First chapter (practice exercises) of my training for the Spanish Actuarial Institute 5 days course "Generalized Linear Models in Auto and Household Ratemaking using SAS" that I've been teaching during the years 2014 and 2015.
Modelos de Frecuencia: modelización de la sobre dispersión Práctica 3: ¿Sobre dispersión ó exceso de ceros? ¿Cómo detectar el exceso de ceros? Práctica 4: Modelos de Coste Medio: ajuste del coste medio Práctica 5: Ajuste del Burning Cost con una distribución Tweedie
set contains information on 22036 settled personal injury insurance claims. These claims arose from accidents occurring from July 1989 through to January 1999. Claims settled with zero payment are not included. Varible Definition total settled amount inj1, ..., inj5 injury 1,..., injury 5 coded as 1 = no injury 2, 3, 4, 5 = injury severities 6 = fatal injury 9 = not recorded legrep legal representation (0 = no, 1 = yes) accmonth accident month (1 = July 1989, ..., 120 = June 1999) repmonth reporting month (as above) finmonth finalization month (as above) op_time operational time
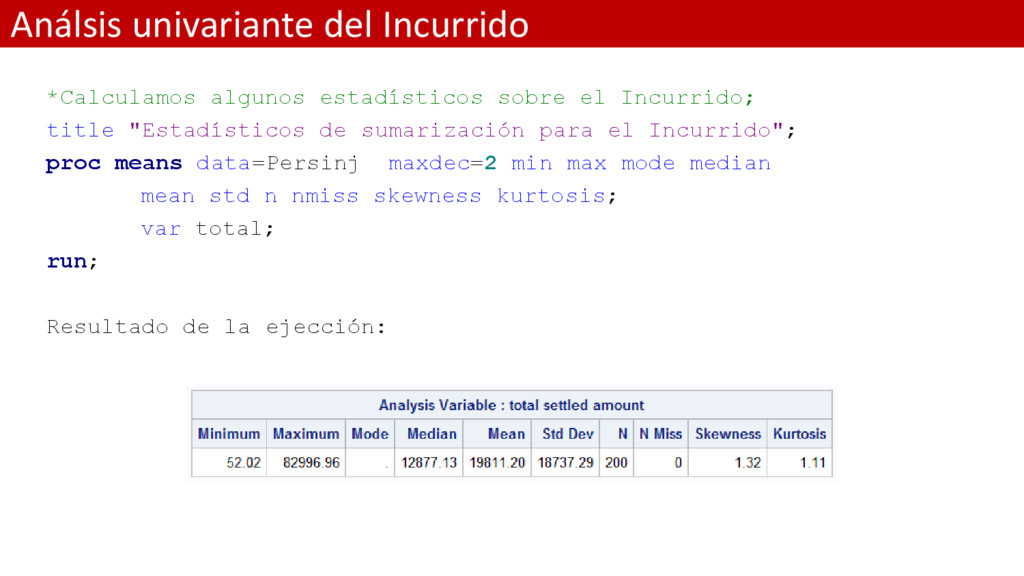
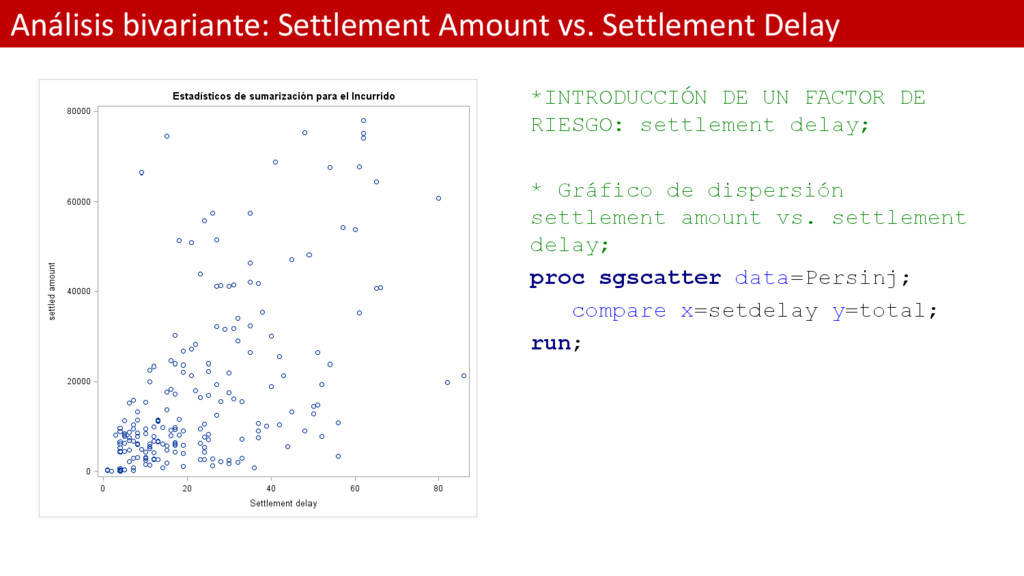
title "Estadísticos de sumarización para el Incurrido"; proc means data=Persinj maxdec=2 min max mode median mean std n nmiss skewness kurtosis; var total; run; Resultado de la ejección:
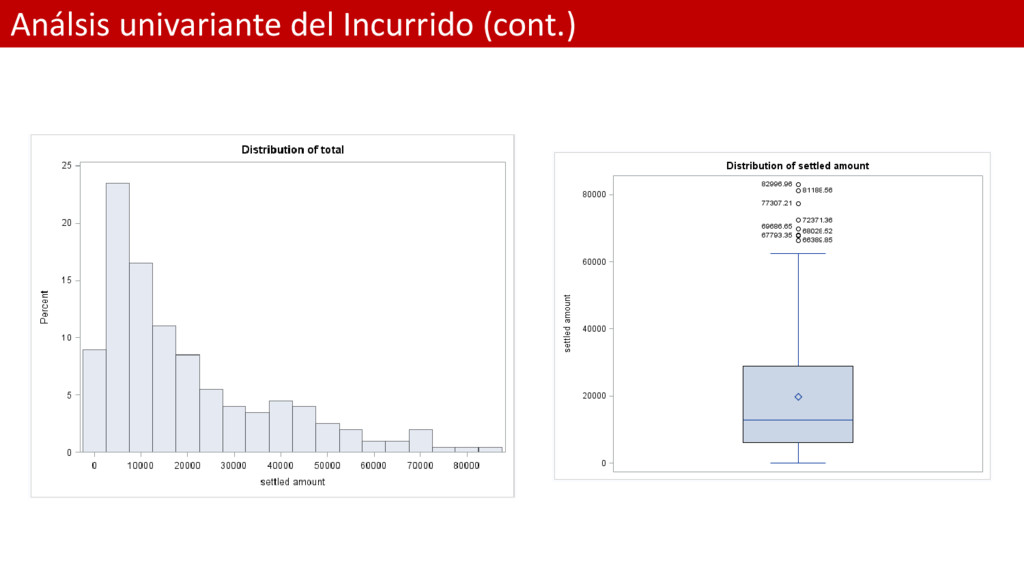
frecuencia para el Incurrido; ods graphics on; title "Histograma del Incurrido"; proc univariate data=Persinj ; var total; histogram / nmidpoints=18; run; *Diagrama de caja para el Incurrido; title "Diagrama de caja del Incurrido"; proc sgplot data=Persinj noautolegend; title 'Distribution of settled amount'; vbox total / datalabel; run;
