Upgrade to Pro
— share decks privately, control downloads, hide ads and more …
Speaker Deck
Features
Speaker Deck
PRO
Sign in
Sign up for free
Search
Search
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diff...
Search
Kento Sasaki
February 08, 2026
Research
660
0
Share
Embed
Copy iframe code
Copy JS code
Copy link
Start on current slide
第66回コンピュータビジョン勉強会@関東 Epona: Autoregressive Diffusion World Model for Autonomous Driving
Kento Sasaki
February 08, 2026
More Decks by Kento Sasaki
See All by Kento Sasaki
大規模言語モデルを用いた日本語視覚言語モデルの評価方法とベースラインモデルの提案 【MIRU 2024】
kentosasaki
3
850
Generative Predictive Model for Autonomous Driving 第61回 コンピュータビジョン勉強会@関東 (後編)
kentosasaki
0
390
Other Decks in Research
See All in Research
論文紹介:HalluCitation Matters
wasyro
0
130
Vector Map as Language: Toward Unified Remote Sensing Vector Mapping
satai
3
110
AIを叩き台として、 「検証」から「共創」へと進化するリサーチ
mela_dayo
0
310
適応的スパムフィルタのための軽量な類似メッセージカウンタ / jsai2026-adaptive-spam-filter
monochromegane
0
4.5k
Spatial Active Noise Control Based on Sound Field Interpolation Incorporating Physical Constraints
skoyamalab
0
130
(SIGQS17) Frasco-VS:フラグメントに基づく薬剤候補化合物選抜の量子アニーリングによる実現
keisukeyanagisawa
PRO
0
170
nlp2026 In-Context Learningに基づく経路案内のための地理的知識の活用方法に関する検討
takashiinui
0
110
Harness Engineering and Al Agent
kzinmr
3
1.8k
AIエージェント時代のLLM-jpモデルのあるべき姿
k141303
0
520
2026年版中小企業白書・小規模企業白書の概要
ozekinote
0
120
衛星×エッジAI勉強会 衛星上におけるAI処理制約とそ取組について
satai
4
620
Unified Audio Source Separation (Defense Slides)
kohei_1979
1
630
Featured
See All Featured
Intergalactic Javascript Robots from Outer Space
