Performance evaluation of MEGADOCK protein-protein interaction prediction system implemented with distributed containers on a cloud computing environment
PDPTA’19 - The 25th International Conference on Parallel and Distributed Processing Techniques and Applications
distributed containers on a cloud computing environment PDPTA’19 - The 25th International Conference on Parallel and Distributed Processing Techniques and Applications Kento Aoyama1,2, Yuki Yamamoto1, Masahito Ohue1, Yutaka Akiyama1 1 Dept. of Computer Science, School of Computing, Tokyo Institute of Technology 2 AIST – Tokyo Tech Real World Big-Data Computation Open Innovation Laboratory, National Institute of Advanced Industrial Science and Technology July 29, 2019
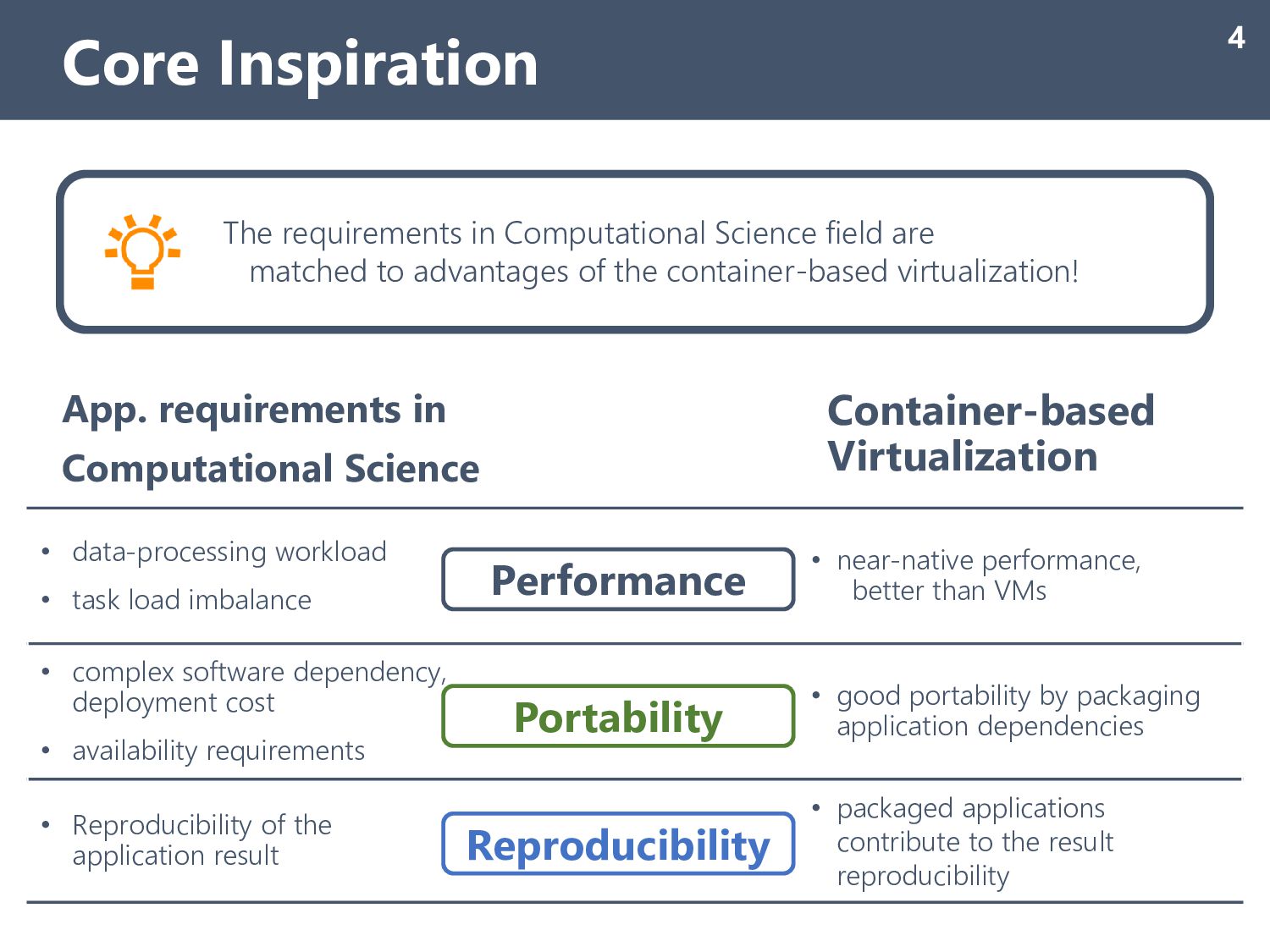
mostly like data-processing, require huge memory I/O & File I/O • calculations strongly depend on data itself, load-imbalanced tasks • requires various dependent software/tools written in different languages • requires scientific reproducibility for the result itself Introduction 2 Reproducibility The application result can be reproducible by other researcher (Reproducibility) Performance The application can show good performance, and good parallel scalability (Performance) Portability The application can be easily available on other machine environment (Availability, Portability)