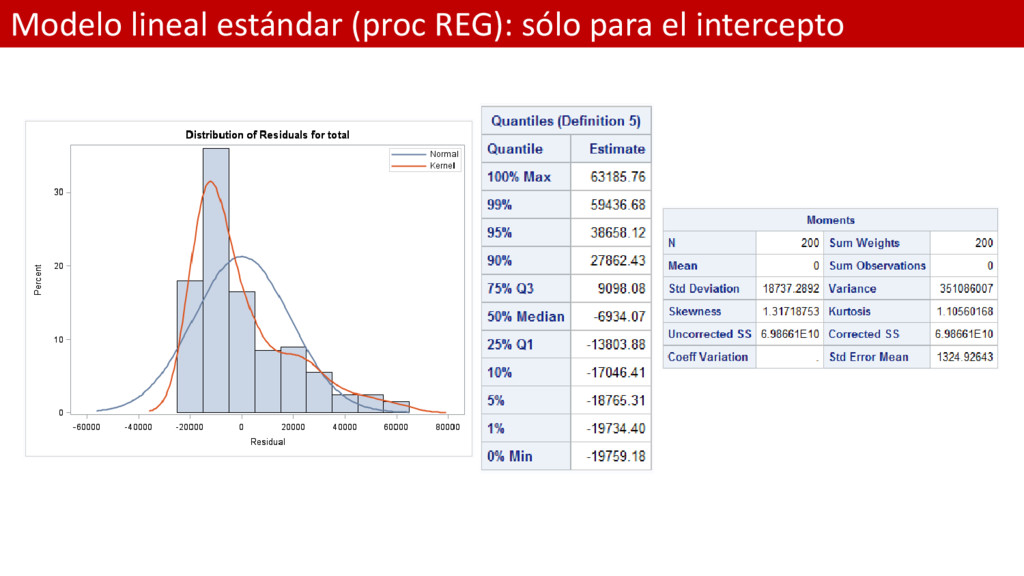
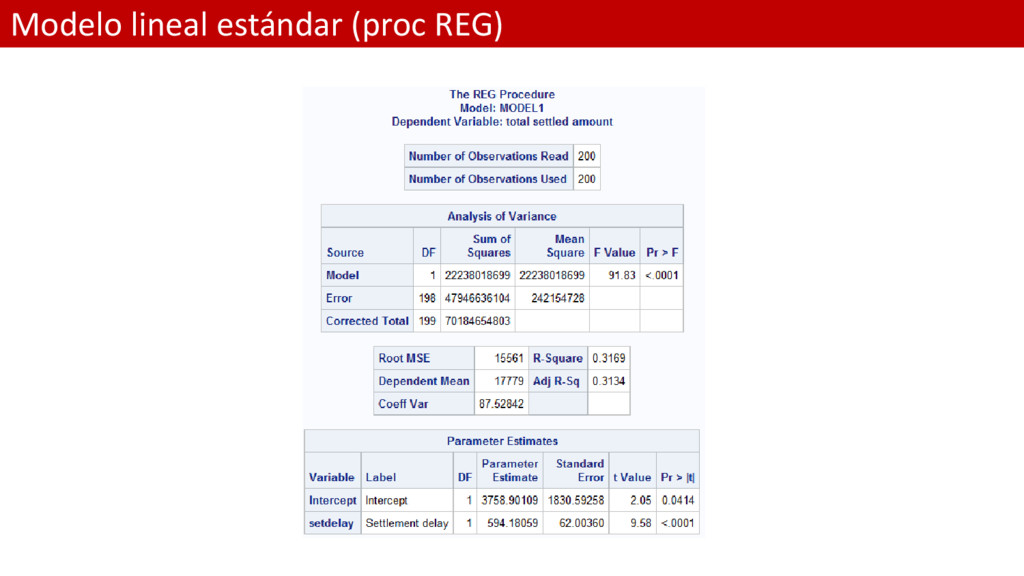
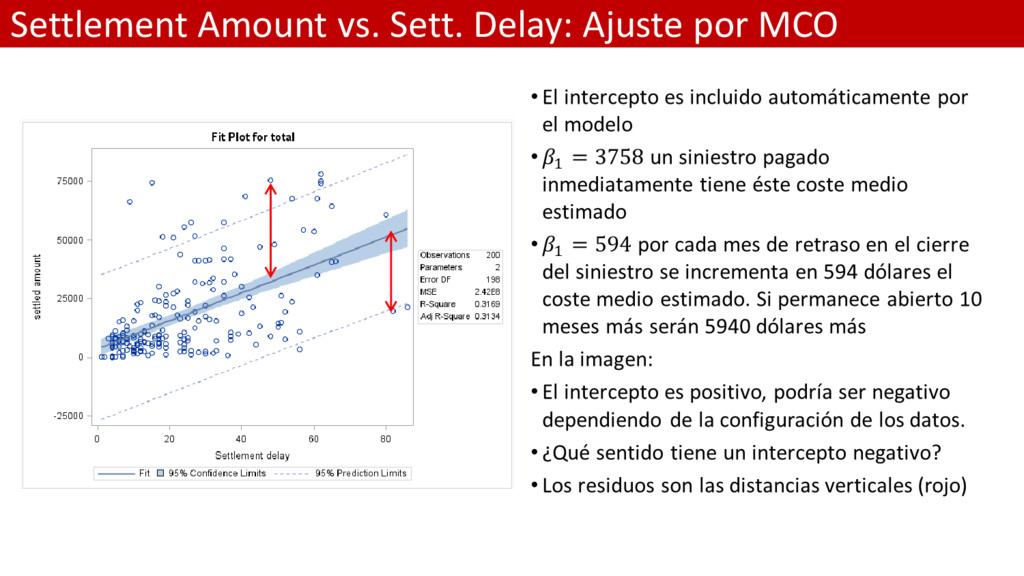
LINEAL ESTÁNDAR SÓLO PARA EL INTERCEPTO; *Ajuste del modelo; proc reg data = Persinj plots=residualhistogram; model total = ; output out=res residual=row_res; run; *Análisis de residuos; proc univariate data = res; var row_res; run;
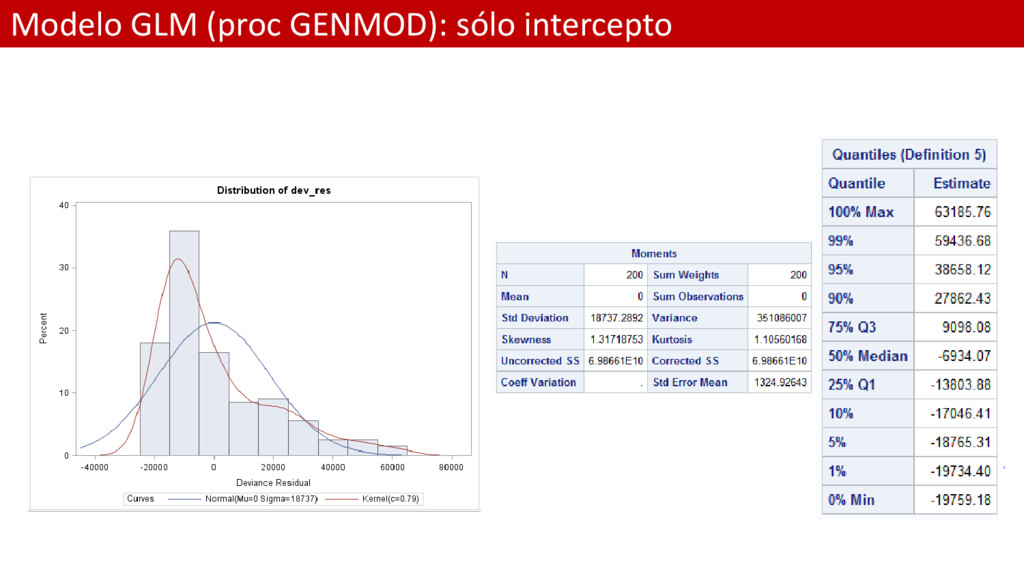
EL INTERCEPTO; * Función de error: Normal; * Link: identity; proc genmod data = Persinj /*plots = all*/; model total = / dist=normal link=id; output out=res_dev resdev=dev_res; run; * Análisis de residuos para el modelo GLM; proc univariate data = res_dev; var dev_res; histogram dev_res / normal kernel; run;
de la media del Incurrido es el mismo que antes 19811.20 • Desviaciones: – pensemos en éste término como una distancia – En el modelo GLM con distribución de error Normal los residuos de desviaciones son lo mismo que los residuos brutos (modelo clásico) – Nota: en SAS a la Desviación se le llama “Scaled Deviance”
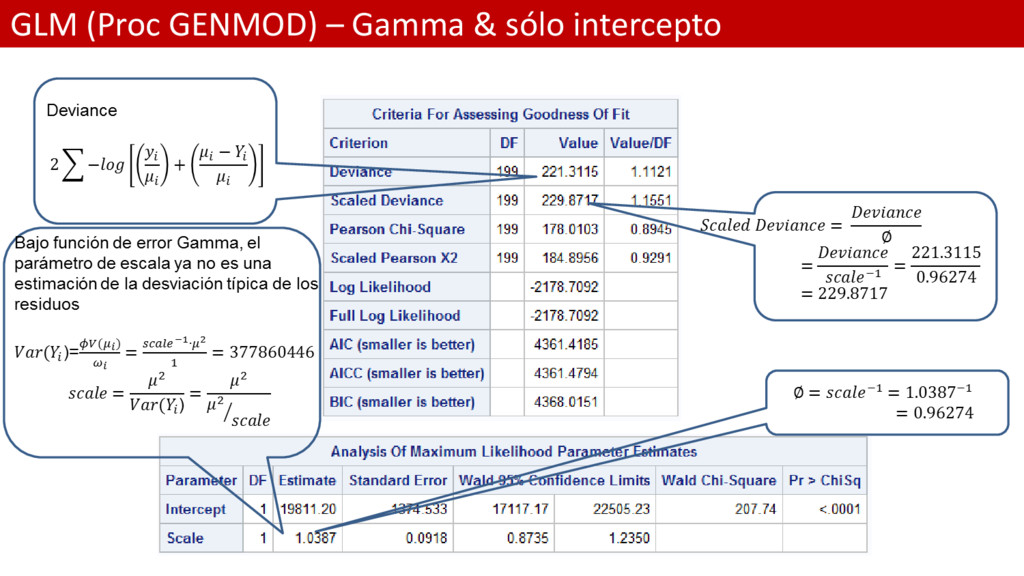
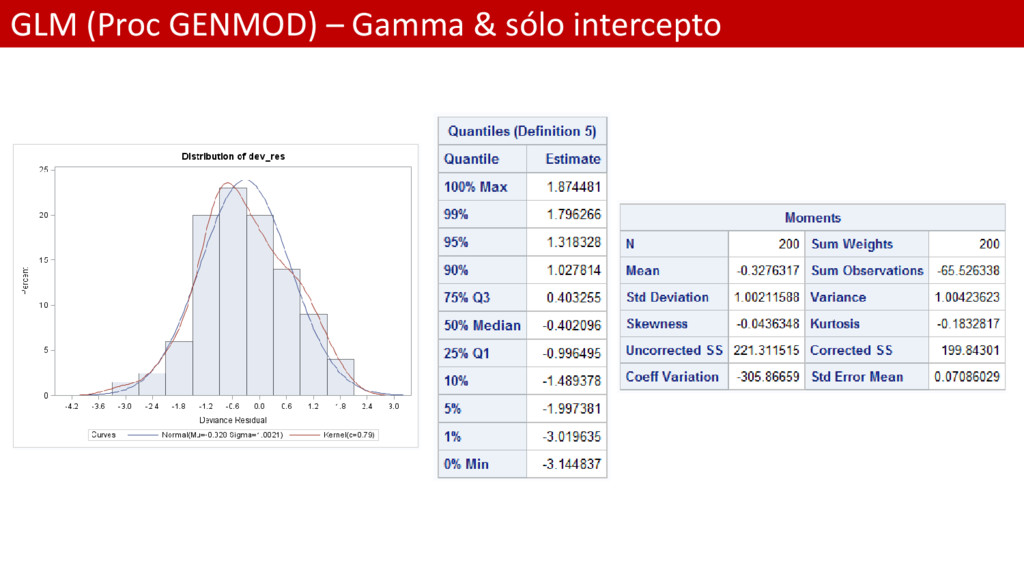
SÓLO PARA EL INTERCEPTO; * Función de error: Gamma; * Link: identity; proc genmod data = Persinj /*plots = all*/; model total = / dist=gamma link=id; output out=res_dev resdev=dev_res; run; * Análisis de residuos para el modelo GLM; proc univariate data = res_dev; var dev_res; histogram dev_res / normal kernel; run;
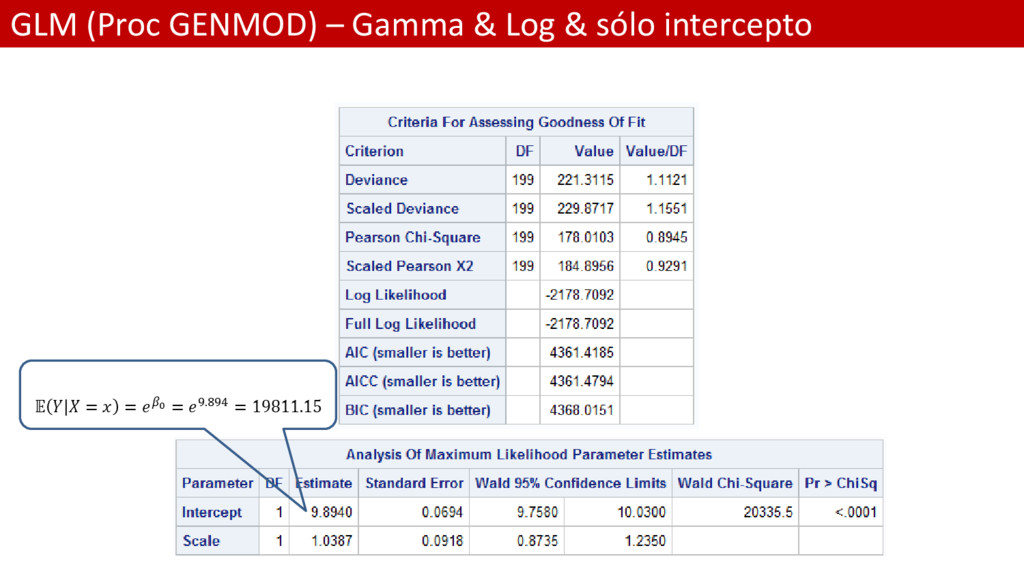
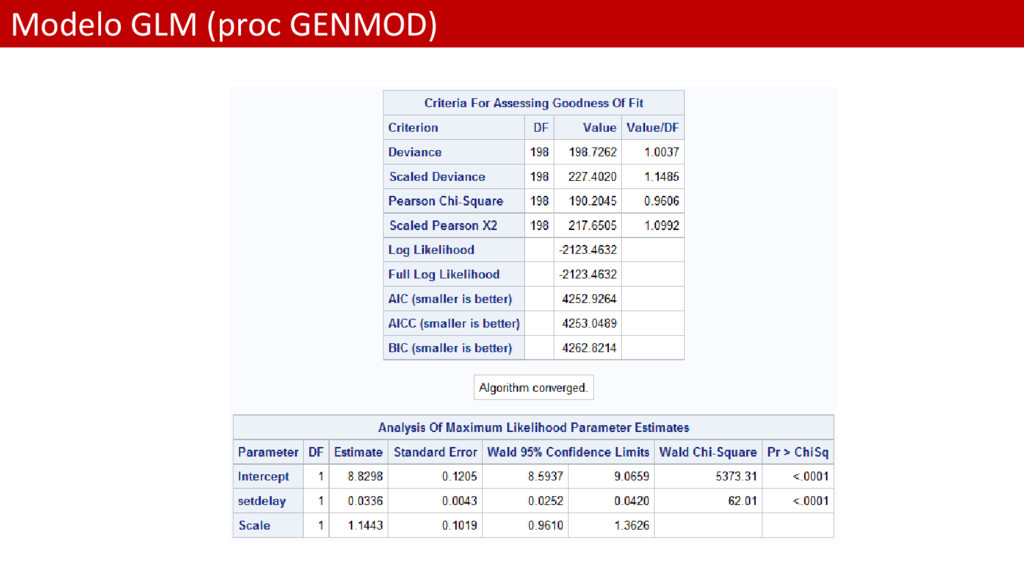
