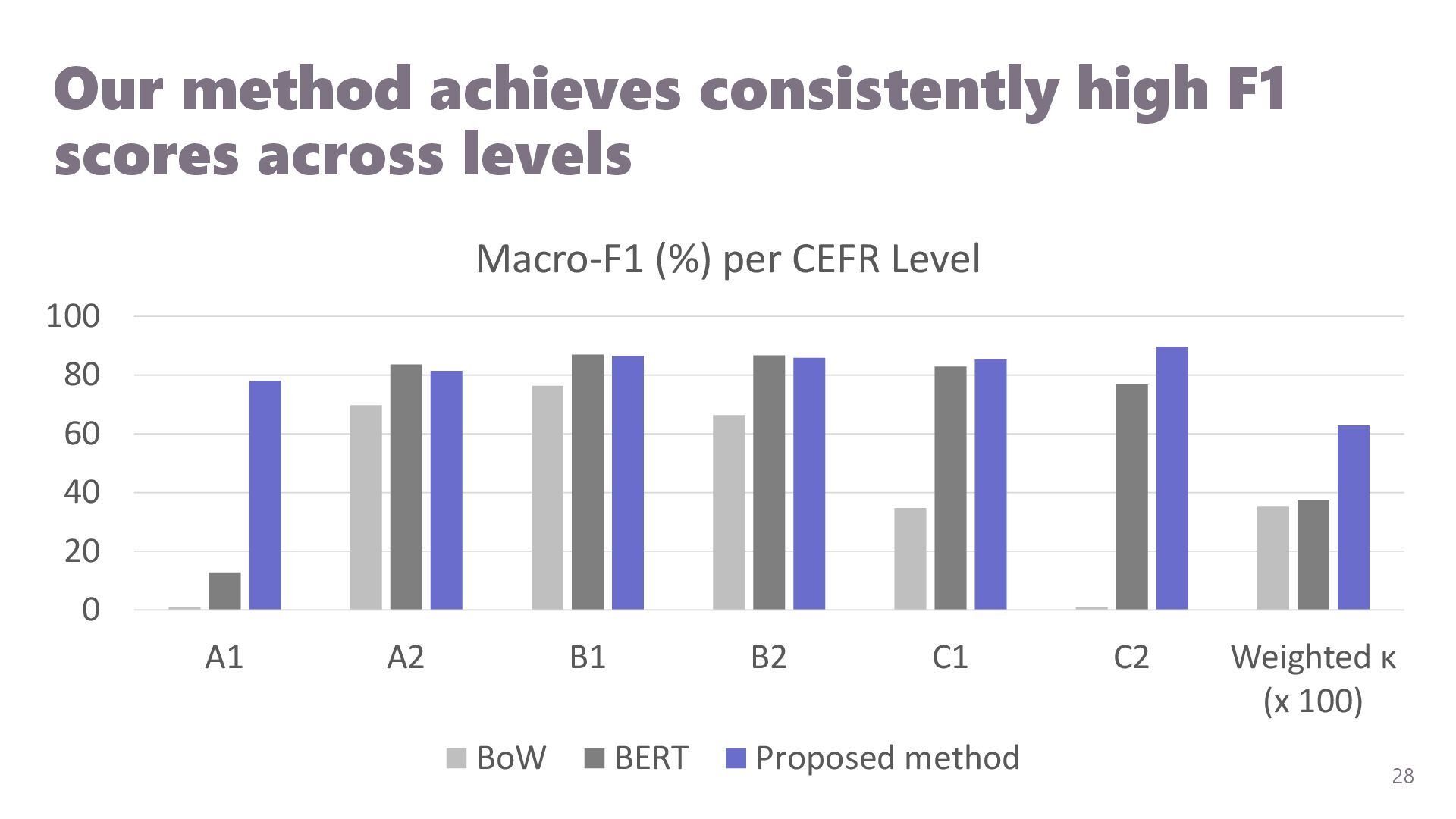{kind=link}
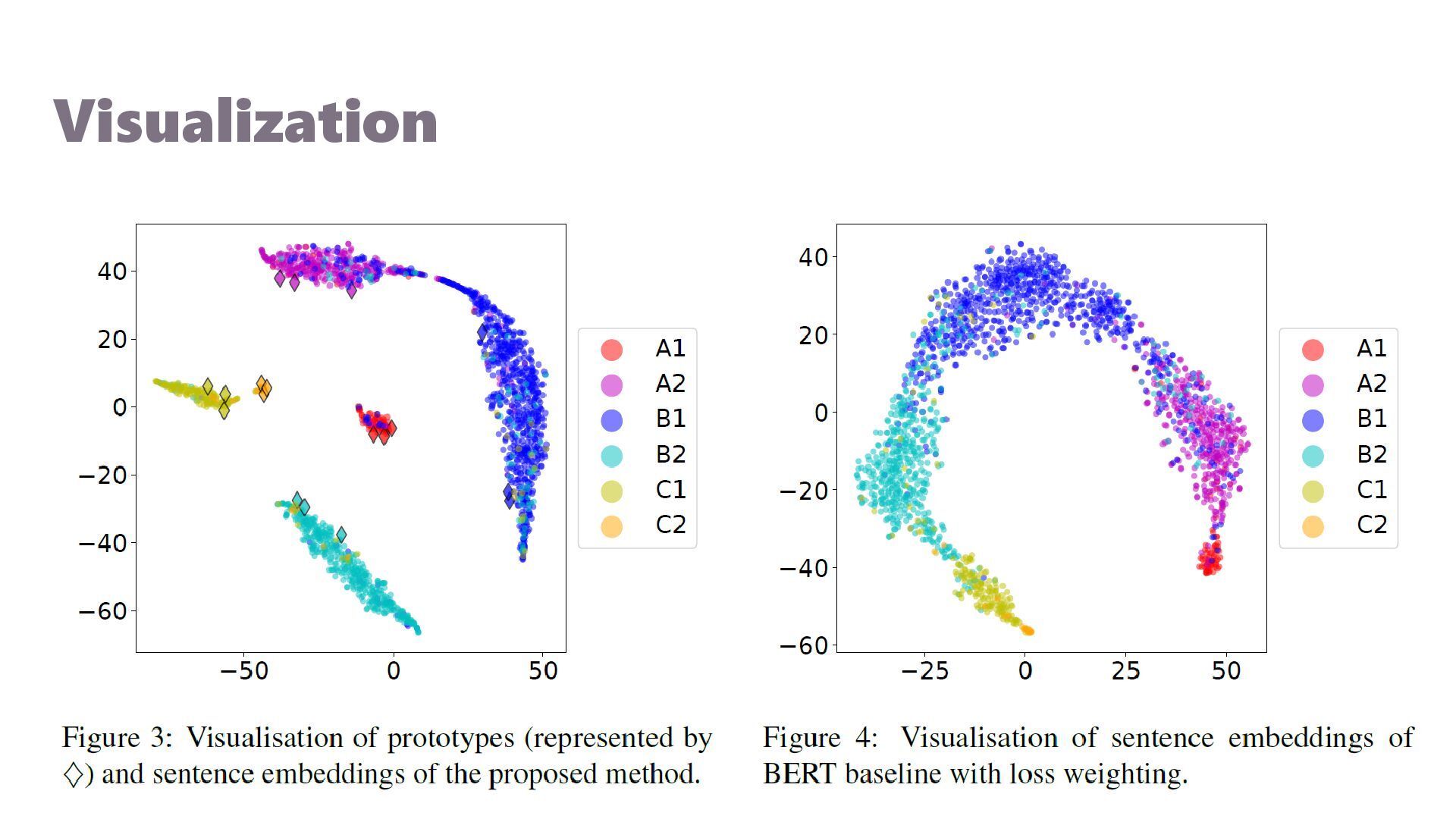{