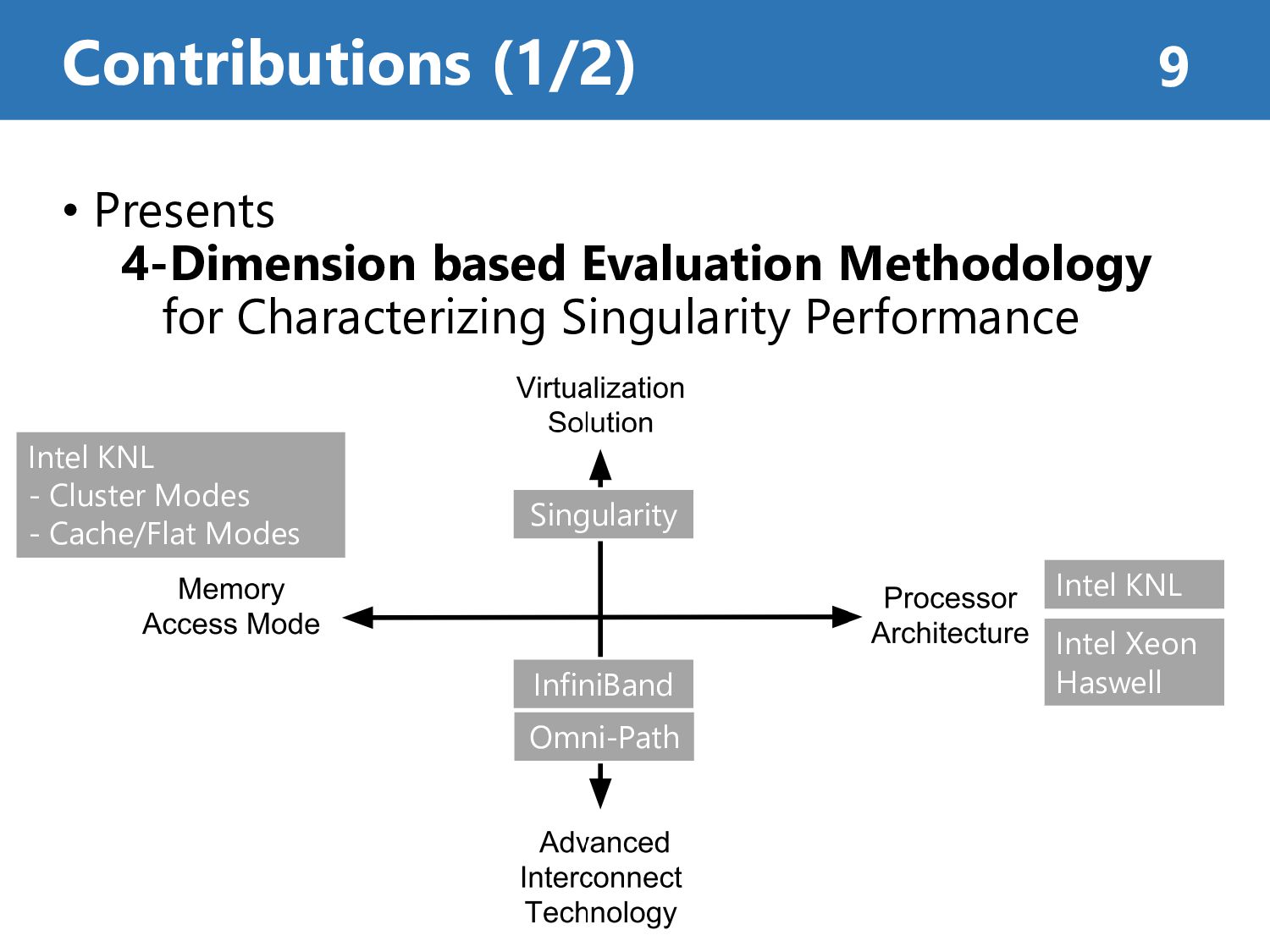
HPC Clouds? by Jie Zhang, Xiaoyi Lu, Dhabaleswar K. Panda* * The Ohio State University In Proceedings of the10th International Conference on Utility and Cloud Computing (UCC '17) pp.151-160, 2017. Kento Aoyama, Ph.D. Student Akiyama Laboratory, Dept. of Computer Science, Tokyo Institute of Technology Journal Seminar (Akiyama and Ishida Laboratory) on April 19th, 2018
Lab) • Best Student Paper Award (UCC’17, this paper) Prof. Dhabaleswar K. (DK) Panda • Professor of the Ohio State University • Faculty of NOWLAB MVAPICH • famous MPI Implementation in HPC e.g.) Sunway TaihuLight, TSUBAME2.5, etc. • http://mvapich.cse.ohio-state.edu/publications/ OSU Benchmark • MPI Communication Benchmark • point-to-point, collective, non-blocking, GPU memory access, … Authors 7 “The MVAPICH Project: Evolution and Sustainability of an Open Source Production Quality MPI Library for HPC” D. Panda, K. Tomko, K. Schulz, A. Majumdar Int'l Workshop on Sustainable Software for Science: Practice and Experiences, Nov 2013. http://nowlab.cse.ohio-state.edu/people
on HPC Clouds?” Answer: Yes. • Singularity shows near-native performance even when running MPI (HPC) applications • Container-Technology is ready for HPC field! What’s the message? 8
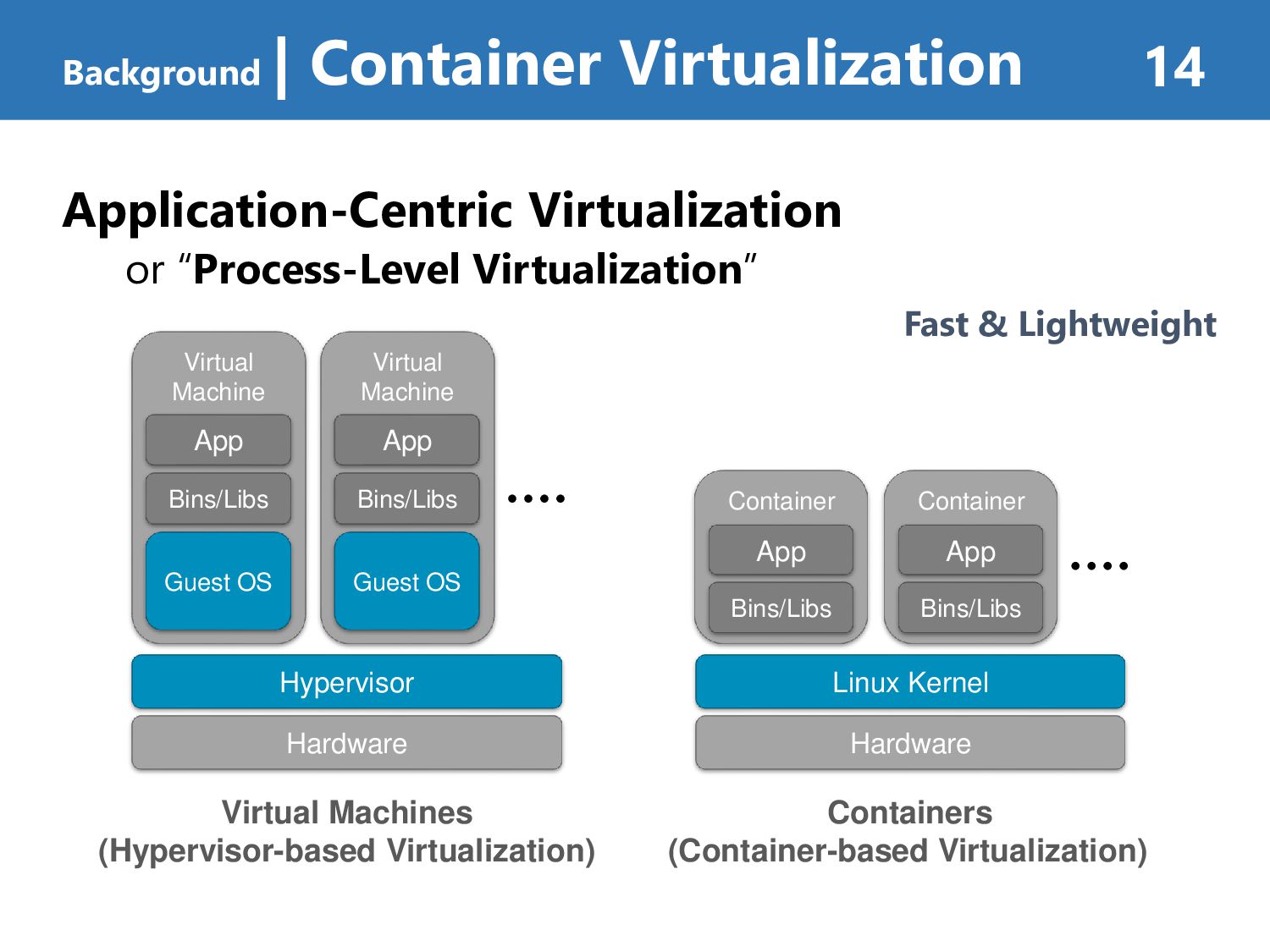
namespace. • No visibility to objects outside the container • Containers have another level of access controls namespace • namespace can isolates system resources • creates separate instances of global namespaces • process id (PID), host & domain name (UTS), inter-process communication (IPC), users (UID), … • Processes running inside the container … • shares the host Linux kernel • has its own root directory and mount table • performs to be running on a normal Linux system