valor estimado de la media del Incurrido es el mismo que antes 19811.20 • El parámetro de dispersión ya no es la deviación estándar de los residuos, aunque es un escalar asociado • La Desviación ha disminuido enormemente • Los criterios AIC, AICC y BIC, que nos permiten comparar entre modelos • Los residuos de desviaciones ahora sí son Normales • La dispersión de los residuos es mucho más baja
*MODELO GLM SÓLO PARA EL INTERCEPTO; * Función de error: Gamma; * Link: log; proc genmod data = Persinj /*plots = all*/; model total = / dist=gamma link=log; output out=res_dev resdev=dev_res; run; * Análisis de residuos para el modelo GLM; proc univariate data = res_dev; var dev_res; histogram dev_res / normal kernel; run;
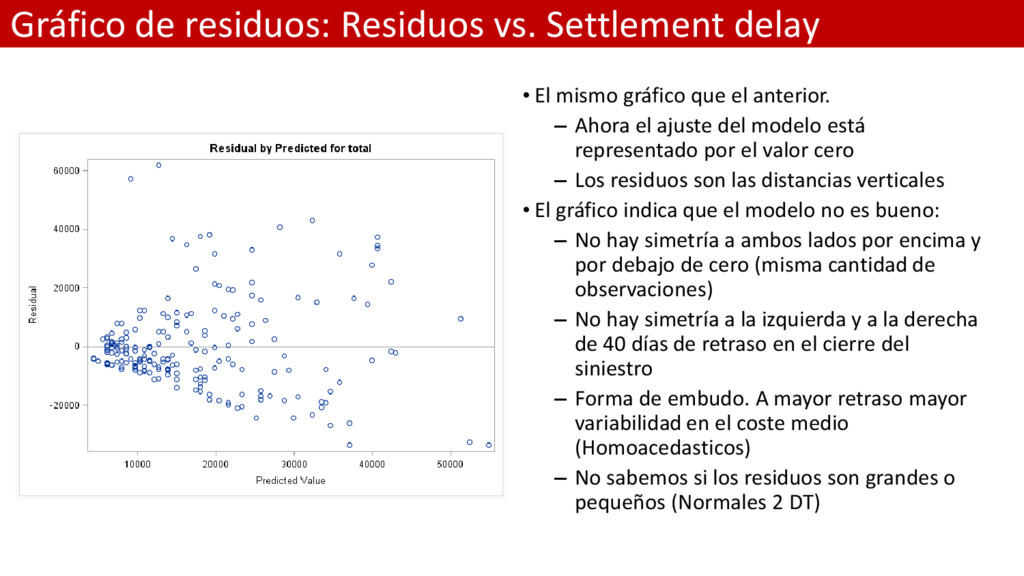
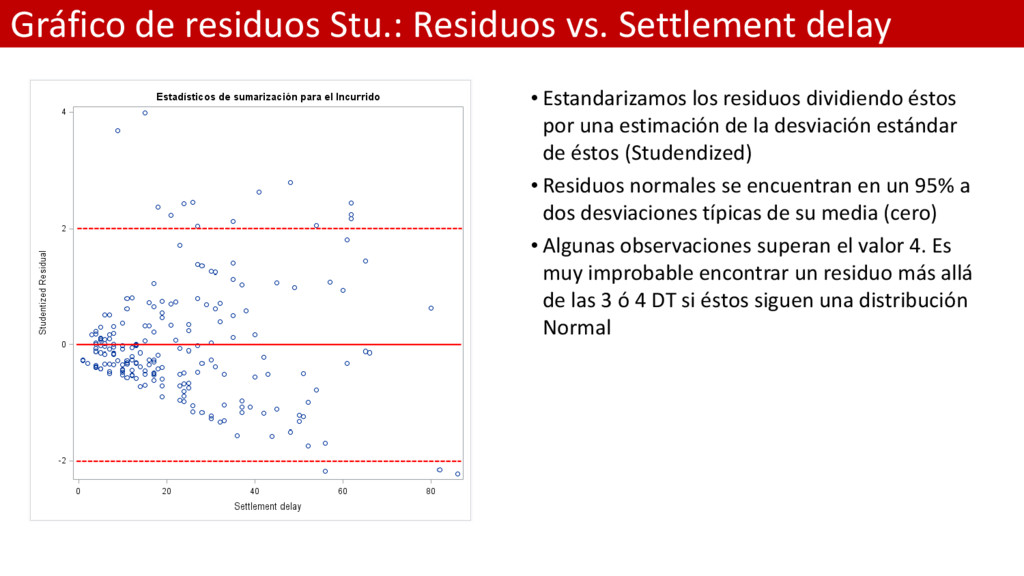
gráfico que el anterior. – Ahora el ajuste del modelo está representado por el valor cero – Los residuos son las distancias verticales • El gráfico indica que el modelo no es bueno: – No hay simetría a ambos lados por encima y por debajo de cero (misma cantidad de observaciones) – No hay simetría a la izquierda y a la derecha de 40 días de retraso en el cierre del siniestro – Forma de embudo. A mayor retraso mayor variabilidad en el coste medio (Homoacedasticos) – No sabemos si los residuos son grandes o pequeños (Normales 2 DT)
los residuos dividiendo éstos por una estimación de la desviación estándar de éstos (Studendized) • Residuos normales se encuentran en un 95% a dos desviaciones típicas de su media (cero) • Algunas observaciones superan el valor 4. Es muy improbable encontrar un residuo más allá de las 3 ó 4 DT si éstos siguen una distribución Normal