tanoku
273
27k
Effective software design: The role of men in debugging patriarchy in IT @ Voxxed Days AMS
baasie
0
450
Building Adaptive Systems
keathley
44
3.1k
[RailsConf 2023] Rails as a piece of cake
palkan
59
6.8k
Done Done
chrislema
186
16k
Redefining SEO in the New Era of Traffic Generation
szymonslowik
1
370
SEOcharity - Dark patterns in SEO and UX: How to avoid them and build a more ethical web
sarafernandez
0
220
The Anti-SEO Checklist Checklist. Pubcon Cyber Week
ryanjones
0
190
The AI Revolution Will Not Be Monopolized: How open-source beats economies of scale, even for LLMs
inesmontani
PRO
3
3.6k
brightonSEO & MeasureFest 2025 - Christian Goodrich - Winning strategies for Black Friday CRO & PPC
cargoodrich
3
760
コードの90%をAIが書く世界で何が待っているのか / What awaits us in a world where 90% of the code is written by AI
rkaga
62
45k
Hiding What from Whom? A Critical Review of the History of Programming languages for Music
tomoyanonymous
3
1k
Transcript
第66回コンピュータビジョン勉強会@関東 世界モデル論文読み会 Kento Sasaki 紹介する論文: Epona: Autoregressive Diffusion World Model
for Autonomous Driving (Zhang+, ICCV 2025) Feb. 8, 2026
⾃⼰紹介 佐々木謙人 (Kento Sasaki) • Research Engineer @ Turing Inc.
(April 2023~) • X account: @kento_sasaki1 • 自動運転VLAモデルの研究開発 • ICLR 2026, AAAI 2026 (Oral), WACV 2025 (Oral) 1
紹介する論⽂ https://kevin-thu.github.io/Epona/ 2
過去のカメラ映像とそれに対応する⾛⾏軌跡(メタアクション)を与えたとき、 将来の⾛⾏ダイナミクスを予測する ⾃動運転世界モデルの問題設定 3
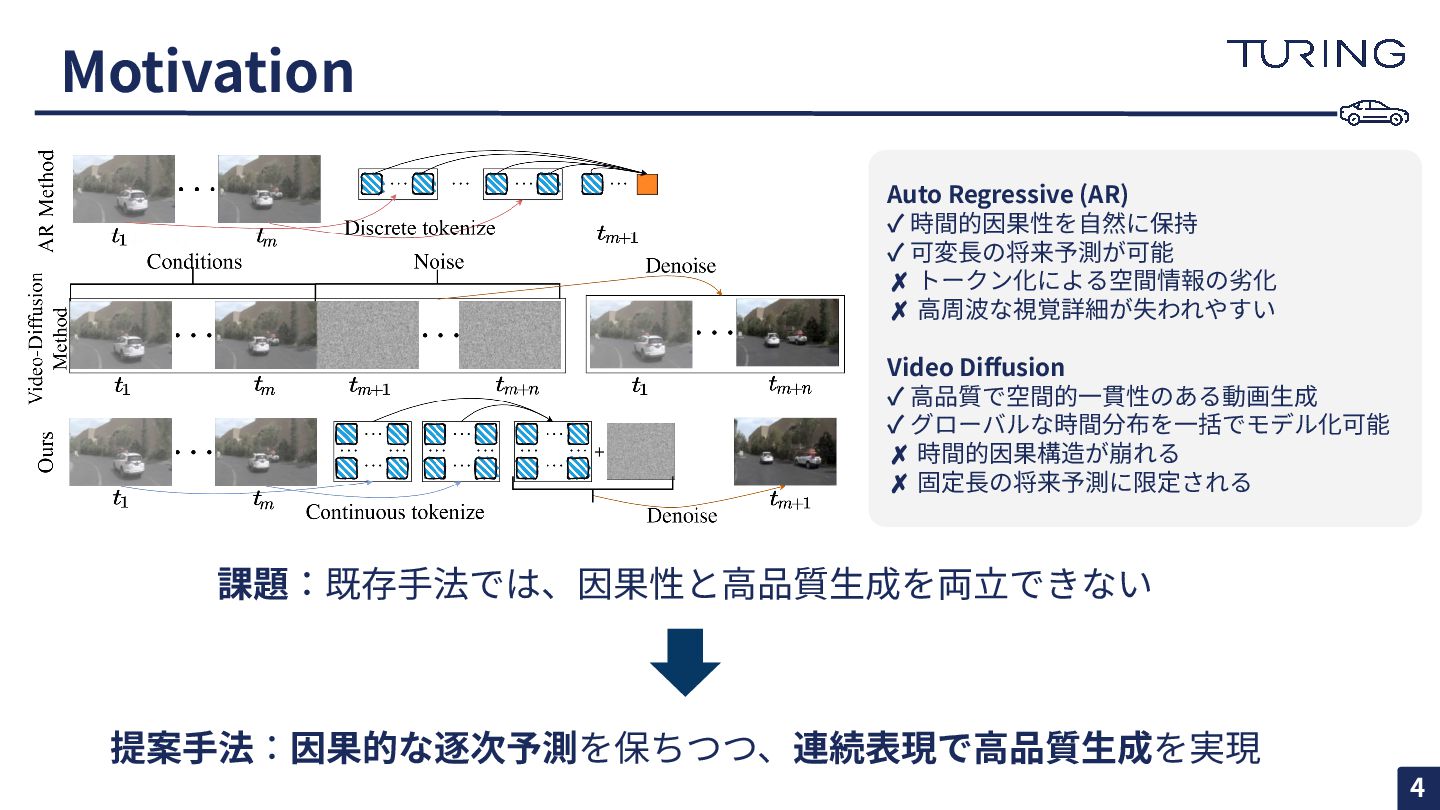
Motivation Auto Regressive (AR) ✓ 時間的因果性を⾃然に保持 ✓ 可変⻑の将来予測が可能 ✗ トークン化による空間情報の劣化