Background | Linux Container (namespace) 15 E. W. Biederman. “Multiple instances of the global Linux namespaces.”, In Proceedings of the 2006 Ottawa Linux Symposium, 2006. Hardware Linux Kernel Container App Bins/Libs own namespace, pid, uid, gid, hosntname, filesystem, …
I/O, File I/O, … • Latency, Bandwidth, Throughput, … How about on Security? • requires root-daemon process (Docker) • requires SUID for binary (Shifter, Singularity) How about on Usability? • where to store container image (repository, local file, …) • affinity with user’s workflow Background | Concerns on HPC Field 17
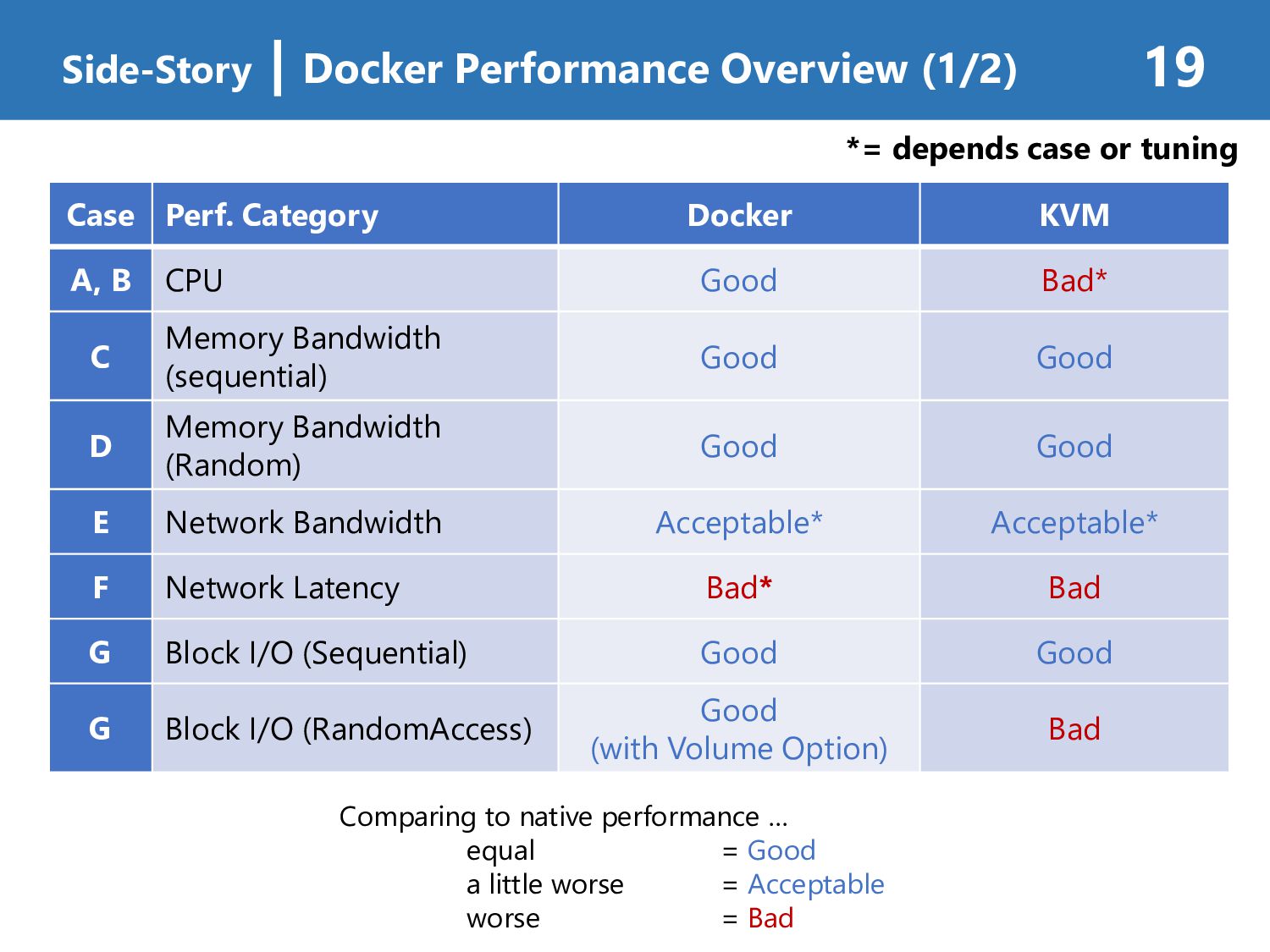
Docker KVM A, B CPU Good Bad* C Memory Bandwidth (sequential) Good Good D Memory Bandwidth (Random) Good Good E Network Bandwidth Acceptable* Acceptable* F Network Latency Bad* Bad G Block I/O (Sequential) Good Good G Block I/O (RandomAccess) Good (with Volume Option) Bad Comparing to native performance … equal = Good a little worse = Acceptable worse = Bad *= depends case or tuning
A. Ferreira, R. Rajamony, and J. Rubio, “An updated performance comparison of virtual machines and Linux containers,” IEEE International Symposium on Performance Analysis of Systems and Software, pp.171-172, 2015. (IBM Research Report, RC25482 (AUS1407-001), 2014.) 0.96 1.00 0.98 0.78 0.83 0.99 0.82 0.98 0.00 0.20 0.40 0.60 0.80 1.00 PXZ [MB/s] Linpack [GFLOPS] Random Access [GUPS] Performance Ratio [based Native] Native Docker KVM KVM-tuned
Shifter W. Bhimji, S. Canon, D. Jacobsen, L. Gerhardt, M. Mustafa, and J. Porter, “Shifter : Containers for HPC,” Cray User Group, pp. 1–12, 2016. Singularity Gregory M. K., Vanessa S., Michael W. B., “Singularity: Scientific containers for mobility of compute”, PLOS ONE 12(5): e0177459. Background | Containers for HPC 21