predicting application • FFT-grid based docking approach (FFTW/CUFFT) • Hybrid parallelization using MPI/GPU/OpenMP • Available on GitHub: akiyamalab/MEGADOCK Related Projects: • MEGADOCK-Azure [M. Ohue+ 2017] • MEGADOCK 5.0 (WIP) Target Application of this Study 3 Performance Portability Performance Performance
better than VMs • complex software dependency, deployment cost • availability requirements • good portability by packaging application dependencies • Reproducibility of the application result • packaged applications contribute to the result reproducibility App. requirements in Computational Science Core Inspiration 4 Performance Portability Reproducibility The requirements in Computational Science field are matched to advantages of the container-based virtualization! Container-based Virtualization
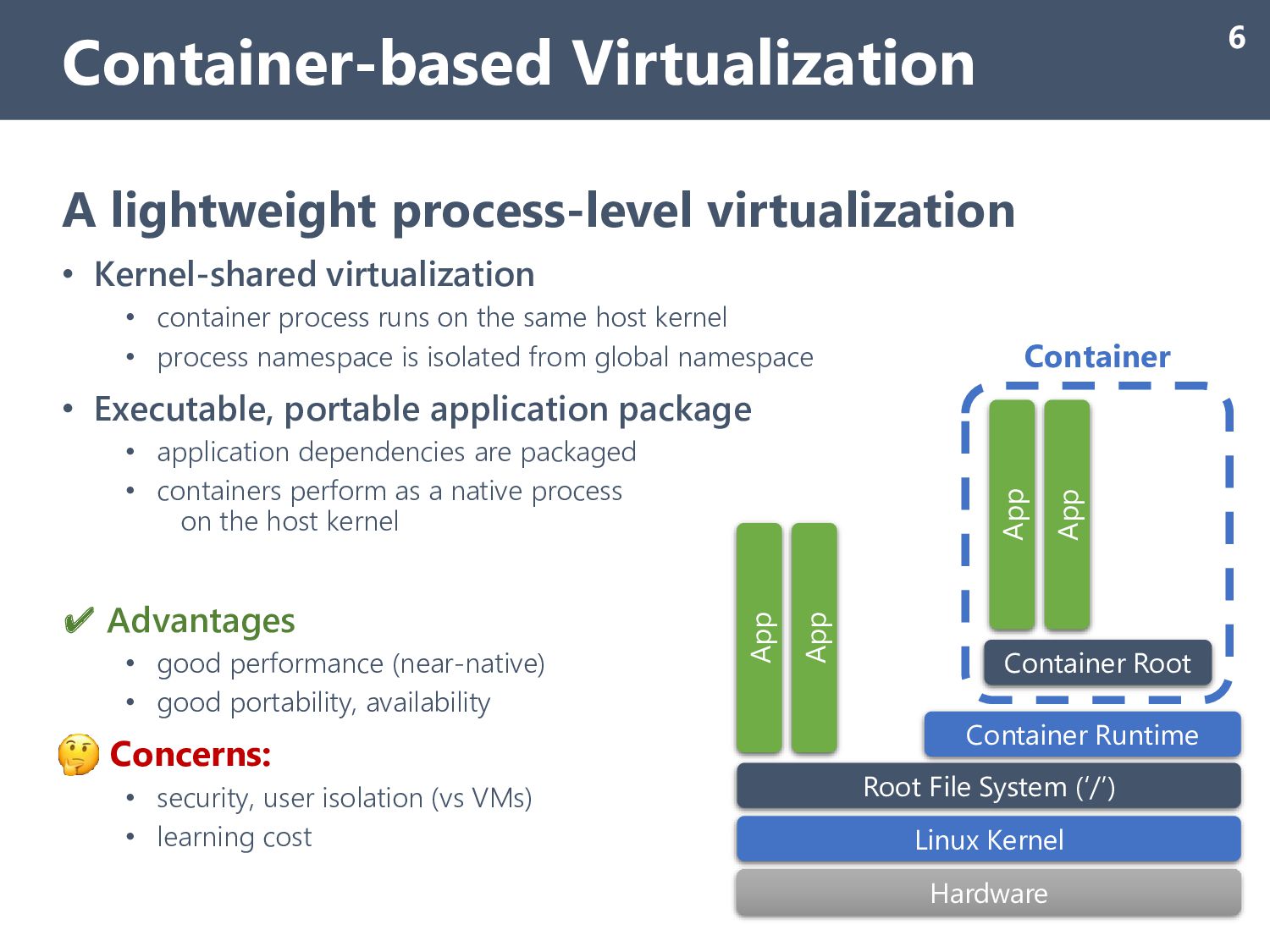
runs on the same host kernel • process namespace is isolated from global namespace • Executable, portable application package • application dependencies are packaged • containers perform as a native process on the host