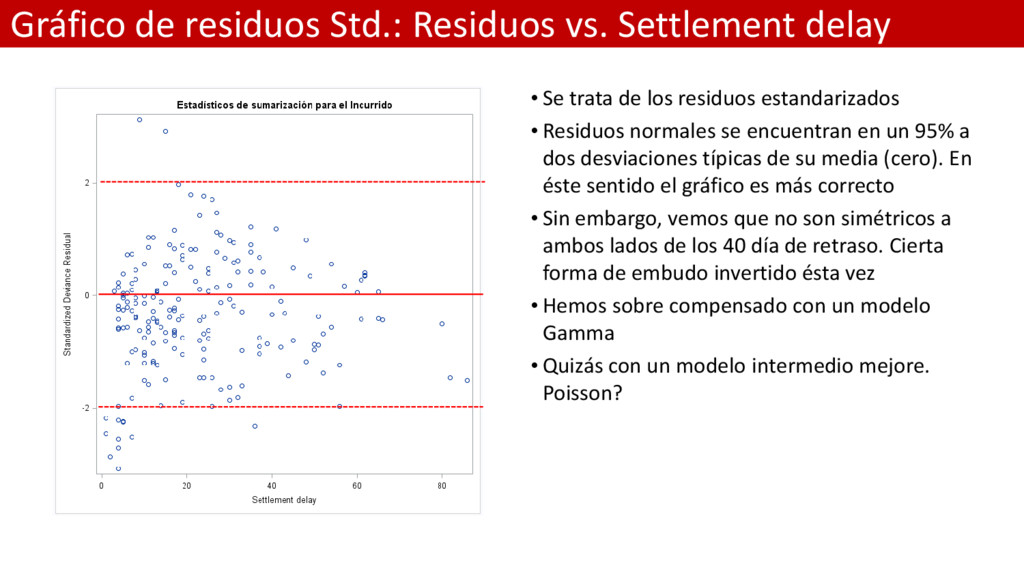
trata de los residuos estandarizados • Residuos normales se encuentran en un 95% a dos desviaciones típicas de su media (cero). En éste sentido el gráfico es más correcto • Sin embargo, vemos que no son simétricos a ambos lados de los 40 día de retraso. Cierta forma de embudo invertido ésta vez • Hemos sobre compensado con un modelo Gamma • Quizás con un modelo intermedio mejore. Poisson?
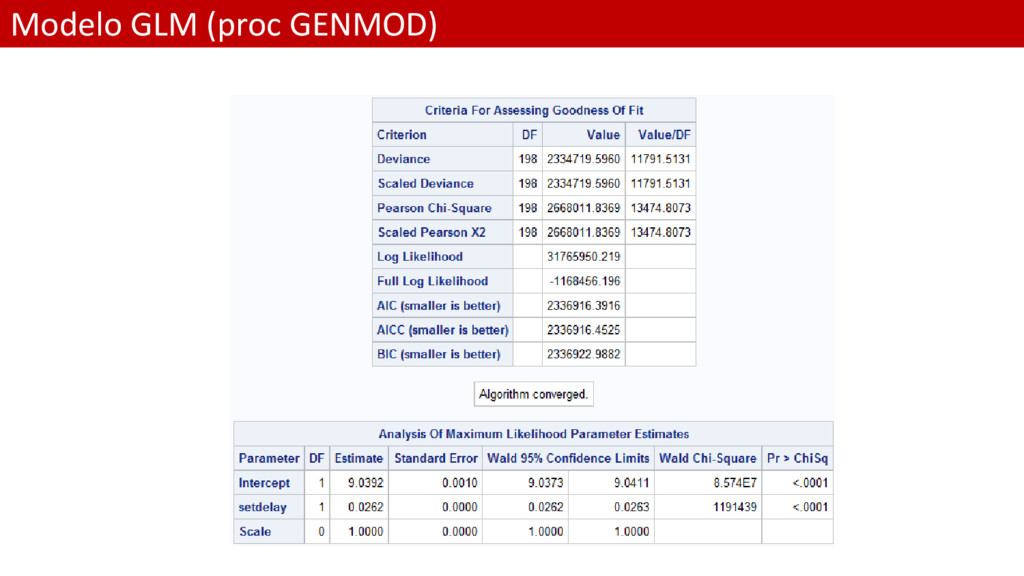
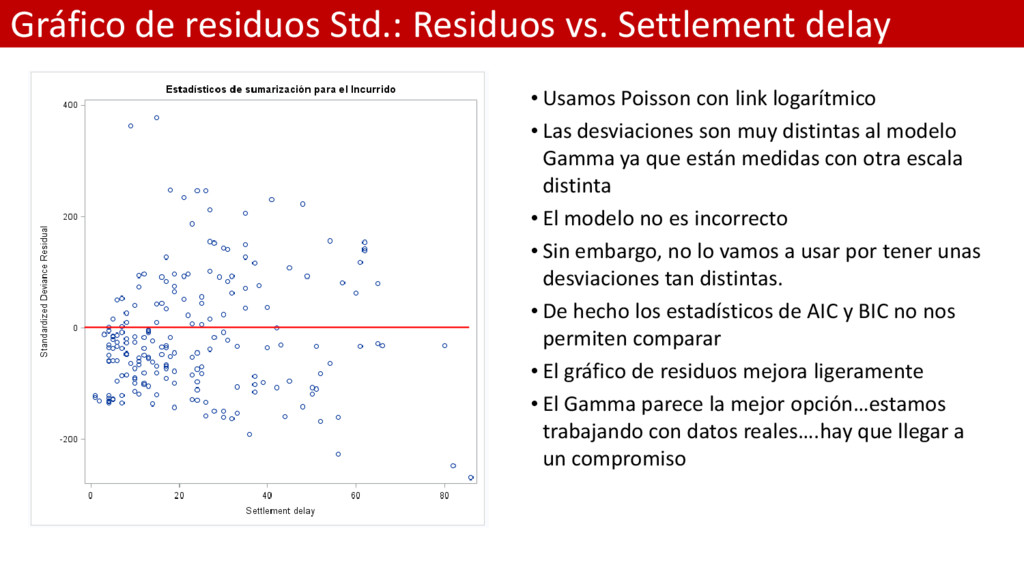
Poisson con link logarítmico • Las desviaciones son muy distintas al modelo Gamma ya que están medidas con otra escala distinta • El modelo no es incorrecto • Sin embargo, no lo vamos a usar por tener unas desviaciones tan distintas. • De hecho los estadísticos de AIC y BIC no nos permiten comparar • El gráfico de residuos mejora ligeramente • El Gamma parece la mejor opción…estamos trabajando con datos reales….hay que llegar a un compromiso
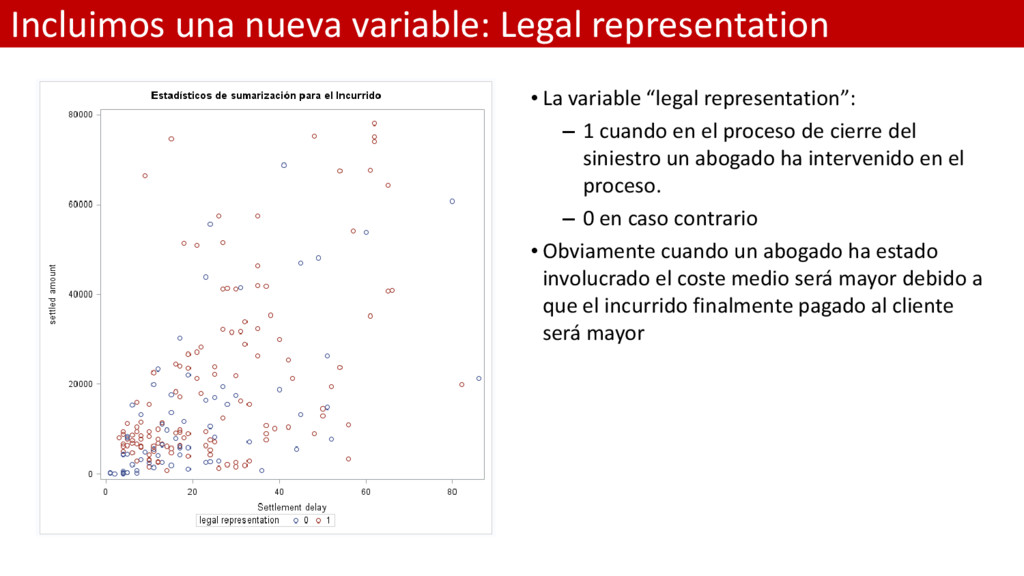
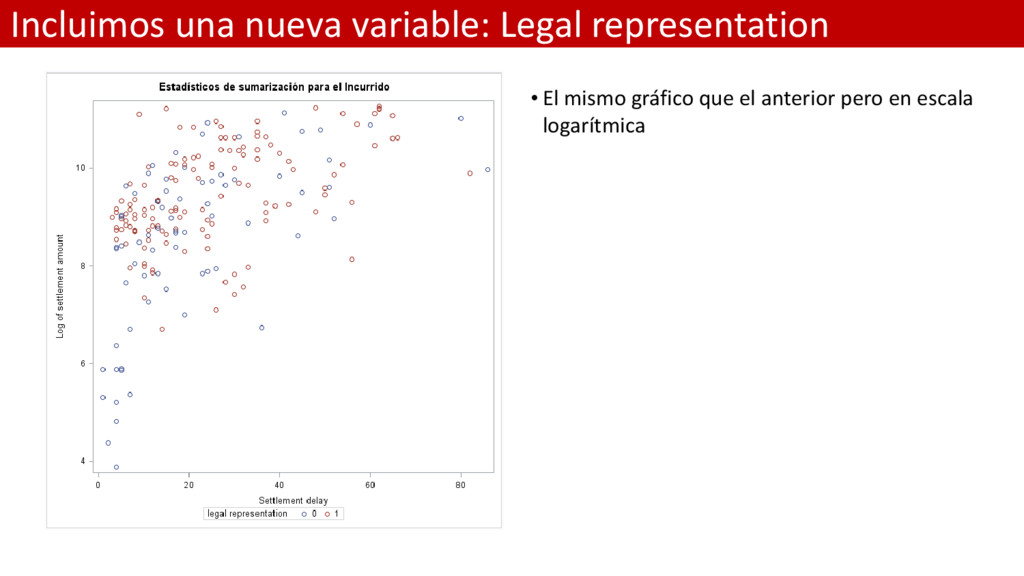
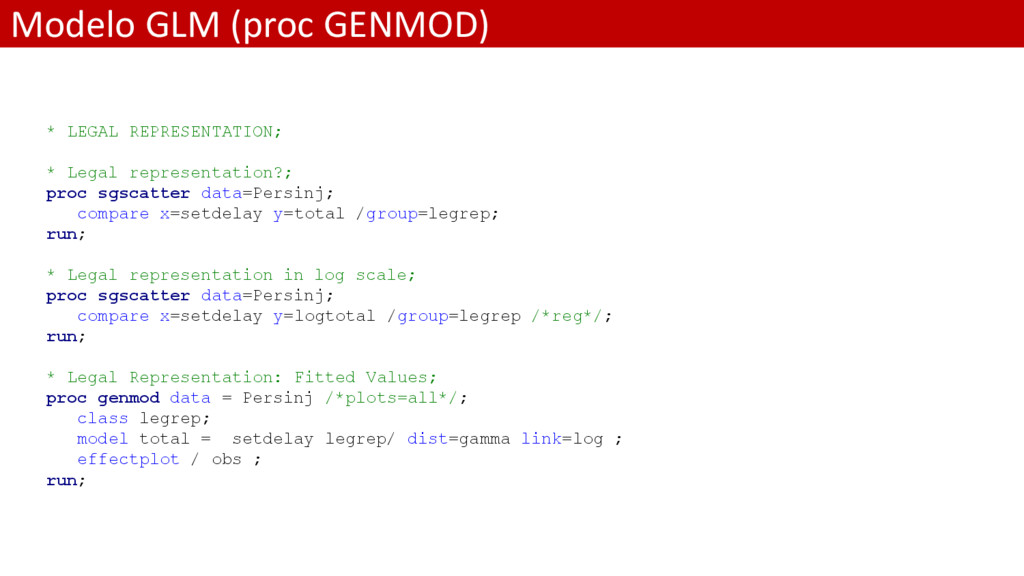
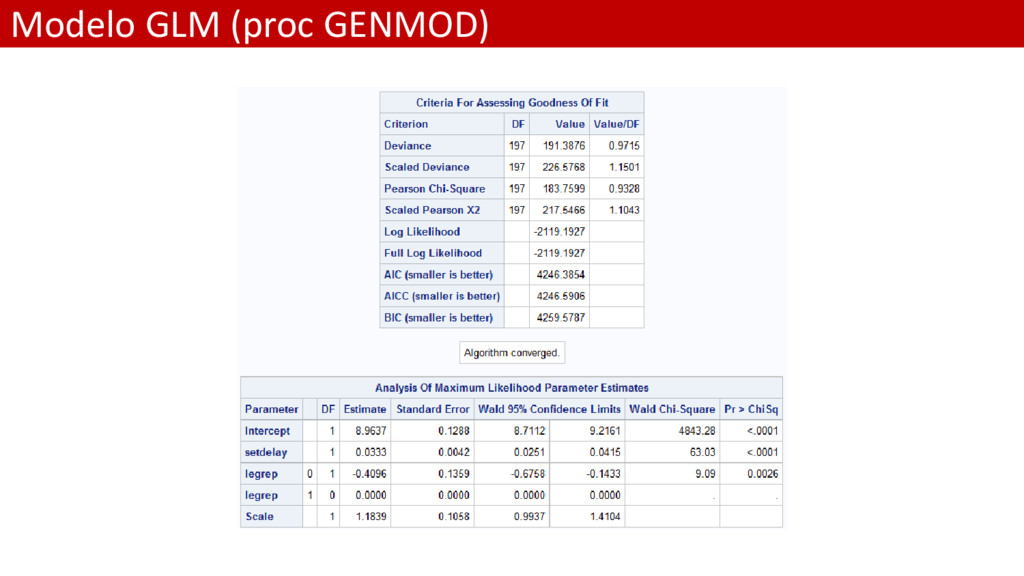
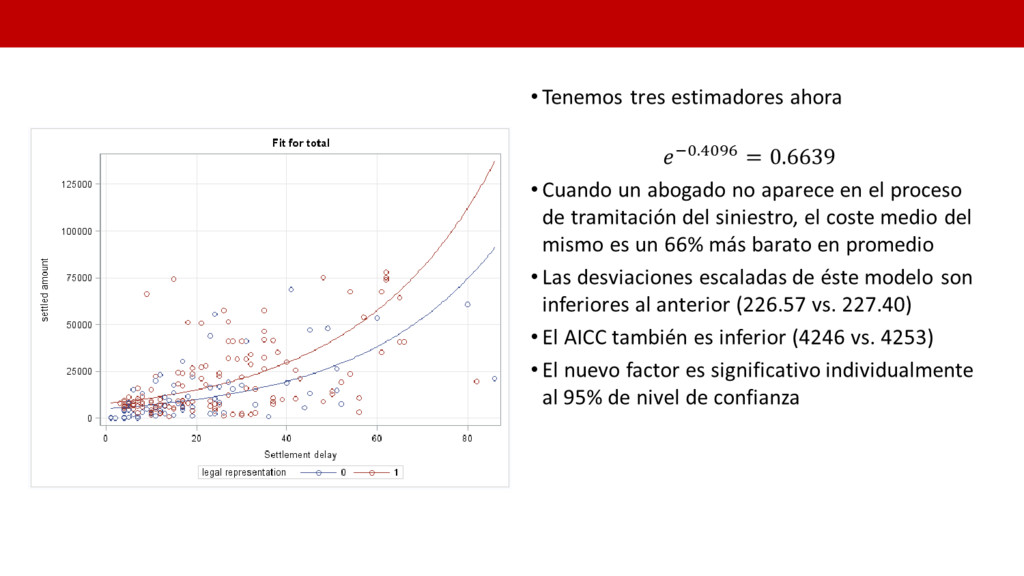
representation”: – 1 cuando en el proceso de cierre del siniestro un abogado ha intervenido en el proceso. – 0 en caso contrario • Obviamente cuando un abogado ha estado involucrado el coste medio será mayor debido a que el incurrido finalmente pagado al cliente será mayor