Michael W. B., “Singularity: Scientific containers for mobility of compute”, PLOS ONE 12(5): e0177459. Linux Container OSS for HPC Workload • Developed by LBNL (Lawrence Berkeley National Laboratory, USA) Key Features • Near-native performance • Not-require the root daemon • Compatible with Docker Container Format • Support HPC Features • NVIDIA GPU, MPI, InfiniBand, etc. http://singularity.lbl.gov/
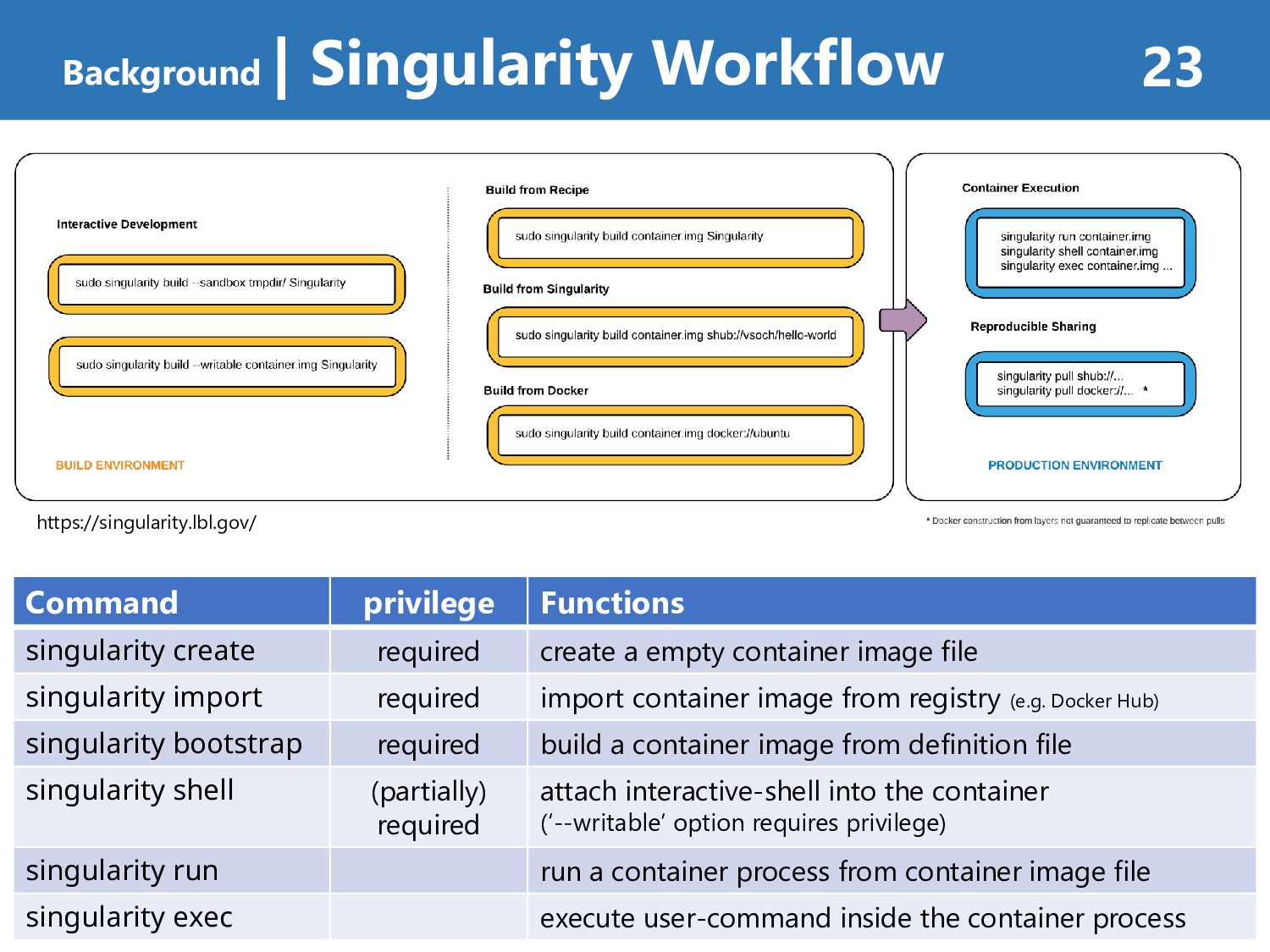
required create a empty container image file singularity import required import container image from registry (e.g. Docker Hub) singularity bootstrap required build a container image from definition file singularity shell (partially) required attach interactive-shell into the container (‘--writable’ option requires privilege) singularity run run a container process from container image file singularity exec execute user-command inside the container process https://singularity.lbl.gov/
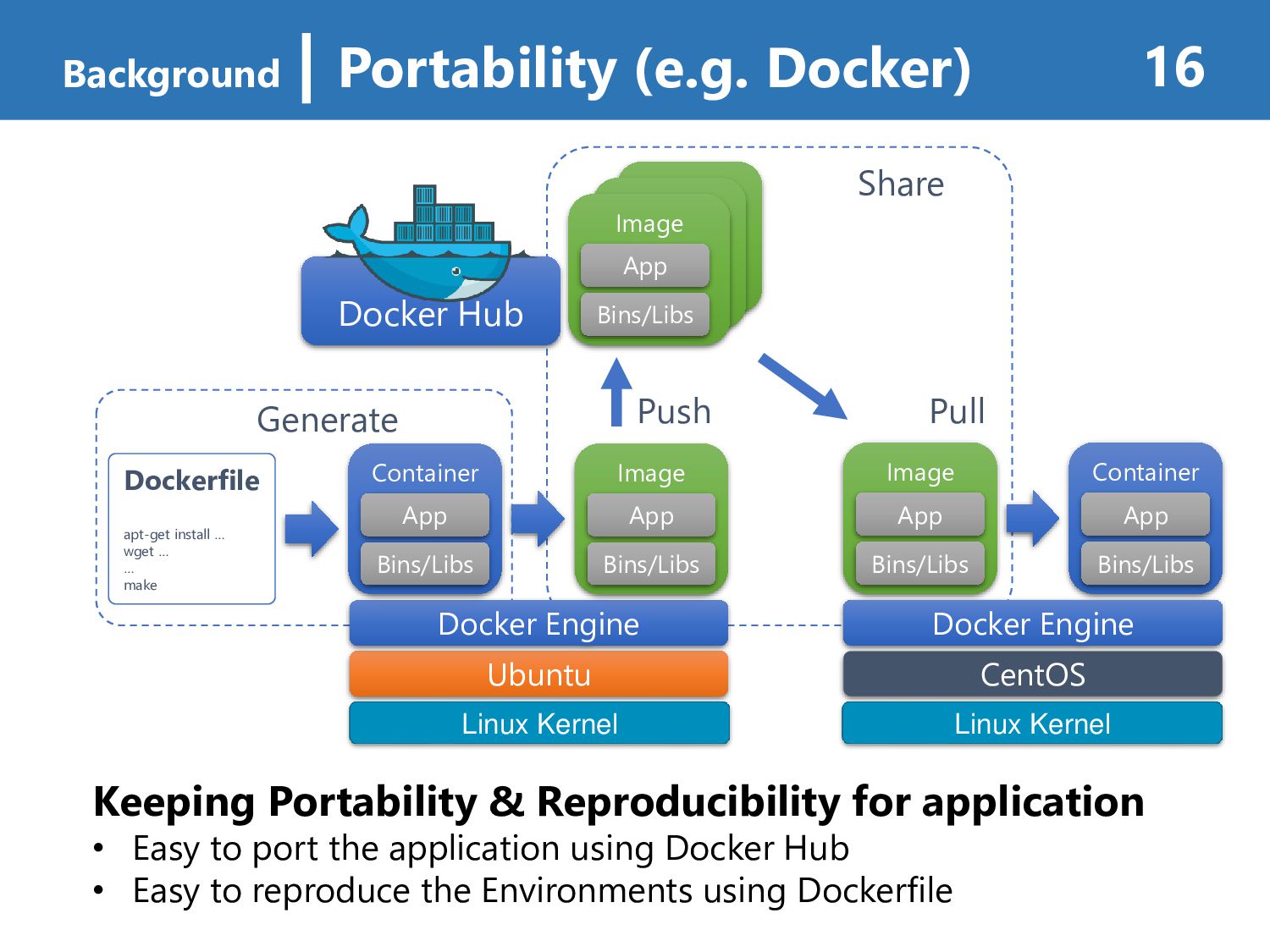
packages library dependencies • can provide Application Portability & Reproducibility under the reasonable Performance • “Singularity” is a Linux Container OSS for HPC Workloads • provide near-native performance • support HPC features (GPU, MPI, InfiniBand, …) Background | Summary 24
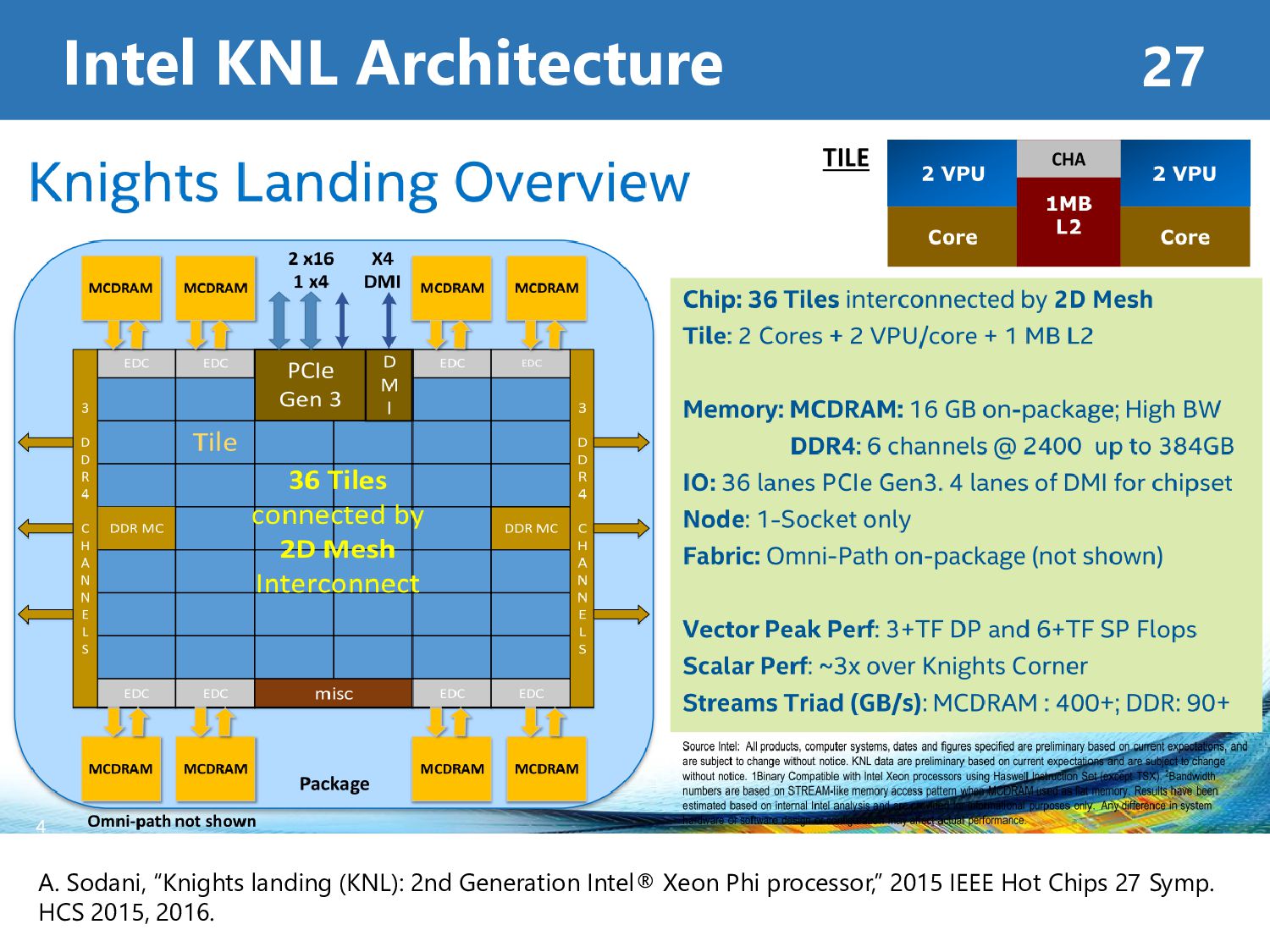
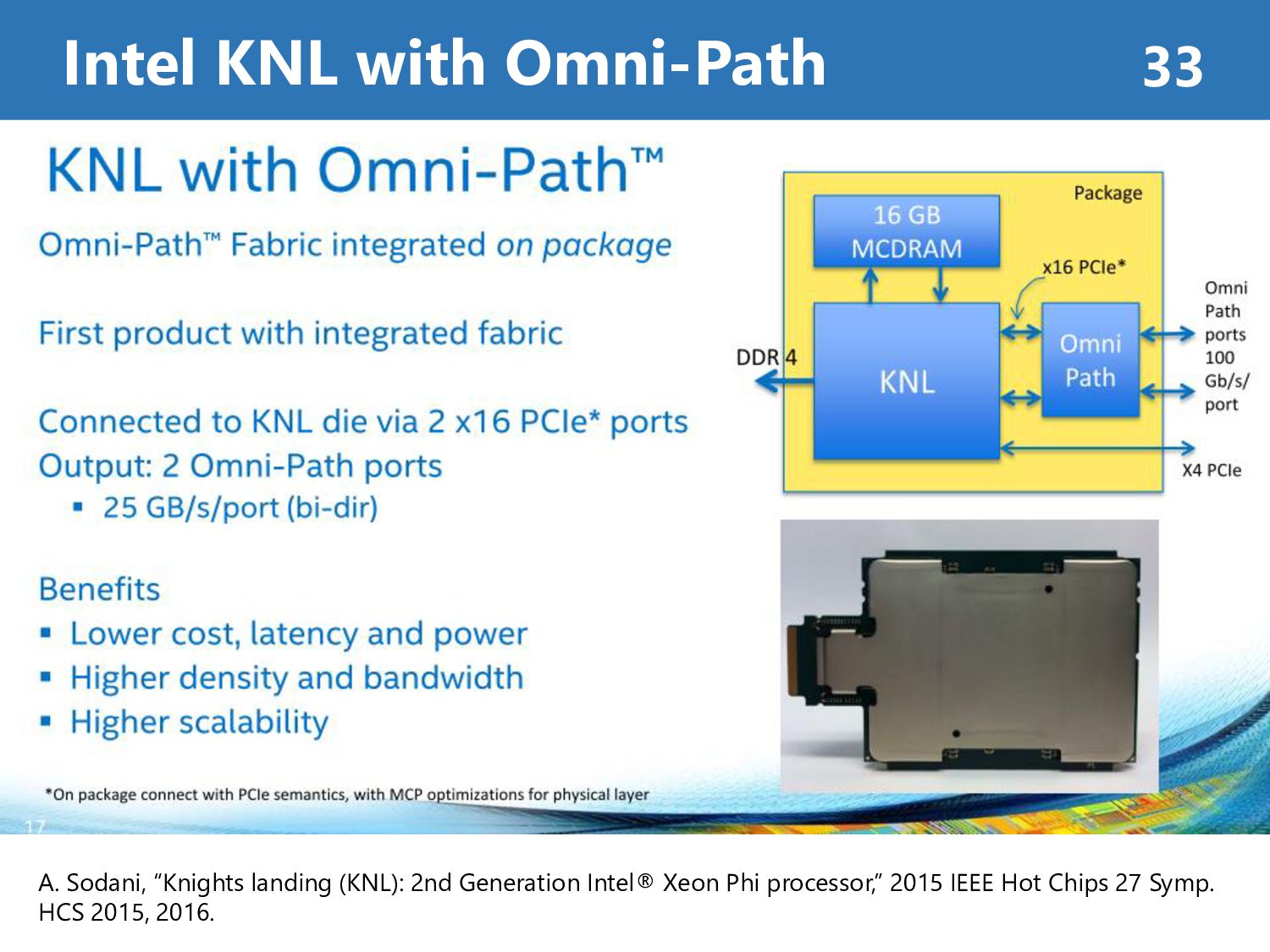
Processor • MIC (Many Integrated Core) designed by Intel® for High-Performance Computing • covers similar HPC areas with GPU • allow use of standard programming language API such as OpenMP, MPI, … • Examples of use on Supercomputers • Oakforest-PACS by JCAHPC (Tokyo Univ., Tsukuba Univ.) • Tianhe-2A by NSCC-GZ (China) A. Sodani, “Knights landing (KNL): 2nd Generation Intel® Xeon Phi processor,” 2015 IEEE Hot Chips 27 Symp. HCS 2015, 2016.