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
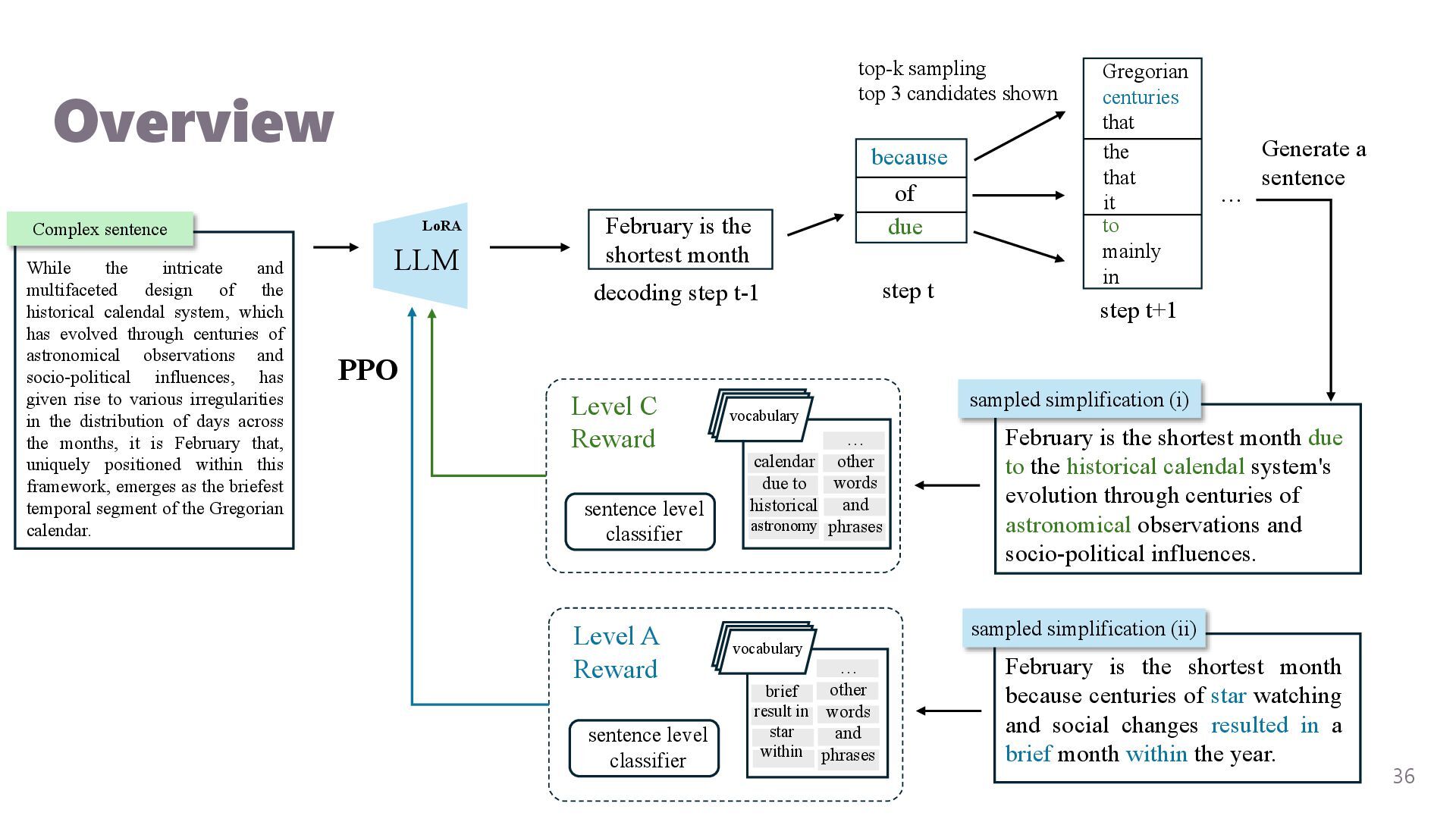{