proc genmod data = Persinj /*plots=all*/; class legrep; model total = setdelay legrep/ dist=gamma link=log ; effectplot / obs link ; run; • La sentencia “effectplot” genera un gráfico de efectos que muestra el comportamiento de un factor de riesgo continuo (setdelay) frente a los niveles de otro factor de riesgo de clasificación (legrep). El objetivo es hacer más sencilla la interpretación del modelo • La opción “obs” muestra además las observaciones originales • La opción “link” muestra el predictor sin transformación
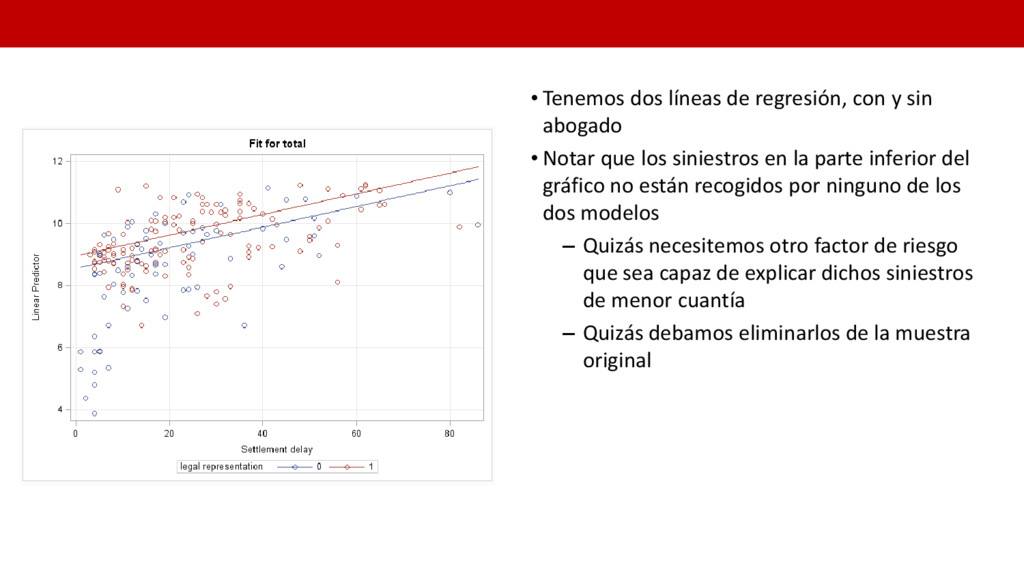
• Notar que los siniestros en la parte inferior del gráfico no están recogidos por ninguno de los dos modelos – Quizás necesitemos otro factor de riesgo que sea capaz de explicar dichos siniestros de menor cuantía – Quizás debamos eliminarlos de la muestra original
data set contains information on 287 observations about moped coverage. Note: to create the dataset run the first step of the code called overdispersion.sas Varible Definition num_claims number of claims (moped - yer) urbanicity rural or urban Type over or under 60 kg age age of the driver veh_age LT1, les than a year. MT1, more than a year
ref='Urban') type (param=ref ref='Under') veh_age (param=ref ref='LT1'); model num_claims = urbanicity type age veh_age / dist=poi link=log type3; estimate 'Rural vs. Urban Urbanicity' urbanicity 1; estimate 'Non-Under vs. Under' type 1; estimate 'MT1 vs. LT1' veh_age 1; estimate 'Age' age -1; title 'Poisson Regression Model of Number of Claims Data'; run;
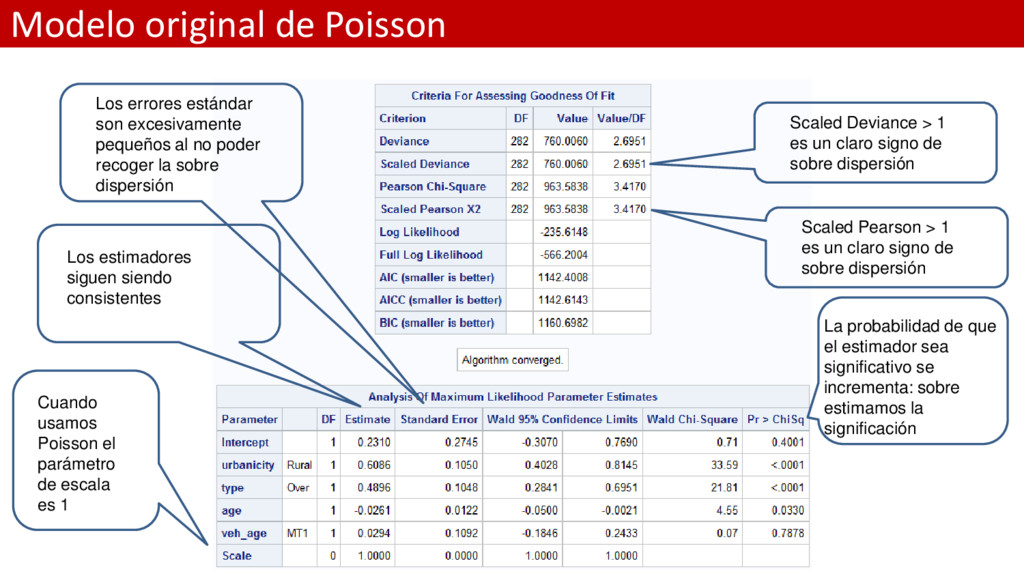
claro signo de sobre dispersión Scaled Pearson > 1 es un claro signo de sobre dispersión Los errores estándar son excesivamente pequeños al no poder recoger la sobre dispersión La probabilidad de que el estimador sea significativo se incrementa: sobre estimamos la significación Los estimadores siguen siendo consistentes Cuando usamos Poisson el parámetro de escala es 1
