GLM in Auto and Household Ratemaking using SAS - Theory
First chapter (theory) of my training for the Spanish Actuarial Institute 5 days course "Generalized Linear Models in Auto and Household Ratemaking using SAS" that I've been teaching during the years 2014 and 2015.
• Licenciado en Economía y Ciencias Actuariales por la Universidad Carlos III • Actuario Senior de Pricing en Liberty seguros • Anteriormente pasé varios años como consultor analítico en SAS Institue • Tengo mucha experiencia construyendo modelos analíticos para la industria aseguradora en multitud de proyectos nacionales e internacionales • Ganador de la competición de Kaggle para empleados de Liberty Mutual Group "Liberty Mutual Group - Fire Peril Loss Cost“ [email protected][email protected] es.linkedin.com/in/markeyser
los modelos GLM: – El modelos estándar de resgresión – La función de “link” – La “familia exponencial” – El término “offset” • Relación entre media y varianza • Práctica 1: Introducción a los modelos GLM • Modelos para la Frecuencia: – El problema de la sobre dispersión – Práctica 2: modelización de la sobre dispersión – El problema del exceso de ceros – Práctica 3: modelización del exceso de ceros • Modelos para el Coste Medio: – Estructuras de error Gamma, Gaussiana Inversa y Log-normal – Práctica 4: ajuste del coste medio
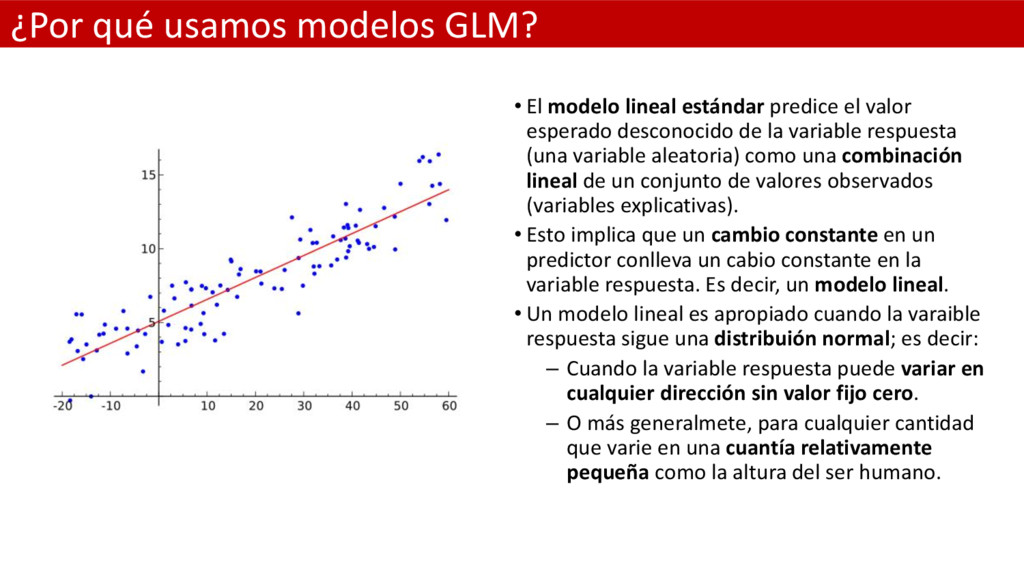
predice el valor esperado desconocido de la variable respuesta (una variable aleatoria) como una combinación lineal de un conjunto de valores observados (variables explicativas). • Esto implica que un cambio constante en un predictor conlleva un cabio constante en la variable respuesta. Es decir, un modelo lineal. • Un modelo lineal es apropiado cuando la varaible respuesta sigue una distribuión normal; es decir: – Cuando la variable respuesta puede variar en cualquier dirección sin valor fijo cero. – O más generalmete, para cualquier cantidad que varie en una cuantía relativamente pequeña como la altura del ser humano.
anterirores no son adecuados para algunos tipos de variables resputa. Por ejemplo: – Cuando la variable respuesta se espera que siempre sea positiva. – Cuando la variable respuesta puede variar en un amplio rango (varios órdenes de magnitud) – Cuando cambios constantes en la variable explicaiva conlleva cambio geométricos en la variable explicativa (en lugar de constates) • Los modelos lineales generalizados son adecuados para modelar éste tipo de variable respuesta.
los siniestros pequeños tienen menos varianza que los grandes. Luego el supuesto clásico no es práctico Y es que, • la variable respuesta es positiva (Frecuencia, Coste Medio) • recorren varios órdenes de magnitud - incurridos entre 50 Euros y 500.000 Euros • Incrementos unitarios en el factor de riesgo (antigüedad del carné de conducir) conllevan incrementos geométricos en la variable respuesta (el coste medio) • ¿Quién ha visto una distribución normal en seguros?
de resgresión lineal estándar (clásico): " = & + ( " + ⋯ + + " + ϵ" , ϵ" ~ 0, 2 De otra forma, tenemos el promedio de la variable " que es el objetivo en modelización predictiva. Además, épsilon ha desaparedido del lado derecho de la ecuación. A ésta expresión la llamamos predictor líneal. Lineal en las betas; es decir, no encontremos 2 ó ( . 4 ya que no es una relación lineal: " = " = & + ( " + ⋯ + + " Otro supuesto clave del modelo lineal estándar es que la varaible respuesta es una variable aleatorioa que sigue una distribución Normal con media mu y variaza constange sigma cuadrado: " ~ , 2 Donde la media mu es el predictor lineal: = " = & + ( " + ⋯ + + "
la variable respuesta, aquello que queremos predecir, la frecuencia, el coste medio o el burning cost (prima pura ó prima de riesgo) • también es conocida, son los factores de riesgo, (la antigüedad del vehículo, 2el número de puertas, etc. ¿Qué desconocemos? • No conocemos las , queremos estimar su valor para saber si nos ayuda a predecir • No conocemos , que representa el término de error de nuestro modelo Predictor lineal: • El objetivo es predecir el valor medio de condicionado a los valores que tomen (, 2 , … , : • Es lineal en parámetros (las betas) • es una variable aleatoria que sigue una distribución normal con varianza constante • es el valor esperado, la media y representa al predictor lineal
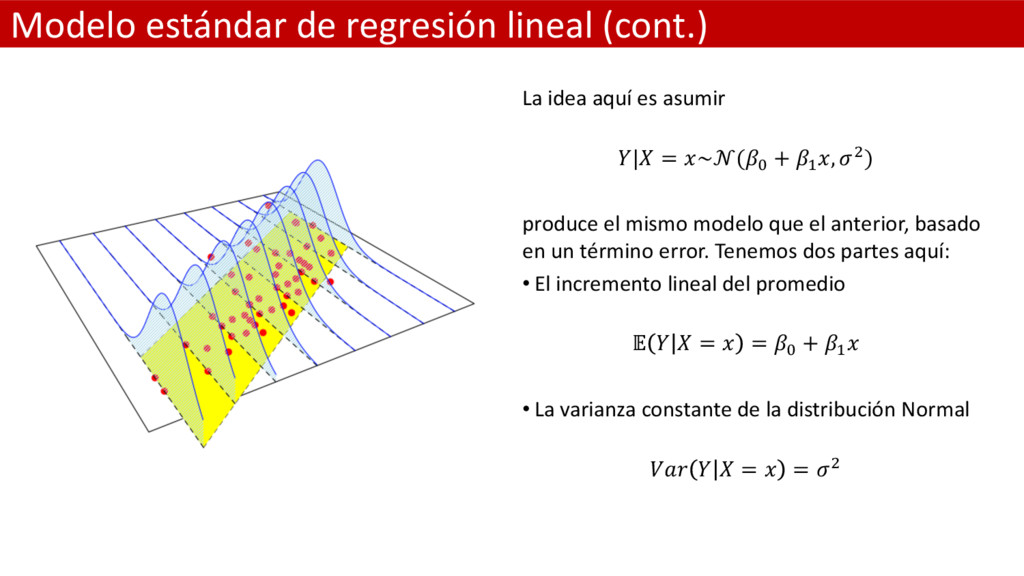
asumir | = ~(& + ( , 2) produce el mismo modelo que el anterior, basado en un término error. Tenemos dos partes aquí: • El incremento lineal del promedio = = & + ( • La varianza constante de la distribución Normal = = 2
= & + ( ( + ⋯ + + + = • La “función de link” es : los modelos GLM relacionan el valor esperado de la variable dependiente ( ) con el predictor lineal () a través de la “función de link” (. ) • Ejemplo: función de link logarítmica: = & + ( ( + ⋯ + + , = que equivale a = JKLJMNML⋯LJO, = P • En nuestro ejemplo anterior para el modelo lineal estándar no podemos ver la función de link, sin embargo, exisete ya que sencillamente es la función identidad, es uno. El modelo lineal estándar es un modelo GLM.