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
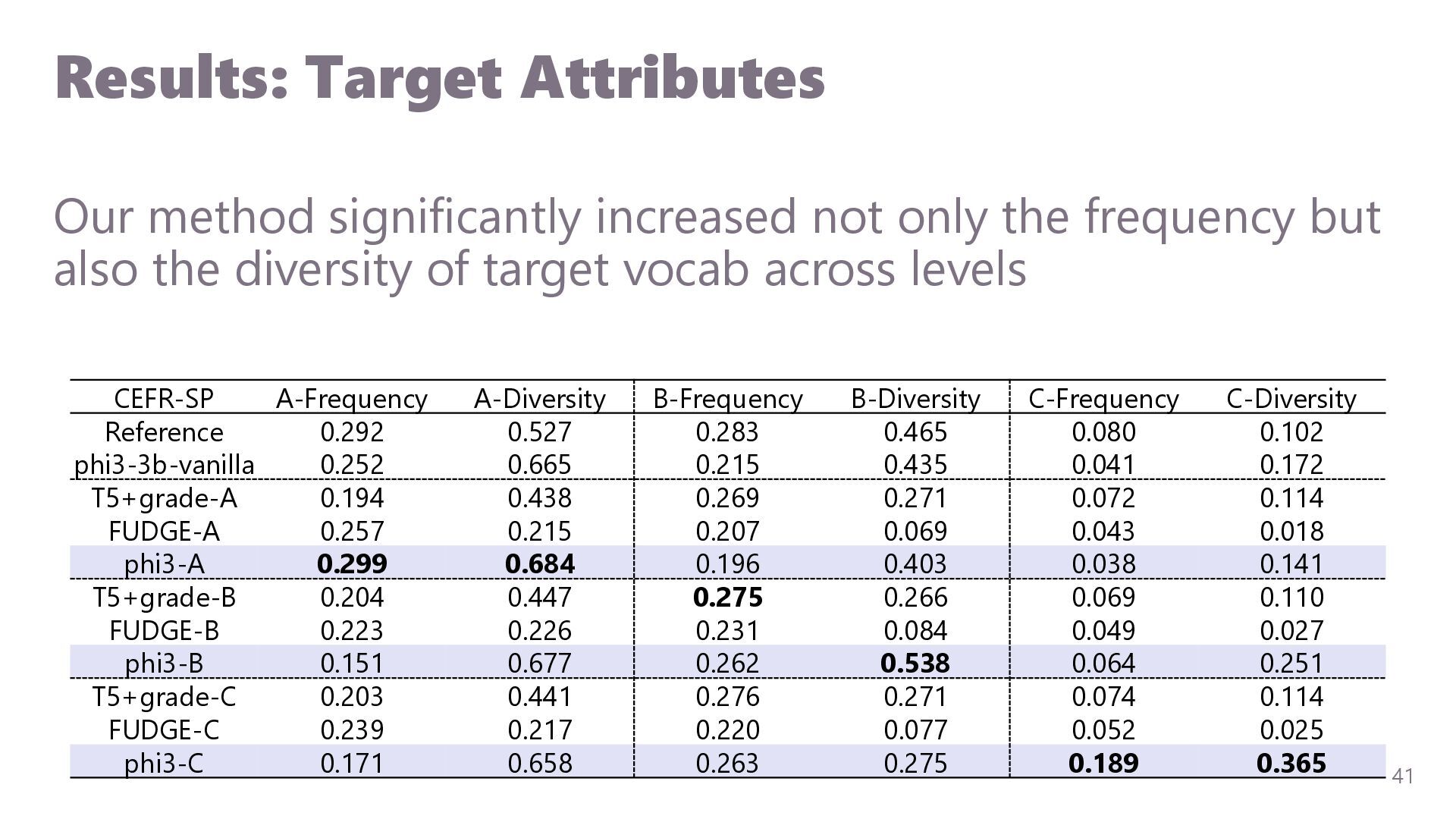{kind=link}