✗ ⾼周波な視覚詳細が失われやすい Video Diffusion ✓ ⾼品質で空間的⼀貫性のある動画⽣成 ✓ グローバルな時間分布を⼀括でモデル化可能 ✗ 時間的因果構造が崩れる ✗ 固定⻑の将来予測に限定される 課題:既存⼿法では、因果性と⾼品質⽣成を両⽴できない 提案⼿法:因果的な逐次予測を保ちつつ、連続表現で⾼品質⽣成を実現 4
Motivation 5
Method
Overview 6
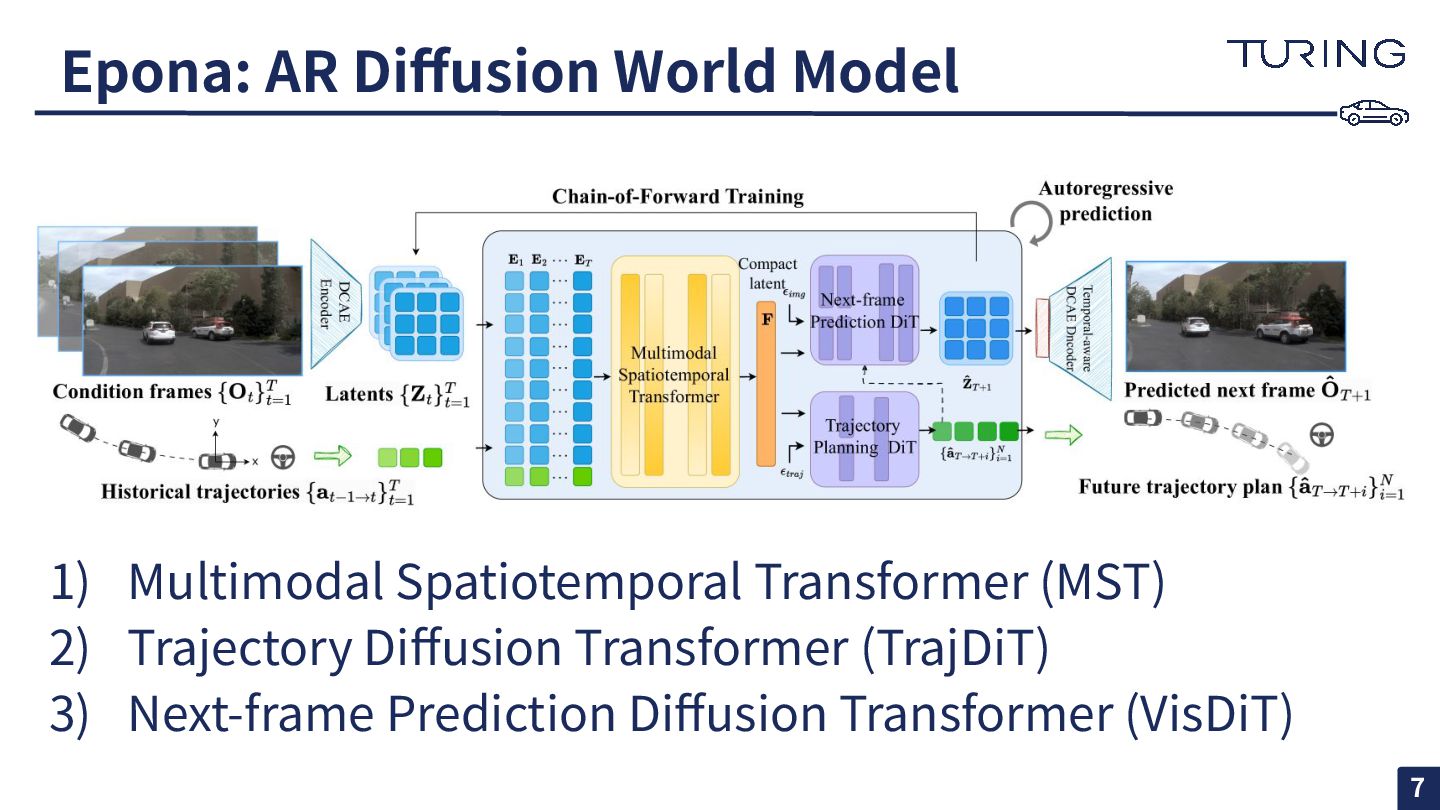
Epona: AR Diffusion World Model 1) Multimodal Spatiotemporal Transformer (MST)
2) Trajectory Diffusion Transformer (TrajDiT) 3) Next-frame Prediction Diffusion Transformer (VisDiT) 7
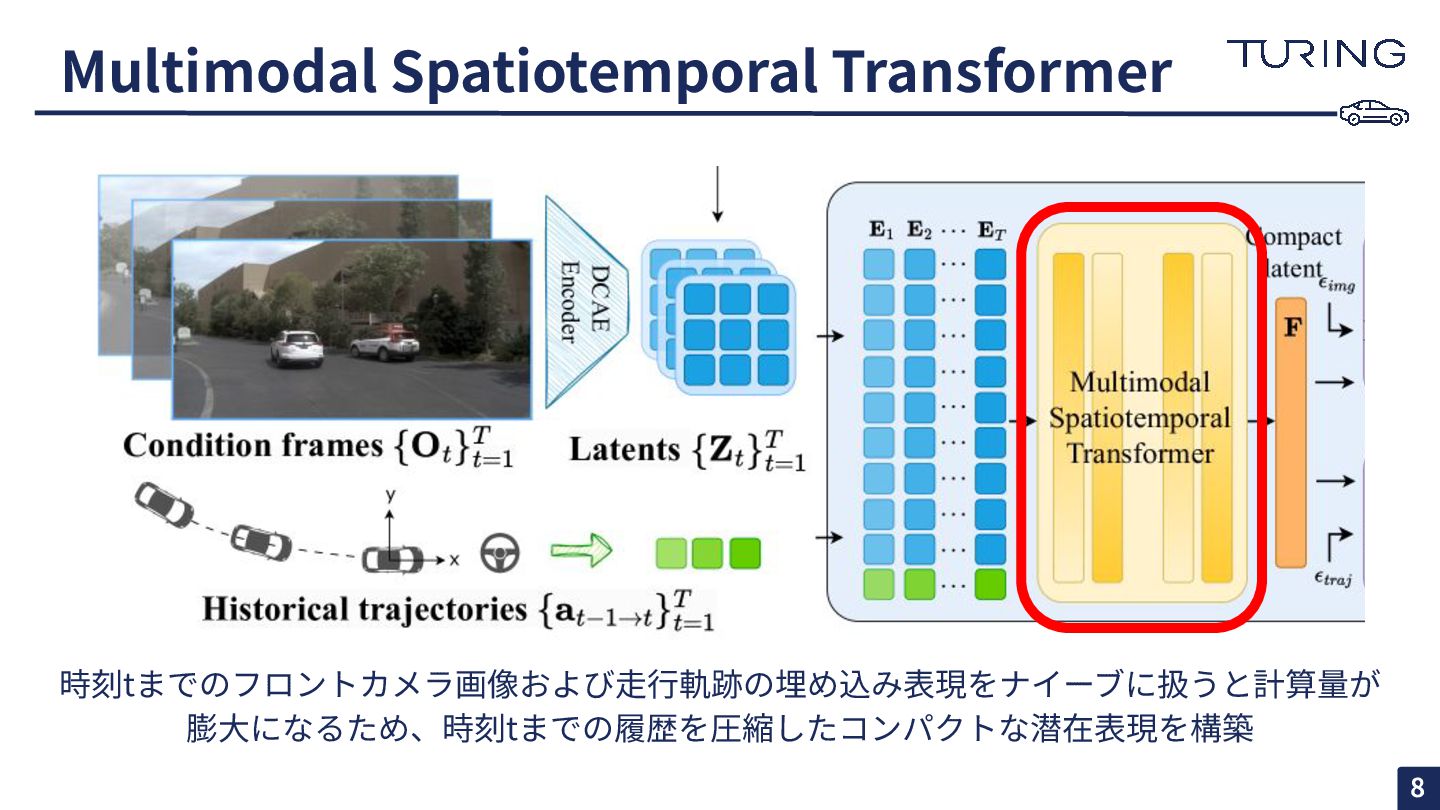
Multimodal Spatiotemporal Transformer 時刻tまでのフロントカメラ画像および⾛⾏軌跡の埋め込み表現をナイーブに扱うと計算量が 膨⼤になるため、時刻tまでの履歴を圧縮したコンパクトな潜在表現を構築 8
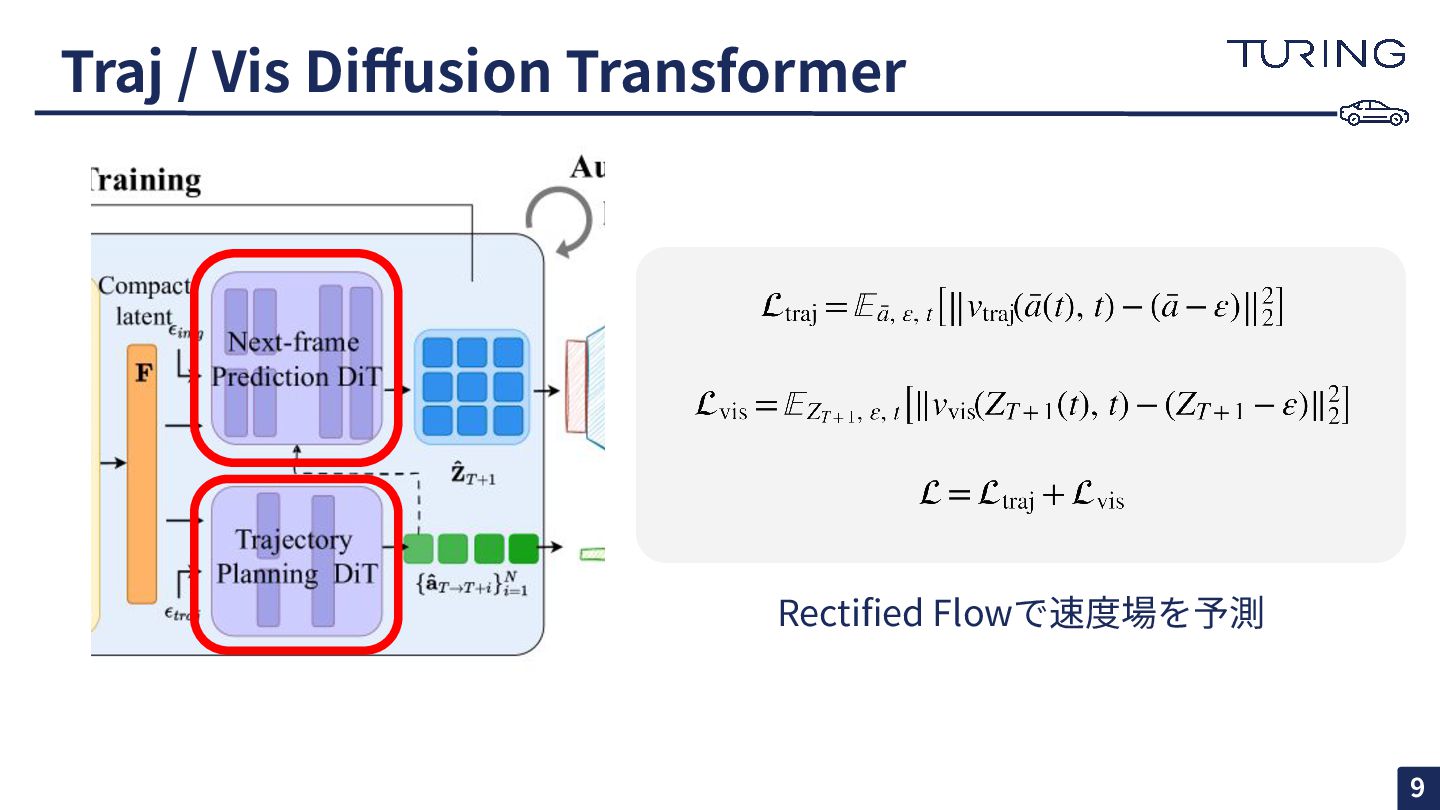
Traj / Vis Diffusion Transformer Rectified Flowで速度場を予測 9
Temporal-aware DCAE Decoder spatiotemporal self-attention層を追加 各フレームごとデコードすると フリッカーや時系列⽅向の不整合が⽣じるため、 フレーム間で情報共有したい DCAE (Deep