nuestra función de link es logarítmica: Log (|) = ~(& + ( , 2) • El incremento del promedio ya no es lineal sino exponencial = = JKLJMT = JK U JMT • La varianza constante de la distribución Normal = = 2 • Un modelo multiplicativo debido a link = log • Un modelo que sigue siendo homoscedástico pero no lineal en su relación con
lineales generalizados " sigue una distribución de la familia exponencial. La familia exponencial de distribuciones depende de dos parámetros y se define como: " " ; , = exp " " − " " + " , donde • " , " y " , son funciones especificadas de ante mano • " es un parámetro relacionado con la media (thita) • es un parámetro de escala relacionado con la varianza (fi)
de vista práctico, es útil conocer que la familia exponencial tiene dos propiedades: 1. La distribución queda completamente especificada en términos de media y varianza 2. La varianza de " es función de su media Esta segunda propiedad queda más clara si expresamos la varianza así: (") = `a(bc) dc Donde, • (" ) se le llama función de varianza, es una función especificada previamente • el parámetro de dispersión (fi) que simplemente escala la varianza • y el " (omega) es una constante que asigna un peso, o credibilidad, a la observación i La familia exponencial engloba múltiples distribuciones: Normal, Gamma, Binomial, Poisson, Negative Binomial, Gaussiana Inversa, entre otras
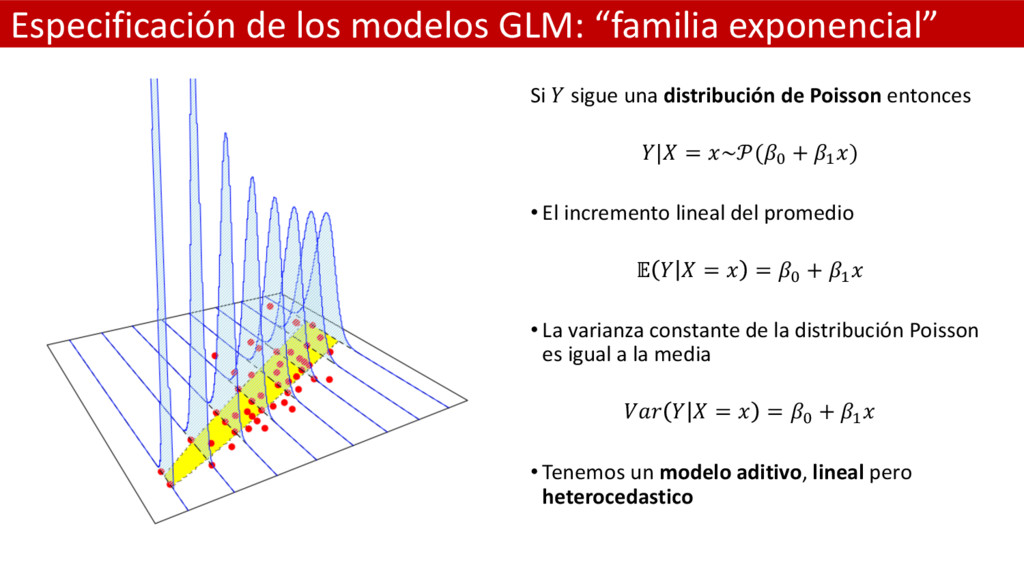
distribución de Poisson entonces | = ~(& + ( ) • El incremento lineal del promedio = = & + ( • La varianza constante de la distribución Poisson es igual a la media = = & + ( • Tenemos un modelo aditivo, lineal pero heterocedastico
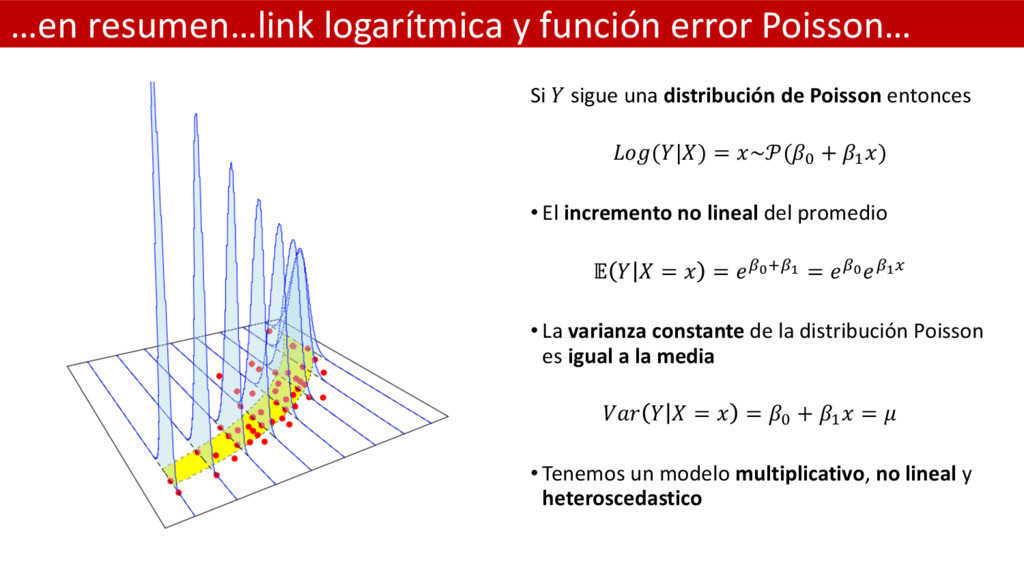