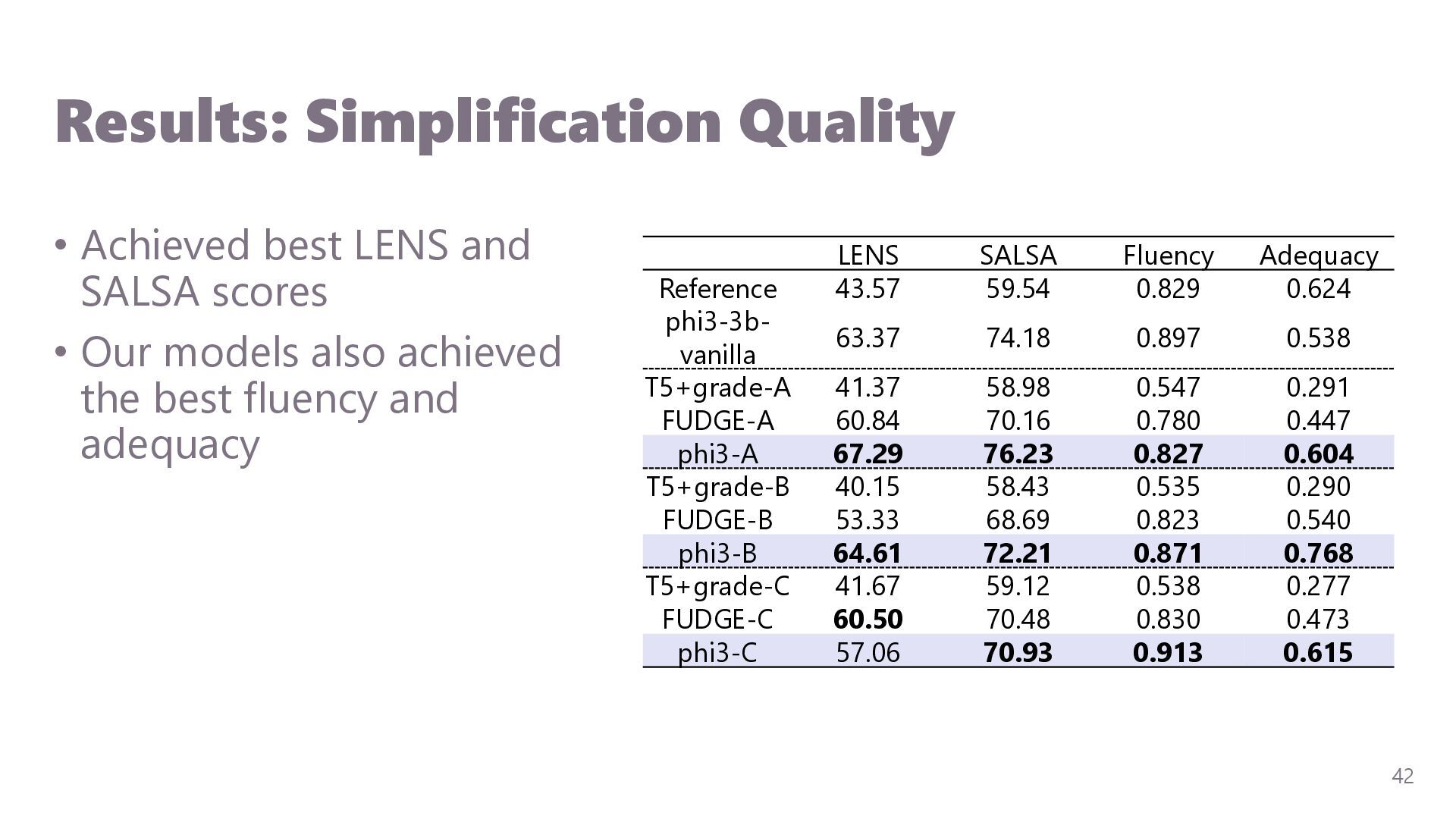{kind=link}
{kind=link}
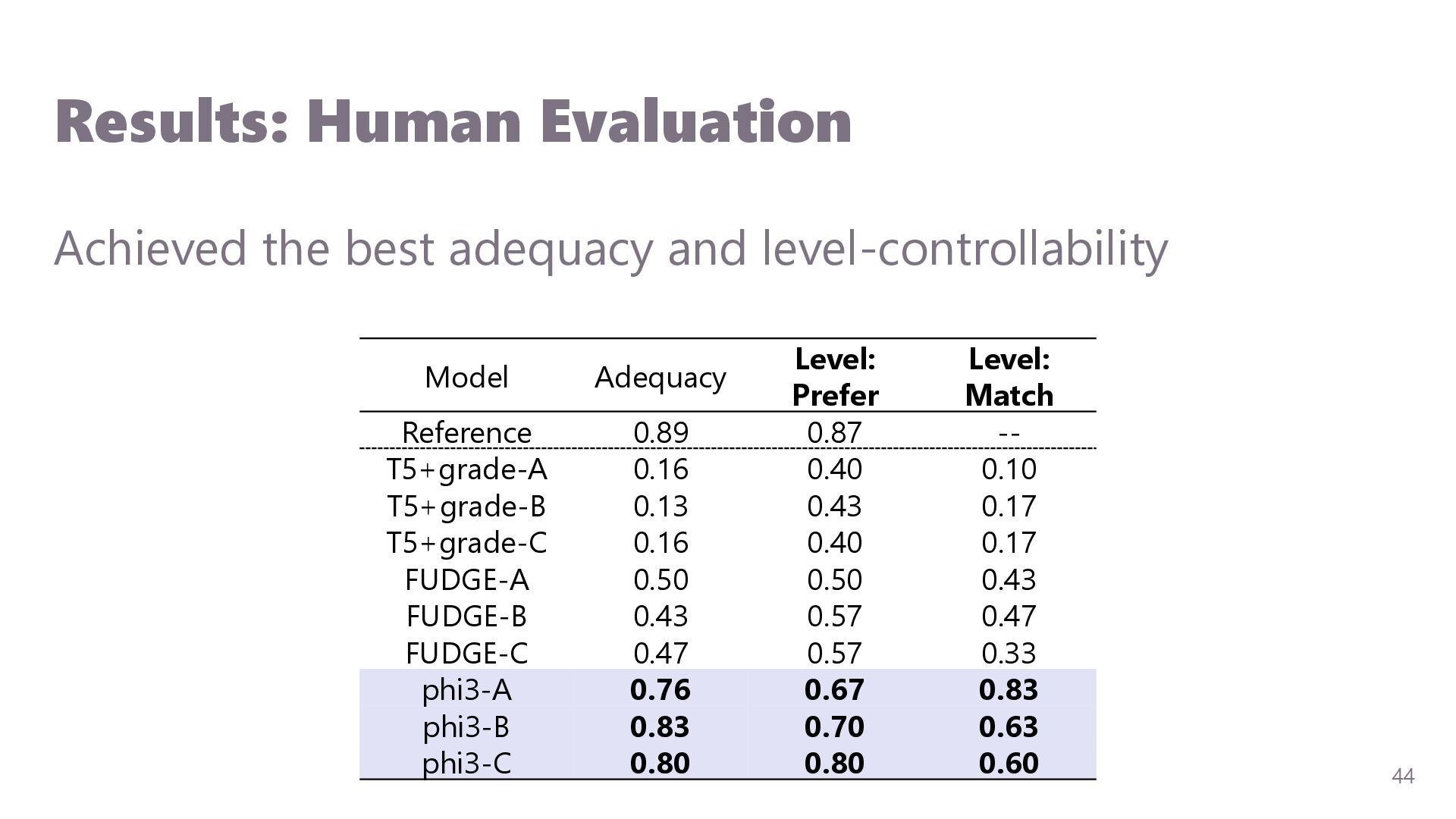{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Questions? Thoughts? https://yukiar.github.io/ [email protected] 50](https://files.speakerdeck.com/presentations/ec5716cffdd14c49a901103e5db310ba/slide_49.jpg){kind=link}