Cost Team name: LM_Lucinda Team members: Marcos Aguilera Keyser Country Office: Liberty Spain 1st/21 LMG teams and 36th/634 teams overall position – top 6%
analytics competitions § Business problem: predict expected fire losses for business insurance policies – Fire losses accounts for significant portion of property losses – High severity and low frequency, volatile and difficult to fit a model § 1st out of 21 Liberty Mutual teams § 36th out of 634 teams § Overall position – top 6% § 14,000 competition entries
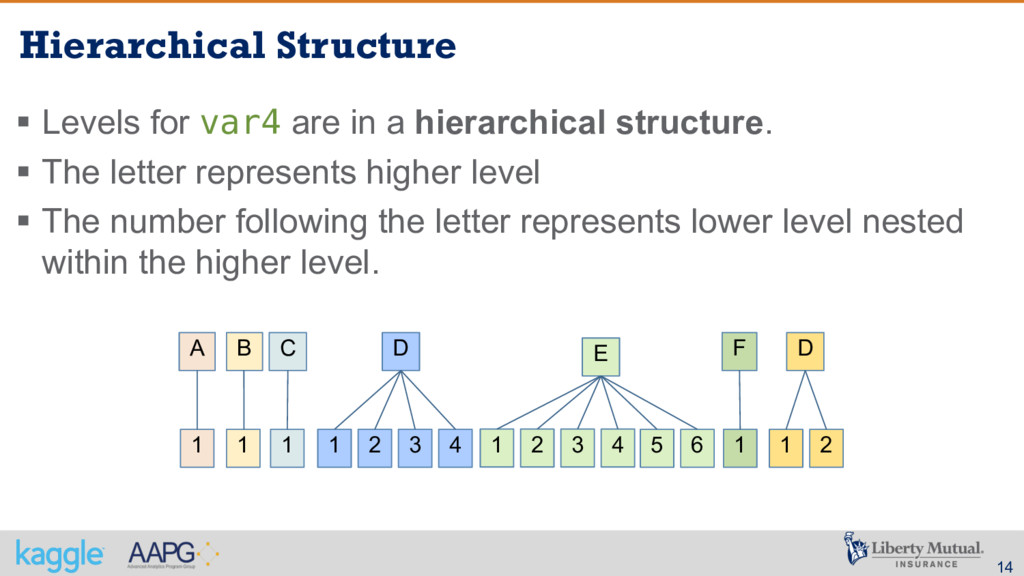
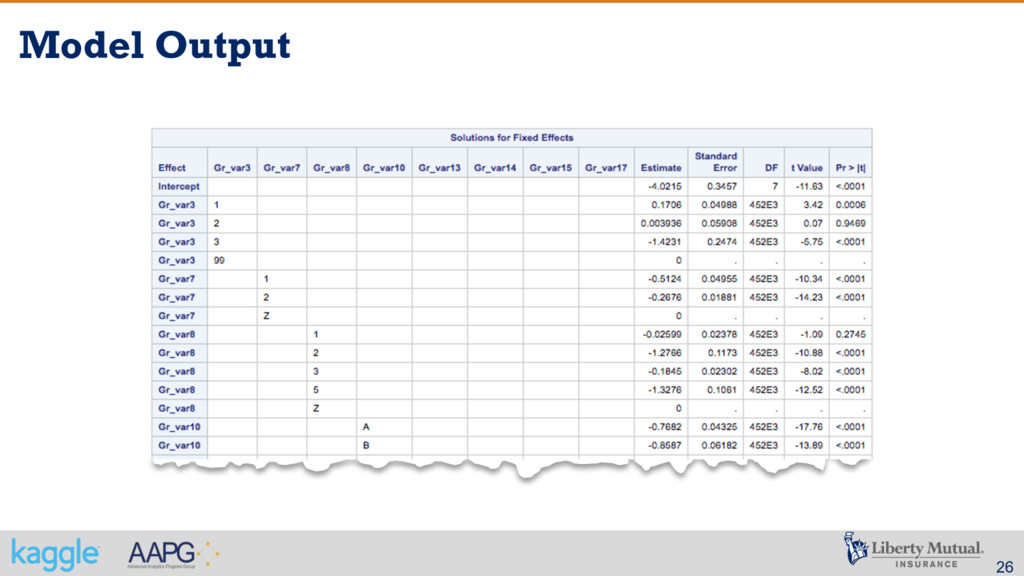
300 – target: a transformed ratio of loss to total insured value – var1 – var17: A set of normalized variables representing policy characteristics – crimeVar1 – crimeVar9: A set of normalized Crime Rate variables – geodemVar1 – geodemVar37: A set of normalized geodemographic variables – weatherVar1 – weatherVar236: A set of normalized weather station variables – Levels for var4 are in a hierarchical structure. The letter represents higher level and the number following the letter represents lower level nested within the higher level.