Compression AutoEncoder) x32のダウンサンプリングが可能な画像オートエンコーダ 10
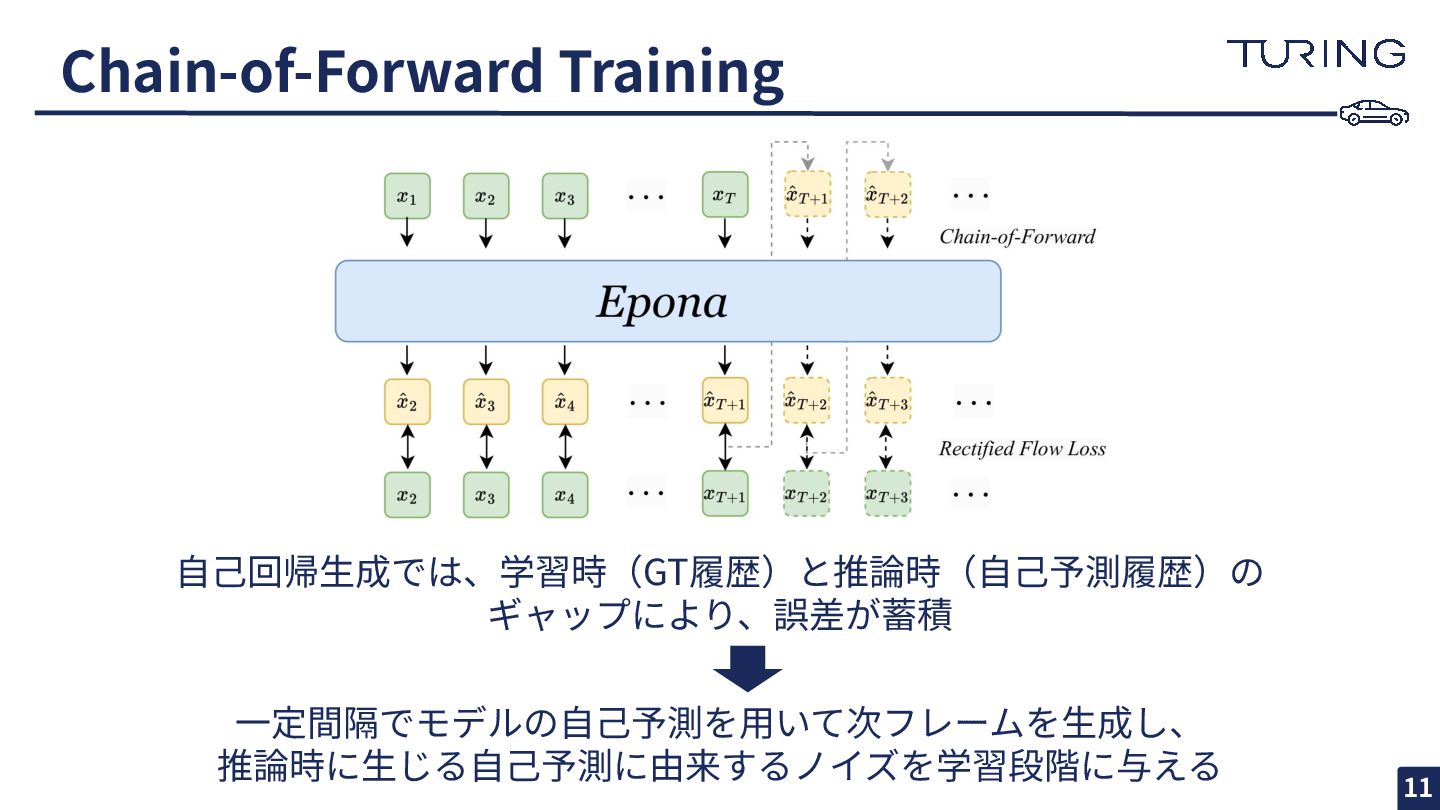
Chain-of-Forward Training ⾃⼰回帰⽣成では、学習時(GT履歴)と推論時(⾃⼰予測履歴)の ギャップにより、誤差が蓄積 ⼀定間隔でモデルの⾃⼰予測を⽤いて次フレームを⽣成し、 推論時に⽣じる⾃⼰予測に由来するノイズを学習段階に与える 11
Experiments
Model Size: 2.5B (MST: 1.3B, VisDiT: 1.2B, TrajDiT: 50M) Training
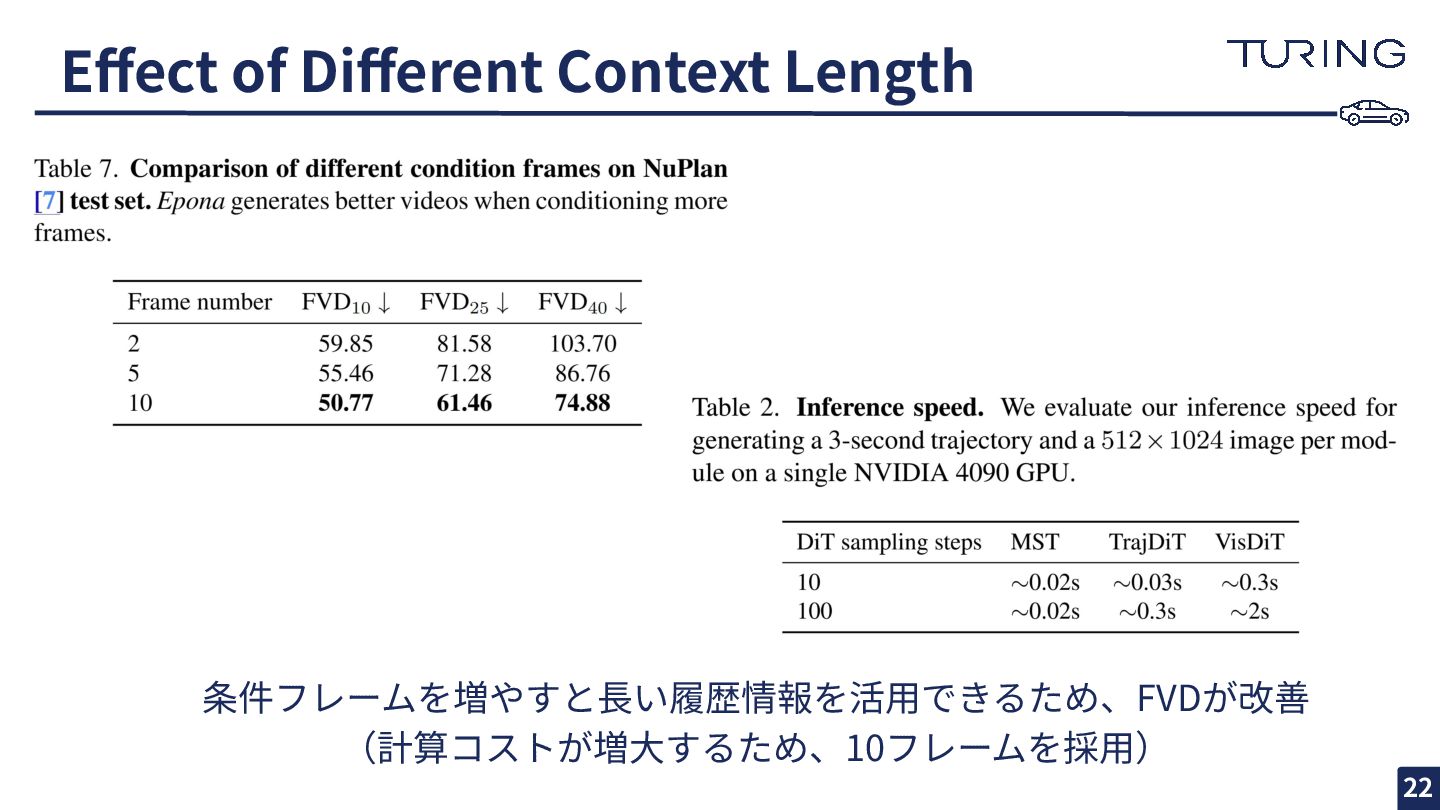
Data: nuPlan, nuScenes (700 scenes), image resolution 512 × 1024 Training: NVIDIA A100 48 GPUs, 2 weeks, 600K iterations, batch size 96 Chain-of-Forward Training: every 10 steps, 3 forward passes each time Training & Implementation Details Evaluation on Video Generation Dataset: nuPlan test: 1,628 scenes, nuScenes val: 1,646 scenes Metrics: Frechet Video Distance (FVD), Frechet Inception Distance (FID) Evaluation on Trajectory Planning Benchmarks: nuScenes (L2 distance, collision rate), NAVSIM 12
