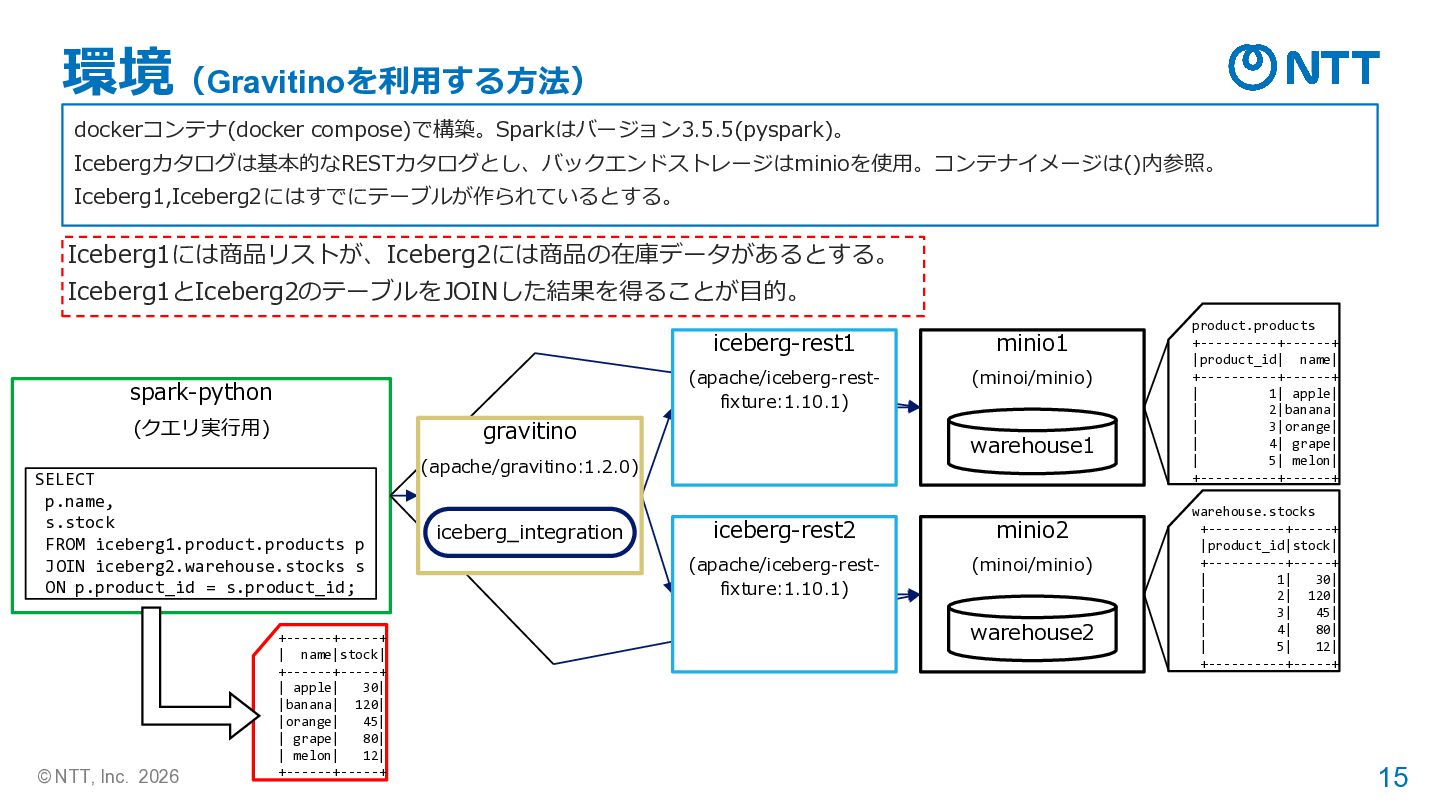
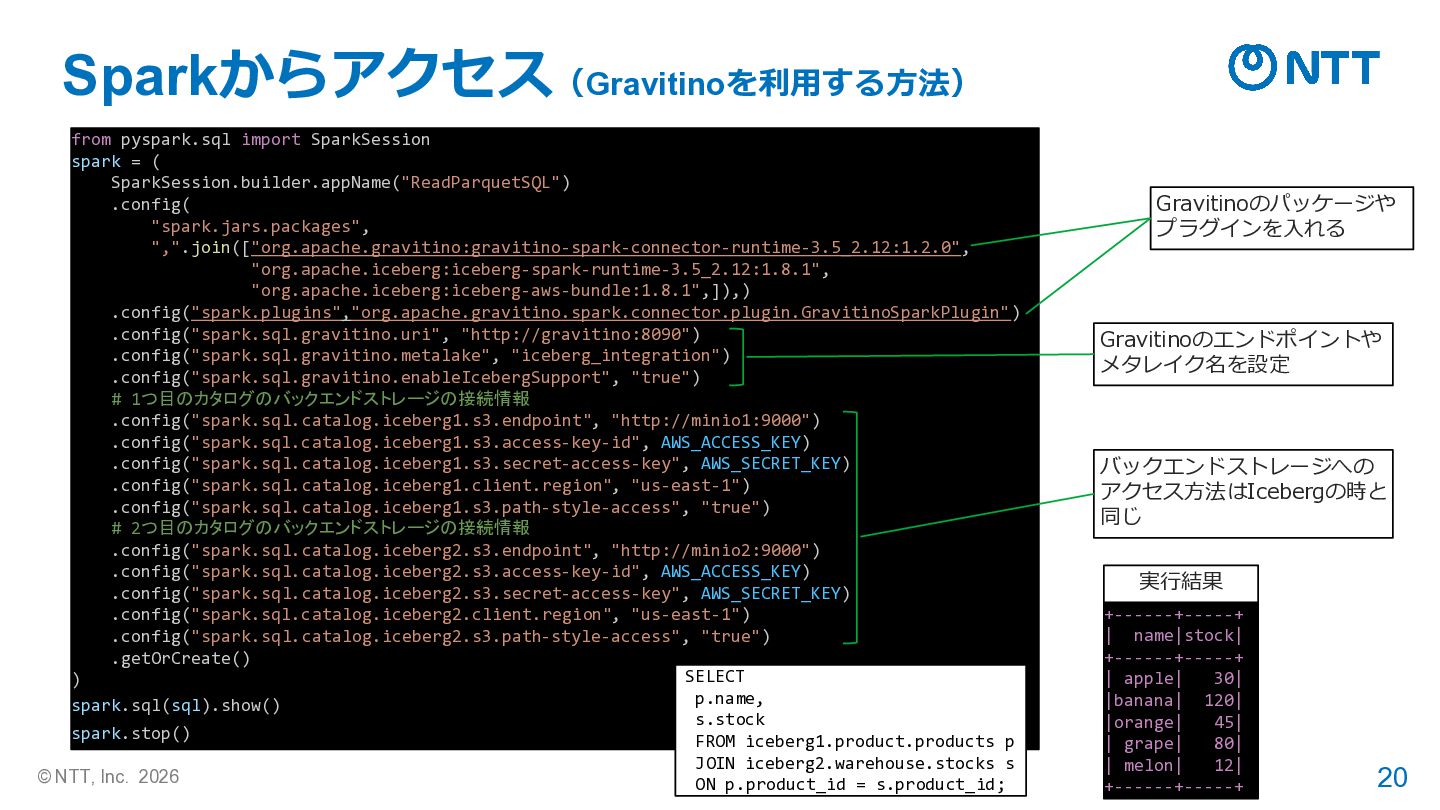
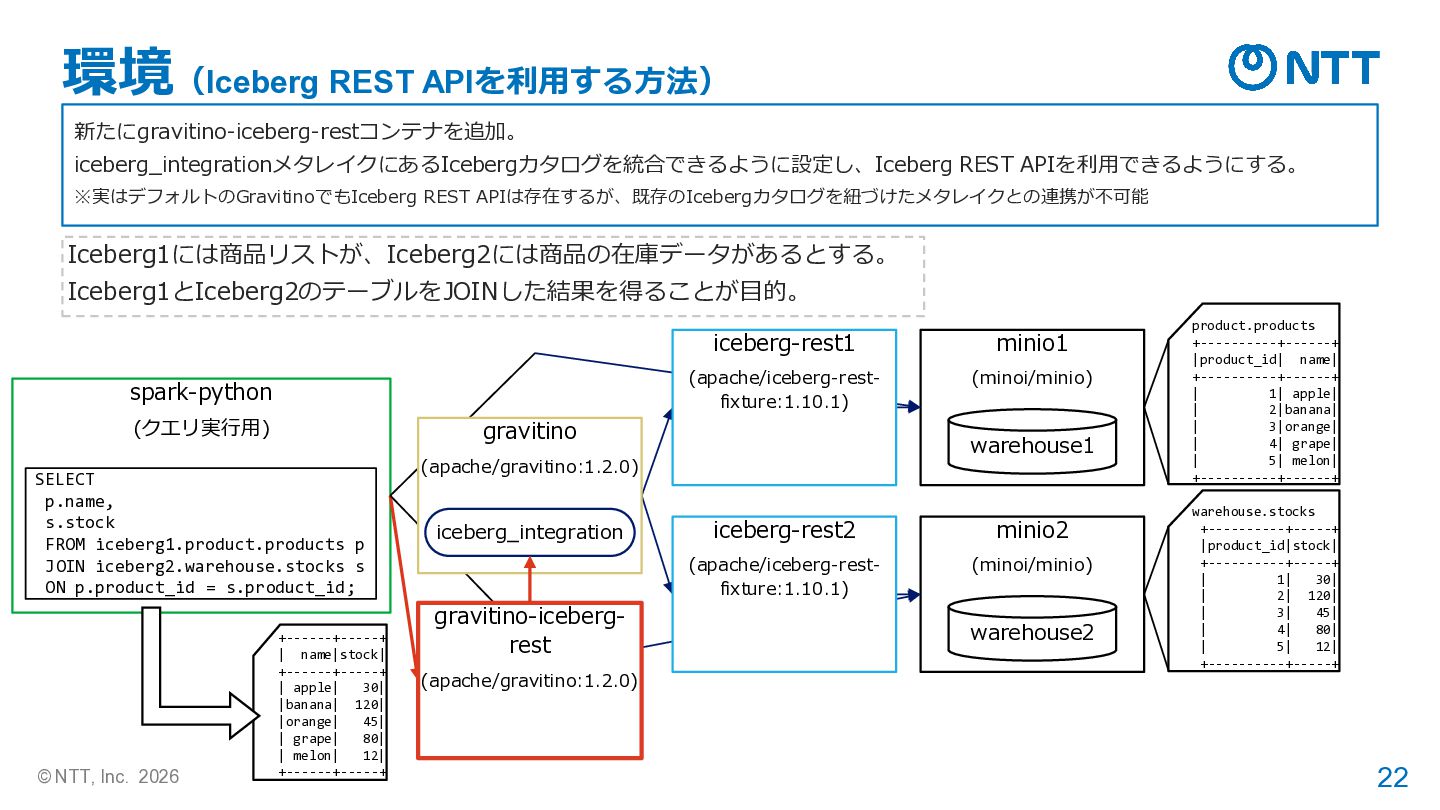
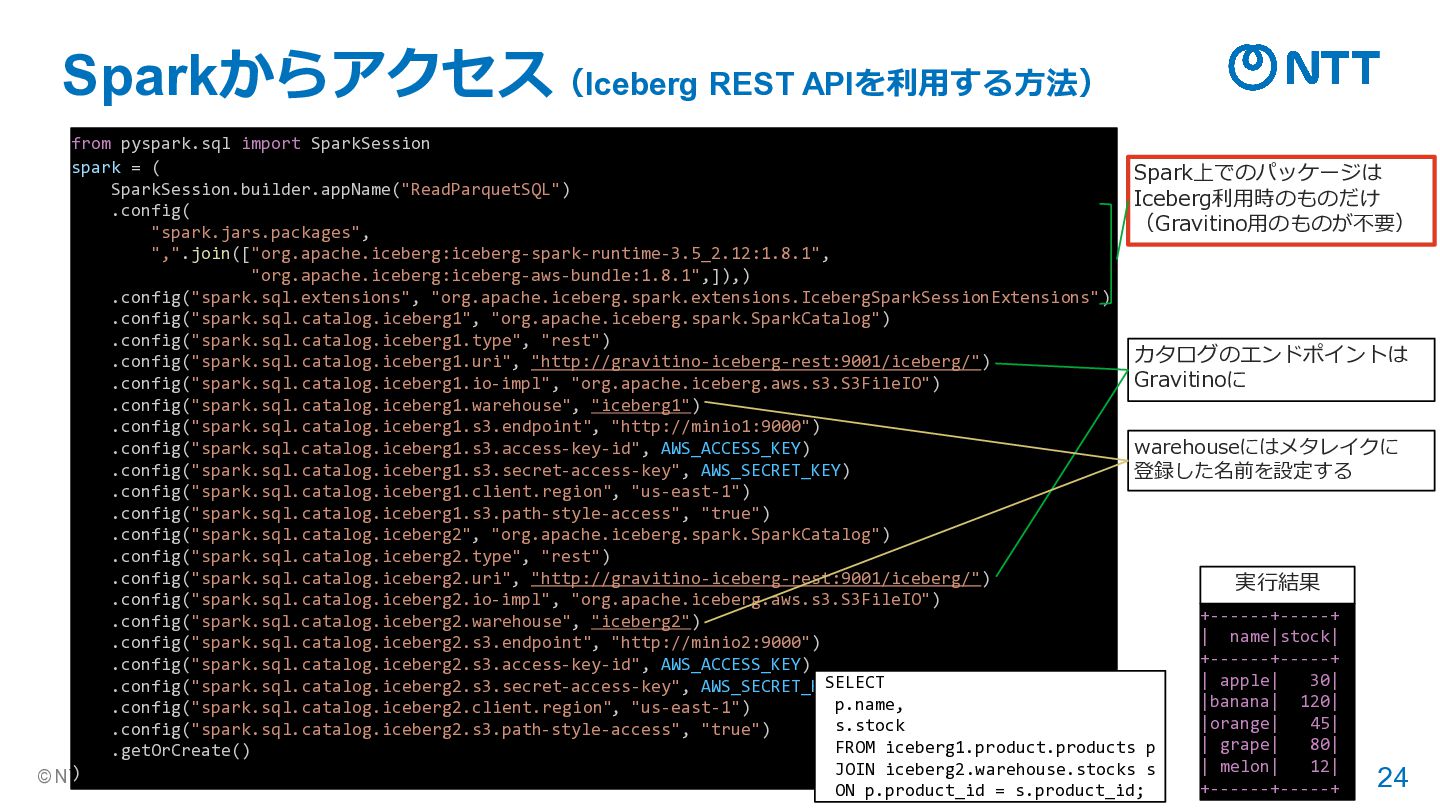
= ( SparkSession.builder.appName("ReadParquetSQL") .config( "spark.jars.packages", ",".join(["org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.8.1", "org