Share
Une introduction au gestionnaire de version Git.
Partir de rien ou de la connaissance d’autres VCS pour arriver à une installation fonctionnelle de Git et des opérations de base.
Licence : CC-BY-SA-NC. Pas d'utilisation commerciale = utilisation en formation rémunérée interdite. Me contacter pour un tel usage.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_65.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_66.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_67.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_68.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_69.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_70.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_71.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_72.jpg){kind=link}
![SHA [master (root-commit) bdeddb3] Put red 1 files changed, 1](https://files.speakerdeck.com/presentations/8fda0b60c7850130bd263af332720c11/slide_73.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
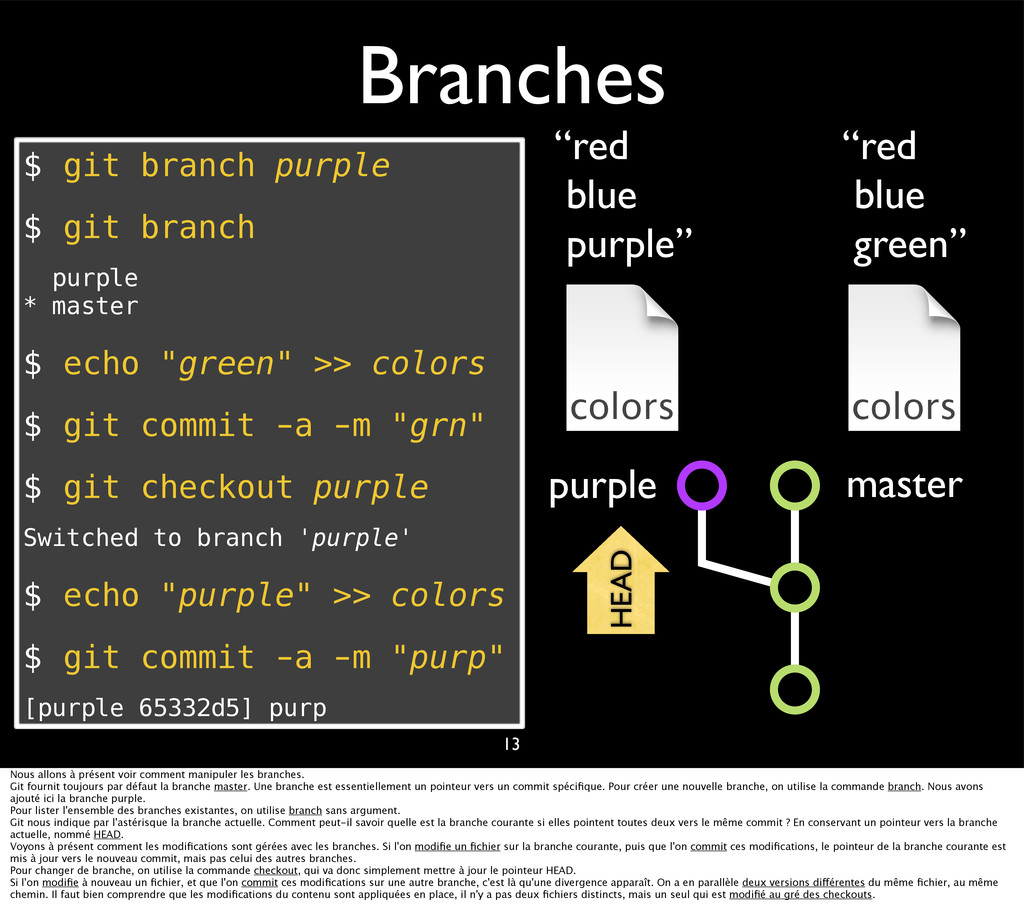{kind=link}