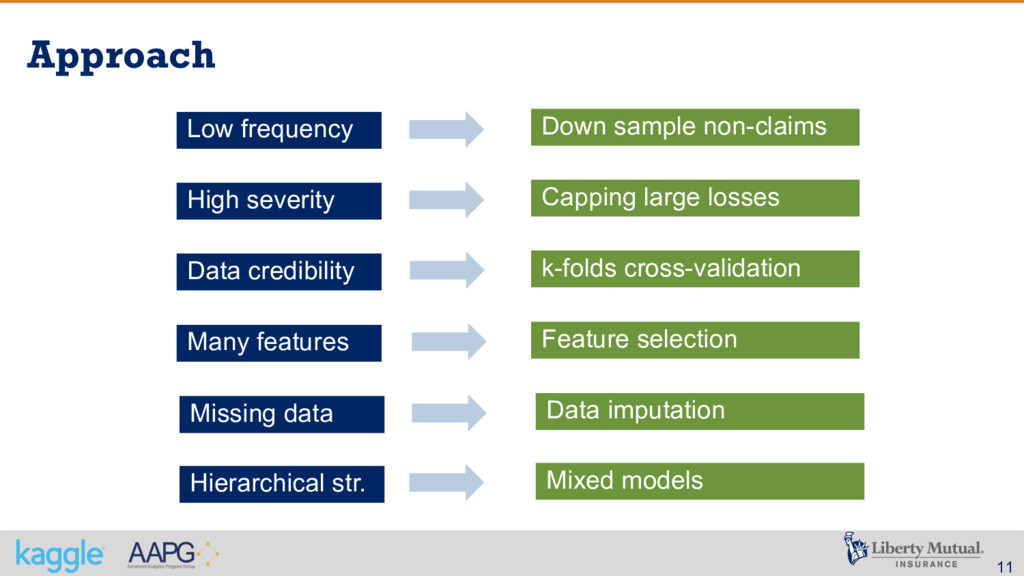
High severity: skewed distribution, cero or positive, varying over a wide range § Data credibility: much less data points compared to personal line § Many features: more than 300 features § Non-informed observations: only 34% are complete cases in the training data § Hierarchical structure: nested observations
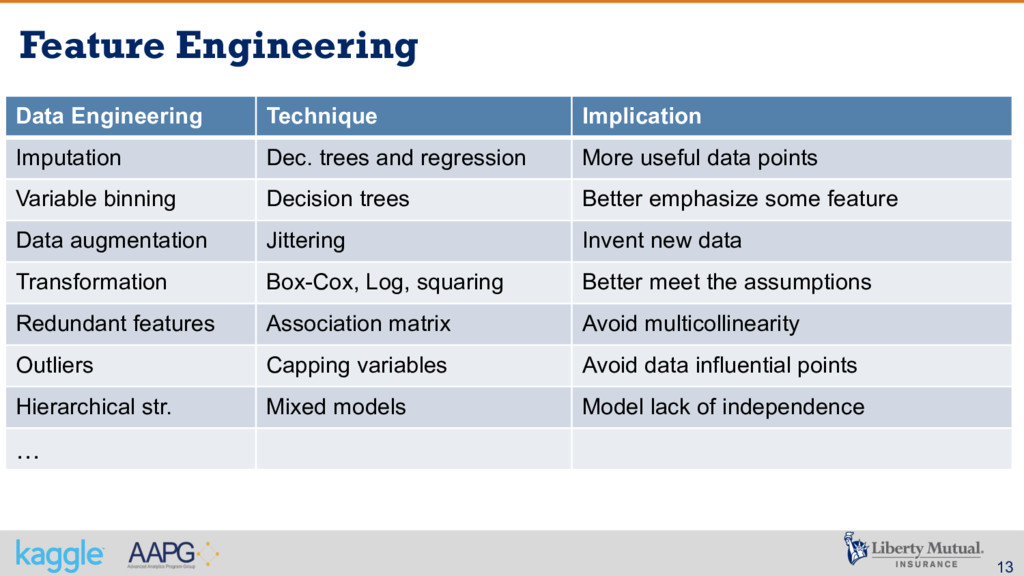
and regression More useful data points Variable binning Decision trees Better emphasize some