Benchmarks NAVSIM (non-reactive simulation) • ⽣成画像と実画像の特徴分布の距離を測定 • 1フレームの画質‧多様性を評価 • ⽣成動画と実動画の時空間特徴分布の
距離を測定 • 動きの⾃然さ‧時間的⼀貫性を評価 衝突回避、安全距離確保、 ルート遵守、快適性などを考慮した PDMスコアを評価 13
Evaluation of Generated Videos 提案⼿法は、従来⼿法と⽐較してFVDスコアが改善しており、 時間的⼀貫性を保った⻑尺動画が⽣成可能 14
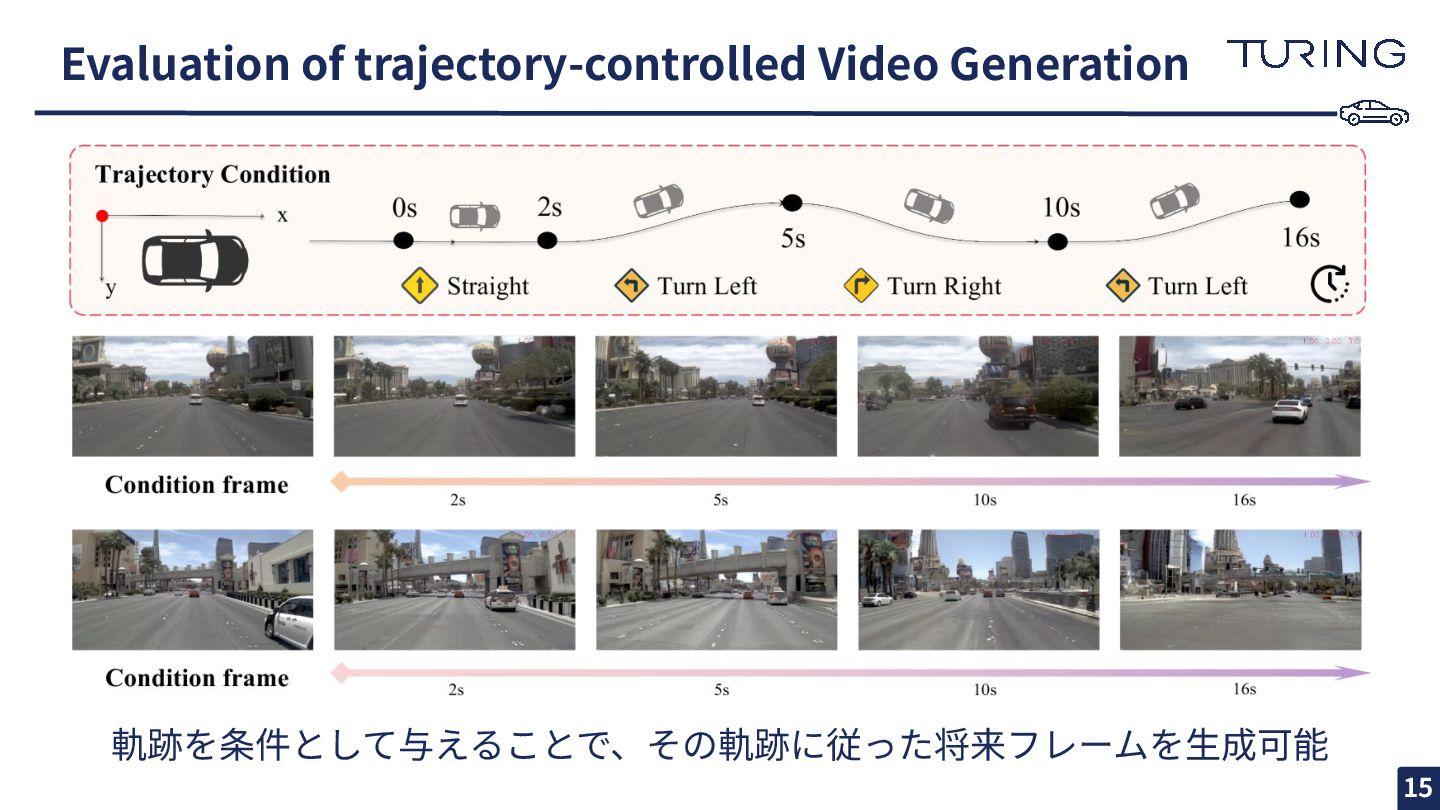
Evaluation of trajectory-controlled Video Generation 軌跡を条件として与えることで、その軌跡に従った将来フレームを⽣成可能 15
Evaluation of trajectory-controlled Video Generation 16
Chain-of-Forwardにより、⾃⼰回帰ドリフトを抑えた⻑尺動画⽣成が可能 Evaluation of Long-range Video Generation 17
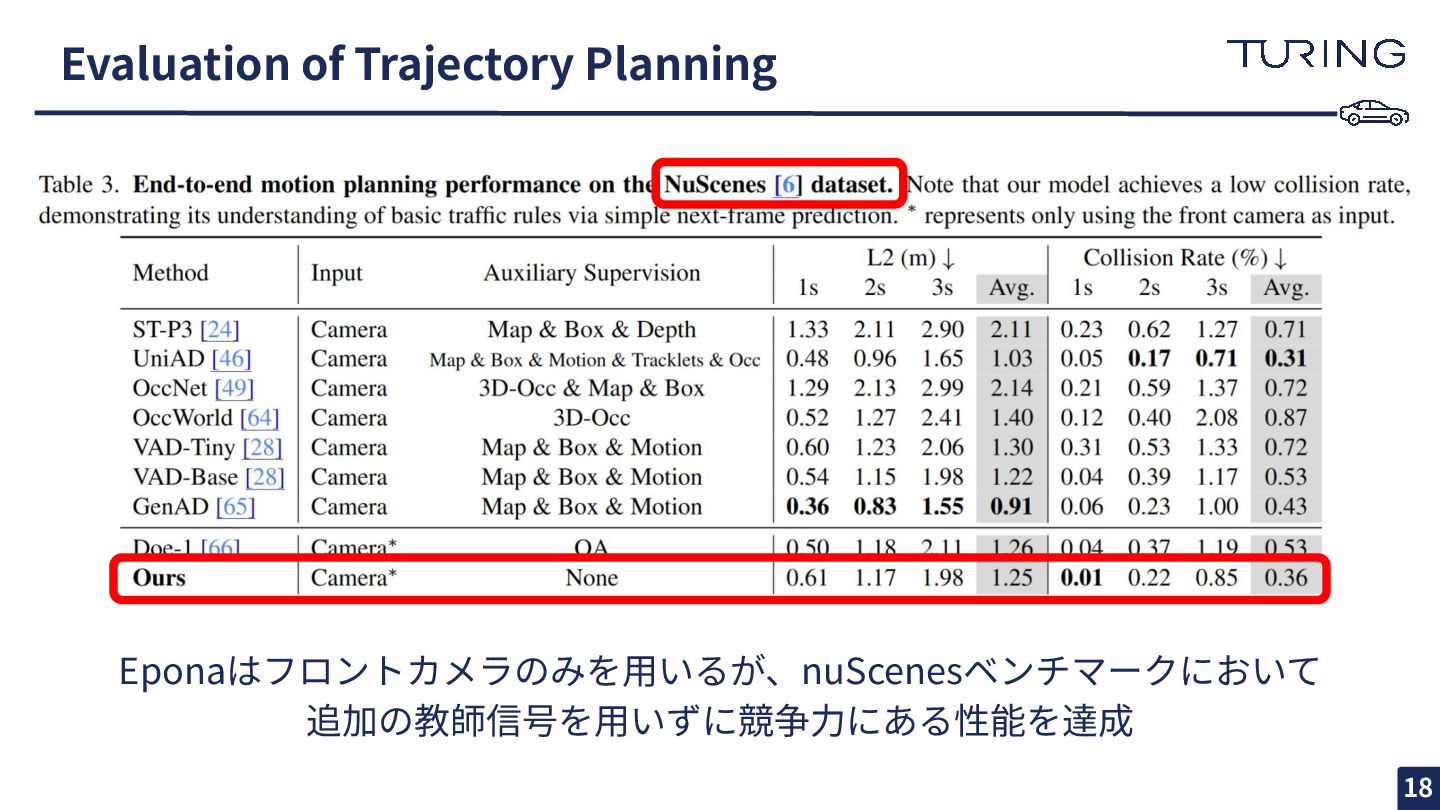
Evaluation of Trajectory Planning Eponaはフロントカメラのみを⽤いるが、nuScenesベンチマークにおいて 追加の教師信号を⽤いずに競争⼒にある性能を達成 18
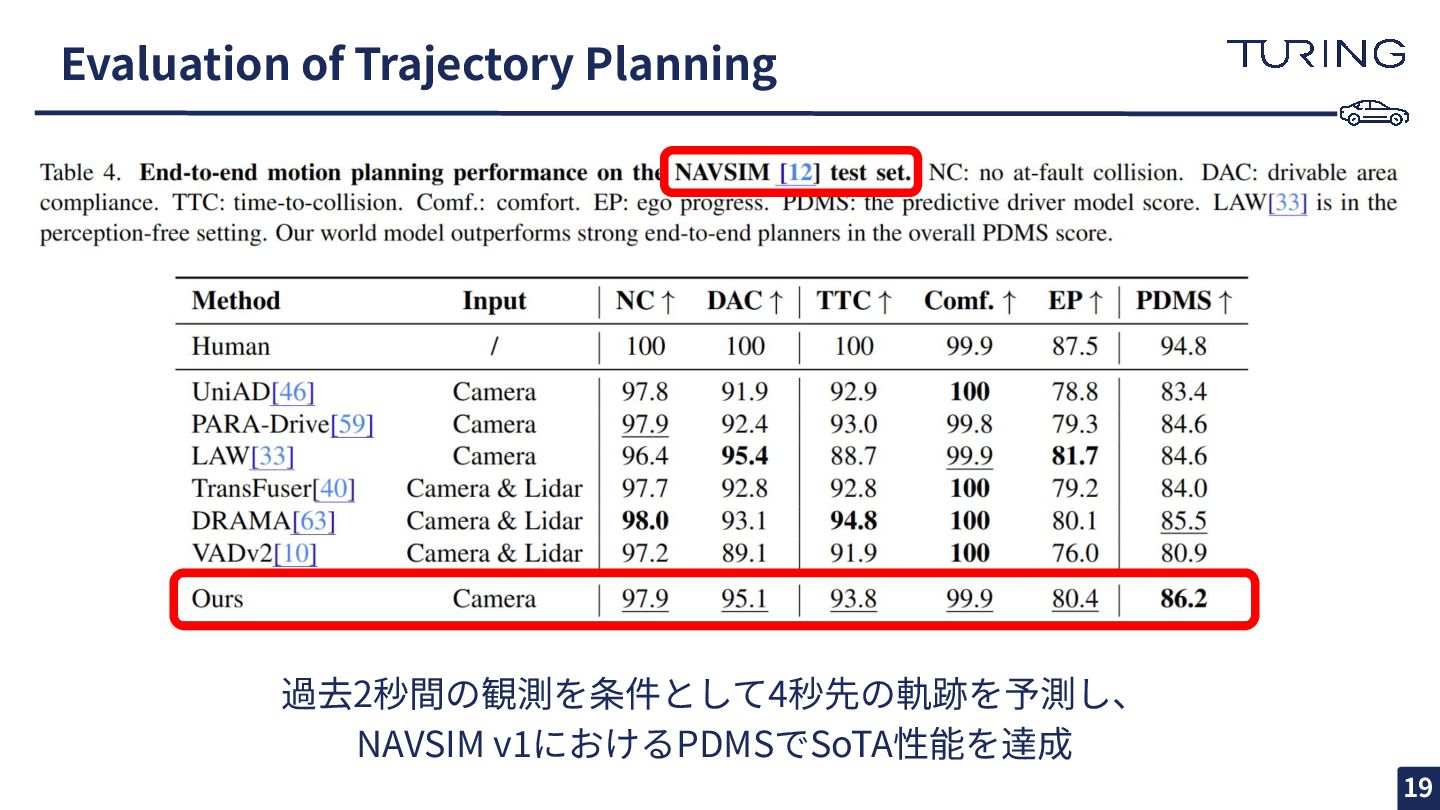