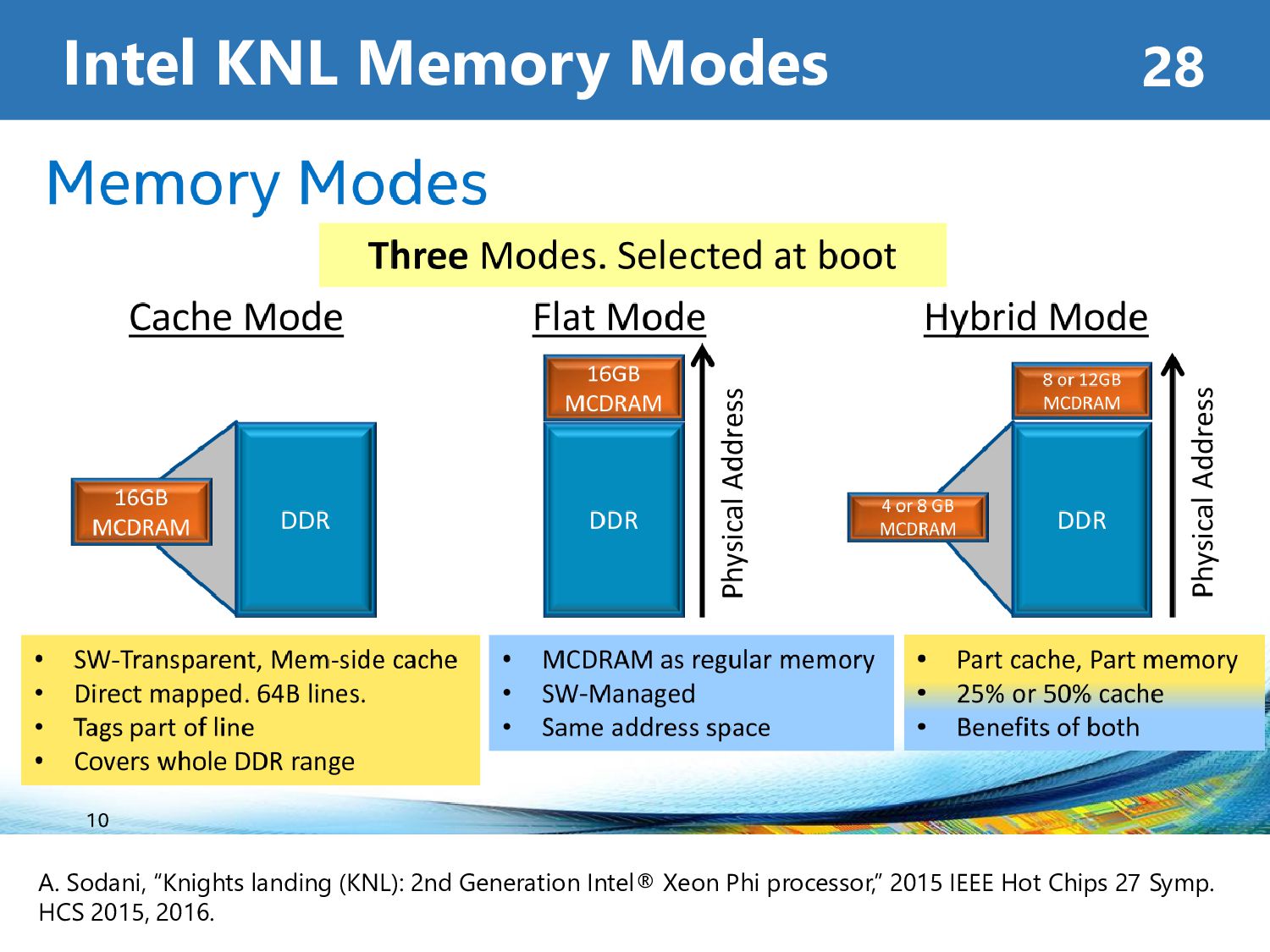
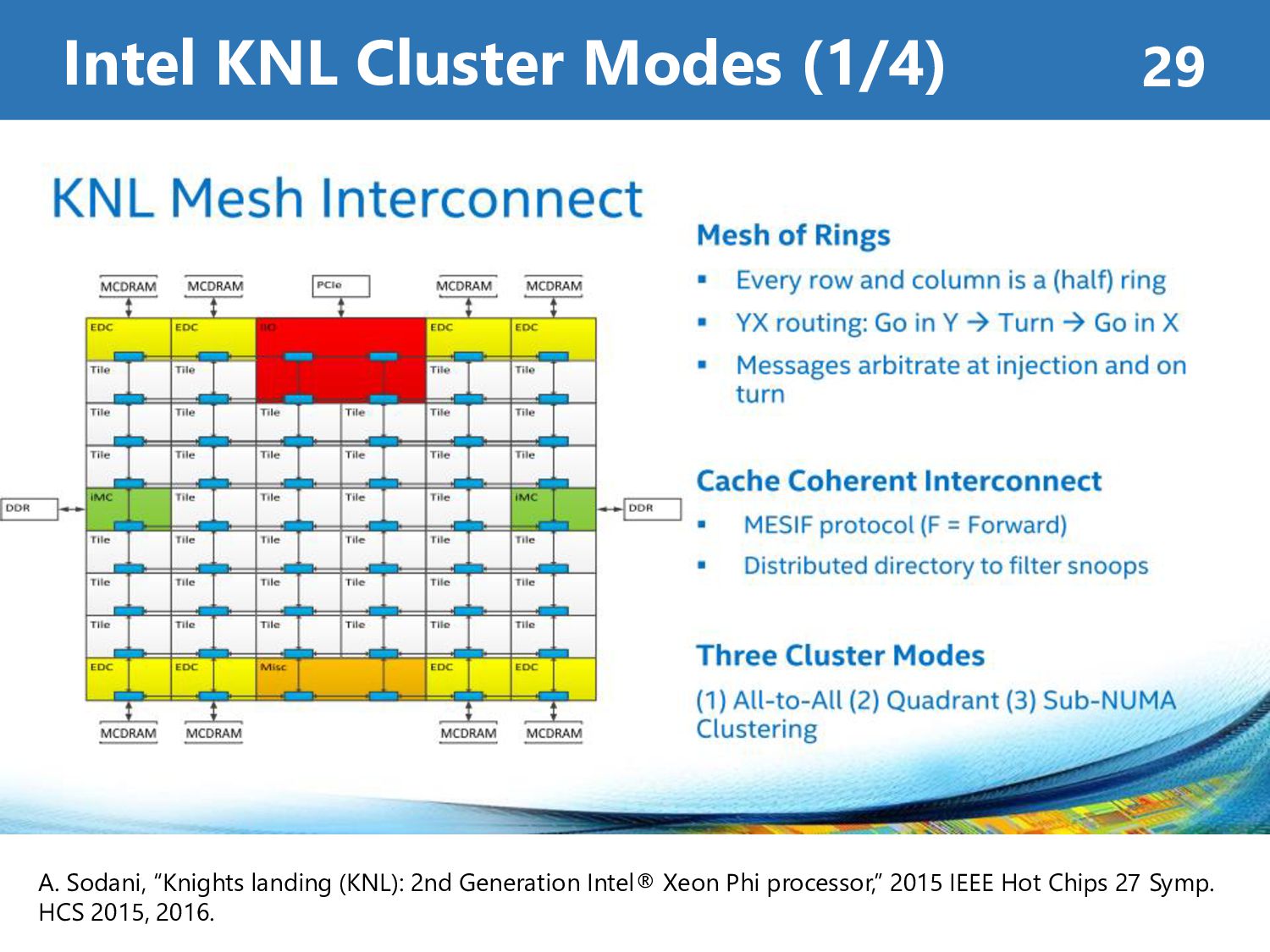
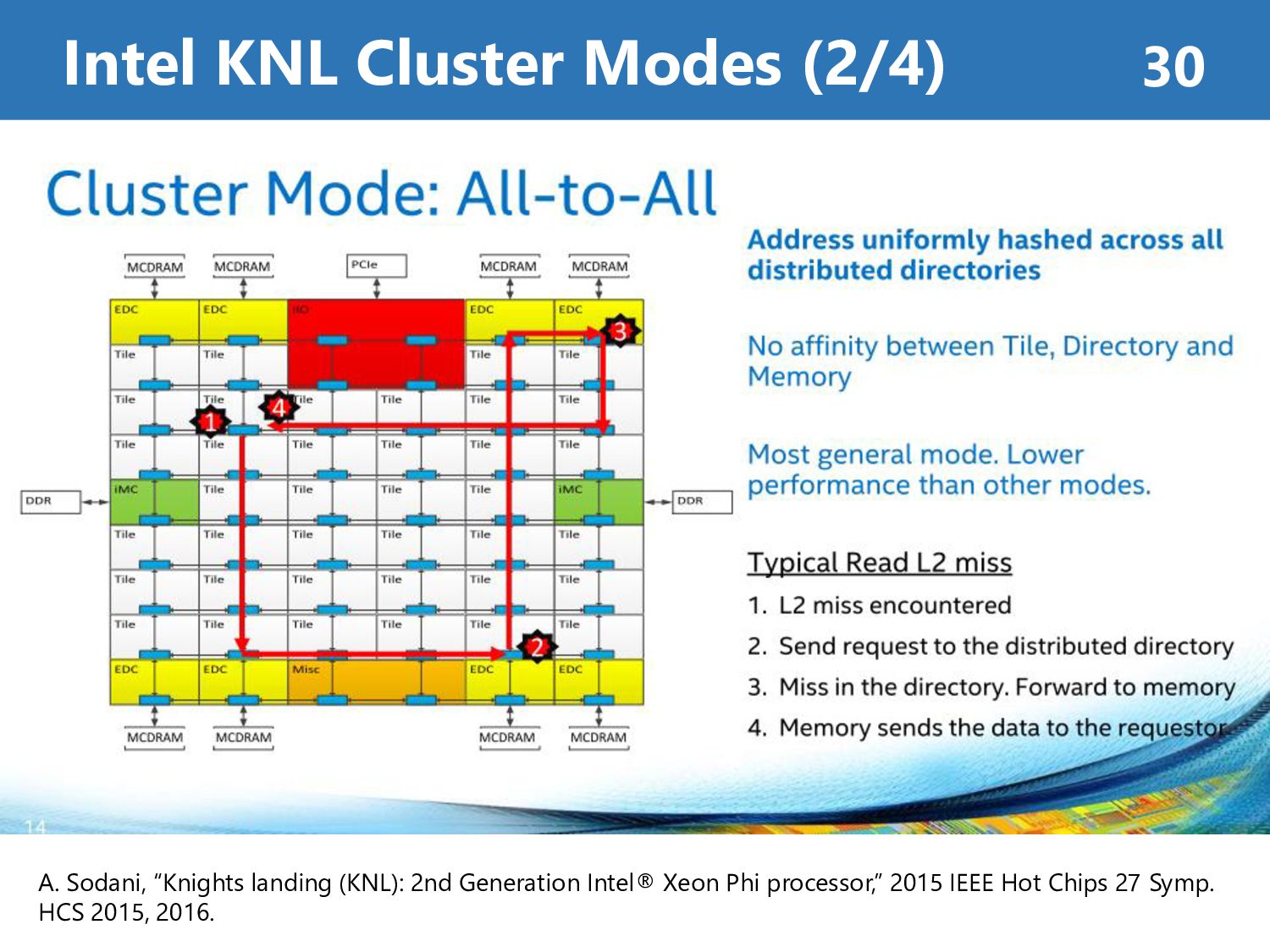
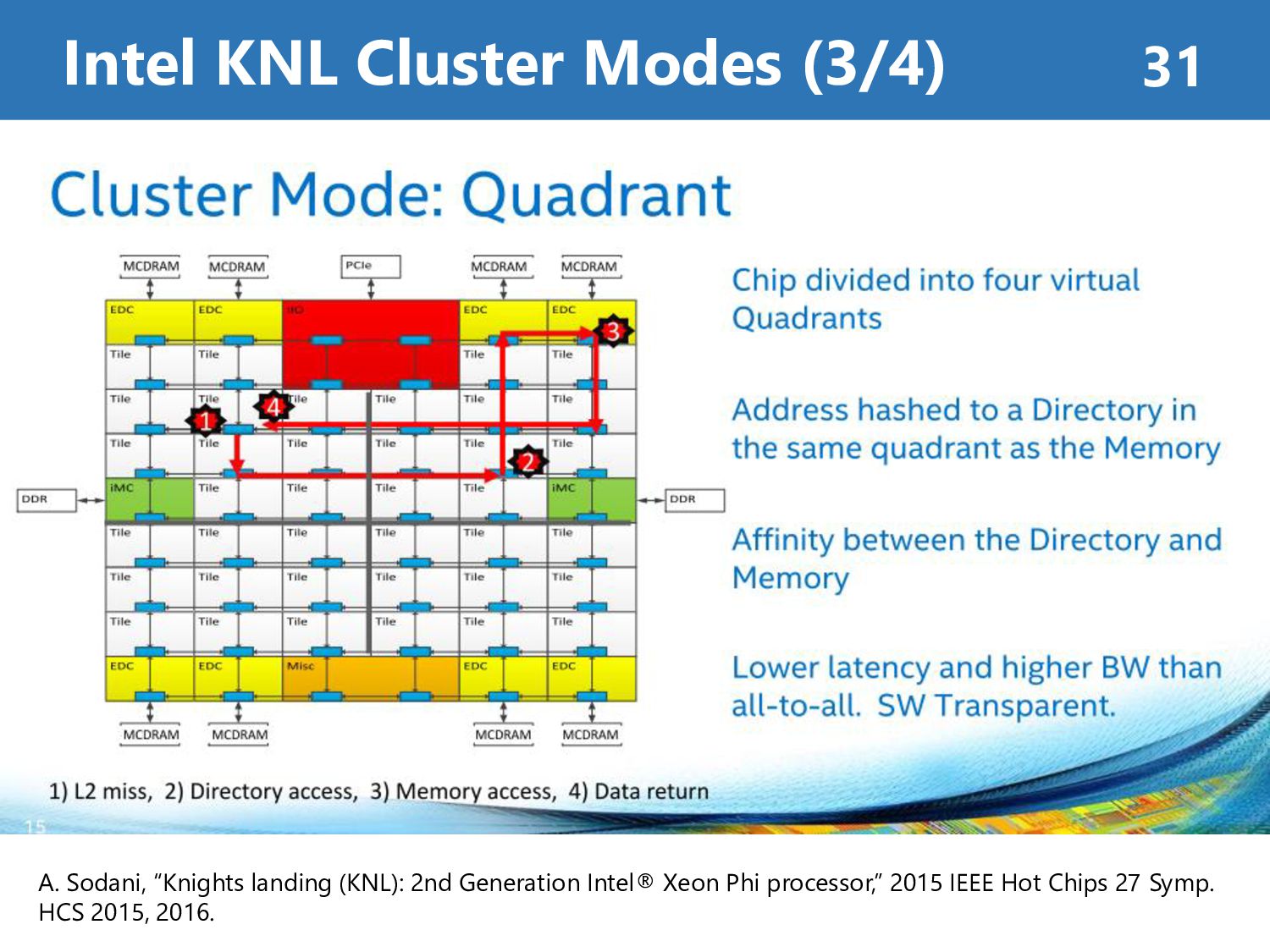
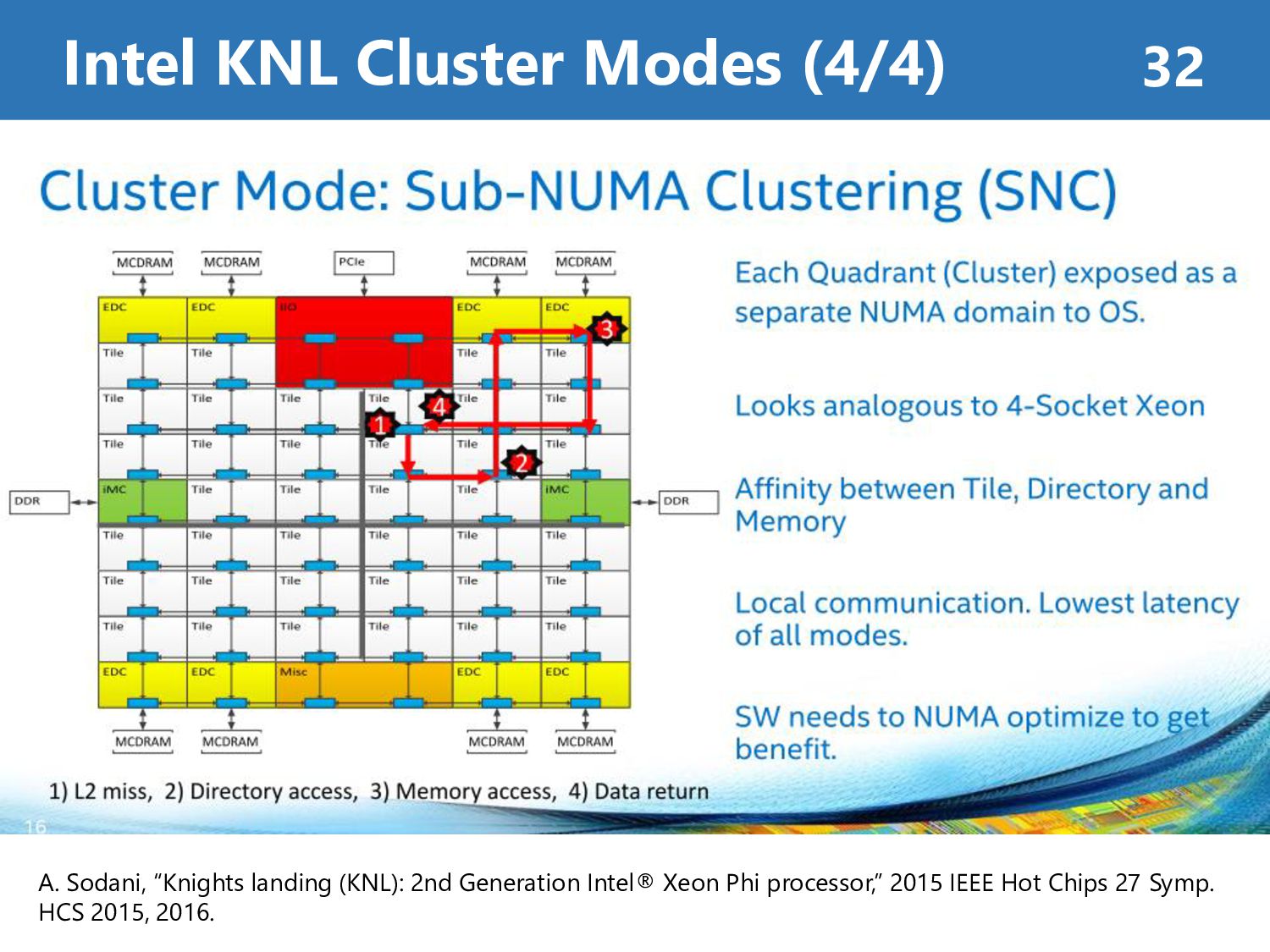
Memory Mode • Cache Mode : Automatically use MCDRAM as L3-Cache • Flat Mode : Manually allocate data onto MCDRAM Cluster Mode • All-to-All : Address uniformly hashed across all distributed directories • Quadrant : Address divided into same quadrant • SNC : Each quadrant exposed as a NUMA node (can be seen as 4 sockets) Intel KNL Summary 34
for compiling all application & libraries on experiments) • MPI library: MVAPICH2-2.3a • OSU micro-benchmarks v5.3 Others • Results are averaged across 5 runs • Cluster mode was set to “All-to-All” or “Quadrant” (?) • >“Since there is only one NUMA node on KNL architecture, we do not consider intra/inter-socket anymore here.” Other Settings 38