.apache.iceberg:iceberg-aws-bundle:1.8.1",]),) .config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") .config("spark.sql.catalog.iceberg1", "org.apache.iceberg.spark.SparkCatalog") .config("spark.sql.catalog.iceberg1.type", "rest") .config("spark.sql.catalog.iceberg1.uri", "http://gravitino-iceberg-rest:9001/iceberg/") .config("spark.sql.catalog.iceberg1.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") .config("spark.sql.catalog.iceberg1.warehouse", "iceberg1") .config("spark.sql.catalog.iceberg1.s3.endpoint", "http://minio1:9000") .config("spark.sql.catalog.iceberg1.s3.access-key-id", AWS_ACCESS_KEY) .config("spark.sql.catalog.iceberg1.s3.secret-access-key", AWS_SECRET_KEY) .config("spark.sql.catalog.iceberg1.client.region", "us-east-1") .config("spark.sql.catalog.iceberg1.s3.path-style-access", "true") .config("spark.sql.catalog.iceberg2", "org.apache.iceberg.spark.SparkCatalog") .config("spark.sql.catalog.iceberg2.type", "rest") .config("spark.sql.catalog.iceberg2.uri", "http://gravitino-iceberg-rest:9001/iceberg/") .config("spark.sql.catalog.iceberg2.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") .config("spark.sql.catalog.iceberg2.warehouse", "iceberg2") .config("spark.sql.catalog.iceberg2.s3.endpoint", "http://minio2:9000") .config("spark.sql.catalog.iceberg2.s3.access-key-id", AWS_ACCESS_KEY) .config("spark.sql.catalog.iceberg2.s3.secret-access-key", AWS_SECRET_KEY) .config("spark.sql.catalog.iceberg2.client.region", "us-east-1") .config("spark.sql.catalog.iceberg2.s3.path-style-access", "true") .getOrCreate() ) Sparkからアクセス(Iceberg REST APIを利用する方法) Spark上でのパッケージは Iceberg利用時のものだけ (Gravitino用のものが不要) カタログのエンドポイントは Gravitinoに warehouseにはメタレイクに 登録した名前を設定する +------+-----+ | name|stock| +------+-----+ | apple| 30| |banana| 120| |orange| 45| | grape| 80| | melon| 12| +------+-----+ 実行結果 SELECT p.name, s.stock FROM iceberg1.product.products p JOIN iceberg2.warehouse.stocks s ON p.product_id = s.product_id;
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
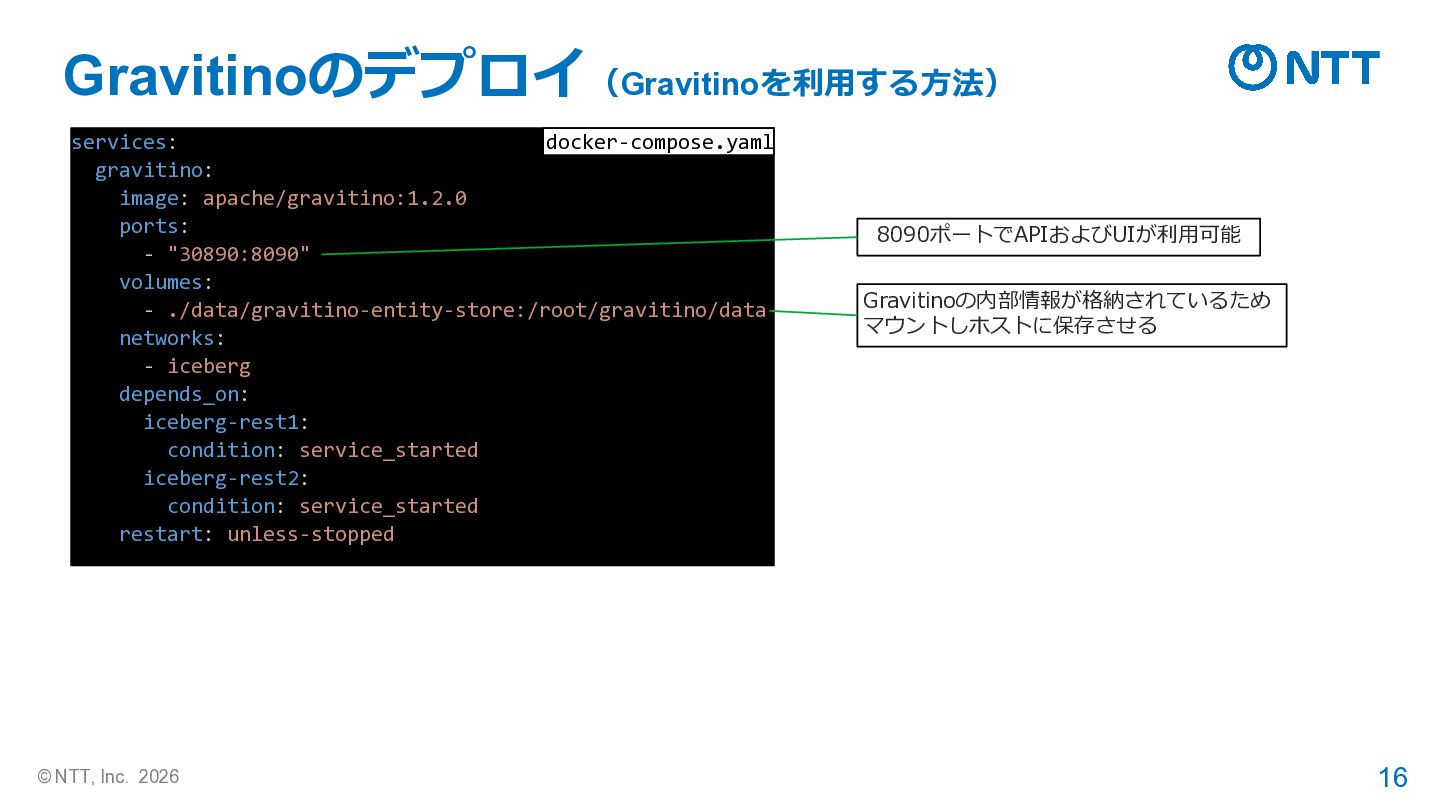{kind=link}
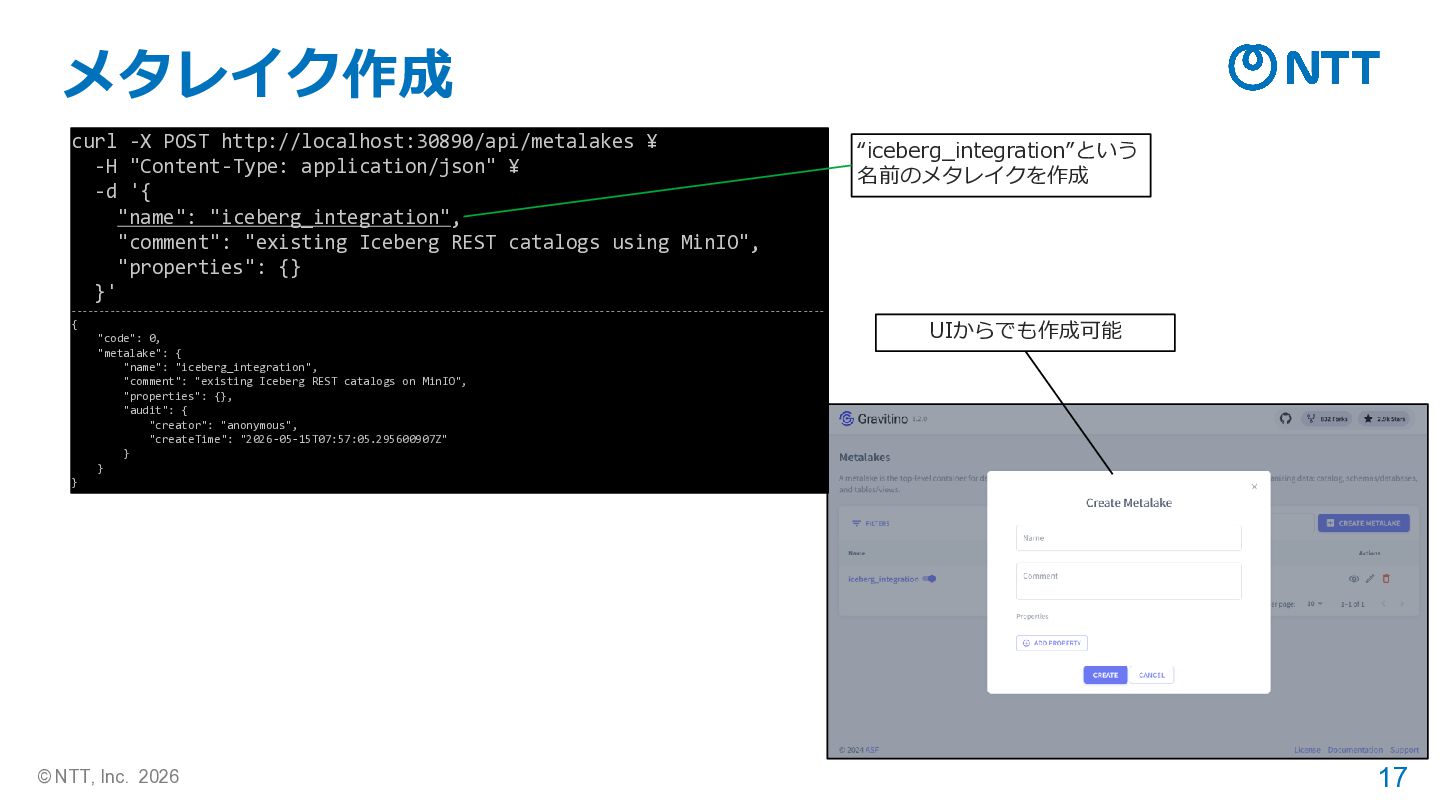{kind=link}
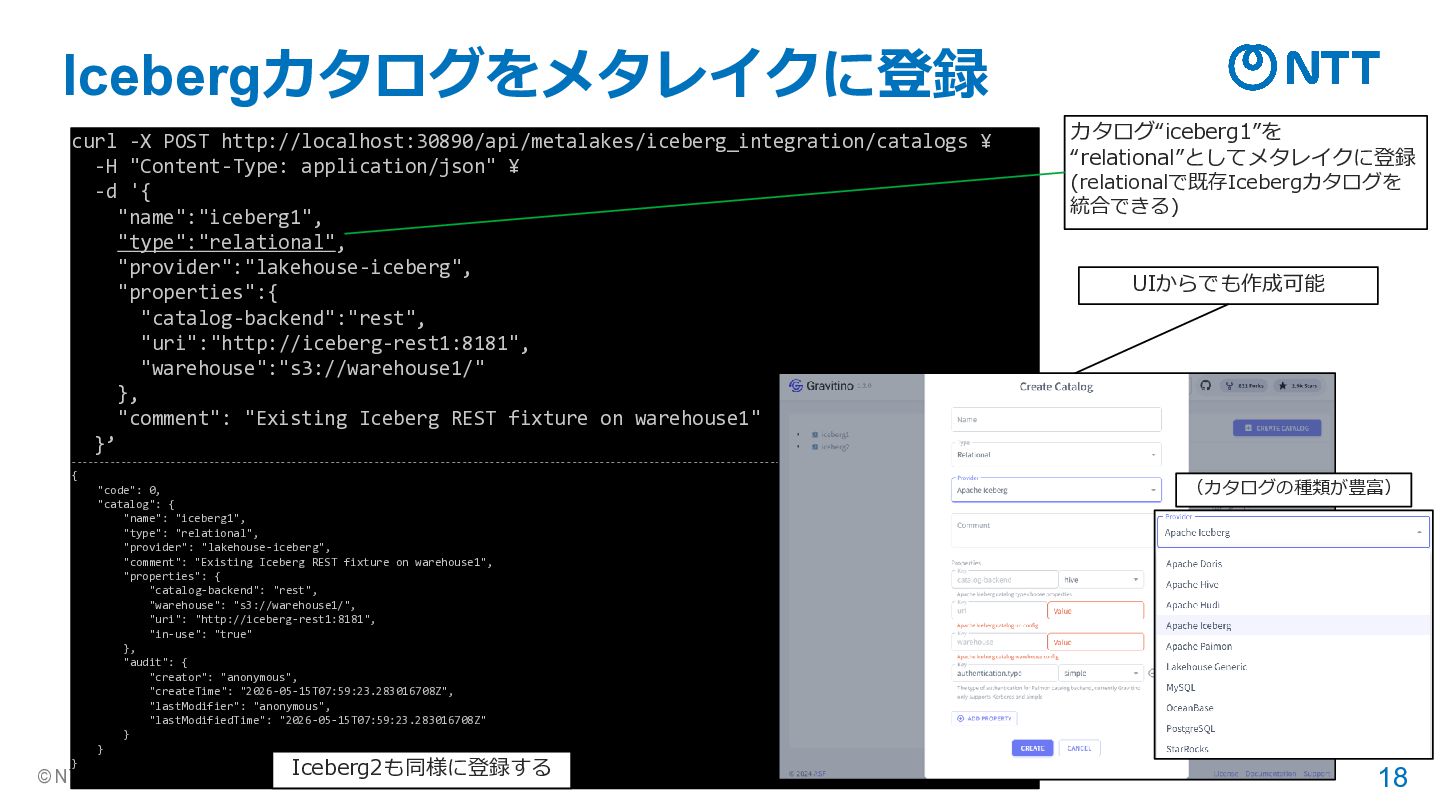{kind=link}
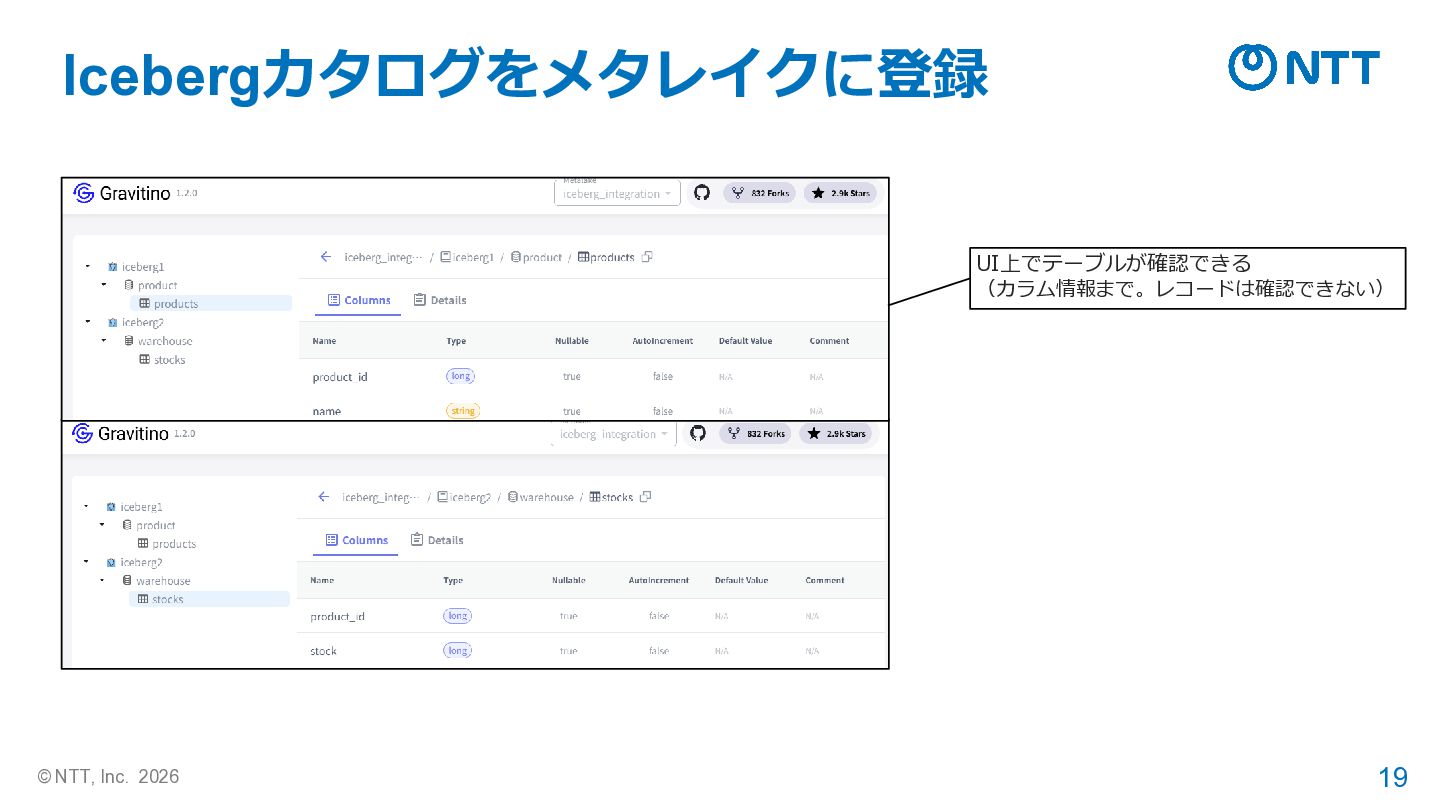{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}