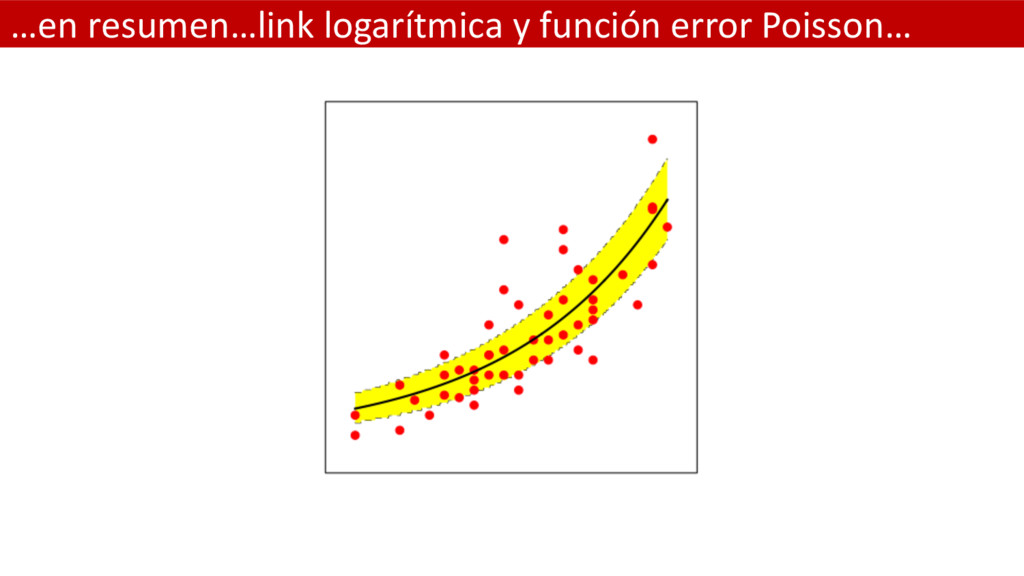
distribución de Poisson entonces (|) = ~(& + ( ) • El incremento no lineal del promedio = = JKLJM = JKJMT • La varianza constante de la distribución Poisson es igual a la media = = & + ( = • Tenemos un modelo multiplicativo, no lineal y heteroscedastico
+ ( ( + ⋯ + + + + offset • El término “offset” es interesante, es como una pero sin el parámetro delante (ó parametro = 1) • Permite introducir efectos que conocemos • En los modelos lineales estándar también existen dichos efectos, pero no es necesario explicitarlos, sencillamente podemos pasarlos al otro lado de la ecuación y restarlos de . • Ahora que tenemos una función de link no podemos ya pasar al otro lado de la ecuación éste otro efecto que conocemos. Por lo tanto, queda aislado en la parte derecha de la ecuación. • Ejemplo: en los modelos de frecuencia la exposición de la póliza es el típico término offset
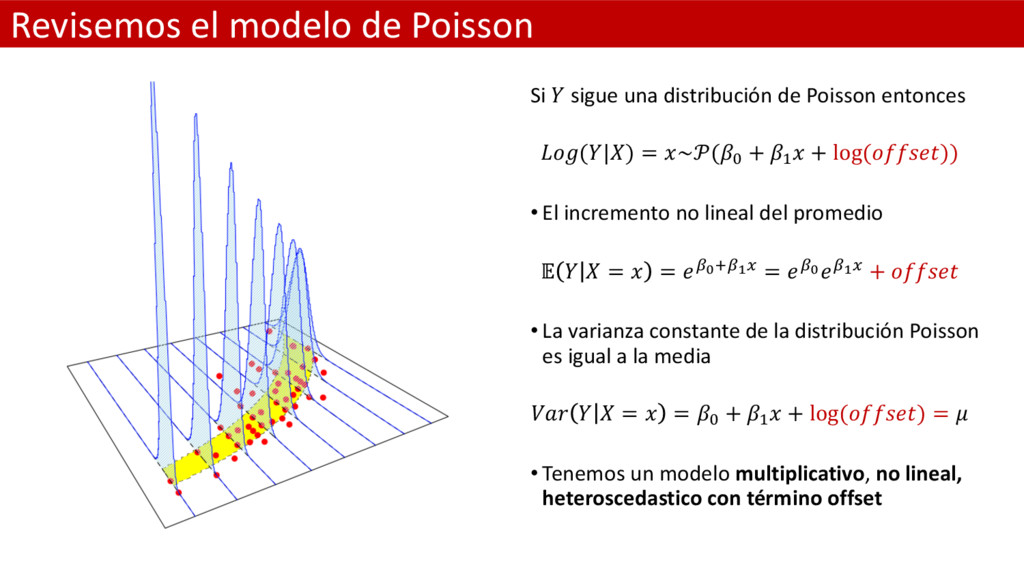
Poisson entonces (|) = ~(& + ( + log ()) • El incremento no lineal del promedio = = JKLJMT = JKJMT + • La varianza constante de la distribución Poisson es igual a la media = = & + ( + log () = • Tenemos un modelo multiplicativo, no lineal, heteroscedastico con término offset
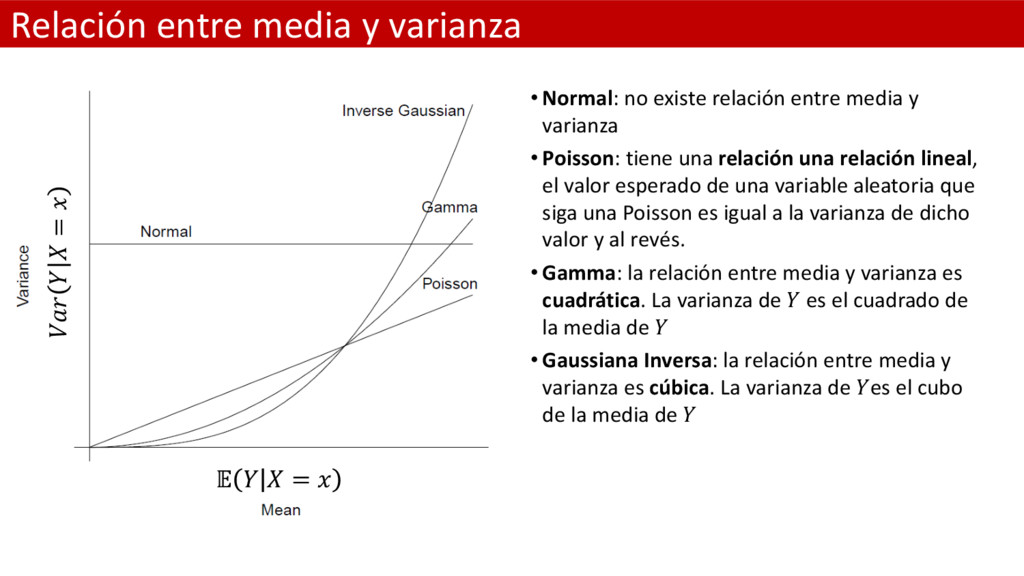
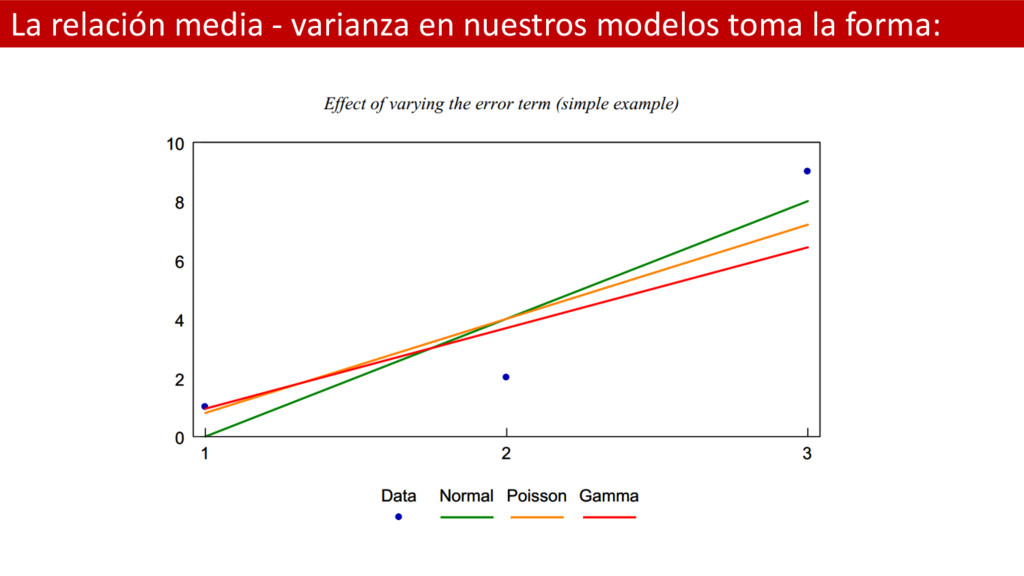
estándar la varianza es constante: = = 2 • Independientemente del valor que tome el valor esperado de = • No hay relación entre ambos componentes • Sin embargo sabemos que los siniestros pequeños tienen menos varianza que los grandes. Luego el supuesto clásico no es práctico • Por suerte tenemos otras alternativas como elegir una función de error de Poisson, Gamma, Gaussiana Inversa, Log normal, etc.