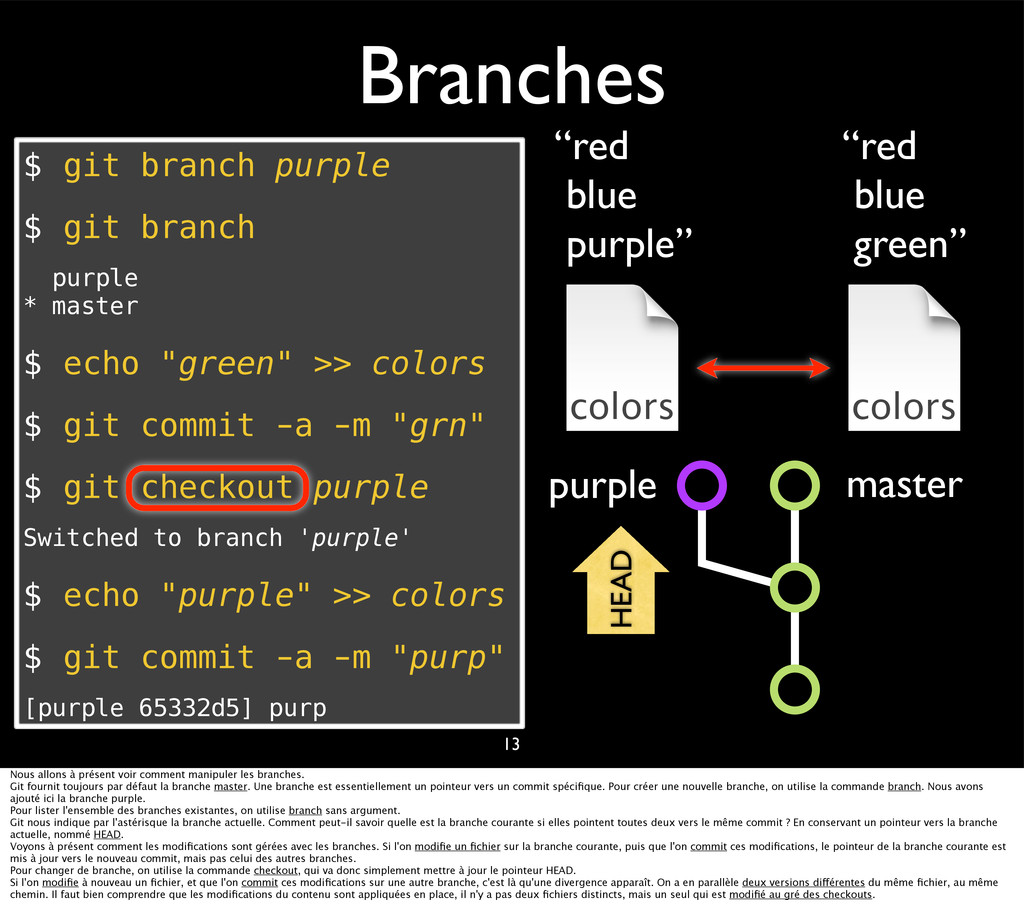{kind=link}
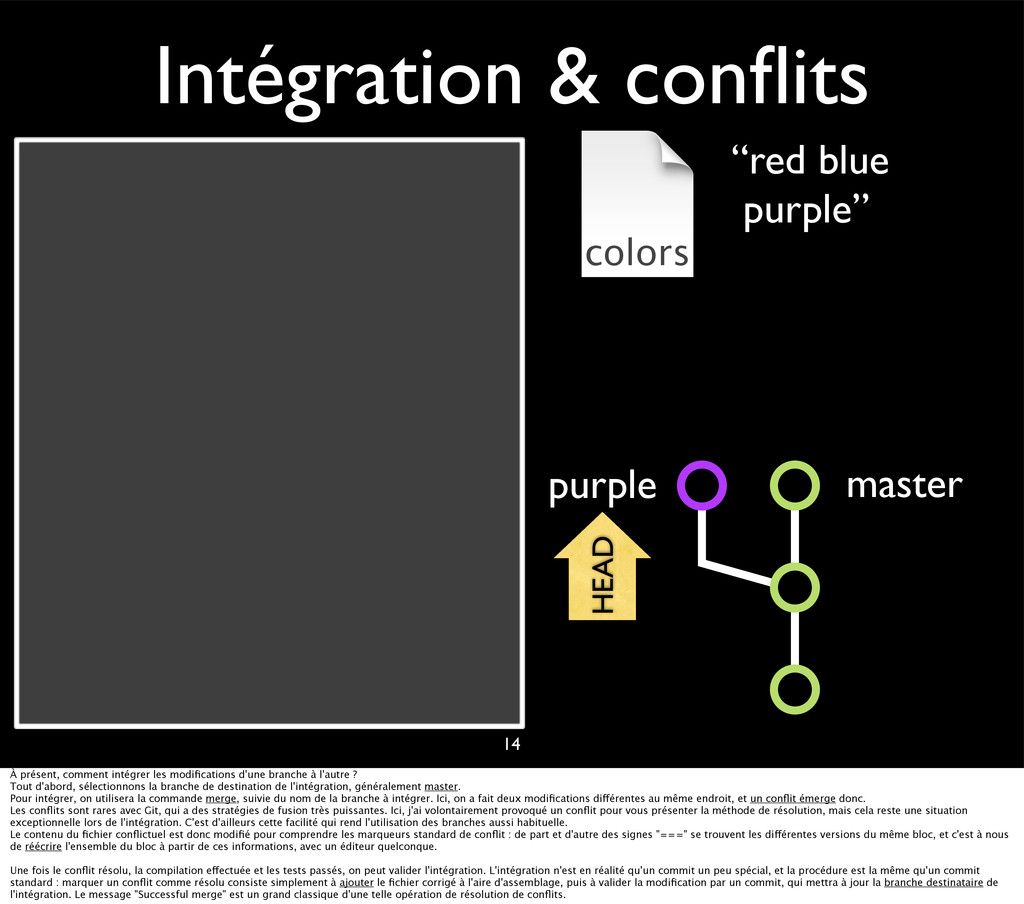{kind=link}
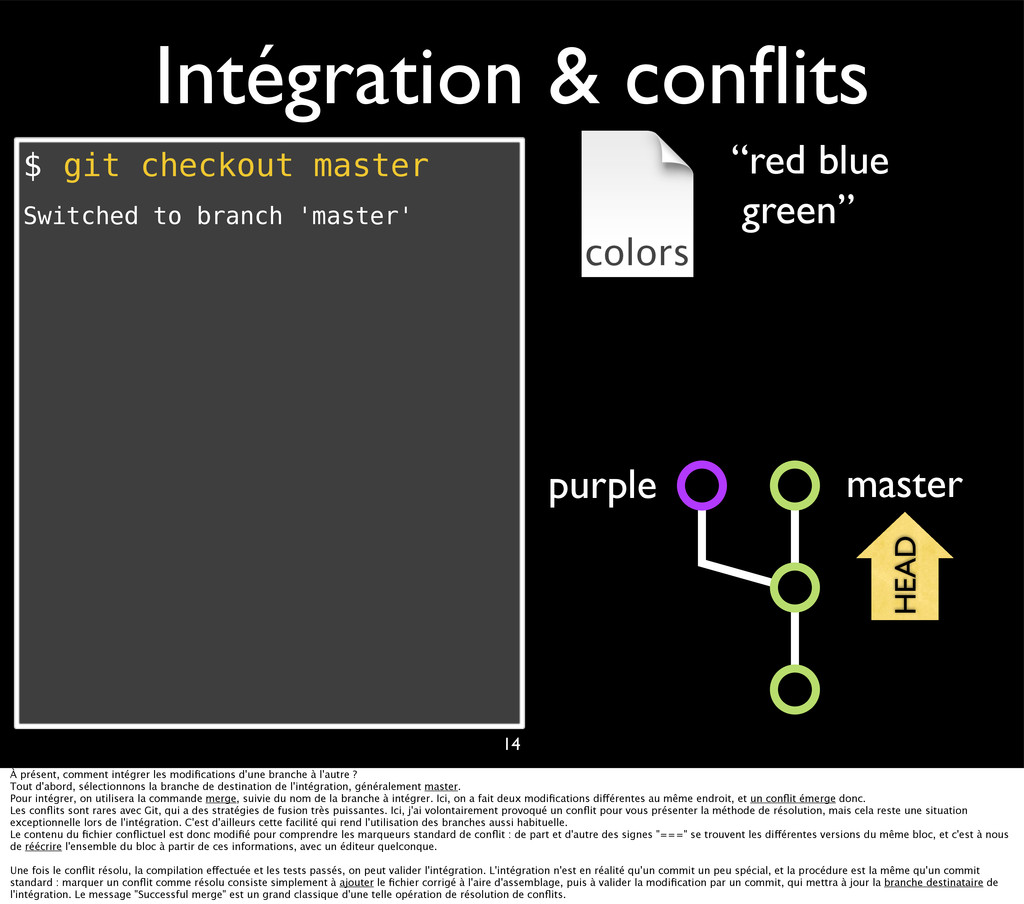{kind=link}
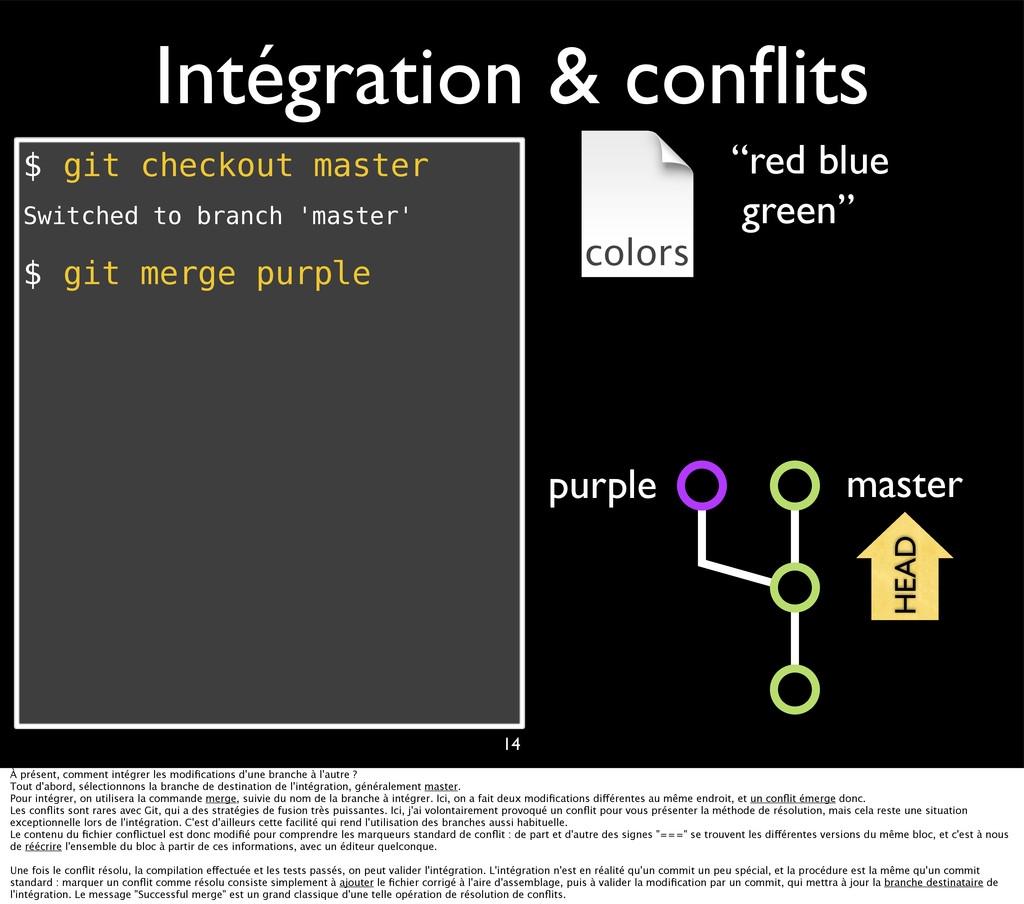{kind=link}