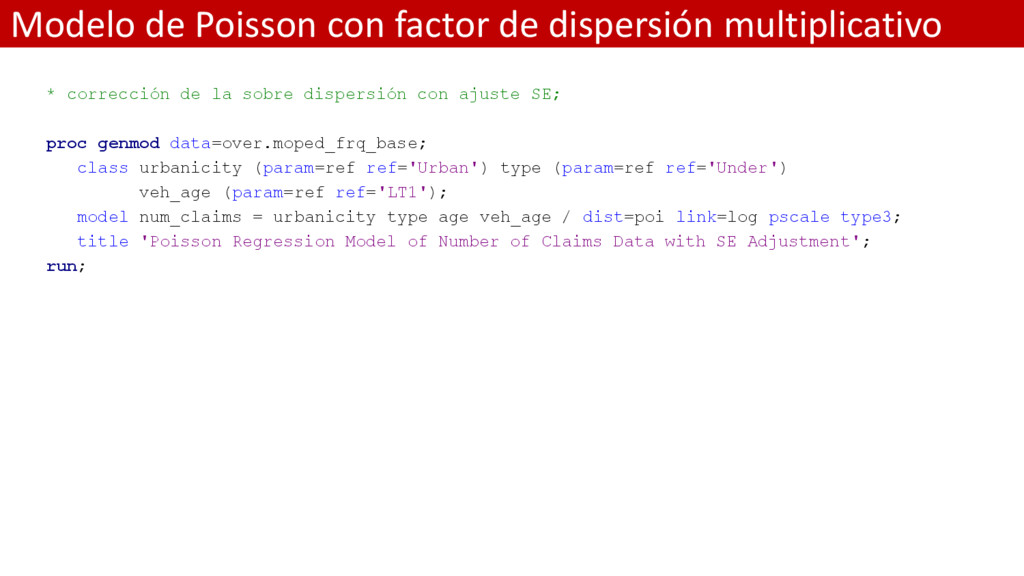
de la sobre dispersión con ajuste SE; proc genmod data=over.moped_frq_base; class urbanicity (param=ref ref='Urban') type (param=ref ref='Under') veh_age (param=ref ref='LT1'); model num_claims = urbanicity type age veh_age / dist=poi link=log pscale type3; title 'Poisson Regression Model of Number of Claims Data with SE Adjustment'; run;
de la Desviación y Pearson Chi- Square son los mismos. Pero los escalados han cambiado. El parámetro de escala es la raíz cuadrada de 3.4170 Esta es la estimación del factor multiplicativo de dispersión Toma el valor 1 porque hemos seleccionado un parámetro de dispersión Chi-cuadrado de Pearson Los parámetros de estimación no cambian pero se han inflado los errores estándar La probabilidad de que el estimador sea significativo se decrece: ya no sobre estimamos la significación
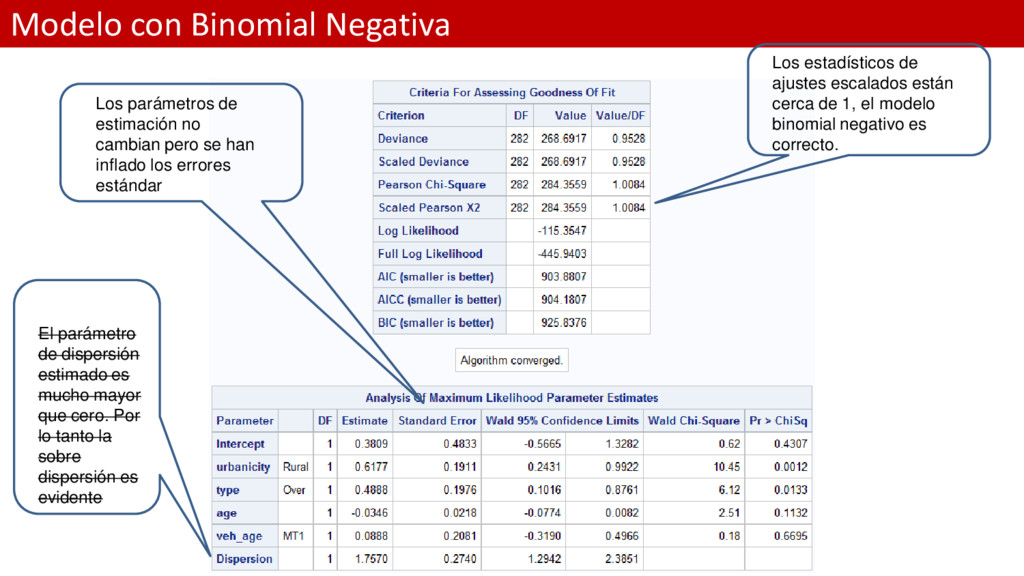
ref='Urban') type (param=ref ref='Under') veh_age (param=ref ref='LT1'); model num_claims = urbanicity type age veh_age / dist=nb link=log type3; estimate 'Rural vs. Urban Urbanicity' urbanicity 1; estimate 'Non-Under vs. Under' type 1; estimate 'MT1 vs. LT1' veh_age 1; estimate 'Age' age -1; title 'Negative Binomial Regression Model of Number of Claims Data'; run;
mucho mayor que cero. Por lo tanto la sobre dispersión es evidente Los estadísticos de ajustes escalados están cerca de 1, el modelo binomial negativo es correcto. Los parámetros de estimación no cambian pero se han inflado los errores estándar