entre media y varianza • Poisson: tiene una relación una relación lineal, el valor esperado de una variable aleatoria que siga una Poisson es igual a la varianza de dicho valor y al revés. • Gamma: la relación entre media y varianza es cuadrática. La varianza de es el cuadrado de la media de • Gaussiana Inversa: la relación entre media y varianza es cúbica. La varianza de es el cubo de la media de = =
el más habitualmente utilizado como punto de partida en los modelos de Frecuencia; es el siguiente: (|) = ~(& + ( + log (ó)) El incremento no lineal del promedio = = (JKLJMTLƒ„… (†‡ˆ) ) = JKJMTƒ„… (‰TŠ) = La varianza crece a una tasa constante ya que en la distribución Poisson media y varianza son iguales = = & + ( = Tenemos un modelo multiplicativo, no lineal y heteroscedastico
es mayor que la varianza teórica para una distribución en particular. • Es decir, la variabilidad es mayor que la predicha por la función de error del modelo GLM • Cuando tratamos de ajustar un modelo a datos de conteo (0,1,2,…,n) es muy frecuente encontrar sobre dispersión en los datos. Consecuencias: • Cuando la verdadera distribución no es Poisson: – Los estimadores de máxima verosimilitud siguen siendo consistentes – Pero sus errores estándar son incorrectos • De hecho la sobre dispersión conlleva: – A infra estimar los errores estándar – A sobre estimar los estadísticos Chi-cuadrados • En consecuencia sobre estimamos la significación de los parámetros estimados en la regresión
debido a un modelo incorrectamente especificado 2. Valores atípicos en los datos 3. Correlación positiva entre las observaciones como consecuencia de la existencia de clusters
de Poisson asume que la variable respuesta sigue una distribución de Poisson condicionada a los valores de las variables explicativas • Si alguna variable explicativa importante está ausente del modelo entonces la heterogeneidad entre las observaciones no explicada por el modelo puede causar mayor variabilidad en la variable respuesta que la predicha por el modelo de Poisson • Al no existir un término de error en el modelo de Poisson, no hay forma de acomodar la variabilidad extra causada por la omisión de una variable explicativa importante • En consecuencia, asumir una distribución de Poisson para una variable de conteo es muy simplista ya que la mayoría de los modelos no están correctamente especificados
el problema de sobre dispersión es hacer uso de un factor de dispersión (∅) cuando definimos la relación entre media y varianza – En la varianza original bajo Poisson: (")= – La nueva varianza con dispersión: (")= ∅ ∗ • Donde el factor de sobre dispersión multiplicativo (∅) es un estadístico Chi-cuadrado dividido por sus grados de libertad ∅ = 2 • La matriz de covarianzas está ahora pre multiplicada por ∅, • y la desviación escalada y la función de máxima verosimilitud están ahora dividas por ∅ • Como la función de mv. es utilizada para calcular los intervalos de confianza entonces • los errores estándar de cada coeficiente son ajustados de ésta forma ()•Ž• = ∗ ()‘’•Ž• • Éste método produce una inferencia adecuada siempre que la sobre dispersión sea moderada
factor de dispersión multiplicativo no genera una nueva distribución de probabilidad, es sencillamente un término corrector a la hora de testar las estimación de los parámetros bajo el modelo de Poisson • Los modelos se ajustan de la forma habitual en Poisson • Los parámetros estimados no se ven afectados por el factor de dispersión multiplicativo • Sin embargo, sí se ven afectados los errores estándares de los coeficientes de regresión de forma que sufren una corrección • Si existe sobre dispersión, los errores estándar se incrementan para albergar el exceso de variabilidad
matriz de covarianzas en el PROC GENMOD: 1. Puedes calcular el factor multiplicativo de sobre dispersión usando las desviaciones (SCALE = deviance) 2. Puedes calcular el factor multiplicativo de sobre dispersión usando el estadístico de la Chi- cuadrado de Pearson (SCALE = Pearson) La mayoría de las veces estarán muy cerca uno del otro • Recordar que cuando exista evidencia de sobre dispersión hay que investigar primero la existencia de otras razones, especialmente la existencia de valores ausentes o la incorrecta especificación del modelo (si faltan importantes interacciones por ejemplo, asumiendo linealidad de las variables continuas cuando la falta de ella es evidente, etc.). Corrigiendo éstos problemas quizás no haga falta usar el factor de dispersión multiplicativo.