feature Data augmentation Jittering Invent new data Transformation Box-Cox, Log, squaring Better meet the assumptions Redundant features Association matrix Avoid multicollinearity Outliers Capping variables Avoid data influential points Hierarchical str. Mixed models Model lack of independence …
hierarchical structure. § The letter represents higher level § The number following the letter represents lower level nested within the higher level. 1 1 1 1 2 3 4 A B C D 1 2 3 4 E 5 6 1 F 1 2 D
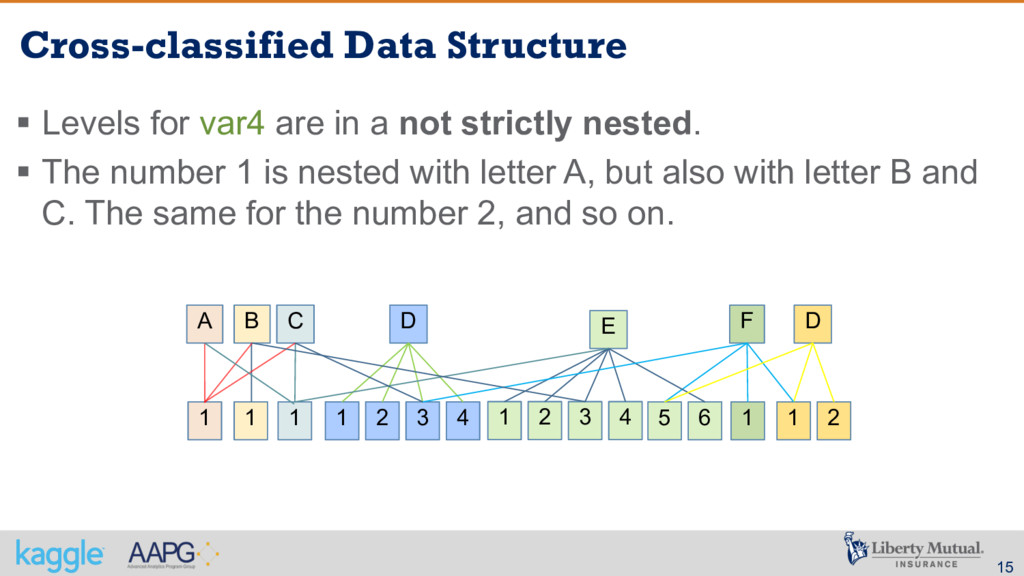
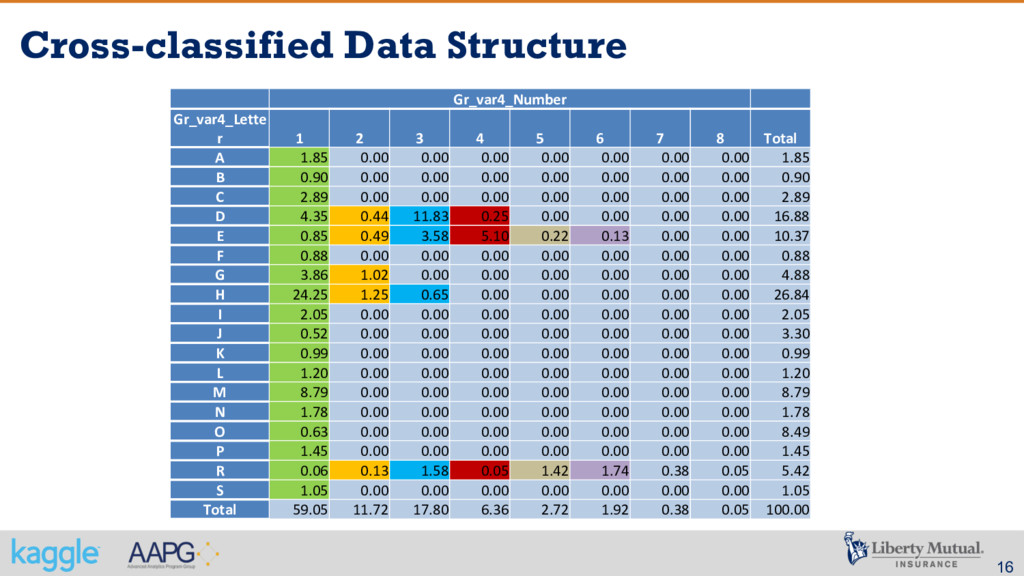
a not strictly nested. § The number 1 is nested with letter A, but also with letter B and C. The same for the number 2, and so on. 1 1 1 1 2 3 4 A B C D 1 2 3 4 E 5 6 1 F 1 2 D
+ private leaderboards § Use the validation set for parameter tuning § Use the test set to estimate the model’s generalization error § Disadvantage: performance sensitive to how we partition the dataset