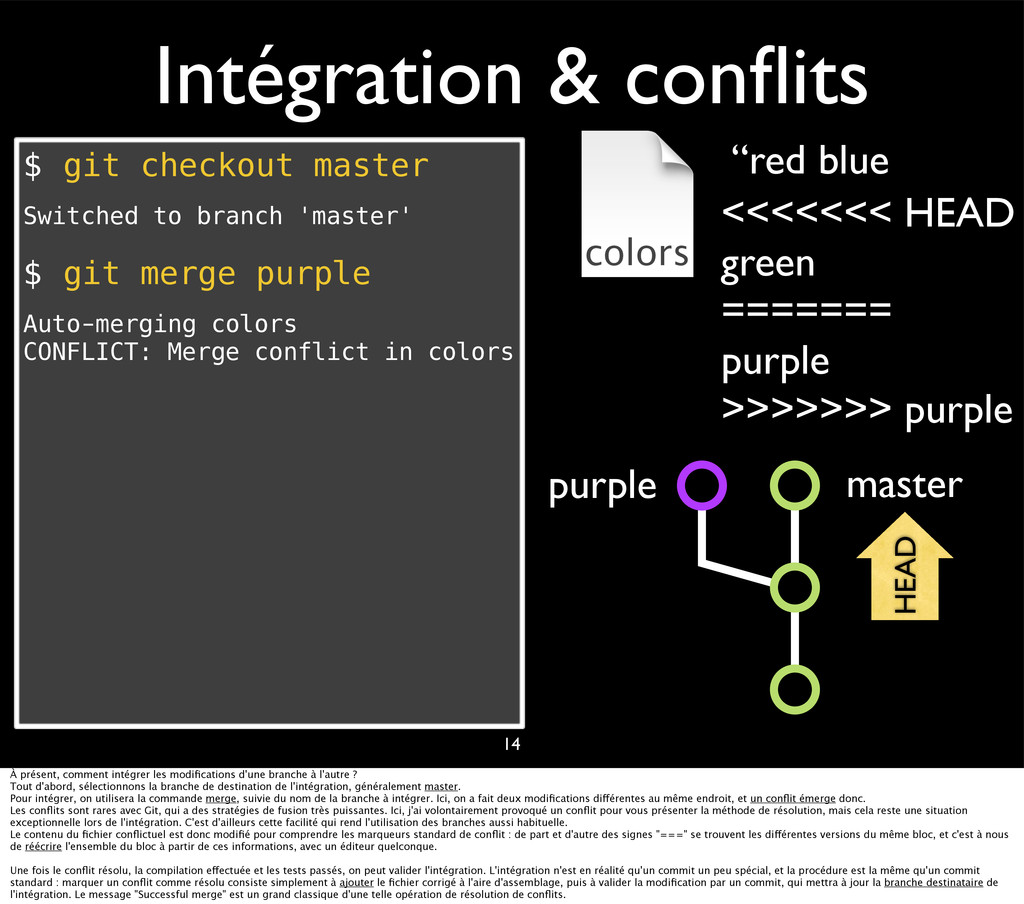{kind=link}
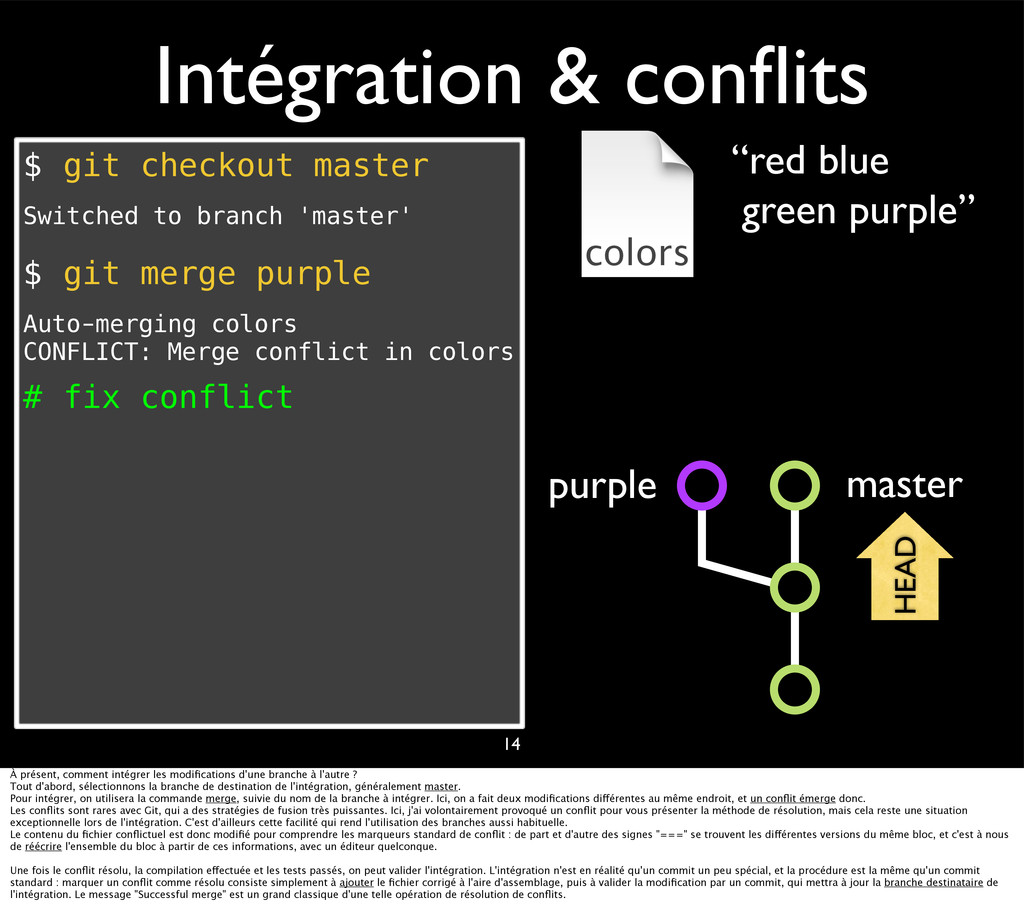{kind=link}
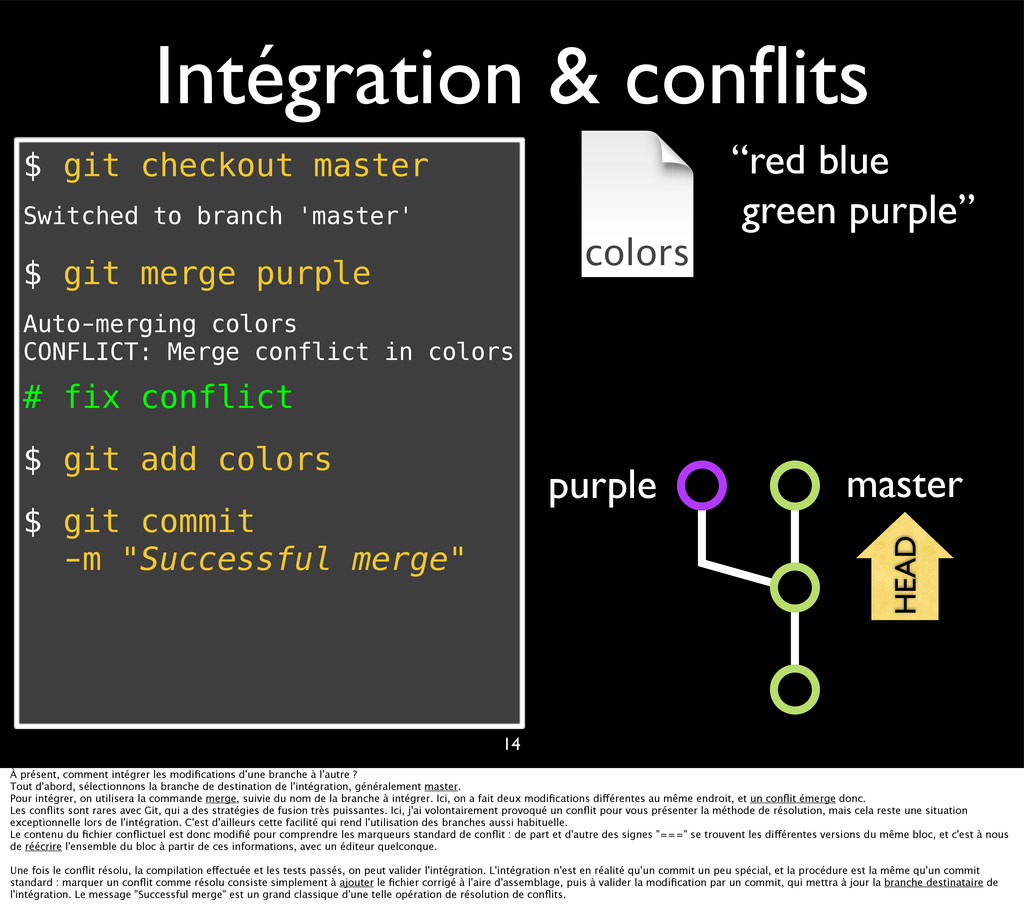{kind=link}
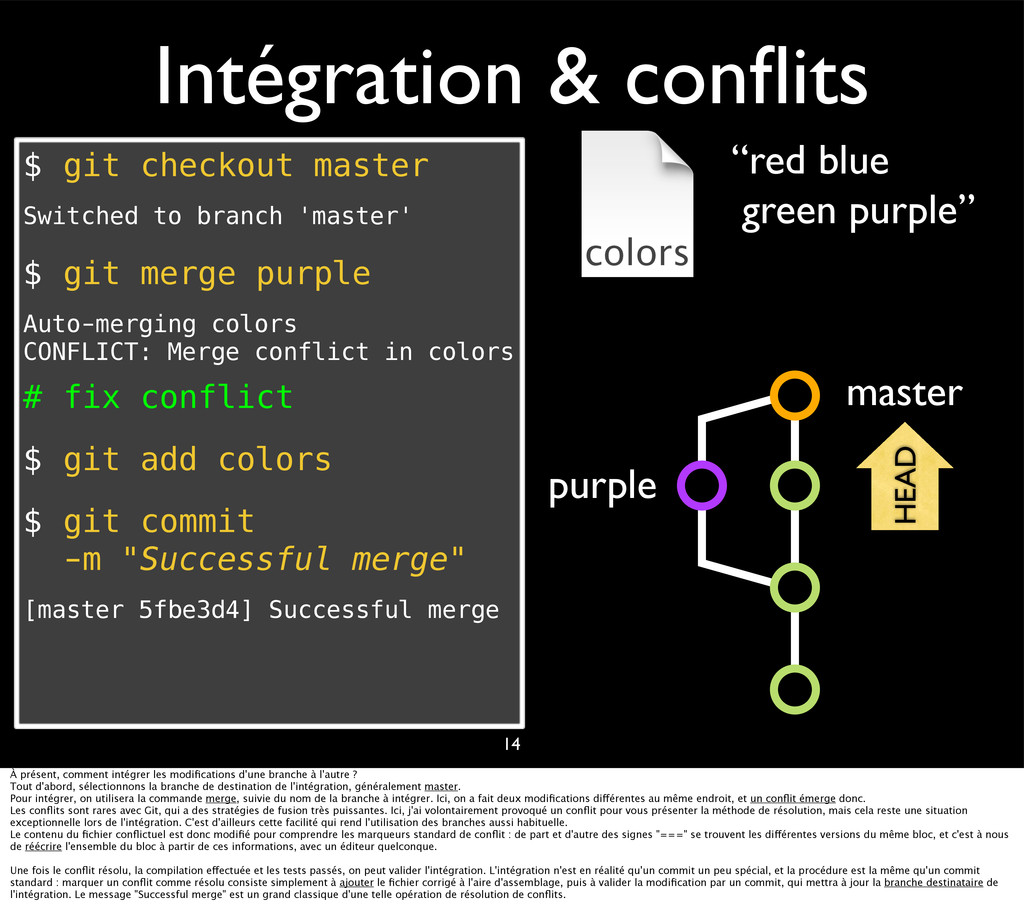{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