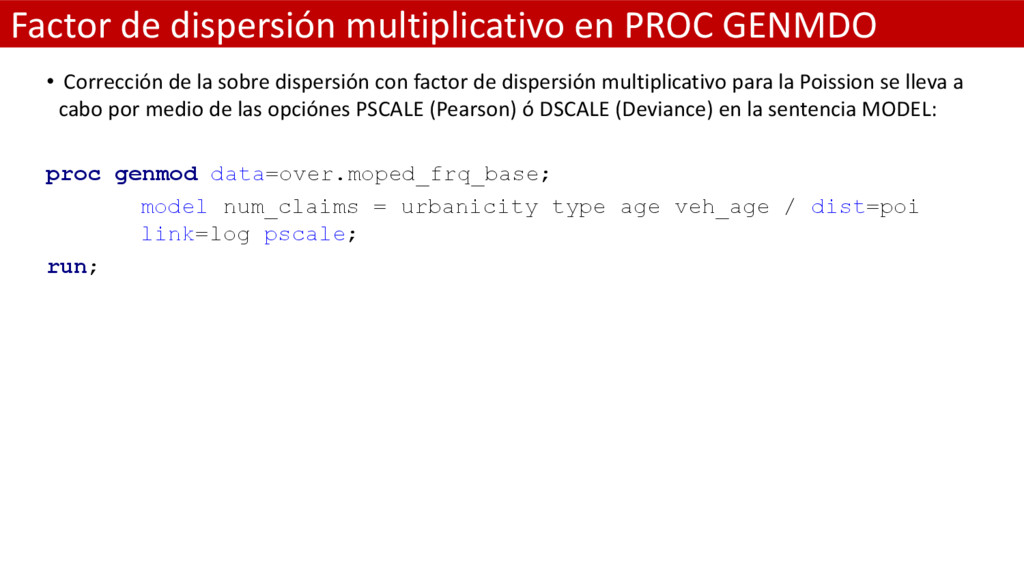
la sobre dispersión con factor de dispersión multiplicativo para la Poission se lleva a cabo por medio de las opciónes PSCALE (Pearson) ó DSCALE (Deviance) en la sentencia MODEL: proc genmod data=over.moped_frq_base; model num_claims = urbanicity type age veh_age / dist=poi link=log pscale; run;
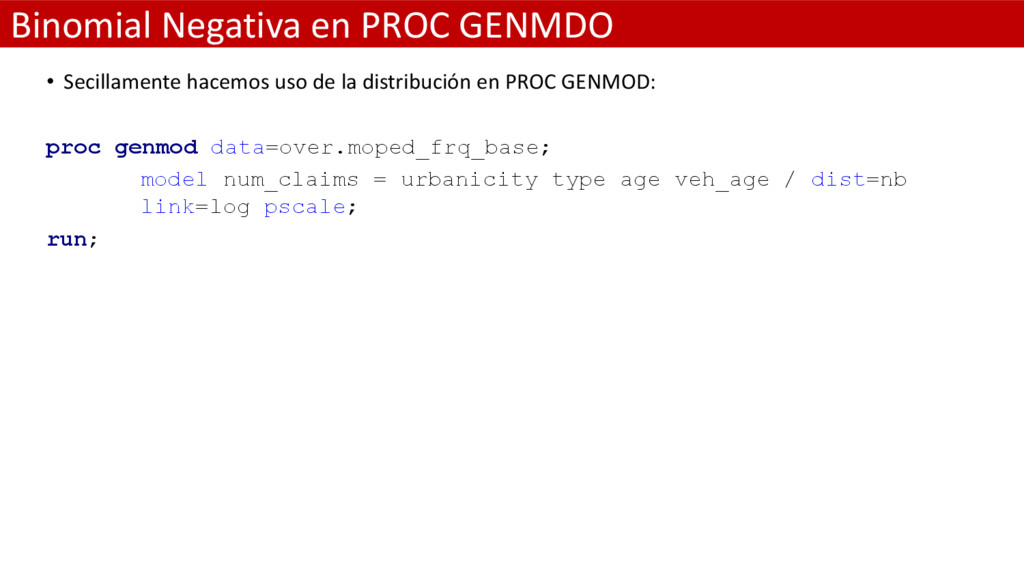
de sortear la sobre dispersión es usando una distribución más flexible que la Poisson • La distribución Binomial Negativa permite a la varianza exceder la media • Al contrario que la rígida Poisson, ésta distribución sí es capaz de albergar la heterogeneidad no recogida por el modelo y tener en cuenta así la sobre dispersión existente • La relación media-varianza cuando usamos la BN, necesita de la estimación de un parámetro adicional de dispersión que debe bien ser estimado y fijado a un valor • Gracias a éste parámetro la varianza puede exceder a la media y permite a la BN tener en cuenta la existencia de sobre dispersión
verosimilitud • No se permite que varié entre observaciones • Cuando k = 0 el modelo corresponde a un modelo de Poisson • Cuando k > 0 : – la sobre dispersión es evidente y los errores estándar se incrementarán en consecuencia. – Los valores estimados de los parámetros permanecen sin apenas cambio en relación al modelo de Poisson, – pero los mayores errores estándar son capaces de aumentar para reflejar la sobre dispersión no capturada por el modelo de Poisson
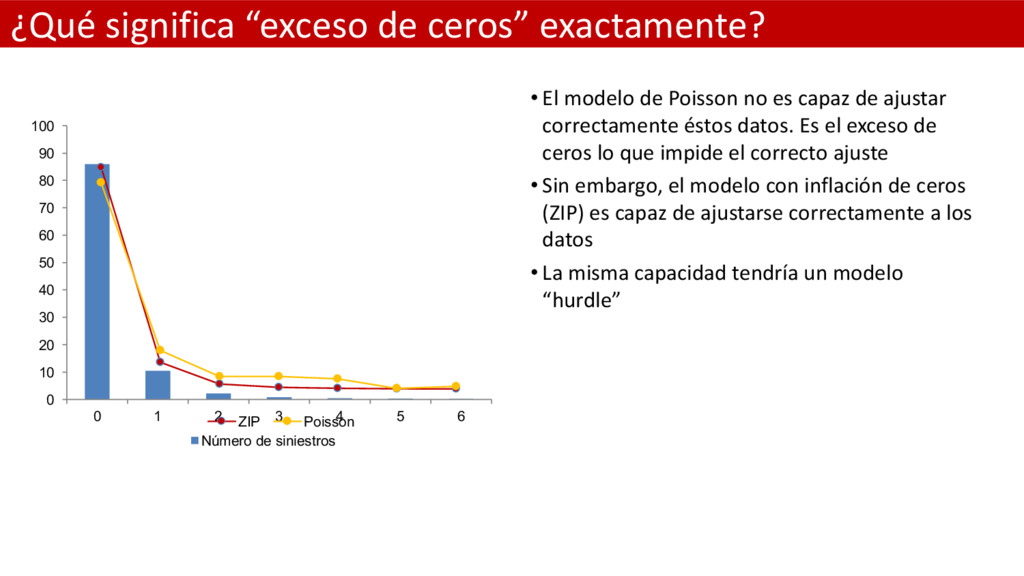
cuando los datos observados muestran una proporción de valores ceros mayor de la que puede ser explicada por un modelo estándar para datos de conteo como el Poisson o Binomial Negativo • Existen dos vías para resolver el problema: – El modelo de inflación o exceso de ceros o “zero inflated model” en inglés – El modelo “hurdle” o modelo de “dos partes” • Ambos modelos el “hurdle” y el “zero inflated” tienen su versión para la Poisson y para la Binomial. En consecuencia, tenemos a nuestra disposición un total de 4 modelos más con los que abordar la modelización de la Frecuencia • Los modelos ZIP y ZINB suelen también utilizarse para solventar el problema de sobre dispersión además del problema de exceso de ceros
Poisson no es capaz de ajustar correctamente éstos datos. Es el exceso de ceros lo que impide el correcto ajuste • Sin embargo, el modelo con inflación de ceros (ZIP) es capaz de ajustarse correctamente a los datos • La misma capacidad tendría un modelo “hurdle” 0 10 20 30 40 50 60 70 80 90 100 0 1 2 3 4 5 6 Número de siniestros ZIP Poisson
que generan exceso de ceros: • Existen dos o más poblaciones distintas en nuestros datos – Ejemplo: si nuestra cartera de autos posee una elevada proporción de persona de edad avanzada que, aunque aseguran su vehículo no lo conducen. En consecuencia no es posible que tengan un accidente con su automóvil – En éste caso la aproximación al problema la haríamos desde un modelo con exceso de ceros • Existen incentivos que alteran el comportamiento del asegurado: – Ejemplo: se trata del fenómeno de “huger for bonus”, que significa que el asegurado no reporta a la compañía todos sus siniestros (evidentemente los de cuantía pequeña) para conservar su bonus el próximo año. En definitiva, para evitar ser penalizado con un incremento de prima mayor que coste del siniestro – En éste caso la aproximación al problema la haríamos desde un modelo “hurdle”
– imaginemos que el 30% de nuestra cartera está formado por personas mayores que no conducen (pese a estar asegurados) – Imaginemos por un momento que podemos distinguirlos (sabemos quién conduce y quién no). Obviamente en la realidad no disponemos de ésta información y de ahí el problema de exceso de ceros • En consecuencia podemos observar que nuestra distribución con inflación de ceros tiene la forma que vemos a la izquierda: – Un 30% de nuestros conductores no conducen y, por tanto, no pueden tener un accidente – El 70% restante conduce y, en consecuencia, podrá o no tener un accidente 0 10 20 30 40 50 60 70 80 90 100 0 1 2 3 4 5 6 conducen no conducen