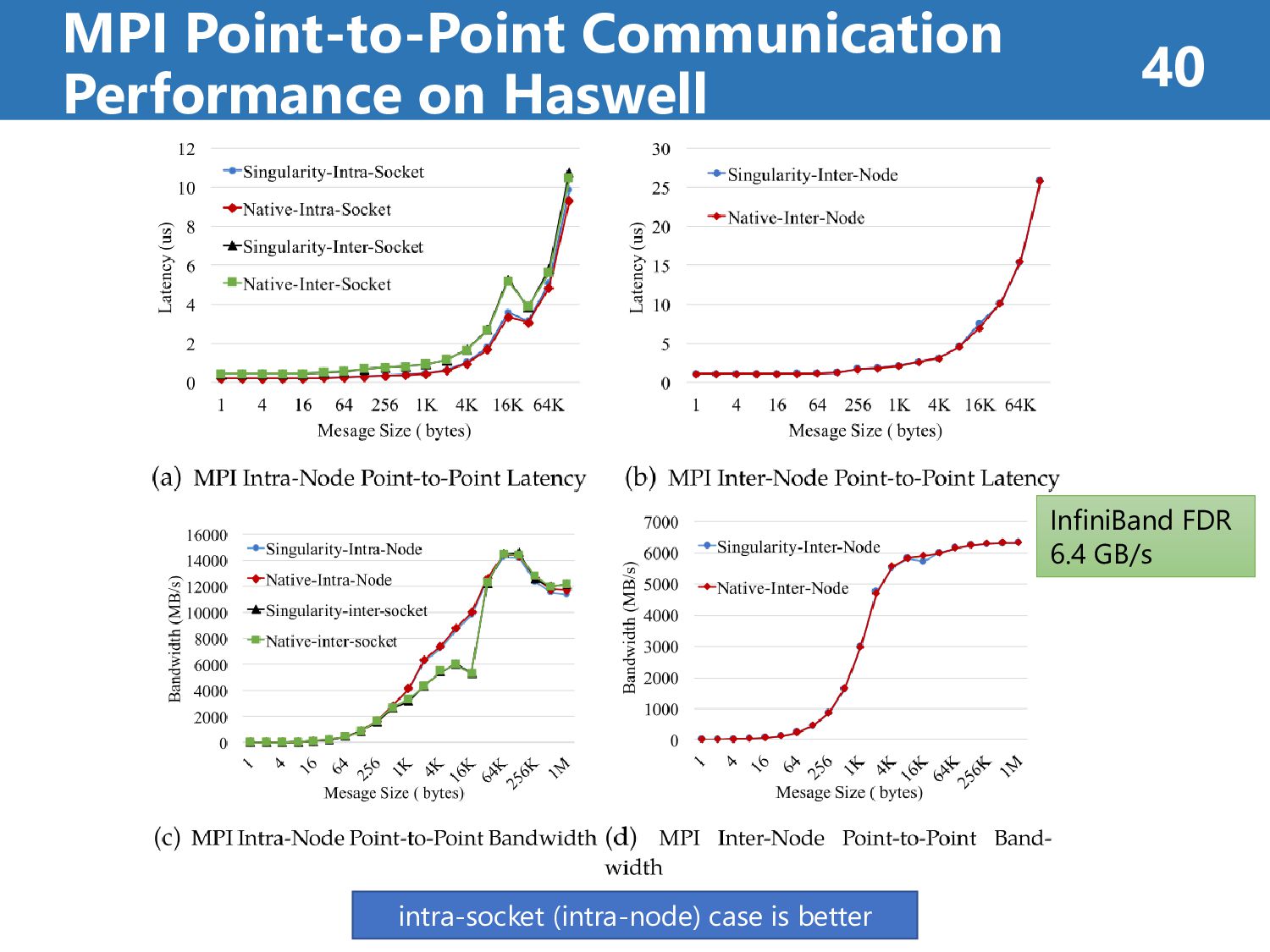
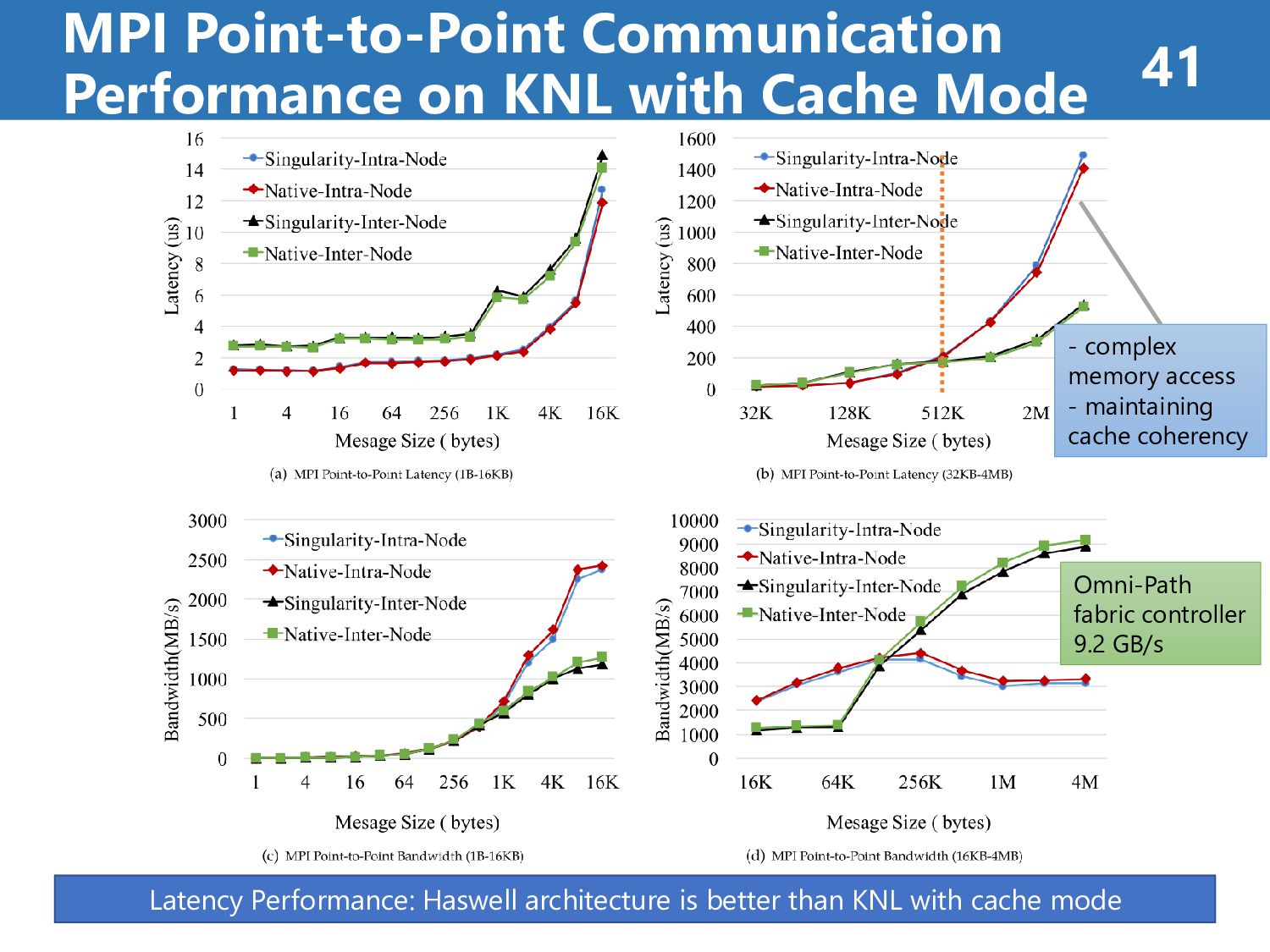
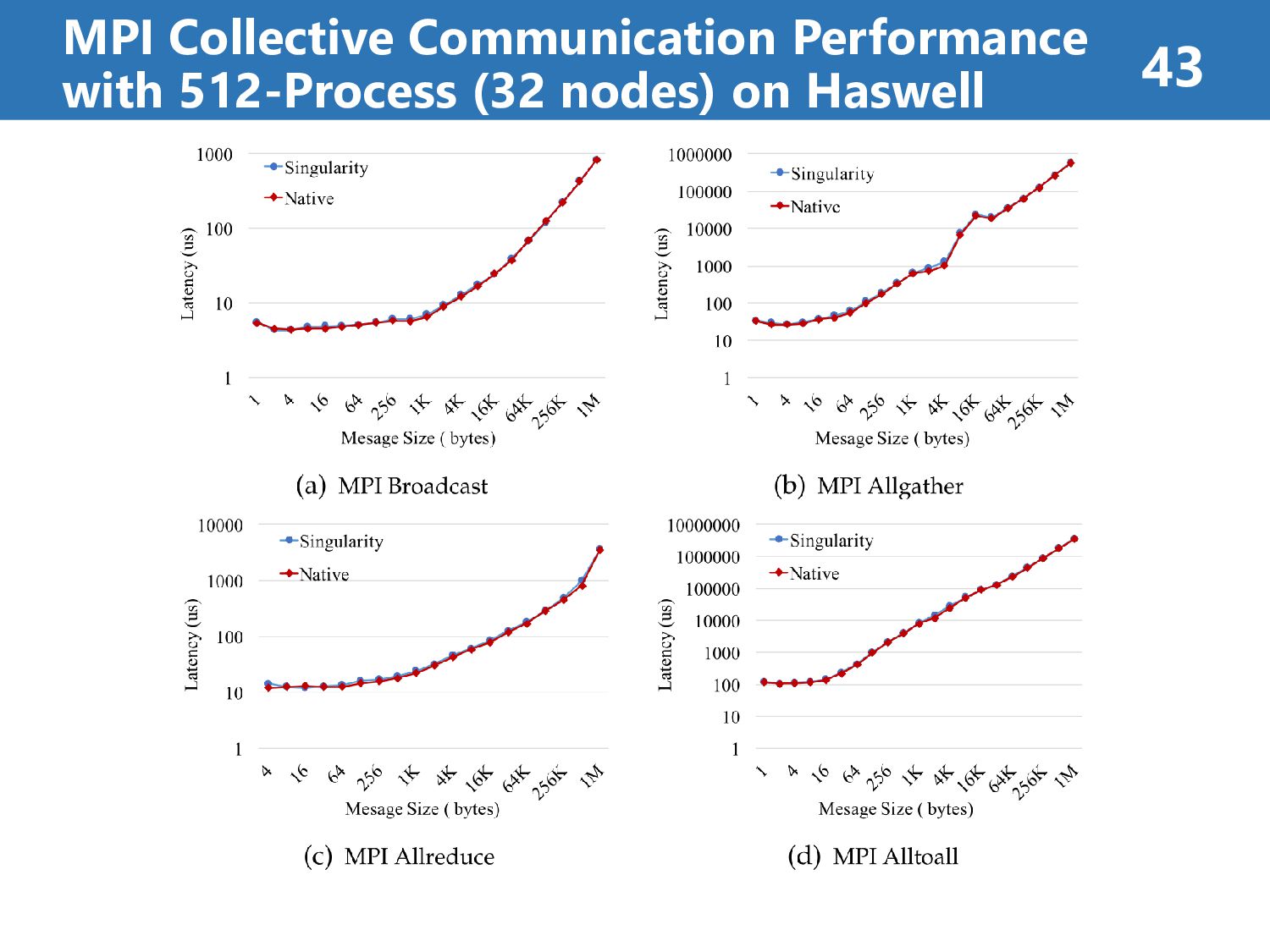
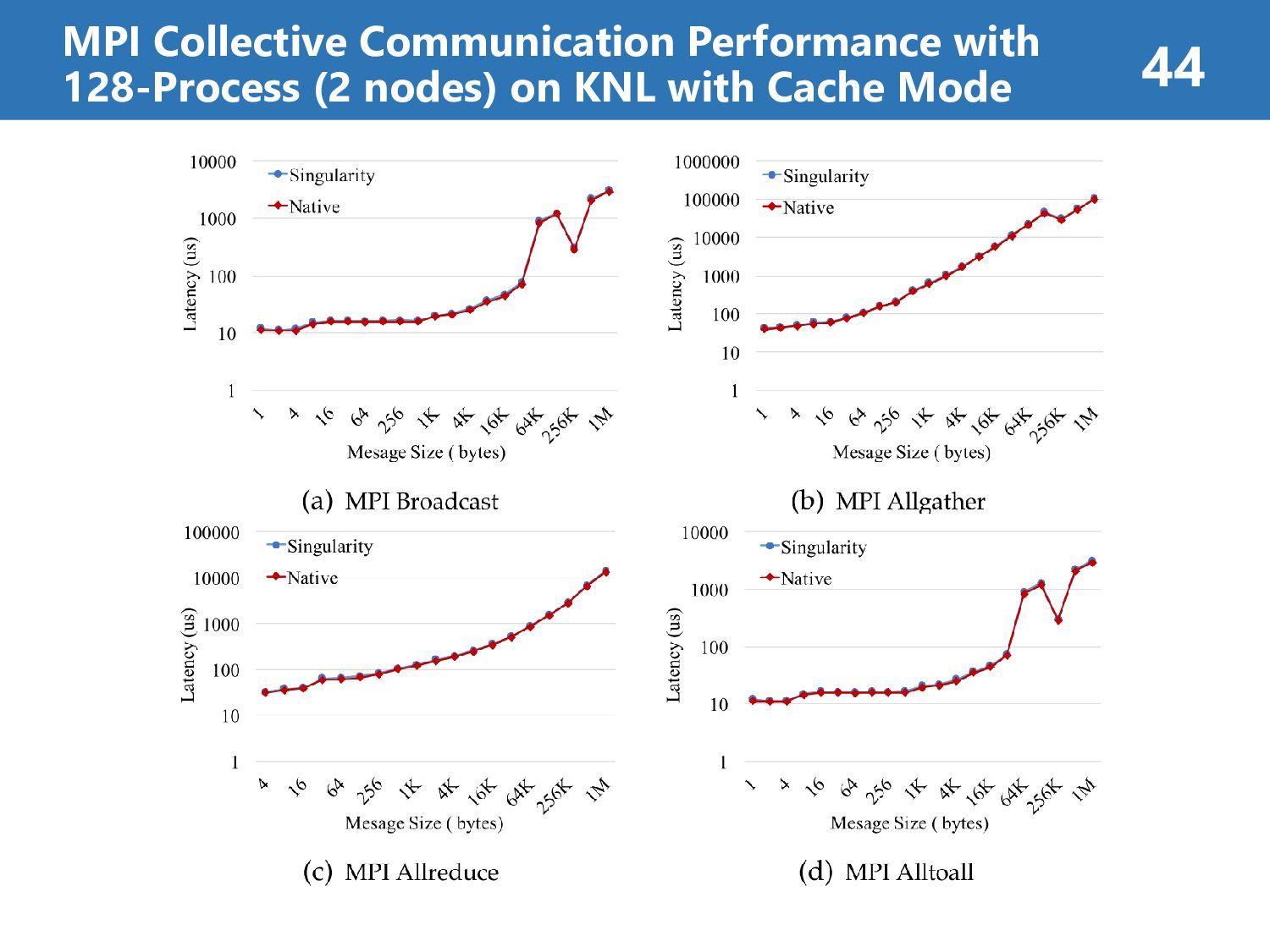
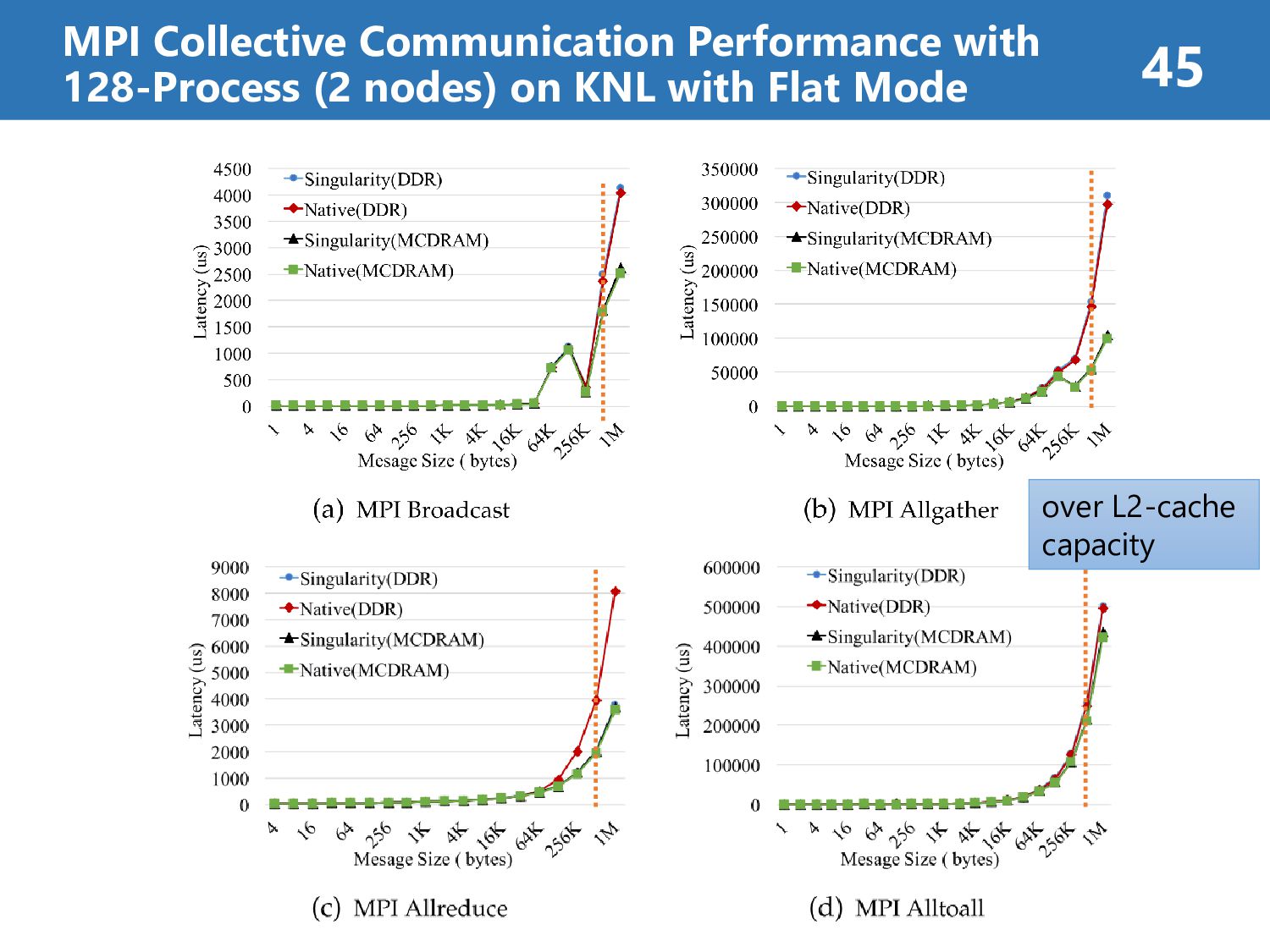
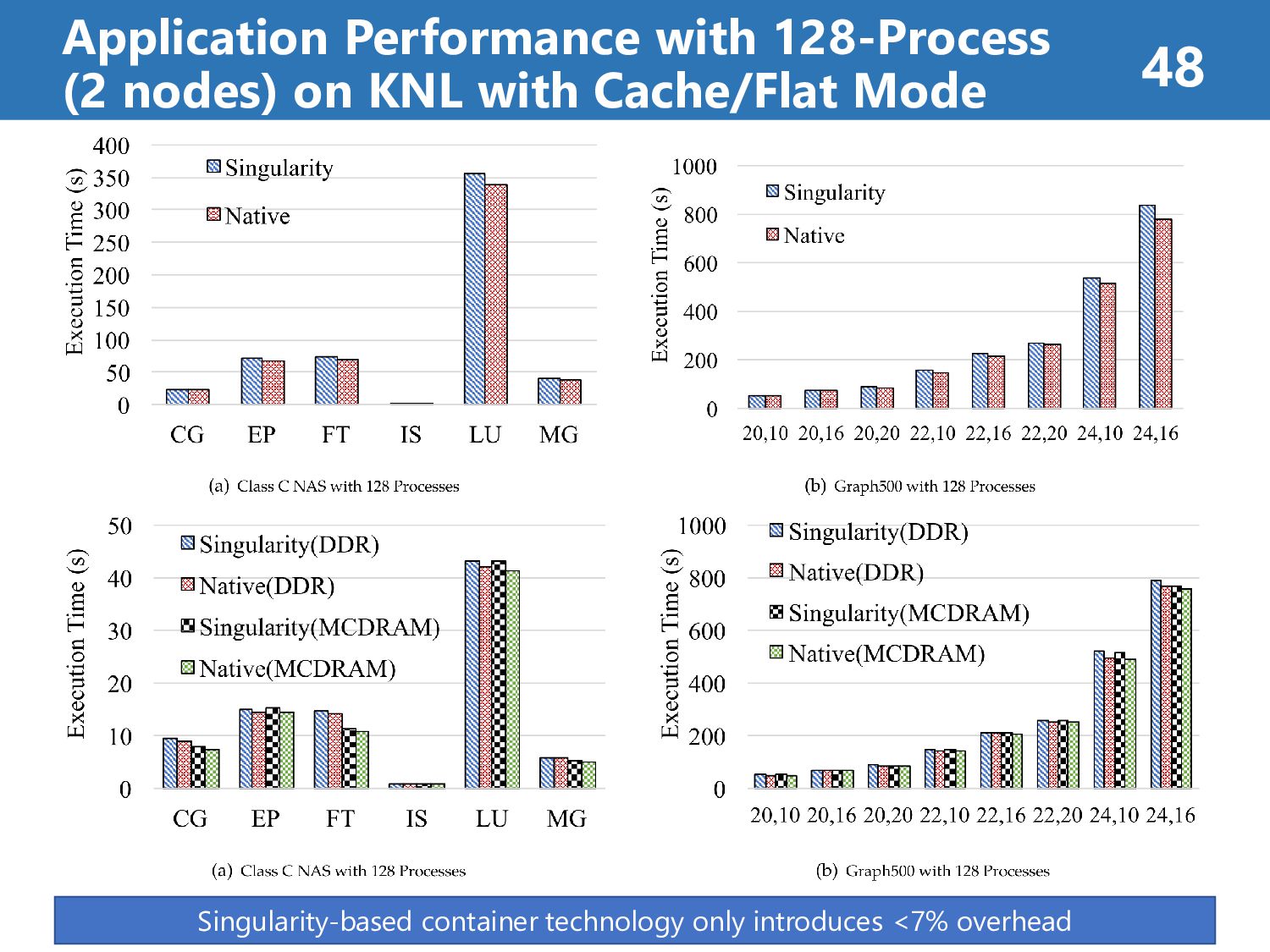
than 7% (on Haswell) • Singularity’s overhead is less than 8% (on KNL) case2: MPI Collective Communication Performance • Singularity’s overhead is less than 8% at all operations • Singularity reflects native performance characteristics case3: HPC Application Performance • Singularity’s overhead is less than 7% at all case “It reveals a promising way for efficiently running MPI applications on HPC clouds.” Results Summary (about Singularity) 39
