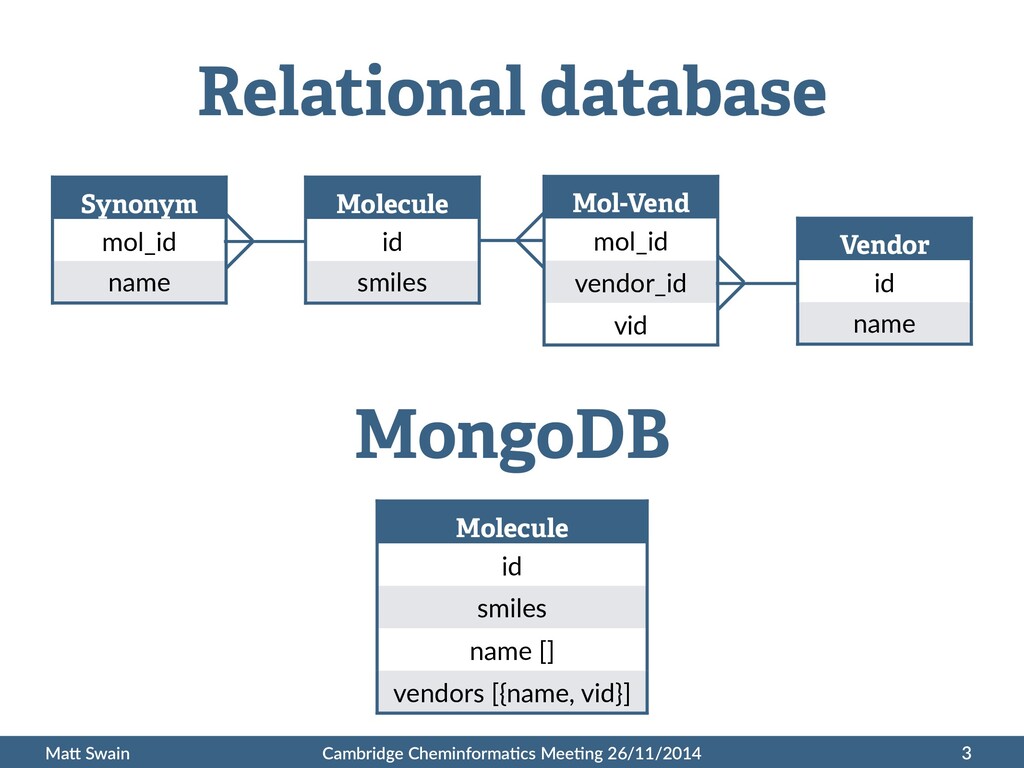
to get started with small projects • Schema-‐less – easy prototyping, heterogeneous data • Language drivers – C, C++, Java, Python, R, Ruby, … • High performance and scalability for large projects 6
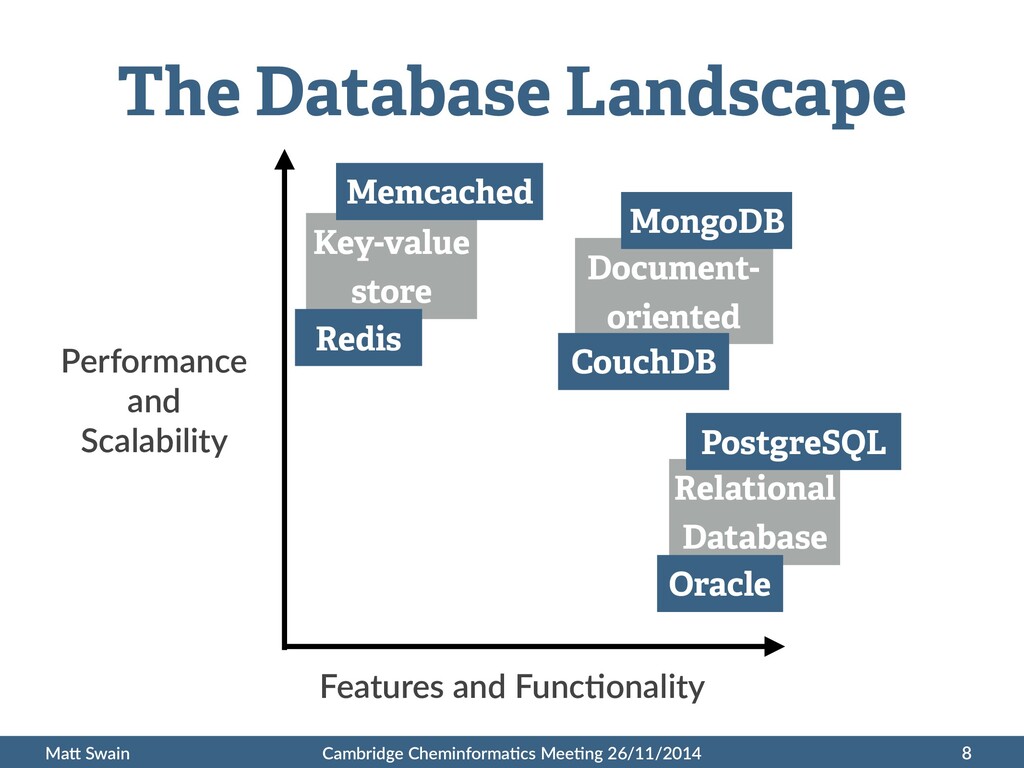
Performance and Scalability Features and Func:onality Document- oriented Relational Database Key-value store Redis MongoDB PostgreSQL Oracle CouchDB Memcached
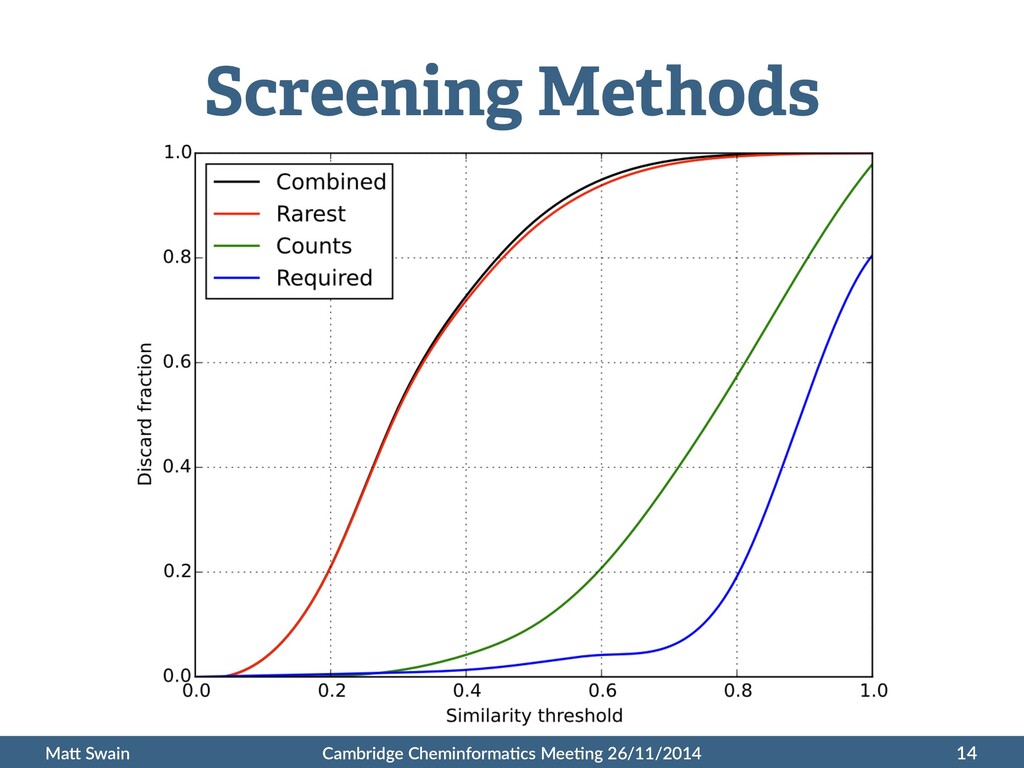
Tanimoto coefficient: • Typical tasks: Similarity Search Basics 9 01001011… [2, 5, 7, 8…] Return all molecules where T > 0.8 with query molecule Return top 20 molecules ranked by T with query molecule