data set contains information on 287 observations about moped coverage. Note: to create the dataset run the first step of the code called count_reg.sas Varible Definition num_claims number of claims (moped - yer) urbanicity rural or urban Type over or under 60 kg age age of the driver veh_age LT1, les than a year. MT1, more than a year
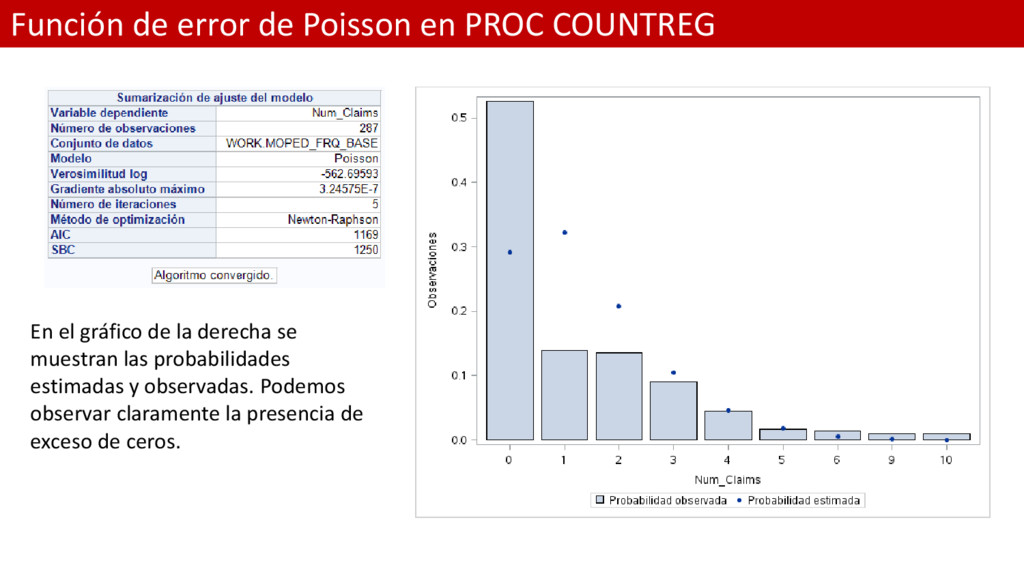
el procedimiento COUNTREG que pertenece al módulo SAS / ETS para analizar de nuevo el conjunto de datos moped_frq_base.sas7bdat • En ocasiones podemos encontrar tanto evidencias de sobre dispersión como evidencias de exceso de ceros en nuestros datos. En ésta práctica vamos a mostrar cómo en éste conjunto de datos encontramos evidencias de ambos efectos. • Además, en ésta práctica vamos a responder a la pregunta ¿Cuándo encontramos evidencias de excesos de ceros? • El procedimiento PROC COUNTREG es capaz calcular directamente la estimación de las probabilidades de tener 0, 1, 2, ..., 10 siniestros para cada observación. Gracias a ésta característica podremos mostrar con claridad cuándo existen excesos de ceros por medio del contraste entre la probabilidad empírica y la predicha por el modelo. Para ello usamos la siguiente sentencia: output out=predpoi probcount(0 to 10); Para saber más: http://support.sas.com/kb/26/161.html
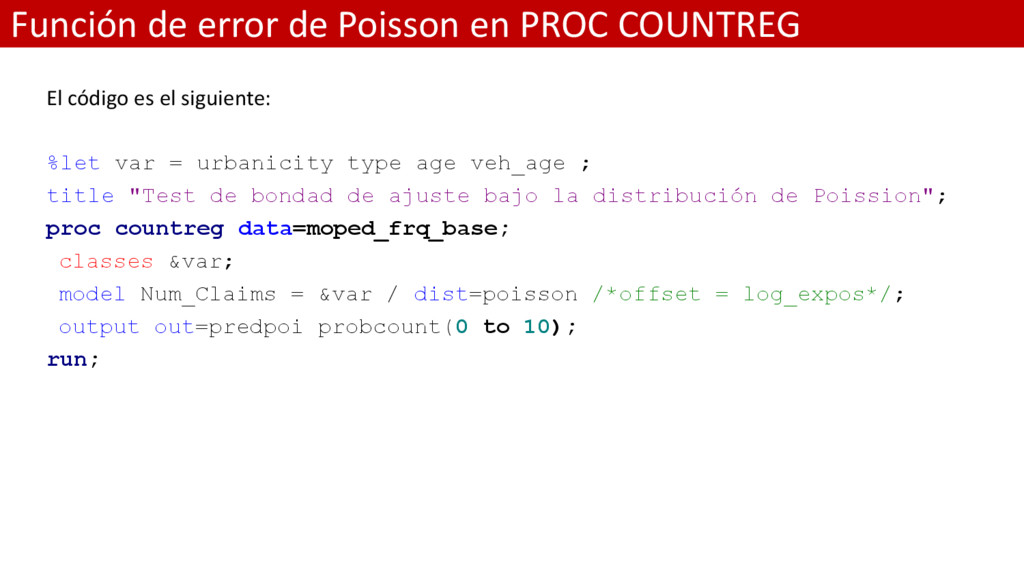
es el siguiente: %let var = urbanicity type age veh_age ; title "Test de bondad de ajuste bajo la distribución de Poission"; proc countreg data=moped_frq_base; classes &var; model Num_Claims = &var / dist=poisson /*offset = log_expos*/; output out=predpoi probcount(0 to 10); run;