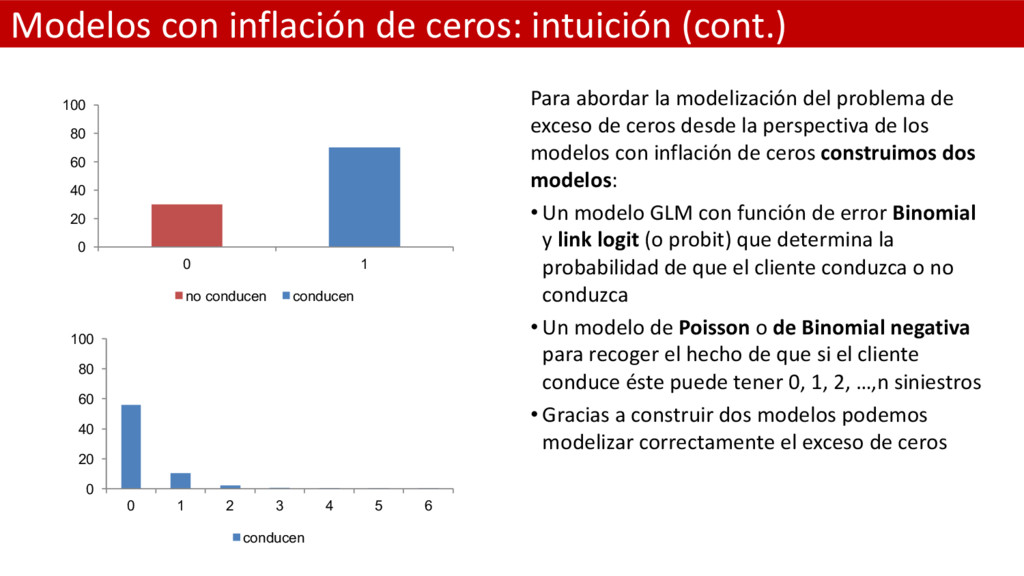
modelización del problema de exceso de ceros desde la perspectiva de los modelos con inflación de ceros construimos dos modelos: • Un modelo GLM con función de error Binomial y link logit (o probit) que determina la probabilidad de que el cliente conduzca o no conduzca • Un modelo de Poisson o de Binomial negativa para recoger el hecho de que si el cliente conduce éste puede tener 0, 1, 2, …,n siniestros • Gracias a construir dos modelos podemos modelizar correctamente el exceso de ceros 0 20 40 60 80 100 0 1 no conducen conducen 0 20 40 60 80 100 0 1 2 3 4 5 6 conducen
son interesantes porque nos permiten modelizar el comportamiento del cliente como un proceso de decisión en dos partes: • En la primera parte el cliente decide si declara sus siniestros de baja cuantía a la compañía o no lo hace • En la segunda parte, si el cliente ha decidido declarar sus siniestros de baja cuantía a la compañía entonces declarará 1, 2, 3,…,n siniestros Los modelos “hurdle” (“vallas”, como las de los corredores de 110 metros vallas) reflejan que para declarar algún siniestro positivo debes haber saltado la “valla” de haber decidido previamente declarar tus siniestros 0 10 20 30 40 50 60 70 80 90 100 0 1 2 3 4 5 6 declaran no declaran
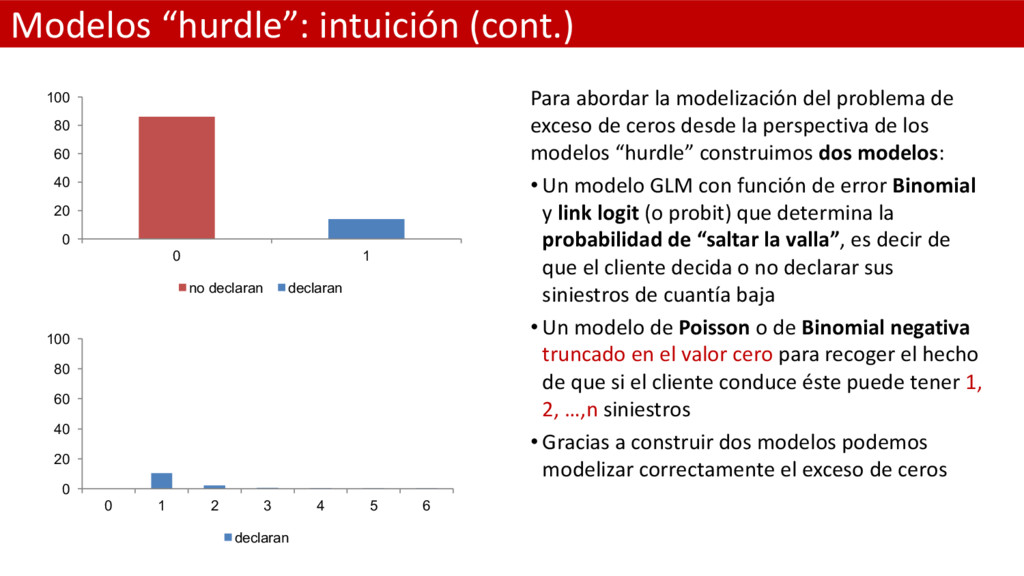
de exceso de ceros desde la perspectiva de los modelos “hurdle” construimos dos modelos: • Un modelo GLM con función de error Binomial y link logit (o probit) que determina la probabilidad de “saltar la valla”, es decir de que el cliente decida o no declarar sus siniestros de cuantía baja • Un modelo de Poisson o de Binomial negativa truncado en el valor cero para recoger el hecho de que si el cliente conduce éste puede tener 1, 2, …,n siniestros • Gracias a construir dos modelos podemos modelizar correctamente el exceso de ceros 0 20 40 60 80 100 0 1 no declaran declaran 0 20 40 60 80 100 0 1 2 3 4 5 6 declaran
trata de modelos que son útiles cuando sospechamos que podrían existir dos sub poblaciones en nuestra población • El modelo básico tiene la siguiente forma donde • = la probabilidad de pertenecer a un grupo de población (no usan el coche) u otro (lo usan) • (0|" ) y (|" ) se basan en algún modelo, bien en un Poisson, bien en un Binomial Negativo
modelo de Poisson con inflación de ceros con link = log usualmente: Notar que si = 0 tenemos un modelo de Poisson con link=log Finalmente la pertenencia a una clase u otra es una variable dicotómica que podemos modelizar con una regresión logística "• 1 − "• = & + ( "• + ⋯ + ’ "•
Sin modelo para la probabilidad de pertenencia a una u otra población: proc genmod data=credrpt; model mdr = age income avgexp / link=log dist=zip type3; zeromodel / link=logit; run; • Con modelo para la probabilidad de pertenencia a una u otra población : proc genmod data=credrpt; model mdr = age income avgexp / link=log dist=zip type3; zeromodel age income avgexp / link=logit; run; • En el “zeromodel” pueden aparecer las mismas variables, sólo algunas u otras completamente distintas a las que aparecen en la sentencia “model” • La distribuciones utilizada también puede ser “zinb”
Sin modelo para la probabilidad de pertenencia a una u otra población: proc fmm data=credrpt; model mdr = age income avgexp / dist=poisson; model mdr = / dist=constant; probmodel; run; • Con modelo para la probabilidad de pertenencia a una u otra población : proc fmm data=credrpt; model mdr = age income avgexp / dist=poisson; model mdr = / dist=constant; probmodel age income ownrent; run;
fmm data=credrpt; model mdr = age income avgexp / dist=poisson; run; *Negative Binomial; proc fmm data=credrpt; model mdr = age income avgexp / dist=negbin; run;
donde • = la probabilidad de pertenecer a un grupo de población (no usan el coche) u otro (lo usan) • (|" ) se basan en algún modelo, bien en un Poisson, bien en un Binomial Negativo truncado en el cero.