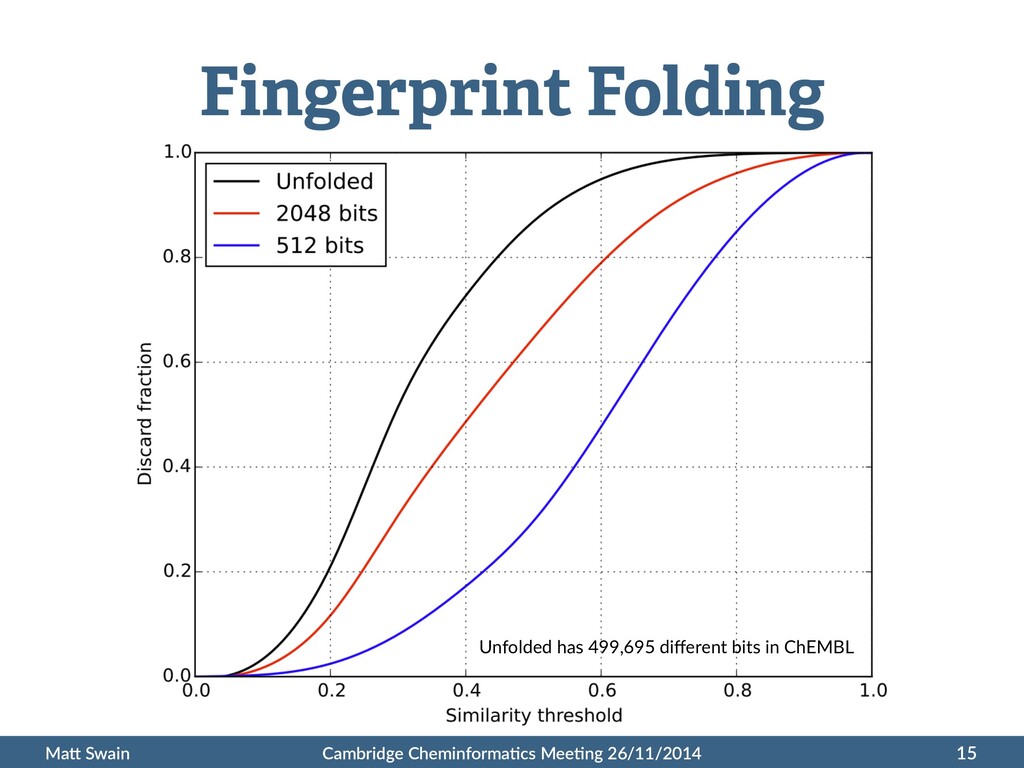
• Use easily searchable fingerprint proper:es to filter • Number of 1-‐bits in results must be in range of query 10 Swamidass, S. J., & Baldi, P. J. Chem. Inf. Model. 2007, 47, 302–317. 10.1021/ci600358f T = Tanimoto threshold Na = Number of 1-‐bits in query fingerprint Nb = Number of 1-‐bits in eligible result fingerprint
At least one bit must be in common between the query fingerprint and a result fingerprint • What is the smallest subset of the query fingerprint where this is s:ll true? • Even if the remaining TNa – 1 bits are all in common, it wouldn’t be enough 11 Davy Suvee, 2011, hUp:/ /datablend.be/?p=254