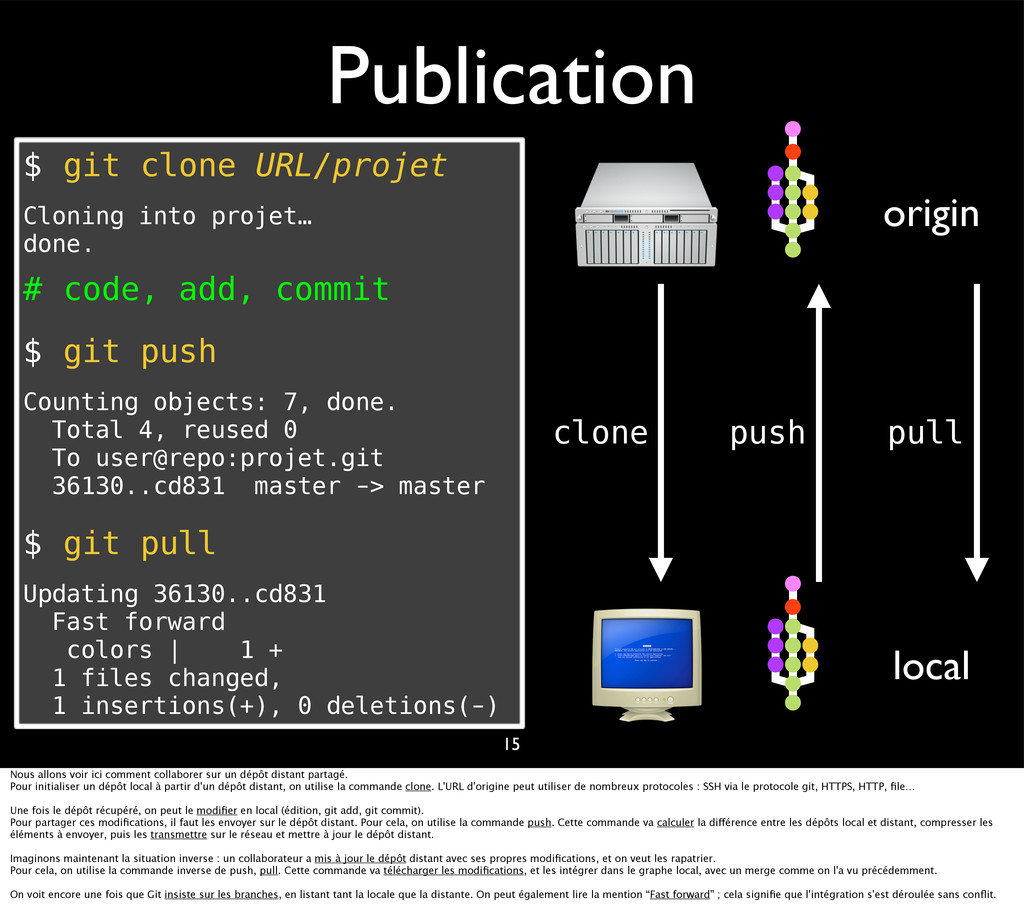{kind=link}
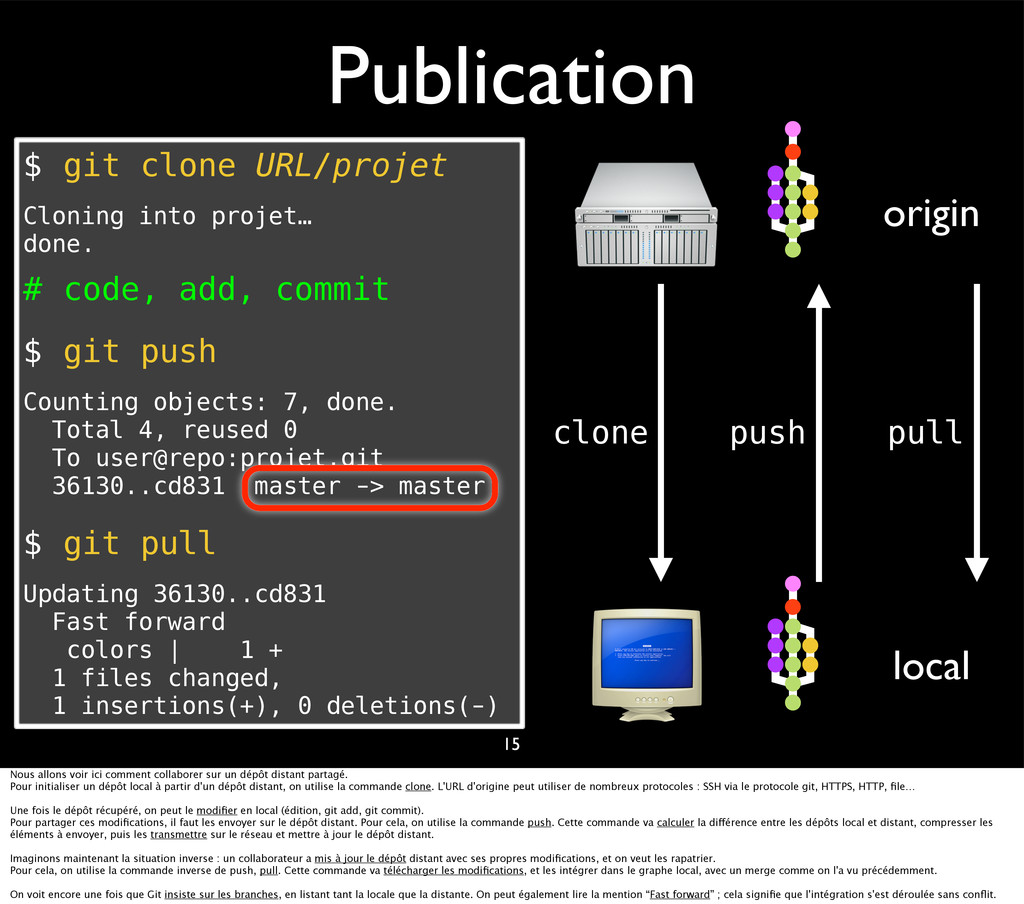{kind=link}
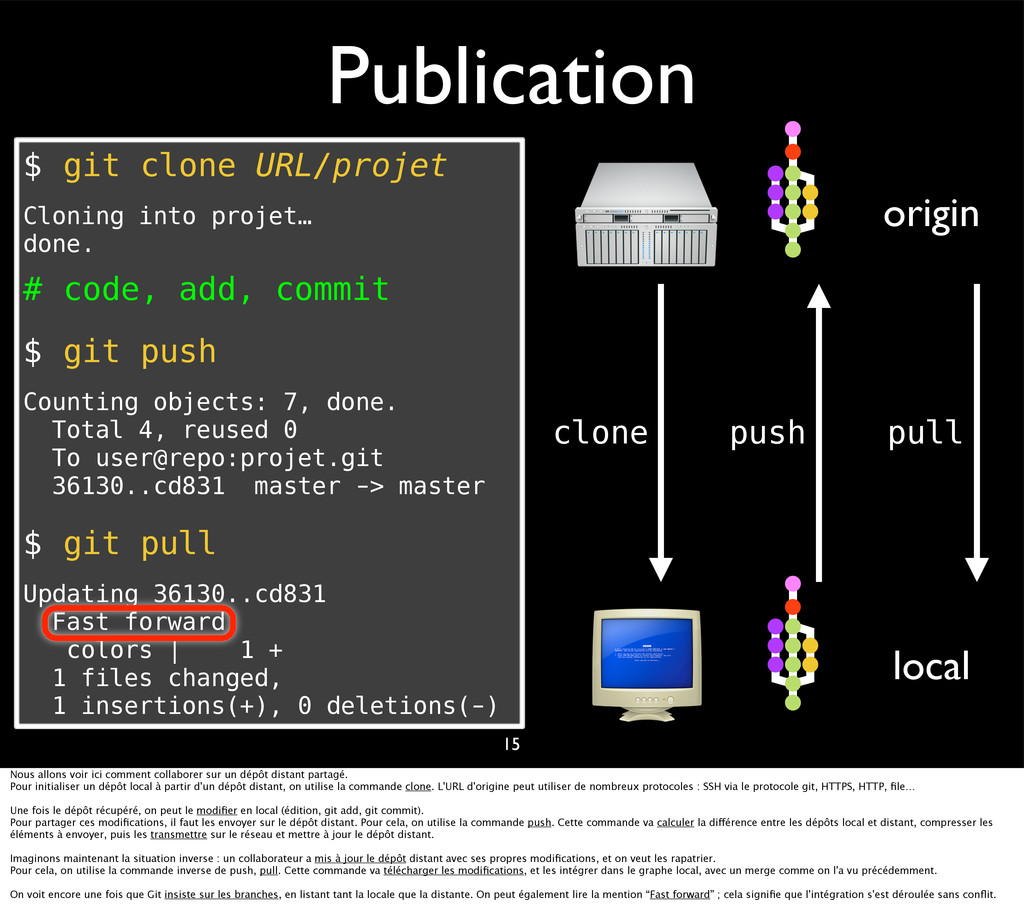{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}