fitting § Divide the data set into k sub samples § Use k-1 sub samples as the training data and one sub samples as the test data § Repeat the second step by choosing different sub sample as the testing set
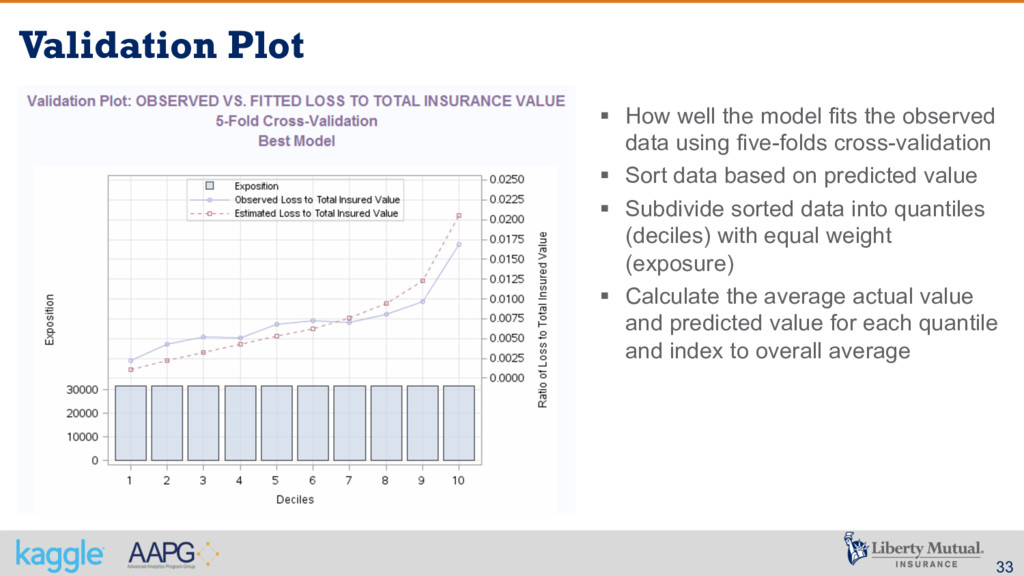
observed data using five-folds cross-validation § Sort data based on predicted value § Subdivide sorted data into quantiles (deciles) with equal weight (exposure) § Calculate the average actual value and predicted value for each quantile and index to overall average