a pipeline of processing tasks on the server • Compute new fields, filter, transform, group, documents 18 Filter using screening methods Calculate bit intersection with query fp Calculate exact tanimoto coefficient Filter based on tanimoto threshold
limit on the CPU, RAM, storage of a single server • Awful performance if working set doesn’t fit in RAM • Sharding: Horizontal scaling to mul:ple servers • Range-‐based sharding vs Hash-‐based sharding 23
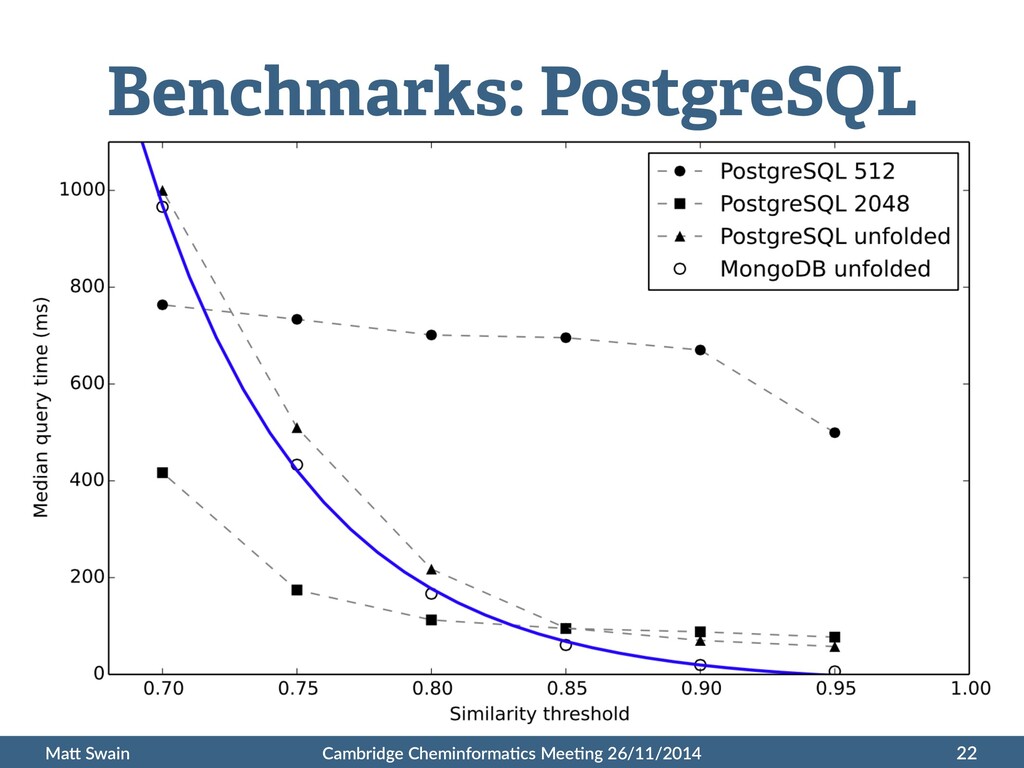
use MongoDB for a chemical database • Comparable performance to PostgreSQL • Use sparse, unfolded fingerprints for best performance • Poten:al for horizontal scaling for huge databases 25
/blog.maU-‐swain.com/post/87093745652/ • Swamidass, S. J., & Baldi, P. Bounds and Algorithms for Fast Exact Searches of Chemical Fingerprints in Linear and Sublinear Time. J. Chem. Inf. Model. 2007, 47, 302–317. 10.1021/ci600358f • Rogers, D., & Hahn, M. Extended-‐Connec7vity Fingerprints. J. Chem. Inf. Model.2010, 50, 742–754. 10.1021/ci100050t • Kristensen, T. G. et al. A tree-‐based method for the rapid screening of chemical fingerprints. Algorithms Mol. Biol., 2010 5, 9. 10.1186/1748-‐7188-‐5-‐9 • RDKit – hUp:/ /www.rdkit.org/docs/GeingStartedInPython.html • MongoDB – hUp:/ /docs.mongodb.org/manual/ 28
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}