Evaluation of Trajectory Planning 過去2秒間の観測を条件として4秒先の軌跡を予測し、 NAVSIM v1におけるPDMSでSoTA性能を達成 19
Ablations
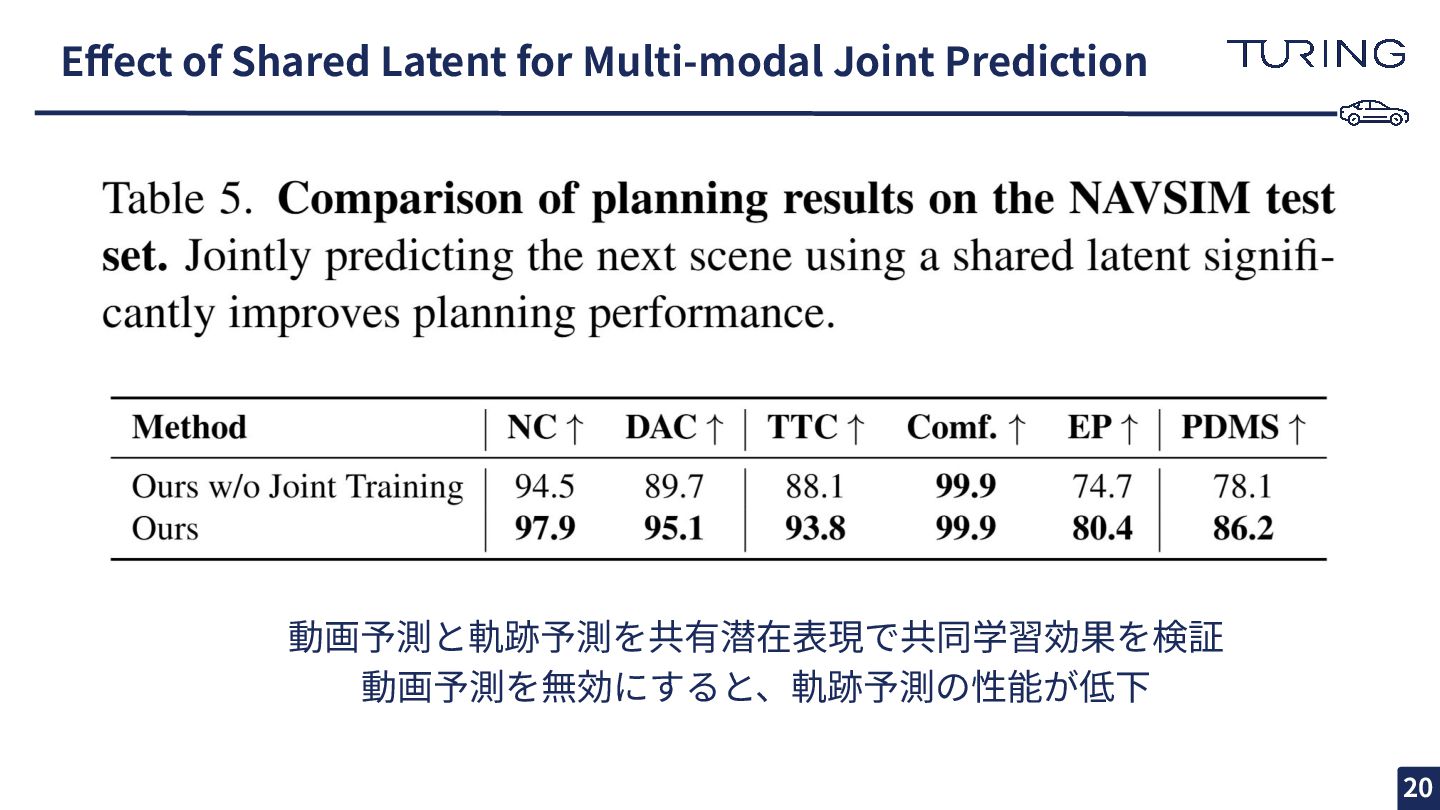
Effect of Shared Latent for Multi-modal Joint Prediction 動画予測と軌跡予測を共有潜在表現で共同学習効果を検証 動画予測を無効にすると、軌跡予測の性能が低下
20
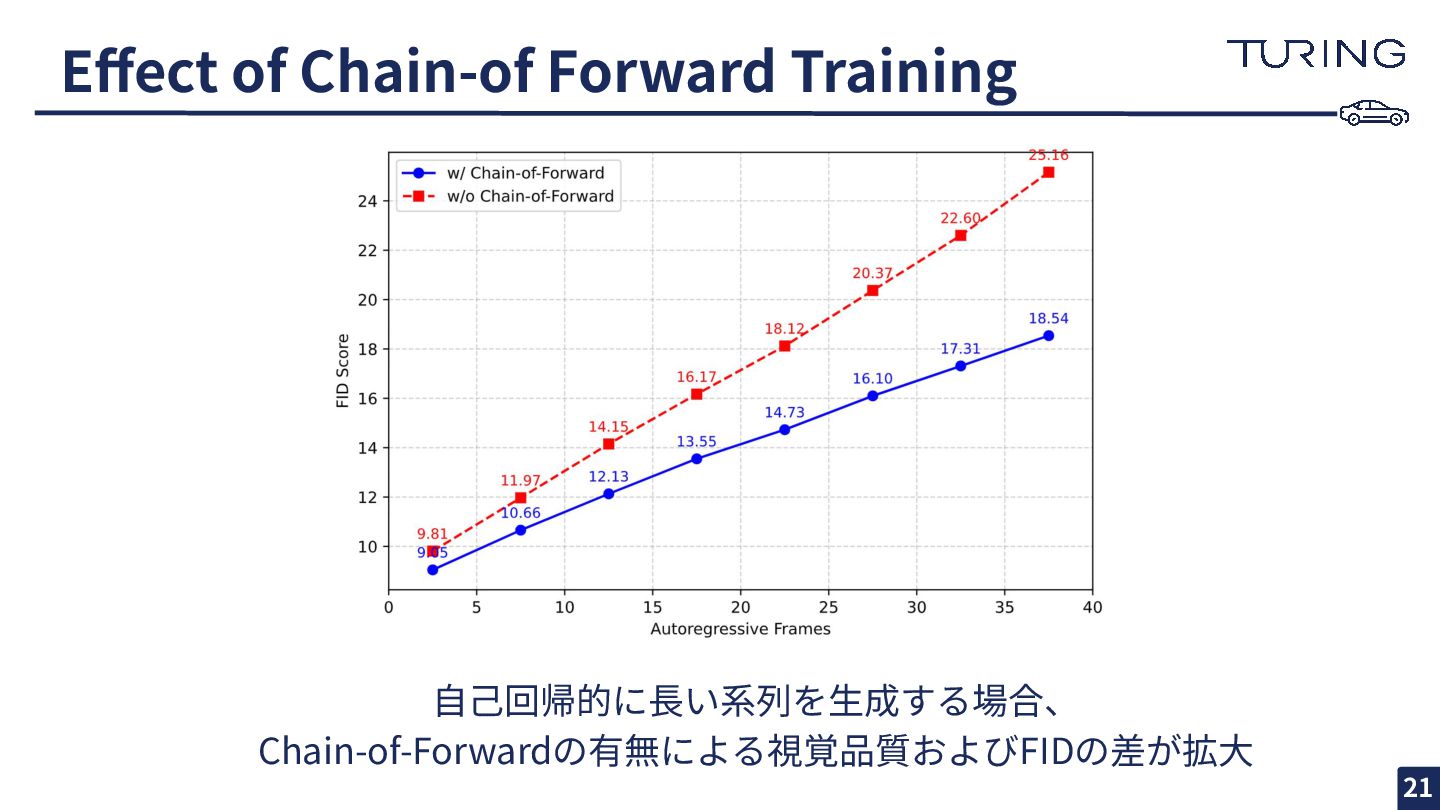
Effect of Chain-of Forward Training ⾃⼰回帰的に⻑い系列を⽣成する場合、 Chain-of-Forwardの有無による視覚品質およびFIDの差が拡⼤ 21
Effect of Different Context Length 条件フレームを増やすと⻑い履歴情報を活⽤できるため、FVDが改善 (計算コストが増⼤するため、10フレームを採⽤) 22
まとめ • Epona: ⾃⼰回帰拡散モデルを⽤いた⾃動運転世界モデル • 過去フレームと軌跡を条件とし、将来フレームと軌跡を同時予測 • Chain-of-Forward学習により⾃⼰回帰ドリフトを抑え、⻑尺動画を⽣成可能 • TrajDiTとVizDiTを分離する設計により、リアルタイムの軌跡⽣成が可能
23
None
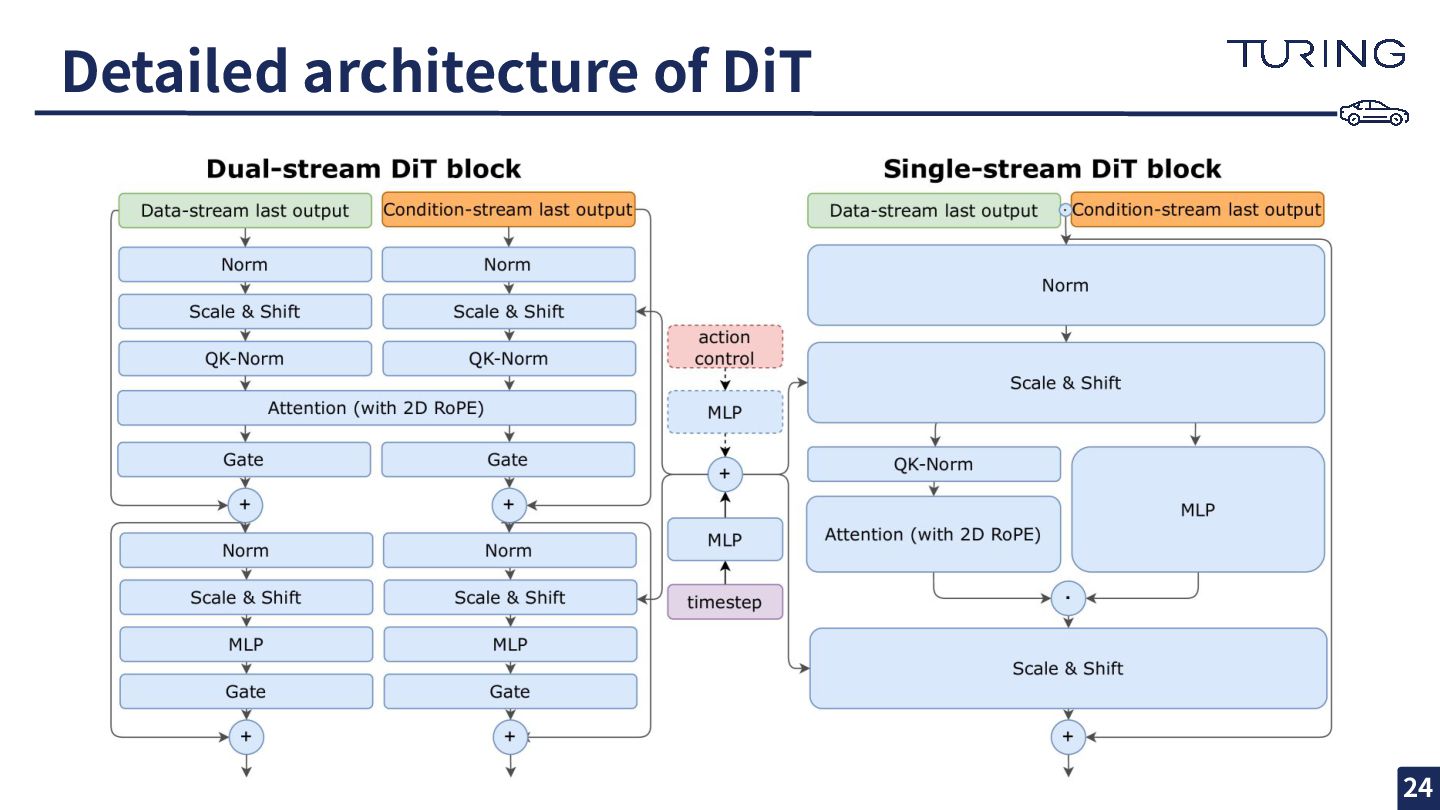
Detailed architecture of DiT 24
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}