= log usualmente: Notar que si = 0 tenemos un modelo de Poisson con link=log truncado en el valor cero. Finalmente la pertenencia a una clase u otra es una variable dicotómica que podemos modelizar con una regresión logística "• 1 − "• = & + ( "• + ⋯ + ’ "•
no pueden ser estimados con el PROC GENMOD a día de hoy. Así que podemos usar el PROC FMM • Sin modelo para la probabilidad de pertenencia a una u otra población: proc fmm data=credrpt; model mdr = age income avgexp / dist=tpoisson lin=log offset=ln_exp; model mdr = / dist=constant; probmodel; run; • Con modelo para la probabilidad de pertenencia a una u otra población proc fmm data=credrpt; model mdr = age income avgexp / dist=tpoisson link=log offset=ln_exp; model mdr = / dist=constant; probmodel age income ownrent; run; • En el “probmodel” pueden aparecer las mismas variables, sólo algunas u otras completamente distintas a las que aparecen en la sentencia “model” • La distribuciones utilizada también puede ser “tnegbin” • La segunda sentendia “model” va siempre sin variables explicativas
1 2 − − 2 22 − ∞ < < ∞ PDF('GAMMA',,< ,> ) Argumentos: • es una variable aleatoria continua • es un parámetro continuo de localizaicón . Rango > 0 • es un parámetro continuo de escala. Por defecto = 1. Rango > 0 • La función de densidad (PDF) para la distribución normal devuelve la función de probabilidad de densidad de una distribución normal con parámetro de localización y parámetro de escala . La PDF es evaluada en
1 2 − ( − 2 22 > 0 PDF('LOGNORMAL',,< ,> ) Argumentos: • es una variable aleatoria continua • especifica un parámetro continuo en escala logarítmica. (exp() es el parámetro de escala). • Rango > 0 • es un parámetro continuo de forma. Por defecto = 1. Rango > 0 La función de densidad (PDF) para la distribución lognormal devuelve la función de proabilidad de densidad de una distribución lognormal con parámetro de escalay parámetro de forma . La PDF es evaluada en Una variable está distribuida de forma lognormal si su logarítimo está distribuida normalmente.
1 ŸΓ Ÿ|( − , > 0 PDF('GAMMA',,α <,σ> ) Argumentos: • es una variable aleatoria continua • especifica un parámetro continuo de forma. Rango > 0 • parámetro continuo en escala . Por defecto = 1. Rango > 0 La función de densidad (PDF) para la distribución gamma distribution devuelve la función de proabilidad de densidad de una distribución gamma con parámetro de forma y parametro de escala . La PDF es evaluada en