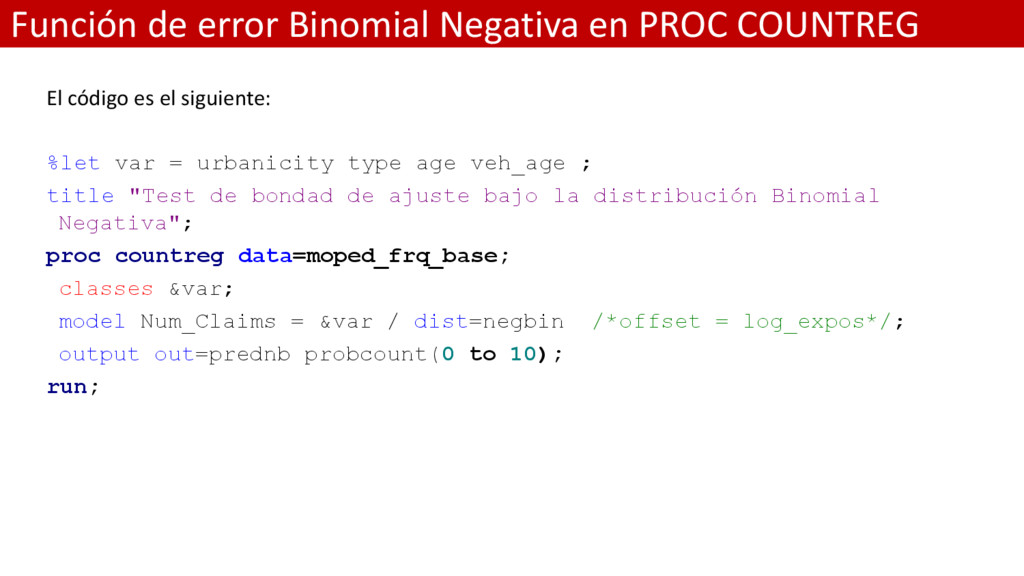
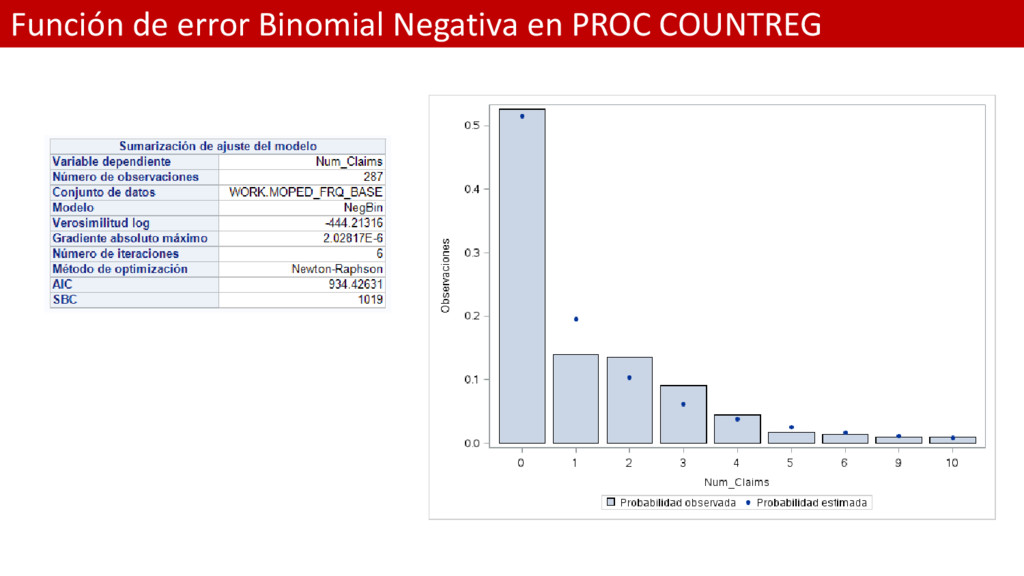
es el siguiente: %let var = urbanicity type age veh_age ; title "Test de bondad de ajuste bajo la distribución Binomial Negativa"; proc countreg data=moped_frq_base; classes &var; model Num_Claims = &var / dist=negbin /*offset = log_expos*/; output out=prednb probcount(0 to 10); run;
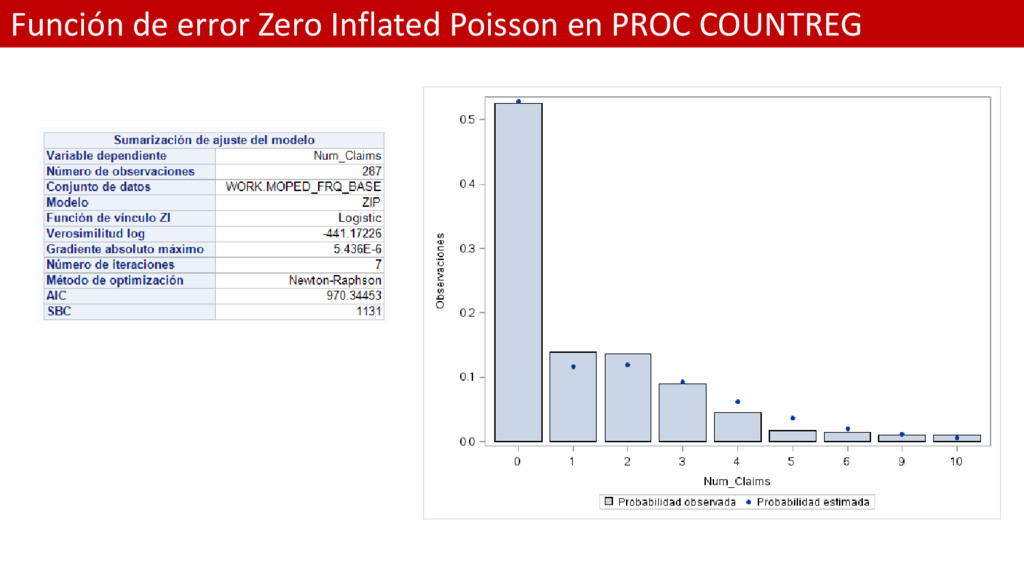
El código es el siguiente: /*el símobolo ~ se consigue apretando la tecla ALT de la izquierda del teclado y en el teclado numérico se escribe 126 y se suelta la tecla ALT*/ title "Test de bondad de ajuste bajo la distribución Poisson con exceso de ceros"; proc countreg data=moped_frq_base; classes &var; model Num_Claims = &var / dist=zip /*offset = log_expos*/; zeromodel Num_Claims ~ &var; output out=predzip probcount(0 to 10); run;
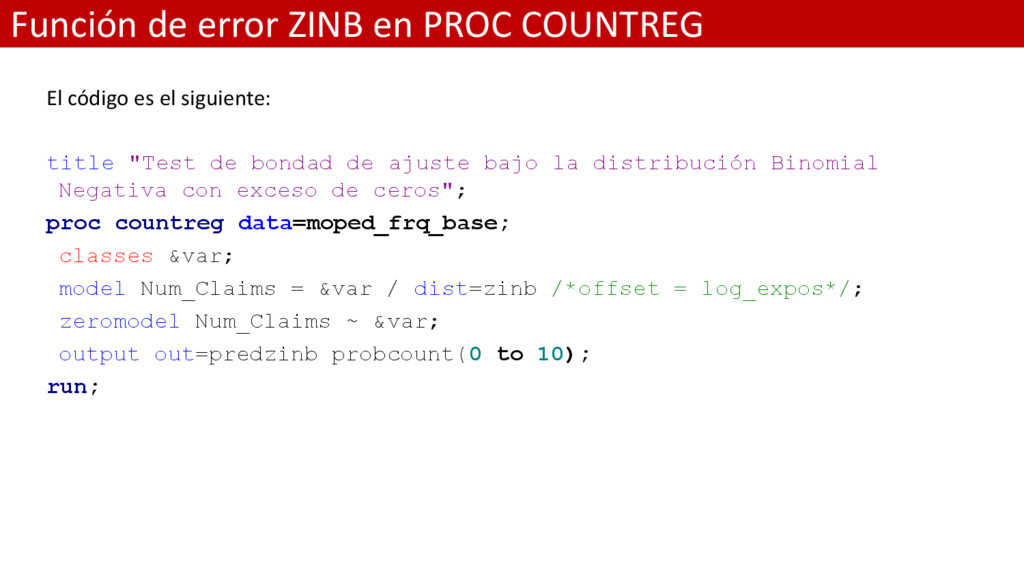
el siguiente: title "Test de bondad de ajuste bajo la distribución Binomial Negativa con exceso de ceros"; proc countreg data=moped_frq_base; classes &var; model Num_Claims = &var / dist=zinb /*offset = log_expos*/; zeromodel Num_Claims ~ &var; output out=predzinb probcount(0 to 10); run;
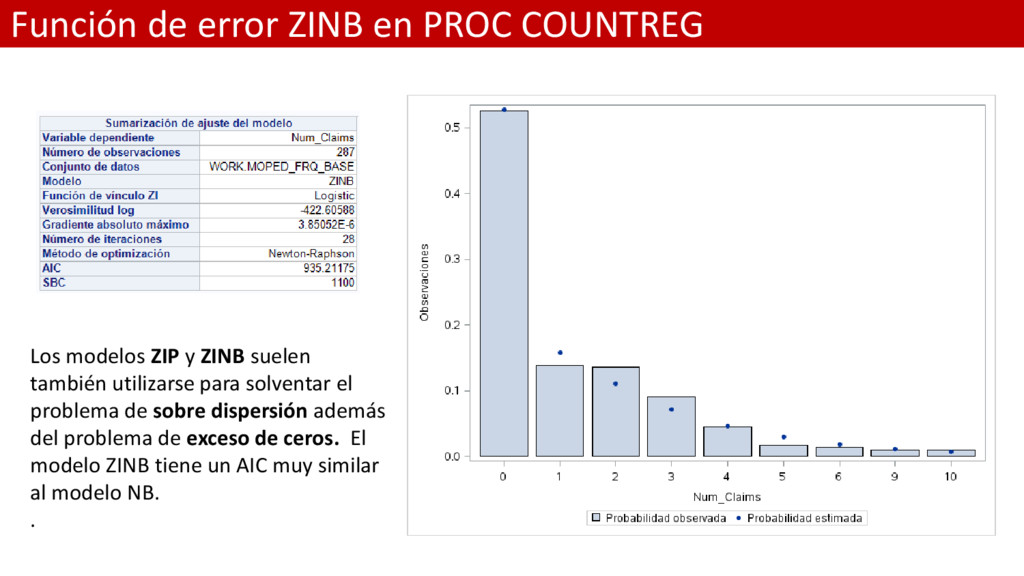
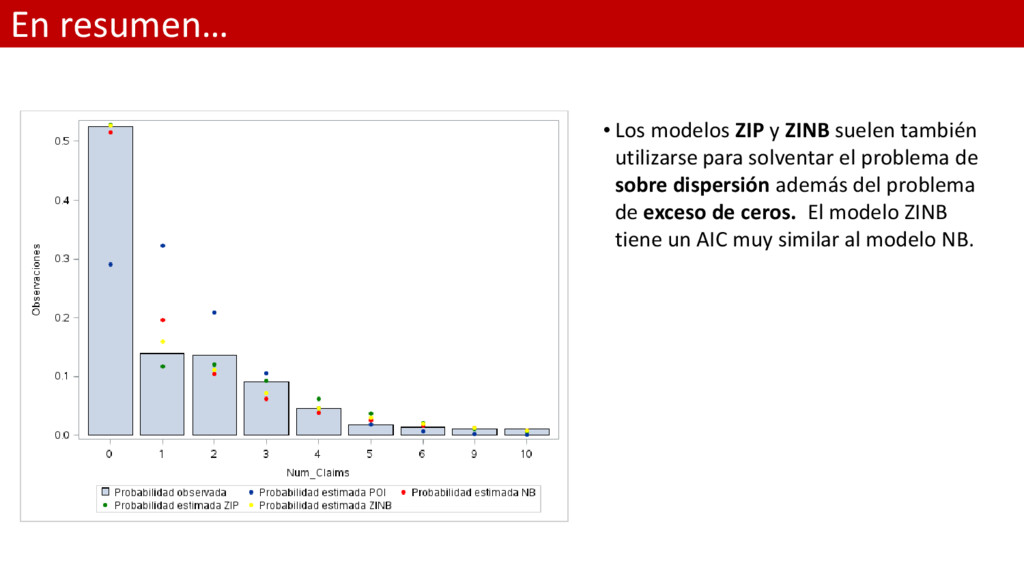
y ZINB suelen también utilizarse para solventar el problema de sobre dispersión además del problema de exceso de ceros. El modelo ZINB tiene un AIC muy similar al modelo NB. .
utilizarse para solventar el problema de sobre dispersión además del problema de exceso de ceros. El modelo ZINB tiene un AIC muy similar al modelo NB.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}