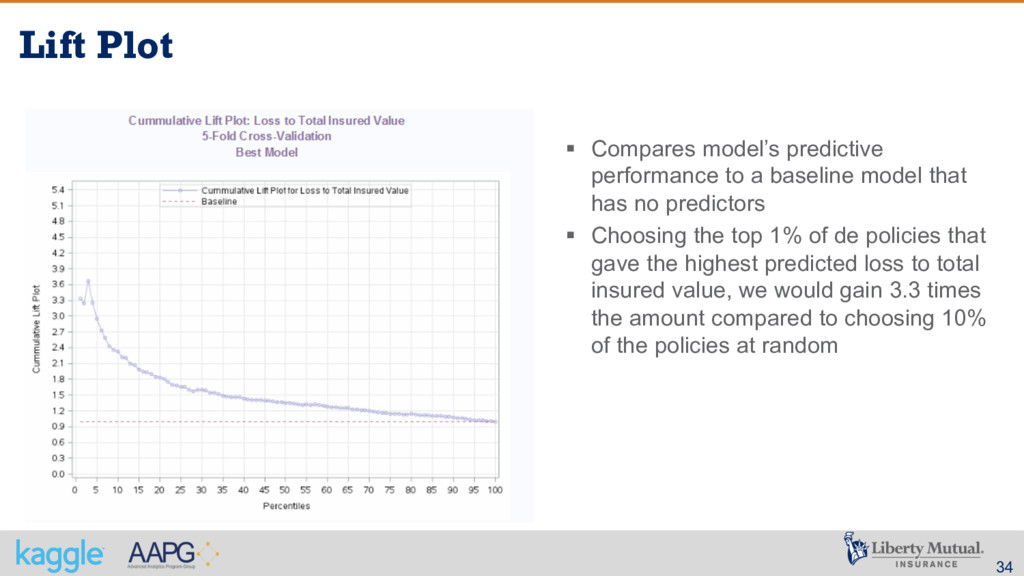
baseline model that has no predictors § Choosing the top 1% of de policies that gave the highest predicted loss to total insured value, we would gain 3.3 times the amount compared to choosing 10% of the policies at random
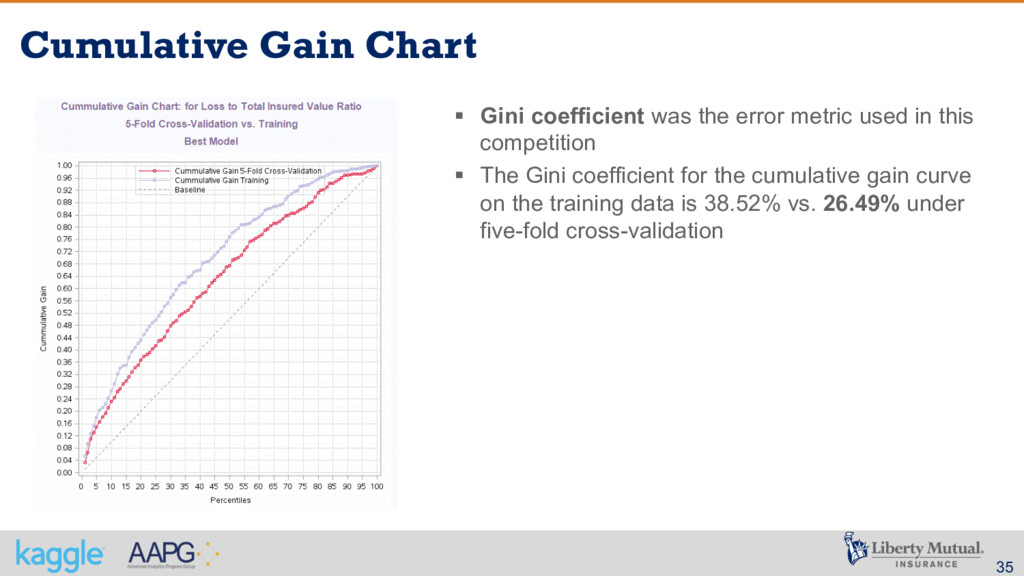
metric used in this competition § The Gini coefficient for the cumulative gain curve on the training data is 38.52% vs. 26.49% under five-fold cross-validation