kernel ✔ Advantages • good performance (near-native) • good portability, availability Concerns: • security, user isolation (vs VMs) • learning cost Container-based Virtualization 6 Hardware Linux Kernel Root File System (‘/’) App App App App Container Root Container Container Runtime
Canon+ 2015] [L. Benedicic+ 2017] [S. Hykes, 2013] HPC Containers Docker Singularity Shifter/Sarus Privilege Model Root Daemon SUID/UserNS SUID Support for GPU nvidia-docker Yes Yes Support for MPI Yes Yes Yes Image compatibility for Docker - Yes Yes Image sharing service/ location Docker Hub, local file Singularity Hub, local file Local service / local repository Image format (general) .tar layers (OCIv1 compat.) .sif/.simg (OCIv1 compat.) squashfs Performance good good good
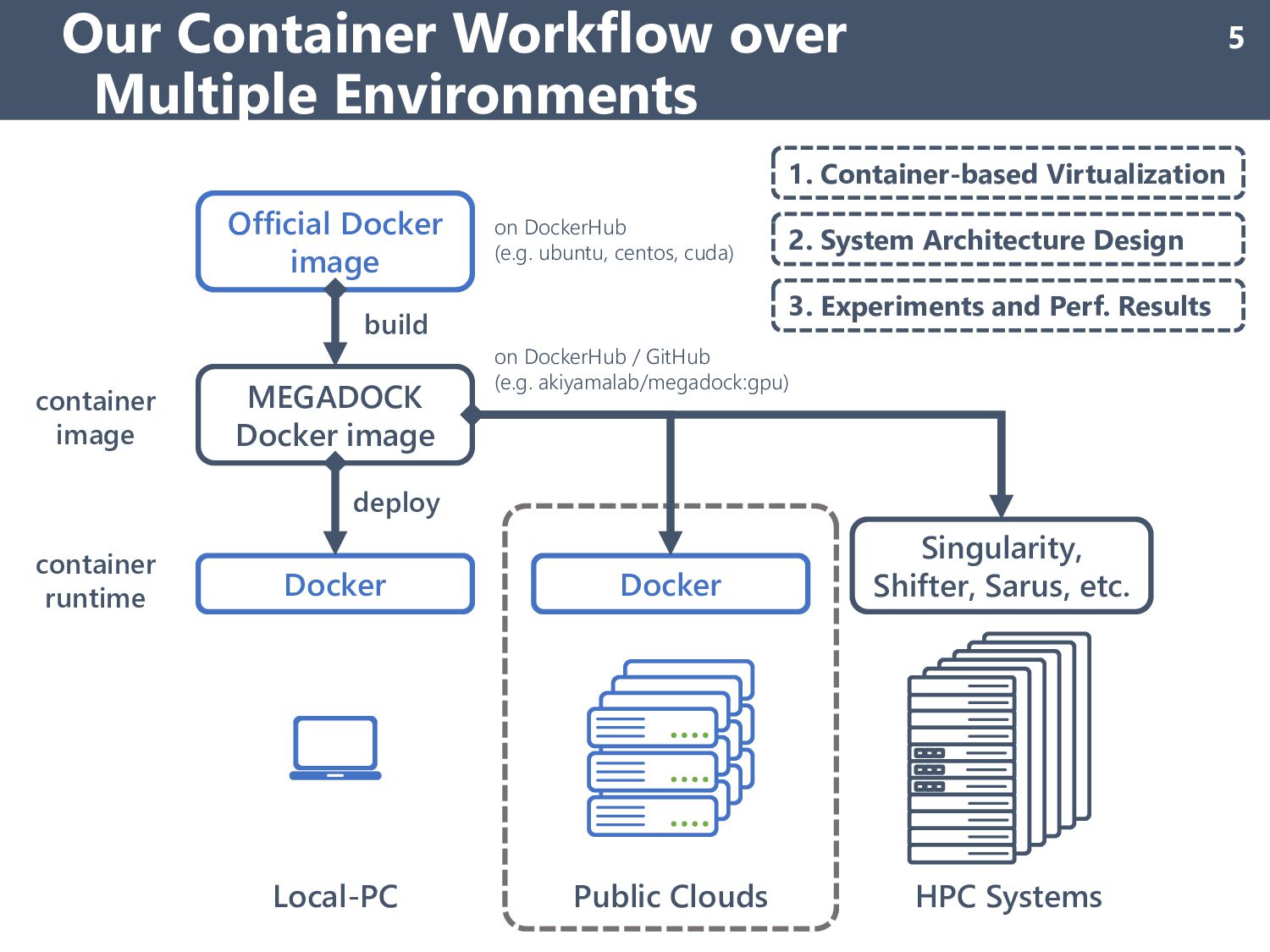
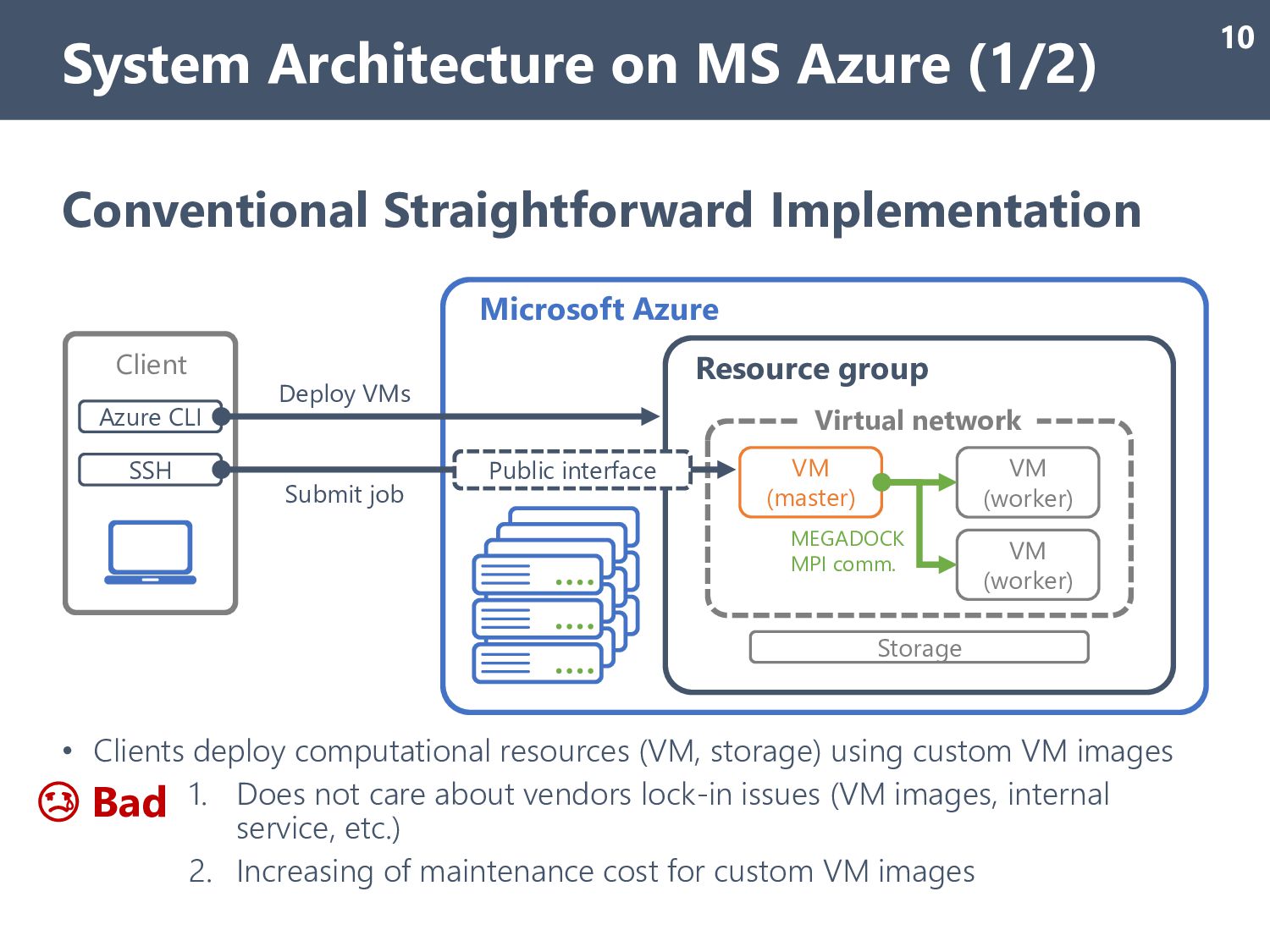
using custom VM images 1. Does not care about vendors lock-in issues (VM images, internal service, etc.) 2. Increasing of maintenance cost for custom VM images System Architecture on MS Azure (1/2) 10 Azure CLI Deploy VMs SSH Submit job Resource group VM (master) VM (worker) VM (worker) Virtual network Microsoft Azure Storage Public interface Client 😢 Bad MEGADOCK MPI comm.
