metal servers ▪ Around 650 VMs (2/3 VMWare and remaining running on KVM) ▪ Orchestration of 100 Docker containers a day ▪ Diverged Operating Systems ▪ Hosting HA services like Artifactory and Graylog (central logging) ▪ Continuous Build and Integration infrastructure for Dynatrace products
„nice“ hand-picked name • Setup and configuration done manually • Knowledge distributed across individuals, but not necessarily shared! • Hidden and/or unknown configuration settings • Classical Snowflake Servers see https://martinfowler.com/bliki/SnowflakeServer.html
hosts for virtual machines ▪ (Hot) Cloning VMs ▪ Multi Purpose Servers ▪ Why is that file or directory there? ▪ Is this folder/file still needed? The dark Middle Ages – Part II
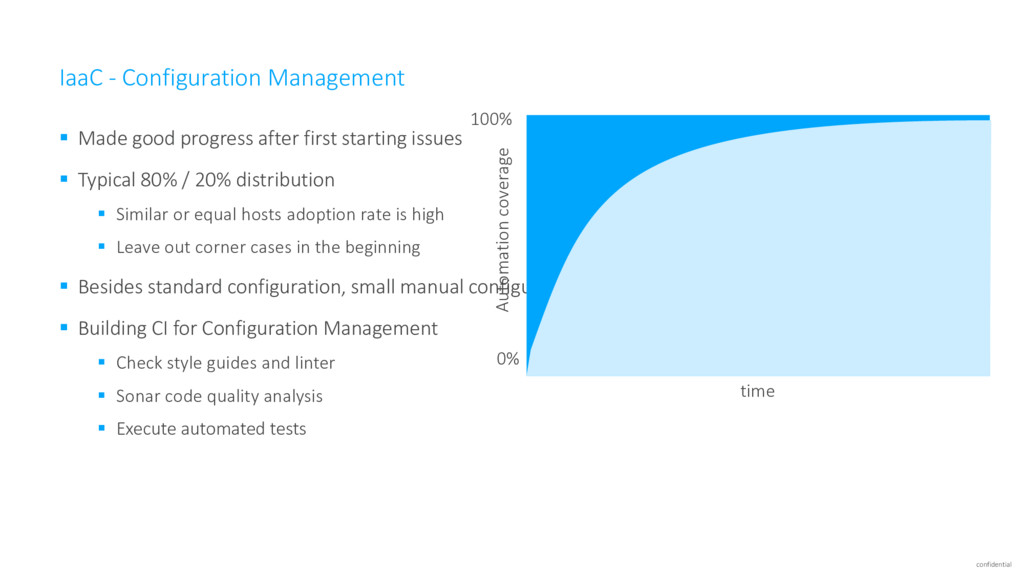
first starting issues ▪ Typical 80% / 20% distribution ▪ Similar or equal hosts adoption rate is high ▪ Leave out corner cases in the beginning ▪ Besides standard configuration, small manual configuration ▪ Building CI for Configuration Management ▪ Check style guides and linter ▪ Sonar code quality analysis ▪ Execute automated tests time 100% 0% Automation coverage
on long running servers ▪ One is not able to manage all files on a Server ▪ Builds or tests damage the server (even unintendedly) ▪ Snapshots reset state of VMs (e.q. for installer tests) ▪ Limited set of VMs – how to run more tests in parallel?