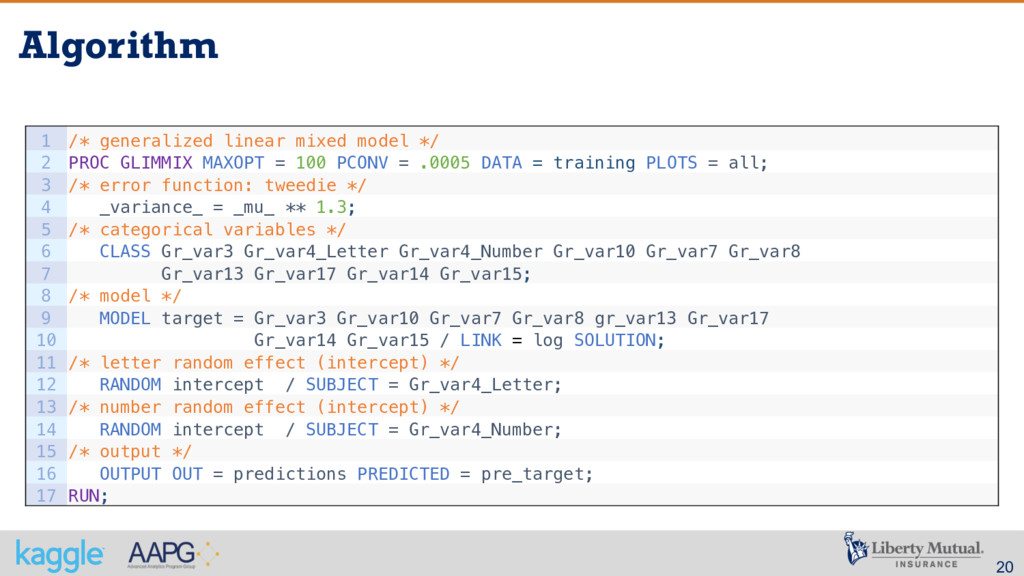
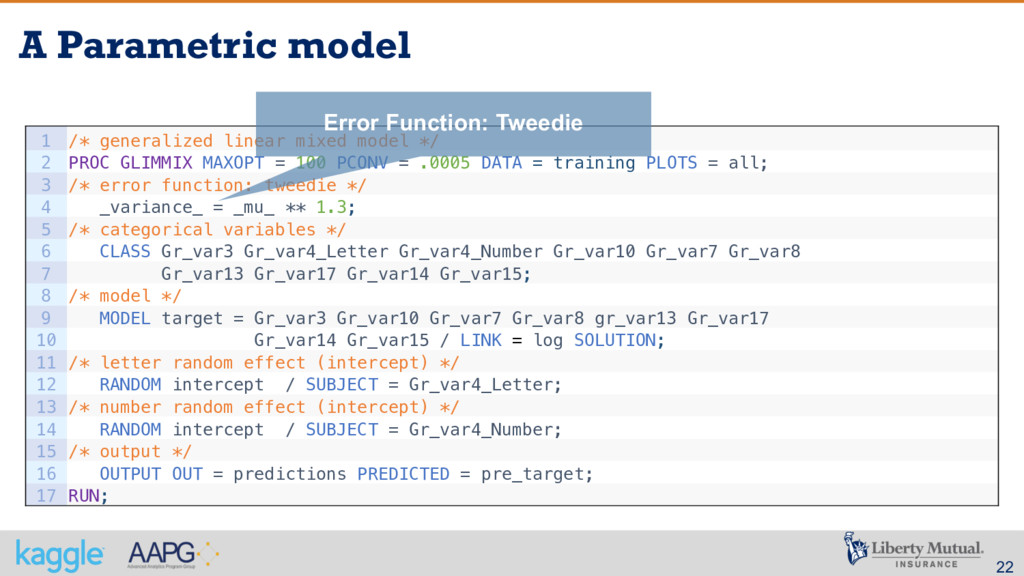
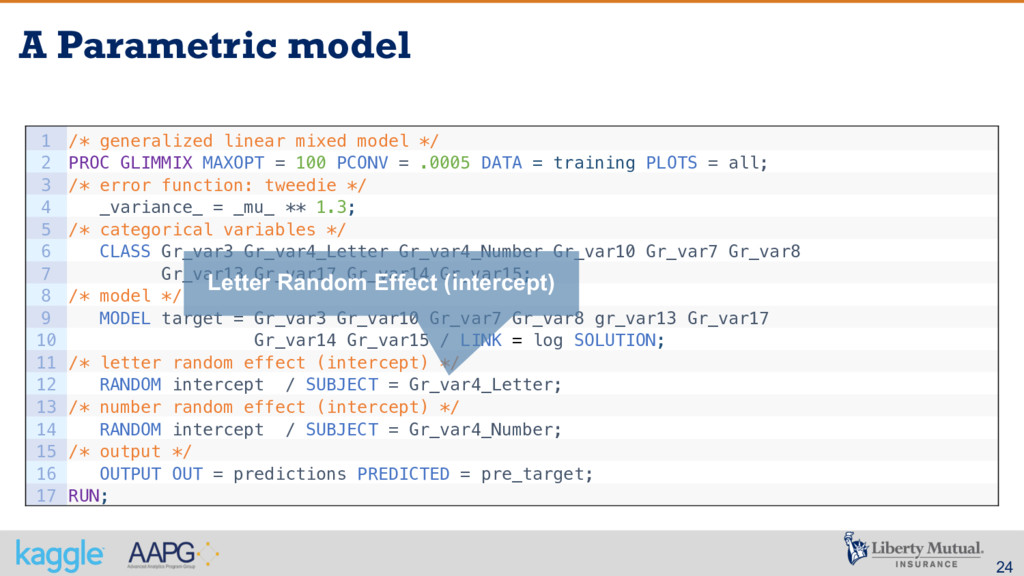
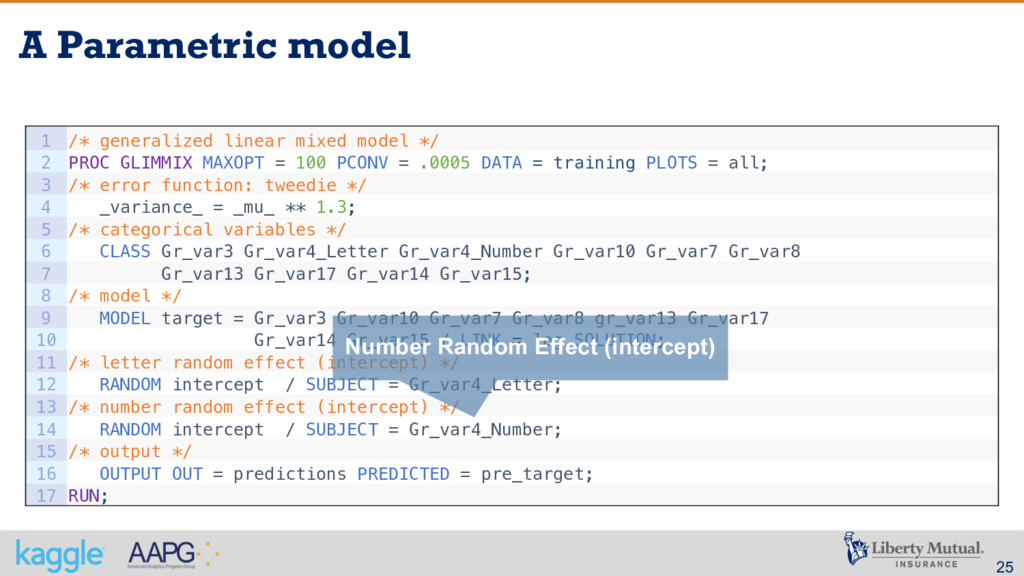
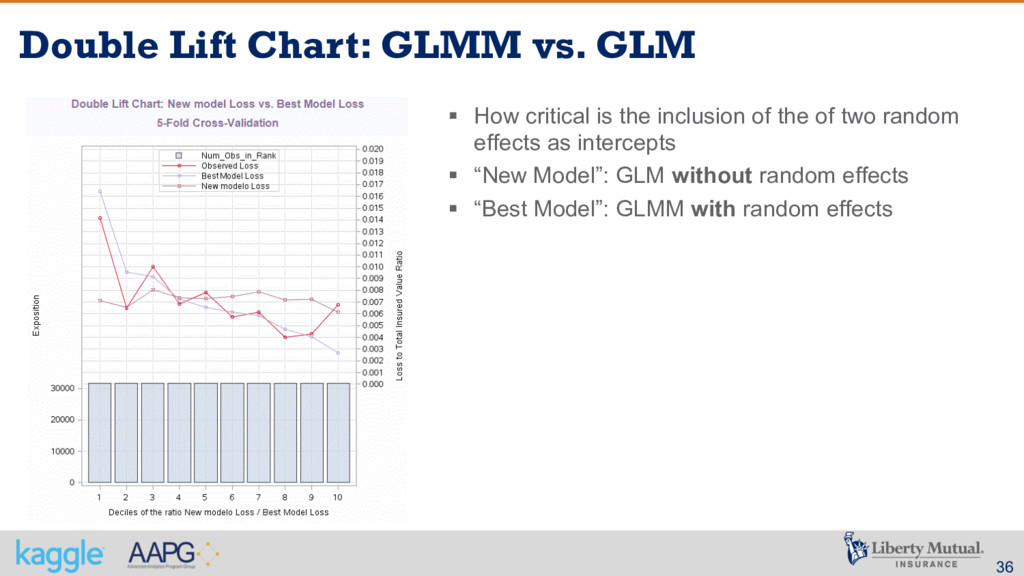
from the best possible algorithm – the winner of the public contest § The use of GLMM in order to deal with spare data and lack of credibility definitely was critical § A careful reading of the problem description was very important
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}