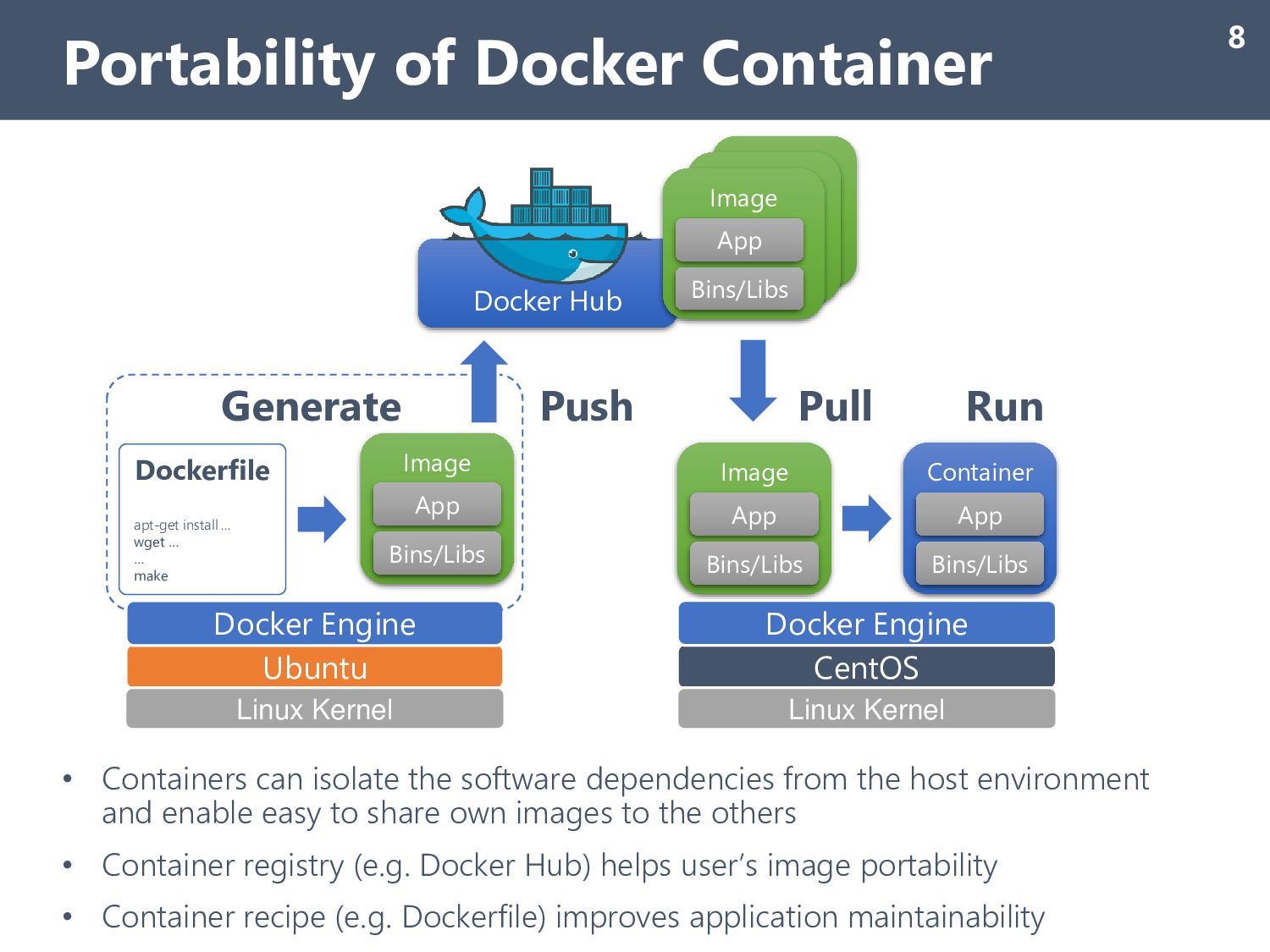
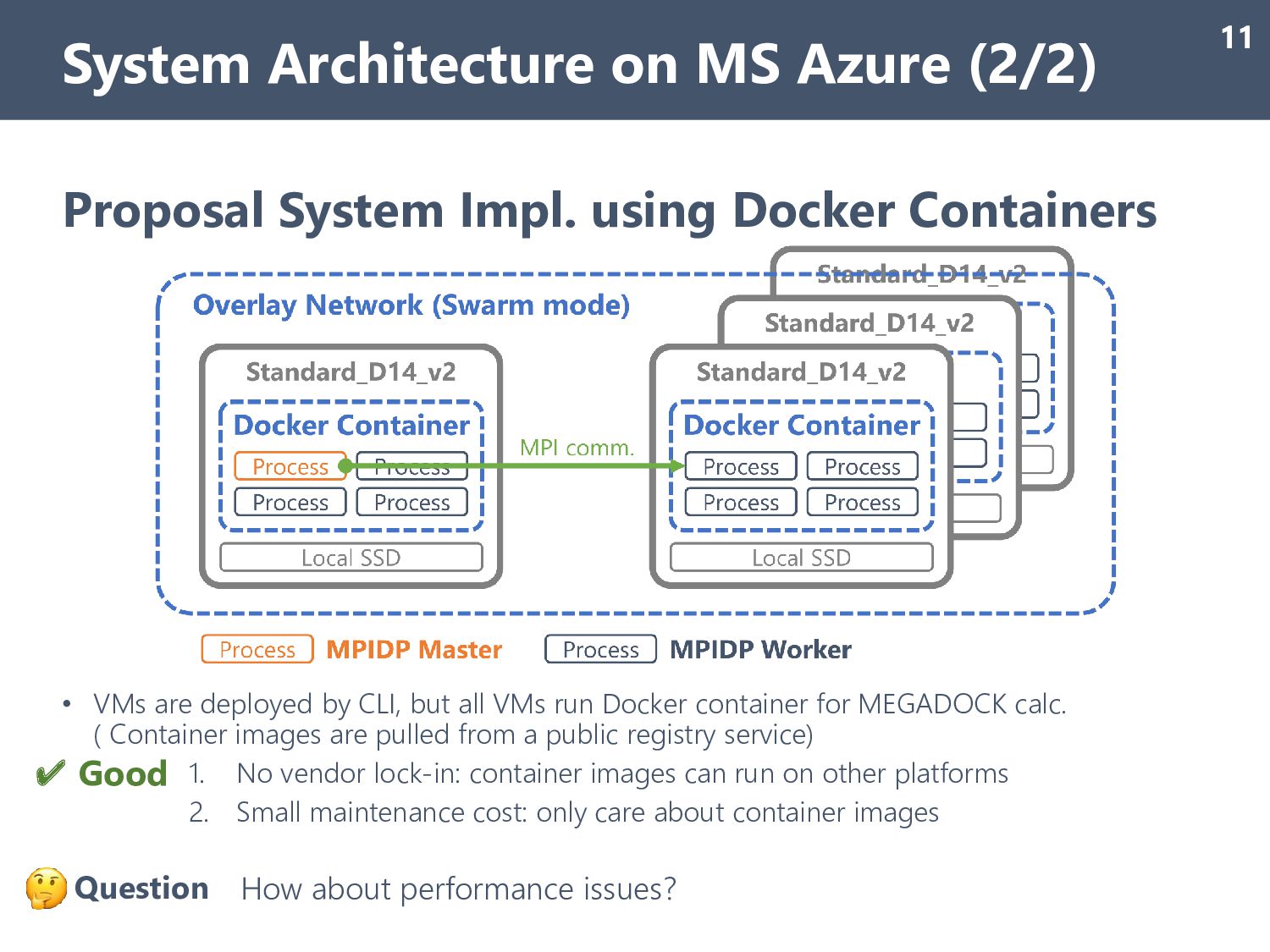
by CLI, but all VMs run Docker container for MEGADOCK calc. ( Container images are pulled from a public registry service) 1. No vendor lock-in: container images can run on other platforms 2. Small maintenance cost: only care about container images How about performance issues? System Architecture on MS Azure (2/2) 11 ✔ Good Question
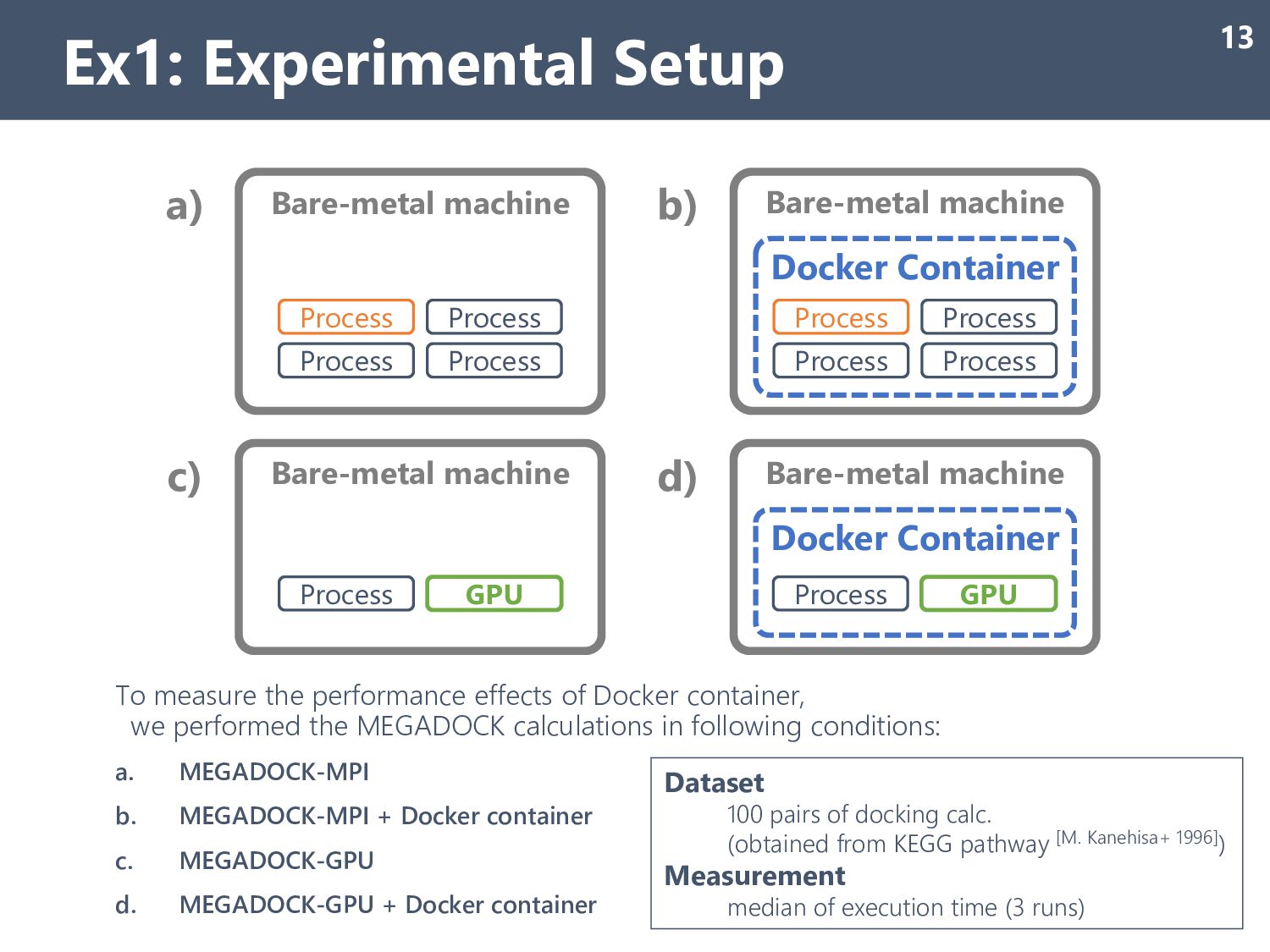
Docker container, we performed the MEGADOCK calculations in following conditions: a. MEGADOCK-MPI b. MEGADOCK-MPI + Docker container c. MEGADOCK-GPU d. MEGADOCK-GPU + Docker container Dataset 100 pairs of docking calc. (obtained from KEGG pathway [M. Kanehisa+ 1996]) Measurement median of execution time (3 runs) Bare-metal machine Process Process Process Process Bare-metal machine