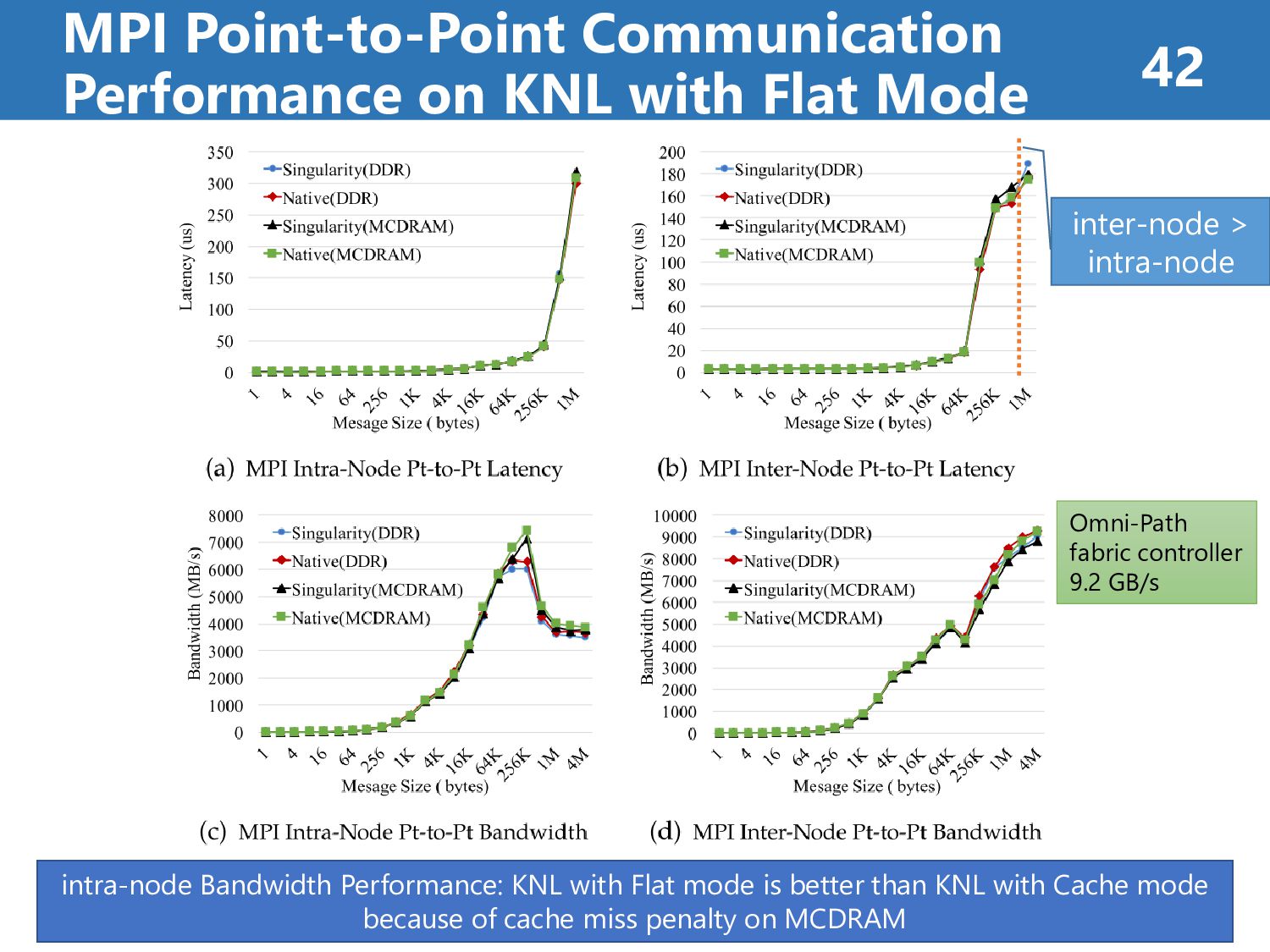
Omni-Path fabric controller 9.2 GB/s inter-node > intra-node intra-node Bandwidth Performance: KNL with Flat mode is better than KNL with Cache mode because of cache miss penalty on MCDRAM
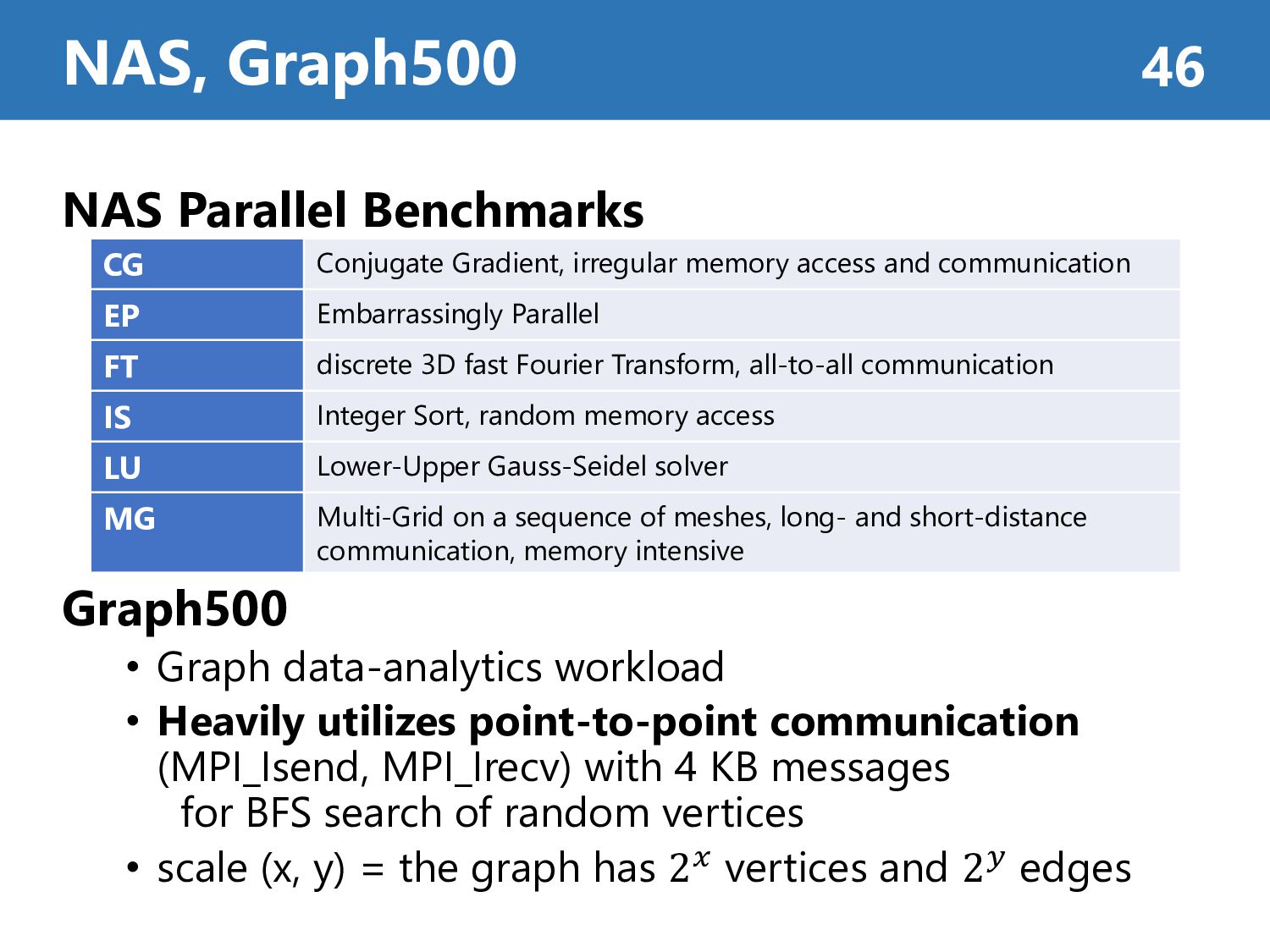
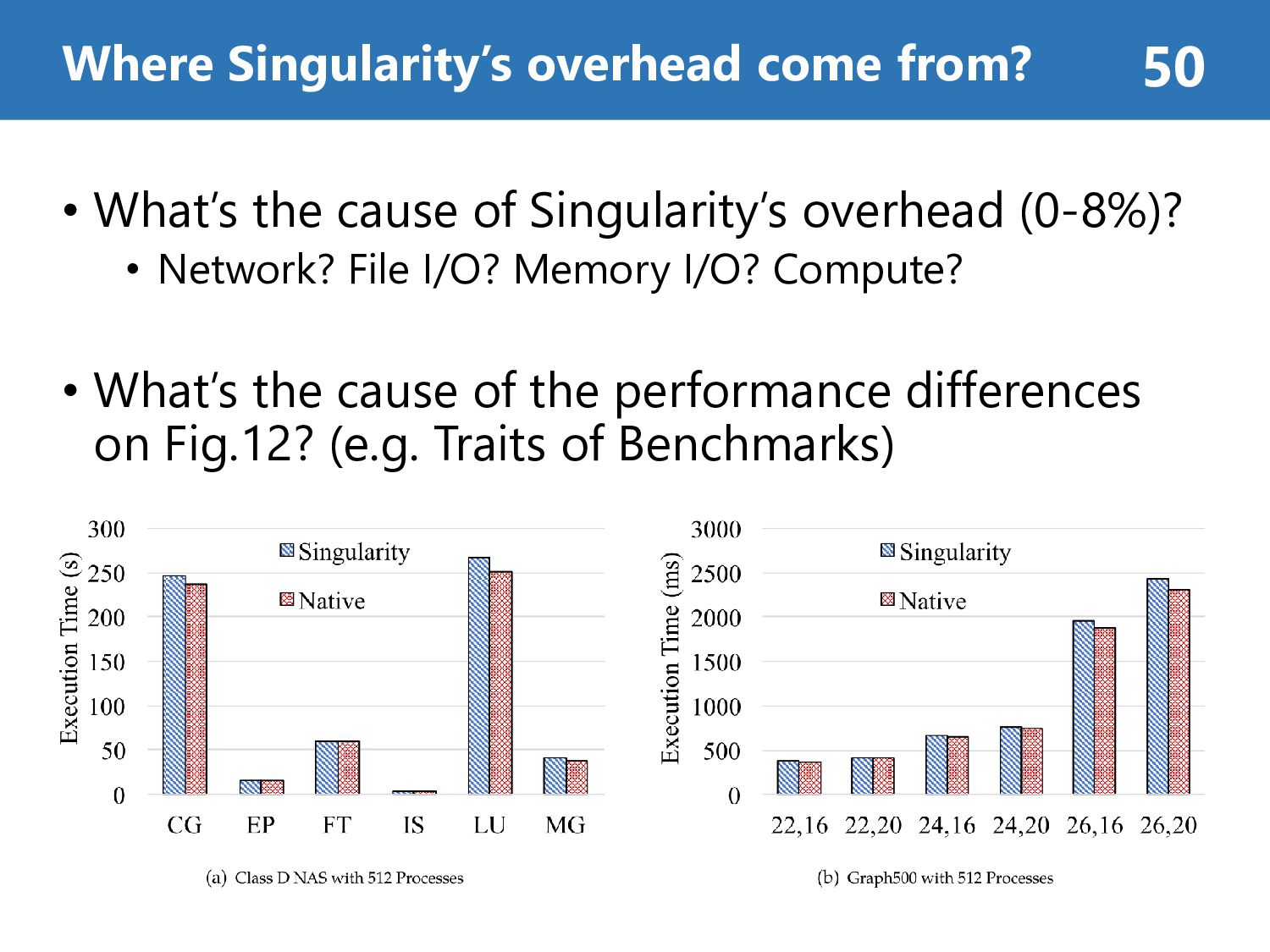
utilizes point-to-point communication (MPI_Isend, MPI_Irecv) with 4 KB messages for BFS search of random vertices • scale (x, y) = the graph has 2𝑥 vertices and 2𝑦 edges NAS, Graph500 46 CG Conjugate Gradient, irregular memory access and communication EP Embarrassingly Parallel FT discrete 3D fast Fourier Transform, all-to-all communication IS Integer Sort, random memory access LU Lower-Upper Gauss-Seidel solver MG Multi-Grid on a sequence of meshes, long- and short-distance communication, memory intensive