templates fully automated ▪ Documentation of system is implicitly done in Code ▪ Replace VMs on a regular basis - even „no“ change is done ▪ Project „Atomic“ is providing a similar approach
images provide perfect Immutable Images (when done right!) ▪ Serverless adoption is moving 10x faster than Container adoption http://blog.spotinst.com/2017/05/01/spotinsts-ceo-takeouts-serverlessconf-2017/ ▪ New offerings like Function as a Service (FaaS) are emerging Even for on-premises hosting (e.q. OpenWhisk) ▪ Hype Driven Development (HDD) https://blog.daftcode.pl/hype-driven-development-3469fc2e9b22?gi=291295a3617e
with snapshotting ▪ EC2 to run instances ▪ Launch Configurations compose different disks and instance types ▪ Auto Scaling Groups Start / terminate instances based on LCs ▪ Cloud Watch for alarming and triggers for ASG ▪ Route53 latency and availability based DNS resolution
via CI pipelines ▪ Create Base Image ▪ Create static website contents ▪ Validate contents ▪ Local tests in static site generation ▪ Sanity checks (also on PRs) ▪ Check for viruses before uploading ▪ Deployment needs to be idempotent
(script) for different deployment targets (dev, staging and production) ▪ At least one prod-deployment during working days ▪ Deploy to a new region? Just one configuration parameter! ▪ Automation is not done for main Route53 entries
▪ Host Intrusion Detection System ▪ Binary identical images in dev, staging and production ▪ Uninstall unneeded or even dangerous packages ▪ Each login is being considered a security breach Immediate alarm is being created ▪ Centralized logging with Sumologic
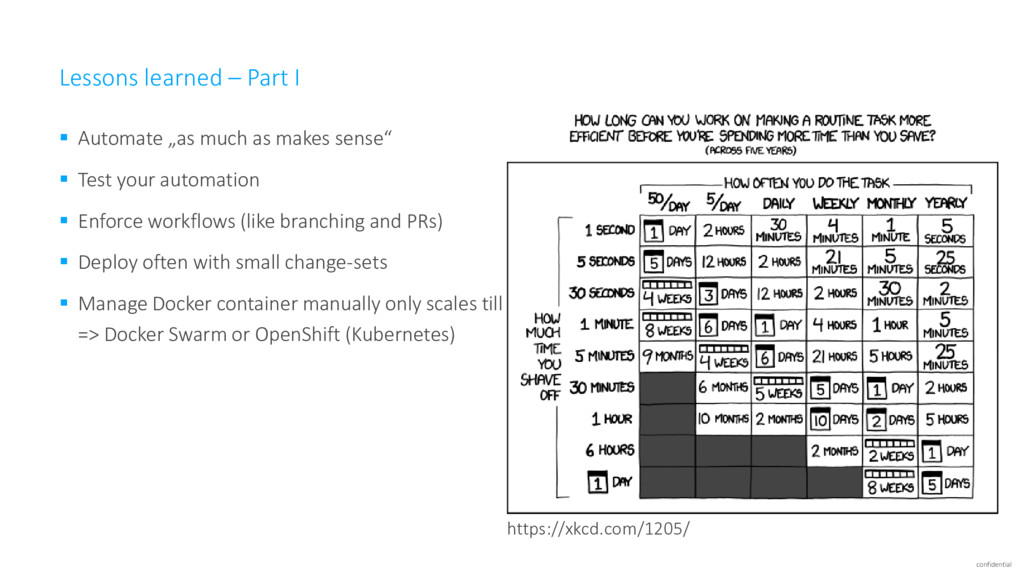
as makes sense“ ▪ Test your automation ▪ Enforce workflows (like branching and PRs) ▪ Deploy often with small change-sets ▪ Manage Docker container manually only scales till roughly 20 – 30 containers => Docker Swarm or OpenShift (Kubernetes) https://xkcd.com/1205/
the first step Lessons learned – Part II ▪ You want to have robust builds ▪ Old or cutting edge answer files are hard to find (like Windows 10 Creators Update) ▪ Repositories for older versions tend to disappear (local copy)
Tooling ▪ Git (BitBucket for Pull-Requests and CI triggers) ▪ Central Build Server with Pipeline Support ▪ Gradle for handling the builds ▪ Configuration Management ▪ Puppet for all continous checks / configuration applying ▪ Ansible for Ad-Hoc deployment or update of distributed environments ▪ Immutable Images ▪ Packer from Hashicorp ▪ Qemu to build KVM machines ▪ Vmware workstation (for building VMWare templates)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}