Docker Container Process Process Process Process Bare-metal machine Process GPU Bare-metal machine Docker Container Process GPU c) a) b) d)
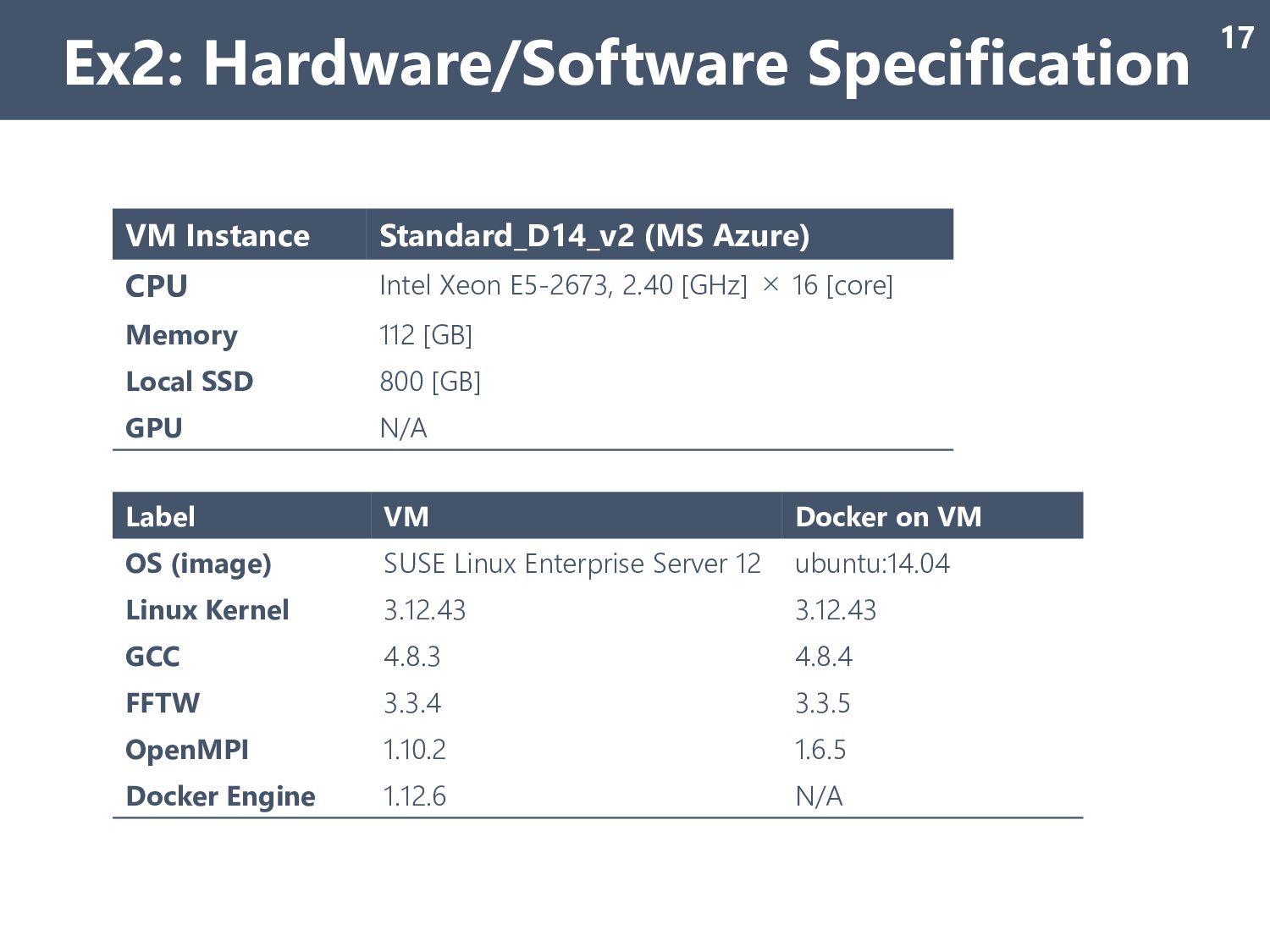
= 3481 pairs docking calc.) Measurement • median of 3 times docking calculation (‘time’ command) Runtime Configurations • OMP_NUM_THREADS=4 • 4 MPI process / 1 node • All file input/output are stored to data volume on local SSD Ex2: Experimental Setup
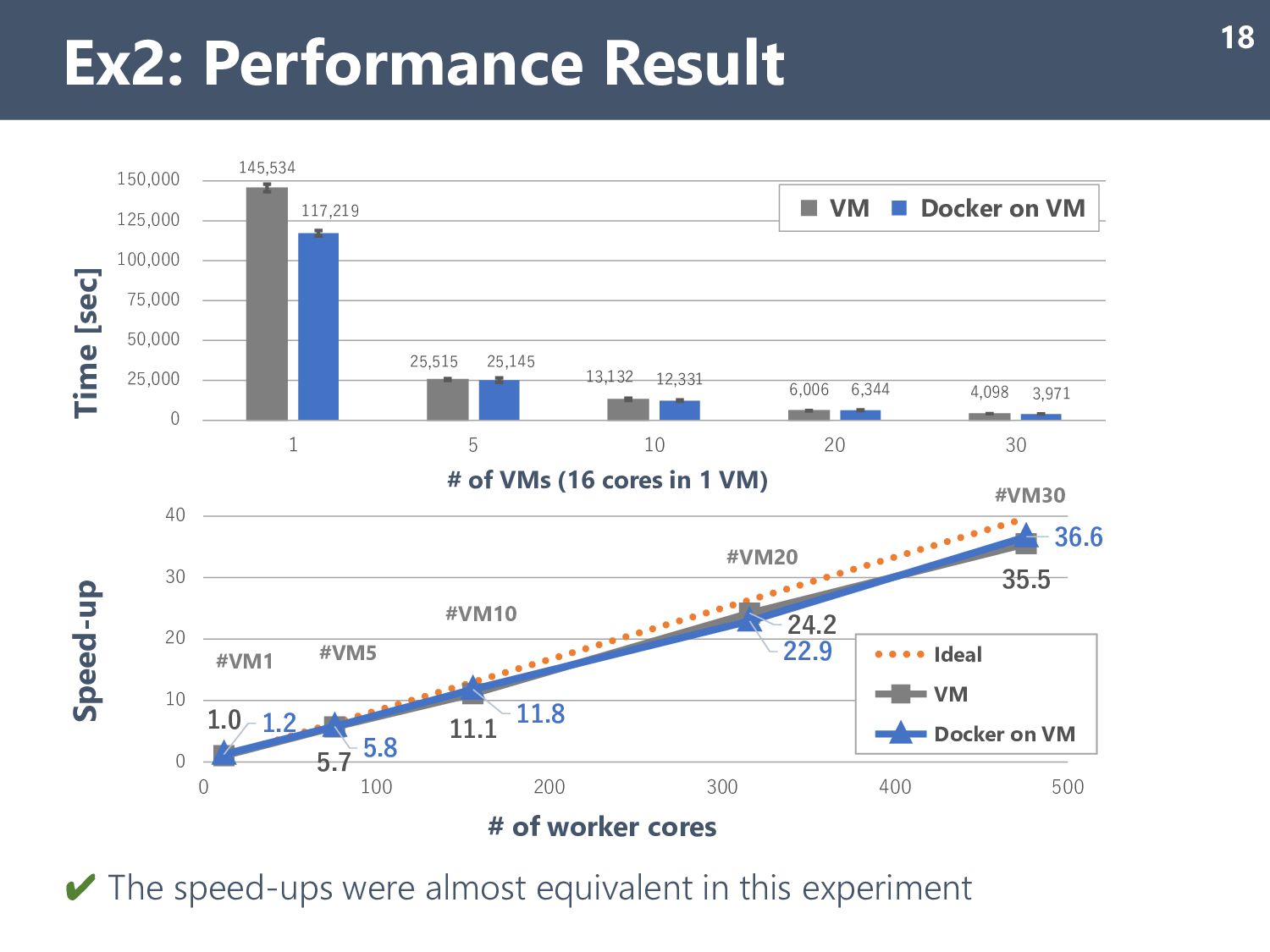
0 25,000 50,000 75,000 100,000 125,000 150,000 1 5 10 20 30 Time [sec] # of VMs (16 cores in 1 VM) VM Docker on VM ✔ The speed-ups were almost equivalent in this experiment Ex2: Performance Result 18 1.0 5.7 11.1 24.2 35.5 1.2 5.8 11.8 22.9 36.6 0 10 20 30 40 0 100 200 300 400 500 Speed-up # of worker cores Ideal VM Docker on VM #VM1 #VM5 #VM10 #VM20 #VM30