File I/O? Memory I/O? Compute? • What’s the cause of the performance differences on Fig.12? (e.g. Traits of Benchmarks) Where Singularity’s overhead come from? 50
and activated 3. The Singularity command (subcommand) process is activated 4. Subcommand options are parsed 5. The appropriate sanity checks are made 6. Environment variables are set 7. The Singularity Execution binary is called (sexec) 8. Sexec determines if it is running privileged and calls the SUID code if necessary 9. Namespaces are created depending on configuration and process requirements 10. The Singularity image is checked, parsed, and mounted in the CLONE_NEWNS namespace 11. Bind mount points are setup so that files on the host are visible in the container 12. The namespace CLONE_FS is used to virtualize a new root file system 13. Singularity calls execvp() and Singularity process itself is replaced by the process inside the container 14. When the process inside the container exits, all namespaces collapse with that process, leaving a clean system (material) Singularity Process Flow 51
conducted the comprehensive studies to evaluate the Singularity’s performance • Singularity-based container technology can achieve near-native performance on Intel Xeon/KNL • Singularity provides a promising way to build the next-generation HPC clouds Conclusion 53
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
![Side-Story | Docker Performance Overview (2/2) 20 [1] W. Felter,](https://files.speakerdeck.com/presentations/06a9dfbd9e2a428885e3f441a90fdd10/slide_19.jpg){kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}