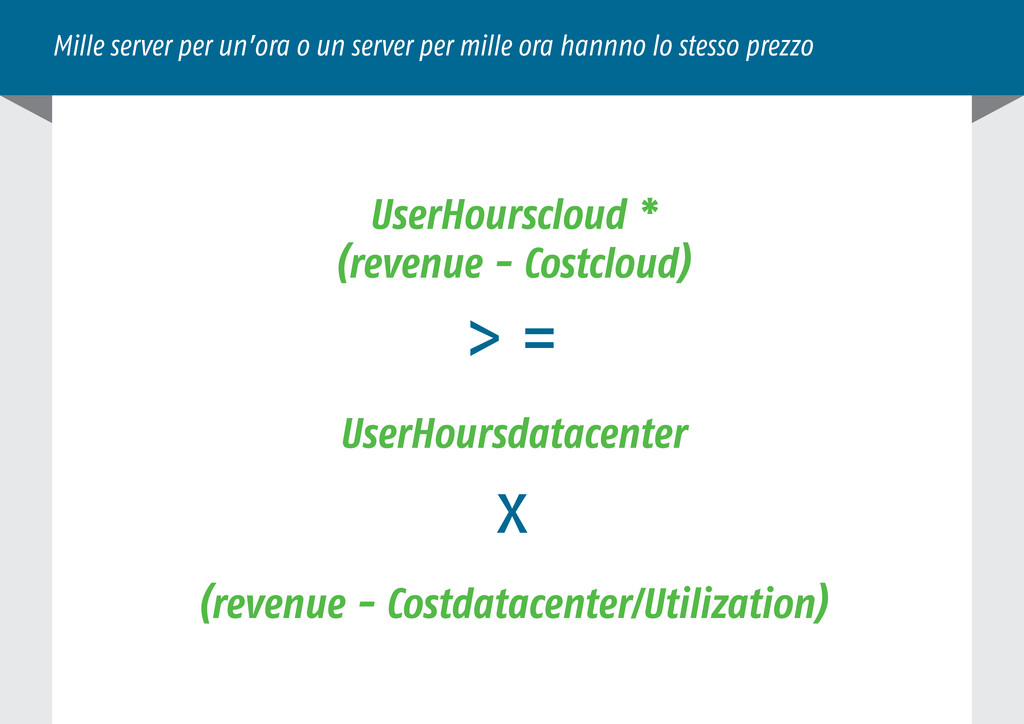
A Berkeley View of Cloud Computing 3. Mille server per un’ora o un server per mille ore hannno lo stesso prezzo 4. Scalabilità? 5. Iaas Pass Saas Nass, what?! *as a service* 6. Cosa mi serve? Analisi dei requisiti 7. Perché scalare presto è sbagliato 8. Non-sense optimization 9. Una questione di design 10. L’importanza della cache 11. Trovare i colli di bottiglia 12. Cloud9 - Case History (presente) 13. Cloud9 - Case History (futuro) 14. Il mondo asincrono 15. Kred - Case history (1) 16. Kred - Case history (2) 17. Cosa vuole il cliente? 18. Q/A
22. Test test test 23. Monitoraggio attivo 24. Prevenire è meglio che curare 25. Datadog demo 26. Data Driven Business Rules 27. AWS Demo 28. Q/A 29. Discussione aperta 30. Ringraziamenti
gestire i picchi di carico Aggiunta di risorse a caldo API Migrazione fra server fisici Decentralizzazione High Availability Provisioning Facilità di manutenzione Sai davvero cos'è il cloud?
• The elimination of an up-front commitment by Cloud users • The ability to pay for use of computing resources ona short-term basis as needed Above the Clouds: A Berkeley View of Cloud Computing
• Non è importante il numero di utenti che avete, ma il numero contemporaneo degli stessi. 100k utenti al giorno se ben distribuiti sono solo 666 utenti/s (bastano 2/3 server) • 100k utenti in 1s richiedono circa 300 server... Perché scalare presto è sbagliato
su un server separato Es. “apache + mod_proxy_balancer + mod_php” Vs “haproxy + nginx + phpfpm” Separazione dei layer applicativi • Creazione delle code • Distribuzione del carico Una questione di design
• Rete gigabit • SSD disk • RAID su dischi “normali” • Backup dei dati interessanti • RabbitMQ per processare i dati (20 server di backend) • KVM Kred - Case history
monitoring senza alert • Non c’è alert senza intervento (manuale o automatizzato) • Se ignori un alert esso è sbagliato (evitate il rumore) Monitoraggio attivo
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Luca Cipriani contatti: [email protected] @mastrolinux](https://files.speakerdeck.com/presentations/6ffa112071e10130970422000a95005c/slide_64.jpg){kind=link}
{kind=link}