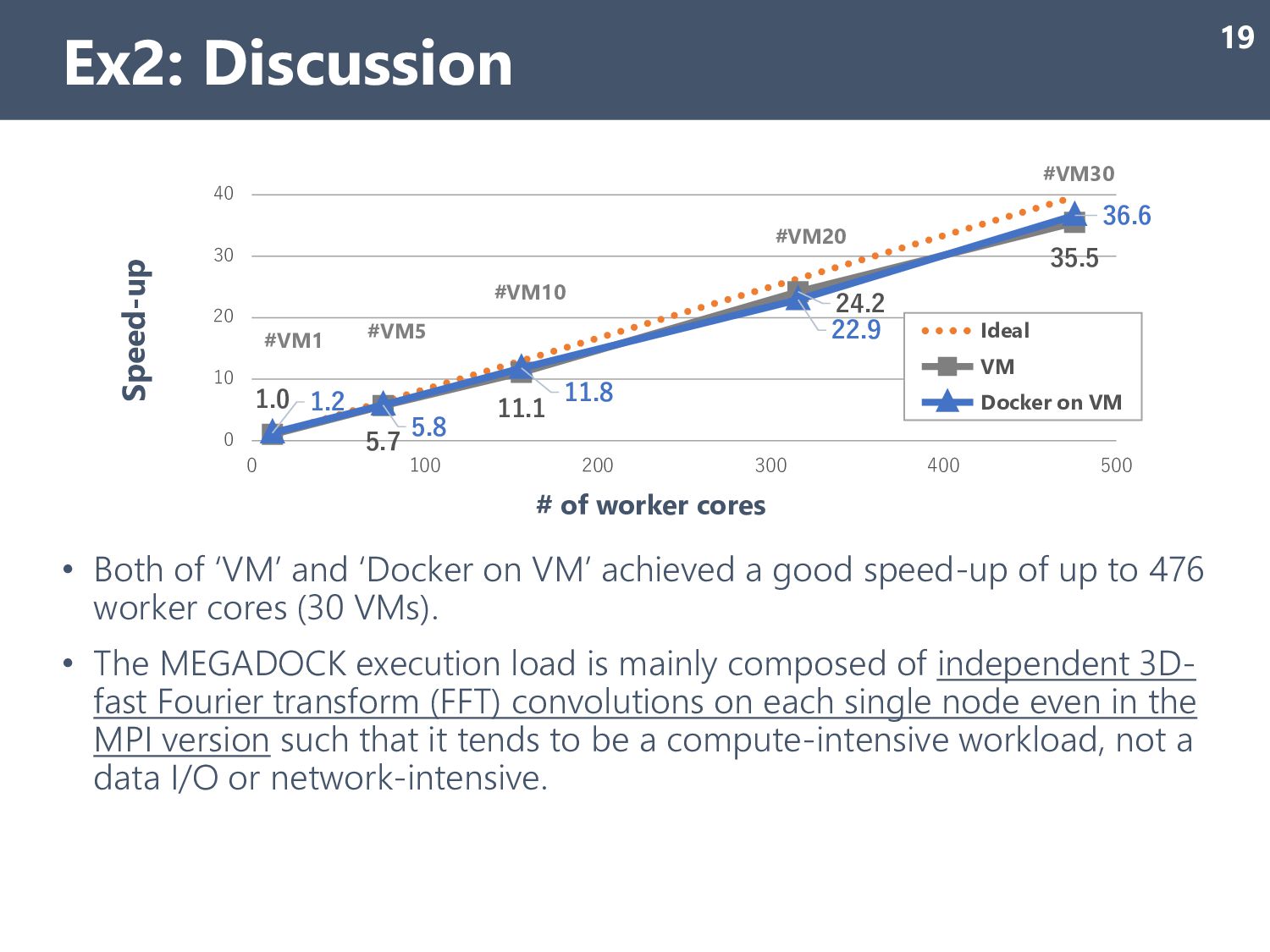
good speed-up of up to 476 worker cores (30 VMs). • The MEGADOCK execution load is mainly composed of independent 3D- fast Fourier transform (FFT) convolutions on each single node even in the MPI version such that it tends to be a compute-intensive workload, not a data I/O or network-intensive. Ex2: Discussion 19 1.0 5.7 11.1 24.2 35.5 1.2 5.8 11.8 22.9 36.6 0 10 20 30 40 0 100 200 300 400 500 Speed-up # of worker cores Ideal VM Docker on VM #VM1 #VM5 #VM10 #VM20 #VM30
this study. So now we are working in progress to demonstrate GPU+MPI parallelization with Singularity containers on multiple-HPC environments. b. In Expriment2, a data point (VM=1) particularly consumed time but the reason was unknown that affected the result of scalability. The reason should be investigated. c. Alternative approach for