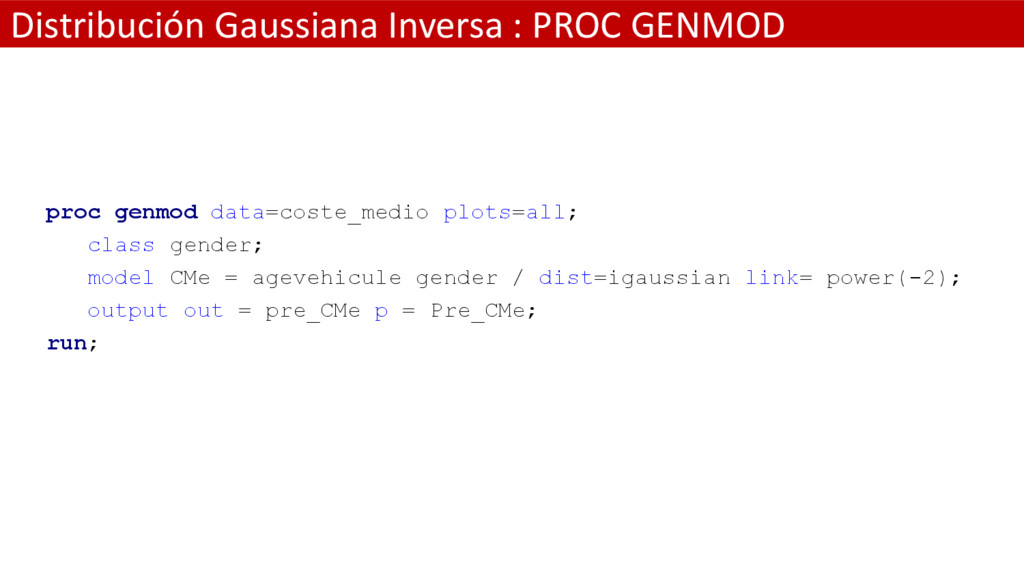
= = 24 ( 2 ¥ − − 2 22 , > 0 PDF(‘IGAUSS',,<,> ) Argumentos: • es una variable aleatoria continua • especifica un parámetro continuo de forma. Rango > 0 • parámetro continuo en escala . Por defecto = 1. Rango > 0 La función de densidad (PDF) para la distribución Gaussiana inversa devuelve la función de proabilidad de densidad de una distribución Gaussiana inversa con parámetro de forma y parametro de escala . La PDF es evaluada en
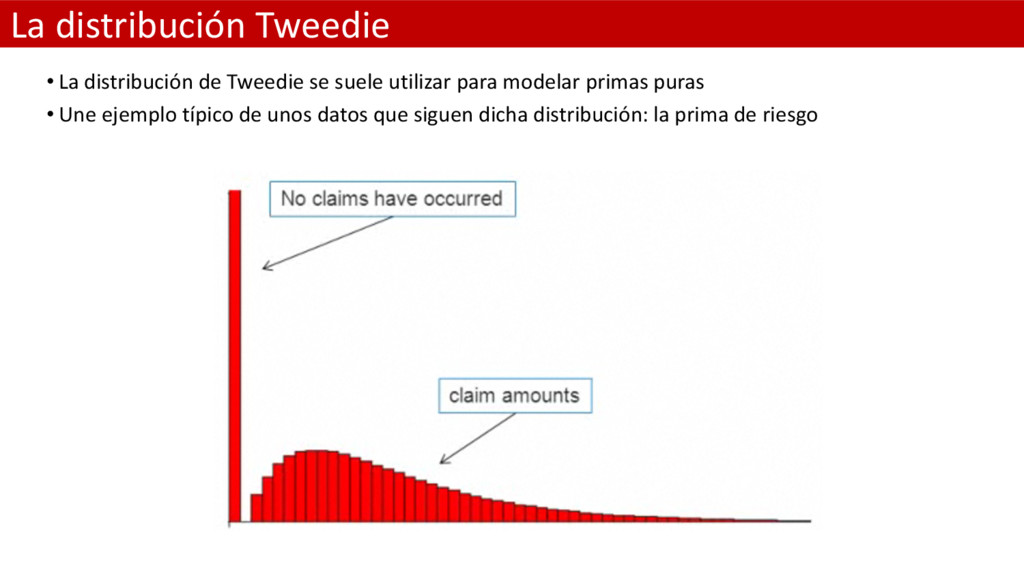
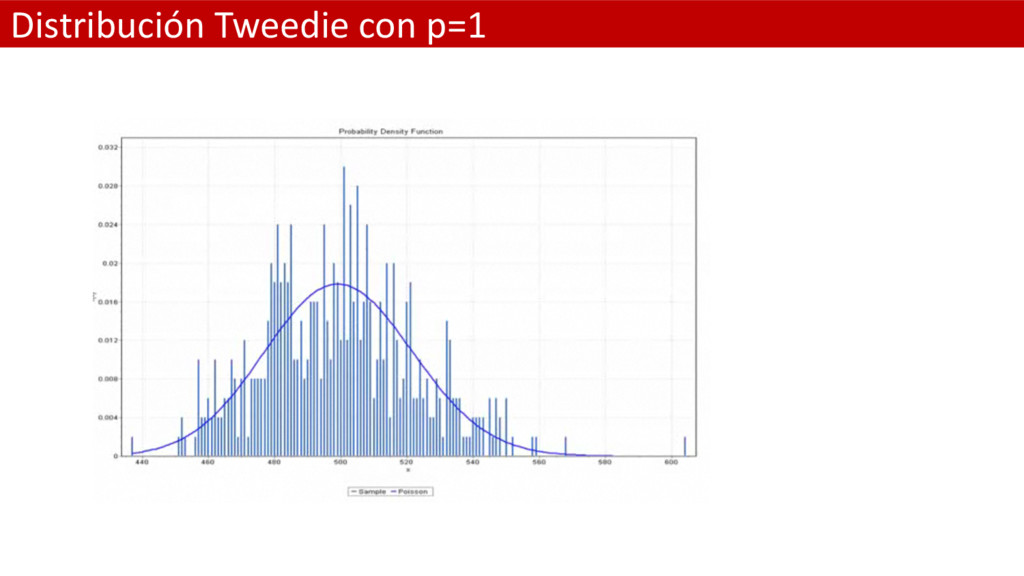
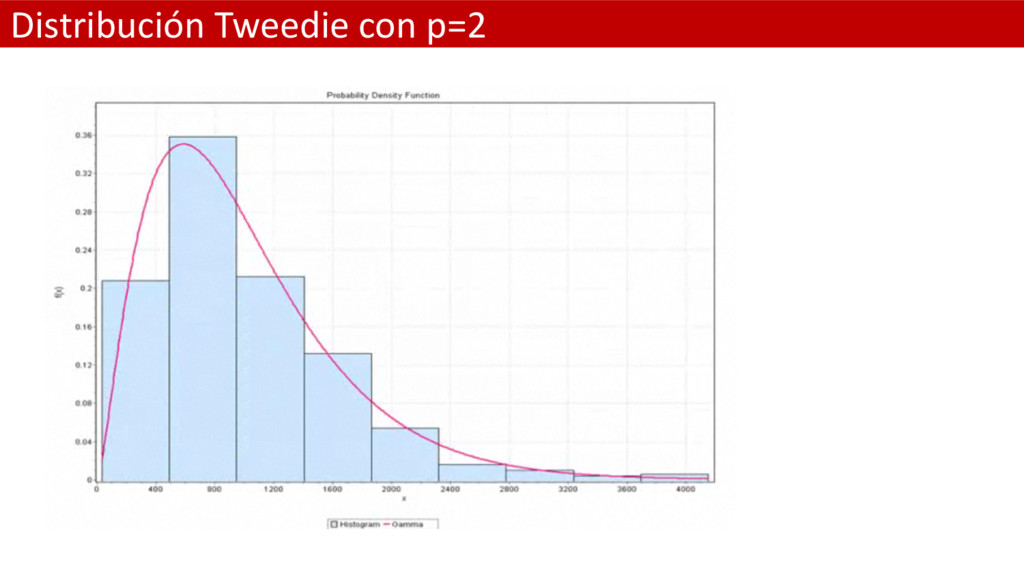
un punto de masa discreto en el valor cero. Siendo así útil para modelizar eventos en los que exista una mixtura de observaciones cero y positivas. • La media y la varianza de la distribución Tweedie es: • Donde fi es el parámetro de dispersión y p es un parámetro extra que controla la varianza de la distribución. • La familia de distribuciones Tweedie incluye varias distribuciones importantes para los GLM: – Cuando p = 0 la distribución Tweedie degenera en una normal – Cuando p = 1 la distribución Tweedie se convierte en una Poisson – Cuando p = 2 se convierte en una Gamma • En la práctica el rango de valores más interesante se encuentra entre 1 y 2. Cuando pasamos de 1 a 2 e el parámetro p la distribución Tweedie progresivamente va perdiendo su punto de masa discreto en cero para ir derivando hacia la Gamma. En éste caso caso decimos que la distibución Tweedie se ha generado como una distribución de Poission compuesta.
GENMOD no soporta de forma natural la distribución Tweedie. Sin embargo, éste procedimiento permite crear la distribución que el usuario desee: PROC GENMOD DATA=TEWEEDIE PLOTS=all; P=1.67; Y=_RESP_; A=_MEAN_; VARIANCE BAR=A**P; DEVIANCE DEV=2*((Y**(2-P)-Y*A**(1-P))/(1-P)-(Y**(2-P)-A**(2-P))/(2-P)); CLASS METROS2 MUN1 MUN2 BOMB_DISTA; WEIGHT ALCCL; MODEL BURNING_COST= METROS2 MUN1 MUN2 BOMB_DISTA/ LINK=LOG SCALE=PEARSON; RUN; • En las sentencias 2 a 6 del código se especifica la distribución Tweedie por el usuario. La opción PEARSON en la sentencia MODEL también es clave.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}