task distributions framework of MEGADOCK; MapReduce frameworks (e.g. Hadoop, Spark), container frameworks (e.g. Kubernetes, Mesosphere). • needed features: fault-tolerant, auto-recovery from failure, … Discussion 21
cases of with/without container (c, d). • Small performance degradation of approximately +6.3% on the (b) Docker container + MEGADOCK-MPI. Conclusion (1/2) 22 Bare-metal machine Process Process Process Process Bare-metal machine Docker Container Process Process Process Process Bare-metal machine Process GPU Bare-metal machine Docker Container Process GPU c) a) b) d) > x4.5 speed > x4.8 speed ≤+6.3% time ≈±0.5% time
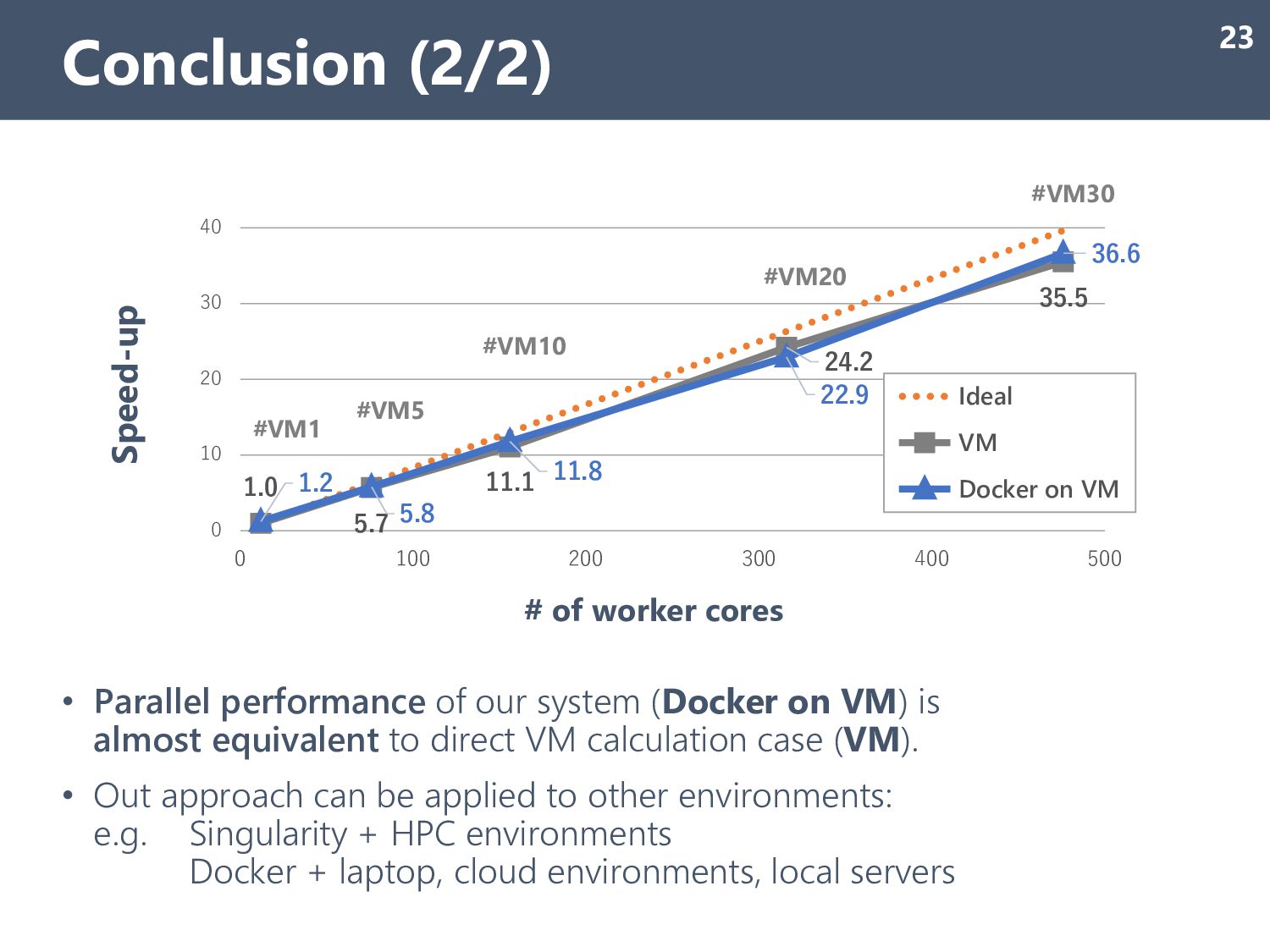
almost equivalent to direct VM calculation case (VM). • Out approach can be applied to other environments: e.g. Singularity + HPC environments Docker + laptop, cloud environments, local servers Conclusion (2/2) 23 1.0 5.7 11.1 24.2 35.5 1.2 5.8 11.8 22.9 36.6 0 10 20 30 40 0 100 200 300 400 500 Speed-up # of worker cores Ideal VM Docker on VM #VM1 #VM5 #VM10 #VM20 #VM30
{kind=link}
{kind=link}
![MEGADOCK [M. Ohue+ 2014] • A high performance Protein-Protein Interaction](https://files.speakerdeck.com/presentations/06b1d91e2bef4a24b3a7d7237efa197c/slide_2.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
![Linux Containers for HPC Env. 7 [G.M. Kurtzer+ 2017] [R.S.](https://files.speakerdeck.com/presentations/06b1d91e2bef4a24b3a7d7237efa197c/slide_6.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![16 Dataset • ZDOCK benchmark 1.0 [R. Chen+ 2003] (59×59](https://files.speakerdeck.com/presentations/06b1d91e2bef4a24b3a7d7237efa197c/slide_15.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}